【深度学习实验】线性模型(二):使用NumPy实现线性模型:梯度下降法
目录
一、实验介绍
二、实验环境
1. 配置虚拟环境
2. 库版本介绍
三、实验内容
0. 导入库
1. 初始化参数
2. 线性模型 linear_model
3. 损失函数loss_function
4. 梯度计算函数compute_gradients
5. 梯度下降函数gradient_descent
6. 调用函数
一、实验介绍
使用NumPy实现线性模型:梯度下降法
二、实验环境
本系列实验使用了PyTorch深度学习框架,相关操作如下:
1. 配置虚拟环境
conda create -n DL python=3.7 conda activate DLpip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib conda install scikit-learn2. 库版本介绍
| 软件包 | 本实验版本 | 目前最新版 |
| matplotlib | 3.5.3 | 3.8.0 |
| numpy | 1.21.6 | 1.26.0 |
| python | 3.7.16 | |
| scikit-learn | 0.22.1 | 1.3.0 |
| torch | 1.8.1+cu102 | 2.0.1 |
| torchaudio | 0.8.1 | 2.0.2 |
| torchvision | 0.9.1+cu102 | 0.15.2 |
三、实验内容
ChatGPT:
线性模型梯度下降法是一种常用的优化算法,用于求解线性回归模型中的参数。它通过迭代的方式不断更新模型参数,使得模型在训练数据上的损失函数逐渐减小,从而达到优化模型的目的。
梯度下降法的基本思想是沿着损失函数梯度的反方向更新模型参数。在每次迭代中,根据当前的参数值计算损失函数的梯度,然后乘以一个学习率的因子,得到参数的更新量。学习率决定了参数更新的步长,过大的学习率可能导致错过最优解,而过小的学习率则会导致收敛速度过慢。
具体而言,对于线性回归模型,梯度下降法的步骤如下:
初始化模型参数,可以随机初始化或者使用一些启发式的方法。
循环迭代以下步骤,直到满足停止条件(如达到最大迭代次数或损失函数变化小于某个阈值):
a. 根据当前的参数值计算模型的预测值。
b. 计算损失函数关于参数的梯度,即对每个参数求偏导数。
c. 根据梯度和学习率更新参数值。
d. 计算新的损失函数值,并检查是否满足停止条件。
返回优化后的模型参数。
本实验中,
gradient_descent函数实现了梯度下降法的具体过程。它通过调用initialize_parameters函数初始化模型参数,然后在每次迭代中计算模型预测值、梯度以及更新参数值。
0. 导入库
import numpy as np1. 初始化参数
在梯度下降算法中,需要初始化待优化的参数,即权重 w 和偏置 b。可以使用随机初始化的方式。
def initialize_parameters():w = np.random.randn(5)b = np.random.randn(5)return w, b2. 线性模型 linear_model
def linear_model(x, w, b):output = np.dot(x, w) + breturn output3. 损失函数loss_function
该函数接受目标值y和模型预测值prediction,计算均方误差损失。
