QCA组态如何科学命名?
前言
(一)文献来源
文献来源:[1]Furnari S, Crilly D, Misangyi V F, et al. Capturing causal complexity: Heuristics for configurational theorizing[J]. Academy of Management Review, 2021, 46(4): 778-799.
(二)阅读过程中发现的好文章
若想使用R语言进行QCA分析推荐阅读:
[2]Cangialosi N. Fuzzy-Set Qualitative Comparative Analysis (fsQCA) in Organizational Psychology: Theoretical Overview, Research Guidelines, and A Step-By-Step Tutorial Using R Software[J]. The Spanish Journal of Psychology, 2023, 26: e21.
介绍:(a)对该方法的完整描述,突出一些最重要的理论方法方面;(b)对最常用的指南和建议的看法,以及 (c)有关如何使用QCA包在R中执行FsQCA的分步说明。来自意大利中部一家公司的120名员工和主管的数据最适合说明如何执行fsQCA。用于从R的QCA包进行分析的代码随教程一起提供,并且可以适应新的数据集。若对QCA研究方法缺乏整体认知推荐阅读:
[3]Park Y K, Fiss P C, El Sawy O A. Theorizing the multiplicity of digital phenomena: The ecology of configurations, causal recipes, and guidelines for applying QCA[J]. Management of Information Systems Quarterly, 2020, 44: 1493-1520.
介绍:该研究提供了一个概念框架和规范性指南,用于应用QCA来开发因果配方,这些配方解释了以理论和配置多重性为特征的复杂数字现象。因果配方是解释因果相关元素如何组合成与感兴趣结果相关的配置的正式陈述。我们根据哪些原因(即阶乘逻辑)以及这些原因如何组合成配置(即组合逻辑)以产生目标结果来描述这些因果配方,并提出了一个配置生态,阐明了多种配置的解释能力以及它们的解释重叠。[4]Misangyi V F, Greckhamer T, Furnari S, et al. Embracing causal complexity: The emergence of a neo-configurational perspective[J]. Journal of management, 2017, 43(1): 255-282.
介绍:该文献表征这种新兴新配置视角的四个基本要素:(a)将案例概念化为集合理论配置,(b)将案例的成员资格校准为集合,(c)从集合之间的必要性和充分性关系的角度来看待因果关系,以及(d)对未观察到的配置进行反事实分析。然后对QCA在管理研究中的使用进行了全面回顾,旨在捕捉管理学者中新配置视角的演变。
一、QCA命名的总体思路
(一)对因果关系复杂化存有的问题
对因果关系复杂性进行理论化是困难的。首先,因果关系复杂的解释需要理论来解释多方面的相互依赖关系,而不是二元关系;其次,虽然许多管理和组织理论明确或隐含地承认其感兴趣的现象背后的因果复杂性,但它们往往是由理论和方法之间的密切相互依存所形成的。最后,相关理论还受到对称假设的进一步挑战,也就是说,隐含的想法是导致现象缺失的因素是导致其存在的因素的反比。相关理论是单一的,因此不太适合解决因果复杂性固有的等性。
