【学习笔记】多模态综述
多模态综述
- 前言
- 1. CLIP & ViLT
- 2. ALBEF
- 3. VLMO
- 4. BLIP
- 5. CoCa
- 6. BeiTv3
- 总结
- 参考链接
前言
本篇学习笔记虽然是多模态综述,本质上是对ViLT后多模态模型的总结,时间线为2021年至2022年,在这两年,多模态领域的模型也是卷的飞起,不断刷新领域的SOTA。在模型结构和数据上提出了很多高效有用的方法,如果你对多模态近两年的发展感兴趣,不妨看一看这一篇文章~
1. CLIP & ViLT
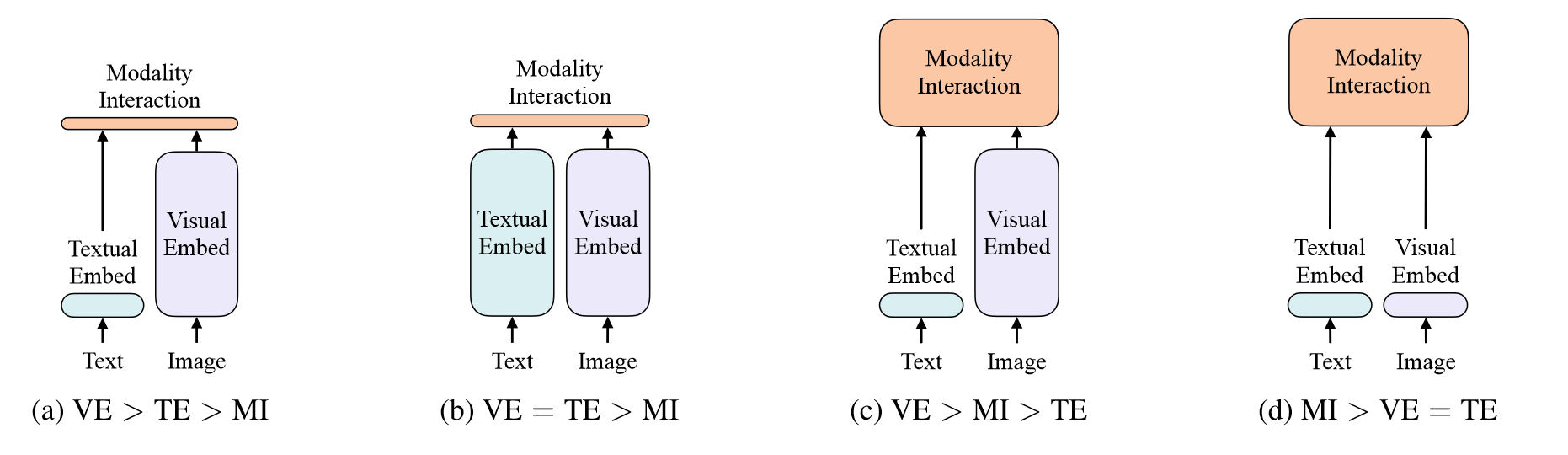
之所以将CLIP和ViLT放在一起,是因为在ViLT这篇论文中对这两项工作进行了很好的总结。从(a)到(d)是文图领域特征抽取模型的发展过程(到ViLT为止),其中(b)展示的就是CLIP的模型结构。它是一个典型的双塔模型,在训练时通过对比学习,将相同的图文对距离拉得很近,对于不同图文对的距离尽量拉得更远。抽取到的图文特征只需要进行简单的点乘就可以做很多多模态的任务。但是CLIP模态交互的部分过于简单,因此很难做复杂的理解任务。为此(c)中的方法在模态融合部分加入了复杂的模型,极大提升了效果。
在ViLT之前,几乎所有的工作都是目标检测的视觉抽取任务,由于都是提前抽取好特征缓存下来,研究人员并没有把过多的注意力放在计算复杂度和推理延迟上。显然在面对未见的下游任务场景时,视觉特征抽取部分的延迟是巨大的。因此ViLT应运而生,ViLT受到ViT的启发,ViT的工作证明了基于图像块的视觉特征和基于目标区域的视觉特征没有太大区别,也能很好拿来做目标检测任务。因此ViLT的作者将图像处理成图像块,和文本以相同的embedding形式输入到模态融合Transformer中,这大大降低了计算复杂度,并且对于下游任务来说,极大降低了推理延迟。
尽管如此,ViLT训练成本巨大,并且在性能上还是和(c)中的方法有一定的差距,可能的原因是在多模态中,视觉特征要远远大于文本特征,而ViLT中文本特征通过BERT的Tokenizer有很好的表征,但是视觉特征只是简单的随机初始化。
因此从结构上,一个好的多模态模型应该更接近于(c)的形式,视觉特征抽取模型要比文本特征抽取模型大,并且在模态融合上有更大的模型。对于训练目标,应该采用ITC+ITM+MLM方法的结合,即图文对比学习,图文匹配,完形填空,高效且性能出色。
2. ALBEF
ALBEF正是上面讨论的理想的多模态模型。ALBEF这篇工作来自于NeurIPS2021,与VILT出发的动机不同,ViLT只是为了提高模型的推理速度,而ALBEF的目的是在模型融合之前,就把图像和文本的特征align起来。具体来说,ALBEF有如下的贡献:
- 采用图文对比学习的方法提前将图文特征进行融合。
- 提出动量蒸馏方法解决噪声网络数据的问题。
对于第二个改进中提到的噪声网络数据,是指从网络中爬取的图文数据,文字内容大多都是关键词,而不是真正描述图像中的内容,因此成为了noisy的图文数据,导致模型很难学习到图文特征。
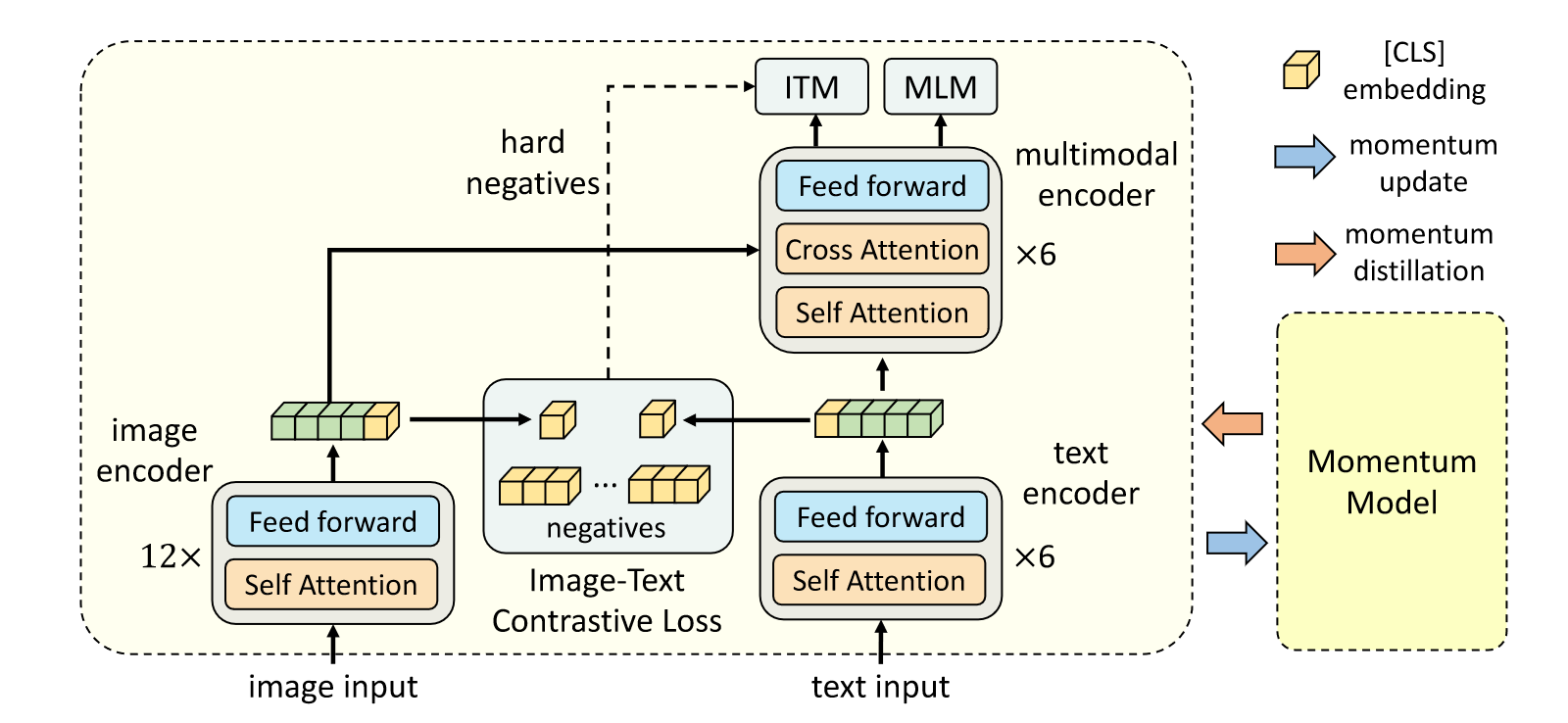
上图是ALBEF的整体模型架构。从简化模型的角度分析,左边是ViT,右边是劈成两半的BERT,前半部分输出和ViT的输出进行ITC的任务,后半部分对图文的特征进行融合。具体来说,图像这边打包成patch输入到ViT中,得到768维度的序列,文本这边转换为文本token序列喂入到6层的文本编码器中,输出768维的特征序列。接着图文token序列中的cls表征通过下采样和标准化降维到256维的特征,然后进行ITC的正负样本对比,让图像和文本的特征尽可能拉进,就完成了第一阶段的学习。
第二阶段,图像特征和文本特征共同输入到multimodal encoder中来实现模态的融合,通过ITM和MLM两个任务进行学习。ITM即图文匹配任务,判断当前的图片和文本是不是同一对,但是ITM任务过于简单,因此作者利用ITC任务中计算的余弦相似度,将最相似的样本作为负样本,来加大模型训练的难度,从而更好学习到特征的信息。MLM任务对输入的文本进行随机掩码,利用上下文和图像特征来预测mask的文本。这里也可以看出,虽然ITM和MLM画在一起,但是属于不同的前向过程,因此训练时间更长。
接着我们再探讨ALBEF另一个贡献点——动量蒸馏。由于预训练的图像对从互联网上收集,因此质量很差,图文经常不匹配。对于ITC学习,即使是负样本的文本也可能与图像匹配,对于MLM来说,可能存在更好的单词能够描述图像。但是ITC和MLM的one-hot标签仍然对这些结果进行惩罚,这会让模型的学习变得困难。作者提出采用动量模型生成的伪标签来帮助模型学习。训练时,作者训练基模型使其预测结果与动量模型的预测结果相匹配。具体来说,这个过程相当于为整个训练又额外添加了两个损失,即针对伪标签的ITC和MLM损失。

