学习Flask之七、大型应用架构
学习Flask之七、大型应用架构
尽管存放在单一脚本的小型网络应用很方便,但是这种应用不能很好的放大。随着应用变得复杂,维护一个大的源文件会出现问题。不像别的网络应用,Flask没有强制的大型项目组织结构。构建应用的方法完全留给开发者。本章,呈现一种组织大型应用到包或模块的方法。
这种结构用于维护本书余下的例子。
项目结构
Example 7-1 展示Flask应用的基础布局
Example 7-1. 基础的多文件Flask应用架构
|-flasky
|-app/
|-templates/
|-static/
|-main/
|-__init__.py
|-errors.py
|-forms.py
|-views.py
|-__init__.py
|-email.py
|-models.py
|-migrations/
|-tests/
|-__init__.py
|-test*.py
|-venv/
|-requirements.txt
|-config.py
|-manage.py
这个结构有4个顶层目录:
• Flask应用通常放在名为app的包里。
• migrations目录包含数据库迁移脚本,如前所述。
• Unit tests 放在tests包里。
• venv目录包含Python虚拟环境,如前所述。
也有一些新的文件:
• requirements.txt列出了依赖包以便在不同的计算机产生相同的虚拟环境。
• config.py存贮配置设置。
• manage.py启动应用和其它应用任务。
为了帮助你理解这个结构,下一节描述如何将hello.py应用转换到这个结构。
配置选项
应用通常需要多种配置设置。最好的例子是在开发、测试和生产过程中需要不同的数据库,以免相互干扰。 不像hello.py里用简单的字典结构配置,而是使用一个层级的配置类。
Example 7-2展示了config.py文件。
Example 7-2. config.py: Application configuration
import os
basedir = os.path.abspath(os.path.dirname(__file__))
class Config:
SECRET_KEY = os.environ.get('SECRET_KEY') or 'hard to guess string'
SQLALCHEMY_COMMIT_ON_TEARDOWN = True
FLASKY_MAIL_SUBJECT_PREFIX = '[Flasky]'
FLASKY_MAIL_SENDER = 'Flasky Admin <flasky@example.com>'
FLASKY_ADMIN = os.environ.get('FLASKY_ADMIN')
@staticmethod
def init_app(app):
pass
class DevelopmentConfig(Config):
DEBUG = True
MAIL_SERVER = 'smtp.googlemail.com'
MAIL_PORT = 587
MAIL_USE_TLS = True
MAIL_USERNAME = os.environ.get('MAIL_USERNAME')
MAIL_PASSWORD = os.environ.get('MAIL_PASSWORD')
SQLALCHEMY_DATABASE_URI = os.environ.get('DEV_DATABASE_URL') or \
'sqlite:///' + os.path.join(basedir, 'data-dev.sqlite')
class TestingConfig(Config):
TESTING = True
SQLALCHEMY_DATABASE_URI = os.environ.get('TEST_DATABASE_URL') or \
'sqlite:///' + os.path.join(basedir, 'data-test.sqlite')
class ProductionConfig(Config):
SQLALCHEMY_DATABASE_URI = os.environ.get('DATABASE_URL') or \
'sqlite:///' + os.path.join(basedir, 'data.sqlite')
config = {
'development': DevelopmentConfig,
'testing': TestingConfig,
'production': ProductionConfig,
'default': DevelopmentConfig
}
Config基类包含所有配置常用的设置,不同的子类定义特定的配置设置。 额外的配置可以按需添加。要使配置更灵活和安全,有些设置可以可选的从环境变量导入。例如 SECRET_KEY值,由于它的敏感性,可以设置在环境里,但是可以提供黙认值以免环境里没有定义。
SQLALCHEMY_DATABASE_URI三种配置有不同的值。这可以使应用在不同的配置下运行,每个使用不同的数据库。
配置类可以定义一个 init_app()类方法,它取应用实例作为参数。这里配置特定的初始化可以进行。现在基础配置类实施一个空的init_app()方法。在配置脚本下部,不同的配置注册于config字典。一个配置(用于开发环境)也注册为黙认。
应用包
应用包是所有的应用代码,静态文件,模板存放的地方。它简单的命名为app,虽然它可以给应用特定的名字,如果需要。