在配置理论中,重点在于理解如何或为什么多个属性组合成不同的配置来解释一种现象,同时也认识到复杂的因果解释可能涉及多个属性配置,导致感兴趣的结果。这使得构型理论化与相关理论化形成鲜明对比,并强调构型的概念是由中心主题或综合机制编排在一起的多维属性。(换个角度理解也就是相关思维和组合思维的区别,即原因可能以复杂的方式结合起来解释一个结果,还有相等性即可能有两种或两种以上的途径可以达到相同的结果;相关性思维侧重于孤立个体解释属性对结果的独特贡献,保持所有其他属性不变。)
(二)理论化的构型方法
管理领域的大多数配置定义都强调构成配置的属性之间的相互依赖关系,并认为配置具有一个或多个中心“逻辑”或主题,协调各种属性的相互作用并限制其多样性。管理学中的配置研究在其理论化工作中有一个共同的总体目的,旨在确定为什么或如何将多个解释因素组合成带来感兴趣结果的配置。与这一学术成果相一致,我们接受构型理论化的概念,即不仅要理解构成构型的多个属性及其联系,还要理解构成其一致性的协调主题。
(三)概念的介绍
1.什么是理论化?
如果把理论视作解释一种现象的思想系统,那么理论化就是理论发展的过程。理论化涉及想象和心理模拟等活动,叙述和论点的口头表达和可视化。当学者们理论化时,他们经常使用启发式,即经验法则来产生见解并创造性地解决问题。理论化的启发式作为“通过特殊方式操纵论证、描述和叙述来产生新思想的自觉手段”,使学者们“在对问题的智力攻击中迅速转换”。
2.什么是构型理论化 ?
构型理论化的目的是解释多重解释因素如何以及为什么结合起来产生感兴趣的现象或结果。构型理论化既包括指定链接属性的组合,也包括阐明构成这些属性如何以及为什么一起工作的基础的编排主题。在最好的情况下,由此产生的构型理论将分析精度(例如,详细描述属性之间的联系)与有意义的综合结合起来。因此,构型理论包含了整体与部分的二元性、简单与复杂、抽象与具体知识、综合与分析之间的紧张关系。我们的目的是解释配置的理论化过程,以便这些二元性所产生的紧张关系可以“保存和管理,而不是简化”。
二、QCA命名的步骤
基于新出现的理论见解或观察,在理论化过程中的任何时候,学者都可以回到前一阶段,重新考虑关键属性,它们的联系和配置,以及它们的编排主题。因此,虽然我们按顺序说明了各个阶段和相应的启发式,但在实践中,构型理论化可能是一个迭代过程(理论化反馈循环)。
(一)范围界定(确定可能形成配置的相关属性)
范围界定阶段主要涉及识别和指定理论化的关键属性,以便相互结合以解释现象。
(1)范围界定阶段的目标应该是界定解释现象的属性
与所有好的理论一样,范围界定最好是通过尽可能多地了解导致一种现象的原因来开始的,无论是从现有的理论还是现有的关于该现象的实质性知识中。Park等人将其称为理解“配置的析因逻辑”,即“描述哪些元素对感兴趣的结果的发生及其原因是重要的,以及哪些元素在因果关系上不相关,可以被剥离”。
这要求做到,通过考虑尽可能多的相关解释性属性来使现象的解释复杂化,而且还包括通过尽可能将相似或一致的属性概念化为高阶结构来简化现象,从而减少需要考虑的属性的数量。具体细化为以下两个范围界定方法即“从锚点复杂化”和“简化到高阶结构”法。
A、从锚点络合。
范围界定阶段的出发点是通过考虑尽可能多的解释属性来使感兴趣的现象的解释复杂化。为了应对从哪里开始复杂化的挑战,我们建议从一个“锚”开始——一个或多个人们认为对解释结果很重要的属性。很少,如果有的话,一个解释性属性本身会导致感兴趣的结果。例如,如果有人对理解性别包容性(或排他性)的“把关”感兴趣。在美国,一些男性高管是如何或为什么在组织中充当促进性别平等的“看门人”,而另一些则是抑制性别平等的?——可能是男性高管自身的某些属性(例如,他们的权力;他们的表演遗产;他们的背景/经验将作为理论化过程的锚点。然后,关键的范围界定问题就变成了:这些关键的男性高管属性与哪些其他解释性属性结合起来,可以解释感兴趣的结果(即性别包容)?因此,复杂化将涉及从锚解释性属性中构建出来,同时考虑它们如何与其他可能在理论上相关的解释性属性相结合。在上述例子中,这可能包括寻求进入组织高管阶层的女性候选人的属性或组织或行业背景的属性。