def loss_function(y, prediction):loss = (prediction - y) * (prediction - y)return loss4. 梯度计算函数compute_gradients
为了使用梯度下降算法,需要计算损失函数关于参数 w 和 b 的梯度。可以使用数值计算的方法来近似计算梯度。
def compute_gradients(x, y, w, b):h = 1e-6 # 微小的数值,用于近似计算梯度grad_w = (loss_function(y, linear_model(x, w + h, b)) - loss_function(y, linear_model(x, w - h, b))) / (2 * h)grad_b = (loss_function(y, linear_model(x, w, b + h)) - loss_function(y, linear_model(x, w, b - h))) / (2 * h)return grad_w, grad_b5. 梯度下降函数gradient_descent
根据梯度计算的结果更新参数 w 和 b,从而最小化损失函数。
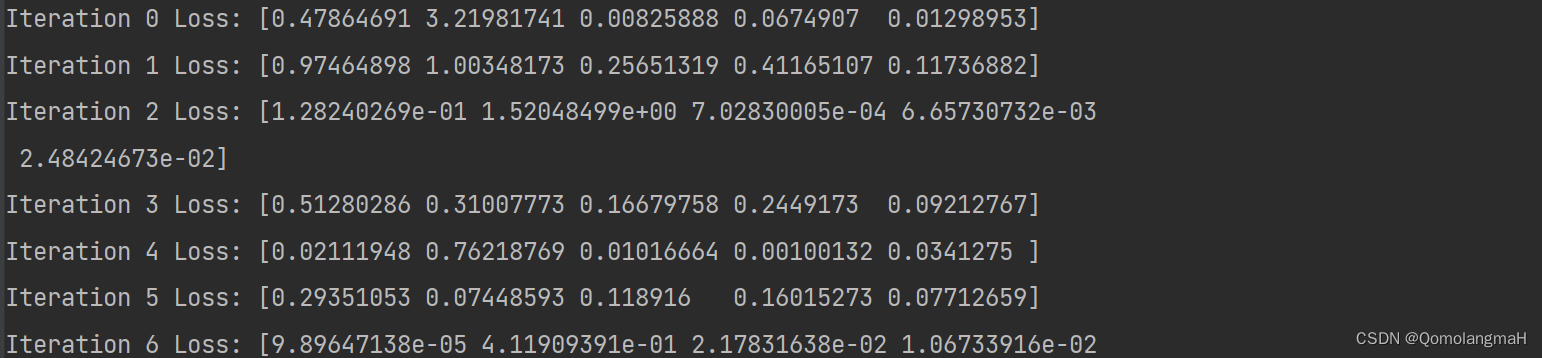
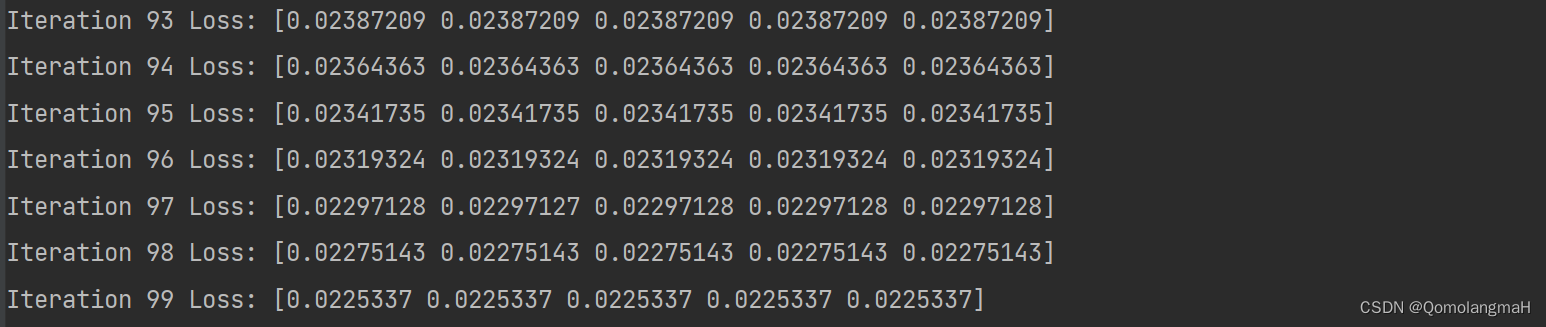
def gradient_descent(x, y, learning_rate, num_iterations):w, b = initialize_parameters()for i in range(num_iterations):prediction = linear_model(x, w, b)grad_w, grad_b = compute_gradients(x, y, w, b)w -= learning_rate * grad_wb -= learning_rate * grad_bloss = loss_function(y, prediction)print("Iteration", i, "Loss:", loss)return w, b6. 调用函数
执行梯度下降优化:调用 gradient_descent 函数并传入数据 x 和 y,设置学习率和迭代次数进行优化。
x = np.random.rand(5)
y = np.array([1, -1, 1, -1, 1]).astype('float')
learning_rate = 0.1
num_iterations = 100
w_optimized, b_optimized = gradient_descent(x, y, learning_rate, num_iterations)在上述代码中,每一次迭代都会打印出当前迭代次数和对应的损失值。通过不断更新参数 w 和 b,使得损失函数逐渐减小,达到最小化损失函数的目的。
希望这个详细解析能够帮助你优化代码并使用梯度下降算法最小化损失函数。如果还有其他问题,请随时提问!
相关文章:
【深度学习实验】线性模型(二):使用NumPy实现线性模型:梯度下降法
目录 一、实验介绍 二、实验环境 1. 配置虚拟环境 2. 库版本介绍 三、实验内容 0. 导入库 1. 初始化参数 2. 线性模型 linear_model 3. 损失函数loss_function 4. 梯度计算函数compute_gradients 5. 梯度下降函数gradient_descent 6. 调用函数 一、实验介绍 使用Nu…...