templates和static 目录是应用包的一部分,所以这两个目录放在app里。数据模型和邮件支持函数也放在这个包里,每个都有它自已的模块如app/models.py 和app/email.py。
使用应用工厂
在一个文件里创建应用非常方便,但是有个大的缺点。因为应用创建在全局范围里,没办法动态的应用配置变化:脚本运行时,应用实例已经创建,进行配置变更太迟了。
这对单元测试特别重要,因为有时它有必要在不同的配置设置下运行以覆盖更好的测试。这个问题的解决方案是延迟应用的创建,通过把它放在工厂 函数里,可以从脚本明文的调用。
这不但可以给脚本时间进行配置也可以创建多个应用实例--也时在测试过程中很有用。例Example 7-3显示的工厂函数,在app包的构造函数里定义。构造函数导入大部分Flask扩展,但是因为没有应用实例初始化他们,它的创建没有初始化,通过传递空参数到构造函数。create_app()函数是应用工厂,取名字作为参数供应用使用。配置设置存贮于一个config.py 定义的类里的配置设置可以直接导入到应用,使用from_object()方法,这个方法在app.config配置对象里。通过config字典的name选择配置对象。一旦应用被创建和配置,扩展就可以被初始化。调用init_app()完成初始化工作。
Example 7-3. app/__init__.py: Application package constructor
from flask import Flask, render_template
from flask.ext.bootstrap import Bootstrap
from flask.ext.mail import Mail
from flask.ext.moment import Moment
from flask.ext.sqlalchemy import SQLAlchemy
from config import config
bootstrap = Bootstrap()
mail = Mail()
moment = Moment()
db = SQLAlchemy()
def create_app(config_name):
app = Flask(__name__)
app.config.from_object(config[config_name])
config[config_name].init_app(app)
bootstrap.init_app(app)
mail.init_app(app)
moment.init_app(app)
db.init_app(app)
# attach routes and custom error pages here
return app
工厂函数返回创建的应用实例,但是注意用工厂函数创建的应用当前未完全,因为它们缺少路由和定制错误处理页。这是下一节的主题。
在Blueprint里实施应用功能
转换到应用工厂会使路由变得复杂。在单一脚本的应用里,应用实例存在于全局范围里,所以路由可以很易容的定义,使用app.route装饰器。但是现在应用在运行时创建,app.route只有在create_app()调用之后才有,这太迟了。像路由,定制错误处理页处理器同样有这个问题,因为它们由app.errorhandler装饰器定义。幸运的是,Flask 提供了更好的解决方案,使用blueprints。blueprint与应用的相似之处是它也可以定义路由。不同之处是与blueprint与关的路由处于支配状态,直到blueprint用一个应用注册,这个时候路由成为应用的一部分。使用全局范围里定义的blueprint,应用的路由可以与单一文件应用的路由的定义方法一样。像应用一样,blueprints也可以定义在一个单一的文件或一个包的多个模块里。为了最大的灵活性,应用包里的子包将创建以存放blueprint。
Example 7-4展示包的构造函数,它创建blueprint。
Example 7-4. app/main/__init__.py: Blueprint creation
from flask import Blueprint
main = Blueprint('main', __name__)
from . import views, errors
Blueprints通过实例化一个Blueprint类对象创建。这个类的构造函数取二个要求的参数:blueprint名和blueprint所在的模块或包。
与应用一样, Python的 __name__ 变量是第二个参数的正确值。应用的路由存放在 包的app/main/views.py模块里。 错误处理器放在 app/main/errors.py。导入变些模块使路由和错误处理页与 blueprint关联。重要的是要注意模块在app/__init__.py脚本的底部导入。以免循环依赖,因为views.py 和errors.py 需要导入主blueprint。blueprint 在 create_app()应用工厂里用应用注册,见Example 7-5.
Example 7-5. app/_init_.py: Blueprint registration
def create_app(config_name):
# ...
from main import main as main_blueprint
app.register_blueprint(main_blueprint)
return app
Example 7-6 展示错误处理器。
Example 7-6. app/main/errors.py: Blueprint with error handlers