上图是伪标签和原始标签的对比,可以看到伪标签有时候更能有效捕获图像的相关信息。
预训练采用的数据集和ViLT一致,都是4million数据集。此外作者又额外加入了更多噪声的CC12million数据集,将性能进一步提高。
实验在五个不同任务的数据集上进行,首先是消融实验的结果:
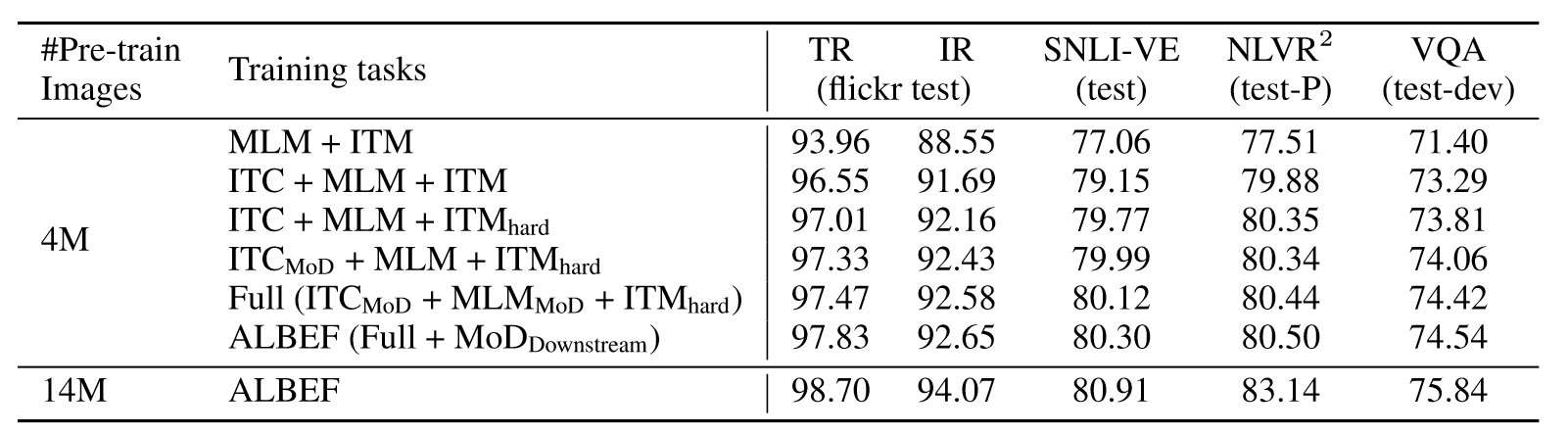
可以看到加入了ITC后,模型的性能有了大幅度的提升,表明融合之前的模态对齐是很有必要的。并且更难的ITM、额外的两个伪标签loss以及更大的训练数据集都对模型的性能有所提升。
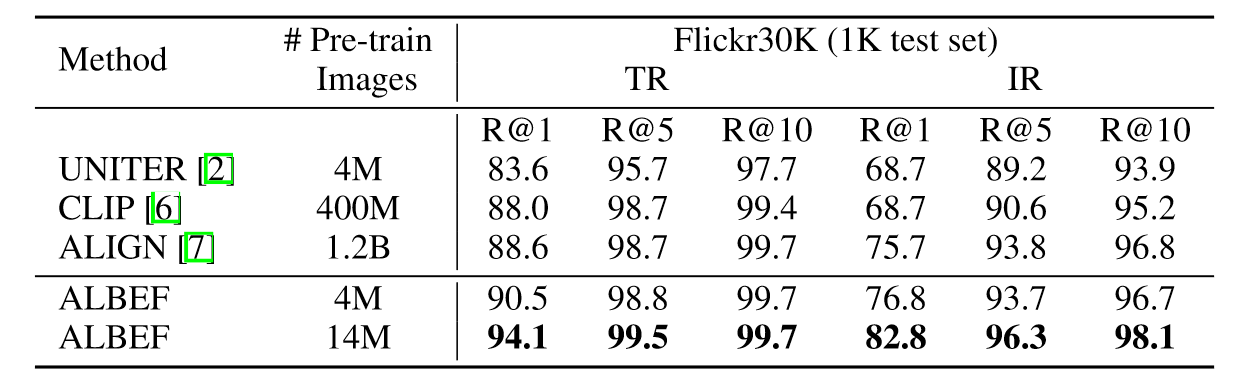
上表是在Flickr30K数据集上零样本的结果,ALBEF仅在4M数据集上预训练就超过了CLIP和ALIGN,二者都是在百倍大的规模数据集上进行预训练。微调结果也是同样的趋势:
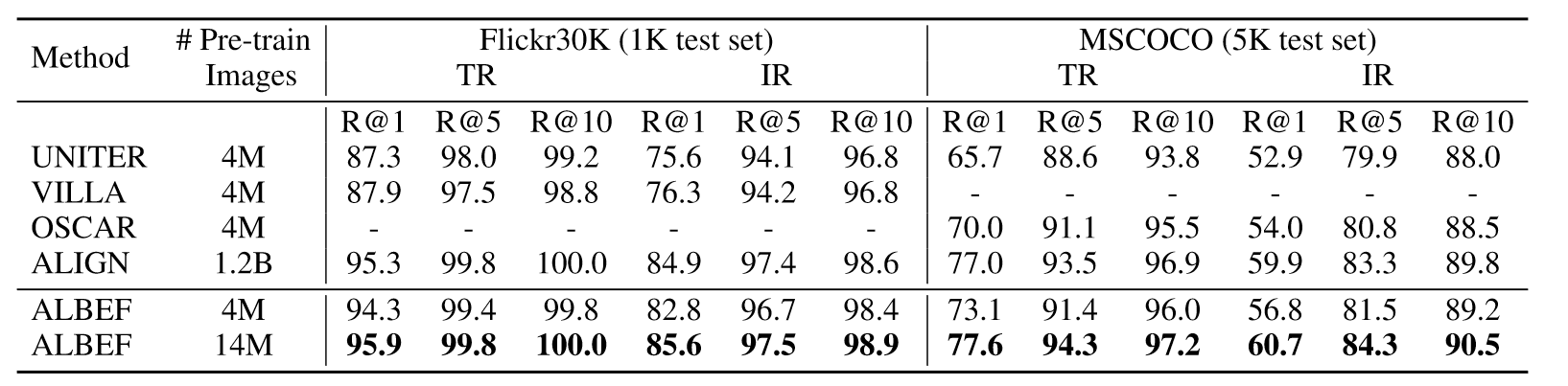
此外,在多个下游任务上与其他SOTA模型相比也是大幅领先。
文中作者还从互信息的角度对ALBEF进行了理论分析,表明不同的训练任务可以解释为生成图像文本对视图的不同方式,即数据增强。总而言之,ALBEF无论在训练速度,还是在推理速度,亦或是通用性和性能表现上都非常亮眼,属于多模态领域里程碑式的工作。
3. VLMO
VLMO这篇工作来自于微软团队,中稿于NeurIPS2022,它主要提出两个贡献点:
- 模型结构上的改进,Mixture-of-Modality-Experts。
- 训练方式的改进,采用分阶段的模型预训练。
这些贡献点的动机也很明确。对于第一个贡献点,当前的双塔模型架构应用广泛,如CLIP和ALIGN,它们采用双编码器架构,分别对文本和图像进行编码,模态交互通过图像和文本特征的余弦相似度实现的。这种方法虽然计算高效,可以提前存储特征信息,但是交互简单难以处理复杂的任务。另一种模型架构是跨模态注意力融合编码器,它可以在复杂的VL分类任务上实现卓越的性能,但是需要计算所有可能的图文对,以计算检索任务的相似度,导致推理时间过慢。
因此本文的VLMO相当于这两种模型的融合,既可以做双编码器也可以做融合编码器,它通过引入Multiway Transformer实现,该模型应用模态expert来取代标准Transformer中的前馈网络,对于不同模态的数据,切换不同的expert来捕获特定于模态的信息,并使用跨模态共享自注意力来对齐视觉和语言信息。
对于第二个贡献点,由于多模态领域常用的数据集仅有4million大小,远远不能满足大规模预训练的要求,但是在单独的文本和图像模态数据集却十分丰富。因此作者提出一种分阶段预训练策略,将vision expert在视觉领域训练好,language expert在文本领域训练好,这样初始化好的参数再在多模态数据集上训练,就会在性能上有大幅的提升。
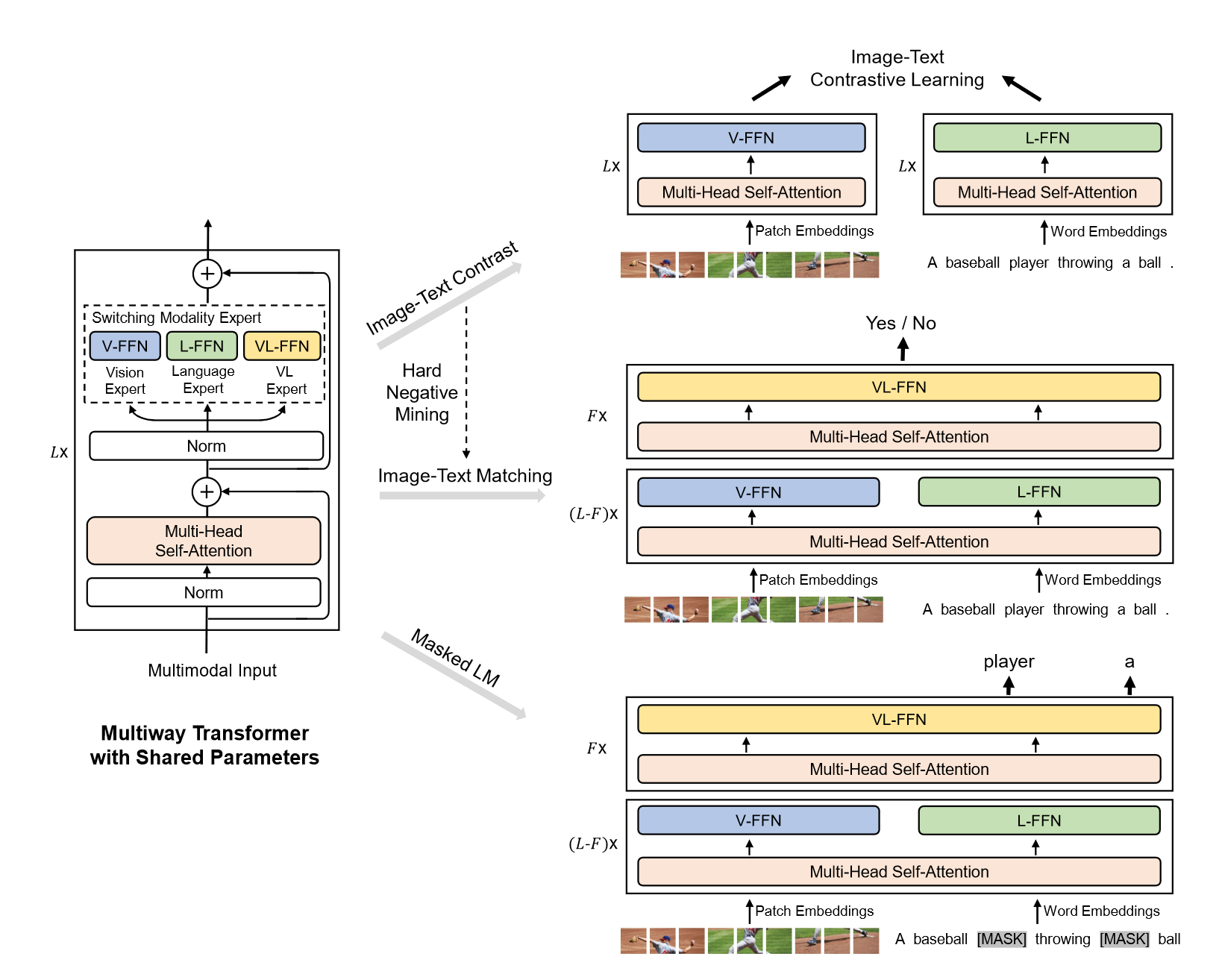
模型结构从形式上和ALBEF一致,单个Transformer块采用的是Multiway Transformer块,相对于Transformer,它在FFN上进行了改动,变成了V-FFN,L-FFN和VL-FFN,根据训练数据模态的不同调整更新不同的FFN。训练任务目标也和ALBEF一致,包括ITC,ITM和MLM,其中ITM也使用了Hard Negative Mining,即将一个batch中最相似的样本作为负样本。ITC的过程和CLIP一致,对V-FFN和L-FFN进行更新。ITM的过程是先单模态更新后模态融合,前L-F层分别对V-FFN和L-FFN进行更新,后F层对VL-FFN进行更新,执行二分类任务。MLM模型和ITM一致,只是拿最后一层对mask的token进行预测。
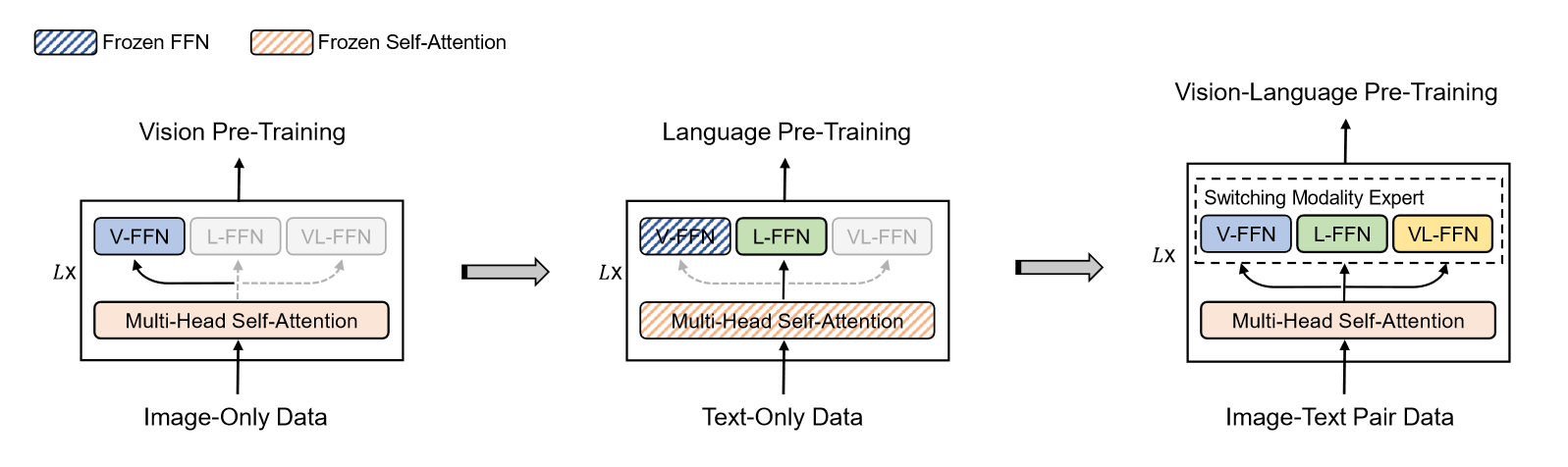
接下来就是本文的第二个贡献点具体实施过程,如上图所示。首先学习图像表征,更新V-FFN和多头自注意力机制的参数,接着冻住多头自注意力和视觉参数,对语言文本进行训练,更新L-FFN,最后所有参数都打开,在多模态数据下进行训练。这里有一个有趣的现象,作者是先在图像上进行训练,再在文本上进行训练,而不是反过来,因为实验发现反过来时效果会变差。
