堆的OJ题
🔥🔥 欢迎来到小林的博客!!
🛰️博客主页:✈️林 子
🛰️博客专栏:✈️ 小林的算法笔记
🛰️社区 :✈️ 进步学堂
🛰️欢迎关注:👍点赞🙌收藏✍️留言
目录
- 703. 数据流中的第 K 大元素
- 692. 前K个高频单词
- 295. 数据流的中位数
703. 数据流中的第 K 大元素
题目链接:703. 数据流中的第 K 大元素
题目描述:
设计一个找到数据流中第 k 大元素的类(class)。注意是排序后的第 k 大元素,不是第 k 个不同的元素。
请实现 KthLargest 类:
KthLargest(int k, int[] nums)使用整数k和整数流nums初始化对象。int add(int val)将val插入数据流nums后,返回当前数据流中第k大的元素。
示例:
输入:
["KthLargest", "add", "add", "add", "add", "add"]
[[3, [4, 5, 8, 2]], [3], [5], [10], [9], [4]]
输出:
[null, 4, 5, 5, 8, 8]解释:
KthLargest kthLargest = new KthLargest(3, [4, 5, 8, 2]);
kthLargest.add(3); // return 4
kthLargest.add(5); // return 5
kthLargest.add(10); // return 5
kthLargest.add(9); // return 8
kthLargest.add(4); // return 8
提示:
1 <= k <= 1040 <= nums.length <= 104-104 <= nums[i] <= 104-104 <= val <= 104- 最多调用
add方法104次 - 题目数据保证,在查找第
k大元素时,数组中至少有k个元素
解题思路: 这一题是典型的topK问题,第K大我们可以建小堆。第K小我们可以建大堆。为什么要这样呢?因为建小堆的话,我们的堆顶就是最小的。我Top一个后,新的堆顶就是倒数第二小的。当我们的堆只有的元素只有K个的时候。那么堆顶的元素就是 nums.size - k小的。反过来就是第K大的。nums这里指的是整个数组。
假设整个数组的大小为 7 , k 为6。 那么当堆的大小为6时,堆顶的元素就是 nums.size - 1(nums.size - heap.size)。也就是第6大的数。所以,TOPK问题找第K大建小堆,找第K小建大堆,我们要反着来。虽然正着来也可以解决单纯的topK问题,但是这一题是有add操作的,如果正着来。那么前面pop掉最大的数据就丢失了。而最小的数据却没有关系,因为小堆存的是最大的K个数。堆顶是最大K个数中最小的一个。

