Python 爬虫实战之爬淘宝商品并做数据分析
前言
是这样的,之前接了一个金主的单子,他想在淘宝开个小鱼零食的网店,想对目前这个市场上的商品做一些分析,本来手动去做统计和分析也是可以的,这些信息都是对外展示的,只是手动比较麻烦,所以想托我去帮个忙。
一、 项目要求:
具体的要求如下:
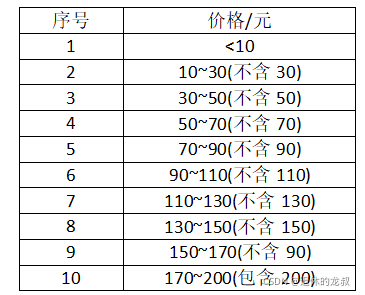
1.在淘宝搜索“小鱼零食”,想知道前10页搜索结果的所有商品的销量和金额,按照他划定好的价格区间来统计数量,给我划分了如下的一张价格区间表:
2.这10页搜索结果中,商家都是分布在全国的哪些位置?
3.这10页的商品下面,用户评论最多的是什么?
4.从这些搜索结果中,找出销量最多的10家店铺名字和店铺链接。
从这些要求来看,其实这些需求也不难实现,我们先来看一下项目的效果。
二、效果预览
获取到数据之后做了下分析,最终做成了柱状图,鼠标移动可以看出具体的商品数量。
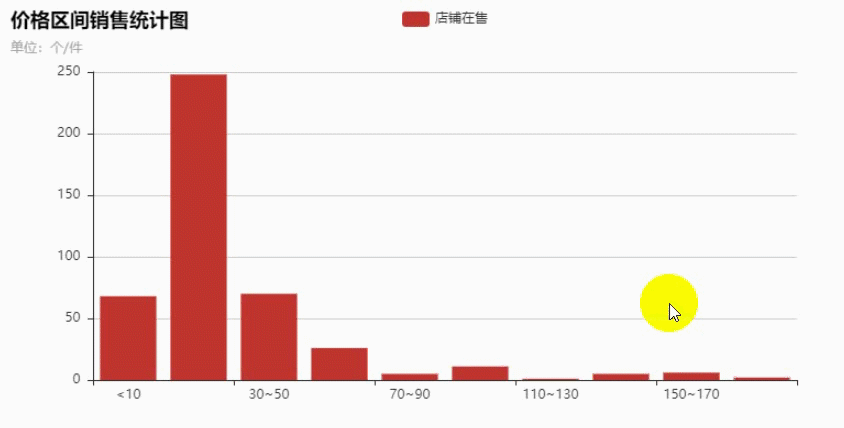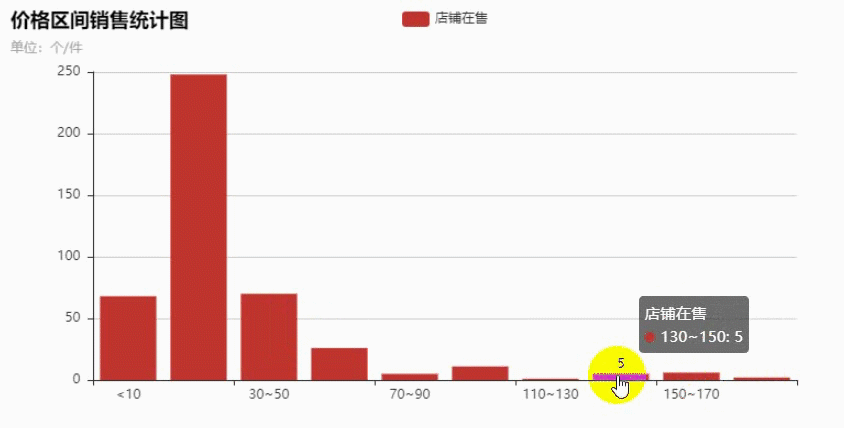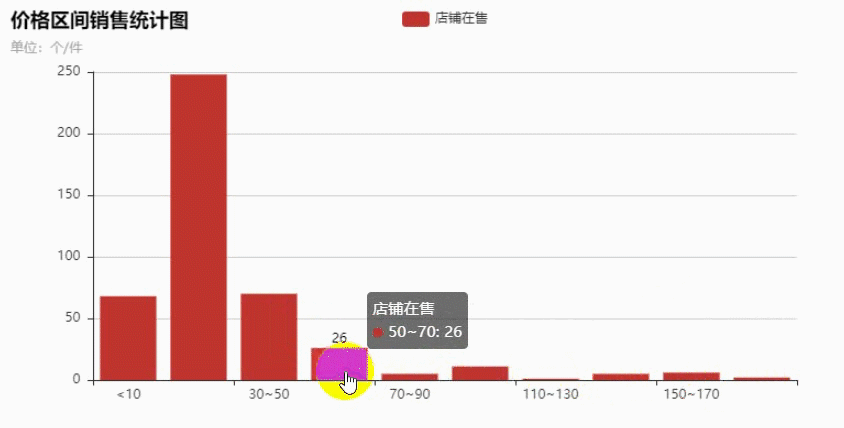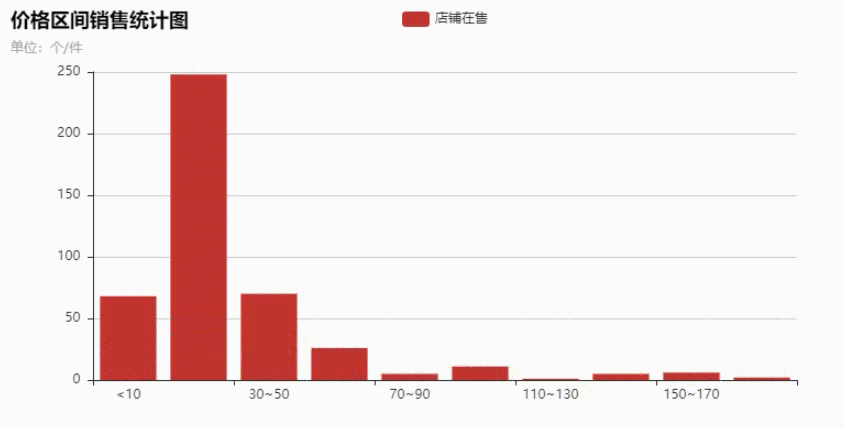
在10~30元之间的商品最多,越往后越少,看来大多数的产品都是定位为低端市场。
然后我们再来看一下全国商家的分布情况:
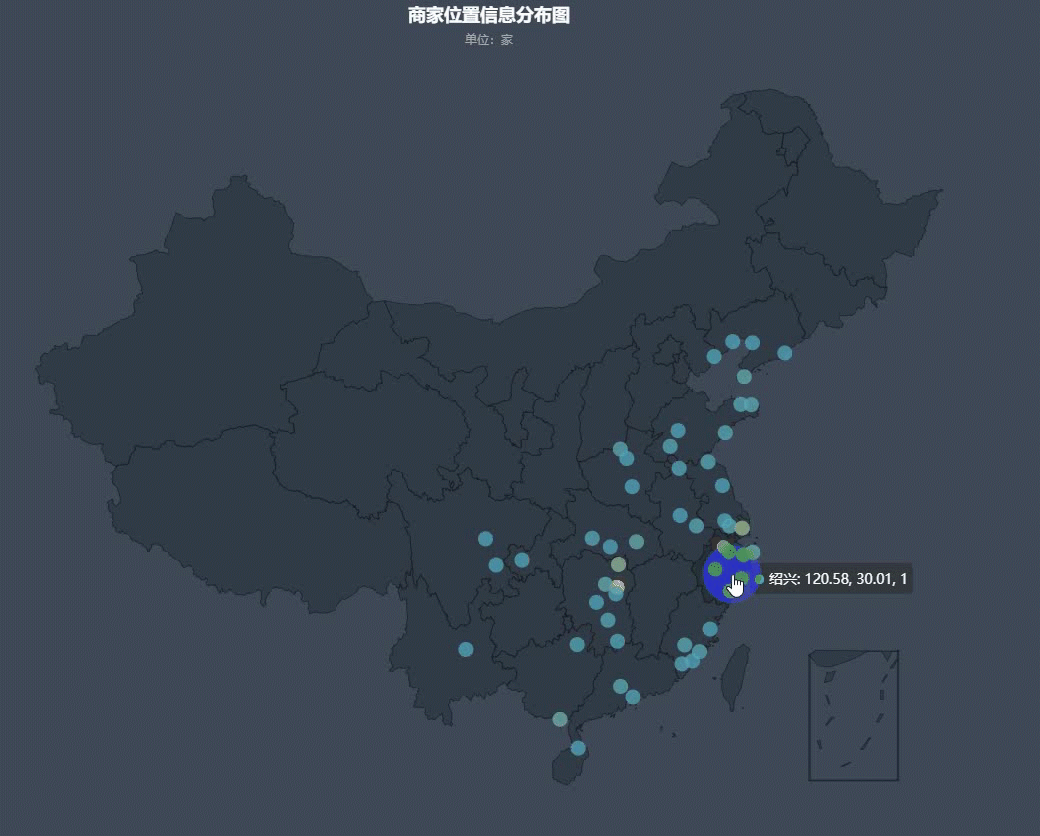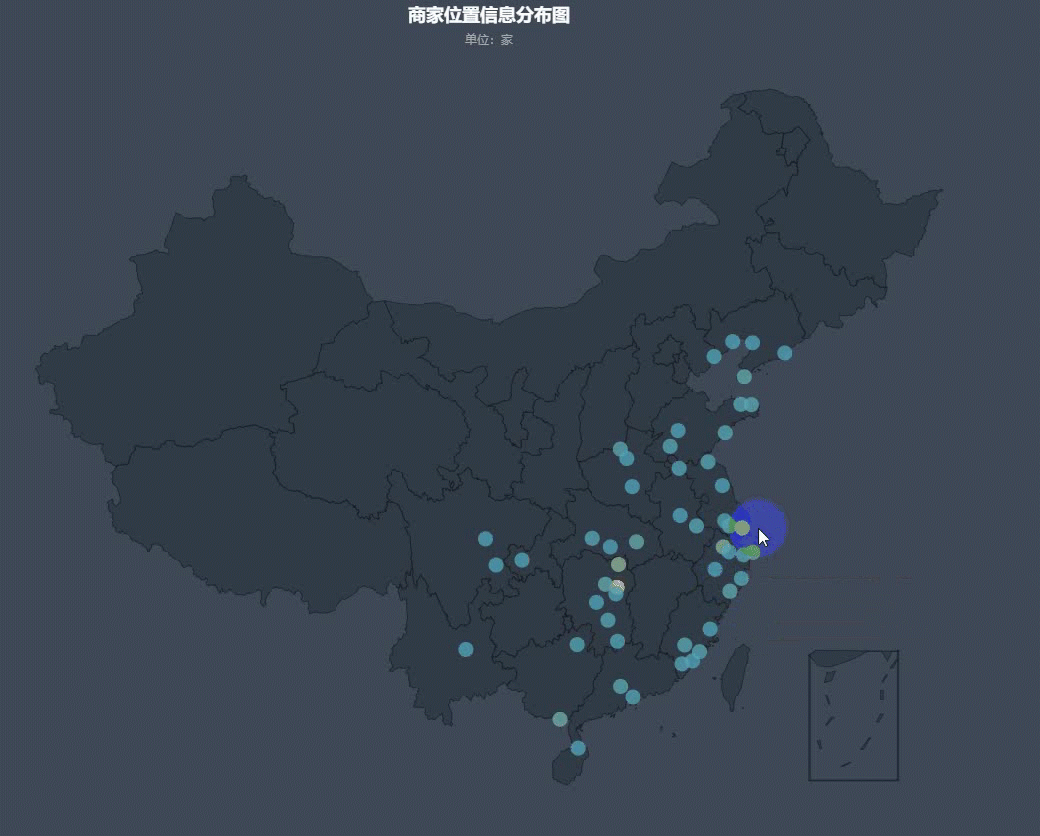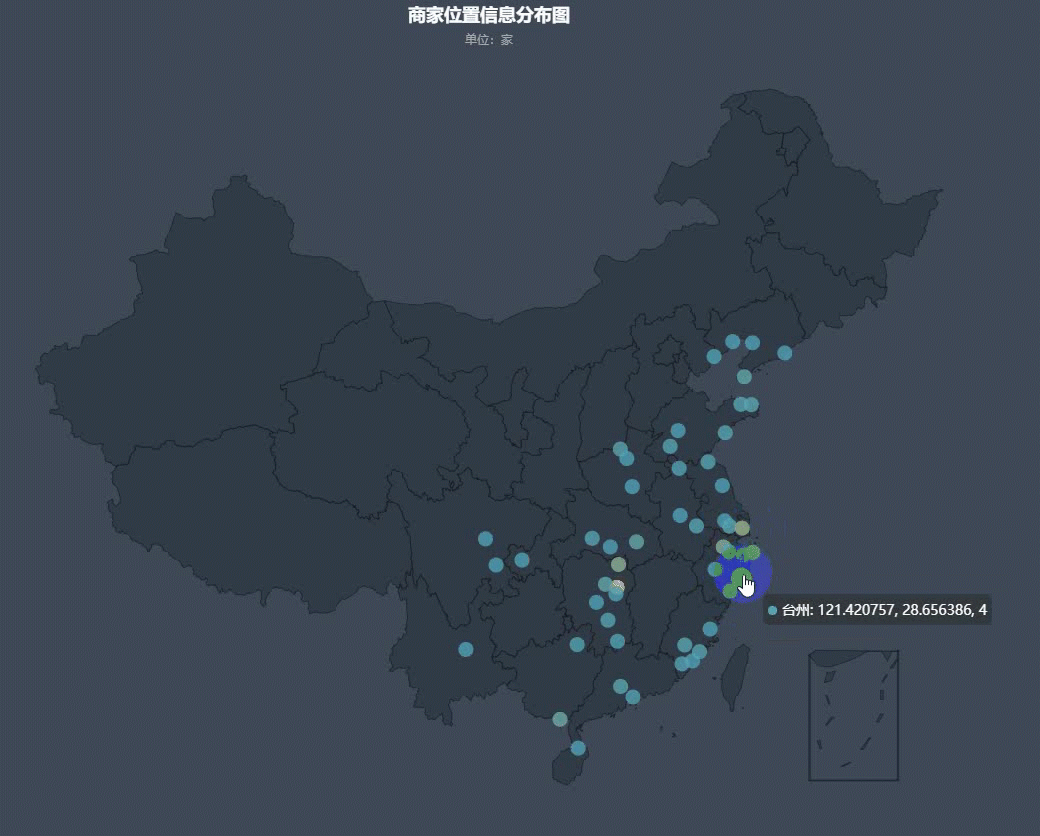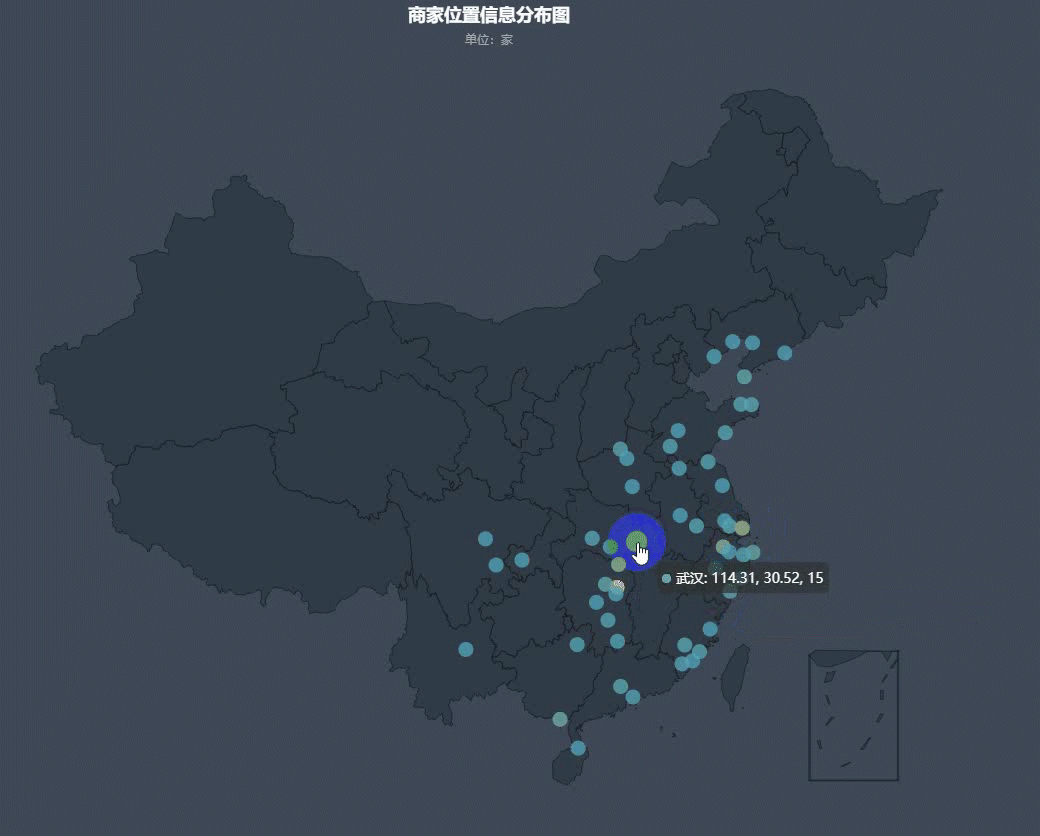
可以看出,商家分布大多都是在沿海和长江中下游附近,其中以沿海地区最为密集。
然后再来看一下用户都在商品下面评论了一些什么:

字最大的就表示出现次数最多,口感味道、包装品质、商品分量和保质期是用户评价最多的几个方面,那么在产品包装的时候可以从这几个方面去做针对性阐述,解决大多数人比较关心的问题。
最后就是销量前10的店铺和链接了。
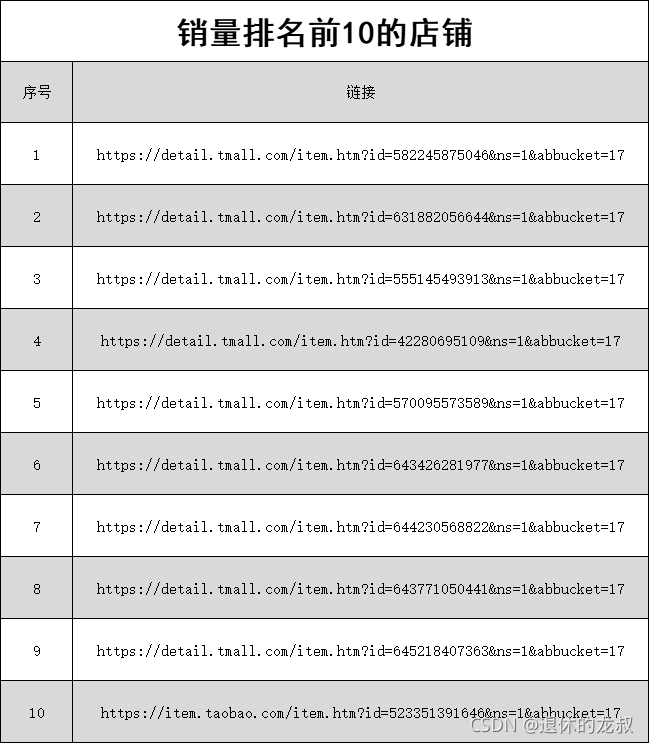
在拿到数据并做了分析之后,我也在想,如果这个东西是我来做的话,我能不能看出来什么东西?或许可以从价格上找到切入点,或许可以从产品地理位置打个差异化,又或许可以以用户为中心,由外而内地做营销。
越往深想,越觉得有门道,算了,对于小鱼零食这一块我是外行,不多想了。
三、爬虫源码
由于源码分了几个源文件,还是比较长的,所以这里就不跟大家一一讲解了,懂爬虫的人看几遍就看懂了,不懂爬虫的说再多也是云里雾里,等以后学会了爬虫再来看就懂了。
测试淘宝爬虫数据 apikey secret
import csvimport osimport timeimport wordcloudfrom selenium import webdriverfrom selenium.webdriver.common.by import Bydef tongji():prices = []with open('前十页销量和金额.csv', 'r', encoding='utf-8', newline='') as f:fieldnames = ['价格', '销量', '店铺位置']reader = csv.DictReader(f, fieldnames=fieldnames)for index, i in enumerate(reader):if index != 0:price = float(i['价格'].replace('¥', ''))prices.append(price)DATAS = {'<10': 0, '10~30': 0, '30~50': 0,'50~70': 0, '70~90': 0, '90~110': 0,'110~130': 0, '130~150': 0, '150~170': 0, '170~200': 0, }for price in prices:if price < 10:DATAS['<10'] += 1elif 10 <= price < 30:DATAS['10~30'] += 1elif 30 <= price < 50:DATAS['30~50'] += 1elif 50 <= price < 