BIT-4-数组
- 一维数组的创建和初始化
- 一维数组的使用
- 一维数组在内存中的存储
- 二维数组的创建和初始化
- 二维数组的使用
- 二维数组在内存中的存储
- 数组越界
- 数组作为函数参数
- 数组的应用实例1:三子棋
- 数组的应用实例2:扫雷游戏
1. 一维数组的创建和初始化
1.1 数组的创建
数组是一组相同类型元素的集合。
数组的创建方式:
type_t arr_name [const_n];
//type_t 是指数组的元素类型
//const_n 是一个常量表达式,用来指定数组的大小数组创建的实例:
//代码1
int arr1[10];//代码2
int count = 10;
int arr2[count];//数组时候可以正常创建?//代码3
char arr3[10];
float arr4[1];
double arr5[20];注:数组创建,在C99标准之前, [ ] 中要给一个常量才可以,不能使用变量。在C99标准支持了变长数组的概念,数组的大小可以使用变量指定,但是数组不能初始化。
1.2 数组的初始化
数组的初始化是指,在创建数组的同时给数组的内容一些合理初始值(初始化)。
看代码:
int arr1[10] = {1,2,3};
int arr2[] = {1,2,3,4};
int arr3[5] = {1,2,3,4,5};
char arr4[3] = {'a',98, 'c'};
char arr5[] = {'a','b','c'};
char arr6[] = "abcdef";数组在创建的时候如果想不指定数组的确定的大小就得初始化。数组的元素个数根据初始化的内容来确定。
但是对于下面的代码要区分,内存中如何分配。
char arr1[] = "abc";
char arr2[3] = {'a','b','c'};1.3 一维数组的使用
对于数组的使用我们之前介绍了一个操作符: [ ] ,下标引用操作符。它其实就数组访问的操作符。我们来看代码:
#include <stdio.h>
int main()
{int arr[10] = {0};//数组的不完全初始化//计算数组的元素个数int sz = sizeof(arr)/sizeof(arr[0]);//对数组内容赋值,数组是使用下标来访问的,下标从0开始。所以:int i = 0;//做下标for(i=0; i<10; i++)//这里写10,好不好?{arr[i] = i;}//输出数组的内容for(i=0; i<10; ++i){printf("%d ", arr[i]);}return 0;
}总结:
- 数组是使用下标来访问的,下标是从0开始。
- 数组的大小可以通过计算得到。
int arr[10];
int sz = sizeof(arr)/sizeof(arr[0]);1.4 一维数组在内存中的存储
接下来我们探讨数组在内存中的存储。
看代码:
#include <stdio.h>int main()
{int arr[10] = {0};int i = 0;int sz = sizeof(arr)/sizeof(arr[0]);for(i=0; i<sz; ++i){printf("&arr[%d] = %p\n", i, &arr[i]);}return 0;
}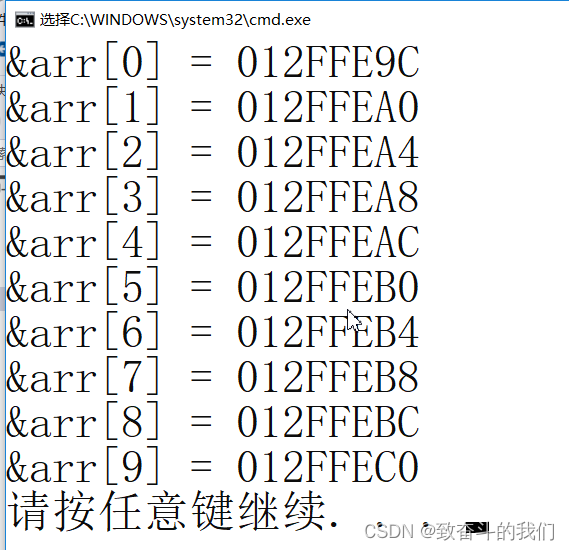
仔细观察输出的结果,我们知道,随着数组下标的增长,元素的地址,也在有规律的递增。
由此可以得出结论:数组在内存中是连续存放的。