所以这一题我们可以建一个小堆。然后把nums所有的数push进去,最后再把堆pop到K的大小。而每次add就push一次,再pop一次,即可维持堆的大小为K。
代码:
class KthLargest {
public:priority_queue<int,vector<int>,greater<int>> _min_heap;int _k;KthLargest(int k, vector<int>& nums) {_k = k ;for(auto& n : nums)_min_heap.push(n); while(_min_heap.size() > k) _min_heap.pop();}int add(int val) {_min_heap.push(val);if(_min_heap.size() > _k) _min_heap.pop();return _min_heap.top();}
};
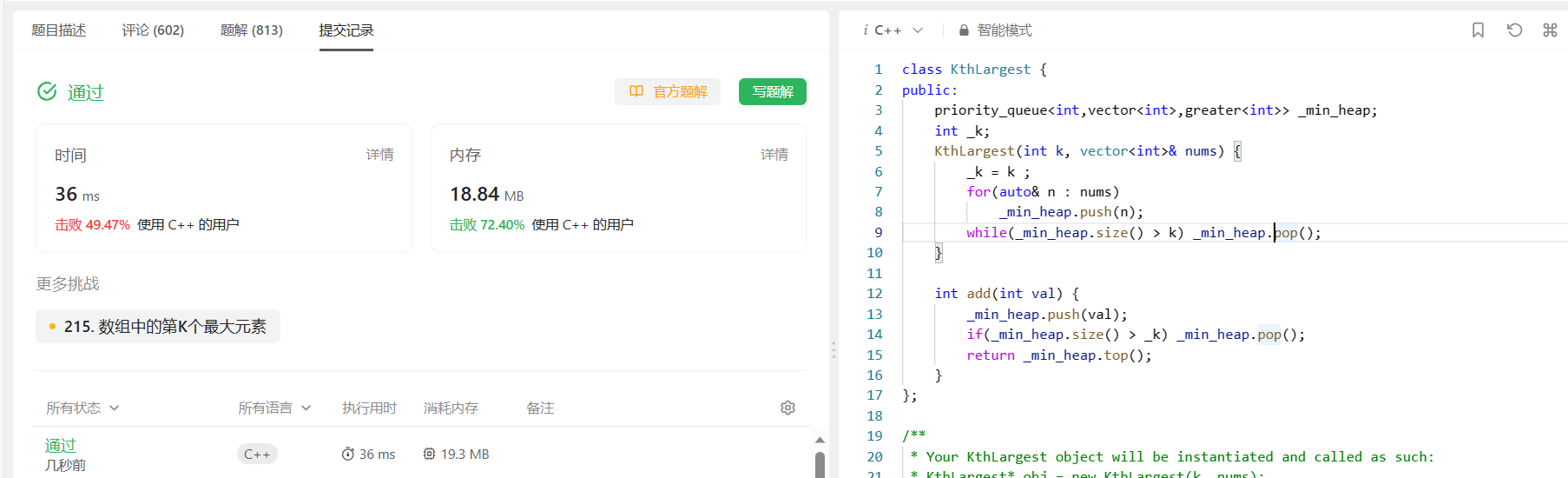
运行结果:
692. 前K个高频单词
题目链接: 692. 前K个高频单词
题目描述:
给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。
示例 1:
输入: words = ["i", "love", "leetcode", "i", "love", "coding"], k = 2
输出: ["i", "love"]
解析: "i" 和 "love" 为出现次数最多的两个单词,均为2次。注意,按字母顺序 "i" 在 "love" 之前。
示例 2:
输入: ["the", "day", "is", "sunny", "the", "the", "the", "sunny", "is", "is"], k = 4
输出: ["the", "is", "sunny", "day"]
解析: "the", "is", "sunny" 和 "day" 是出现次数最多的四个单词,出现次数依次为 4, 3, 2 和 1 次。
注意:
1 <= words.length <= 5001 <= words[i] <= 10words[i]由小写英文字母组成。k的取值范围是[1, **不同** words[i] 的数量]
**进阶:**尝试以 O(n log k) 时间复杂度和 O(n) 空间复杂度解决。
解题思路:
首先这一题有2个关键点,第一点是按频次比较。第二点是频次相同时,按字母序排序。所以这里我们要一个哈希表来统治所有字符串出现的次数。然后再把哈希表的这一对key,value值入堆,而堆的大小也和上题一样设置为K个。因为频次取前K个,所以我们对频次用小根堆排。但是频次相同的字符串又要按字母序排,所以对字母序排序我们又要用大堆。
比如第一个用例。我们用堆排好序是这样的。频次用小根堆排,而频次相同,我们则按大根堆对string排。
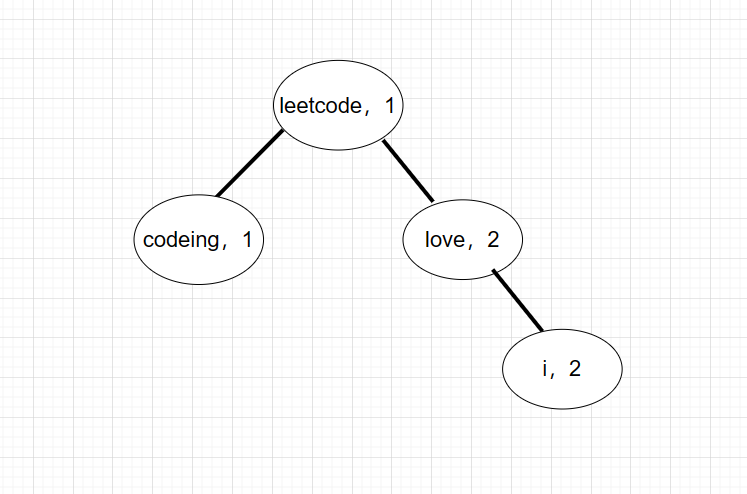
而因为我们的K为2,所以堆的大小只能是2。最后变成这样。