70:DATAS['50~70'] += 1elif 70 <= price < 90:DATAS['70~90'] += 1elif 90 <= price < 110:DATAS['90~110'] += 1elif 110 <= price < 130:DATAS['110~130'] += 1elif 130 <= price < 150:DATAS['130~150'] += 1elif 150 <= price < 170:DATAS['150~170'] += 1elif 170 <= price < 200:DATAS['170~200'] += 1for k, v in DATAS.items():print(k, ':', v)def get_the_top_10(url):top_ten = []# 获取代理ip = zhima1()[2][random.randint(0, 399)]# 运行quicker动作(可以不用管)os.system('"C:\Program Files\Quicker\QuickerStarter.exe" runaction:5e3abcd2-9271-47b6-8eaf-3e7c8f4935d8')options = webdriver.ChromeOptions()# 远程调试Chromeoptions.add_experimental_option('debuggerAddress', '127.0.0.1:9222')options.add_argument(f'--proxy-server={ip}')driver = webdriver.Chrome(options=options)# 隐式等待driver.implicitly_wait(3)# 打开网页driver.get(url)# 点击部分文字包含'销量'的网页元素driver.find_element(By.PARTIAL_LINK_TEXT, '销量').click()time.sleep(1)# 页面滑动到最下方driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')time.sleep(1)# 查找元素element = driver.find_element(By.ID, 'mainsrp-itemlist').find_element(By.XPATH, './/div[@class="items"]')items = element.find_elements(By.XPATH, './/div[@data-category="auctions"]')for index, item in enumerate(items):if index == 10:break# 查找元素price = item.find_element(By.XPATH, './div[2]/div[1]/div[contains(@class,"price")]').textpaid_num_data = item.find_element(By.XPATH, './div[2]/div[1]/div[@class="deal-cnt"]').textstore_location = item.find_element(By.XPATH, './div[2]/div[3]/div[@class="location"]').textstore_href = item.find_element(By.XPATH, './div[2]/div[@class="row row-2 title"]/a').get_attribute('href').strip()# 将数据添加到字典top_ten.append({'价格': price,'销量': paid_num_data,'店铺位置': store_location,'店铺链接': store_href})for i in top_ten:print(i)def get_top_10_comments(url):with open('排名前十评价.txt', 'w+', encoding='utf-8') as f:pass# ip = ipidea()[1]os.system('"C:\Program Files\Quicker\QuickerStarter.exe" runaction:5e3abcd2-9271-47b6-8eaf-3e7c8f4935d8')options = webdriver.ChromeOptions()options.add_experimental_option('debuggerAddress', '127.0.0.1:9222')# options.add_argument(f'--proxy-server={ip}')driver = webdriver.Chrome(options=options)driver.implicitly_wait(3)driver.get(url)driver.find_element(By.PARTIAL_LINK_TEXT, '销量').click()time.sleep(1)element = driver.find_element(By.ID, 'mainsrp-itemlist').find_element(By.XPATH, './/div[@class="items"]')items = element.find_elements(By.XPATH, './/div[@data-category="auctions"]')original_handle = driver.current_window_handleitem_hrefs = []# 先获取前十的链接for index, item in enumerate(items):if index == 10:breakitem_hrefs.append(item.find_element(By.XPATH, './/div[2]/div[@class="row row-2 title"]/a').get_attribute('href').strip())# 爬取前十每个商品评价for item_href in item_hrefs:# 打开新标签# item_href = 'https://item.taobao.com/item.htm?id=523351391646&ns=1&abbucket=11#detail'driver.execute_script(f'window.open("{item_href}")')# 切换过去handles = driver.window_handlesdriver.switch_to.window(handles[-1])# 页面向下滑动一部分,直到让评价那两个字显示出来try:driver.find_element(By.PARTIAL_LINK_TEXT, '评价').click()except Exception as e1:try:x = driver.find_element(By.PARTIAL_LINK_TEXT, '评价').location_once_scrolled_into_viewdriver.find_element(By.PARTIAL_LINK_TEXT, '评价').click()except Exception as e2:try:# 先向下滑动100,放置评价2个字没显示在屏幕内driver.execute_script('var q=document.documentElement.scrollTop=100')x = driver.find_element(By.PARTIAL_LINK_TEXT, '评价').location_once_scrolled_into_viewexcept Exception as e3:driver.find_element(By.XPATH, '/html/body/div[6]/div/div[3]/div[2]/div/div[2]/ul/li[2]/a').click()time.sleep(1)try:trs = driver.find_elements(By.XPATH, '//div[@class="rate-grid"]/table/tbody/tr')for index, tr in enumerate(trs):if index == 0:comments = tr.find_element(By.XPATH, './td[1]/div[1]/div/div').text.strip()else:try:comments = tr.find_element(By.XPATH,'./td[1]/div[1]/div[@class="tm-rate-fulltxt"]').text.strip()except Exception as e:comments = tr.find_element(By.XPATH,'./td[1]/div[1]/div[@class="tm-rate-content"]/div[@class="tm-rate-fulltxt"]').text.strip()with open('排名前十评价.txt', 'a+', encoding='utf-8') as f:f.write(comments + '\n')print(comments)except Exception as e:lis = driver.find_elements(By.XPATH, '//div[@class="J_KgRate_MainReviews"]/div[@class="tb-revbd"]/ul/li')for li in lis:comments = li.find_element(By.XPATH, './div[2]/div/div[1]').text.strip()with open('排名前十评价.txt', 'a+', encoding='utf-8') as f:f.write(comments + '\n')print(comments)def get_top_10_comments_wordcloud():file = '排名前十评价.txt'f = open(file, encoding='utf-8')txt = f.read()f.close()w = wordcloud.WordCloud(width=1000,height=700,background_color='white',font_path='msyh.ttc')# 创建词云对象,并设置生成图片的属性w.generate(txt)name = file.replace('.txt', '')w.to_file(name + '词云.png')os.startfile(name + '词云.png')def get_10_pages_datas():with open('前十页销量和金额.csv', 'w+', encoding='utf-8', newline='') as f:f.write('\ufeff')fieldnames = ['价格', '销量', '店铺位置']writer = csv.DictWriter(f, fieldnames=fieldnames)writer.writeheader()infos = []options = webdriver.ChromeOptions()options.add_experimental_option('debuggerAddress', '127.0.0.1:9222')# options.add_argument(f'--proxy-server={ip}')driver = webdriver.Chrome(options=options)driver.implicitly_wait(3)driver.get(url)# driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')element = driver.find_element(By.ID, 'mainsrp-itemlist').find_element(By.XPATH, './/div[@class="items"]')items = element.find_elements(By.XPATH, './/div[@data-category="auctions"]')for index, item in enumerate(items):price = item.find_element(By.XPATH, './div[2]/div[1]/div[contains(@class,"price")]').textpaid_num_data = item.find_element(By.XPATH, './div[2]/div[1]/div[@class="deal-cnt"]').textstore_location = item.find_element(By.XPATH, './div[2]/div[3]/div[@class="location"]').textinfos.append({'价格': price,'销量': paid_num_data,'店铺位置': store_location})try:driver.find_element(By.PARTIAL_LINK_TEXT, '下一').click()except