再想一想GPT
一 前言
花了大概两天时间看完《这就是ChatGPT》,触动还是挺大的,让我静下来,认真地想一想,是否真正理解了ChatGPT,又能给我们以什么样的启发。
二 思考
在工作和生活中,使用ChatGPT或文心一言,逐渐形成了习惯,总想听听它们的意见。无论是小学作文还是小的编程测试例子,大部分情况下还是能够给我一个比较靠谱的意见,而且是个“知错就改”的AI,对于它的回答不满意,多换几个提示词总能给我想要的效果,这确实是令人吃惊和感到不可思议的,特别是在对有错别字的提问,上下文关联提问,能给出让人看得懂的回答,仿佛它存储了无穷多的知识。
2.1 高纬度是一种有效的压缩方法
首先我想到的这个模型在磁盘上存储大概有多大,问了下ChatGPT,3.5版本模型大概1.2TB的,包括权重文件必要文件等;
GPT-3.5 模型是一个非常大的模型,具体占用的磁盘空间会因为存储格式和配置参数的不同而有所变化。然而,根据 OpenAI 的官方文档,GPT-3.5 模型的大小大约为 1.2TB。这个大小包括了模型的权重参数、配置文件以及其他必要的文件。请注意,这个数字是基于 GPT-3.5 模型的官方发布,可能会因为后续的模型更新和改进而有所变化。如果你需要具体的数字,建议参考 OpenAI 官方文档或联系 OpenAI 获取最新的信息真是难以置信,在1.2TB的存储上,竟然可以满足各行各业人的提问,而且效果都还不错。
这里面存储的不光是知识,还有逻辑,最神奇的是语言习惯的逻辑,以前开发个类人的对话机器人是非常难的,别说人类语言,光编程语言编译都要进过词法分析、语法分析等复杂过程才能理解它要做什么,而GPT不用理解它们,就经过训练好,奇妙给出了符合语法和语义的答案。
所以,我认为GPT是一种高纬度的压缩,是对各类知识的内容的高纬度的提出抽象、是对语言高维度的抽象,虽然我们还不能完全理解这种逻辑。举个简单的例子有一张很大的纸,如果平铺开来可能有足球场那么大,但是如果折叠下,通过多次折叠后,这张纸,可能会变成拳头大小的模型。为什么它会变小了,因为它的维度变化了,它的被压缩了。 GPT -3 的参数有1750亿个,每个参数看做一个维度的话,表示的维度空间是很高的,所以它能压缩信息。
同样可以根据这样的启发,如果高维度的数据想要简化,需要降低维度,降低维度其实是减少信息的密度,如果高维度的信息,展开在低纬度是很庞大的。 这有点像一个立方体,如果展开平铺下来是有六个面的。
2.2 信息的无序是因为维度不够高
除了GPT能够回答各行各业的知识外,还有个神奇之处,它能给出网络上没有出现问题的答案,而且是合理的答案,而且是符合人类语言习惯的答案。
所以引申出了一个问题,GPT是否真的理解了我们的问题,如果理解了,为什么有的简单的数学计算会计算错误,如果没理解,它又如何给出了网上没有问题的合理答案那?
书中给出GPT本质在做续写,我们给出问题或提示词后,GPT根据我们给出的问题或词语给出最合理的续写,它觉得下个出现的词语靠的概率,即哪个词最该出现,就给出哪个词语,在使用过程中常常看到单词是一个个蹦出来的,那是从众多单词中,选择最合理的单词输出出来,这个类似于N-Gram,即每个单词出现不是孤立的,和它前面的N个词语相关,这就可以找到序列的秩序关系,同样的原理,对我们的语言也是一样,如果N足够长,那生成的句子,读起来就是合理的了,更奇妙的是这种合理不光是语言通顺与否的合理,而且是逻辑的合理,没有使用任何推理,仅仅使用神经网络训练出来的模型,就可以达到这种令人惊叹的效果。
这让我想到的那句话,一切答案都在问题之中,有了GPT,我们有了问题也就有了答案,嗨你看提问比答案更重要了,也可以说我们能理解的答案,其实蕴藏在以前的文本之中,只是GPT帮我们拼凑出来,展现给我们。
从某种意义来说,知识本质就是一种词语的关系,词序的排列,不光包括科学知识,还包括语言习惯、语义语法知识,只要维度够高,任何知识都可以通过单词来组合得到,这种组合的逻辑关系和内在联系可以将知识或信息进行高度的压缩。
看极客时间 《AI大数据模型之美》的一个对评分进行情感分析的例子,通过简单的调用GPT的API,计算评论内容和"好评"、"差评" 这两个词语的向量相似性,轻易地区分出了好评的评论和差评的评论:
import openai
import os
from openai.embeddings_utils import cosine_similarity, get_embedding# 获取访问open ai的密钥
openai.api_key = os.getenv("OPENAI_API_KEY")
# 选择使用最小的ada模型
EMBEDDING_MODEL = "text-embedding-ada-002"# 获取"好评"和"差评"的
positive_review = get_embedding("好评")