B、思维扩展到他们最初对锚点的预感所依据的理论领域或学科之外。
也可以使用用于解释兴趣现象的属性(“事实”)与一组没有导致兴趣现象的类似属性(“衬托”)进行比较,其比较的想法是“潜在原因可能位于事实和衬托的因果历史不同的地方”。在实践中,事实/陪衬的并置通常采用“为什么X[事实]而不是Y[陪衬]?”,其中的衬托可以基于观察、直觉或先验理论。密尔的“比较把握”概念同样表明,通过研究一种现象的相关解释因素如何在不同的背景或历史时期发生变化,可能会导致学者找到“线索”,为他们的理论提供信息,并允许识别新的解释属性。
(2)找出合理的连贯性
构型理论不仅意味着多个属性结合起来解释一个结果,而且还意味着在所讨论的属性之间存在一些内在的逻辑或似是而非的一致性。
这些多重属性如何或为什么合理地相互结合以解释结果?第一,通过明确现有理论或文献中隐含的构型论证,可以帮助识别似是而非的相干性。第二,在一些文献中,对解释属性之间的似是而非的配置一致性的指示可能更多地基于经验。
(3)简化为高阶结构
在构型理论中,复杂性随着所考虑的属性及其潜在联系的数量呈指数增长。其结果可能是缺乏理论上的简洁和似是而非的连贯性。考虑到这一挑战,一个简化的理论化步骤是寻找有助于包含这种复杂性的高阶结构,并限制所考虑的解释属性的数量。
第一,学者们认识到某些解释性属性可以基于其潜在的共性在更抽象的层面上进行简约的思考;第二,某些解释属性的似是而非的一致性可能成为将属性组合成高阶构念的基础.
(二)链接(考虑属性如何相互连接)
在连接阶段,学者们需要进一步理论化这些属性如何或为什么相互连接或相互关联,以形成一个或一组可以解释这一现象的配置。
组态理论化过程的链接阶段涉及考虑在范围界定阶段中指定的属性如何或为什么相互连接。因此,链接是关于发现组合逻辑,“解释配置的不同元素如何相互关联,以分析的方式产生结果”。为此,我们提供了启发式方法,用于理论化配置中属性的合取(或共现)和这些配置的析取(或等价)。我们还提供了一些启发式方法,旨在理论化一个属性的缺失如何或为什么可能是解释结果的理论化配置的一部分,因为,如上所述,属性的缺失通常与属性的存在解释现象一样重要。
(1)组合性思考
第一, 合词通常包括一些属性,这些属性在理论上被认为是相互补充或偶然的。虽然偶然性意味着一个或多个属性的解释效果是其他相关属性存在或不存在的函数,但互补性意味着两个或多个属性相互增强彼此对预期结果的贡献,即它们是协同的。第二,考虑互补性不仅需要从“与”的角度来思考,还需要考虑解释因素如何或为什么相互增强。
(2)等效性思考
第一, 一个或多个属性或属性配置可能是产生结果的替代品。替代意味着这些属性配置的功能等价,这不同于互补基础上的相互增强。第二,虽然上述相等性的概念本质上涉及在显示结果的不同实例(即案例)之间发生的相等路径,但相等性也可能发生在给定的案例中,特别是当结果被多个充分解释属性的存在过度决定时。
(3)对缺失属性的思考
学者们必须翻转他们的参考框架,将属性的缺失本身概念化为解释性属性,而不是简单地认为该属性不适用于结果。第一,对缺失的思考要求学者思考构成因果配方的每个属性的缺失是如何或为什么与其他属性的存在和缺失相关联的。第二,也促使人思考关是否存在属性间的等效替换。
(三)命名(标记配置以唤起它们的编排主题)
最后,在命名阶段,重点是阐明底层编排主题并标记已识别的配置。
命名是构型理论化的关键阶段,因为它涉及到构建一个总体叙事,有意义地传达构成每26个理论化构型和整体构型理论的复杂模式。我们确定了三个关键的命名启发式,这些启发式来自于令人信服的解释同时是可信的和独特的见解。因此,我们的启发式“表达简单”和“捕捉整体”包含了合理性,而启发式“唤起配置的本质”包含了独特性。这些启发式方法还解决了发展构型理论的另一个核心挑战,即捕捉独特性和整体性。