Exception as e:driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')driver.find_element(By.PARTIAL_LINK_TEXT, '下一').click()for i in range(9):time.sleep(1)driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')element = driver.find_element(By.ID, 'mainsrp-itemlist').find_element(By.XPATH, './/div[@class="items"]')items = element.find_elements(By.XPATH, './/div[@data-category="auctions"]')for index, item in enumerate(items):try:price = item.find_element(By.XPATH, './div[2]/div[1]/div[contains(@class,"price")]').textexcept Exception:time.sleep(1)driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')price = item.find_element(By.XPATH, './div[2]/div[1]/div[contains(@class,"price")]').textpaid_num_data = item.find_element(By.XPATH, './div[2]/div[1]/div[@class="deal-cnt"]').textstore_location = item.find_element(By.XPATH, './div[2]/div[3]/div[@class="location"]').textinfos.append({'价格': price,'销量': paid_num_data,'店铺位置': store_location})try:driver.find_element(By.PARTIAL_LINK_TEXT, '下一').click()except Exception as e:driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')driver.find_element(By.PARTIAL_LINK_TEXT, '下一').click()# 一页结束for info in infos:print(info)with open('前十页销量和金额.csv', 'a+', encoding='utf-8', newline='') as f:fieldnames = ['价格', '销量', '店铺位置']writer = csv.DictWriter(f, fieldnames=fieldnames)for info in infos:writer.writerow(info)if __name__ == '__main__':url = 'https://s.taobao.com/search?q=%E5%B0%8F%E9%B1%BC%E9%9B%B6%E9%A3%9F&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.21814703.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=4&ntoffset=4&p4ppushleft=2%2C48&s=0'# get_10_pages_datas()# tongji()# get_the_top_10(url)# get_top_10_comments(url)get_top_10_comments_wordcloud()
通过上面的代码,我们能获取到想要获取的数据,然后再Bar和Geo进行柱状图和地理位置分布展示,这两块大家可以去摸索一下。
相关文章:
Python 爬虫实战之爬淘宝商品并做数据分析
前言 是这样的,之前接了一个金主的单子,他想在淘宝开个小鱼零食的网店,想对目前这个市场上的商品做一些分析,本来手动去做统计和分析也是可以的,这些信息都是对外展示的,只是手动比较麻烦,所以…...