而此时我TOP得到的是字母序较大的值,所以我们在把堆的值填入返回的string数组时需要倒着填,因为小的要放在前面。
要实现这种排序,我们需要自己写一个cmp函数,作为priority_queue的第三个模板参数。
代码:
class Solution {typedef pair<string,int> PSI; //排序的仿函数struct cmp{bool operator()(const PSI& a ,const PSI& b){if(a.second == b.second){//频次相同,用大根堆排return a.first < b.first; //小的放下面}return a.second > b.second; //小根堆排,大的放下面}};public:vector<string> topKFrequent(vector<string>& words, int k) {unordered_map<string,int> map; //1.统计所有字符出现次数for(auto& word : words) map[word]++; //2.将哈希表所有元素入堆priority_queue<PSI,vector<PSI>,cmp> heap; for(auto& it : map) heap.push({it.first,it.second}); //堆的大小只能为k while(heap.size() > k) heap.pop(); //将堆的元素逆序放到ret数组中vector<string> ret(k); for(int i = k - 1; i >= 0 ; i--){//将堆顶字符串放在数组的尾部,逆序放ret[i] = heap.top().first;heap.pop();}return ret;}
};
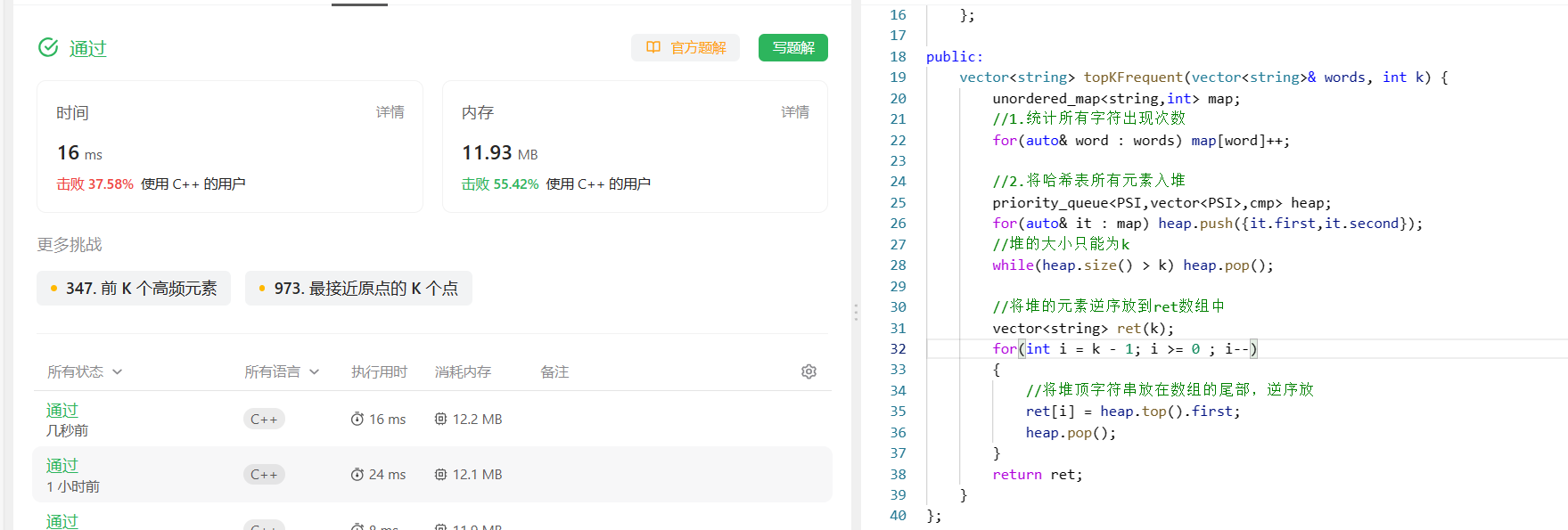
运行结果:
295. 数据流的中位数
题目链接:[295. 数据流的中位数
题目描述:
中位数是有序整数列表中的中间值。如果列表的大小是偶数,则没有中间值,中位数是两个中间值的平均值。
- 例如
arr = [2,3,4]的中位数是3。 - 例如
arr = [2,3]的中位数是(2 + 3) / 2 = 2.5。