带你熟练使用list
🎈个人主页:🎈 :✨✨✨初阶牛✨✨✨ 🐻强烈推荐优质专栏: 🍔🍟🌯C的世界(持续更新中) 🐻推荐专栏1: 🍔🍟🌯C语言初阶 🐻推荐专栏2: 🍔…...
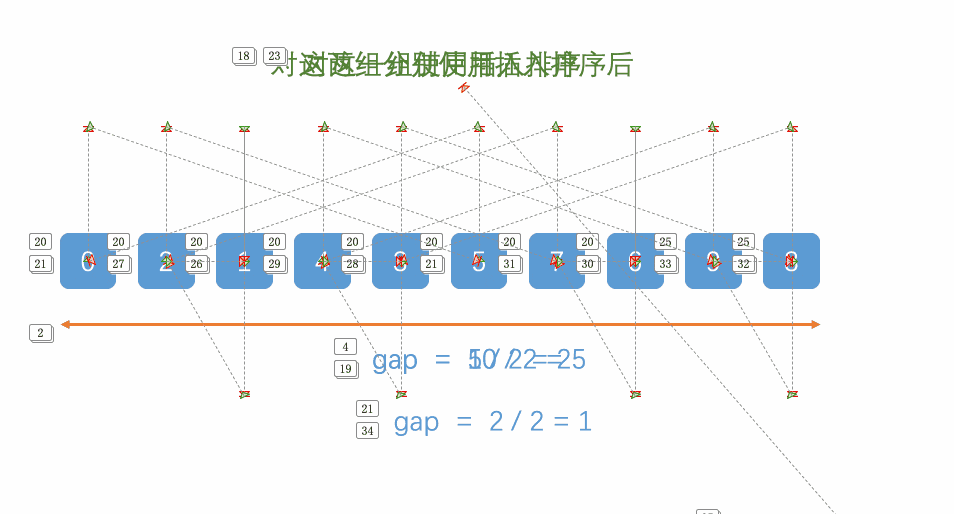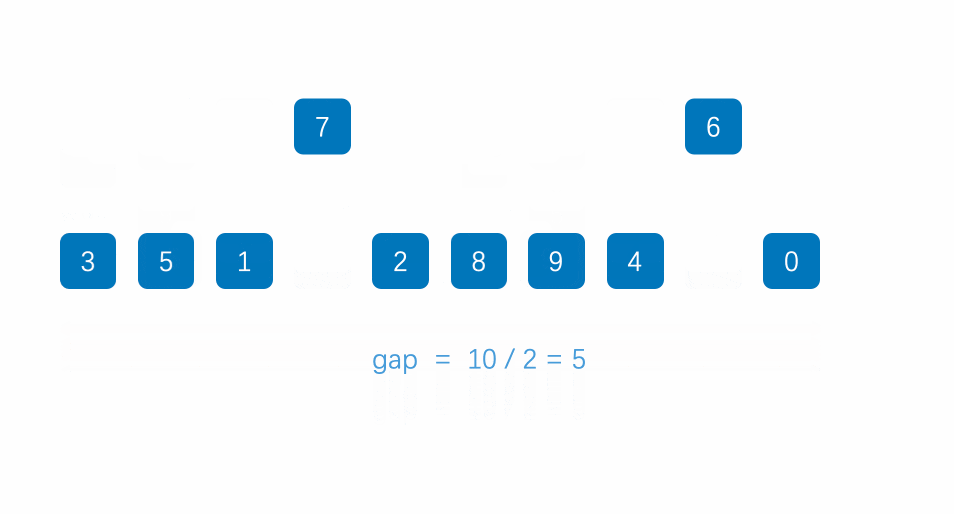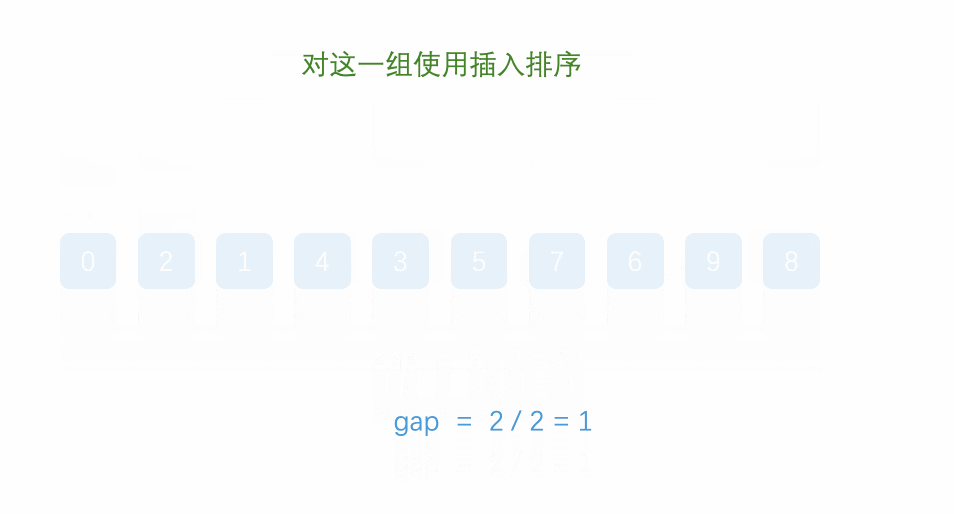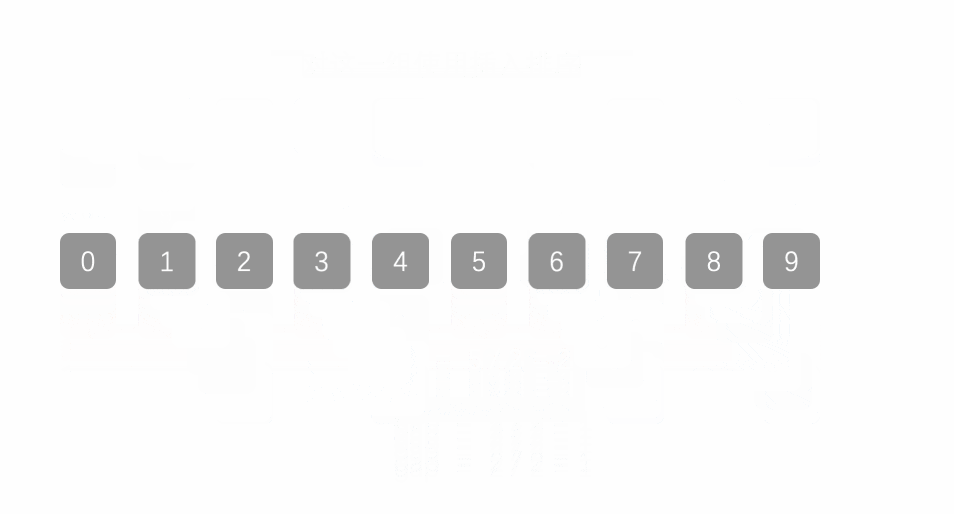
排序——希尔排序
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、希尔排序二、希尔排序动态图三、希尔排序程序代码四、希尔排序习题总结 