计算机竞赛 大数据商城人流数据分析与可视化 - python 大数据分析
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 基于大数据的基站数据分析与可视化
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:3分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
课题背景
- 随着当今个人手机终端的普及,出行群体中手机拥有率和使用率已达到相当高的比例,手机移动网络也基本实现了城乡空间区域的全覆盖。根据手机信号在真实地理空间上的覆盖情况,将手机用户时间序列的手机定位数据,映射至现实的地理空间位置,即可完整、客观地还原出手机用户的现实活动轨迹,从而挖掘得到人口空间分布与活动联系特征信息。移动通信网络的信号覆盖从逻辑上被设计成由若干六边形的基站小区相互邻接而构成的蜂窝网络面状服务区,手机终端总是与其中某一个基站小区保持联系,移动通信网络的控制中心会定期或不定期地主动或被动地记录每个手机终端时间序列的基站小区编号信息。
- 商圈是现代市场中企业市场活动的空间,最初是站在商品和服务提供者的产地角度提出,后来逐渐扩展到商圈同时也是商品和服务享用者的区域。商圈划分的目的之一是为了研究潜在的顾客的分布以制定适宜的商业对策。
分析方法与过程
初步分析:
- 手机用户在使用短信业务、通话业务、开关机、正常位置更新、周期位置更新和切入呼叫的时候均产生定位数据,定位数据记录手机用户所处基站的编号、时间和唯一标识用户的EMASI号等。历史定位数据描绘了用户的活动模式,一个基站覆盖的区域可等价于商圈,通过归纳经过基站覆盖范围的人口特征,识别出不同类别的基站范围,即可等同地识别出不同类别的商圈。衡量区域的人口特征可从人流量和人均停留时间的角度进行分析,所以在归纳基站特征时可针对这两个特点进行提取。
总体流程:
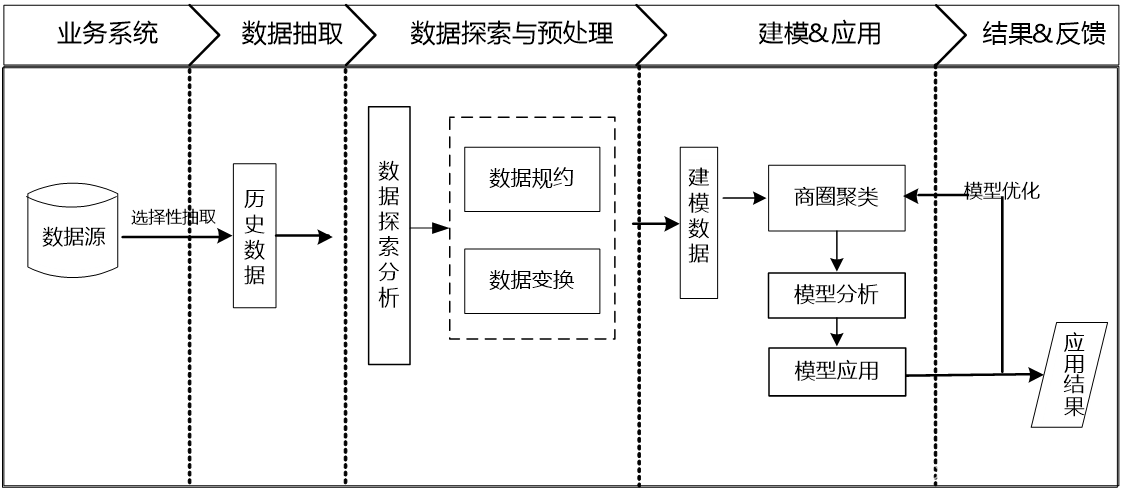
1.数据探索分析
EMASI号为55555的用户在2014年1月1日的定位数据

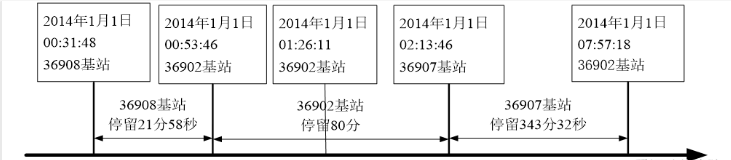
2.数据预处理
数据规约
- 网络类型、LOC编号和信令类型这三个属性对于挖掘目标没有用处,故剔除这三个冗余的属性。而衡量用户的停留时间并不需要精确到毫秒级,故可把毫秒这一属性删除。
- 把年、月和日合并记为日期,时、分和秒合并记为时间。
import numpy as np
import pandas as pd data=pd.read_excel(‘C://Python//DataAndCode//chapter14//demo//data//business_circle.xls’) # print(data.head()) #删除三个冗余属性
del data[[‘网络类型’,‘LOC编号’,‘信令类型’]]#合并年月日periods=pd.PeriodIndex(year=data['年'],month=data['月'],day=data['日'],freq='D')data['日期']=periodstime=pd.PeriodIndex(hour=data['时'],minutes=data['分'],seconds=data['秒'],freq='D')data['时间']=timedata['日期']=pd.to_datetime(data['日期'],format='%Y/%m/%d')data['时间']=pd.to_datetime(data['时间'],format='%H/%M/%S')数据变换
