Hive学习——分桶抽样、侧视图与炸裂函数搭配、hive实现WordCount
目录
一、分桶抽样
1.抽取表中10%的数据
2.抽取表中30%的数据
3.取第一行
4.取第10行
5.数据块抽样
6.tablesample详解
二、UDTF——表生成函数
1.explode()——炸裂函数
2.posexpolde()——只能对array进行炸裂
3.inline()——炸裂结构体数组
三、UDTF与侧视图的搭配使用
案例一:
1.炸裂likes列: 注意别名不要使用关键词
2.对employee表进行炸裂:
案例二:
案例三:hive实现WordCount
一、分桶抽样
-- 创建分桶表
create table employee_id_buckets
(name string,employee_id int,work_place array<string>,gender_age struct<gender:string,age:int>,skills_score map<string,int>,depart_title map<string,array<string>>
)clustered by (employee_id) into 2 bucketsrow format delimited fields terminated by '|'collection items terminated by ','map keys terminated by ':'lines terminated by '\n';-- 设置task任务数量为2,桶的数量与tasks任务不同
set map.reduce.tasks=2;-- 开启分桶设置
set hive.enforce.bucketing=true;-- 加载数据
insert overwrite table employee_id_buckets select * from employee_id;-- 查询分桶表
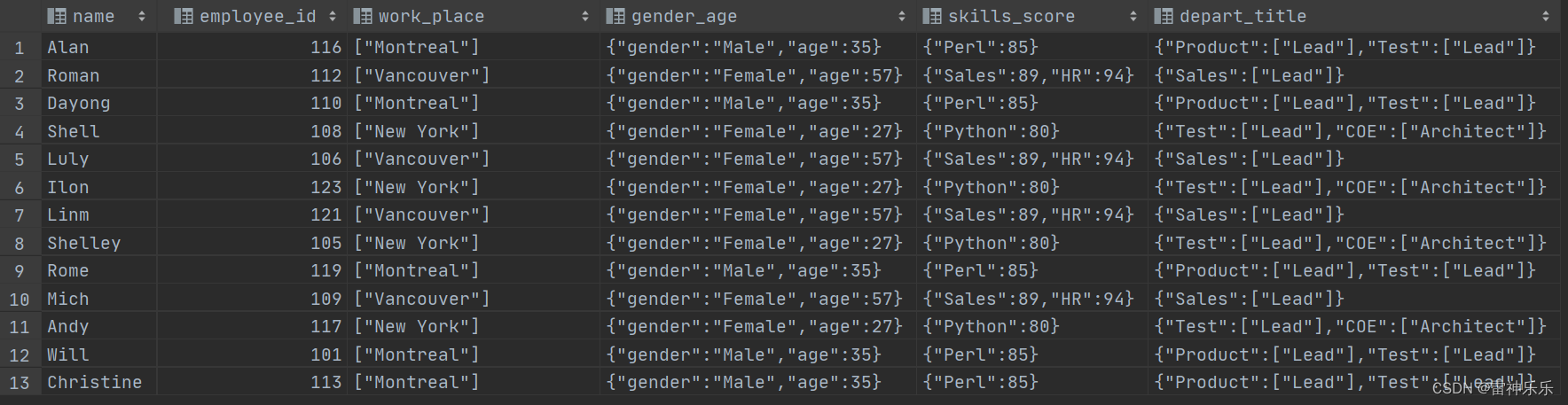
select * from employee_id_buckets;[root@lxm147 data]# vim ./employee_id.txt Michael|100|Montreal,Toronto|Male,30|DB:80|Product:Developer:Lead
Will|101|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Steven|102|New York|Female,27|Python:80|Test:Lead,COE:Architect
Lucy|103|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Mike|104|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Shelley|105|New York|Female,27|Python:80|Test:Lead,COE:Architect
Luly|106|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Lily|107|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Shell|108|New York|Female,27|Python:80|Test:Lead,COE:Architect
Mich|109|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Dayong|110|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Sara|111|New York|Female,27|Python:80|Test:Lead,COE:Architect
Roman|112|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Christine|113|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Eman|114|New York|Female,27|Python:80|Test:Lead,COE:Architect
Alex|115|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Alan|116|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Andy|117|New York|Female,27|Python:80|Test:Lead,COE:Architect
Ryan|118|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Rome|119|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Lym|120|New York|Female,27|Python:80|Test:Lead,COE:Architect
Linm|121|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Dach|122|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Ilon|123|New York|Female,27|Python:80|Test:Lead,COE:Architect
Elaine|124|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
1.抽取表中10%的数据
-- 每次提取的数据一样
select * from employee_id_buckets tablesample (10 percent) s;-- 25条数据抽取10%的数据