(1)简明扼要
一个相关的风险是,构型理论“比传统的二元或相互作用理论复杂得多”。此外,正如范围界定部分所说明的那样,由于构型理论化可能建立在多种理论或学科之上,它冒着从多种研究传统中引入和混淆技术术语的风险,从而变得不必要的复杂。为了最大限度地降低这些风险,这种启发式的重点是在理论的口头表达中寻求简单性7——通过“沿着复杂性的阶梯向下移动”。虽然避免过度简化与结果相关的预期配置模式的理论争论很重要,但有影响力的配置理论应该是“灵感综合和强烈概念美感的产物”。这来自于标签和框架的主题,这些主题在配置内部和配置之间协调属性,我们通过简单性,我们指的是语法上的简单或优雅,即一个人的论点的数量和简洁性,而不是本体论上的简单或简约,即假设属性的数量和复杂性。
简单表达需要使用适当的语言,避免复杂解释的陷阱。同样,互补和替代效应也可以很容易地用简单的语言来描述。
(2)捕捉整体
如何才能最好地捕捉到支撑构型理论的总体逻辑?第一,启发式的“捕捉整体”强调了传达“中心组织主题”的重要性,这是理论化配置所共有的。第二,捕捉整体的一个重要步骤是给构型理论贴上标签,使中心组织主题透明。
(3)关注配置的本质特征
构型理论还需要注意每种构型的显著特征。这需要标记单个配置以及解释它们的编排主题,尽管这里的重点在于描述每个配置中的主题,而不是跨所有配置。标记配置的一个简单的启发式方法是考虑该配置的范例或“强实例”,即可能最接近理论配置的情况。想象典型的或强有力的案例代表一个配置帮助学者理论化其驱动,协调主题。极具影响力的构型理论的例子反映了清楚地唤起每种构型本质的方法。
对配置的描述性和唤起性标签的搜索也可以从“丰富的历史数据中受益,这些数据可以帮助研究人员发现驱动配置的主题。
(四)反馈循环理论化
构型理论化过程的阶段可能是递归的和迭代的,而不是严格顺序的。
第一种反馈循环涉及到学者们因为在联系阶段出现的想法而回到范围界定的情况。通过考虑属性的连接性、等性或缺失,学者们可能会发现所考虑的配置与结果之间的逻辑矛盾,促使他们重新指定最初确定的属性。第二种学者们可以通过反思他们在命名阶段设计的用于描述配置的标签和叙述来重新概念化在范围界定阶段确定的属性。命名也可能有助于形成第三种理论化反馈循环,促使学者重新思考连接和等终连接以及连接阶段考虑的缺席因素的作用。事实上,通过反思构型之间的异同,以及通过命名所阐明的每种构型的编排,学者们可能会意识到,根据它们在整体构型理论和单个构型中的作用,一些属性之间的联系可能需要重新概念化。综上所述,这三种类型的理论化反馈循环强调,学者们在构型理论化过程的每个阶段所积累的知识,可能会影响他们对其他阶段的属性和构型的思考。
三、思考
(1)构型理论化过程的模型,该模型由三个阶段组成——范围界定、链接和命名——并提供了三组启发式,旨在刺激每个阶段的构型思维。我们的模型和它的启发式旨在促进因果复杂现象的理论化,这样做的目标是使构型理论化更容易理解,然后具有科学意义。
(2)我们对构型理论化过程的关注强调,理论的发展本身就是一种实践,可以通过“经验法则”来促进不同的思维方式和促进发现。
(3)启发式命名方法与启发式命名法有相通之处。主题建模者将一致性——反映“清晰和界限良好的主题明显的分类标准”(Hannigan等人,2019:592)——视为一个重要的拟合指标。识别似是而非的连贯性的启发式意味着,连贯性可以被认为是比仅仅是一个度量更广泛。从结构上观察连贯性有助于证实任何紧急分类方案是否真正有意义,并表明协调主题。此外,主题建模者经常面临标记和理论化他们在分析中发现的维度的挑战。
(4)可以引入多种视觉手段是支持理论发展的重要途径。
相关文章:

QCA组态如何科学命名?
前言 (一)文献来源 文献来源:[1]Furnari S, Crilly D, Misangyi V F, et al. Capturing causal complexity: Heuristics for configurational theorizing[J]. Academy of Management Review, 2021, 46(4): 778-799. (二ÿ…...

外贸行业中常用的邮箱推荐
随着全球贸易的不断发展,外贸行业越来越重要。在这个过程中,电子邮件作为一种重要的沟通工具,扮演着关键的角色。然而,对于许多外贸从业者来说,选择合适的邮箱服务并不容易。本文将探讨外贸邮箱和普通邮箱的区别&#…...

高性能实践
1、认识性能 从用户体验来看,性能就是响应时间短; 从开发角度来看,性能主要是执行效率高。 性能主要表现形式如下: (1)响应时间,AVG、MAX、MIN、TP95、TP99 (2)吞吐…...

说说hashCode() 和 equals() 之间的关系?
每天一道面试题,陪你突击金九银十! 上一篇关于介绍Object类下的几种方法时面试题时,提到equals()和hashCode()方法可能引出关于“hashCode() 和 equals() 之间的关系?”的面试题,本篇来解析一下这道基础面试题。 先祭一…...

算法通关村-----图的基本算法
图的实现方式 邻接矩阵 定义 邻接矩阵是一个二维数组,其中的元素表示图中节点之间的关系。通常,如果节点 i 与节点 j 之间有边(无向图)或者从节点 i 到节点 j 有边(有向图),则矩阵中的元素值…...

基于随机森林+小型智能健康推荐助手(心脏病+慢性肾病健康预测+药物推荐)——机器学习算法应用(含Python工程源码)+数据集(二)
目录 前言总体设计运行环境Python环境依赖库 模块实现1. 疾病预测2. 药物推荐1)数据预处理2)模型训练及应用3)模型应用 其它相关博客工程源代码下载其它资料下载 前言 本项目基于Kaggle上公开的数据集,旨在对心脏病和慢性肾病进行…...
stm32学习-芯片系列/选型
【03】STM32HAL库开发-初识STM32 | STM概念、芯片分类、命名规则、选型 | STM32原理图设计、看数据手册、最小系统的组成 、STM32IO分配_小浪宝宝的博客-CSDN博客 STM32:ST是意法半导体,M是MCU/MPU,32是32位。 ST累计推出了:…...

LeetCode //C - 200. Number of Islands
200. Number of Islands Given an m x n 2D binary grid grid which represents a map of *‘1’*s (land) and *‘0’*s (water), return the number of islands. An island is surrounded by water and is formed by connecting adjacent lands horizontally or vertically…...

使用Python构建强大的网络爬虫
介绍 网络爬虫是从网站收集数据的强大技术,而Python是这项任务中最流行的语言之一。然而,构建一个强大的网络爬虫不仅仅涉及到获取网页并解析其HTML。在本文中,我们将为您介绍创建一个网络爬虫的过程,这个爬虫不仅可以获取和保存网…...

图像处理之《基于语义对象轮廓自动生成的生成隐写术》论文精读
一、相关知识 首先我们需要了解传统隐写和生成式隐写的基本过程和区别。传统隐写需要选定一幅封面图像,然后使用某种隐写算法比如LSB、PVD、DCT等对像素进行修改将秘密嵌入到封面图像中得到含密图像,通过信道传输后再利用算法的逆过程提出秘密信息。而生…...

Java 字节流
一、输入输出流 输入输出 ------- 读写文件 输入 ------- 从文件中获取数据到自己的程序中,接收处理【读】 输出 ------- 将自己程序中处理好的数据保存到文件中【写】 流 ------- 数据移动的轨迹 二、流的分类 按照数据的移动轨迹分为:输入流 输出流…...

华硕电脑怎么录屏?分享实用录制经验!
“华硕电脑怎么录屏呀,刚买的笔记本电脑,是华硕的,自我感觉挺好用的,但是不知道怎么录屏,最近刚好要录一个教程,怎么都找不到在哪里录制,有人能教教我吗?” 随着电脑技术的不断发展…...