假设原始数据所有用户在观测窗口期间L( 天)曾经经过的基站有 N个,用户有 M个,用户 i在 j天在 num1 基站的工作日上班时间停留时间为
weekday_num1,在 num1 基站的凌晨停留时间为night_num1 ,在num1基站的周末停留时间为weekend_num1, 在
num1基站是否停留为 stay_num1 ,设计基站覆盖范围区域的人流特征:
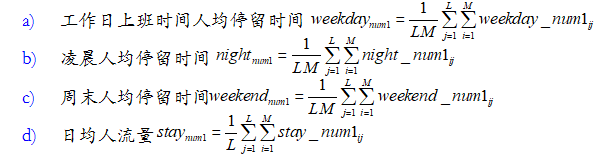

由于各个属性的之间的差异较大,为了消除数量级数据带来的影响,在进行聚类前,需要进行离差标准化处理。
#- _\- coding: utf-8 -_ - #数据标准化到[0,1] import pandas as pd #参数初始化
filename = ‘…/data/business_circle.xls’ #原始数据文件
standardizedfile = ‘…/tmp/standardized.xls’ #标准化后数据保存路径data = pd.read_excel(filename, index_col = u'基站编号') #读取数据data = (data - data.min())/(data.max() - data.min()) #离差标准化data = data.reset_index()data.to_excel(standardizedfile, index = False) #保存结果
3.构建模型
构建商圈聚类模型
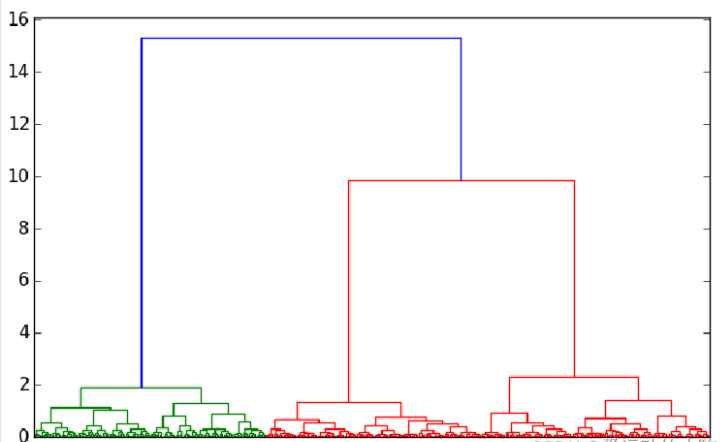
采用层次聚类算法对建模数据进行基于基站数据的商圈聚类,画出谱系聚类图。从图可见,可把聚类类别数取3类。
#- _\- coding: utf-8 -_ - #谱系聚类图
import pandas as pd #参数初始化
standardizedfile = ‘…/data/standardized.xls’ #标准化后的数据文件
data = pd.read_excel(standardizedfile, index_col = u’基站编号’) #读取数据```python
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import linkage,dendrogram
#这里使用scipy的层次聚类函数Z = linkage(data, method = 'ward', metric = 'euclidean') #谱系聚类图
P = dendrogram(Z, 0) #画谱系聚类图
plt.show()
```
模型分析
针对聚类结果按不同类别画出4个特征的折线图。
#- _\- coding: utf-8 -_ -
#层次聚类算法
import pandas as pd #参数初始化
standardizedfile = ‘…/data/standardized.xls’ #标准化后的数据文件
k = 3 #聚类数