前言 希尔排序定义希尔排序算法分析希尔排序程序代码希尔排序练习题 一、希尔排序…...
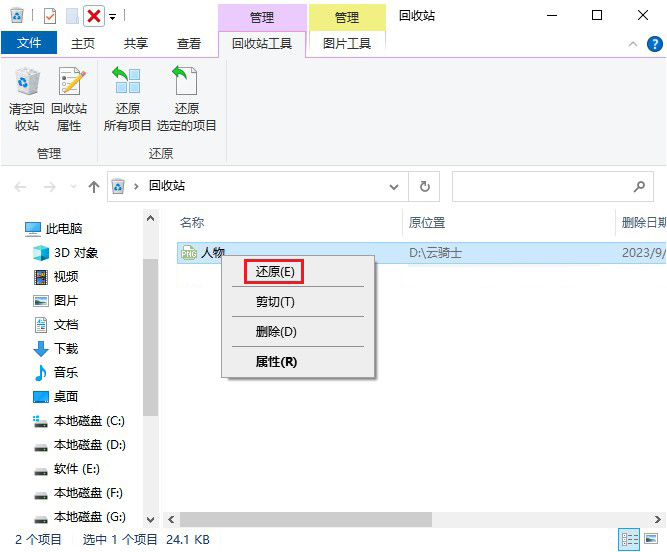
为什么文件夹里的文件看不到?了解原因及应对措施
无论是在个人电脑中还是在其他存储介质上,我们经常会遇到文件夹中的文件突然不可见的情况。这种问题给我们的工作和生活带来了不便,并可能导致数据丢失。本文将分析文件夹中文件看不见的原因,并介绍相应的解决方法,以帮助大家更好…...
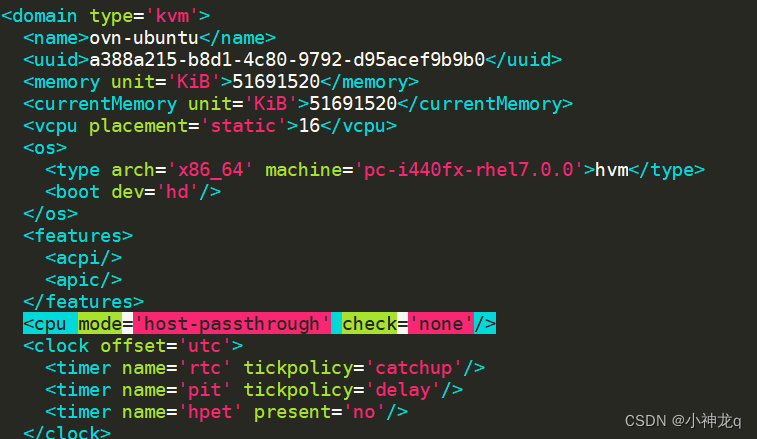
KVM嵌套虚拟化实现