)
Python爬虫-requests.exceptions.SSLError: HTTPSConnectionPool疑难杂症解决(1)
前言 本文是该专栏的第7篇,后面会持续分享python爬虫案例干货,记得关注。 在爬虫项目开发中,偶尔可能会遇到SSL验证问题“requests.exceptions.SSLError: HTTPSConnectionPool(host=www.xxxxxx.com, port=443): Max retries exceeded with url ...”。亦或是验证之后的提示…...

12:STM32---RTC实时时钟
目录 一:时间相关 1:Unix时间戳 2: UTC/GMT 3:时间戳转化 二:BKP 1:简历 2:基本结构 三: RTC 1:简历 2: 框图 3:RTC基本结构 4:RTC操作注意 四:案例 A:读写备份寄存器 1:连接图 2: 步骤 3: 代码 B:实时时钟 1:连接图 2:函数介绍 3:代码 一:时间相关 1:Un…...
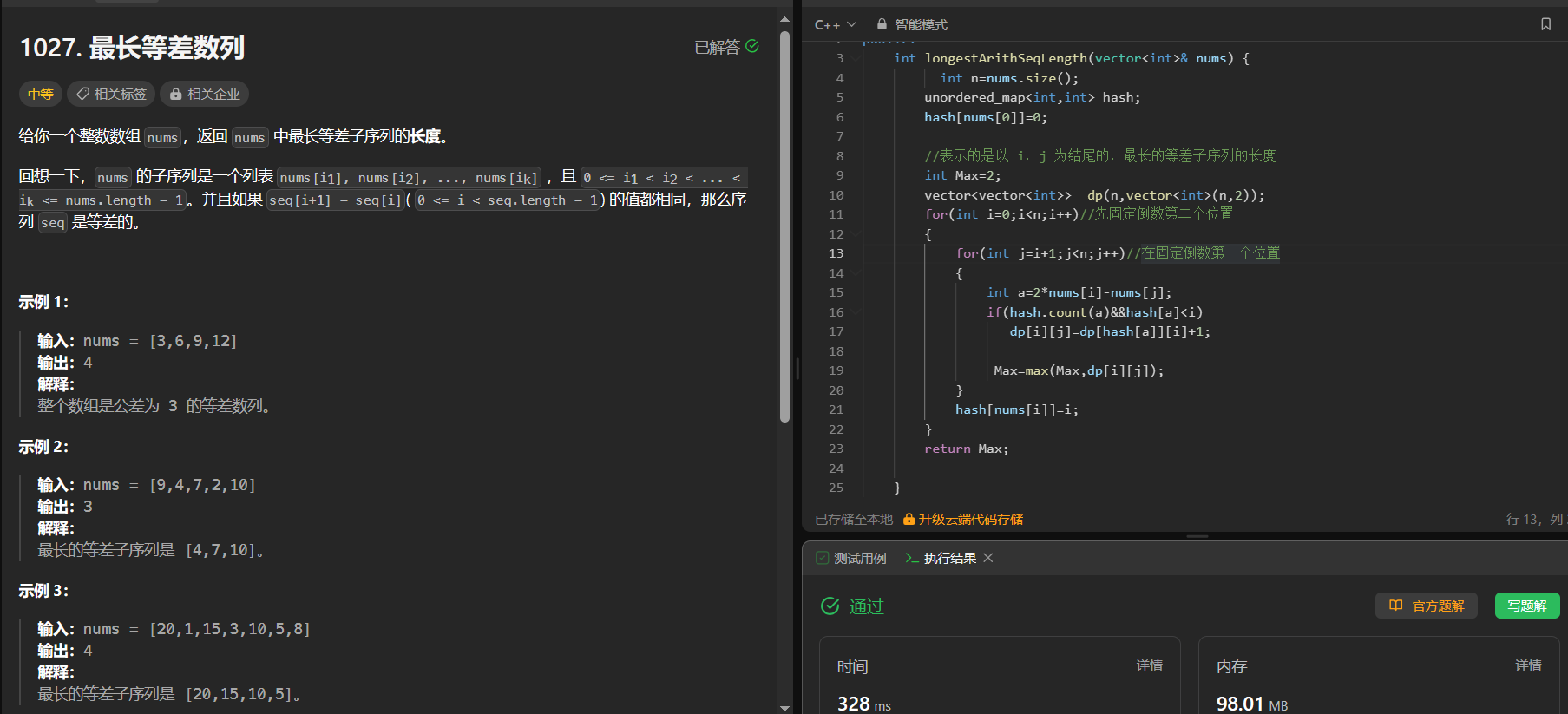
【动态规划刷题 16】最长等差数列 (有难度) 等差数列划分 II - 子序列
1027. 最长等差数列 https://leetcode.cn/problems/longest-arithmetic-subsequence/ 给你一个整数数组 nums,返回 nums 中最长等差子序列的长度。 回想一下,nums 的子序列是一个列表 nums[i1], nums[i2], …, nums[ik] ,且 0 < i1 <…...
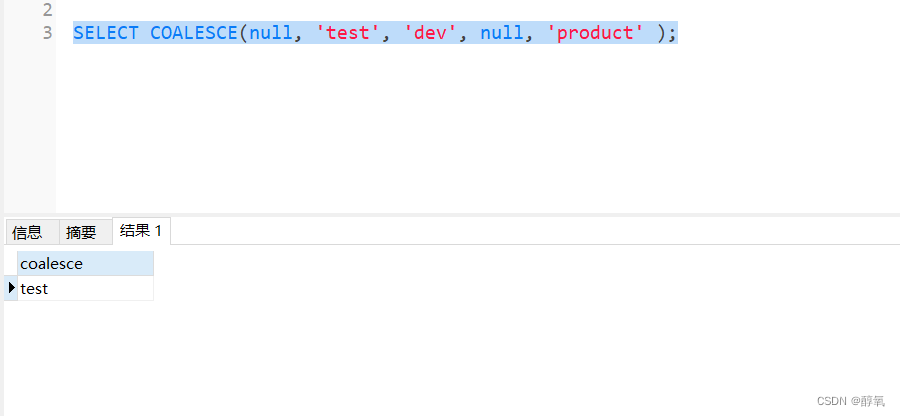
【postgresql】替换 mysql 中的ifnull()
数据库由mysql 迁移到postgresql,程序在执行查询时候报错。 HINT: No function matches the given name and argument types. You might need to add explicit type casts. CONTEXT: referenced column: ifnull 具体SQL: SELECT ifnull(phone,) FROM c_user p…...