data = pd.read_excel(standardizedfile, index_col = u’基站编号’) #读取数据from sklearn.cluster import AgglomerativeClustering #导入sklearn的层次聚类函数model = AgglomerativeClustering(n_clusters = k, linkage = 'ward')model.fit(data) #训练模型#详细输出原始数据及其类别r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) #详细输出每个样本对应的类别r.columns = list(data.columns) + [u'聚类类别'] #重命名表头import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号style = ['ro-', 'go-', 'bo-']xlabels = [u'工作日人均停留时间', u'凌晨人均停留时间', u'周末人均停留时间', u'日均人流量']pic_output = '../tmp/type_' #聚类图文件名前缀for i in range(k): #逐一作图,作出不同样式plt.figure()tmp = r[r[u'聚类类别'] == i].iloc[:,:4] #提取每一类for j in range(len(tmp)):plt.plot(range(1, 5), tmp.iloc[j], style[i])plt.xticks(range(1, 5), xlabels, rotation = 20) #坐标标签plt.title(u'商圈类别%s' %(i+1)) #我们计数习惯从1开始plt.subplots_adjust(bottom=0.15) #调整底部plt.savefig(u'%s%s.png' %(pic_output, i+1)) #保存图片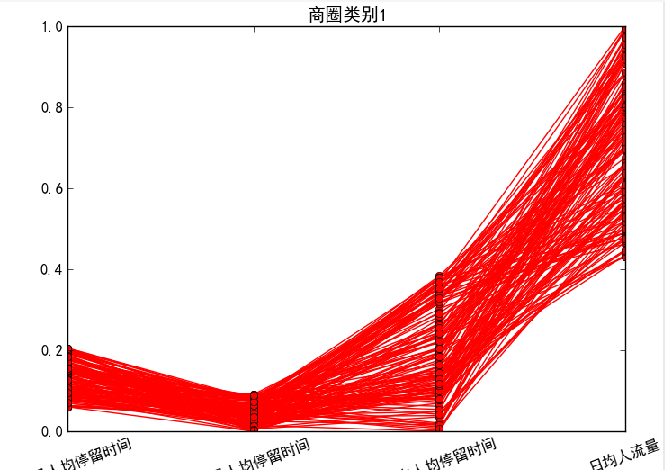
对于商圈类别1,日均人流量较大,同时工作日上班时间人均停留时间、凌晨人均停留时间和周末人均停留时间相对较短,该类别基站覆盖的区域类似于商业区

对于商圈类别2,凌晨人均停留时间和周末人均停留时间相对较长,而工作日上班时间人均停留时间较短,日均人流量较少,该类别基站覆盖的区域类似于住宅区。
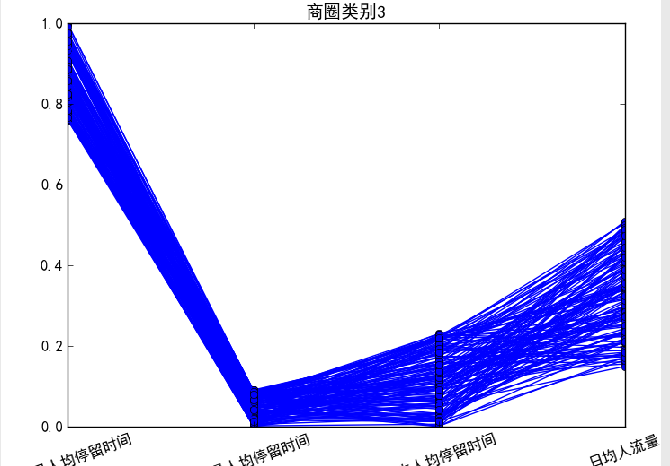
对于商圈类别3,这部分基站覆盖范围的工作日上班时间人均停留时间较长,同时凌晨人均停留时间、周末人均停留时间相对较短,该类别基站覆盖的区域类似于白领上班族的工作区域。
总结
商圈类别2的人流量较少,商圈类别3的人流量一般,而且白领上班族的工作区域一般的人员流动集中在上下班时间和午间吃饭时间,这两类商圈均不利于运营商的促销活动的开展,商圈类别1的人流量大,在这样的商业区有利于进行运营商的促销活动。
最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
计算机竞赛 大数据商城人流数据分析与可视化 - python 大数据分析
0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 基于大数据的基站数据分析与可视化 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🥇学长这里给一个题目综合评分(每项满分5分) 难度…...