2.抽取表中30%的数据
select * from employee_id_buckets tablesample (30 percent); -- 25条数据抽取30%的数据
3.取第一行
select * from employee_id_buckets tablesample (1 rows);-- 取第1行
4.取第10行
select * from employee_id_buckets tablesample (10 rows) s;-- 取前10行
5.数据块抽样
select * from employee_id_buckets tablesample (bucket 1 out of 2);
建表时设置的桶的数量是2,将2个桶分成两份,2/2=1,一个桶一份,取第一个桶。
select *
from employee_id_buckets tablesample (bucket 1 out of 2 on rand());
将数据随机分到2个桶,抽取第一个桶的数据。
select * from employee_id_buckets tablesample (bucket 1 out of 4 on rand());将数据随机分到4个桶,抽取第一个桶的数据。
因此,如果一个表分成了8个桶,想要抽到第3个桶里面1/4的数据,那么of后面就是(8/(1/4))=32,bucket后面就是3(代表第几个桶)。
select * from employee_id_buckets tablesample (bucket 3 out of 32 on rand());
6.tablesample详解
抽样语句,语法:
TABLESAMPLE(BUCKET x OUT OF y)1.y必须是
table总bucket数的倍数或者因子。 hive根据y的大小,决定抽样的比例。 例如,table总共分了64份,当y=32时,抽取(64/32=)2个bucket的数据,当y=128时,抽取(64/128=)1/2个bucket的数据。2.x表示从哪个
bucket开始抽取。 例如,table总bucket数为32,tablesample(bucket 3 out of 16),表示总共抽取(32/16=)2个bucket的数据,分别为第3个bucket和第(3+16=)19个bucket的数据。
二、UDTF——表生成函数
接收一行数据,输出一行或多行数据。
1.explode()——炸裂函数
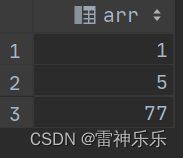
-- 对array进行炸裂
select explode(`array`(1,5,77));
-- 对map进行炸裂
select explode(`map`('name','zs','age',13)) as(key,value);

2.posexpolde()——只能对array进行炸裂
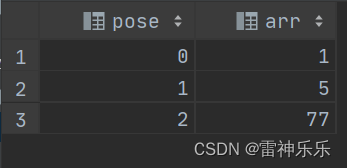
-- 炸裂时可以输出下标
select posexplode(`array`(1,5,77)) as (pose,arr);
3.inline()——炸裂结构体数组
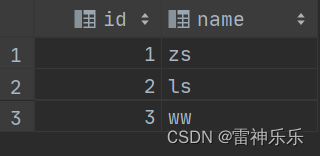
-- 对结构体数组进行炸裂
select inline(`array`(named_struct('id', 1, 'name', 'zs'),named_struct('id', 2, 'name', 'ls'),named_struct('id', 3, 'name', 'ww'))) as (id, name);
三、UDTF与侧视图的搭配使用
Lateral View通常与UDTF配合使用。Lateral View可以将UDTF应用到源表的每行数据,将每行数据转换为一行或多行,并将源表中每行的输出结果与该行连接起来,形成一个虚拟表。
语法:Lateral View写在from的表的后面,紧接着是炸裂函数,炸裂函数后面是炸裂出来的表的别名,as 后面是炸裂出来的表的字段名。

案例一:
有一个employee表:

1.炸裂likes列: 注意别名不要使用关键词
-- 炸裂likes
select id, name, ll
from student2 lateral view explode(likes) lk as ll;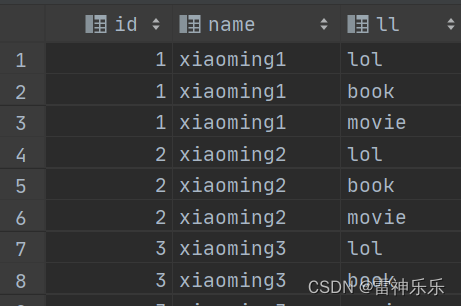
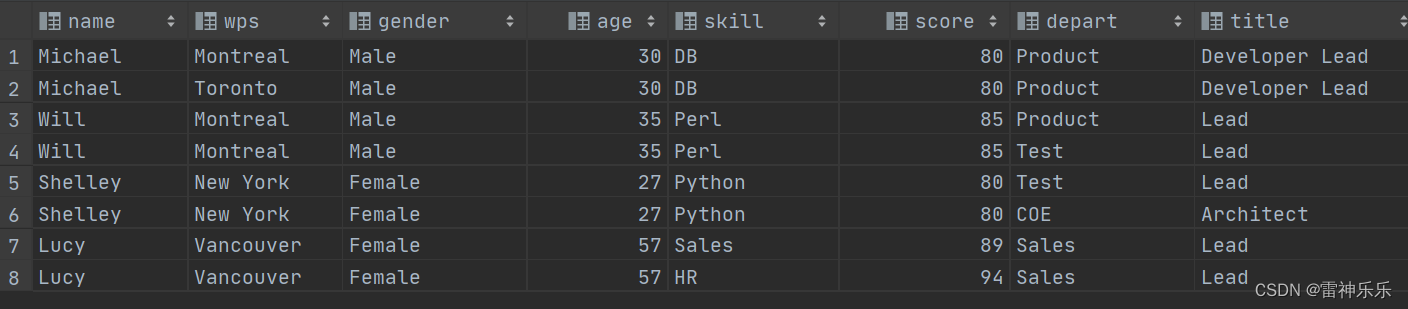
2.对employee表进行炸裂:
select name,wps,gender_age.gender,-- gender_age.gender 结构块炸裂gender_age.age,skill,score,depart,title from employeelateral view explode(workplace) place as wpslateral view explode(skills_score) skd as skill, score -- map炸成两列显示lateral view explode(depart_title) dt as depart, title;
案例二:
-- 建表
create table movie_info
(movie string, --电影名称category string --电影分类
)row format delimited fields terminated by "\t";-- 加载数据
insert overwrite table movie_info
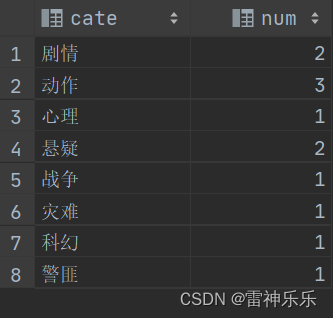
values ("《疑犯追踪》", "悬疑,动作,科幻,剧情"),("《Lie to me》", "悬疑,警匪,动作,心理,剧情"),("《战狼2》", "战争,动作,灾难");select explode(split(category, ',')) category
from movie_info;-- 第一种炸裂写法
select t.category, count(1) num
from (select explode(split(category, ',')) categoryfrom movie_info) t
group by t.category;-- 炸裂函数搭配侧视图写法
select cates,count(1) num
from (select split(category, ',') as catefrom movie_info) tlateral view explode(t.cate) tmp as cates
group by cates;
案例三:hive实现WordCount
hive实现WordCount的方法与案例二的第一种解法类似
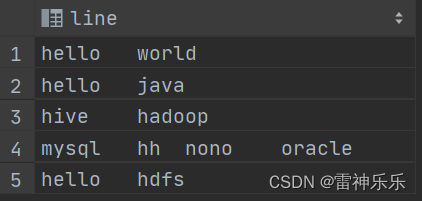
-- 新建一个表 create table if not exists words(line string );-- 加载数据 load data local inpath '/opt/atguigu/wordcount.txt' overwrite into table words;select * from words;
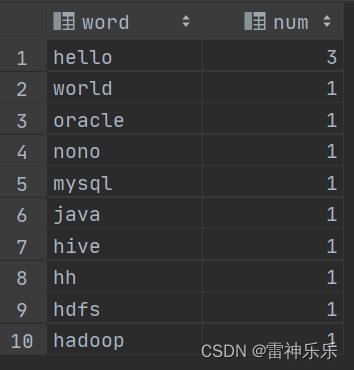
-- 先将每一行数据划分为数组 select split(line, '\t') word from words;-- 将数组拆分 select explode(split(line, '\t')) word from words;-- 拆分后就是一个表,分组计数排序 select t.word,count(1) num from (select explode(split(line, '\t')) wordfrom words) t group by t.word order by num desc;
相关文章:
Hive学习——分桶抽样、侧视图与炸裂函数搭配、hive实现WordCount
目录 一、分桶抽样 1.抽取表中10%的数据 2.抽取表中30%的数据 3.取第一行 4.取第10行 5.数据块抽样 6.tablesample详解 二、UDTF——表生成函数 1.explode()——炸裂函数 2.posexpolde()——只能对array进行炸裂 3.inline()——炸裂结构体数组 三、UDTF与侧视图的搭…...