KVM嵌套虚拟化实现 理论 Libvirt主要支持三种 CPU mode host-passthrough: libvirt 令 KVM 把宿主机的 CPU 指令集全部透传给虚拟机。因此虚拟机能够最大限度的使用宿主机 CPU 指令集,故性能是最好的。但是在热迁移时,它要求目的节点的 CPU 和源节点的…...
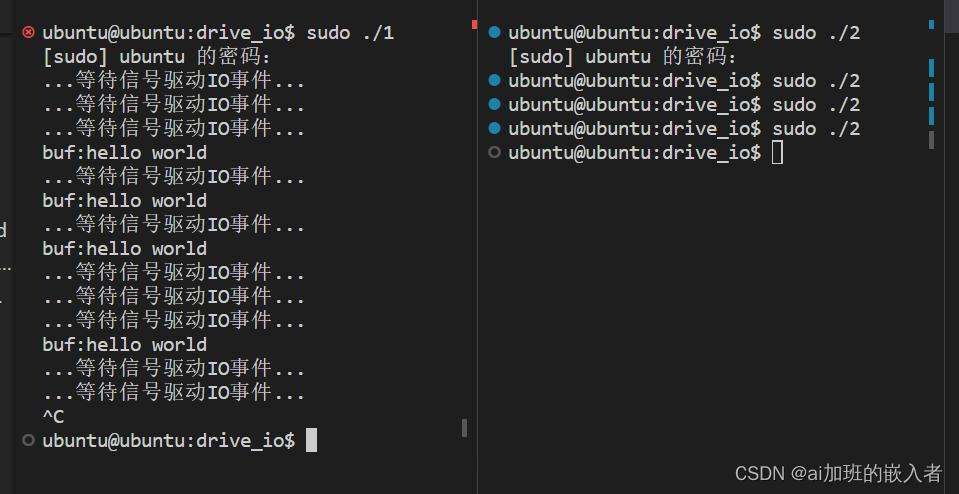
驱动开发,IO模型,信号驱动IO实现过程
1.信号驱动IO框架图 分析: 信号驱动IO是一种异步IO方式。linux预留了一个信号SIGIO用于进行信号驱动IO。进程主程序注册一个SIGIO信号的信号处理函数,当硬件数据准备就绪后会发起一个硬件中断,在中断的处理函数中向当前进程发送一个SIGIO信号…...