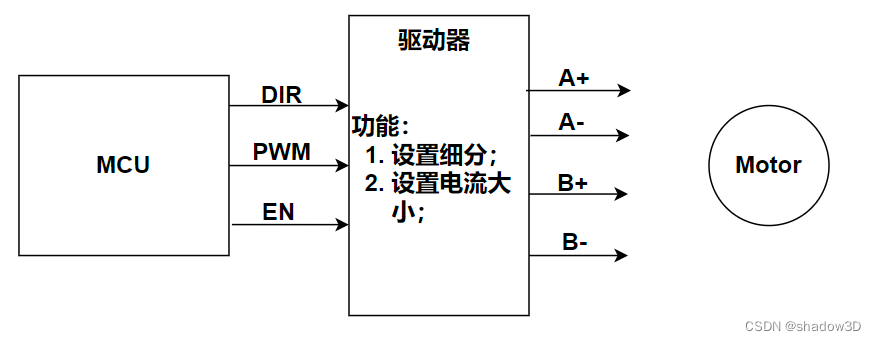
各种电机驱动原理
步进电机 步进电机参考资料 野火官方文档 步进电机驱动原理 上面参考文档中有的内容就不写了,写一下我自己的总结吧。 说明: 电机驱动器输入信号有电机转动方向信号DIR,电机转速信号PWM,电机使能信号EN;电机驱动器…...

人脸图像数据增强
为什么要做数据增强 在计算机视觉相关任务中,数据增强(Data Augmentation)是一种常用的技术,用于扩展训练数据集的多样性。它包括对原始图像进行一系列随机或有规律的变换,以生成新的训练样本。数据增强的主要目的是增…...

Android 查看按键信息的常用命令详解
Android 查看按键信息的常用命令详解 文章目录 Android 查看按键信息的常用命令详解一、主要命令:二、命令详解1、getevent2、getevent -l3、dumsys input4、cat XXX.kl4、cat /dev/input/eventX5、getevent 其他命令6、input keyevent XX 三、简单示例修改四、总结…...

【Java 基础篇】Properties 结合集合类的使用详解
Java 中的 Properties 类是一个常见的用于管理配置信息的工具,它可以被看作是一种键值对的集合。虽然 Properties 通常用于处理配置文件,但它实际上也可以作为通用的 Map 集合来使用。在本文中,我们将详细探讨如何使用 Properties 作为 Map 集…...

数字孪生体标准编程
数字孪生体标准 括ISO TC184/SC4正在制定数字孪生制造标准ISO 23247、ISO/IEC JTC1/AG11正在推动数字孪生体标准、IEEE P2806正在做有关“数字表达”的标准。赢家通吃的标准战 卡尔夏皮罗和哈尔范里安撰写了《信息规则:网络经济战略指南》(Information R…...

力扣 -- 394. 字符串解码
解题方法: 参考代码: class Solution{ public:string decodeString(string s){stack<string> sst;stack<int> dst;//防止字符串栈为空的时候再追加字符串到栈顶元素sst.push("");int n s.size();int i 0;while(i<n)//最好不…...

面试官:什么是虚拟DOM?如何实现一个虚拟DOM?说说你的思路
🎬 岸边的风:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 ⛺️ 生活的理想,就是为了理想的生活 ! 目录 一、什么是虚拟DOM 二、为什么需要虚拟DOM 三、如何实现虚拟DOM 小结 一、什么是虚拟DOM 虚拟 DOM (…...

