Python爬虫之Scrapy框架系列(13)——实战ZH小说爬取数据入MySql数据库
目录:
- 1 数据持久化存储,写入Mysql数据库
- ①定义结构化字段:
- ②重新编写爬虫文件:
- ③编写管道文件:
- ④辅助配置(修改settings.py文件):
- ⑤navicat创库建表:
- ⑥ 效果如下:
1 数据持久化存储,写入Mysql数据库
①定义结构化字段:
- (items.py文件的编写):
# -*- coding: utf-8 -*-# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass NovelItem(scrapy.Item):'''匹配每个书籍URL并解析获取一些信息创建的字段'''# define the fields for your item here like:# name = scrapy.Field()category = scrapy.Field()book_name = scrapy.Field()author = scrapy.Field()status = scrapy.Field()book_nums = scrapy.Field()description = scrapy.Field()c_time = scrapy.Field()book_url = scrapy.Field()catalog_url = scrapy.Field()class ChapterItem(scrapy.Item):'''从每个小说章节列表页解析当前小说章节列表一些信息所创建的字段'''# define the fields for your item here like:# name = scrapy.Field()chapter_list = scrapy.Field()class ContentItem(scrapy.Item):'''从小说具体章节里解析当前小说的当前章节的具体内容所创建的字段'''# define the fields for your item here like:# name = scrapy.Field()content = scrapy.Field()chapter_url = scrapy.Field()
②重新编写爬虫文件:
- (将解析的数据对应到字段里,并将其yield返回给管道文件pipelines.py)
# -*- coding: utf-8 -*-
import datetimeimport scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rulefrom ..items import NovelItem,ChapterItem,ContentItemclass Bh3Spider(CrawlSpider):name = 'zh'allowed_domains = ['book.zongheng.com']start_urls = ['https://book.zongheng.com/store/c0/c0/b0/u1/p1/v0/s1/t0/u0/i1/ALL.html']rules = (# Rule定义爬取规则: 1.提取url(LinkExtractor对象) 2.形成请求 3.响应的处理规则# 源码:Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True)# 1.LinkExractor是scrapy框架定义的一个类,它定义如何从每个已爬网页面中提取url链接,并将这些url作为新的请求发送给引擎# 引擎经过一系列操作后将response给到callback所指的回调函数。# allow=r'Items/'的意思是提取链接的正则表达式 【相当于findall(r'Items/',response.text)】# 2.callback='parse_item'是指定回调函数。# 3.follow=True的作用:LinkExtractor提取到的url所生成的response在给callback的同时,还要交给rules匹配所有的Rule规则(有几条遵循几条)# 拿到了书籍的url 回调函数 process_links用于处理LinkExtractor匹配到的链接的回调函数# 匹配每个书籍的urlRule(LinkExtractor(allow=r'https://book.zongheng.com/book/\d+.html',restrict_xpaths=("//div[@class='bookname']")), callback='parse_book', follow=True,process_links="process_booklink"),# 匹配章节目录的urlRule(LinkExtractor(allow=r'https://book.zongheng.com/showchapter/\d+.html',restrict_xpaths=('//div[@class="fr link-group"]')), callback='parse_catalog', follow=True),# 章节目录的url生成的response,再来进行具体章节内容的url的匹配 之后此url会形成response,交给callback函数Rule(LinkExtractor(allow=r'https://book.zongheng.com/chapter/\d+/\d+.html',restrict_xpaths=('//ul[@class="chapter-list clearfix"]')), callback='get_content',follow=False, process_links="process_chapterlink"),# restrict_xpaths是LinkExtractor里的一个参数。