from flask import render_template
from . import main
@main.app_errorhandler(404)
def page_not_found(e):
return render_template('404.html'), 404
@main.app_errorhandler(500)
def internal_server_error(e):
return render_template('500.html'), 500
在blueprint里书写错误处理器的不同之处是如果使用错误处理器装饰函数,处理器只会因错误blueprint内的错误而调用。要安装应用范围内的处理器,必须使用app_errorhandler。
Example 7-7展示更新于blueprint内的应用路由
Example 7-7. app/main/views.py: Blueprint with application routes
from datetime import datetime
from flask import render_template, session, redirect, url_for
from . import main
from .forms import NameForm
from .. import db
from ..models import User
@main.route('/', methods=['GET', 'POST'])
def index():
form = NameForm()
if form.validate_on_submit():
# ...
return redirect(url_for('.index'))
return render_template('index.html',
form=form, name=session.get('name'),
known=session.get('known', False),
current_time=datetime.utcnow())
在blueprint里书写view在两个主要的不同之处。首先,像前面的错误处理器,路由装饰器来自blueprint。
第二个不同之处是 url_for() 函数的使用。你可能记得,这个函数的第一个参数是路由的endpoint名, 在应用的路由里黙认是view名。例如,在一个脚本的应用的index()view函数的URL可以用url_for('index')获得。
blueprints的不同是Flask使用名字空间来调用来自blueprint的endpoints,以便多个blueprints可以定义view函数使用相同的endpoint名而不冲突。名字空间是blueprint的名(blueprint构造器的第一个参数),所以index()view函数用endpoint名main.index注册,它的URL可以用url_for('main.index')获得。blueprints里url_for()函数也支持更短格式的 endpoints,其中blueprint名可以忽略,例如url_for('.index')。使用这种标记,使用当前请求的blueprint。这意味着相同blueprint里的重定向可以用更短格式,而blueprints间的重定向必须使用 namespaced端点名。
要完成应用页的变更, form对象也存贮在app/main/forms.py的blueprint里。
启动脚本
使用在顶层目录里的manage.py文件来启动应用。这个脚本展示于 Example 7-8.
Example 7-8. manage.py: 启动脚本
#!/usr/bin/env python
import os
from app import create_app, db
from app.models import User, Role
from flask.ext.script import Manager, Shell
from flask.ext.migrate import Migrate, MigrateCommand
app = create_app(os.getenv('FLASK_CONFIG') or 'default')
manager = Manager(app)
migrate = Migrate(app, db)
def make_shell_context():
return dict(app=app, db=db, User=User, Role=Role)
manager.add_command("shell", Shell(make_context=make_shell_context))
manager.add_command('db', MigrateCommand)
if __name__ == '__main__':
manager.run()
脚本以创建一个应用开始。使用的配置来自环境变量FLASK_CONFIG, 如果它被定义。如果没有定义,使用黙认的配置。然后Flask-Script, Flask-Migrate, 和Python shell的自制义上下文初始化。
作为习惯,增加一行shebang,以便基于Unix的操作系统里脚本可以执行为./manage.py 而不是python manage.py。
Requirements文件
应用必须包括requirements.txt文件记录所有的依赖包,带上正确的版本号。 这很重要,对于不同机器上产生相同的虚拟环境。例如应用布局于生产环境。这个文件通过如下命令自动产生:
(venv) $ pip freeze >requirements.txt
当包被安装或更新时刷新这个文件是很好的想法。示例的requirements文件如下:
Flask==0.10.1
Flask-Bootstrap==3.0.3.1
Flask-Mail==0.9.0
Flask-Migrate==1.1.0
Flask-Moment==0.2.0
Flask-SQLAlchemy==1.0
Flask-Script==0.6.6
Flask-WTF==0.9.4
Jinja2==2.7.1
Mako==0.9.1
MarkupSafe==0.18
SQLAlchemy==0.8.4
WTForms==1.0.5
Werkzeug==0.9.4
alembic==0.6.2
blinker==1.3
itsdangerous==0.23
当你要构建相同的虚拟环境时,你可以创建新的虚拟环境,然后运行如下命令:
(venv) $ pip install -r requirements.txt
你读这本书时,示例requirements.txt 的版本号可能已经过时了。如果你喜欢,你可以使用最新发行包。如果你遇到问题,你可以返回requirements文件指定的版本,因为这些是已知与应用兼容的。
单元测试
这个应用很小,还没有太多的测试,但作为示例,有两个测试可以按Example 7-9:
Example 7-9. tests/test_basics.py: Unit tests
import unittest
from flask import current_app
from app import create_app, db
class BasicsTestCase(unittest.TestCase):
def setUp(self):
self.app = create_app('testing')
self.app_context = self.app.app_context()
self.app_context.push()
db.create_all()
def tearDown(self):
db.session.remove()
db.drop_all()
self.app_context.pop()
def test_app_exists(self):
self.assertFalse(current_app is None)
def test_app_is_testing(self):
self.assertTrue(current_app.config['TESTING'])
这些测试用python标准库的标准的unittest包。 setUp()和tearDown()在测试前后运行,任何有test_开始的名称的方法都按测试执行。如果你想要学习更多用python unittest包写单元测试,请看官方文档。
setUp()方法试图创建一个与运行应用相似的测试环境。它首先创建一个测试的应用配置和激活上下文。这一步确保测试可以像正常的请求一样访问。然后它创建一个新的数据库,必要时测试可以使用它。数据库和应用上下文用tearDown()方法删除。
第一个测试确保应用实全存在。第二个测试确保应用运行于测试本置。要使测试目录成为一个合适的包,需要增加tests/__init__.py,但这可以是空的文件。因为 unittest包可以扫描所有模块并定位测试。要运行单元测试,可以在manage.py脚本增加制定命令。
Example 7-10 展示如何增加test命令。
Example 7-10. manage.py: Unit test launcher command
@manager.command
def test():
"""Run the unit tests."""
import unittest
tests = unittest.TestLoader().discover('tests')
unittest.TextTestRunner(verbosity=2).run(tests)
manager.command装饰器使定制命令变得简单。装饰函数的名称用作命令名,函数的 docstring 显示于帮助信息。test()的实施调用来自unittest包的测试运行器。单元测试可以用如下方法执行。
(venv) $ python manage.py test
test_app_exists (test_basics.BasicsTestCase) ... ok
test_app_is_testing (test_basics.BasicsTestCase) ... ok
.----------------------------------------------------------------------
Ran 2 tests in 0.001s
OK
数据库设置
重构的应用使用一个不同于单一脚本版本的数据库。数据库URL取自环境变量作为第一选择,黙认的SQLite数据库作为备选。环境变量和数据文件对于三种配置是不同的。例如,在开发配置里,URL来自环境变量DEV_DATABASE_URL,如果没有定义则使用名为 data-dev.sqlite的 SQLite 数据库。不管数据库URL的来源,都要首先创建新数据库的数据表。当用Flask-Migrate来跟踪迁移时,可以创建或更新数据库表到最新的版本,使用如下命令:
(venv) $ python manage.py db upgrade
不管你信不信,你已到达 Part I的结尾了。你已学习了用Flask构建网络应用的必要元素,但是你可能还不确定如何用这些元素来形成一个实际的应用。
相关文章:

学习Flask之七、大型应用架构
学习Flask之七、大型应用架构 尽管存放在单一脚本的小型网络应用很方便,但是这种应用不能很好的放大。随着应用变得复杂,维护一个大的源文件会出现问题。不像别的网络应用,Flask没有强制的大型项目组织结构。构建应用的方法完全留给开发者。…...
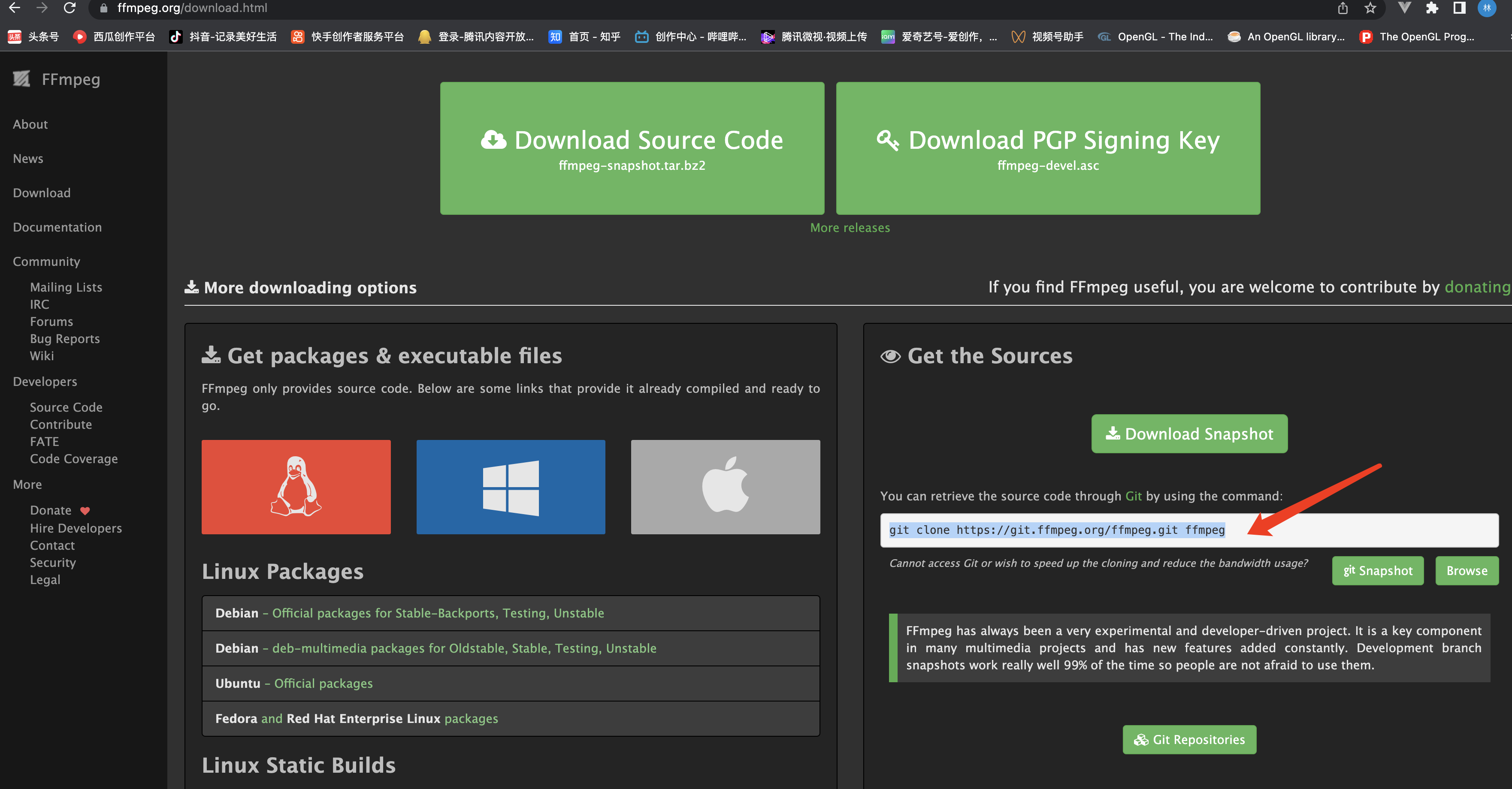
CentOS9下编译FFMPEG源码
克隆...