实现 MedianFinder 类:
MedianFinder()初始化MedianFinder对象。void addNum(int num)将数据流中的整数num添加到数据结构中。double findMedian()返回到目前为止所有元素的中位数。与实际答案相差10-5以内的答案将被接受。
示例 1:
输入
["MedianFinder", "addNum", "addNum", "findMedian", "addNum", "findMedian"]
[[], [1], [2], [], [3], []]
输出
[null, null, null, 1.5, null, 2.0]解释
MedianFinder medianFinder = new MedianFinder();
medianFinder.addNum(1); // arr = [1]
medianFinder.addNum(2); // arr = [1, 2]
medianFinder.findMedian(); // 返回 1.5 ((1 + 2) / 2)
medianFinder.addNum(3); // arr[1, 2, 3]
medianFinder.findMedian(); // return 2.0
提示:
-105 <= num <= 105- 在调用
findMedian之前,数据结构中至少有一个元素 - 最多
5 * 104次调用addNum和findMedian
解题思路:
题目是找中位数,那么我们可以用2个堆。一个大堆,一个小端。大于中位数的值放小堆里面,小于等于中位数的值放大堆里面。我们只需要保证两个堆的大小相等,或者大堆的大小比小堆大1。每当一次add操作时,我们先判断两个堆大小是否相等。如果相等,则说明要往大堆push数据,那么我们先把num放进小堆,再取小堆的堆顶放入大堆,这样大堆的长度就+1了。如果不相等,说明大堆的大小比小堆大1,那么我们要往小堆push数据,所以我们先把num放进大堆,再取大堆的堆顶放入小堆。