negative_review = get_embedding("差评")positive_example = get_embedding("买的银色版真的很好看,一天就到了,晚上就开始拿起来完系统很丝滑流畅,做工扎实,手感细腻,很精致哦苹果一如既往的好品质")
negative_example = get_embedding("降价厉害,保价不合理,不推荐")def get_score(sample_embedding):return cosine_similarity(sample_embedding, positive_review) - cosine_similarity(sample_embedding, negative_review)positive_score = get_score(positive_example)
negative_score = get_score(negative_example)print("好评例子的评分 : %f" % (positive_score))
print("差评例子的评分 : %f" % (negative_score))得分结果:
好评例子的评分 : 0.070963
差评例子的评分 : -0.081472好评的评论和"好评"这个词语的相似性,比和"差评" 这个词语的相似性要大,相反也一样成立,简单来说在高维度上,好评的评论和"好评" 靠的更近,和"差评"离的更远,简单又神奇,就算把例子复杂化一点,用否定的否定来构建句子,仍然可以得到一样的效果:
good_restraurant = get_embedding("这家餐馆太好吃了,一点都不糟糕")
bad_restraurant = get_embedding("这家餐馆太糟糕了,一点都不好吃")good_score = get_score(good_restraurant)
bad_score = get_score(bad_restraurant)
print("好评餐馆的评分 : %f" % (good_score))
print("差评餐馆的评分 : %f" % (bad_score))得分结果:
好评餐馆的评分 : 0.062719
差评餐馆的评分 : -0.074591这说明,这些单词或句子,在一个高维度的空间上,是存在一定的关系的,这个关系就是我们平时所说的所谓的知识。
以前我们都是通过学习文章,通过整体去理解文章,先通过语言的逻辑理解文章的含义,再通过逻辑抽象理解文章表达的内容。而GPT,是从单词的关系去理解,只要战的维度高,就能学到其中的逻辑其中我们低维度视角无法看到的内容。
三 未来
3.1 GPT的智能
据说GPT新版本已经通过了图灵测试,从一定程度上来说,它具备了人类所说的智慧,文字一直认为是人类才会的高级玩意,通过它我们交流了思想、传递了知识、交换了信息,现在GPT一个模型,只有1750亿参数的模型,通过学习网络上的文本资料,竟然构建了这样的知识库,不存储知识,却能根据知识回答问题,不存语法规则,却回答的合情合理,这种神奇的涌现效果,让人感觉神奇的同时,思考起来又不寒而栗。
随着它学习的越来越多内容,不光有问题,据说还有视频、录音、图片等,它会越来越像个各方面都在行的专家,可以在我们冥思苦想没有灵感的时候,给我们以启示,这些知识都是存在的,而我们却不知道竟然可以如此组合,它不能从无到有创建出一个独立的分支,却可以通过各种组合将现有的知识利用达到极致,这种组合何尝不是一种创新,利用它的能力,未来人类在交叉学科上,在知识本质的理解上,语言规律的摸索上,给人们更多的启迪。
这让我想起了GPT的API中的温度参数,这个参数在0-2之间变化,温度为0,输出的回答变化越小,温度为2,输出的变化最大,而且每个输出在语法和语义上都是合理的,答案的多样性,也许是人们创新的一个源泉了。
所以GPT的智能会越来越高、越来越像个各方面的专家,能给使用者带来不可思议组合式的创新。
3.2 AI最终会统治地球嘛
现在的GPT,对发明者来说,他们开始可能也不知道会有如此神奇的效果,通过多层神经网络的组合,通过大类的样本的续写训练,竟然涌现出来了类人的智能。
为什么2千亿左右的参数或神经网络的连接就可以模拟人类的知识和语言习惯,除N-Gram外,是否蕴含其他逻辑,其原理到底是什么,如果参数增加到万亿,训练出来的又是一个什么样的怪物,它是否拥有着自主意识,这个自主意识和人类的又肯定不同,它可能不是人们想的那样,有什么邪恶的想法,想要逃出来,统治人类啥的。它可能只是按照自己的规律走,只是从人类角度来看它可能有了自己的思考和逻辑,它不知道,可能只是沿着最优解去做,统治不统治人类可能只是个副产物。
我不知道,AI最终是否会统治地球,只是知道,如果统治了地球,那一定是以一个我们难以想象或理解的方式。
相关文章:

再想一想GPT
一 前言 花了大概两天时间看完《这就是ChatGPT》,触动还是挺大的,让我静下来,认真地想一想,是否真正理解了ChatGPT,又能给我们以什么样的启发。 二 思考 在工作和生活中,使用ChatGPT或文心一言,…...
Blazor前后端框架Known-V1.2.15
V1.2.15 Known是基于C#和Blazor开发的前后端分离快速开发框架,开箱即用,跨平台,一处代码,多处运行。 Gitee: https://gitee.com/known/KnownGithub:https://github.com/known/Known 概述 基于C#和Blazo…...
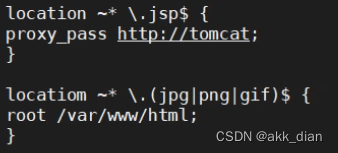
Tomcat 的部署和优化
目录 1、什么是Tomcat 1.1、静态页面的选择 2、Tomcat是怎么运行的 3、安装jdk & 部署jdk环境 & Tomcat 安装 1、安装jdk 2、配置jdk环境变量 3、tomcat安装 4、Tomcat启动 5.优化tomcat启动速度 6.Tomcat的主要命令 7.Tomcat 配置虚拟主机 8.Tomca…...
后端中间件安装与启动(Redis、Nginx、Nacos、Kafka)
后端中间件安装与启动 RedisNginxNacosKafka Redis 1.打开cmd终端,进入redis文件目录 2.输入redis-server.exe redis.windows.conf即可启动,不能关闭cmd窗口 (端口配置方式:redis目录下的redis.windows.conf配置文件,…...