炼石:八年饮冰难凉热血,初心如磐百炼成钢
炼石成立八周年 八载笃行,踔厉奋发。创立于2015年的炼石,今天迎来了八岁生日,全体员工共同举行了温暖又充满仪式感的周年庆典。过去的2022,是三年疫情的艰难“收官之年”,新的2023,将是数据安全行业成为独…...

Python基本数据类型
Python有六种基本数据类型Number(数字)String(字符串) List(列表) Tuple(元组) Set(集合)Dictionary(字典)String(字符串&…...
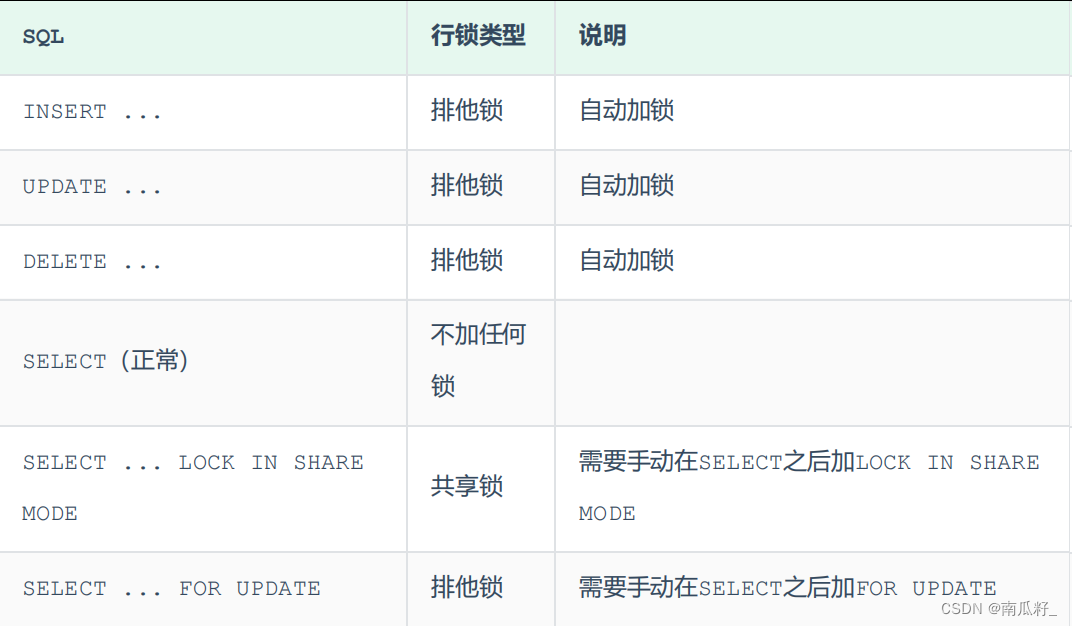
【MySQL进阶】 锁
😊😊作者简介😊😊 : 大家好,我是南瓜籽,一个在校大二学生,我将会持续分享Java相关知识。 🎉🎉个人主页🎉🎉 : 南瓜籽的主页…...