python学习--python的异常处理机制
try…except try:n1int(input(请输入一个整数))n2int(input(请输入另一个整数))resultn1/n2print(结果为,result) except ZeroDivisionError: print(除数不能为0)try…except…else 如果try块中没有抛出异常,则执行else块,如果try中抛出异常࿰…...
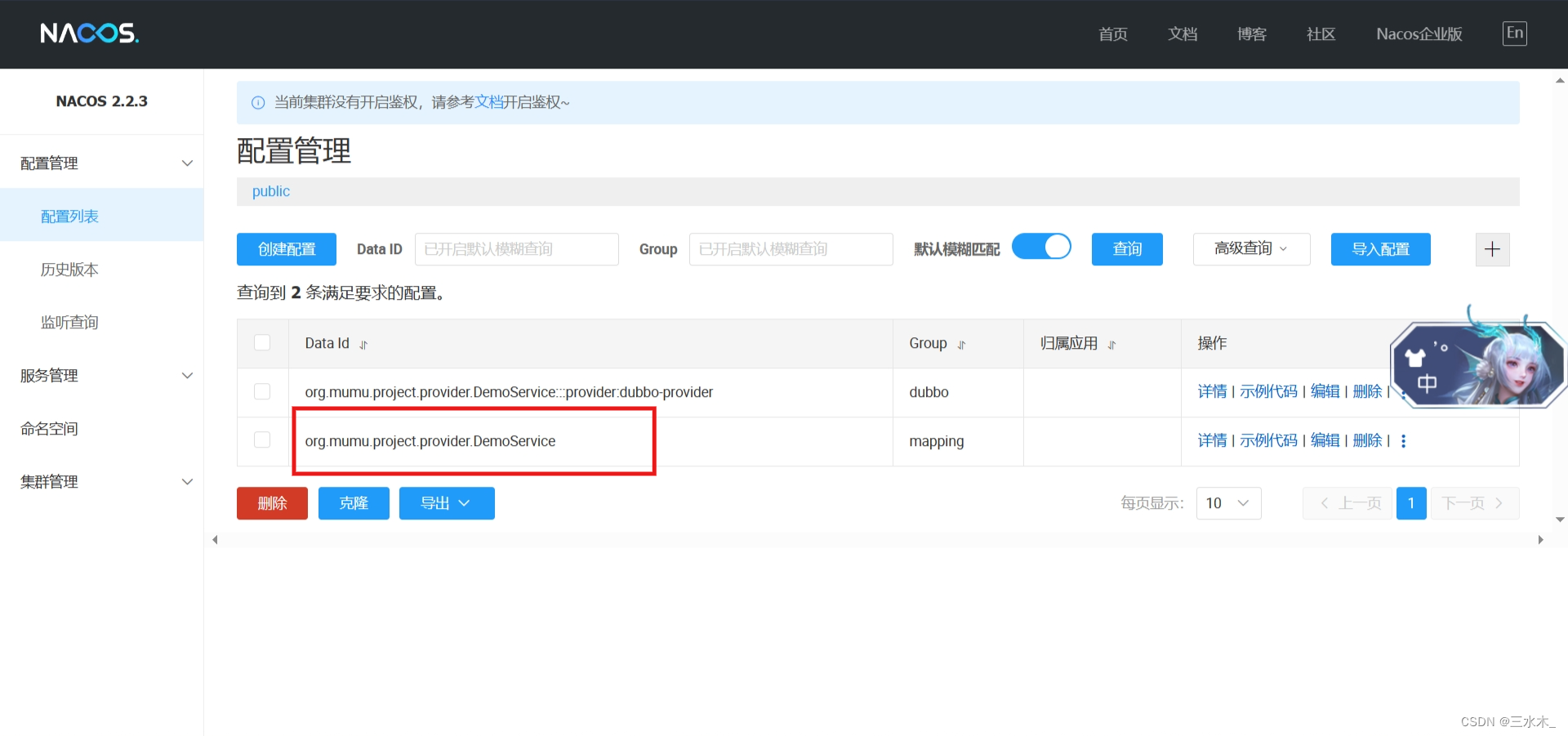
nacos+Dubbo整合快速入门
官网:Nacos Spring Boot 快速开始 下载下载链接启动:进入bin目录,startup.cmd -m standalone引入依赖 <dependency><groupId>org.apache.dubbo</groupId><artifactId>dubbo</artifactId><version>3.0.9…...
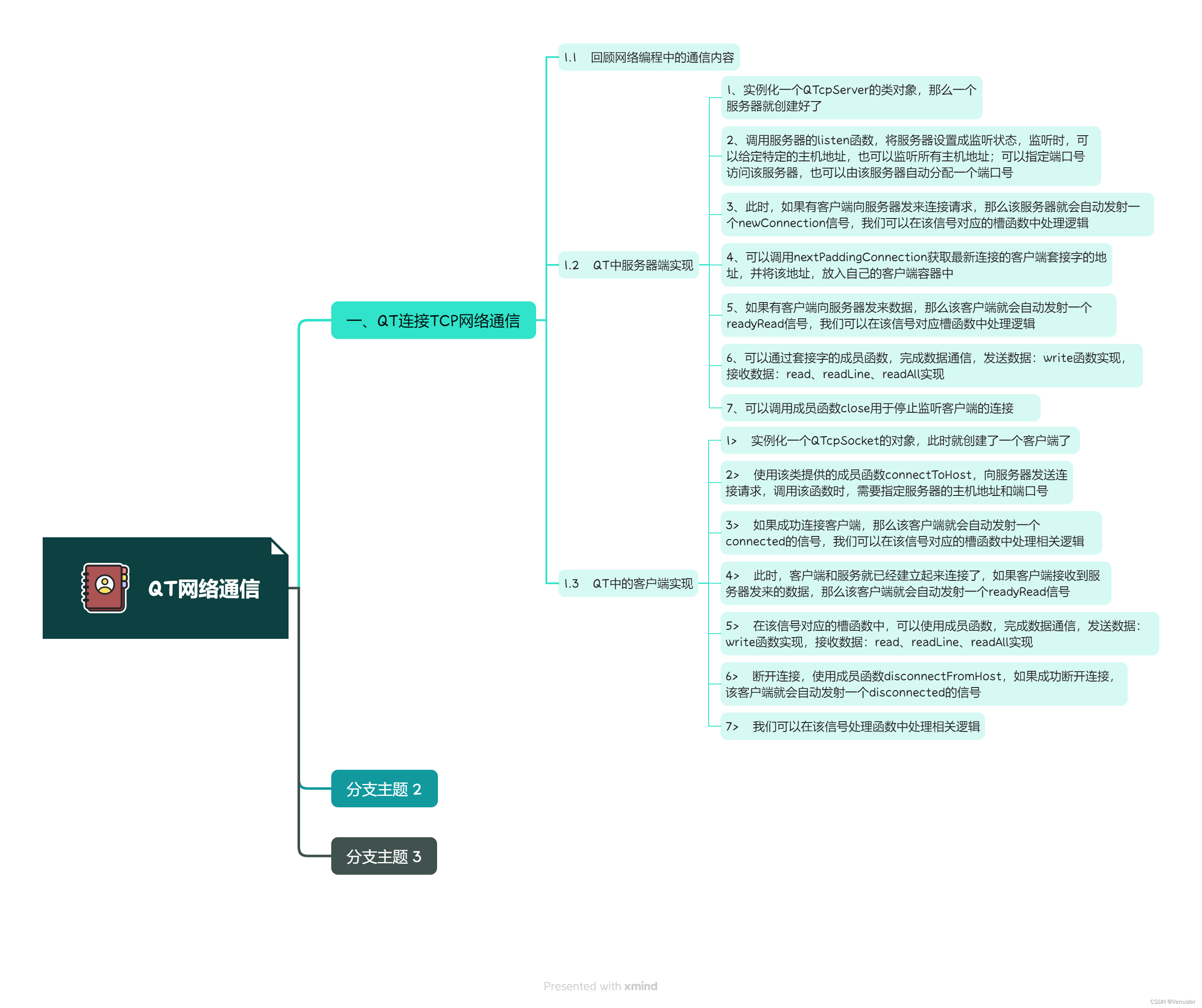
QT实现钟表
1、 头文件 #ifndef MAINWINDOW_H #define MAINWINDOW_H#include <QMainWindow> #include <QPaintEvent> //绘制事件类 #include <QDebug> //信息调试类 #include <QPainter> //画家类 #include <QTimerEve…...
准备我们心爱的IDEA写Jsp