大数据算法
1. TOP K 算法 有10个⽂件,每个⽂件1G,每个⽂件的每⼀⾏存放的都是⽤户的 query,每个⽂件的 query 都可能重复。要求你按照 query 的频度排序。 方法1: 顺序读取10个⽂件,按照 hash(query)%10 的结果将 query 写⼊到…...

非暴力沟通读书笔记
浅读《非暴力沟通》,本书对于沟通的方式总结成了一个方法论,从13个章节去概述非暴力沟通的方法和重点。其中最重要的是非暴力沟通四要素,观察、感受、需要、请求。同时在沟通中注意观察,投入爱,重视倾听的力量…...
代码随想录【Day21】| 530. 二叉搜索树的最小绝对差、501. 二叉搜索树中的众数、236. 二叉树的最近公共祖先
530. 二叉搜索树的最小绝对差 题目链接 题目描述: 给你一棵所有节点为非负值的二叉搜索树,请你计算树中任意两节点的差的绝对值的最小值。 示例: 提示:树中至少有 2 个节点。 难点: 解答错误!仅考虑了…...
注意啦,面试通过后,别忘了教师资格证认定
所有要「教师资格证认定」教程的宝子们看过来面试合格的小伙伴都可以进行认定工作 . 认定时间 查询各省份认定公告,确定认定时间范围。以下是公告汇总网址(https://www.jszg.edu.cn/portal/qualification_cert/dynamics?id21691) 认定次数 每…...
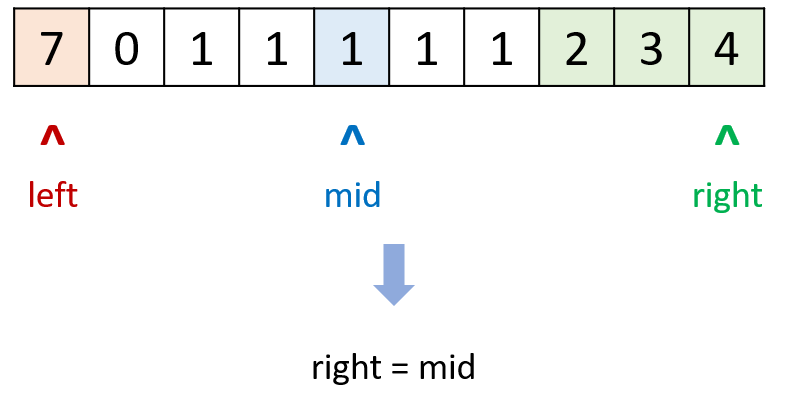
【LeetCode】No.154. 寻找旋转排序数组中的最小值 II -- Java Version
题目链接:https://leetcode.cn/problems/find-minimum-in-rotated-sorted-array-ii/ 1. 题目介绍(154. 寻找旋转排序数组中的最小值 II) 已知一个长度为 n 的数组,预先按照升序排列,经由 1 到 n 次 旋转 后࿰…...