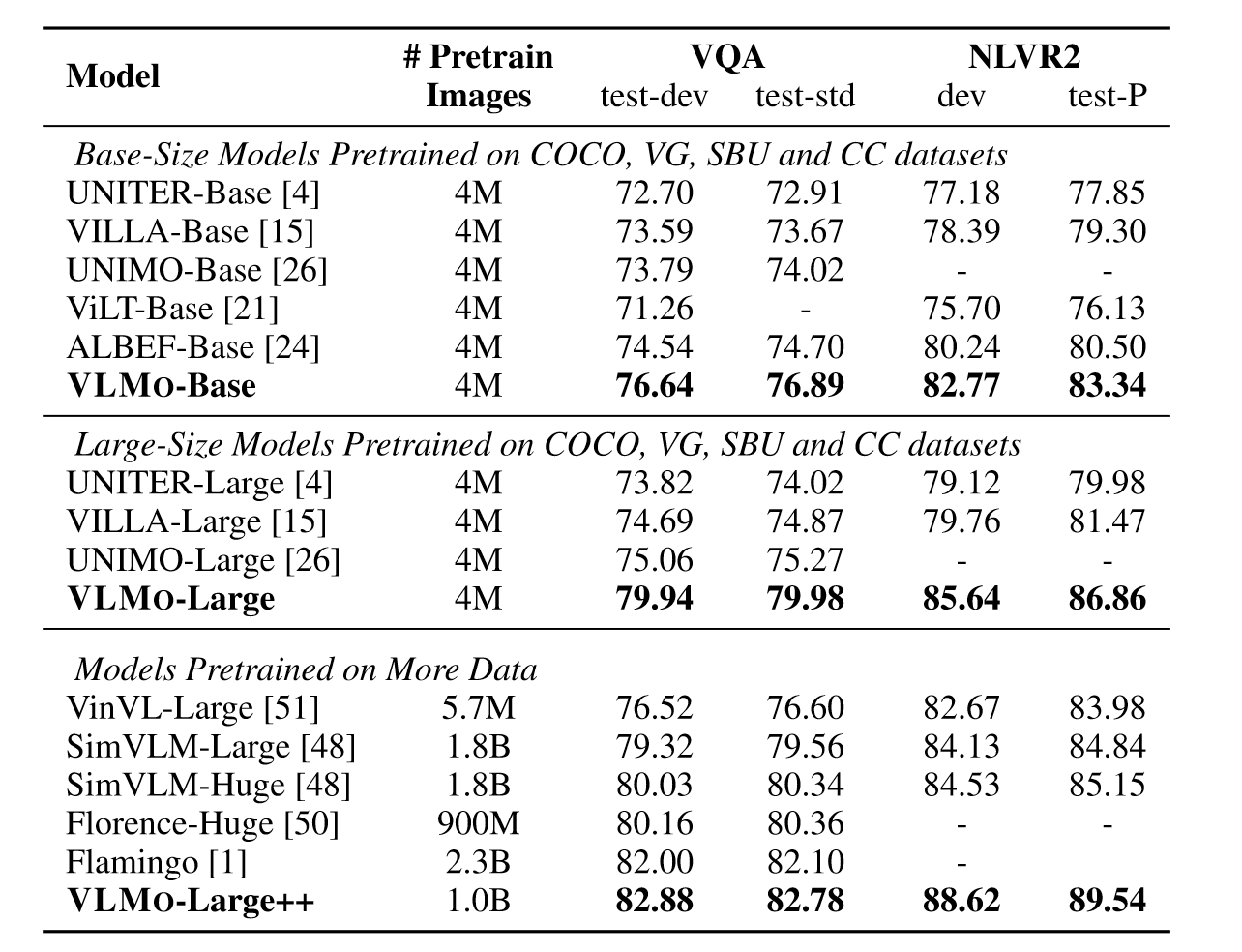
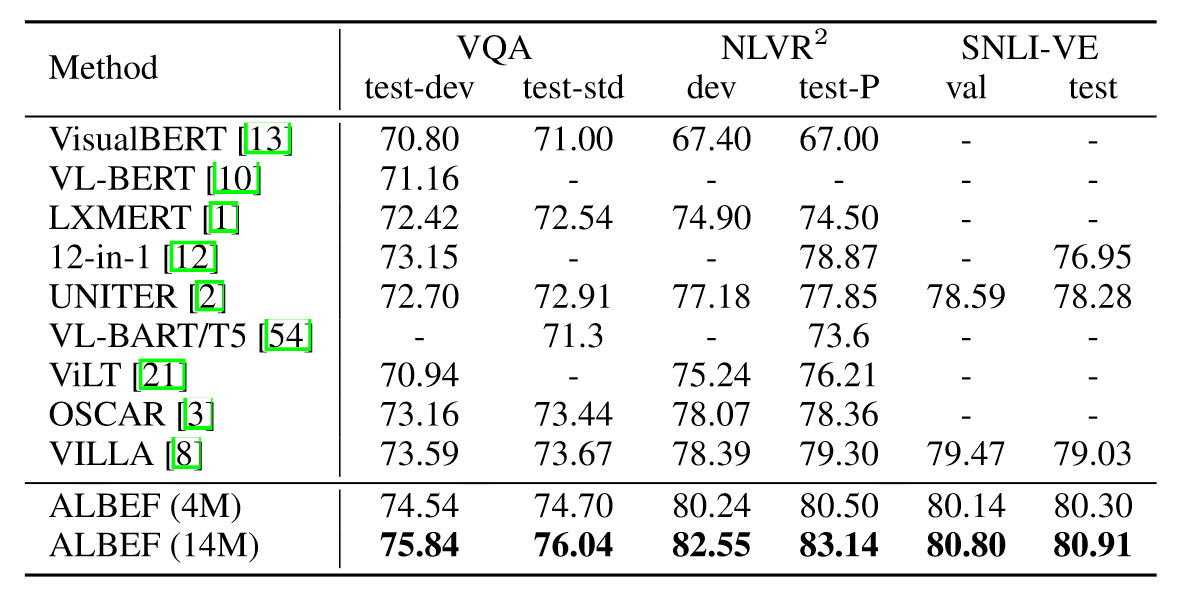
实验部分如上表所示,可以看到无论是base模型,还是large模型,亦或是Large++模型,VLMO的性能都要好于其他模型,并且随着模型增大,训练数据增多,模型的性能也进一步提升。
总结一下,本文提出了统一的视觉语言预训练模型VLMO,它既可以作为双编码器用于高效的视觉和语言的检索,又可以作为融合编码器为跨模态交互建模。此外,作者还表明利用大规模图像和纯文本语料的分阶段预训练极大改善了视觉语言预训练。实验部分表明,VLMO在各种视觉语言分类和检索基准上都要优于先前的先进模型。
未来作者将从以下几个方面对VLMO进行改进:
- 进一步扩大VLMO预训练模型的规模。
- VLMO微调执行视觉语言生成任务是有趣的方向,比如根据图像生成字幕。
- 视觉-语言预训练在多大程度上可以帮助彼此,特别是Multiway Transformer自然融合了图文表征的时候。
- 可以尝试融入更多模态的信息(speech,video,structured knowledge),支持通用的多模态预训练。
4. BLIP
随着多模态领域的发展,近两年的工作采用了Transformer Encoder和Decoder的方法,典型的工作就有来自ICML2022的BLIP。BLIP的动机和上篇工作VLMO有异曲同工之妙。首先都是从模型角度出发,现有的方法大多数都是encoder架构的模型,可以在理解任务上有出色的表现,但是在生成任务上表现不佳。此外还有一些encoder-decoder架构的模型,它们可以做生成任务,但是又在图文检索等理解任务上表现不佳。第二个动机也是和数据有关。当前大多数模型都是在充满噪声的大规模数据集上预训练,虽然通过扩大数据集获得了性能上的提升,但是嘈杂的网络文本对视觉的学习并不是最优的。
因此,本文提出了BLIP模型,其主要贡献点如下:
- Multimodal mixture of Encoder-Decoder(MED):一个用于有效多任务预训练和灵活迁移学习的新模型架构。联合了三个联合预训练目标ITC、ITM和LM。
- Captioning and Filtering(CapFilt):一种新的数据集增强方法,用于从噪声文本对中学习。Captioner模块用于为图像生成描述,filter模块从原始网络文本和合成文本中删除嘈杂的标题。
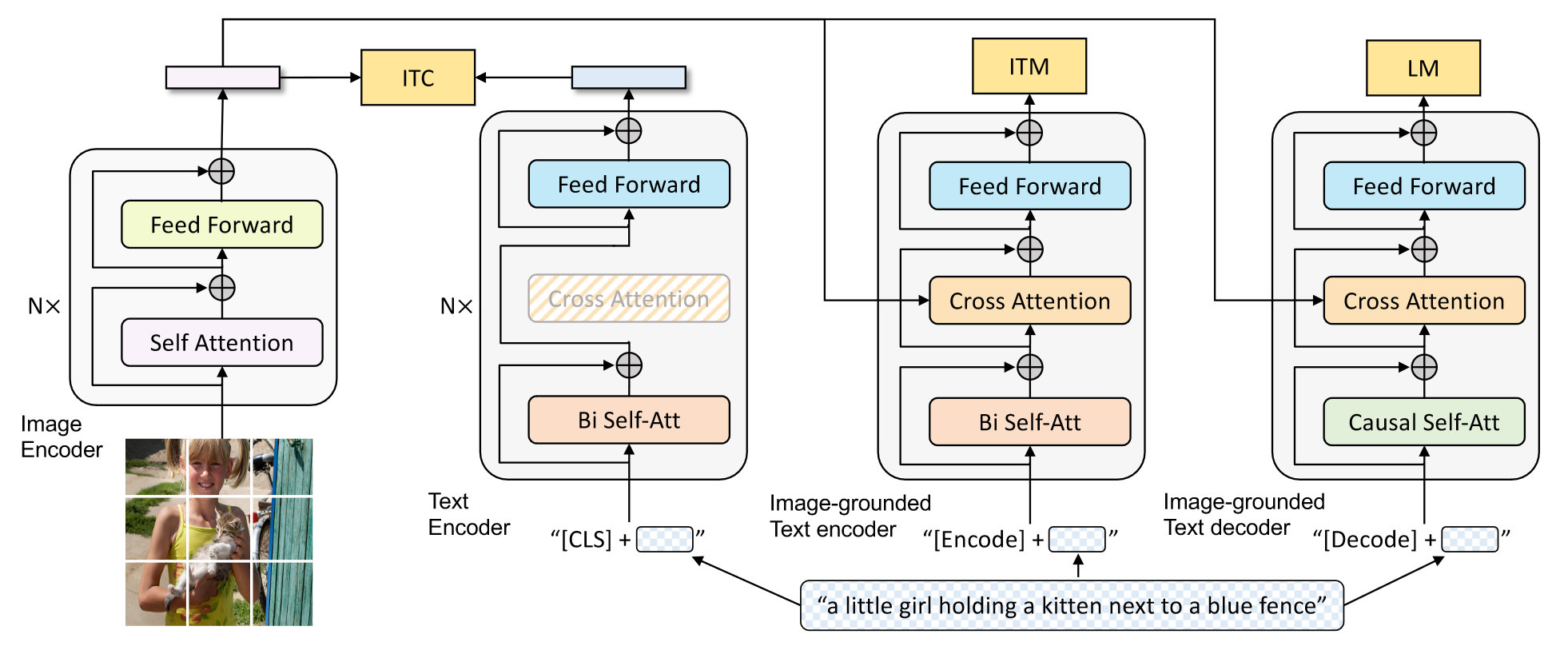
上图是MED的整体架构。之前的工作如VLMO,它的MOME模型就是受到ALBEF的启发构建出来的,这里的MED模型同时受到ALBEF和VLMO启发,其Encoder就是ALBEF,其共享参数的形式就是参考了VLMO。具体来说,MED由四个模块组成,第一个模块是图像的编码器,将图像打包成patch抽取图像的特征。后面三个模块本质上是一个模型,只不过执行不同的任务,第一个模块对文本进行单独编码,和图像特征执行ITC任务,可以看成是CLIP模型。第二个模块将文本和图像的编码进行混合,执行ITM任务,学习模态融合的知识。第三个模块是解码器模块,在之前编码器基础上去除了Bi Self-Att,加入了Causal Self-Att,执行LM任务,让模型拥有生成的能力。由于这篇工作的作者都是ALBEF的原班人马,因此ALBEF中有用的trick也被搬到BLIP中,比如动量编码器,难负样本等。
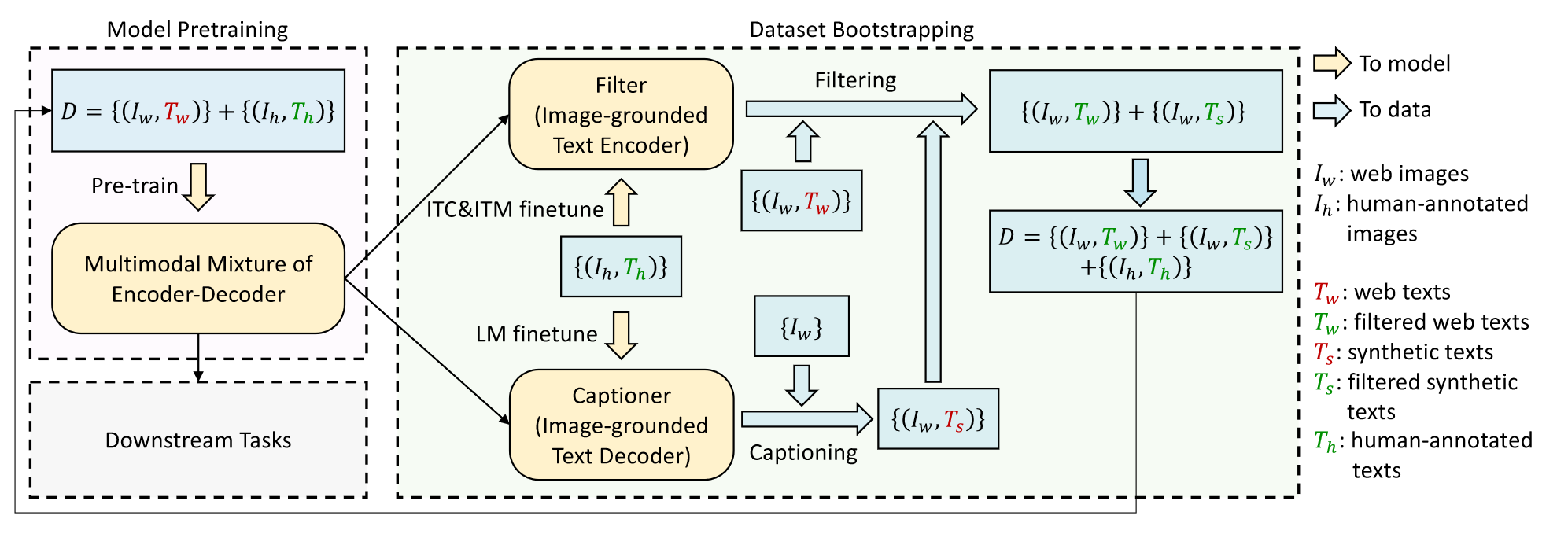
接着就是BLIP第二个贡献CapFilt,如上图所示。左边部分是在原始的噪声数据集上训练并执行下游任务的模块,显然这些数据并不是最优的选择。因此作者提出了Captioning和Filtering,合成CapFilt,前者用于给定网络图像生成图像的caption,后者作为过滤器过滤噪声文本。二者都是通过相同的MED模型初始化,并在COCO数据集上微调,只不过前者基于ITC和ITM微调,后者基于LM微调。微调后的模型作用于噪声数据集,对数据集进行清洗,生成更可靠的caption。