JSP学习 一、准备我们心爱的IDEA new一个项目:New Project --> Next -->Next -->Finsh 二、配置好服务器Tomcat-9.0.30 1.> 在WEB-INF下创建一个Lib包 将jsp-api.jar复制进去,并使其生效 未生效前: 生效过程: 2.>…...
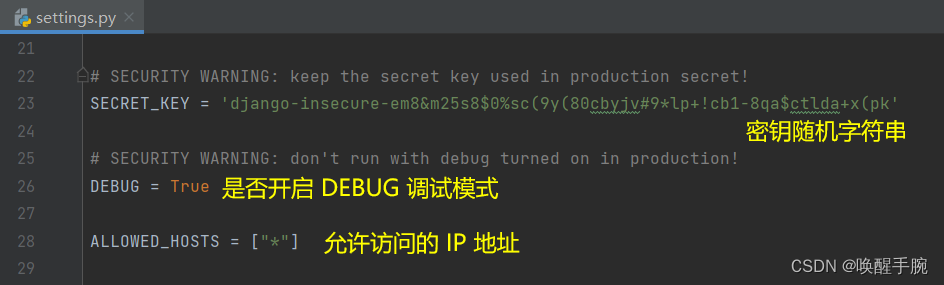
将近 5 万字讲解 Python Django 框架详细知识点(更新中)
Django 框架基本概述 Django 是一个开源的 Web 应用后端框架,由 Python 编写。它采用了 MVC 的软件设计模式,即模型(Model)、视图(View)和控制器(Controller)。在 Django 框架中&am…...
Arcgis提取每个像元的多波段反射率值
Arcgis提取每个像元的多波段反射率值 数据预处理 数据预处理阶段需要对遥感图像进行编辑传感器参数、辐射定标、大气校正、正射校正,具体流程见该文章 裁剪研究区 对于ENVI处理得到的tiff影像,虽然是经过裁剪了,但是还存在黑色的背景值&a…...
)
JavaScript面试题整理(一)
数据类型篇 1、JavaScript有哪些数据类型,它们的区别是什么? 基本数据类型:number、string、boolean、undefined、NaN、BigInt、Symbol 引入数据类型:Object NaN是JS中的特殊值,表示非数字,NaN不是数字…...