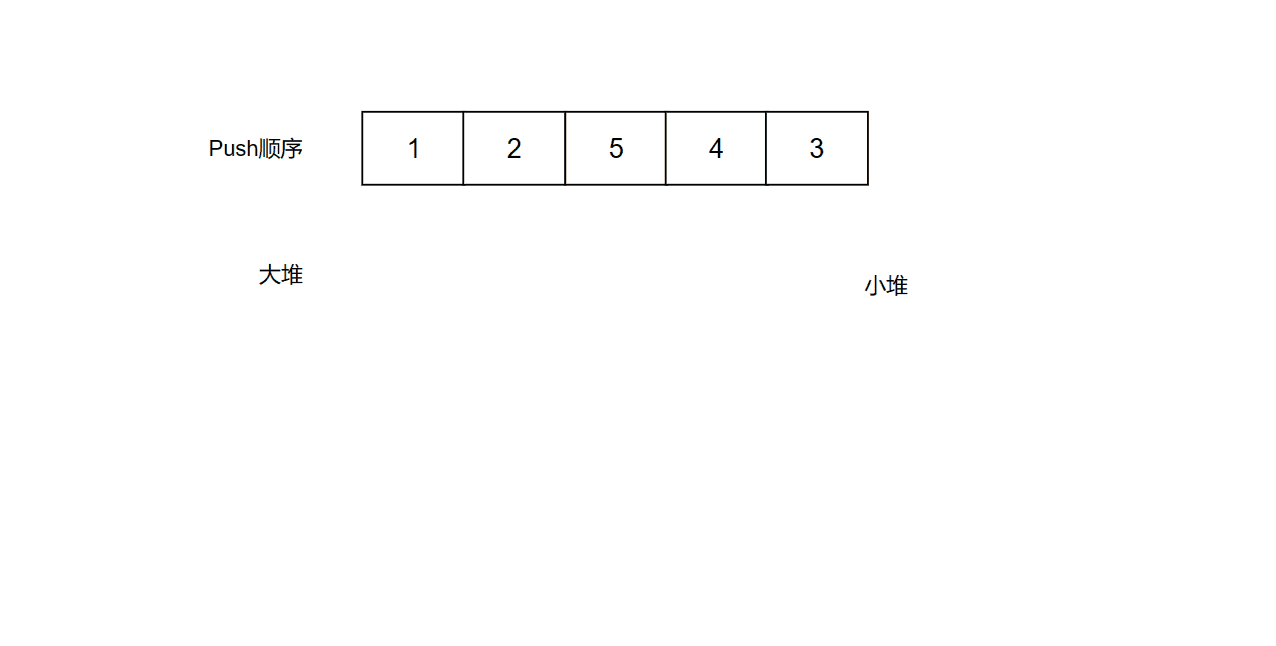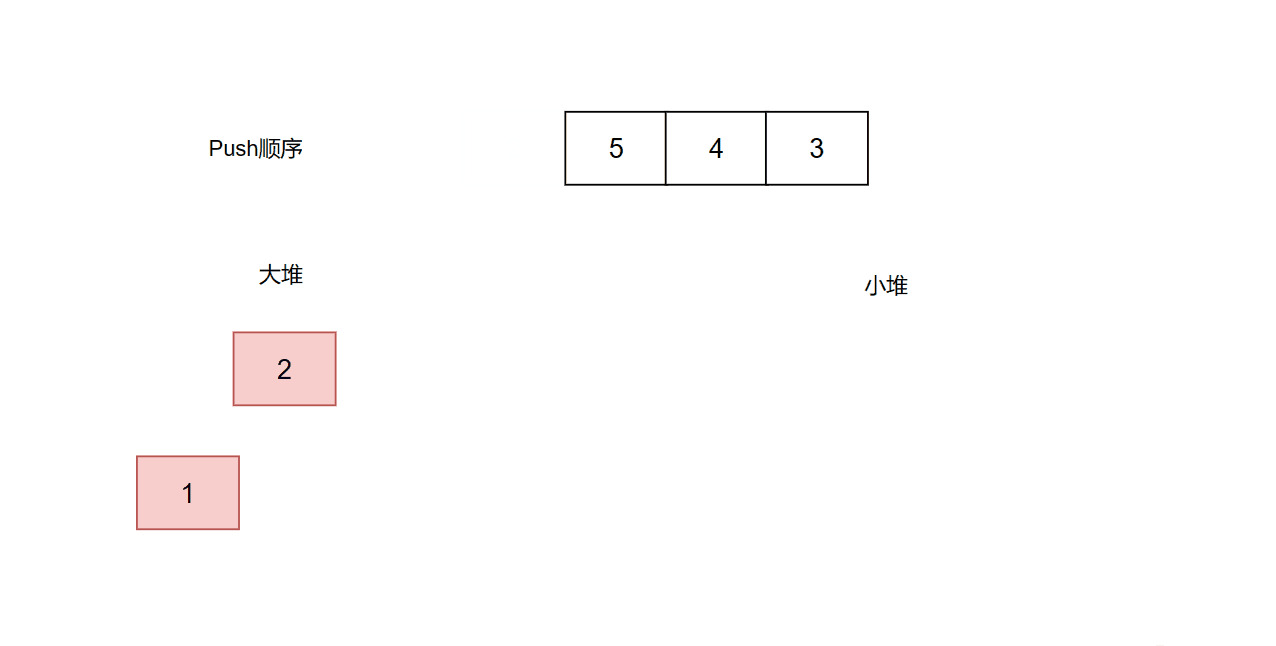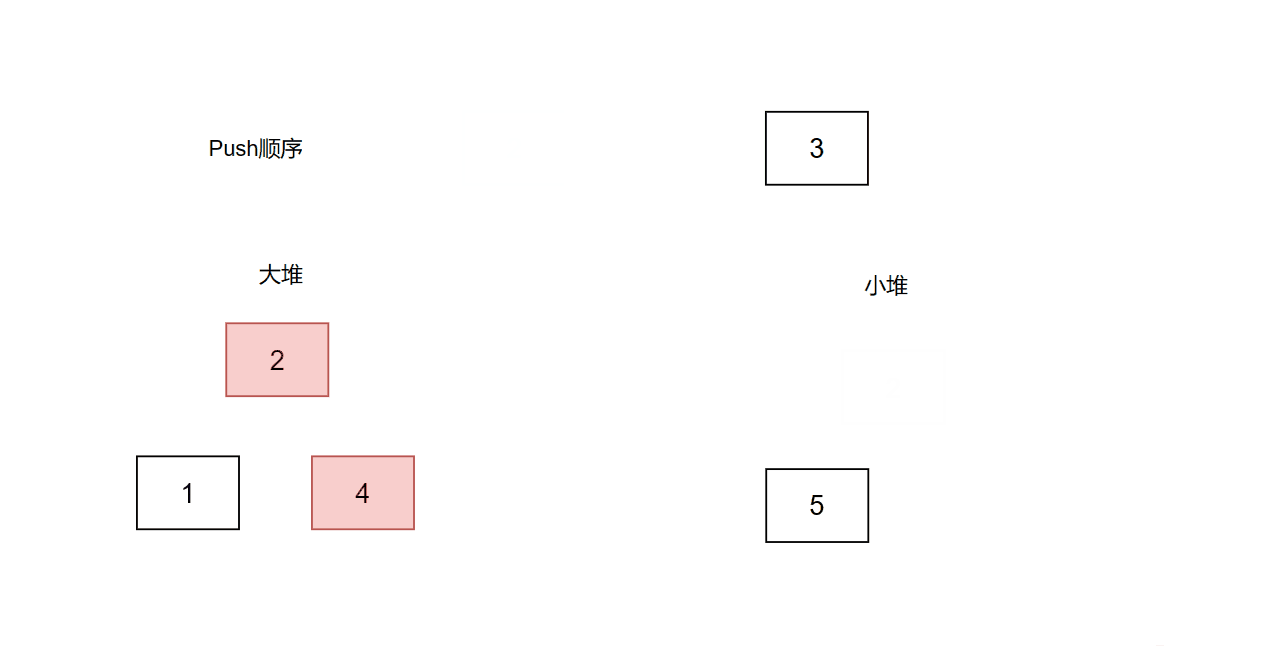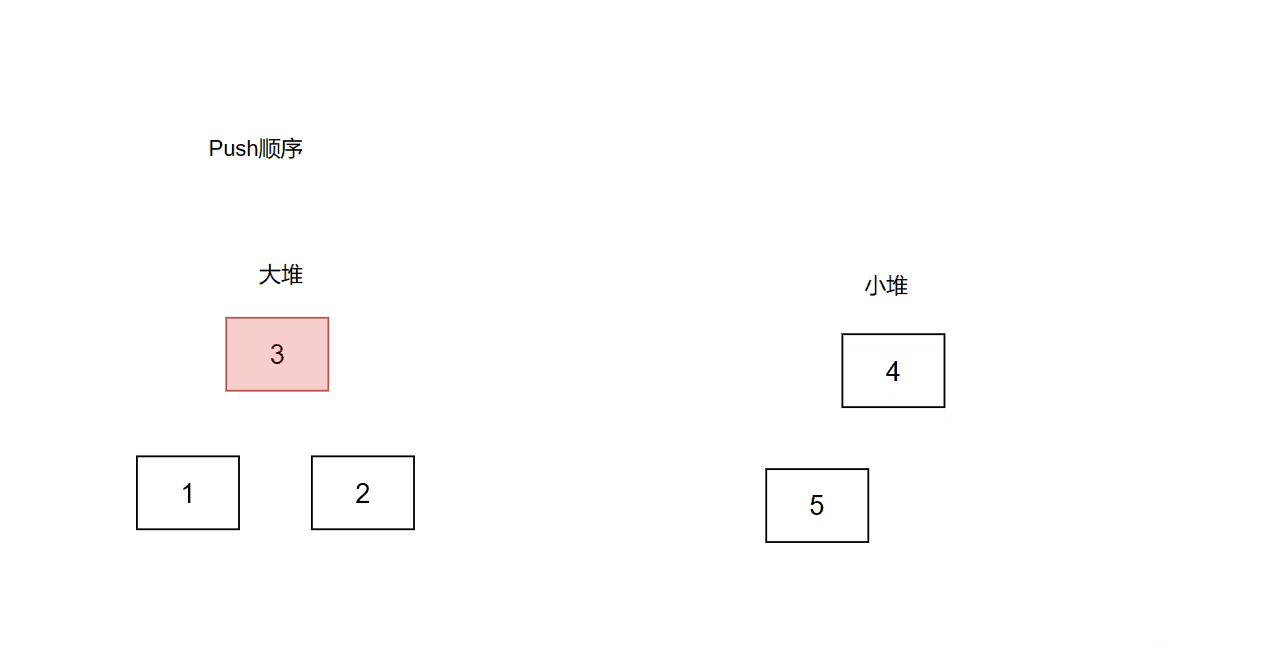
代码:
class MedianFinder {
public:priority_queue<int,vector<int>,greater<int>> _less_heap;//小堆priority_queue<int,vector<int>,less<int>> _greater_heap;//大堆MedianFinder() {}void addNum(int num) {if(_greater_heap.size() == 0){//第一次插入,直接入大堆_greater_heap.push(num); return; }//其他次插入,判断俩个堆的大小if(_greater_heap.size() == _less_heap.size()){//两个堆的大小相等,则放进大堆,不过需要先把num放进小堆,取小堆的堆顶放入大堆_less_heap.push(num);int top = _less_heap.top();_less_heap.pop();_greater_heap.push(top); }else {//两个堆大小不相等,则说明大堆多一个,把num放进大堆,取大堆的堆顶放入小堆,俩个堆的大小则平衡_greater_heap.push(num); int top = _greater_heap.top();_greater_heap.pop();_less_heap.push(top);}}double findMedian() {//如果俩个堆大小相等,返回堆顶和 /2 ,反之返回大堆堆顶if(_less_heap.size() == _greater_heap.size())return (_less_heap.top() + _greater_heap.top()) / 2.0; return _greater_heap.top();}
};运行结果:
相关文章:
堆的OJ题
🔥🔥 欢迎来到小林的博客!! 🛰️博客主页:✈️林 子 🛰️博客专栏:✈️ 小林的算法笔记 🛰️社区 :✈️ 进步学堂 &am…...