为了进一步解释上述过程,上图展示了生成过滤的结果。第一张图生成的caption明显可以更好描述图像,因此选择生成的caption作为图像的文本,第三张图原始的文本更契合图像内容,因此保留原始的文本而丢弃生成的caption。
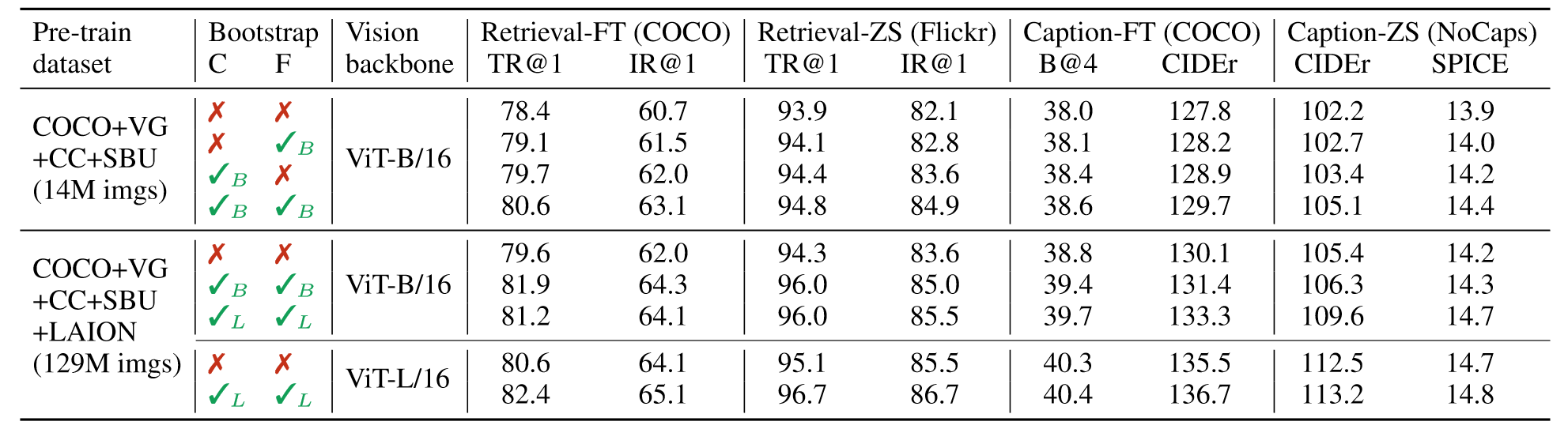
消融实验部分很好说明了大模型,大的更干净的数据集可以对模型性能有着更好的提升。
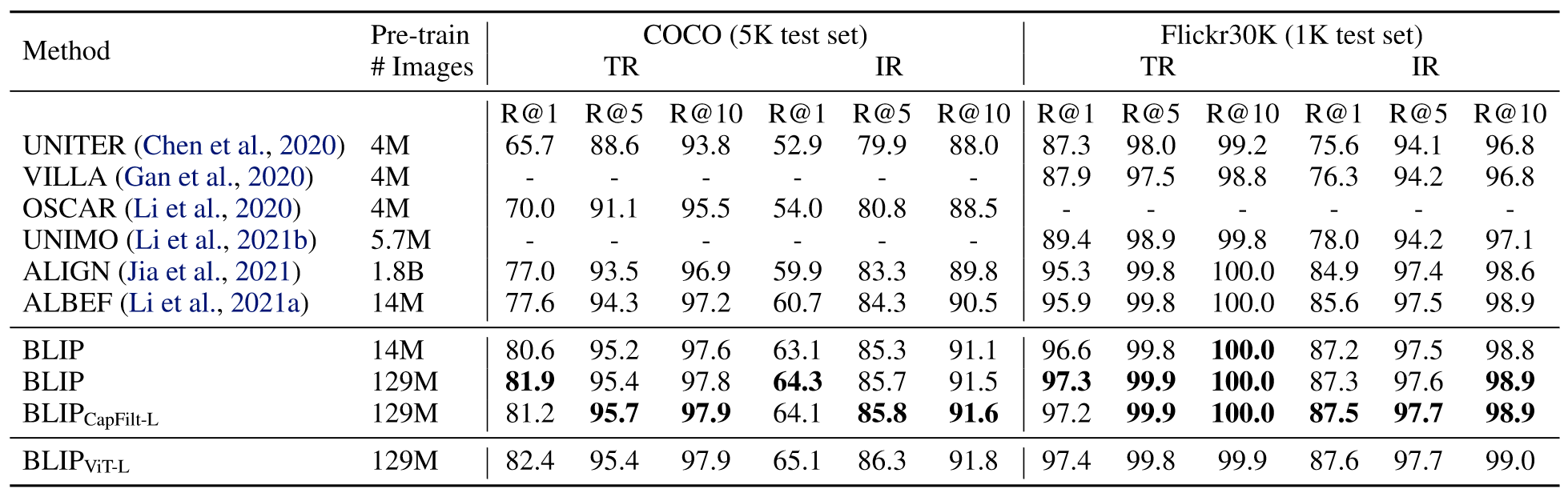
和别的模型相比,BLIP也是极具优越性,在COCO和Flickr30K数据集上都达到了SOTA。
5. CoCa
之前的工作证明了decoder模型的优越性,但是由于计算不同的loss需要多次前向过程,因此计算和时间成本过高。CoCa进一步简化了之前工作的设计,文本端只使用decoder模型,只需要一次的前向过程就可以计算ITC Loss和Captioning Loss。其结构和伪代码如下图所示:
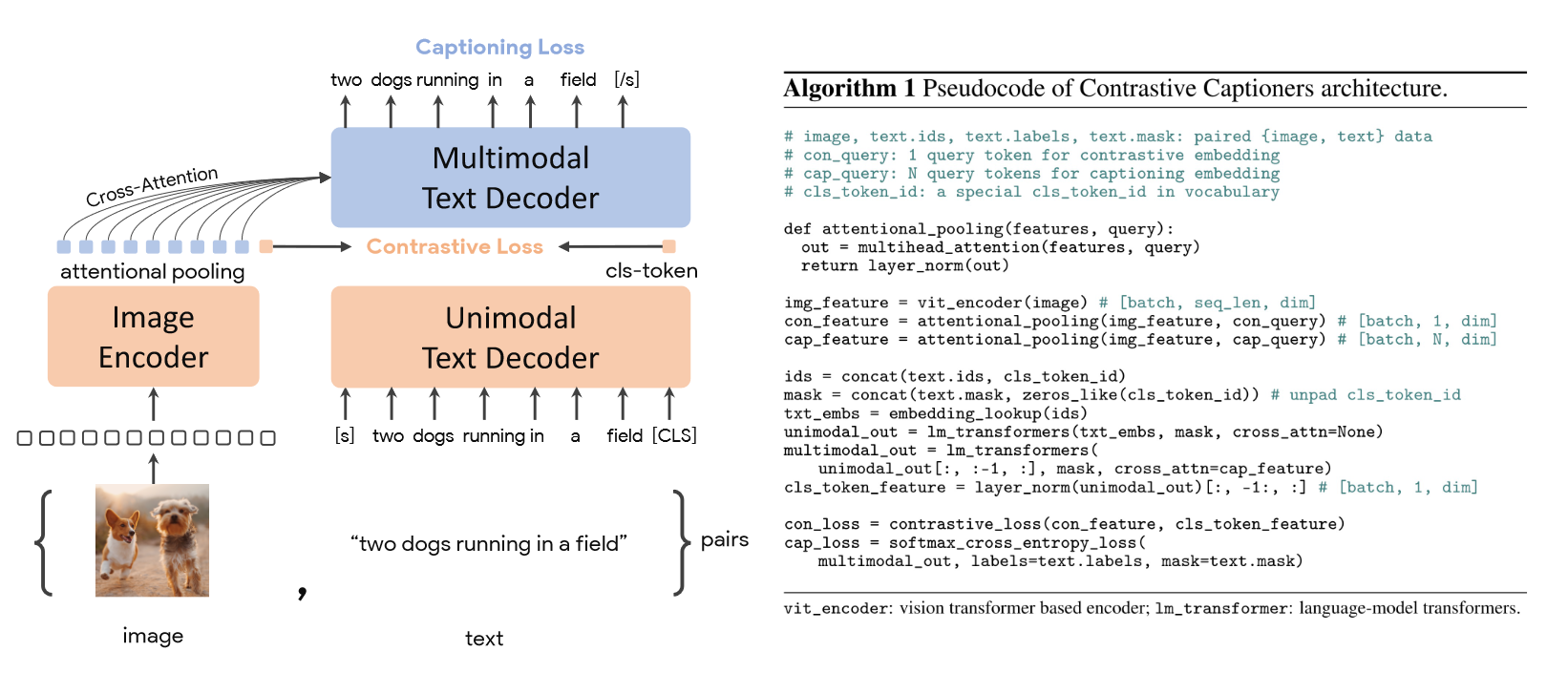
可以看到整体的结构和ALBEF几乎一样,只不过在文本端全部换成了Decoder,图像特征也通过attention pooling用于模态的融合。整体的方法相当简洁,由于是decoder架构,所以作者在几十亿规模的数据集、21亿参数的模型上进行预训练,scale的能力是相当出色。
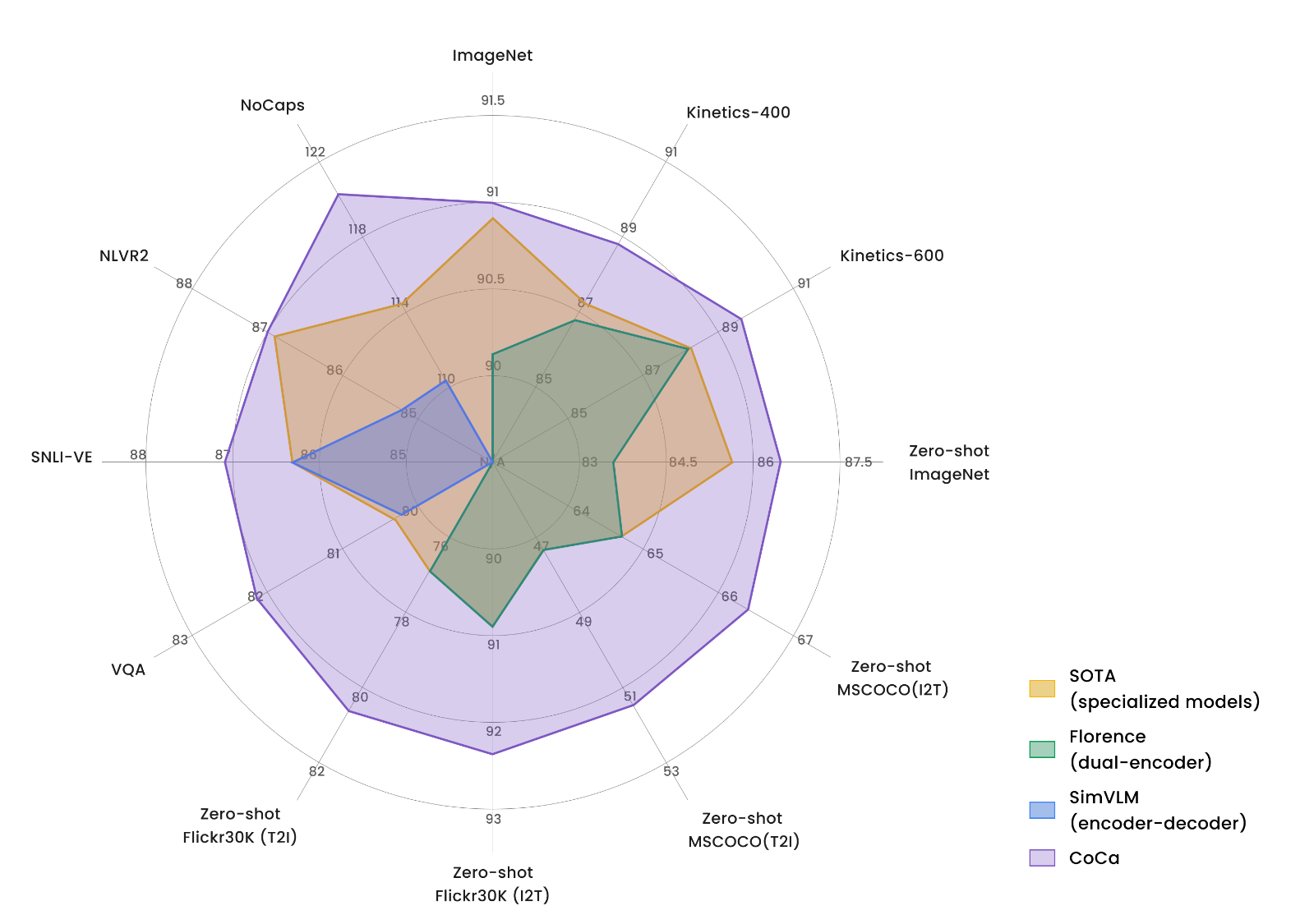
文中的多边形图也极大展示了CoCa的优势。CoCa在各个数据集以及零样本上都展现出强大的能力,刷新了各个榜单的SOTA。
6. BeiTv3
随着多模态领域的工作越来越丰富,研究人员开始追求真正的大一统模型。BeiTv3的目标非常明确,它就是为了做更大一统的多模态模型,无论是模型大小还是目标函数甚至是数据集的规模,都要求统一。这篇工作上来就卖弄它的结果,如下图所示:
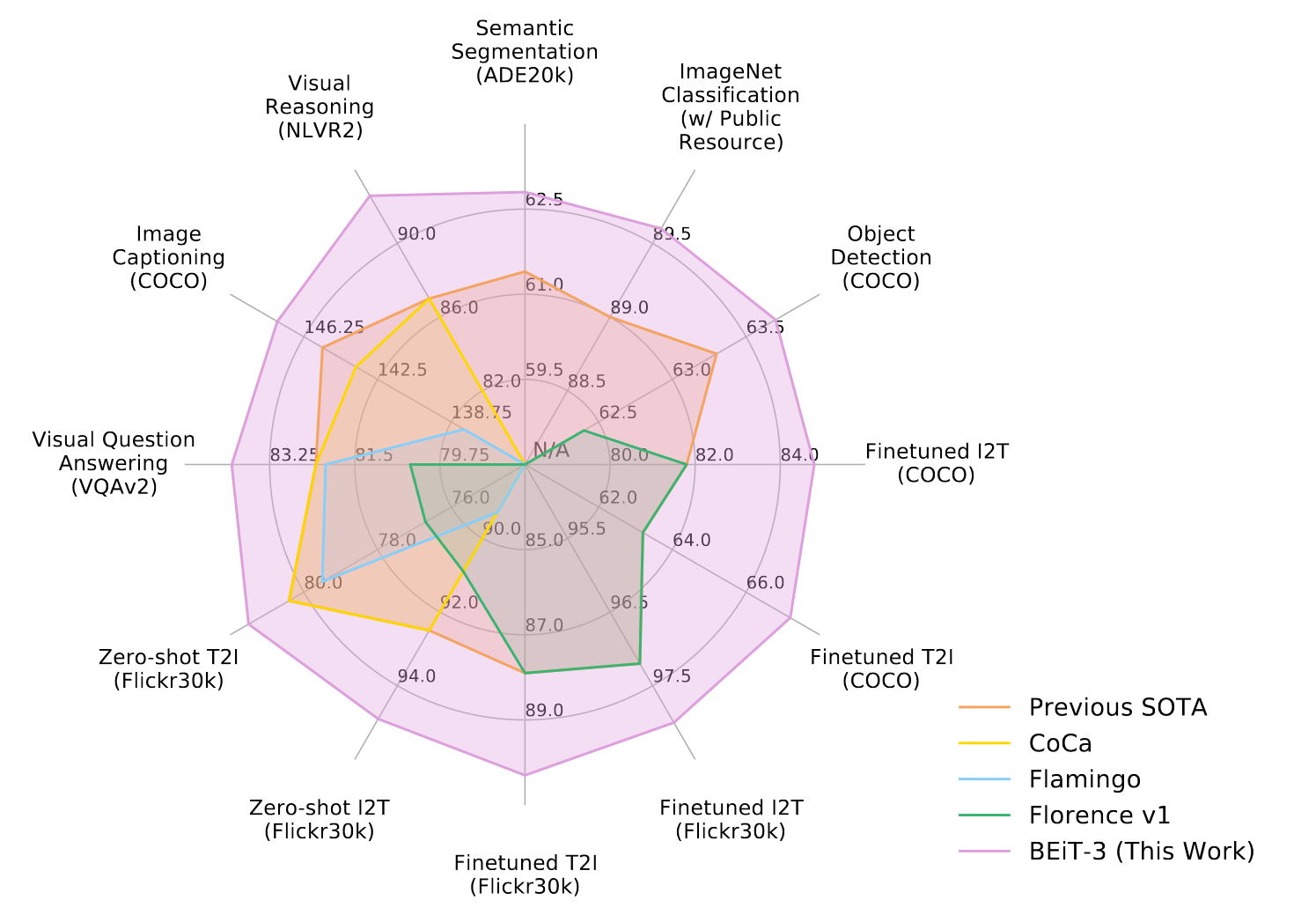
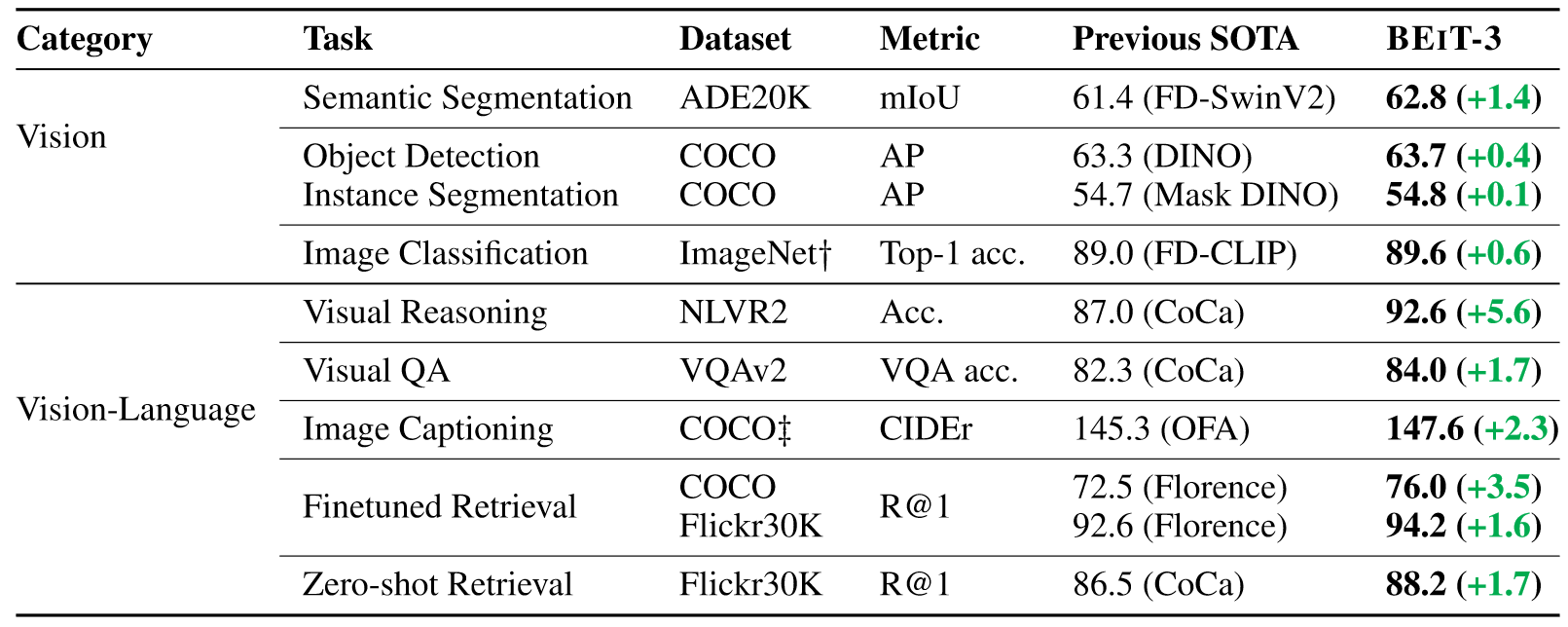
性能可谓是全方位包围之前的模型。BEiTv3得出了两点结论:
- 目标函数不是越多越好,关键还是在于loss之间能否互相弥补。
- 数据不是越大越好,数据的质量更为关键。
为了达到大一统的目的,本篇工作本质上是融合了之前所有模型的优势,主要从以下三个方面展开:
- Transformer提供统一编码,实现模态模型架构的统一。
- mask-then-predict的训练目标,减少过多训练目标带来的效率低下和冗余。
- 扩大模型规模和预训练数据规模。
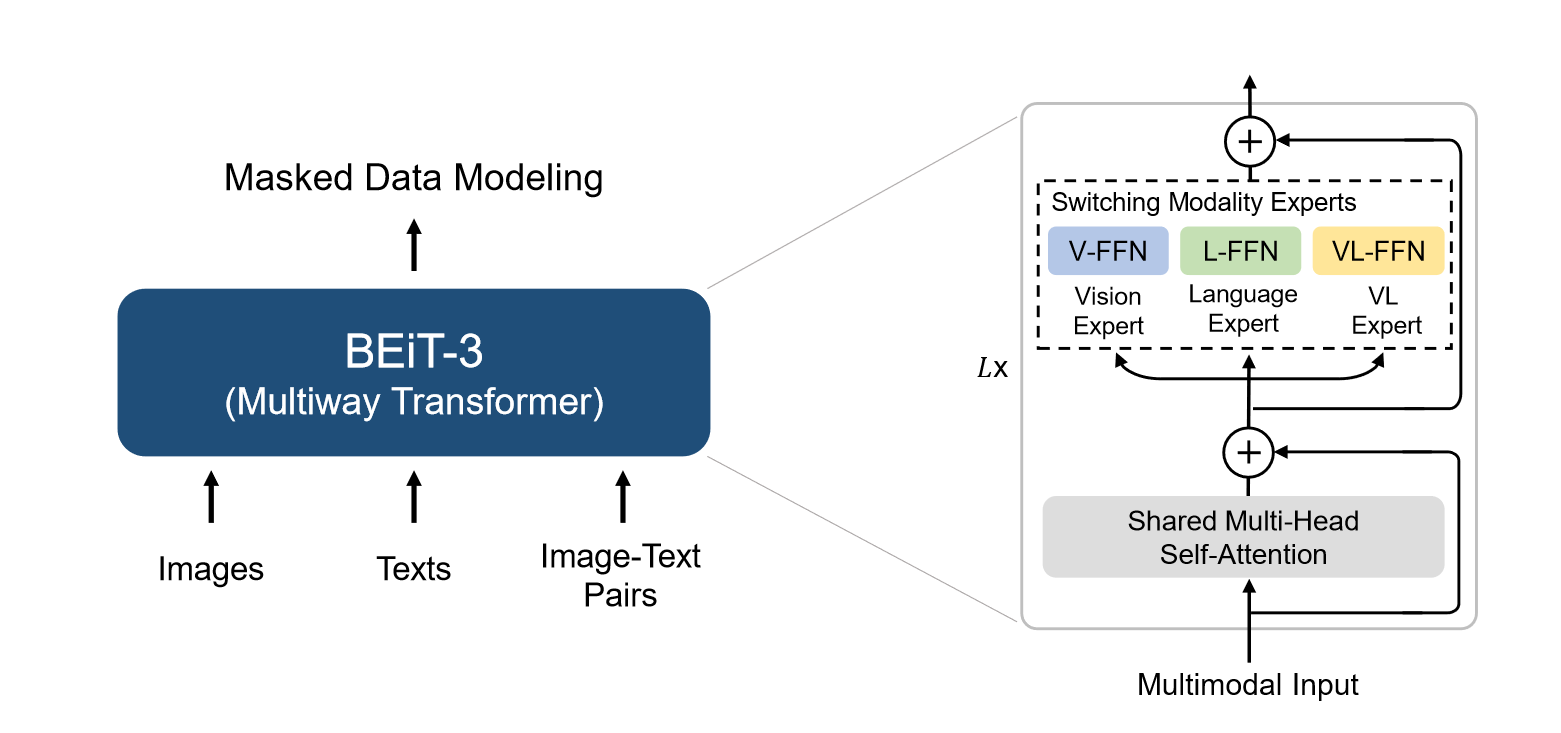
模型的具体结构如上图所示,其实就是VLMO的变体,并且预训练任务只做Masked Data Modeling。
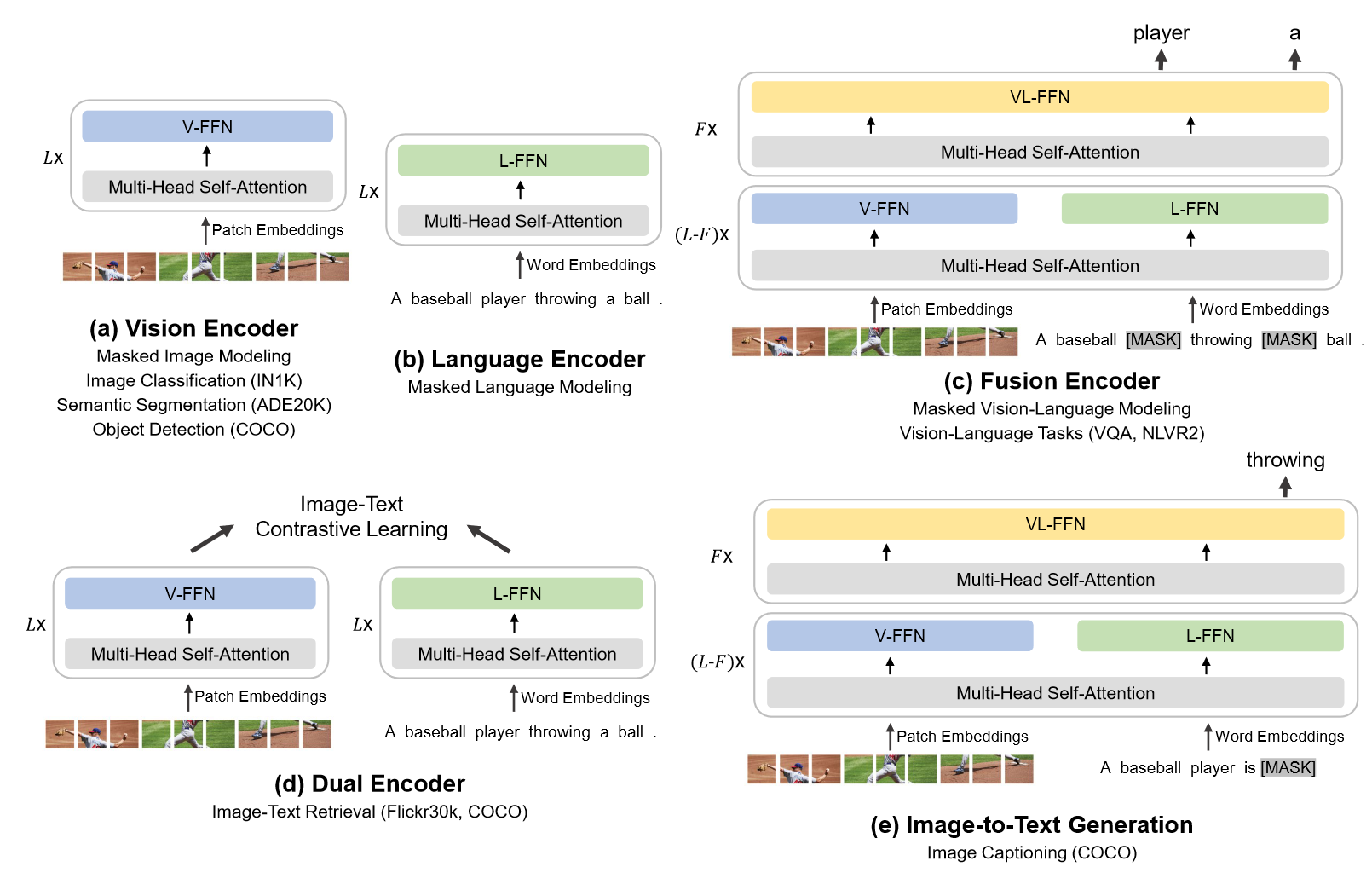
在执行下游任务时,模型也能实现很好的迁移,如上图所示,通过调用模型中不同的模块来执行下游任务,而这些模块都在预训练阶段得到充分的训练,只需要简单微调甚至零样本就能得到很好的效果。
总结
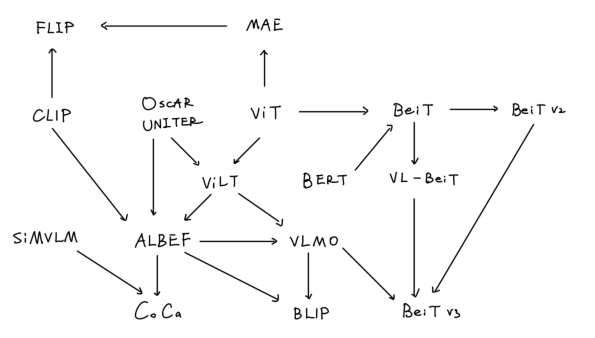