左神高级进阶班3(TreeMap顺序表记录线性数据的使用, 滑动窗口的使用,前缀和记录结构, 可能性的舍弃)
目录 【案例1】 【题目描述】 【思路解析】 【代码实现】 【案例2】 【题目描述】 【思路解析】 【代码实现】 【案例3】 【题目描述】 【思路解析】 【代码实现】 【案例4】 【题目描述】 【思路解析】 【代码实现】 【案例1】 【题目描述】 【思路解析】 这里…...

Linux线程
1.进程是资源管理的最小单位,线程是程序执行的最小单位。 2.每个进程有自己的数据段、代码段和堆栈段。线程通常叫做轻型的进程,它包含独立的栈和CPU寄存器状态,线程是进程的一条执行路径,每个线程共享其所附属进程的所有资源,包括…...

C++ 太卷,转 Java?
最近看到知乎、牛客等论坛上关于 C 很多帖子,比如: 2023年大量劝入C 2023年还建议走C方向吗? 看了一圈,基本上都是说 C 这个领域唯一共同点就是都使用 C 语言,其它几乎没有相关性。 的确是这样,比如量化交…...

《Java并发编程实战》第2章-线程安全性
0.概念理解 对象状态:存储在状态变量(例如实例或静态域)中的数据; 线程安全性:当多个线程访问某个类时,这个类始终都能表现出正确的行为,那么就称这个类是线程安全的; 竞态条件&…...

二蛋赠书三期:《C#入门经典(第9版)》
文章目录 前言活动规则参与方式本期赠送书籍介绍作者介绍内容简介读者对象获奖名单 结语 前言 大家好!我是二蛋,一个热爱技术、乐于分享的工程师。在过去的几年里,我一直通过各种渠道与大家分享技术知识和经验。我深知,每一位技术…...