javascript高级程序设计第四版读书笔记-第五章 基本引用类型
19.如何创建一个指定的本地时间? Dete只能接收时间戳,有两种方法可以将字符串参数变为时间戳,他们是Date隐式调用的, 分别是Date.parse() 创建的是GTM时间,Date.UTC()创建的是本地时间 Date.UTC()方法也返回日期的毫秒表示&#x…...

《爆肝整理》保姆级系列教程python接口自动化(二十一)--unittest简介(详解)
简介 前边的随笔主要介绍的requests模块的有关知识个内容,接下来看一下python的单元测试框架unittest。熟悉 或者了解java 的小伙伴应该都清楚常见的单元测试框架 Junit 和 TestNG,这个招聘的需求上也是经常见到的。python 里面也有单元 测试框架-unitt…...
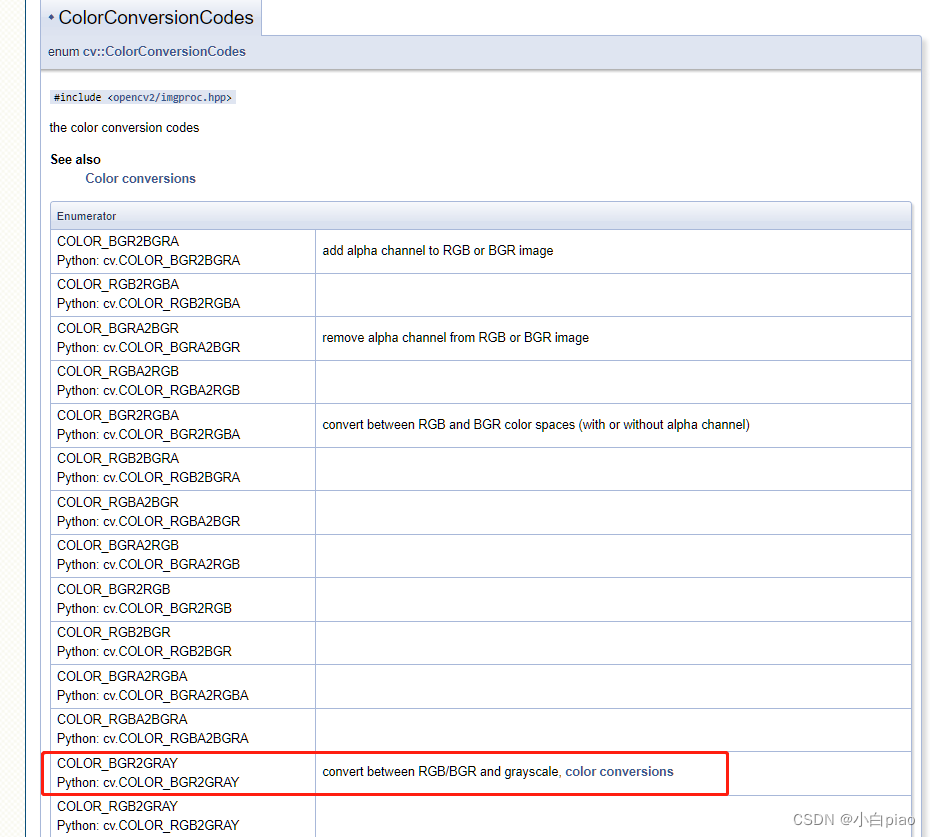
【C++的OpenCV】第四课-OpenCV图像常用操作(一):Mat对象深化学习、灰度、ROI
我们开始图像处理的基本操作的了解一、图像对象本身的加深学习1.1 Mat对象和ROI1.1.1 创建一个明确的Mat对象1.1.2 感兴趣的区域ROI二、图像的灰度处理2.1 概念2.2 cvtColor()函数2.3 示例一、图像对象本身的加深学习 1.1 Mat对象和ROI 这是一个技术经验的浅尝,所以…...
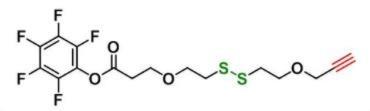
Propargyl-PEG1-SS-PEG1-PFP ester,1817735-30-0,炔基应用于生物标记
【中文名称】丙炔-单乙二醇-二硫键-单乙二醇-五氟苯酚酯【英文名称】 Propargyl-PEG1-SS-PEG1-PFP ester【结 构 式】【CAS号】1817735-30-0【分子式】C16H15F5O4S2【分子量】430.4【基团部分】炔基基团【纯度标准】95%【包装规格】1g,5g,10g,…...
产品运营︱用户活跃度低的解决方法
app用户活跃度低,产品拉新变现效率慢,这是运营app时难免会遇到的情况。要想解决这类问题,就要从可能的原因下手,进行产品的优化改进,记录下改变后的关键数据变化,定期做好复盘工作进行调整。 一、app用户量…...