上述的一系列工作可以总结为上面这张图。本文关于多模态的工作其实是从ViT出发的,之前多模态领域对于图像特征的抽取都需要借助CNN架构的模型和目标检测任务,效率低,性能差。随着ViT提出后,多模态领域终于实现文图框架上的统一,即ViLT工作的诞生。但是此时的工作还是在探索图像特征抽取模型、文本特征抽取模型和特征融合模型之间的权重,因此性能甚至还不如之前的模型。ALBEF的工作奠定了模型的权重关系,结合了CLIP的方法,在融合前先进行一次文图特征的对齐,整个训练过程设计了三个训练目标,在性能上实现了显著的提升。但是ALBEF针对不同的模态总共设计了三个模型,既然都是统一的Transformer架构的模型,为什么不能只使用一个模型呢?为此VLMO采用了Multiway Transformer,让所有的模态特征学习都在一个模型中进行,通过冻结FFN和共享自注意力机制实现,实验结果上也是优于ALBEF。但是之前这些工作都只能做多模态理解任务,BLIP开创了生成任务的先河,加入了decoder架构,执行LM任务,并且利用对图像生成caption的优势对数据进行质量上的提升,从而进一步提高模型的性能。CoCa进一步简化先前的工作,文本端只采用decoder架构模型,只需要一次的前向过程就可以计算ITC Loss和Captioning Loss。最后,BeiTv3总结前面所有的工作,目标是成为大一统的多模态模型,在模型和数据规模上都进一步scale,以搭积木的方式处理各种下游任务,结果全方位包围了多模态领域和多个单模态领域的SOTA。
上面主要是从模型结构角度来分析多模态领域方法的改进,其实数据上也有很多改进。因为多模态领域数据集和单模态比起来明显不足,于是很多工作都采用从网络中爬取的文本对进行训练,但是网络数据质量不佳。为此ALBEF提出动量蒸馏方法解决噪声网络数据的问题,VLMO利用单模态数据集进行预训练,而BLIP出色的生成能力让其可以为图像生成更准确的文本caption,从而进一步提升模型的性能。
实际上,虽然BeiTv3这篇工作的目标是成为大一统模型,并且能够做各种各样的下游任务,但都是需要通过模型的组合拼接实现的,从本质上并没有实现大一统,真正的大一统模型是不需要根据下游任务调整模型结构的,如现在的GPT-4等大模型,而这也正是当前多模态领域发展的方向。
参考链接
https://arxiv.org/pdf/2104.13921.pdf
http://proceedings.mlr.press/v139/radford21a/radford21a.pdf
https://arxiv.org/pdf/2107.07651.pdf
https://proceedings.neurips.cc/paper_files/paper/2022/file/d46662aa53e78a62afd980a29e0c37ed-Paper-Conference.pdf
https://proceedings.mlr.press/v162/li22n/li22n.pdf
https://arxiv.org/pdf/2205.01917.pdf
https://arxiv.org/pdf/2208.10442.pdf
相关文章:
【学习笔记】多模态综述
多模态综述 前言1. CLIP & ViLT2. ALBEF3. VLMO4. BLIP5. CoCa6. BeiTv3总结参考链接 前言 本篇学习笔记虽然是多模态综述,本质上是对ViLT后多模态模型的总结,时间线为2021年至2022年,在这两年,多模态领域的模型也是卷的飞起…...