)
单例模式(懒汉式,饿汉式,变体)
单例模式,用于确保一个类只有一个实例,并提供一个全局访问点以访问该实例。 饿汉式(Eager Initialization) 程序启动时就创建实例 #include <iostream> class SingletonEager { private:static SingletonEager* instanc…...

Java Lambda表达式:简洁且强大的函数式编程工具
Lambda表达式是Java 8及以后版本中引入的一种函数式编程特性。它是一种匿名函数,允许开发人员以简洁和易读的方式编写代码,并且可以作为参数传递给方法或存储在变量中。Lambda表达式的基本语法如下:(parameters) -> expression,…...
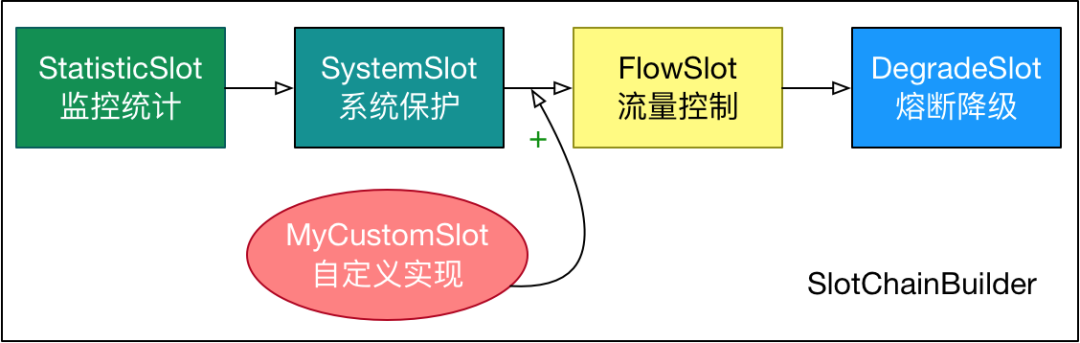
开源框架中的责任链模式实践
作者:vivo 互联网服务器团队-Wang Zhi 责任链模式作为常用的设计模式而被大家熟知和使用。本文介绍责任链的常见实现方式,并结合开源框架如Dubbo、Sentinel等进行延伸探讨。 一、责任链介绍 在GoF 的《设计模式》一书中对责任链模定义的:将…...
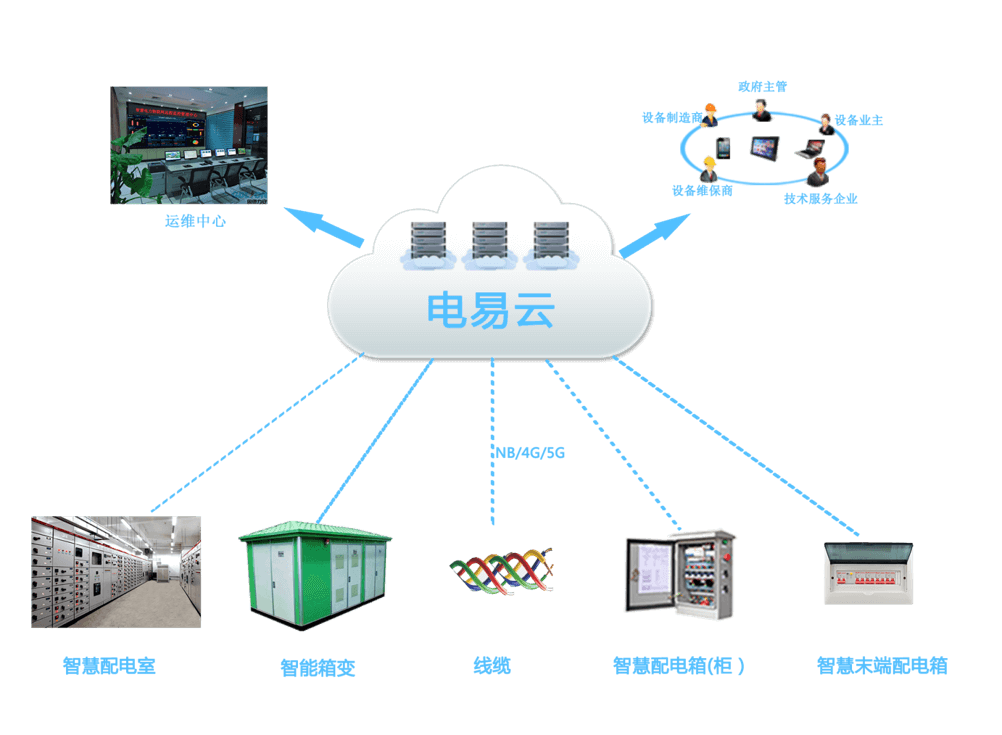
智能配电系统:保障电力运行安全、可控与高效
智能配电系统是一种先进的电力分配技术,它通过智能化、数字化和网络化等方式,有效地保障了电力运行的安全、可控和高效。 力安科技智能配电系统是在配电室(含高压柜、变压器、低压柜)、箱式变电站、配电箱及动力柜(…...
-每天学习10个知识)
MySQL学习系列(11)-每天学习10个知识
目录 1. 数据库设计的关键因素2. 使用存储过程和函数来提高性能和可重用性3. MySQL性能优化4. 使用视图简化查询和提供数据安全性5. 数据库备份和恢复策略的重要性和实践经验6. 在分布式系统中保证数据一致性和可用性7. 理解MySQL的复制和其在实际应用中的作用8. 使用游标进行分…...