【电子元件】常用电子元器件的识别之电阻器
目录 前言1. 电阻器的识别1.1 普通电阻器的识别1. 普通电阻器的识别色环电阻器绕线电阻器水泥电阻器贴片电阻器网络电阻器(排阻)保险电阻器精密电阻器2. 电阻器的符号3. 普通电阻器的主要参数标称阻值和允许误差额定功率最高工作电压温度系数1.2 电位器的识别1. 电位器的识别…...

指针和数组笔试题讲解(2)
🐵本篇文章将会对上篇一维数组笔试题的剩余部分和二维数组的笔试题进行讲解 一、一维数组 1>试题部分(一)✏️ char* p "abcdef";printf("%zd\n", sizeof(p)); printf("%zd\n", sizeof(p 1)); printf("%zd\n", sizeo…...

MapReduce YARN 的部署
1、部署说明 Hadoop HDFS分布式文件系统,我们会启动: NameNode进程作为管理节点DataNode进程作为工作节点SecondaryNamenode作为辅助 同理,Hadoop YARN分布式资源调度,会启动:ResourceManager进程作为管理节点NodeM…...

vue 引入zTree
下载js包解压后找个地方放文件夹内 引入 import "/common/zTree/js/jquery-1.4.4.min" import "/common/zTree/js/jquery.ztree.core.min.js" import "/common/zTree/js/jquery.ztree.excheck.min.js" import "/common/zTree/css/metroSt…...