Ubuntu安装中文拼音输入法
ubuntu安装中文拼音输入法 ubuntu版本为23.04 1、安装中文语言包 首先安装中文输入法必须要让系统支持中文语言,可以在 Language Support 中安装中文语言包。 添加或删除语音选项,添加中文简体,然后会有Applying changes的对话框&#x…...

高端知识竞赛中用到的软件和硬件有哪些
现在单位搞知识竞赛,已不满足于用PPT放题,找几个简单的抢答器、计分牌弄一下了,而是对现场效果和科技感要求更高了。大屏要分主屏侧屏,显示内容要求丰富炫酷;选手和评委也要用到平板等设备;计分要大气些&am…...

Vue 3.3 发布
本文为翻译 原文地址:宣布推出 Vue 3.3 |The Vue Point (vuejs.org) 今天我们很高兴地宣布 Vue 3.3 “Rurouni Kenshin” 的发布! 此版本侧重于开发人员体验改进 - 特别是 TypeScript 的 SFC <script setup> 使用。结合 Vue Language Tools&…...

算法|图论 3
LeetCode 130- 被围绕的区域 题目链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 题目描述:给你一个 m x n 的矩阵 board ,由若干字符 X 和 O ,找到所有被 X 围绕的区域,并将这些区域…...
【数据结构】二叉树的层序遍历(四)
目录 一,层序遍历概念 二,层序遍历的实现 1,层序遍历的实现思路 2,创建队列 Queue.h Queue.c 3,创建二叉树 BTree.h BTree.c 4,层序遍历的实现 一,层序遍历概念 层序遍历:除了先序…...
macOS文件差异比较最佳工具:Beyond Compare 4
Beyond Compare for mac是一款Scooter Software研发的文件同步对比工具。你可以选择针对多字节的文本、文件夹、源代码,甚至是支持比对adobe文件、pdf文件或是整个驱动器,检查其文件大小、名称、日期等信息。你也可以选择使用Beyond Compare合并两个不同…...
Windows+Pycharm 如何创建虚拟环境
当我们开发一个别人的项目的时候,因为项目里有很多特有的包,比如 Pyqt5.我们不想破坏电脑上原来的包版本,这个时候,新建一个虚拟环境,专门针对这个项目就很有必要了. 简略步骤: 1.新建虚拟环境 1.打开 pycharm 终端(Terminal)安装虚拟环境工具: pip install virtualenv2.创…...

vant 按需导入 vue2
vant 按需导入 vue2 1、通过npm安装 # Vue 3 项目,安装最新版 Vant: npm i vant -S# Vue 2 项目,安装 Vant 2: npm i vantlatest-v2 -S2、自动按需引入组件 babel-plugin-import 是一款 babel 插件,它会在编译过程中…...

Java手写分治算法和分治算法应用拓展案例
Java手写分治算法和分治算法应用拓展案例 1. 算法思维导图 以下是用Mermanid代码表示的分治算法的实现原理: #mermaid-svg-nvJwIm97kPHEXQOR {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-nvJwIm97kP…...

学习 CodeWhisperer 的一些总结
目前一些常见的的 AI 工具 GitHub Copilot:GitHub 与 OpenAI 合作开发的一个人工智能助手。 Codeium:是一个免费的人工智能驱动的代码生成工具 Tabnine:一个自动代码生成工具,免费版本非常有限,只提供简短的代码完成…...
JavaScript 中的 `this` 指向问题与其在加密中的应用
JS中的 this 关键字是一个非常重要的概念,它在不同情况下会指向不同的对象或值。在本文中,我们将深入探讨 JavaScript 中 this 的各种情况,并思考如何将其应用于 JS加密中的一些有趣用途。 1. 全局上下文中的 this 在全局上下文中ÿ…...

深入理解算法的时间复杂度
文章目录 时间复杂度的定义时间复杂度的分类时间复杂度分析常见数据结构和算法的时间复杂度常见数据结构常见算法 常见排序算法说明冒泡排序(Bubble Sort)快速排序(Quick Sort)归并排序(Merge Sort)堆排序(Heap Sort) 时间复杂度的定义 时间复杂度就是一种用来描述算法在输入规…...