作用:过滤(对前面allow匹配到的url进行区域限制),只允许此参数匹配的allow允许的url通过此规则!!!)def process_booklink(self, links):for index, link in enumerate(links):# 限制一本书if index == 0:print("限制一本书:", link.url)yield linkelse:returndef process_chapterlink(self, links):for index,link in enumerate(links):#限制21章内容if index<=20:print("限制20章内容:",link.url)yield linkelse:returndef parse_book(self, response):print("解析book_url")# 字数:book_nums = response.xpath('//div[@class="nums"]/span/i/text()').extract()[0]# 书名:book_name = response.xpath('//div[@class="book-name"]/text()').extract()[0].strip()category = response.xpath('//div[@class="book-label"]/a/text()').extract()[1]author = response.xpath('//div[@class="au-name"]/a/text()').extract()[0]status = response.xpath('//div[@class="book-label"]/a/text()').extract()[0]description = "".join(response.xpath('//div[@class="book-dec Jbook-dec hide"]/p/text()').extract())c_time = datetime.datetime.now()book_url = response.urlcatalog_url = response.css("a").re("https://book.zongheng.com/showchapter/\d+.html")[0]item=NovelItem()item["category"]=categoryitem["book_name"]=book_nameitem["author"]=authoritem["status"]=statusitem["book_nums"]=book_numsitem["description"]=descriptionitem["c_time"]=c_timeitem["book_url"]=book_urlitem["catalog_url"]=catalog_urlyield itemdef parse_catalog(self, response):print("解析章节目录", response.url) # response.url就是数据的来源的url# 注意:章节和章节的url要一一对应a_tags = response.xpath('//ul[@class="chapter-list clearfix"]/li/a')chapter_list = []for index, a in enumerate(a_tags):title = a.xpath("./text()").extract()[0]chapter_url = a.xpath("./@href").extract()[0]ordernum = index + 1c_time = datetime.datetime.now()catalog_url = response.urlchapter_list.append([title, ordernum, c_time, chapter_url, catalog_url])item=ChapterItem()item["chapter_list"]=chapter_listyield itemdef get_content(self, response):content = "".join(response.xpath('//div[@class="content"]/p/text()').extract())chapter_url = response.urlitem=ContentItem()item["content"]=contentitem["chapter_url"]=chapter_urlyield item
③编写管道文件:
- (pipelines.py文件)
- 数据存储到MySql数据库分三步走:
①存储小说信息;
②存储除了章节具体内容以外的章节信息(因为:首先章节信息是有序的;其次章节具体内容是在一个新的页面里,需要发起一次新的请求);
③更新章节具体内容信息到第二步的表中。
# -*- coding: utf-8 -*-# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.htmlimport pymysql
import logging
from .items import NovelItem,ChapterItem,ContentItem