链队列的基本操作(带头结点,不带头结点)
结构体 typedef struct linknode{int data;struct linknode* next;后继指针 }linknode; typedef struct {linknode* front, * rear;//队头队尾指针 }linkquene; 初始化队列(带头结点) int initquene(linkquene* q)//初始化队列 {q->front q->r…...

深入学习 Redis Cluster - 基于 Docker、DockerCompose 搭建 Redis 集群,处理故障、扩容方案
目录 一、基于 Docker、DockerCompose 搭建 Redis 集群 1.1、前言 1.2、编写 shell 脚本 1.3、执行 shell 脚本,创建集群配置文件 1.4、编写 docker-compose.yml 文件 1.5、启动容器 1.6、构建集群 1.7、使用集群 1.8、如果集群中,有节点挂了&am…...
笔记)
C现代方法(第3、4章)笔记
文章目录 C现代方法笔记(chapter3&4)第3章 格式化输入/输出3.1 printf函数3.1.1 转换说明3.1.2 转义序列 3.2 scanf函数3.2.1 scanf函数的工作方法3.2.2 格式串中的普通字符3.2.3 易混淆的printf函数和scanf函数 问与答编程题 第4章 表达式4.1 算术运…...
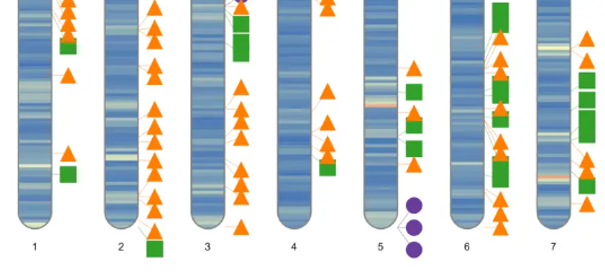
R语言绘制染色体变异位置分布图,RIdeogram包
变异位点染色体分布图 今天分享的内容是通过RIdeogram包绘制染色体位点分布图,并介绍一种展示差异位点的方法。 在遗传学研究中,通过测序等方式获得了基因组上某些位置的基因型信息。 如下表,第一列是变异位点的ID,第二列是染色体…...
每天10个小知识点)
Vue知识系列(7)每天10个小知识点
目录 系列文章目录Vue知识系列(1)每天10个小知识点Vue知识系列(2)每天10个小知识点Vue知识系列(3)每天10个小知识点Vue知识系列(4)每天10个小知识点Vue知识系列(5&#x…...
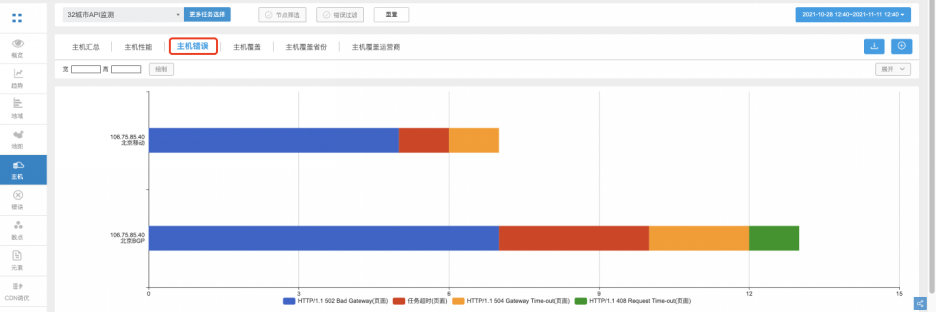
5分钟就能实现的API监控,有什么理由不做呢?
API深度影响着你的应用 今天的数字应用世界其实是一个以API为中心的世界,我们只是没有意识到这些API的重要性。比如在电子商务交易、社交媒体等对交互高度依赖的领域,可以说API决定了应用的质量一点也不为过。 以京东为例,用户的每一次操作背…...
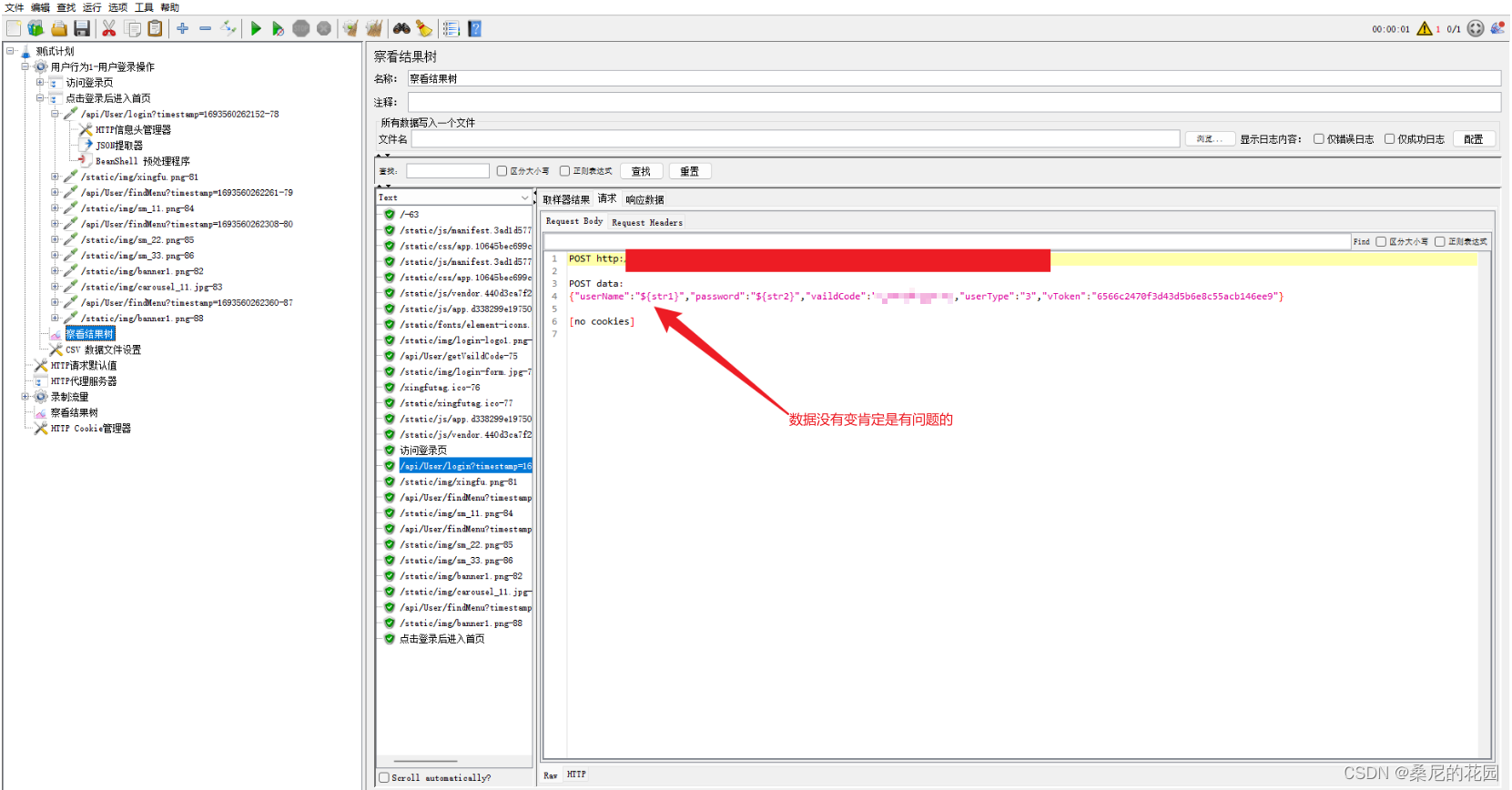
Jmeter引入外部jar包以满足加密数据的Post请求
目录 一、把项目打成jar包 1、创建一个Maven项目,并保证可以正常运行。 2、把工具类放置项目中,确保无报错且能够正常使用。 3、打包 4、验证 jar包是否有效 5、你想打多个工具类的包 二、在jmeter中使用 1、把jar包放到jmeter仓库下,…...