Augmented Large Language Models with Parametric Knowledge Guiding
本文是LLM系列文章,针对《Augmented Large Language Models with Parametric Knowledge Guiding》的翻译。 参数知识引导下的增强大型语言模型 摘要1 引言2 相关工作3 LLM的参数化知识引导4 实验5 结论 摘要 大型语言模型(LLM)凭借其令人印…...
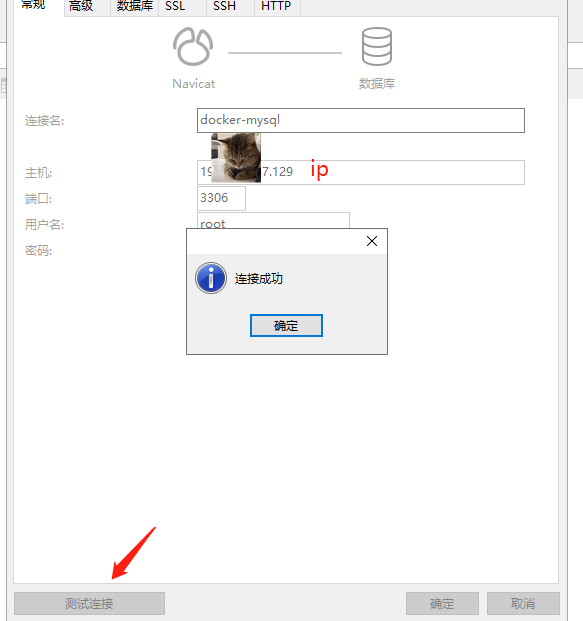
Docker启动Mysql容器并进行目录挂载
一、创建挂载目录 mkdir -p 当前层级下创建 mkdir -p mysql/data mkdir -p mysql/conf 进入到conf目录下创建配置文件touch hym.conf 并把配置文件hmy.conf下增加以下内容使用vim hym.conf即可添加(cv进去就行) Esc :wq 保存 [mysqld] skip-name-resolve character_set_…...
力扣刷题(简单篇):两数之和、两数相加、无重复字符的最长子串
坚持就是胜利 一、两数之和 题目链接:https://leetcode.cn/problems/two-sum/ 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应…...

Spark的基础
实训笔记--Spark的基础 Spark的基础一、Spark的诞生背景二、Spark概念2.1 Spark Core2.2. Spark SQL2.3 Spark Streaming2.4 Spark MLlib2.5 Spark GraphX2.6 Spark R 三、Spark的特点3.1 计算快速3.2 易用性3.3 兼容性3.4 通用性 四、Spark的安装部署4.1 Spark的安装部署就是安…...
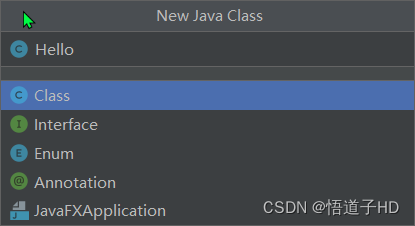
如何在idea中新建第一个java小程序
如何在idea中新建第一个java小程序 1.打开软件2.新建项目3.找到安装的jdk文件路径4.继续下一步5.创建项目名称并配置项目路径6.点击完成即可。7.在项目文件的src文件夹下创建java类,程序等7.1其他java项目或文件不能运行的原因: 8.新建类并运行程序9.输入…...

AOP全局异常处理
AOP全局异常处理 由于Controller可能接收到来自业务层、数据层、数据库抛出的异常,因此需要使用AOP思想,进行全局异常处理,异常可通过调试获得。 package org.sinian.reggie.common;import lombok.extern.slf4j.Slf4j; import org.springfram…...
一阶低通滤波器滞后补偿算法
一阶低通滤波器的推导过程和双线性变换算法请查看下面文章链接: PLC算法系列之数字低通滤波器(离散化方法:双线性变换)_双线性离散化_RXXW_Dor的博客-CSDN博客PLC信号处理系列之一阶低通(RC)滤波器算法_RXXW_Dor的博客-CSDN博客_rc滤波电路的优缺点1、先看看RC滤波的优缺点…...

JS中Symbol的介绍
1、 引入Symbol类型的背景 ES5 的对象属性名都是字符串,这容易造成属性名冲突的问题 举例: 使用别人的模块/对象, 又想为之添加新的属性,这就容易使得新属性名与原有属性名冲突 2、Symbol类型简介 symbol是一种原始数据类型 其余原始类型: 未定义(undefined) 、…...