物联网网关:连接设备与云端的桥梁
物联网网关作为连接设备与云端的桥梁,承担着采集数据、设备远程控制、协议转换、数据传输等重要任务。物联网网关是一种网络设备,它可以连接多个物联网设备,实现设备之间的数据传输和通信。物联网网关通常具有较高的网络带宽和处理能力&#…...

ChatGPT企业版来了,速度翻倍,无使用限制
美国时间8月28日,OpenAI宣布了自ChatGPT推出以来最重大的新闻:将推出ChatGPT企业版,企业版ChatGPT将直接对接GPT-4,提供无限制访问、高级数据分析功能、定制服务等服务,并支持处理更长文本输入的长上下文窗口。 OpenAI…...

opencv图像像素类型转换与归一化
文章目录 opencv图像像素类型转换与归一化1、为什么对图像像素类型转换与归一化2、在OpenCV中,convertTo() 和 normalize() 是两个常用的图像处理函数,用于图像像素类型转换和归一化;(1)convertTo() 函数用于将一个 cv…...
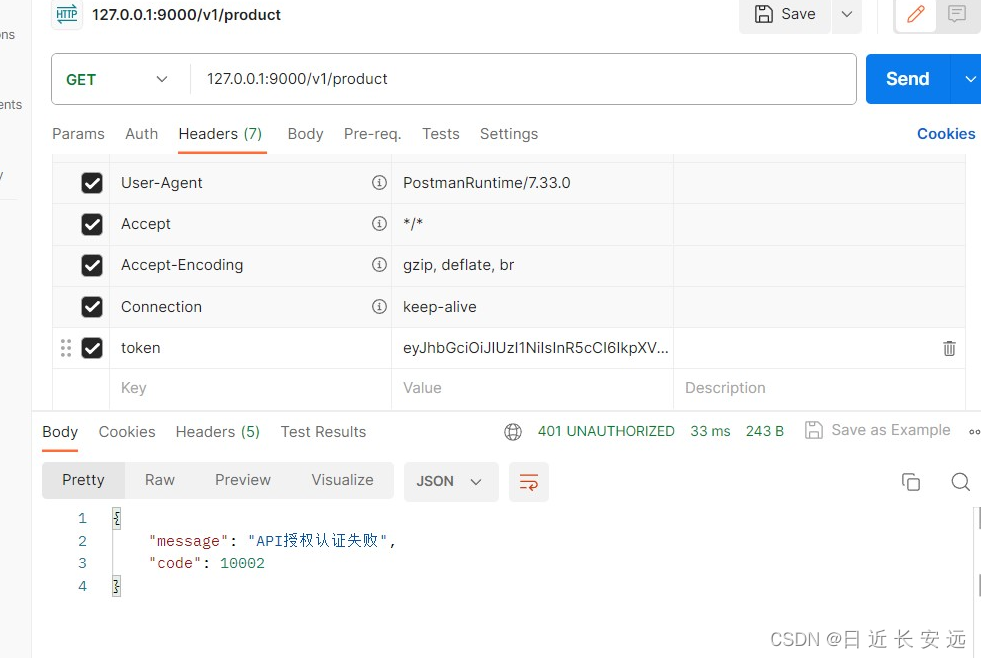
【自学开发之旅】Flask-前后端联调-异常标准化返回(六)
注册联调: 前端修改: 1.修改请求向后端的url地址 文件:env.development修改成VITE_API_TARGET_URL http://127.0.0.1:9000/v1 登录:token验证 校验forms/user.py from werkzeug.security import check_password_hash# 登录校验…...
springcloud3 分布式事务解决方案seata之XA模式4
一 seata的模式 1.1 seata的几种模式比较 Seata基于上述架构提供了四种不同的分布式事务解决方案: XA模式:强一致性分阶段事务模式,牺牲了一定的可用性,无业务侵入 TCC模式:最终一致的分阶段事务模式,有…...
编译ctk源码
目录 前景介绍 下载The Common Toolkit (CTK) cmake-gui编译 vs2019生成 debug版本 release版本 前景介绍 CTK(Common Toolkit)是一个用于医学图像处理和可视化应用程序开发的工具集,具有以下特点: 基于开源和跨平台的Qt框…...
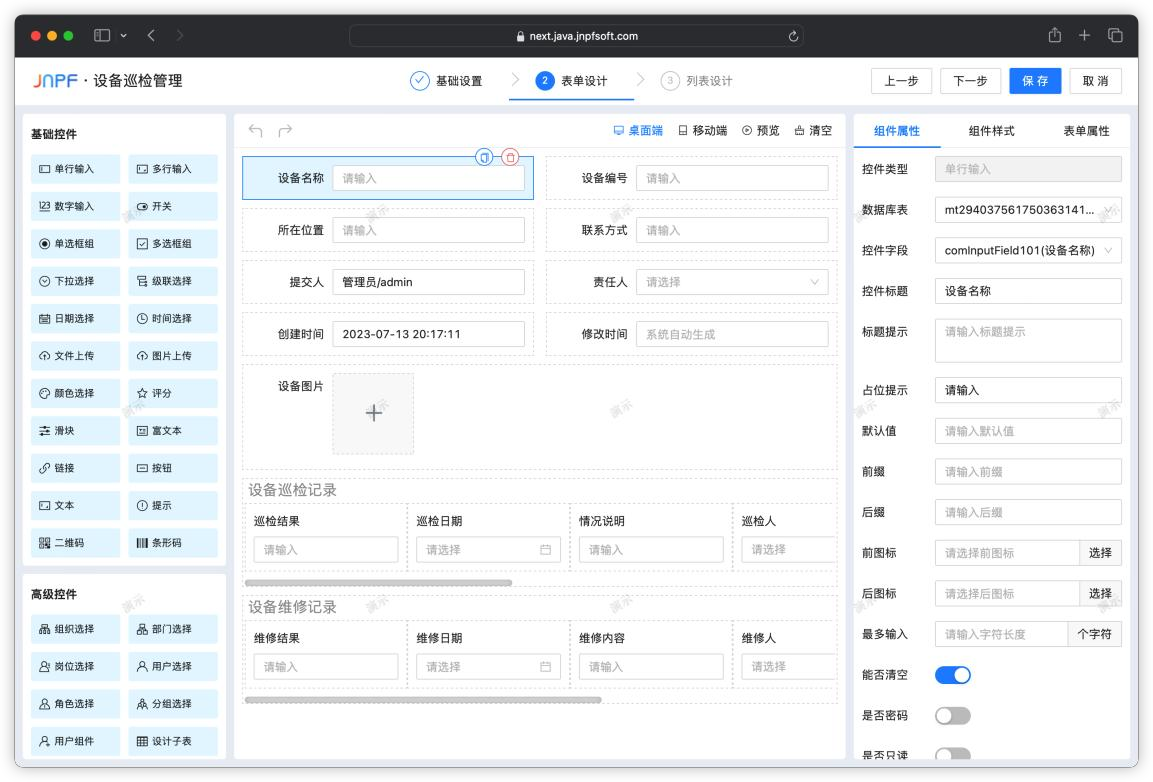
前后端分离的低代码快速开发框架
低代码开发正逐渐成为企业创新的关键工具。通过提高开发效率、降低成本、增强灵活性以及满足不同用户需求,低代码开发使企业能够快速响应市场需求,提供创新解决方案。选择合适的低代码平台,小成本组建一个专属于你的应用。 项目简介 这是一个…...