2. 二维数组的创建和初始化
2.1 二维数组的创建
//数组创建
int arr[3][4];
char arr[3][5];
double arr[2][4];2.2 二维数组的初始化
//数组初始化
int arr[3][4] = {1,2,3,4};
int arr[3][4] = {{1,2},{4,5}};
int arr[][4] = {{2,3},{4,5}};//二维数组如果有初始化,行可以省略,列不能省略2.3 二维数组的使用
二维数组的使用也是通过下标的方式。
看代码:
#include <stdio.h>int main()
{int arr[3][4] = {0};int i = 0;for(i=0; i<3; i++){int j = 0;for(j=0; j<4; j++){arr[i][j] = i*4+j;}}for(i=0; i<3; i++){int j = 0;for(j=0; j<4; j++){printf("%d ", arr[i][j]);}}return 0;
}2.4 二维数组在内存中的存储
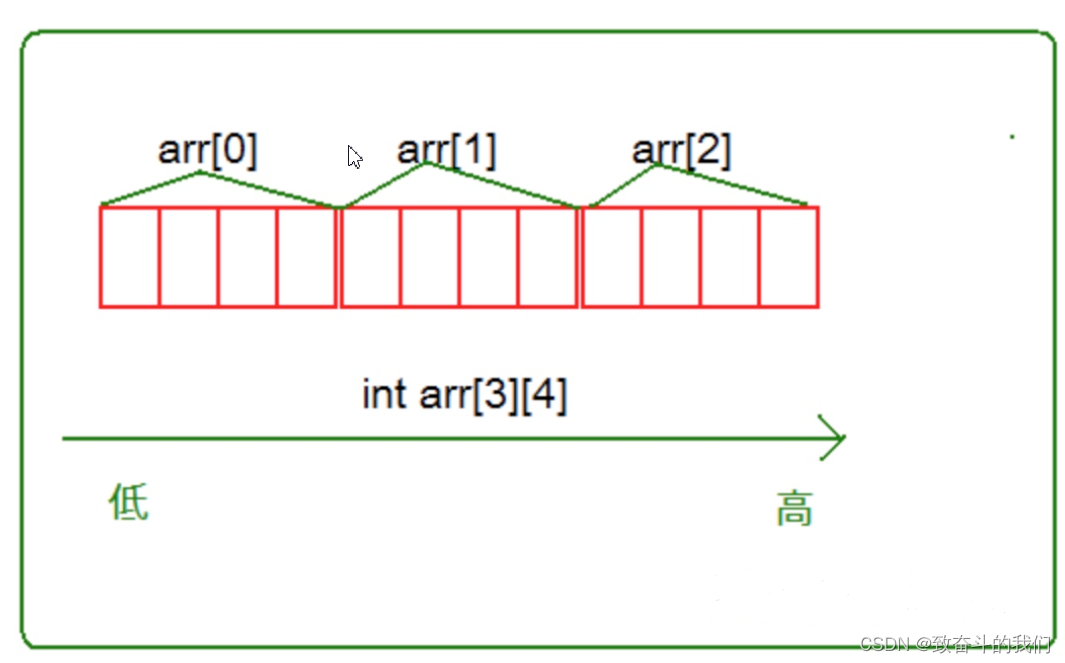
像一维数组一样,这里我们尝试打印二维数组的每个元素。
#include <stdio.h>int main()
{int arr[3][4];int i = 0;for(i=0; i<3; i++){int j = 0;for(j=0; j<4; j++){printf("&arr[%d][%d] = %p\n", i, j,&arr[i][j]);}}return 0;
}
通过结果我们可以分析到,其实二维数组在内存中也是连续存储的。
3. 数组越界
数组的下标是有范围限制的。
数组的下规定是从0开始的,如果数组有n个元素,最后一个元素的下标就是n-1。
所以数组的下标如果小于0,或者大于n-1,就是数组越界访问了,超出了数组合法空间的访问。
C语言本身是不做数组下标的越界检查,编译器也不一定报错,但是编译器不报错,并不意味着程
序就是正确的,所以程序员写代码时,最好自己做越界的检查。
#include <stdio.h>int main()
{int arr[10] = {1,2,3,4,5,6,7,8,9,10};int i = 0;for(i=0; i<=10; i++){printf("%d\n", arr[i]);//当i等于10的时候,越界访问了}return 0;
}二维数组的行和列也可能存在越界。
4. 数组作为函数参数
往往我们在写代码的时候,会将数组作为参数传个函数,比如:我要实现一个冒泡排序(这里要讲算法思想)函数将一个整形数组排序。
那我们将会这样使用该函数:
4.1 冒泡排序函数的错误设计
//方法1:
#include <stdio.h>
void bubble_sort(int arr[])
{int sz = sizeof(arr)/sizeof(arr[0]);//这样对吗?int i = 0;for(i=0; i<sz-1; i++){int j = 0;for(j=0; j<sz-i-1; j++){if(arr[j] > arr[j+1]){int tmp = arr[j];arr[j] = arr[j+1];arr[j+1] = tmp;}}}
}int main()