封装统一响应结果类和消息枚举类
在开发中,响应结果都需要统一格式,下面给出一个例子,可自行修改。 package com.lili.utils;import com.fasterxml.jackson.annotation.JsonInclude; import com.lili.enums.AppHttpCodeEnum;import java.io.Serializable;/*** author YLi_Ji…...

深圳市2026年打造人工智能先锋城市项目扶持计划申请指南
本项目扶持计划下设十个项目类别,均采用事后奖补类支持方式。1、申报单位需同时满足基础申报条件和专项申报条件。基础申报条件如下:(一)申报单位为在深圳市内(含深汕特别合作区)从事生产经营活动ÿ…...

TortoiseSvn与TortoiseGit:从零开始的安装与汉化实战指南
1. TortoiseSvn与TortoiseGit:版本控制界的"瑞士军刀" 第一次接触代码版本管理时,我完全被命令行劝退了。直到发现了TortoiseSvn和TortoiseGit这两个神器——它们就像给Windows资源管理器装上了版本控制的"外挂",所有操作…...

Void-Memory:内存与持久化的平衡术,构建高性能本地缓存与状态存储
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫G3sparky/void-memory。乍一看这个标题,可能会让人有点摸不着头脑——“虚空记忆”?这听起来更像是一个哲学概念或者游戏里的技能名。但作为一个在技术圈摸爬滚打多年的老手&#x…...

XHS-Downloader:一款完全免费的小红书内容采集神器
XHS-Downloader:一款完全免费的小红书内容采集神器 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&#x…...

别再混淆了!给数据科学新手的平稳性、自相关性核心概念白话图解
时间序列分析入门:用生活化类比理解平稳性与自相关性 刚接触时间序列分析时,你是否曾被"平稳性"和"自相关性"这些术语搞得一头雾水?就像第一次学游泳时,教练说的"打腿节奏"和"换气时机"一…...

【初阶数据结构】 左右逢源的分支诗律 二叉树1
📖 点击展开/收起 文章目录 文章目录树的概念***树的基础概念***森林树和森林的存储二叉树二叉树的性质二叉树的遍历二叉树的前序遍历二叉树的中序遍历二叉树的后序遍历希望读者们多多三连支持小编会继续更新你们的鼓励就是我前进的动力!树的概念 在讲解…...

基于AI编程前沿技术,主题为变形金刚:手脑协同 + 触发指令 + AI大数据落地系统,目前落地解决方案
变形金刚:手脑协同 + 触发指令 + AI大数据落地系统 一、系统架构总览 这个变形金刚系统以“多重控制融合”为核心,将手/脑/语音三条控制通道汇聚到同一个AI大脑,实现对人形机器人/机械结构的实时操控: ┌───────────────────────────────…...

AiP8F7201单芯片电机驱动方案:从硬件设计到FOC算法实战
1. 项目概述:当MCU遇上三相全桥,一颗芯片的“跨界”革命最近在做一个无刷电机驱动的小项目,选型时发现了一个挺有意思的芯片——AiP8F7201。这玩意儿严格来说不能算传统意义上的“微控制器”,它更像是一个自带“大脑”和“强健四肢…...

5分钟快速上手GSE:魔兽世界智能技能循环终极指南
5分钟快速上手GSE:魔兽世界智能技能循环终极指南 【免费下载链接】GSE-Advanced-Macro-Compiler GSE is an alternative advanced macro editor and engine for World of Warcraft. 项目地址: https://gitcode.com/gh_mirrors/gs/GSE-Advanced-Macro-Compiler …...
)
YOLOv5实战:如何一键导出检测框的坐标、类别和置信度到TXT文件(附完整代码)
YOLOv5实战:结构化导出检测结果的工程化解决方案 在计算机视觉项目的实际落地过程中,我们常常需要将模型检测结果以结构化形式保存,用于后续的数据分析、系统集成或模型评估。本文将深入探讨如何通过YOLOv5高效导出检测框的坐标、类别和置信度…...