logger=logging.getLogger(__name__) #生成以当前文件名命名的logger对象。 用日志记录报错。class ZonghengPipeline(object):def open_spider(self,spider):# 连接数据库data_config = spider.settings["DATABASE_CONFIG"]if data_config["type"] == "mysql":self.conn = pymysql.connect(**data_config["config"])self.cursor = self.conn.cursor()def process_item(self, item, spider):# 写入数据库if isinstance(item,NovelItem):#写入书籍信息sql="select id from novel where book_name=%s and author=%s"self.cursor.execute(sql,(item["book_name"],item["author"]))if not self.cursor.fetchone(): #.fetchone()获取上一个查询结果集。在python中如果没有则为Nonetry:#如果没有获得一个id,小说不存在才进行写入操作sql="insert into novel(category,book_name,author,status,book_nums,description,c_time,book_url,catalog_url)"\"values(%s,%s,%s,%s,%s,%s,%s,%s,%s)"self.cursor.execute(sql,(item["category"],item["book_name"],item["author"],item["status"],item["book_nums"],item["description"],item["c_time"],item["book_url"],item["catalog_url"],))self.conn.commit()except Exception as e: #捕获异常并日志显示self.conn.rollback()logger.warning("小说信息错误!url=%s %s")%(item["book_url"],e)return itemelif isinstance(item,ChapterItem):#写入章节信息try:sql="insert into chapter (title,ordernum,c_time,chapter_url,catalog_url)"\"values(%s,%s,%s,%s,%s)"#注意:此处item的形式是! item["chapter_list"]====[(title,ordernum,c_time,chapter_url,catalog_url)]chapter_list=item["chapter_list"]self.cursor.executemany(sql,chapter_list) #.executemany()的作用:一次操作,写入多个元组的数据。形如:.executemany(sql,[(),()])self.conn.commit()except Exception as e:self.conn.rollback()logger.warning("章节信息错误!%s"%e)return itemelif isinstance(item,ContentItem):try:sql="update chapter set content=%s where chapter_url=%s"content=item["content"]chapter_url=item["chapter_url"]self.cursor.execute(sql,(content,chapter_url))self.conn.commit()except Exception as e:self.conn.rollback()logger.warning("章节内容错误!url=%s %s") % (item["chapter_url"], e)return itemdef close_spider(self,spider):# 关闭数据库self.cursor.close()self.conn.close()
④辅助配置(修改settings.py文件):
第一个:关闭robots协议;
第二个:开启延迟;
第三个:加入头文件;
第四个:开启管道:
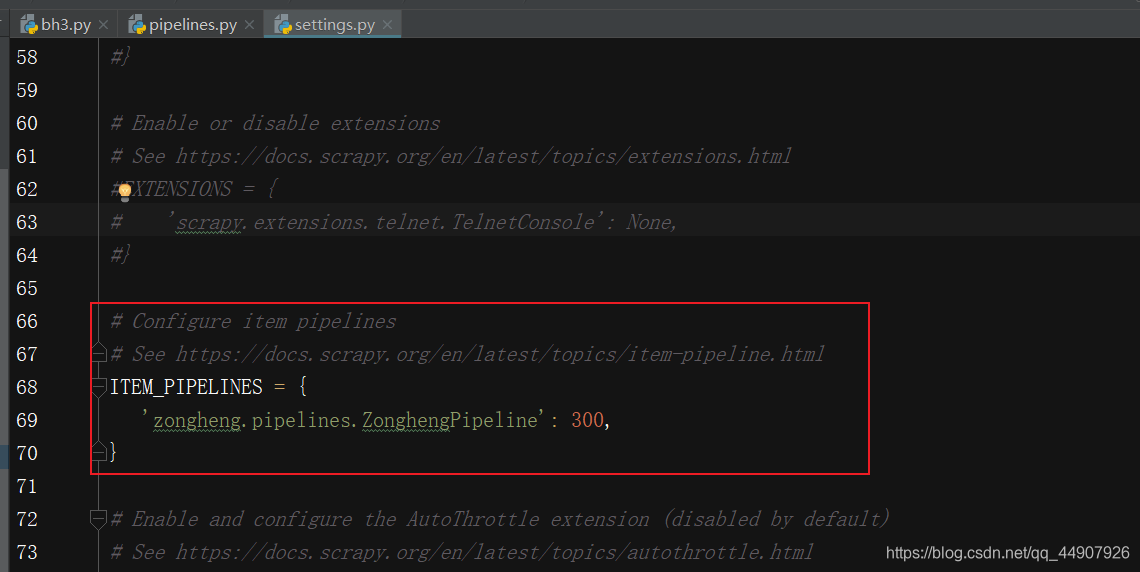
第五个:配置连接Mysql数据库的参数:
DATABASE_CONFIG={"type":"mysql","config":{"host":"localhost","port":3306,"user":"root","password":"123456","db":"zongheng","charset":"utf8"}
}
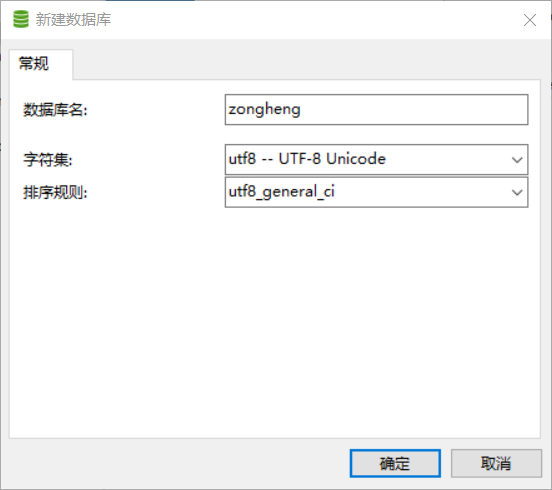
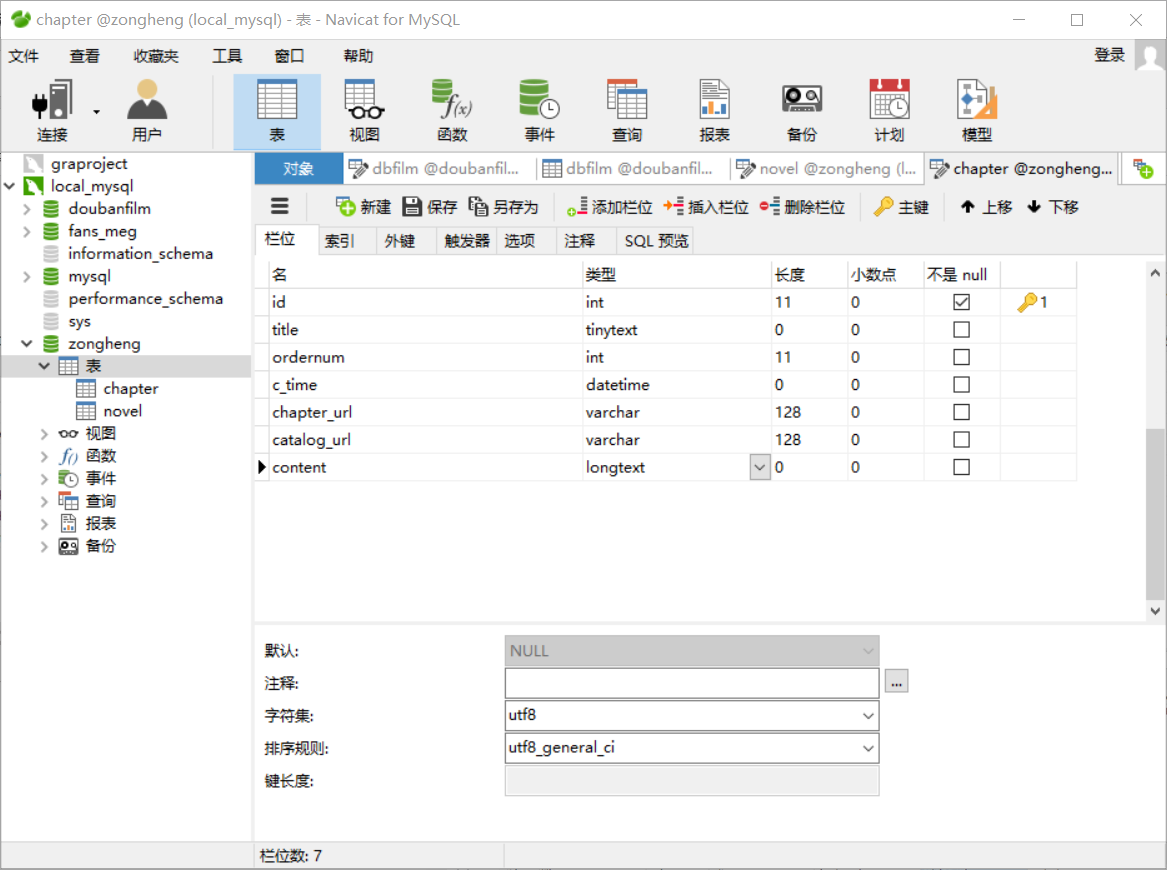
⑤navicat创库建表:
(1)创库:
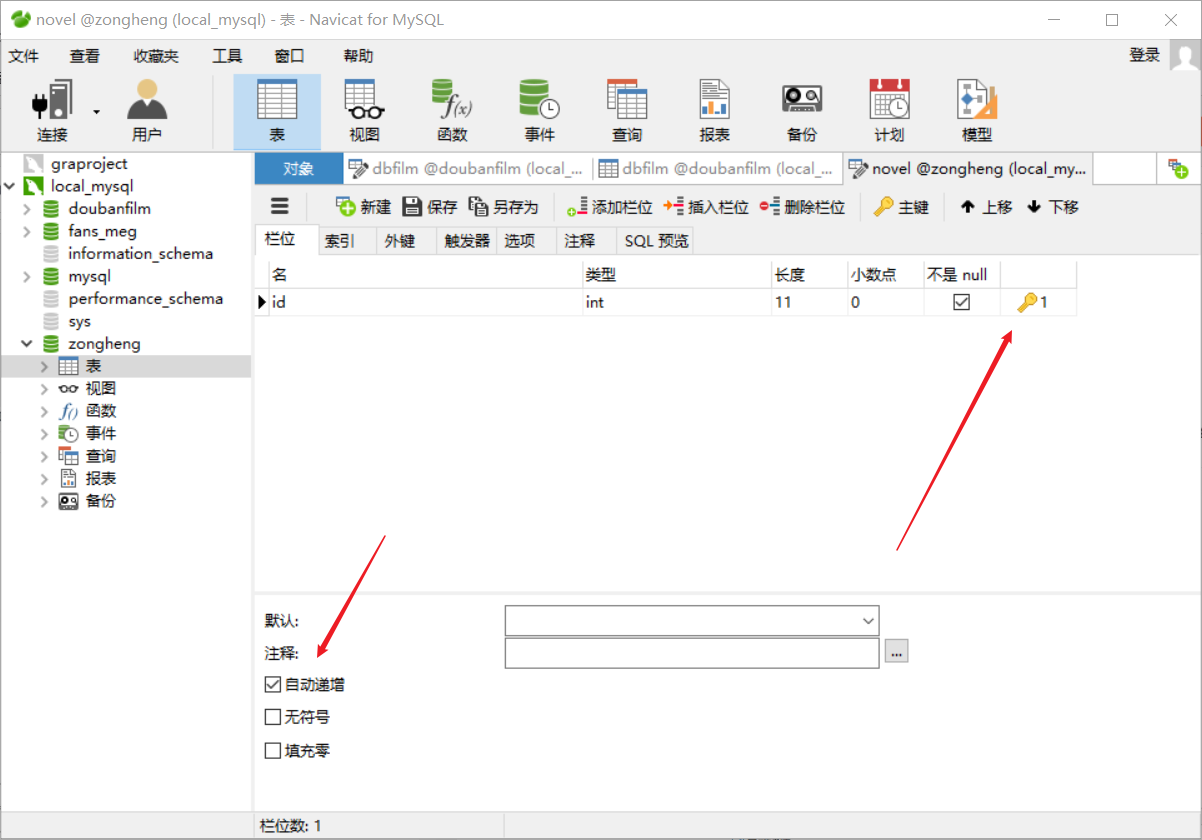
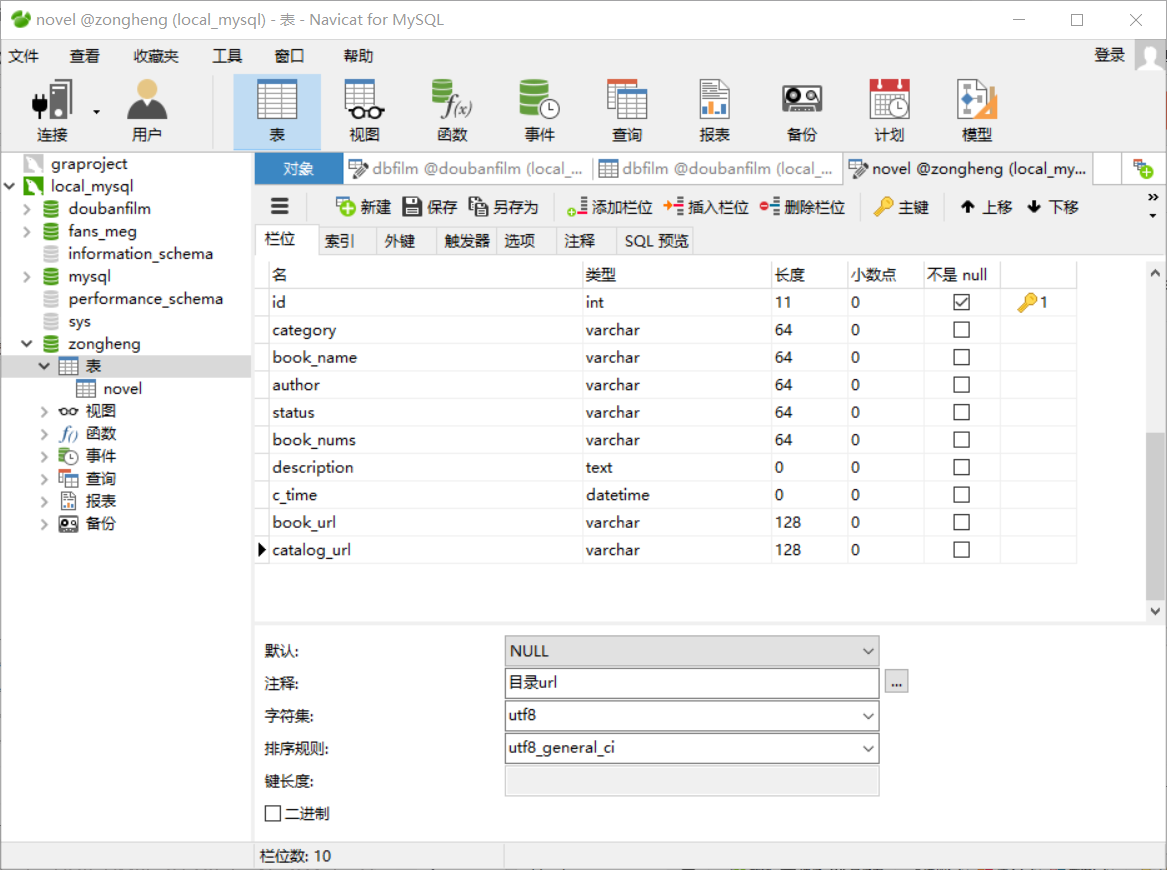
(2)建表:(注意:总共需要建两张表!)
-
存储小说基本信息的表,表名为novel
-
存储小说具体章节内容的表,表名为chapter:
- 注意id不要忘记设自增长了!
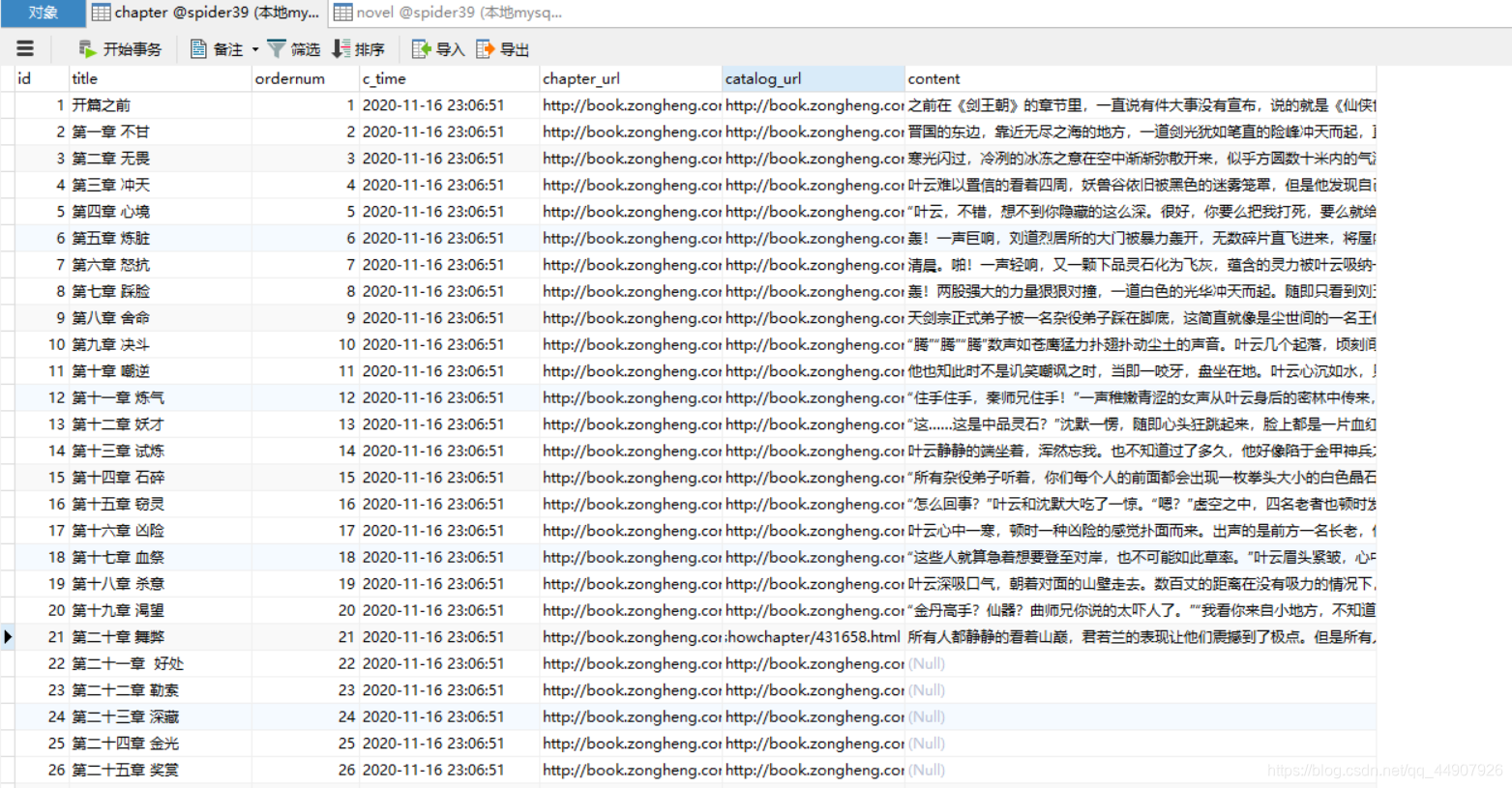
⑥ 效果如下:

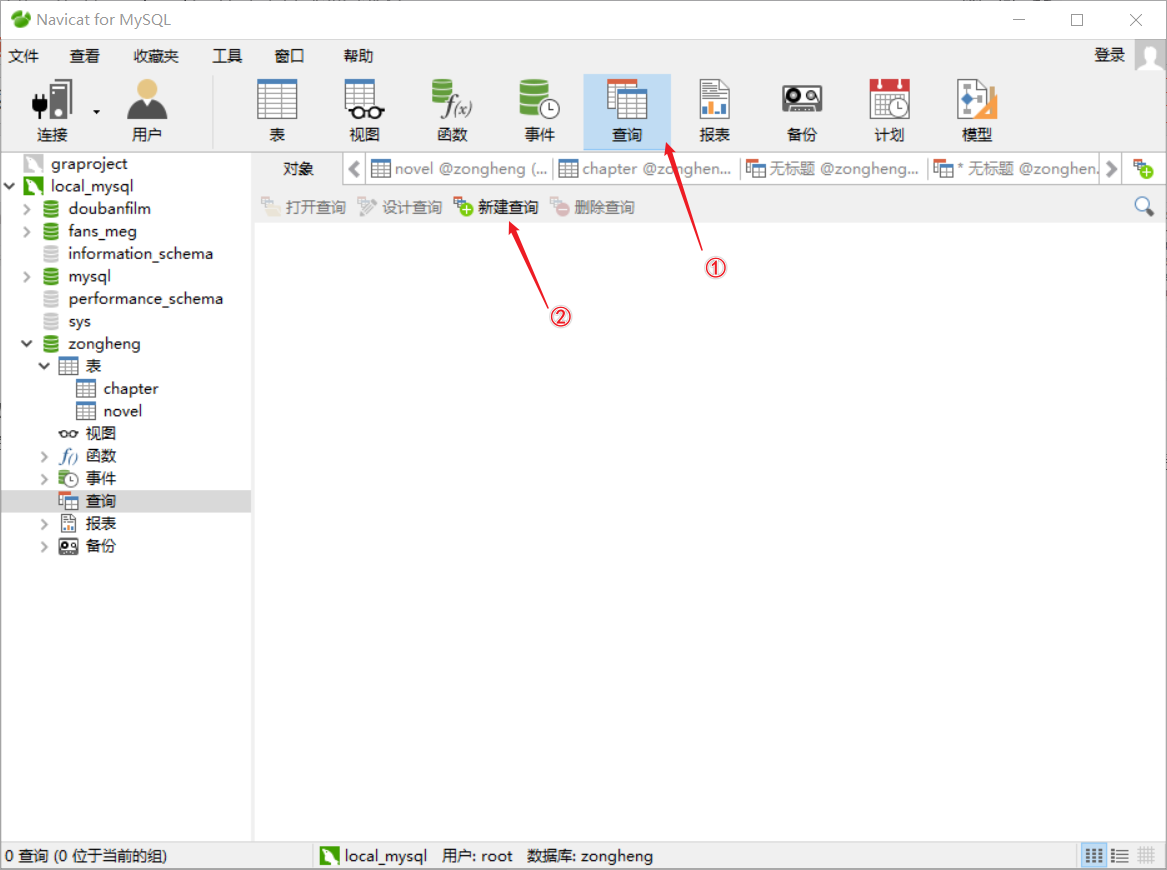
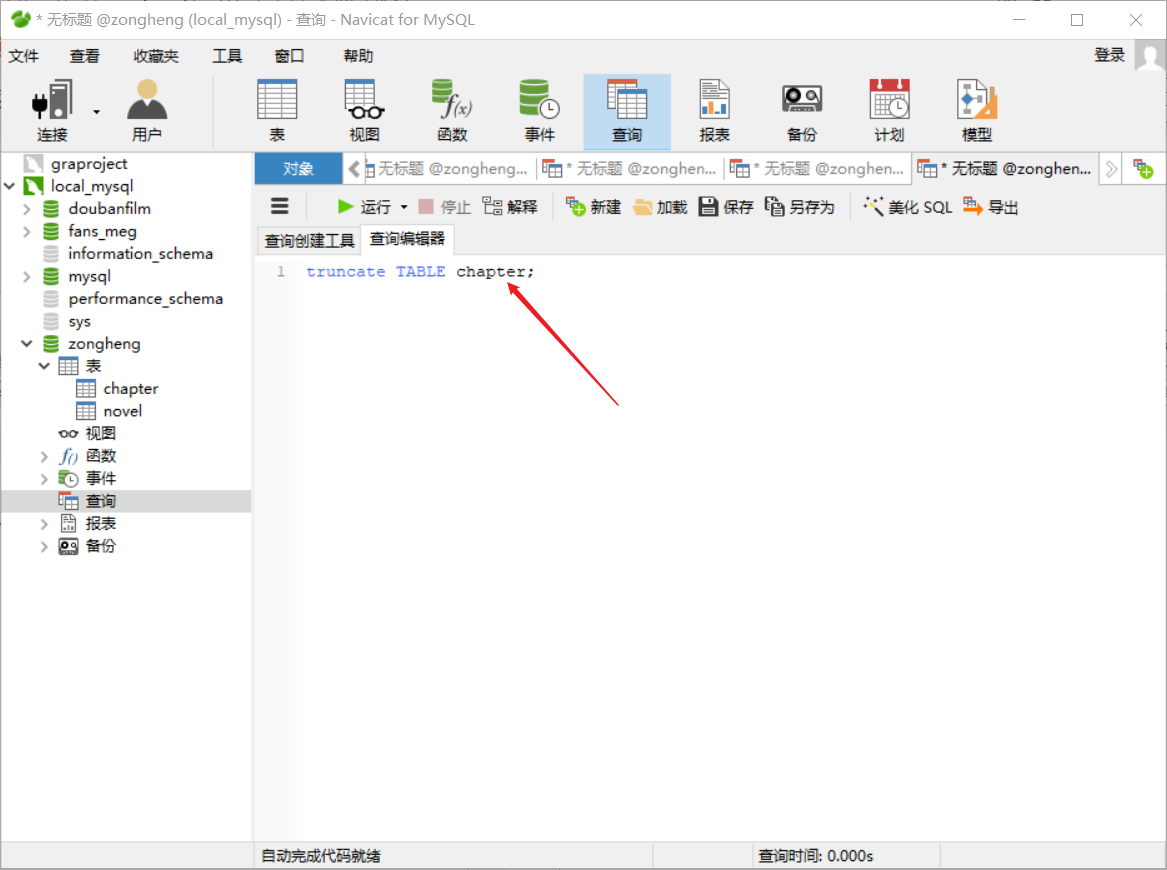
- 拓展操作:
如果来回调试有问题的话,需要删除表中所有数据重新爬取,直接使用navicate删除表中所有数据(即delete操作),那么id自增长就不会从1开始了。
这该咋办呢?
相关文章:
Python爬虫之Scrapy框架系列(13)——实战ZH小说爬取数据入MySql数据库
目录:1 数据持久化存储,写入Mysql数据库①定义结构化字段:②重新编写爬虫文件:③编写管道文件:④辅助配置(修改settings.py文件):⑤navicat创库建表:⑥ 效果如下…...
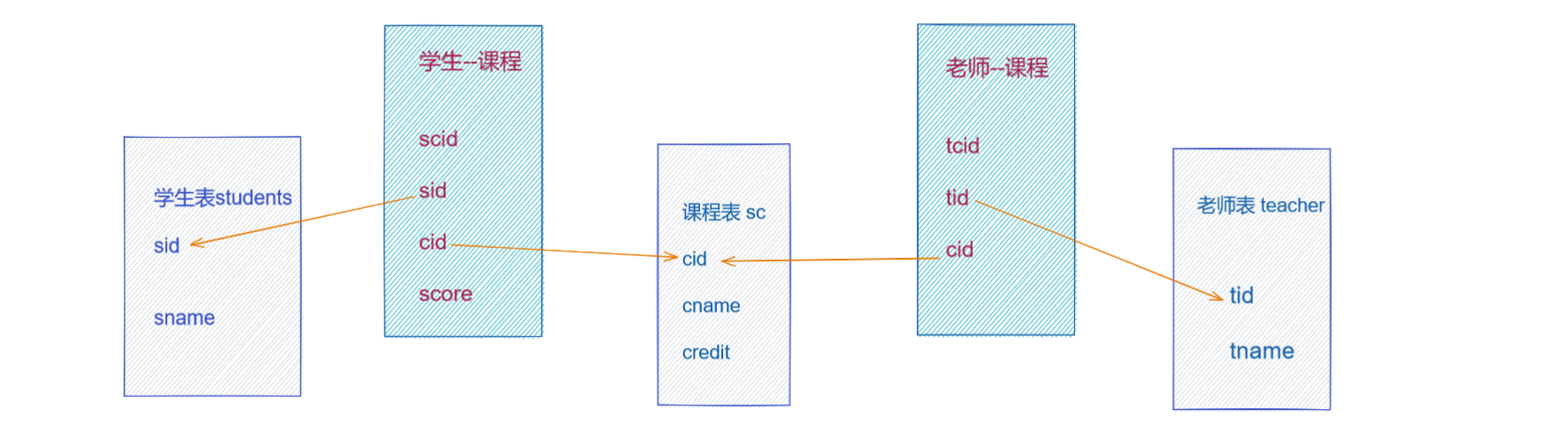
MySQL篇02-三大范式,多表查询
数据入库时,由于数据设计不合理,会存在数据重复、更新插入异常等情况, 故数据库中表的设计遵循的设计规范:三大范式1.第一范式(1NF)要求数据库的每一列都是不可分割的原子数据项,即原子性。强调的是列的原子性,即数据库中每一列的…...