{int arr[] = {3,1,7,5,8,9,0,2,4,6};bubble_sort(arr);//是否可以正常排序?for(i=0; i<sizeof(arr)/sizeof(arr[0]); i++){printf("%d ", arr[i]);}return 0;
}方法1,出问题,那我们找一下问题,调试之后可以看到 bubble_sort 函数内部的 sz ,是1。
难道数组作为函数参数的时候,不是把整个数组的传递过去?
4.2 数组名是什么?
#include <stdio.h>int main()
{int arr[10] = {1,2,3,4,5};printf("%p\n", arr);printf("%p\n", &arr[0]);printf("%d\n", *arr);//输出结果return 0;
}结论:
数组名是数组首元素的地址。(有两个例外)
如果数组名是首元素地址,那么:
int arr[10] = {0};
printf("%d\n", sizeof(arr));为什么输出的结果是:40?
补充:
1. sizeof(数组名),计算整个数组的大小,sizeof内部单独放一个数组名,数组名表示整个数 组。
2. &数组名,取出的是数组的地址。&数组名,数组名表示整个数组。
除此1,2两种情况之外,所有的数组名都表示数组首元素的地址。
4.3 冒泡排序函数的正确设计
当数组传参的时候,实际上只是把数组的首元素的地址传递过去了。
所以即使在函数参数部分写成数组的形式: int arr[] 表示的依然是一个指针: int *arr 。
那么,函数内部的 sizeof(arr) 结果是4。
如果 方法1 错了,该怎么设计?
//方法2
void bubble_sort(int arr[], int sz)//参数接收数组元素个数
{//代码同上面函数
}
int main()
{int arr[] = {3,1,7,5,8,9,0,2,4,6};int sz = sizeof(arr)/sizeof(arr[0]);bubble_sort(arr, sz);//是否可以正常排序?for(i=0; i<sz; i++){printf("%d ", arr[i]);}return 0;
}5. 数据实例:
5.1 数组的应用实例1:三子棋
5.2 数组的应用实例2:扫雷游戏
因为篇幅有限,所以这两个数组的应用实例我会单独做两篇博客详细讲解。
相关文章:
BIT-4-数组
一维数组的创建和初始化一维数组的使用 一维数组在内存中的存储 二维数组的创建和初始化二维数组的使用二维数组在内存中的存储 数组越界数组作为函数参数数组的应用实例1:三子棋 数组的应用实例2:扫雷游戏 1. 一维数组的创建和初始化 1.1 数组的创建 …...
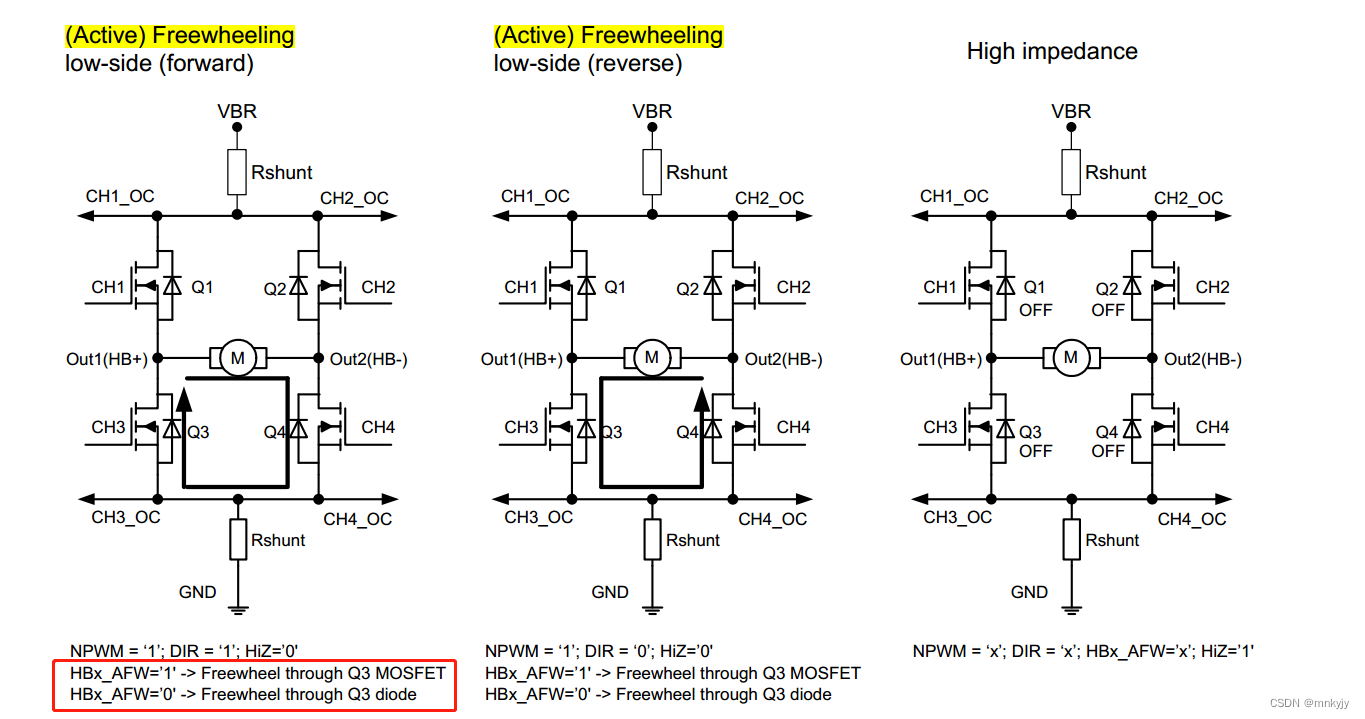
L9945的H桥续流模式
在H桥的配置中,包括两种续流模式:主动续流和被动续流。 一个L9945可输出两个H桥驱动。HB1在CMD3中配置,HB2在CMD7中配置。 主动续流:通过Q3的MOS的二极管来续流 被动续流:通过Q3外部的二极管来续流...
Ubuntu20.04安装Nvidia显卡驱动、CUDA11.3、CUDNN、TensorRT、Anaconda、ROS/ROS2
1.更换国内源 打开终端,输入指令: wget http://fishros.com/install -O fishros && . fishros 选择【5】更换系统源,后面还有一个要输入的选项,选择【0】退出,就会自动换源。 2.安装NVIDIA驱动 这一步最痛心…...