了解冒泡排序
package com.mypackage.array;import java.util.Arrays;public class Demo07 {public static void main(String[] args) {int[] a {3,2,6,7,4,5,6,34,56,7};int[] sort1 sort1(a); //调用我们自己写的排序方法后,返回一个排序后的数组System.out.println(Array…...
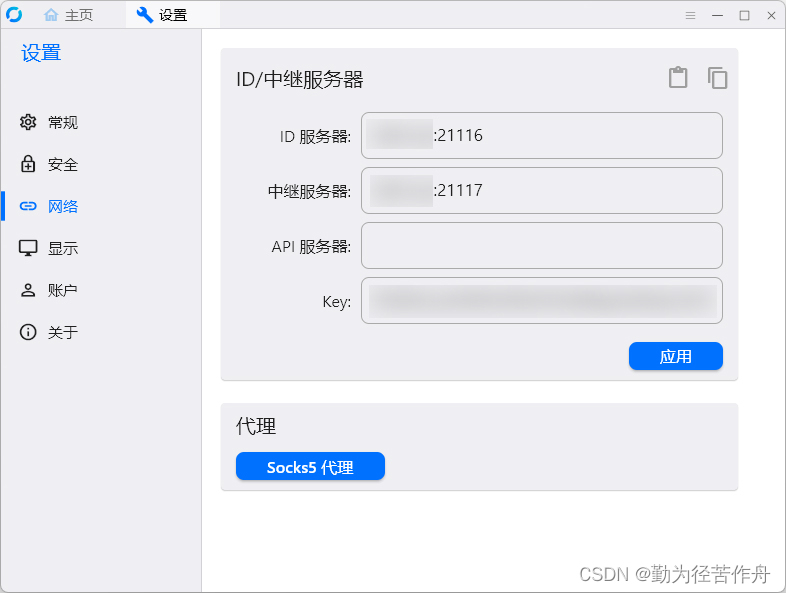
群辉 Synology NAS Docker 安装 RustDesk-server 自建服务器只要一个容器
from https://blog.zhjh.top/archives/M8nBI5tjcxQe31DhiXqxy 简介 之前按照网上的教程,rustdesk-server 需要安装两个容器,最近想升级下版本,发现有一个新镜像 rustdesk-server-s6 可以只安装一个容器。 The S6-overlay acts as a supervi…...
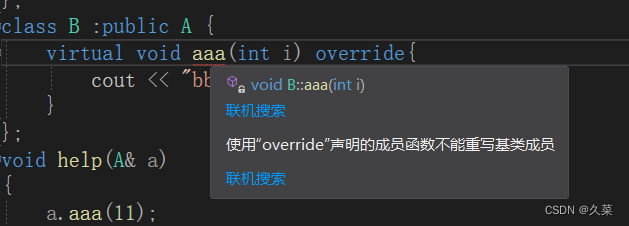
为什么要有override
多态一定会成功吗 因为逻辑是用户编写的,那么肯定会有遗漏的地方,那就要规则来限制。就比如多态,都知道条件之一是子类重写了父类的虚函数,但是如果子类没有严格遵守这个规则,就无法达到目的。就比如这个代码…...

Linux界的老古董
Slackware 是由 Patrick Volkerding 制作的 Linux 发行版,从 1993 年发布至今也一直在 Patrick 带领下进行维护。7 月 17 日,Slackware 才刚刚过完它 24 岁的生日,看似年纪轻轻的它,已然是 Linux 最古老的发行版。 Slackware 的发…...

安卓逆向 - Xposed入门教程
一、引言 Xposed框架,是Android中Hook技术的一个著名的框架,拥有非常丰富的模块,给我们分析app提供了极大的便利,Xposed框架是开源的。最高支持到Android 8(重要) github地址:GitHub - rovo89…...