【Java 基础篇】Java同步代码块解决数据安全
多线程编程是现代应用程序开发中的常见需求,它可以提高程序的性能和响应能力。然而,多线程编程也带来了一个严重的问题:数据安全。在多线程环境下,多个线程同时访问和修改共享的数据可能导致数据不一致或损坏。为了解决这个问题&a…...

亿纬锦能项目总结
项目名称:亿纬锦能 项目链接:https://www.evebattery.com 项目概况: 此项目用到了 wow.js/slick.js/swiper-bundle.min.js/animate.js/appear.js/fullpage.js以及 slick.css/animate.css/fullpage.css/swiper-bundle.min.css/viewer.css 本项目是一种…...
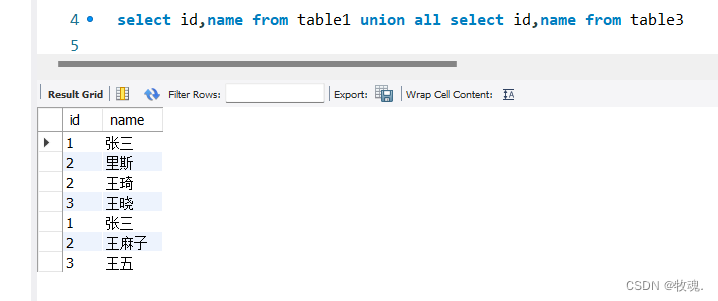
简明 SQL 组合查询指南:掌握 UNION 实现数据筛选
在SQL中,组合查询是一种将多个SELECT查询结果合并的操作,通常使用UNION和UNION ALL两种方式。 UNION 用于合并多个查询结果集,同时去除重复的行,即只保留一份相同的数据。UNION ALL 也用于合并多个查询结果集,但不去除…...

【springMvc】自定义注解的使用方式
🎬 艳艳耶✌️:个人主页 🔥 个人专栏 :《Spring与Mybatis集成整合》 ⛺️ 生活的理想,为了不断更新自己 ! 1.前言 1.1.什么是注解 Annontation是Java5开始引入的新特征,中文名称叫注解。 它提供了一种安全…...
求二维子数组的和(剖析)
文章目录 🐒个人主页🏅JavaSE系列专栏📖前言:本篇剖析一下二维子数组求和规则: 🐒个人主页 🏅JavaSE系列专栏 📖前言:本篇剖析一下二维子数组求和 规则: 这…...
代码开发思路介绍)
无(低)代码开发思路介绍
无代码或者低代码开发的思路,是通过非编程代码,而是基于页面拖拉拽的方式来实现创建web应用的功能。 作为程序员我们知道私有云公有云已经实现了基础设施的web方式管理。DEVOPS把代码发布,管理也实现了web方式管理。那么我们很容易能够想到,只要把拖拉拽出来的项目自动化部…...