MLAgents (0) Unity 安装及运行
1、下载ML-Agents 下载地址 GitHub - Unity-Technologies/ml-agents: The Unity Machine Learning Agents Toolkit (ML-Agents) is an open-source project that enables games and simulations to serve as environments for training intelligent agents using deep reinfo…...
)
typename关键字详解(消除歧义)
typename关键字详解 文章目录 typename关键字详解定义用法1.和class同义,用于引入泛型编程中所用到的模板参数2.用来消除歧义,告诉编译器后面的是类型名而不是变量名 定义 typename相当于泛型编程中class的同义关键字,用来指出模板类型所依赖…...

设计模式_解释器模式
解释器模式 案例 角色 1 解释器基类 (BaseInterpreter) 2 具体解释器1 2 3... (Interperter 1 2 3 ) 3 内容 (Context) 4 用户 (user) 流程 (上下文) ---- 传…...

【算法基础】数学知识
质数 质数的判定 866. 试除法判定质数 - AcWing题库 时间复杂度是logN #include<bits/stdc.h> using namespace std; int n; bool isprime(int x) {if(x<2) return false;for(int i2;i<x/i;i){if(x%i0) return false;}return true; } signed main() {cin>&g…...
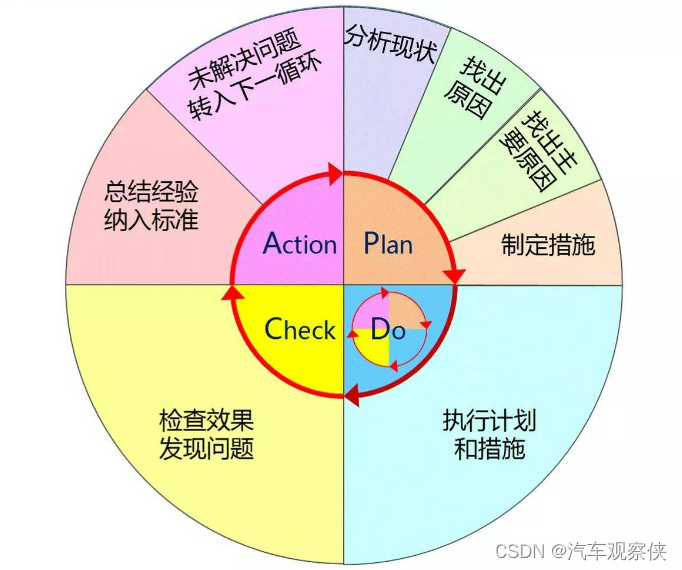
PDCA循环
目录 1.认识PDCA: 2.PDCA循环的经典案例 3.PDCA的四个阶段和八个步骤 4.PDCA循环的优缺点: 5.案例 6.其他作用 1.认识PDCA: PDCA循环最早由美国质量统计控制之父Shewhat(休哈特)提出的PDS(Plan Do Se…...
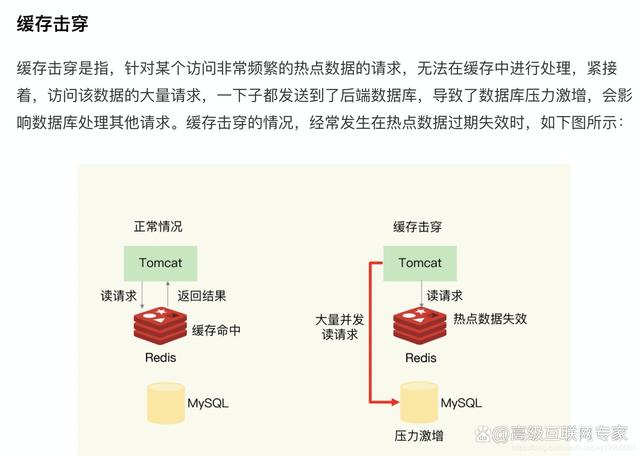
Redis 缓存雪崩、缓存穿透、缓存击穿
Redis 是一种常用的内存缓存工具,但在某些情况下,它可能会遭受缓存雪崩、缓存穿透和缓存击穿等问题。下面是一些预防这些问题的建议: 1、缓存雪崩 缓存雪崩指的是在某个时间点上,大量的缓存数据同时失效或过期,导致大…...
Android Media3 ExoPlayer 开启缓存功能
ExoPlayer 开启播放缓存功能,在下次加载已经播放过的网络资源的时候,可以直接从本地缓存加载,实现为用户节省流量和提升加载效率的作用。 方法一:采用 ExoPlayer 缓存策略 第 1 步:实现 Exoplayer 参考 Exoplayer 官…...