vue-cli3创建Vue项目
文章目录前言一、使用vue-cli3创建项目1.检查当前vue的版本2.下载并安装Vue-cli33.使用命令行创建项目二、关于配置前言 本文讲解了如何使用vue-cli3创建属于自己的Vue项目,如果本文对你有所帮助请三连支持博主,你的支持是我更新的动力。 下面案例可供…...
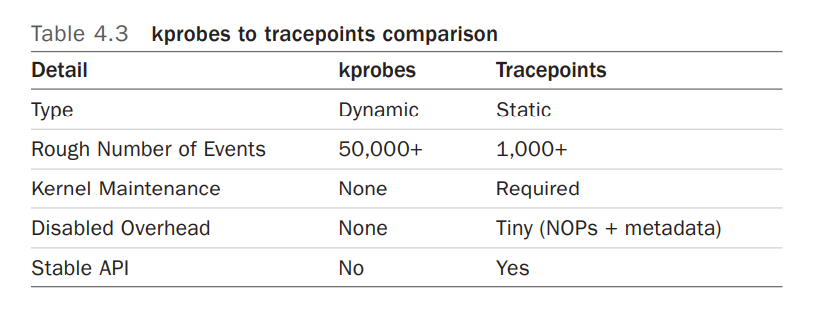
Linux perf probe 的使用(三)
文章目录前言一、Dynamic Tracing二、kprobes2.1 perf kprobe 的使用2.2 kprobe Arguments3.3 tcp_sendmsg()3.3.1 Kernel: tcp_sendmsg()3.3.2 Kernel: tcp_sendmsg() with size3.3.2 Kernel: tcp_sendmsg() line number and local variable三、uprobes的使用3.1 perf uprobe …...