代码随想录刷题 Day14
144.二叉树的前序遍历(opens new window) 要注意下创建函数参数传递不是很理解 class Solution { public:void tranversal(TreeNode* s, vector<int> &b) {if (s NULL) {return;}b.push_back(s->val);tranversal(s->left, b);tranversal(s->right, b);}v…...

二分类问题的解决利器:逻辑回归算法详解(一)
文章目录 🍋引言🍋逻辑回归的原理🍋逻辑回归的应用场景🍋逻辑回归的实现 🍋引言 逻辑回归是机器学习领域中一种重要的分类算法,它常用于解决二分类问题。无论是垃圾邮件过滤、疾病诊断还是客户流失预测&…...

docker alpine镜像中遇到 not found
1.问题: docker alpine镜像中遇到 sh: xxx: not found 例如 # monerod //注:此可执行文件已放到/usr/local/bin/ sh: monerod: not found2.原因 由于alpine镜像使用的是musl libc而不是gnu libc,/lib64/ 是不存在的。但他们是兼容的&…...

python的多线程多进程与多协程
python的多线程是假多线程,本质是交叉串行,并不是严格意义上的并行,或者可以这样说,不管怎么来python的多线程在同一时间有且只有一个线程在执行(举个例子,n个人抢一个座位,但是座位就这一个,不…...

一文介绍使用 JIT 认证后实时同步用户更加优雅
首先本次说的 JIT 指的是 Just In Time ,可以理解为及时录入,一般用在什么样的场景呢? 还记的上次我们说过关于第三方组织结构同步的功能实现,主要目的是将第三方源数据同步到内部平台中来,方便做管控和处理 此处的管…...

搞定“项目八怪”,你就是管理高手!
大家好,我是老原。 玛丽.弗列特说:“权力已经逐渐被视为一个群体的组合能力。我们通过有效联系获取力量。” 有效联系也就是指的沟通,这个部分占据我们项目经理工作内容的80%,可见沟通在项目管理中的重要性。 项目经理的沟通包…...
)
数据结构第8章查找:单元测试15题全解析(顺序查找+折半查找+分块查找+哈希查找)
第8章 查找 单元测试1. 线性表只有以( A )方式存储,才能进行折半查找。A. 顺序B. 链接C. 二叉树D. 关键字有序的2. 有序表为{2,4,10,13,33,42,46,64&#x…...

如何快速掌握unnpk:网易游戏资源解包的完整入门指南
如何快速掌握unnpk:网易游戏资源解包的完整入门指南 【免费下载链接】unnpk 解包网易游戏NeoX引擎NPK文件,如阴阳师、魔法禁书目录。 项目地址: https://gitcode.com/gh_mirrors/un/unnpk 你是否曾经好奇过网易游戏《阴阳师》中那些精美的角色立绘…...

WordPress Playground部署实战:从开发到生产的完整流程指南
WordPress Playground部署实战:从开发到生产的完整流程指南 【免费下载链接】wordpress-playground Run WordPress in the browser via WebAssembly PHP 项目地址: https://gitcode.com/gh_mirrors/wo/wordpress-playground WordPress Playground 是一个革命…...

别再为前后端AES加解密头疼了!手把手教你用CryptoJS和Java 8实现无缝对接
跨平台AES加解密实战:打通CryptoJS与Java的密钥对齐与编码陷阱 前后端分离架构下,数据安全传输始终是开发者的核心关切。当看到控制台抛出javax.crypto.BadPaddingException: Given final block not properly padded这类错误时,多数开发者都会…...
)
SpringBoot3 + ShardingJDBC读写分离进阶:如何用AOP实现强制走主库(@Master注解实战)
SpringBoot3 ShardingJDBC读写分离进阶:如何用AOP实现强制走主库(Master注解实战) 在分布式数据库架构中,读写分离是提升系统吞吐量的常见方案。但当你的SpringBoot3应用已经配置好ShardingJDBC的基础读写分离功能后,…...
)
【无人机三维路径规划】基于遗传算法GA实现复杂山地环境下无人机三维路径规划研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

`SaveKeyDataAsync` 重构优化版本
✅ SaveKeyDataAsync 重构优化版本 以下是针对 StationRepository 中 SaveKeyDataAsync 方法的完整重构,包含生产级最佳实践。 1. 重构后的 StationRepository.cs(重点方法) // MaxWell.Repository/StationRepository.cs using Microsoft.Ent…...

CircuitPython嵌入式开发实战:内存管理、BLE通信与异步编程优化
1. 项目概述:CircuitPython开发中的核心挑战与应对思路 在嵌入式硬件开发领域,CircuitPython以其对Python语法的友好支持,极大地降低了硬件编程的门槛。然而,从桌面环境转向资源极度受限的微控制器(MCU)世界…...

别再死记硬背了!用PyTorch手把手拆解ECAPA-TDNN中的Res2Net与SENet模块
用PyTorch实战解析ECAPA-TDNN中的Res2Net与SENet模块 当我们在说话人识别任务中追求更高的准确率时,ECAPA-TDNN无疑是一个绕不开的标杆模型。这个模型之所以能在VoxSRC等权威比赛中屡创佳绩,关键在于其精心设计的Res2Net和SENet模块的协同工作。本文将带…...

终极Windows APK安装器:3分钟学会在电脑上安装Android应用
终极Windows APK安装器:3分钟学会在电脑上安装Android应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否想在Windows电脑上直接运行Android应用&am…...