MyBatis注解开发
MyBatis常用注解 注解对应XML说明Insert< insert>新增SQLUpdate< update>更新SQLDelete< delete>删除SQLSelect< select>查询SQLParam–参数映射Results< resultMap>结果映射Result< id>< result>字段映射 开发流程: 1…...
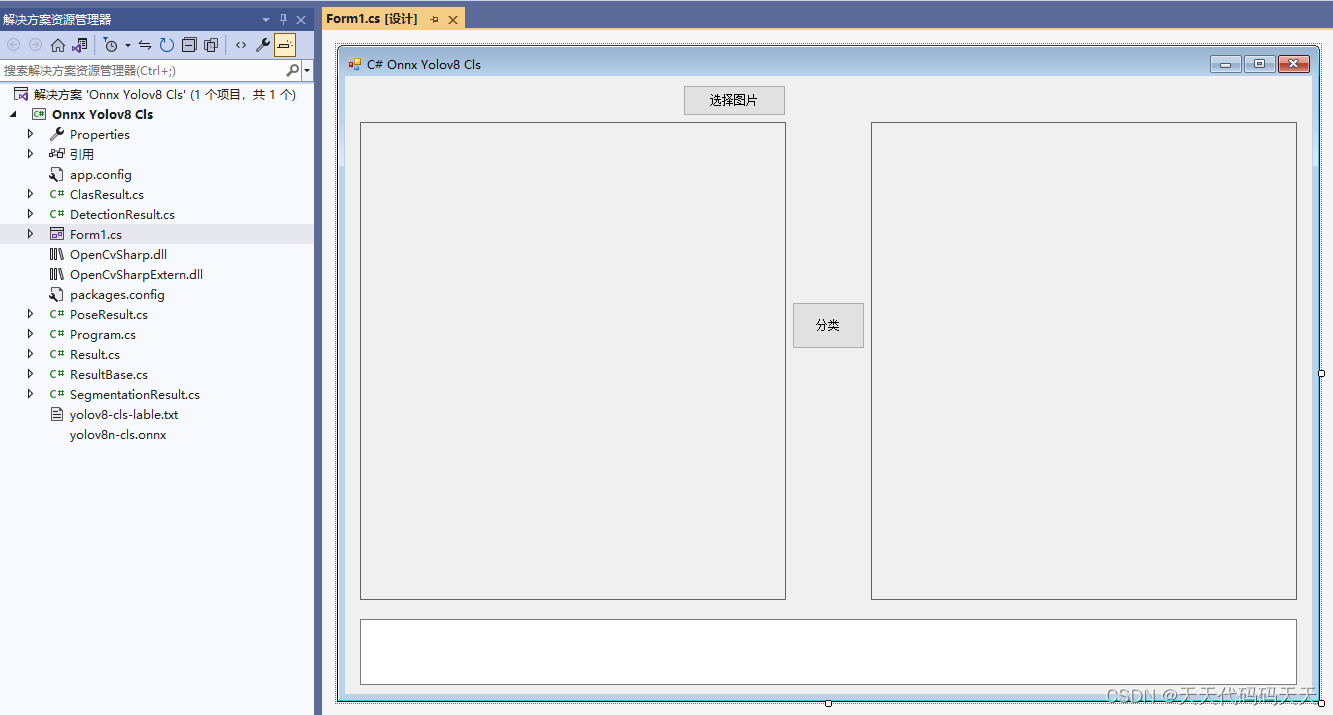
C# Onnx Yolov8 Cls 分类
效果 项目 代码 using Microsoft.ML.OnnxRuntime; using Microsoft.ML.OnnxRuntime.Tensors; using OpenCvSharp; using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System…...