python GUI编程 多窗口跳转
# 多窗口跳转例子from tkinter import *def main(): # 主窗体def goto(num):root.destroy() # 关闭主窗体if num 1:one() # 进入第1个窗体elif num 2:two() # 进入第2个窗体root Tk()root.geometry(300x150600200)root.title(登录窗口)but1 Button(root, text"进入…...
nuxt 学习笔记
这里写目录标题路由跳转NuxtLinkquery参数params参数嵌套路由tab切换效果layouts 文件夹强制约定放置所有布局文件,并以插槽的形式作用在页面中1.在app.vue里面2.component 组件使用Vue < component :is"">Vuex生命周期数据请求useFetchuseAsyncDat…...
Python编程自动化办公案例(1)
作者简介:一名在校计算机学生、每天分享Python的学习经验、和学习笔记。 座右铭:低头赶路,敬事如仪 个人主页:网络豆的主页 目录 前言 一.使用库讲解 1.xlrd 2.xlwt 二.主要案例 1.批量合并 模板如下…...
一站式 Elasticsearch 集群指标监控与运维管控平台
上篇文章写了一下消息运维管理平台,今天带来的是ES的监控和运维平台。目前初创企业,不像大型互联网公司,可以重复的造轮子。前期还是快速迭代试错阶段,方便拿到市场反馈,及时调整自己的战略和产品方向。让自己活下去&a…...