【华为OD机试模拟题】用 C++ 实现 - 求最大数字
最近更新的博客 华为OD机试 - 入栈出栈(C++) | 附带编码思路 【2023】 华为OD机试 - 箱子之形摆放(C++) | 附带编码思路 【2023】 华为OD机试 - 简易内存池 2(C++) | 附带编码思路 【2023】 华为OD机试 - 第 N 个排列(C++) | 附带编码思路 【2023】 华为OD机试 - 考古…...

吉卜力风格水彩画怎么画?
著名的水彩艺术家陈坚曾说:“水彩是用水润调和形成的饱和度极高的艺术画面,在纸上晕染的画面面积、强度等具有许多随意性,天空的颜色乌云密布,都是很随意的,难以模仿。” 是的,水彩画的妙处就在于不确定的…...

Python的类变量和对象变量声明解析
Python的类变量和对象变量声明解析 原文链接:https://www.cnblogs.com/bwangel23/p/4330268.html Python的类和C一样,也都是存在两种类型的变量,类变量和对象变量!前者由类拥有,被所有对象共享,后者由每个…...

#笨鸟先飞 猴博士电路笔记 第一篇 电路基础
第零课 基础知识串联与并联电源电势与电位差第一课 电阻电路的等效变换电压源串联电流源并联电压源和电流源串联电压源和电流源并联电压源转化为电流源电流源转化为电压源Δ-Y等效变换第二课 基尔霍夫定律基尔霍夫电流定律任一结点上流出电流之和等于流入电流之和。受控电流源&…...
快捷式~node.js环境搭建
1、安装包官网下载:Node.js (nodejs.org) 2、安装完成后修改环境变量 在上面已经完成了 node.js 的安装,即使不进行此步骤的环境变量配置也不影响node.js的使用 但是,若不进行环境变量配置,那么在使用命令安装 node.js全局模块 …...

ZooKeeper实现分布式队列、分布式锁和选举详解
提示:本文章非原创,记录一下优秀的干货。 [原创参考]:https://blog.csdn.net/qq_40378034/article/details/117014648 前言 ZooKeeper源码的zookeeper-recipes目录下提供了分布式队列、分布式锁和选举的实现GitHub地址。 本文主要对这几种实…...

【swift】swift quick start
一、常量和变量 常量let,变量var 也可以用于确定数组和字典的不可变和可变 二、数据类型: Int:整数类型,可表示有符号整数或无符号整数,分别使用Int和UInt表示。 Float:单精度浮点数类型,用于…...

浅谈volatile关键字
文章目录1.保证内存可见性2.可见性验证3.原子性验证4.原子性问题解决5.禁止指令重排序6.JMM谈谈你的理解6.1.基本概念6.2.JMM同步规定6.2.1.可见性6.2.2.原子性6.2.3.有序性6.3.Volatile针对指令重排做了啥7.你在哪些地方用过Volatile?volatile是Java提供的轻量级的…...
10 种 Spring事务失效场景
10 种 Spring事务失效场景 1.概述 Spring针对Java Transaction API (JTA)、JDBC、Hibernate和Java Persistence API(JPA)等事务 API,实现了一致的编程模型,而Spring的声明式事务功能更是提供了极其方便的事务配置方式,配合Spring Boot的自动…...

重读《DOOM启世录》
许多游戏开发者都是网瘾少年,抱着对游戏的热爱进入游戏行业,在经历996的加班加点,买房的压力,浮躁同样跟随着我们,我们是否还热爱着自己的事业,我们不是天才,也成不了卡马克,但是我们…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

30岁裸辞后,我用两个月拿下AI应用认证,现在OFFER选择困难症犯了
30岁裸辞那天,我最怕的不是没收入,而是突然发现:过去积累的经验,正在被AI重新定价。以前会写方案、做表格、跟项目,算是职场硬通货;到了2026年,招聘JD里开始频繁出现AI工具应用、智能工作流、Pr…...

番茄小说下载器终极指南:三步构建你的离线阅读自由王国
番茄小说下载器终极指南:三步构建你的离线阅读自由王国 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾在地铁里读到精彩章节时突然断网?是否在…...

微信小程序3D开发框架技术对比:XR-Frame与threejs-miniprogram
随着微信小程序逐步支持3D渲染与AR能力,开发者面临两个主要官方方案:自研的XR-Frame和适配Three.js的threejs-miniprogram。本文将从架构设计、渲染机制、功能集成、开发模式及适用场景等维度进行技术分析,为技术选型提供参考。一、XR-Frame&…...

Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题
Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款完全免费开源的…...
)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)第一次戴上Meta Quest 3时,那种虚拟与现实交织的震撼感至今难忘。但作为开发者,更让我着迷的是如何让虚拟物体在真实空间中"记住"…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...

为你的Hermes Agent自定义Provider,接入Taotoken多模型池
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的Hermes Agent自定义Provider,接入Taotoken多模型池 在构建复杂的AI应用时,开发者常常面临一个核心挑…...

3分钟掌握JetBrains IDE试用期重置:终极完整指南
3分钟掌握JetBrains IDE试用期重置:终极完整指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置工具(ide-eval-resetter)是一个开源项目,专…...

LoRa物联网与动态基线算法在养殖体温监测中的实战应用
1. 项目概述:为什么我们需要一个智能体温监测系统?在规模化养殖场里干了十几年,我见过太多因为体温异常没被及时发现而导致的损失。一头育肥猪突然不吃食,等饲养员第二天巡栏发现时,可能已经高烧好几天,继发…...