linux下使用crontab定时器,并且设置定时不执行的情况,附:项目启动遇到的一些问题和命令
打开终端,以root用户身份登录。 运行以下命令打开cron任务编辑器: crontab -e 如果首次编辑cron任务,会提示选择编辑器。选择你熟悉的编辑器,比如nano或vi,并打开相应的配置文件。 在编辑器中,添加一行类…...

linux下二进制安装docker最新版docker-24.0.6
一.基础环境 本次实操是公司技术培训下基于centos7.9操作系统安装docker最新版docker-24.0.6,下载地址是:https://download.docker.com/linux/static/stable/x86_64/docker-24.0.6.tgz 二. 下载Docker压缩包 mkdir -p /opt/docker-soft cd /opt/docker…...

计算机视觉 01(介绍)
一、深度学习 1.1 人工智能 1.2 人工智能,机器学习和深度学习的关系 机器学习是实现人工智能的一种途径,深度学习是机器学习的一个子集,也就是说深度学习是实现机器学习的一种方法。与机器学习算法的主要区别如下图所示[参考:黑…...

Java下部笔记
目录 一.双列集合 1.Map 2.Map的遍历方式 3.可变参数 4.Collection中的默认方法 5.不可变集合(map不会) 二.Stream流 1.获取stream流 2.中间方法 3.stream流的收集操作 4.方法引用 1.引用静态方法 2.引用成员方法 3.引用构造方法 4.使用类…...
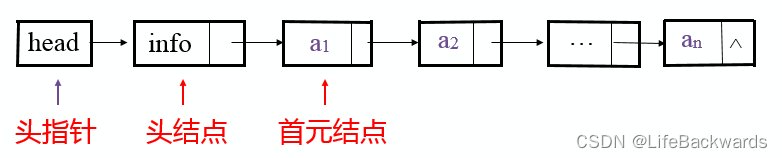
链表基本操作
单链表简介 单链表结构 头指针是指向链表中第一个结点的指针 首元结点是指链表中存储第一个数据元素a1的结点 头结点是在链表的首元结点之前附设的一个结点;数据域内只放空表标志和表长等信息 单链表存储结构定义: typedef struct Lnode { ElemTyp…...