RestTemplate远程调用
我们现在项目中使用的RPC远程调用技术是Dubbo实际上除了Dubbo技术之外,还有很多远程调用的方法它们有些调用的思想都和Dubbo完全不同Dubbo是SpringCloudAlibaba提供的功能强大的RPC框架但是Dubbo功能也有限制,如果我们想调用的方法不是我们当前项目的组件或功能,甚至想调用的方…...

registerForActivityResult使用
目录 针对 activity 结果注册回调 启动 activity 以获取其结果 在单独的类中接收 activity 结果 测试 创建自定义协定 registerForActivityResult()是startActivityForResult()的替代,简化了数据回调的写法 启动另一个 activity&#x…...

工作中,python真的有用吗?
普通上班族学Python有用吗? 那么,我也在这里提出一个问题:Python究竟适不适合办公人士来学习,以及学了之后究竟能不能给我的工作来带质一般的飞跃? 以我的亲身经历为例,我可以很负责的告诉大家,…...
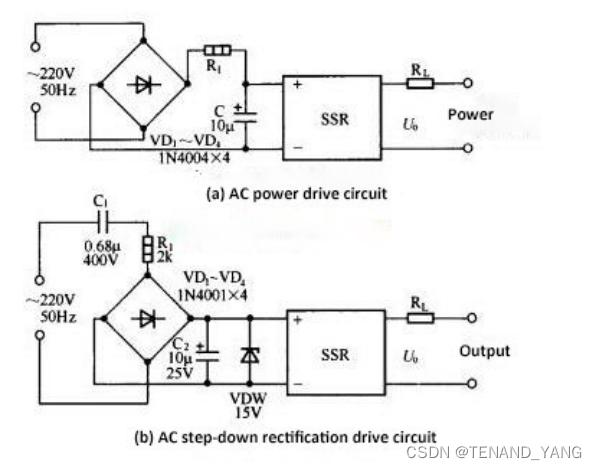
固态继电器控制电路
固态继电器控制电路 固态继电器(SSR)的种类和型号很多,因此其输入控制方法和控制电路也相应众多。固态继电器(SSR)的共同特点在于驱动电流或驱动电压小,即只需输入一个小信号即可控制SSR的开关。 如果需要…...
数仓、数据湖、湖仓一体、数据网格的探索与研究
第一代:数据仓库 定义 为解决数据库面对数据分析的不足,孕育出新一类产品数据仓库。数据仓库(Data Warehouse)是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策和信息的全局共享。 数…...

设计模式系列 - 备忘录模式
介绍&定义 备忘录模式,也叫快照(Snapshot)模式,英文翻译是 Memento Design Pattern。在 GoF 的《设计模式》一书中,备忘录模式是这么定义的: Captures and externalizes an object’s internal state…...

详细介绍React生命周期和diffing算法
事件处理 1.通过onXxx属性指定事件处理函数(注意大小写) React使用的是自定义(合成)事件, 而不是使用的原生DOM事件 —— 为了更好的兼容性;React中的事件是通过事件委托方式处理的(委托给组件最外层的元素) ——为了的高效。 2.通过event.target得到发生事件的DOM…...

面向对象的特点
1、什么是对象对象的含义是指具体的某一个事物,即在现实生活中能够看得见摸得着的事物。在面向对象程序设计中,对象所指的是计算机系统中的某一个成分。在面向对象程序设计中,对象包含两个含义,其中一个是数据,另外一个…...
智慧校园平台源码 智慧教务 智慧电子班牌系统
系统介绍 智慧校园系统是通过信息化手段,实现对校园内各类资源的有效集成 整合和优化,实现资源的有效配置和充分利用,将校务管理过程的优化协调。为校园提供数字化教学、数字化学习、数字化科研和数字化管理。 致力于为家长和教师提供一个全方位、多层…...
])
Vue篇.03-组合式API [setup()]
单文件组件(1)<script setup><script setup> 是在单文件组件 (SFC) 中使用组合式 API 的编译时语法糖。当同时使用 SFC 与组合式 API 时该语法是默认推荐启用该语法,需要在 <script> 代码块上添加 setup attribute, 里面的代码会被编译成组件 s…...
QHashIterator-官翻
QHashIterator Class template <typename Key, typename T> class QHashIterator QHashIterator 类为 QHash 和 QMultiHash 提供 Java 风格的常量迭代器。更多内容… 头文件:#include qmake:QT core 所有成员列表,包括继承的成员废弃的成员 公共成员函数…...