C# 调用Python
一、简介 IronPython 是一种在 NET 和 Mono 上实现的 Python 语言,由 Jim Hugunin(同时也是 Jython 创造者)所创造。 Python是一种跨平台的计算机程序设计语言。 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。 Python是…...
)
51单片机最强模块化封装(3)
文章目录 前言一、创建smg文件,添加smg文件路径二、smg文件编写三、模块化测试总结前言 本篇文章将带大家继续封装我们的代码。 这里我们会封装数码管的操作函数。 一、创建smg文件,添加smg文件路径 这里的操作就不过多解释了,大家自行看前面的文章即可。 51单片机模块化…...

【CSS 布局】水平垂直居中
CSS 布局-水平垂直居中 一、水平居中 创建一个父盒子,和子盒子 <div class"parent"><div class"child"></div> </div>基本样式如下 .parent {background-color: #fff; }.child {background-color: #999;width: 100p…...

【C++】类和对象--类的6个默认成员函数
目录1.类的6个默认成员函数2.构造函数2.1概念2.2特性3.析构函数3.1概念3.2特性4.拷贝构造函数4.1概念4.2特征5.赋值运算符重载5.1运算符重载5.2赋值运算符重载5.3前置和后置重载5.4流插入和流提取运算符重载6.const成员7.取地址重载和const取地址操作符重载1.类的6个默认成员函…...

常见面试题---------如何处理MQ消息丢失的问题?
如何处理MQ消息丢失的问题? RabbitMQ丢失消息分为如下几种情况: 生产者丢消息: 生产者将数据发送到RabbitMQ的时候,可能在传输过程中因为网络等问题而将数据弄丢了。 RabbitMQ自己丢消息: 如果没有开启RabbitMQ的持久化&#x…...

十四、Linux网络:高级IO
目录 五种IO模型 同步IO 阻塞IO 非阻塞IO 信号驱动IO IO多路转接 异步IO...

带你走进API安全的知识海洋
Part1什么是API API(Application Programming Interface,应用程序接口)是一些预先定义的接口(如函数、HTTP接口),或指软件系统不同组成部分衔接的约定。用来提供应用程序与开发人员基于某软件或硬件得以访…...
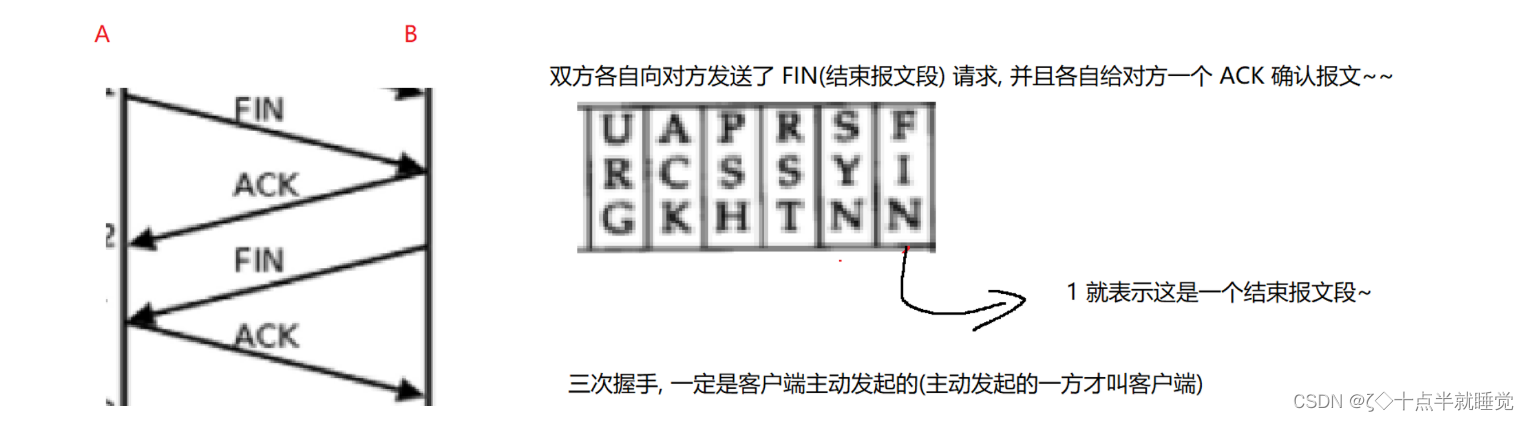
【Java】TCP的三次握手和四次挥手
三次握手 TCP三次握手是一个经典的面试题,它指的是TCP在传递数据之前需要进行三次交互才能正式建立连接,并进行数据传递。(客户端主动发起的)TCP之所以需要三次握手是因为TCP双方都是全双工的。 什么是全双工? TCP任何…...