Linux学习笔记-Ubuntu系统下配置用户ssh只能访问git仓库
目录 一、基本信息1.1 系统信息1.2 git版本[^1]1.2.1 服务器端git版本1.2.2 客户端TortoiseGit版本1.2.3 客户端Git for windows版本 二、创建git用户和群组[^2]2.1 使用groupadd创建群组2.2 创建git用户2.2.1 使用useradd创建git用户2.2.2 配置新建的git用户ssh免密访问 2.3 创…...

央媒发稿不能改?媒体发布新闻稿有哪些注意点
传媒如春雨,润物细无声,大家好,我是51媒体网胡老师。 “央媒发稿不能改”是媒体行业和新闻传播领域的普遍理解。央媒,即中央主要媒体,是权威性的新闻源,当这些媒体发布新闻稿或报道时,其他省、…...
计算机竞赛 深度学习 opencv python 公式识别(图像识别 机器视觉)
文章目录 0 前言1 课题说明2 效果展示3 具体实现4 关键代码实现5 算法综合效果6 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 基于深度学习的数学公式识别算法实现 该项目较为新颖,适合作为竞赛课题方向,学…...

KPM算法
概念 KMP(Knuth–Morris–Pratt)算法是一种字符串匹配算法,用于在一个主文本字符串中查找一个模式字符串的出现位置。KMP算法通过利用模式字符串中的重复性,避免无意义的字符比较,从而提高效率。 KMP算法的核心思想是…...
全流程GMS地下水数值模拟及溶质(包含反应性溶质)运移模拟技术教程
详情点击公众号链接:全流程GMS地下水数值模拟及溶质(包含反应性溶质)运移模拟技术教程 前言 GMS三维地质结构建模 GMS地下水流数值模拟 GMS溶质运移数值模拟与反应性溶质运移模 详情 1.GMS的建模数据的收集、数据预处理以及格式等ÿ…...

GE D20 EME 10BASE-T电源模块产品特点
GE D20 EME 10BASE-T 电源模块通常是工业自动化和控制系统中的一个关键组件,用于为系统中的各种设备和模块提供电源。以下是可能包括在 GE D20 EME 10BASE-T 电源模块中的一些产品特点: 电源输出:D20 EME 模块通常提供一个或多个电源输出通道…...
游戏工作时d3dcompiler_47.dll缺失怎么修复?5种修复方法分享
游戏提示 d3dcompiler_47.dll 缺失的困扰,相信许多玩家都遇到过。这种情况通常会导致游戏无法正常运行,给玩家带来很大的不便。那么,该如何解决这个问题呢?小编将为大家介绍几种解决方法,希望对大家有所帮助。 首先&am…...

关于激光探测器光斑质心算法在FPGA硬件的设计
目录 0引言 1CCD采集图像质心算法 2基于FPGA的图像质心算法 3仿真结果与分析 4结论 0引言 在一些姿态检测的实际应用中,需要在被测对象上安装激光探测器[1],利用CCD相机捕捉激光光斑来检测观测对象的实际情况,光斑图像质心坐标的提取是图…...

理清SpringBoot CURD处理逻辑、顺序
💗wei_shuo的个人主页 💫wei_shuo的学习社区 🌐Hello World ! 理清SpringBoot CURD处理逻辑、顺序 Controller(控制器): 控制器接收来自客户端的请求,并负责处理请求的路由和参数解析…...

缓存读写淘汰算法W-TinyLFU算法
在W-TinyLFU中,每个缓存项都会被赋予一个权重。这个权重可以表示缓存项的大小、使用频率、是否是热数据等因素。每次需要淘汰缓存时,W-TinyLFU会选择小于一定阈值的权重的缓存项进行淘汰,以避免淘汰热数据。 另外,W-TinyLFU也会根…...