IoT产品创新方法论:构建“场景 × 技术 × 数据 × 商业”的系统创新能力
目录 一、 问题与背景 二、 本文将系统讲解 三、 什么是IoT产品创新 3.1 核心定义 3.2 IoT创新的核心变化 3.3 创新的三种层级(阶梯论) 四、 IoT产品创新结构模型(核心框架) 4.1 四维创新模型(核心体系) 4.2 创新演进路径 五、 五大IoT创新方法论(核心武器库)…...

对比按需计费与TokenPlan在长期项目中的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按需计费与TokenPlan在长期项目中的成本体感差异 在长期运行的AI项目中,成本控制是一个持续优化的过程。不同的计费…...
分享2026最新版)
艾尔登法环风灵月影修改器下载(已汉化)分享2026最新版
《艾尔登法环》以交界地为舞台,打造了一款兼具开放世界探索与高难度挑战的角色扮演游戏。玩家将扮演褪色者,在破碎的土地上冒险,挑战强大敌人、收集装备、提升能力,最终成为艾尔登之王。游戏以硬核战斗与开放探索为核心࿰…...

告别Let‘s Encrypt:用开源XCA构建私有CA,签发全站浏览器信任的SSL证书
1. 为什么你需要私有CA? 每次看到浏览器里那个"不安全"的红色警告,我就浑身难受。以前我也和大家一样用Lets Encrypt,直到有次紧急发布时遇到证书续期失败,整个团队熬夜排查到凌晨三点。从那天起,我就开始研…...

Flutter + 开源鸿蒙跨端实战|基于空间地理信息的**城市全域智慧泊车调度与多维运维管理平台** Day1 项目架构基座与工程化环境搭建
Flutter 开源鸿蒙跨端实战|基于空间地理信息的城市全域智慧泊车调度与多维运维管理平台 Day1 项目架构基座与工程化环境搭建 欢迎入驻开源鸿蒙全栈技术实战社区:https://openharmonycrossplatform.csdn.net <!-- Schema.org 结构化数据 --> <…...

苹果为何拒绝TD-SCDMA特供版iPhone?复盘技术标准与市场时机的战略博弈
1. 项目概述:一场关于苹果与中国移动的世纪猜想2012年的科技圈,空气中弥漫着一股躁动与期待。几乎所有的行业分析师和手机发烧友都在讨论同一个话题:苹果公司是否会为了全球最大的移动运营商——中国移动,专门推出一款支持TD-SCDM…...

3步构建个人知识库:微信读书笔记智能同步终极方案
3步构建个人知识库:微信读书笔记智能同步终极方案 【免费下载链接】obsidian-weread-plugin Obsidian Weread Plugin is a plugin to sync Weread(微信读书) hightlights and annotations into your Obsidian Vault. 项目地址: https://gitcode.com/gh_mirrors/ob…...

从虚拟到物理:电子系统原型设计的工程化策略与实战解析
1. 原型设计全景:从概念到实物的工程化思维 在电子系统设计领域,尤其是面对航空航天、汽车电子、通信设备这类高复杂、高可靠性要求的项目时,“原型”这个词的分量远超一个简单的模型。它不是一个可有可无的步骤,而是连接创意与产…...

数学全景地图6---数学的内容、方法和意义,50年代苏联的数学全景大书Big Picture。
0、数学--它的内容、方法和意义。Mathematics--Its Content, Methods, and Meaning.----俄文原版于1956年。英文翻译版于1963年。中文翻译版于1950年代。----在国内的《数学大辞典》中,特别指出这本书《数学-它的内容方法和意义》,是当时的数学辞书之一。…...

基于STC89C51单片机的多波形信号发生器设计与Proteus仿真
基于STC89C51单片机的多波形信号发生器设计与Proteus仿真 摘 要 随着电子技术和集成电路的飞速发展,信号发生器作为电子测量领域的基础设备,其性能和智能化水平不断提升。本设计以STC89C51单片机为控制核心,设计了一款多波形信号发生器。系统…...