[qiankun]-部署后线上问题
[qiankun]-部署后线上问题微服务加载问题-现象1现象描述问题分析解决方案微服务加载问题-现象2现象描述问题分析微服务加载问题-现象3现象描述分析解决方案属于项目打包后,部署到服务器上,所遇到的部分问题 微服务加载问题-现象1 现象描述 项目部署实…...

位图数组 布隆过滤器
文章目录位图数组获取索引获取索引状态设置索引状态布隆过滤器特点大致原理位图数组 一个int类型的整数用4字节,也就是32个bit位来表示,将整数类型的数组转换成位图数组,那么存储长度将变为原来的32倍 arr[0] 表示0-31 arr[1] 表示32-63 //...获取索引…...
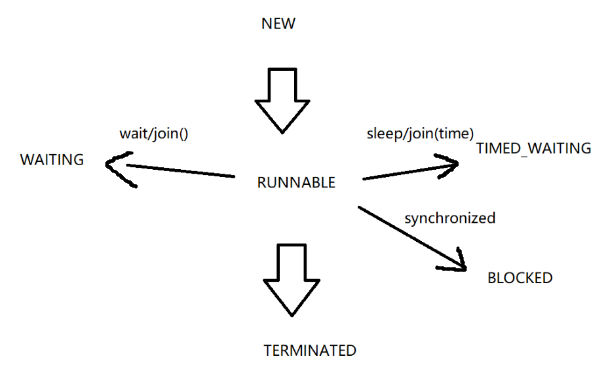
多线程Thread常用方法和状态
Thread类 及常见方法 1、常见构造方法 方法说明Thread()创建线程对象Thread(Runnable target)使用 Runnable 对象创建线程对象Thread(String name)创建线程对象,并命名Thread(Runnable target, String name)使用 Runnable 对象创建线程对象,并命名Thre…...

Unity-MCP协议:可嵌入、可协商的AI上下文通信标准
1. 这不是又一个“AI插件”,而是Unity开发工作流的底层重定义你有没有过这样的时刻:在Unity里反复调整Animator Controller的过渡条件,只为让角色转身动画不穿模;写完一段NavMesh寻路逻辑,却要花两小时调试Agent卡在斜…...

告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略
告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略当开发者尝试在UniApp中实现沉浸式设计时,往往会遇到一个令人头疼的问题——默认的白色安全区和状态栏导致界面元素(如电池图标、信号强度)几乎不可见。…...

Java数组工具类实战:设计不可实例化的静态工具类
实现一个工具类 MathUtils,满足以下要求: 1. 所有方法均为静态,且该类不能从外部实例化(提示:使用私有构造器)。 2. 提供三个静态方法:- maxArray(int[] arr):返回较大值;…...

第3篇:系统透视——信息部门如何构建“税务友好型”IT架构
本篇导读:如果你是信息总监或IT负责人,请通读全文,尤其是“系统合规设计的三必须”和“现场检查SOP”;如果你是财税人员,请重点阅读“研产供销全链条的系统对接要求”和“与IT部门的协作要点”;如果你是老板…...

【与我学 ClaudeCode】协作篇 之 Worktree + Task Isolation :目录隔离的并行执行通道
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】协作篇 之 Worktree Task Isolation :目录隔离的并行执行通道》. Le…...

OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案
OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否拥有一台性能尚可但已被…...

yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案
yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上体验任天堂Switch游戏的魅力吗?yuzu模拟器正是你寻找的完美答案。作为…...

基于Meshtastic构建LoRa Mesh网络:从硬件自制到传感器集成实战
1. 项目概述:构建一个灵活且易用的LoRa Mesh网络 如果你对物联网、远程传感或者去中心化通信网络感兴趣,那么LoRa技术一定不会陌生。它以其超低功耗、超远距离和强大的抗干扰能力,成为了构建广域传感网络的理想选择。然而,传统的…...

观察不同模型在统一 API 下的响应速度与输出风格差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察不同模型在统一 API 下的响应速度与输出风格差异 在为大语言模型应用选择模型时,开发者通常会关注两个核心维度&am…...

Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验
Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为在Windows电脑上无法直接安装安卓应用而烦…...