C++中的 throw详解
在《C++异常处理》一节中,我们讲到了 C++ 异常处理的流程,具体为: 抛出(Throw)--> 检测(Try) --> 捕获(Catch) 异常必须显式地抛出,才能被检测和捕获到;如果没有显式的抛出,即使有异常也检测不到。在 C++ 中,我们使用 throw 关键字来显式地抛出异常,它的用…...

vue 封装Table组件
基于element-plus UI 框架封装一个table组件 在项目目录下的components新建一个Table.vue <template><section class"wrap"><el-tableref"table":data"tableData" v-loading"loading" style"width: 100%":…...

别再乱装驱动了!Ubuntu 20.04显卡驱动‘掉了’的终极排查与修复思路
Ubuntu 20.04显卡驱动失效的系统化诊断与修复指南 当你正专注于一个重要项目时,突然发现Ubuntu的NVIDIA显卡驱动"神秘消失"——这种体验对Linux用户来说简直像一场噩梦。nvidia-smi命令返回"驱动未加载",外接显示器黑屏,…...

AXI协议深度解析:从握手到低功耗,一次搞懂芯片内部数据流的那些“潜规则”
AXI协议深度解析:从握手到低功耗,一次搞懂芯片内部数据流的那些“潜规则” 在当今高性能计算和复杂SoC设计中,AXI协议已成为连接处理器、存储器和外设的黄金标准。但真正理解AXI的精髓,远不止于掌握基础操作——那些隐藏在规范字里…...

计算机视觉导航评估框架:从算法指标到用户体验的完整闭环
1. 项目概述:为什么我们需要一个“导航评估框架”?在计算机视觉辅助视障人士导航这个领域,我见过太多“实验室里的英雄”和“现实中的矮子”。一个算法在精心布置的走廊里识别障碍物准确率高达99.9%,但一到人潮涌动的火车站广场&a…...

混元图像3.0:多模态联合表征驱动的视觉逻辑引擎
1. 项目概述:这不是又一个“图生图”玩具,而是一次底层能力的重新定义“混元:发布图像3.0图生图模型,总参数量80亿”——这个标题里藏着三个被多数人忽略的关键信号:“图像3.0”不是版本号,是代际跃迁的命名…...

知识图谱与智能体如何革新小说创作:graphify-novel项目深度解析
1. 项目概述:用知识图谱为你的小说创作装上“第二大脑”如果你是一位小说创作者,无论是网文作者、传统文学写作者,还是游戏叙事设计师,你一定经历过这样的痛苦时刻:写到第30章,突然想不起某个配角在第5章出…...
—— 提前终止 + 参数共享 + 稀疏表示(三十))
深度学习正则化(三)—— 提前终止 + 参数共享 + 稀疏表示(三十)
1. 定位导航 正则化 5 篇中,本篇承前启后: 第 28:参数范数惩罚(L1/L2)— 加在损失函数上 第 29:数据增强、噪声、半监督 — 操作数据 第 30(本篇):提前终止、参数共享、稀疏表示 — 隐式正则化 第 31:Bagging + Dropout 第 32:对抗训练 + 切面分类 本篇的三个方法表…...

教育资源共享新范式:智能解析技术如何重塑教材获取体验
教育资源共享新范式:智能解析技术如何重塑教材获取体验 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内容。 项目地址…...

面试官追问LDA与PCA区别?用这张对比图+3个核心公式轻松讲明白
LDA与PCA本质区别:3个核心公式实战对比解析 当面试官要求你解释LDA和PCA的区别时,他们真正想考察的是什么?不是简单的概念复述,而是对两种降维技术底层逻辑的深刻理解。本文将用几何直觉、数学本质和代码实例,带你穿透…...

实战部署Funannotate基因组注释工具:3种高效配置方案指南
实战部署Funannotate基因组注释工具:3种高效配置方案指南 【免费下载链接】funannotate Eukaryotic Genome Annotation Pipeline 项目地址: https://gitcode.com/gh_mirrors/fu/funannotate Funannotate是一款专业的真核生物基因组注释工具,特别针…...

Qt 批量读取Excel数据:从性能瓶颈到优化实践
1. 为什么Qt读取Excel会卡成PPT? 第一次用Qt操作Excel表格时,我兴冲冲写了个循环读取单元格的代码。结果打开包含5000行数据的文件后,进度条像蜗牛爬坡,鼠标指针转成彩色圆圈,程序直接卡成PPT幻灯片模式——这场景估计…...