JUC并发编程
1.什么是JUC java.util工具包、包、分类 业务:普通业务线程代码 Thread Runable: 没有返回值、效率相比Callable相对较低。 2.线程和进程 进程:一个程序,QQ.exe Music.exe 程序的集合 一个进程往往可以包含多个线程,至少包含一个…...

概率统计·假设检验【正态总体均值的假设检验、正态总体方差的假设检验】
均值假设检验定义 2类错误 第1类错误(弃真):当原假设H0为真,观察值却落入拒绝域,因而拒 绝H0这类错误是“以真为假” 犯第一类错误的概率显著性水平α第2类错误(取伪):当原假设H0不…...

如何预测机组设备健康状态?你可能需要这套解决方案
1. 应用场景随机振动[注1]会发生在工业物联网的各个场景中,包括产线机组设备的运行、运输设备的移动、试验仪器的运行等等。通过分析采集到的振动信号可以预估设备的疲劳年限、及时知晓设备已发生的异常以及预测未来仪器可能发生的异常等等。本篇教程会提供给有该方…...

C++类和对象:面向对象编程的核心。| 面向对象还编什么程啊,活该你是单身狗。
👑专栏内容:C学习笔记⛪个人主页:子夜的星的主页💕座右铭:日拱一卒,功不唐捐 文章目录一、前言二、面向对象编程三、类和对象1、类的引入2、类的定义Ⅰ、声明和定义在一起Ⅱ、声明和定义分开Ⅲ、成员变量命…...

教培机构管理越忙越乱?用对工具,比多雇两个人更高效
不少培训机构校长都有同样的感受:明明团队很拼,每天从早忙到晚,可机构依旧问题不断。招生线索散落在微信、表格、登记本里,跟进不及时就白白流失;排课全靠人工核对,老师冲突、教室撞期、调课通知不到位是常…...

深度学习草图到全栈代码生成:技术原理、实现挑战与工程实践
1. 项目概述:从草图到全栈应用的智能跃迁在软件开发领域,从产品原型到最终上线的代码实现,中间横亘着一条巨大的“实现鸿沟”。产品经理或设计师用Sketch、Figma等工具绘制出精美的界面草图,而工程师则需要将这些静态的视觉稿&…...

AI驱动SEO技术架构:从自动化脚本到模式识别的工程实践
1. 项目概述:从“垃圾场”到“架构师”的AI SEO转型如果你最近打开搜索引擎,发现前几页的结果里充斥着大量读起来味同嚼蜡、观点模糊、甚至自相矛盾的文章,那你大概率是撞上了“AI垃圾场”。没错,现在很多人的SEO策略简单得令人发…...

现代React Native开发:从Expo生态到Redux状态管理的工程实践
1. 项目概述:一个为现代React Native开发量身定制的生产力引擎 如果你和我一样,在过去几年里用React Native做过几个项目,那你一定对项目初始化时那种重复、繁琐的“体力活”深有体会。每次新建一个项目,都要重新安装一堆依赖库&…...

如何用JPlag守护代码原创性:5分钟快速上手指南
如何用JPlag守护代码原创性:5分钟快速上手指南 【免费下载链接】JPlag State-of-the-Art Source Code Plagiarism & Collusion Detection. Check for plagiarism in a set of programs. 项目地址: https://gitcode.com/gh_mirrors/jp/JPlag 你是否曾担心…...

自建链接管理服务OtterLink:从部署到实战的完整指南
1. 项目概述:一个链接管理的“瑞士军刀” 最近在折腾个人知识库和内容分发,发现一个痛点:手头攒了太多链接。技术文章、工具网站、项目仓库、临时笔记链接……散落在浏览器书签、聊天记录、备忘录里,时间一长要么找不到ÿ…...

Arm CoreLink CMN-600硬件错误解析与解决方案
1. Arm CoreLink CMN-600硬件错误深度解析在复杂SoC设计中,互连架构的质量直接决定整个系统的稳定性和性能。作为Arm Neoverse平台的核心组件,CoreLink CMN-600(Coherent Mesh Network)承担着处理器集群、内存控制器和I/O设备之间…...

大模型对话的端到端加密与隐私计算实战:基于CipherChat与TEE的架构解析
1. 项目概述:当大模型对话遇上“密码学”的硬核保护最近在折腾大语言模型(LLM)应用落地的朋友,估计都绕不开一个核心痛点:安全与隐私。无论是企业内部的知识库问答,还是面向用户的个性化AI助手,…...

一键批量下载网易云音乐FLAC无损音乐:Golang高效解决方案
一键批量下载网易云音乐FLAC无损音乐:Golang高效解决方案 【免费下载链接】NeteaseCloudMusicFlac 根据网易云音乐的歌单, 下载flac无损音乐到本地.。 项目地址: https://gitcode.com/gh_mirrors/nete/NeteaseCloudMusicFlac 你是否曾梦想拥有一个完整的无损…...

从零到一:深入拆解 I/O 多路复用的前世今生与实战选型
1. 从单线程阻塞到多路复用:I/O模型的进化史 第一次写网络程序时,你可能遇到过这样的场景:服务器在accept()一个客户端连接后,整个程序就像被冻住一样,直到这个客户端发送数据才能继续运行。这就是最原始的阻塞I/O模型…...