Fiddler常用的快键键
Fiddler有很多常用的快捷键,这些快捷键可以帮助你更快速地完成任务。以下是一些常用的快捷键: F12:启动/停止抓包。 CtrlR:打开FiddlerScript窗口。 CtrlH:切换到 Inspector 页签的 Header 视图。 CtrlT:切…...

【Linux】生产消费模型 + 线程池
文章目录 📖 前言1. 生产消费模型2. 阻塞队列2.1 成员变量:2.2 入队(push)和出队(pop):2.3 封装与测试运行:2.3 - 1 对代码进一步封装2.3 - 2 分配运算任务2.3 - 3 测试与运行 3. 循环阻塞队列3.1 POSIX信号量:3.1 - 1…...
基于springboot+vue的爱心助农网站(前后端分离)
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战 主要内容:毕业设计(Javaweb项目|小程序等)、简历模板、学习资料、面试题库、技术咨询 文末联系获取 项目介绍…...
)
“华为杯”研究生数学建模竞赛2019年-【华为杯】D题:汽车行驶工况构建(附获奖论文和MATLAB代码实现)
目录 摘 要: 1. 问题重述 2. 模型假设 2.1 题目对模型给出的假设...

v-cloak的作用和原理
1、作用 v-cloak 指令常用在插值表达式的标签中,用于解决当网络加载很慢或者频繁渲染页面时,页面显示出源代码的情况。 所以为了提高用户的体验性,使用指令 v-cloak,搭配着 CSS 一起使用,在加载时隐藏挂载内容&#x…...

pip pip3安装库时都指向python2的库
当在python3的环境下使用pip3安装库时,发现居然都指向了python2的库 pip -V pip3 -V安装命令更改为: python3 -m pip install <package>...

和逸云 RK3229 如何进入maskrom强刷模式
图中红圈两个点短接以后插usb,就可以进入maskrom模式强刷...

防静电离子风扇的应用及优点
防静电静电离子风扇是一种用于消除静电的设备,它可以通过离子化原理将静电荷离子化,从而达到静电的效果。防静电静电离子风扇通常采用离子风扇的形式,通过离子化原理将静电荷离子化,从而消除静电。 防静电静电离子风扇的工作原理…...
git中无法使用方向键的问题
windows下使用git命令行执行react脚本安装,发现无法使用上下键来去选中选项。最后只能换成cmd命令执行,发现可以上下移动以选中需要的选项。 bash命令行:移动光标无法移动选项 cmd命令行...

负载均衡中间件---Nginx
一.nginx的好处 学习 Nginx 对于一个全栈开发者来说是非常有价值的,下面是一些学习 Nginx 的原因和好处: 反向代理和负载均衡:Nginx 是一个高性能的反向代理服务器,可以用于将客户端请求转发给多个后端服务器,实现负…...

从ARIMA差分到MIM网络:一个老派时间序列技巧如何革新了深度学习预测
从差分思想到记忆网络:传统时间序列技巧如何重塑深度学习架构 在气象预报的雷达回波图中,降水云团的形态每秒钟都在剧烈变化;城市交通流量监测数据里,早晚高峰的波动与平峰期形成鲜明对比;股票市场的价格曲线更是以难以…...
完整移植方案)
正点原子 RK3562 Android14 集成 GStreamer 1.24.13(CLI + V4L2 插件)完整移植方案
RK3562 Android 系统中集成 GStreamer CLI V4L2 插件的完整移植方案,重点难点在于:预编译产物整理、Android.bp 自动生成、vendor 路径安装、运行时环境变量注入,以及 Android 动态链接 namespace 限制的排查。 正点原子RK3562J开发板瑞芯微…...

20 鸿蒙LiteOS信号量原理实战:信号量作用、MAX_COUNT含义、线程同步源码解析
鸿蒙LiteOS信号量原理实战:信号量作用、MAX_COUNT含义、线程同步源码解析 一、前言 本文基于小凌派 RK2206鸿蒙LiteOS标准示例代码,从零讲解LiteOS内核信号量核心概念:为什么需要信号量、信号量能干什么、MAX_COUNT参数真实含义,…...

LVGL图片资源全解析:从C数组到图标字体的高效集成方案
1. LVGL图片资源方案概述 在嵌入式GUI开发中,图片资源的管理直接影响产品性能和开发效率。LVGL作为轻量级图形库,提供了三种主流的图片集成方案:内部C数组、外部文件系统图片和图标字体。每种方案都有其独特的适用场景和实现方式,…...
)
AD导出Gerber到CAM350拼板全流程避坑指南(附文件漏导出自查清单)
AD导出Gerber到CAM350拼板全流程避坑指南(附文件漏导出自查清单) 在硬件产品开发中,PCB设计到生产的转换环节往往隐藏着诸多"暗礁"。我曾亲眼见过一个团队因为钻孔文件覆盖问题导致生产延误两周,损失近十万元。本文将分…...

使用Taotoken CLI工具一键配置多开发环境下的API访问密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置多开发环境下的API访问密钥 在团队协作或个人多设备开发场景中,为不同的AI开发工具&…...

别只把Docker当虚拟机!《Docker实践》没细说的5个生产环境‘骚操作’
别只把Docker当虚拟机!5个生产环境高阶实践指南 当团队从开发测试转向生产环境时,Docker的使用方式往往需要质的飞跃。许多工程师在初期将容器简单视为轻量级虚拟机,却忽略了容器化架构真正的威力。本文将揭示那些官方文档鲜少提及࿰…...

2026论文降AI实战SOP:保留排版格式,8款工具与结构级优化指南
内容ai率检测数值太高,不得不熬夜改了一遍又一遍,润色到想吐,结果检测报告上数字还是不尽人意,截止日期越逼越近,真的是没办法了。 我花了整整三天,把2026全网热门的几十款降AI工具通通测了个遍࿰…...

解决 Claude Code 频繁封号问题之转向 Taotoken 稳定服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决 Claude Code 频繁封号问题之转向 Taotoken 稳定服务 对于依赖 Claude Code 进行开发的工程师而言,账号访问权限的…...

Windows APK安装工具终极指南:轻松在电脑上安装Android应用
Windows APK安装工具终极指南:轻松在电脑上安装Android应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 您是否曾经希望在Windows电脑上直接安装Android…...