数据结构:树和二叉树之-堆排列 (万字详解)
目录 树概念及结构 1.1树的概念 1.2树的表示 编辑2.二叉树概念及结构 2.1概念 2.2数据结构中的二叉树:编辑 2.3特殊的二叉树: 编辑 2.4 二叉树的存储结构 2.4.1 顺序存储: 2.4.2 链式存储: 二叉树的实现及大小堆…...

GAIA-DataSet:如何构建下一代AIOps智能运维的黄金基准?
GAIA-DataSet:如何构建下一代AIOps智能运维的黄金基准? 【免费下载链接】GAIA-DataSet GAIA, with the full name Generic AIOps Atlas, is an overall dataset for analyzing operation problems such as anomaly detection, log analysis, fault local…...

从数据到角度:手把手调试大疆C板BMI088,解决姿态解算精度跳动的那些坑
从数据到角度:手把手调试大疆C板BMI088,解决姿态解算精度跳动的那些坑 调试嵌入式系统中的传感器数据,尤其是姿态解算这类对精度要求极高的应用,往往需要开发者具备跨领域的知识储备和丰富的实战经验。本文将分享我在使用大疆C板搭…...

Obsidian Importer:一站式笔记数据迁移终极指南
Obsidian Importer:一站式笔记数据迁移终极指南 【免费下载链接】obsidian-importer Obsidian Importer lets you import notes from other apps and file formats into your Obsidian vault. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-importer …...

利用 Taotoken 模型广场为不同智能体任务选择合适的模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 模型广场为不同智能体任务选择合适的模型 在设计多智能体系统时,一个常见的挑战是如何为系统中承担不同…...
)
避开这3个坑,你的MAX30102心率数据才准确(Arduino实测经验)
避开这3个坑,你的MAX30102心率数据才准确(Arduino实测经验) 在可穿戴设备和健康监测领域,MAX30102传感器因其集成度高、体积小巧而广受欢迎。但许多开发者在使用过程中常遇到数据不稳定、读数漂移等问题。本文将基于实际项目经验&…...

Windows Cleaner:解决C盘爆红问题的3个高效方法
Windows Cleaner:解决C盘爆红问题的3个高效方法 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 当您的Windows电脑C盘突然变红,可用空间告…...

歌词滚动姬:免费网页版LRC歌词制作工具终极指南
歌词滚动姬:免费网页版LRC歌词制作工具终极指南 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 还在为制作精准的LRC歌词而烦恼吗?歌词滚动姬…...

Vue 3侧边栏菜单完整指南:快速构建现代化管理后台导航系统
Vue 3侧边栏菜单完整指南:快速构建现代化管理后台导航系统 【免费下载链接】vue-sidebar-menu A Vue.js Sidebar Menu Component 项目地址: https://gitcode.com/gh_mirrors/vu/vue-sidebar-menu 在Vue.js生态中,Vue侧边栏菜单组件(vu…...

OpenClaw爬虫框架Docker化实践:从环境封装到生产部署
1. 项目概述:当“OpenClaw”遇见Docker最近在折腾一个挺有意思的项目,叫“OpenClaw”。这名字听起来有点酷,对吧?它本质上是一个网络爬虫框架,但设计理念和常见的Scrapy、Puppeteer这些不太一样。OpenClaw更侧重于“规…...

终极免费打字练习软件Qwerty Learner:提升英语输入速度的完整指南
终极免费打字练习软件Qwerty Learner:提升英语输入速度的完整指南 【免费下载链接】qwerty-learner 为键盘工作者设计的单词记忆与英语肌肉记忆锻炼软件 / Words learning and English muscle memory training software designed for keyboard workers 项目地址: …...