[具身智能-680]:ROS2 可视化与调试工具与示例
按日常开发必用分类,每条可直接复制运行,新手也能马上上手。一、3D 可视化工具1. rviz2(核心 3D 可视化)功能查看:机器人模型、激光雷达、点云、地图、TF 坐标、导航路径、相机图像、机械臂、代价地图等。启动bash运行…...

uni-number-box深度解析:从基础属性到高级双向绑定实战
1. uni-number-box基础入门:从零开始玩转数字输入框 第一次接触uni-number-box时,我也觉得这不就是个简单的数字加减控件吗?直到在电商项目中真正用起来,才发现这个看似简单的组件藏着不少门道。uni-number-box是uni-app框架提供的…...
/瑞芯微刷机驱动(DriverAssitant)_多个版本下载及教程分享)
瑞芯微刷机工具(RKDevTool)/瑞芯微刷机驱动(DriverAssitant)_多个版本下载及教程分享
瑞芯微刷机工具(RKDevTool)/瑞芯微刷机驱动(DriverAssitant)_多个版本下载及教程分享 适合(处理器是RK字母开头的芯片),比如RK3128、RK3188、RK3229、RK3288、RK3368、RK3328、RK3399、RK3528、RK3568、RK3566、RK3588等等瑞芯微芯…...
)
别再手动折腾了!用Stack Builder一键搞定PostGIS 2.1 for PostgreSQL 9.2 (Windows 64位)
告别繁琐配置:用Stack Builder轻松部署PostGIS空间数据库 在Windows环境下配置PostgreSQL的空间扩展PostGIS,传统方式往往需要手动下载安装包、配置环境变量、执行SQL脚本等一系列操作。对于刚接触空间数据库的开发者来说,这个过程既耗时又容…...
)
告别马赛克!用MATLAB复刻复古报纸印刷的Bayer抖动算法(附完整代码)
用MATLAB重现复古报纸印刷:Bayer抖动算法的艺术与技术实践 老式报纸上的图片总带着一种独特的粗糙美感——那些由无数小黑点构成的图像,在纸张上呈现出微妙的灰度过渡。这种看似简单的印刷技术背后,隐藏着数字图像处理中一项经典算法…...

告别编译警告!MDK AC6编译器下STM32Cube FreeRTOS工程的__packed等语法适配指南
ARM Compiler v6下STM32Cube FreeRTOS工程的零警告优化实战 当你从ARM Compiler v5切换到v6时,可能会发现原本运行良好的STM32CubeMX生成的FreeRTOS工程突然冒出几十个编译警告。这些黄色的小三角虽然不会阻止程序编译,但对于追求代码质量的开发者来说&a…...

Cesium三维地形剖切与开挖:从原理到可复用组件封装
1. 为什么需要地形剖切与开挖功能? 在三维地理信息系统中,地形剖切与开挖是最常用的分析功能之一。想象一下,你正在规划一条地下隧道,或者需要分析某处地质构造,这时候如果能把地表"切开"查看内部情况&#…...

宇树GO2机器人ROS2控制:从零到自主导航的完整指南
宇树GO2机器人ROS2控制:从零到自主导航的完整指南 【免费下载链接】go2_ros2_sdk Unofficial ROS2 SDK support for Unitree GO2 AIR/PRO/EDU 项目地址: https://gitcode.com/gh_mirrors/go/go2_ros2_sdk Unitree GO2 ROS2 SDK是一个专门为宇树科技GO2系列机…...

OpenClaw 汉化版 Windows 一键安装指南|零基础 5 分钟部署 告别命令行
前言 在本地部署 AI 智能体时,英文界面晦涩、命令行操作复杂、环境配置繁琐,是很多零基础用户的三大痛点。OpenClaw 汉化中文版专为国内用户优化,采用全中文图形化界面 免环境配置 一键部署设计,全程无任何命令行操作ÿ…...

STM32CubeMX LL库定时器中断避坑指南:为什么你的中断不触发?
STM32CubeMX LL库定时器中断避坑指南:为什么你的中断不触发? 在嵌入式开发中,定时器中断是最基础也最常用的功能之一。然而,当开发者从标准库转向LL库(Low Layer Library)时,往往会遇到各种&quo…...