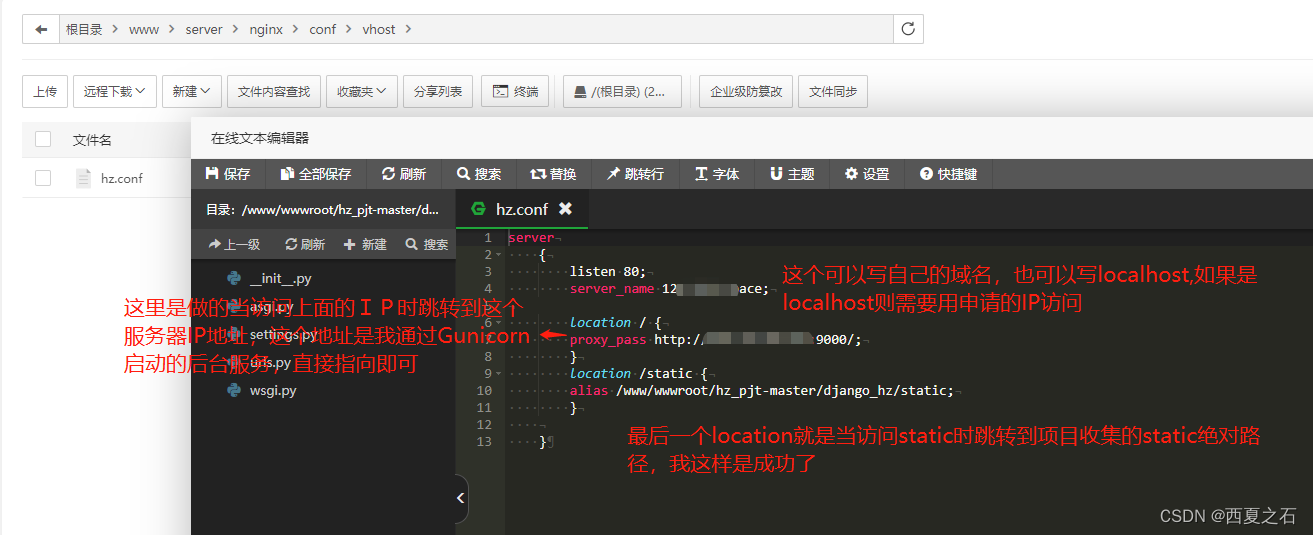
如何通过Gunicorn和Niginx部署Django
本文主要介绍如何配置Niginx加载Django的静态资源文件,也就是Static 1、首先需要将Django项目中的Settings.py 文件中的两个参数做以下设置: STATIC_URL /static/ STATIC_ROOT os.path.join(BASE_DIR, static) 然后在宝塔面板中执行python manage.…...
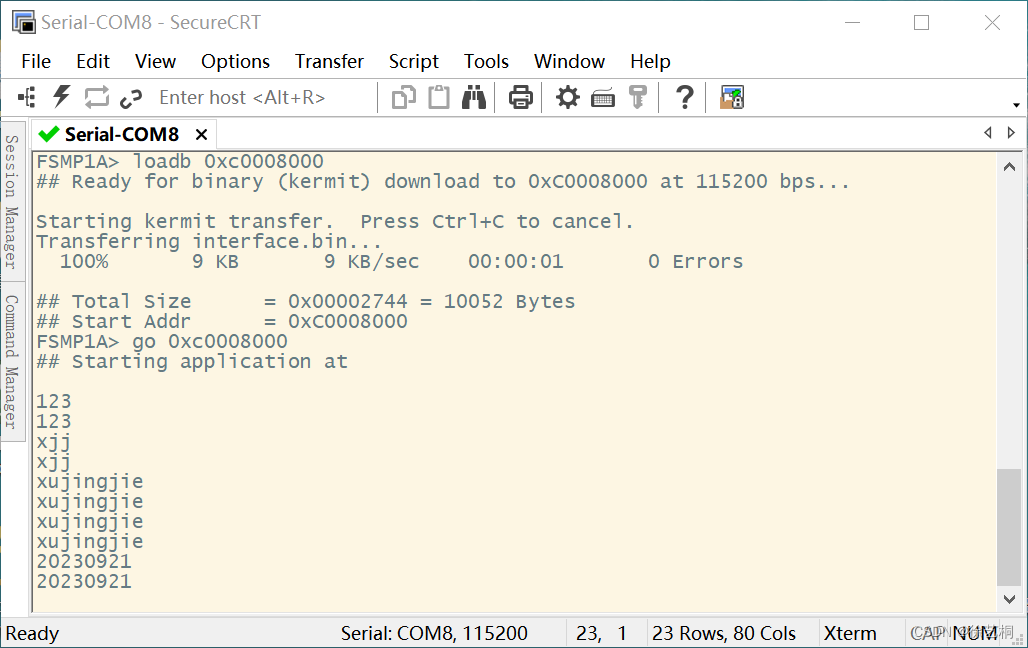
C语言 cortex-A7核UART总线实验
一、C 1)uart4.h #ifndef __UART4_H__ #define __UART4_H__ #include "stm32mp1xx_rcc.h" #include "stm32mp1xx_gpio.h" #include "stm32mp1xx_uart.h&quo…...

asp.net C#免费反编译工具ILSpy
在维护一个没有源码的C#项目,只能反编译了。 项目主页 https://github.com/icsharpcode/ILSpy 使用方法 中文界面使用简单,把你要反编译的dll拖过去就可以了。好使!!!...

演讲实录:DataFun 垂直开发者社区基于指标平台自主洞察北极星指标
在7月14日举办的 Kyligence 用户大会的数智新应用论坛上,DataFun COO 杜颖女士为大家带来了《垂直开发者社区基于指标平台自主洞察北极星指标》的主题演讲。接下来,我们一起看看 DataFun 如何在没有专门的 IT 团队的情况下,实现对北极星指标的…...
ffmpeg编译 Error: operand type mismatch for `shr‘
错误如下: D:\msys2\tmp\ccUxvBjQ.s: Assembler messages: D:\msys2\tmp\ccUxvBjQ.s:345: Error: operand type mismatch for shr D:\msys2\tmp\ccUxvBjQ.s:410: Error: operand type mismatch for shr D:\msys2\tmp\ccUxvBjQ.s:470: Error: operand type mismatch…...
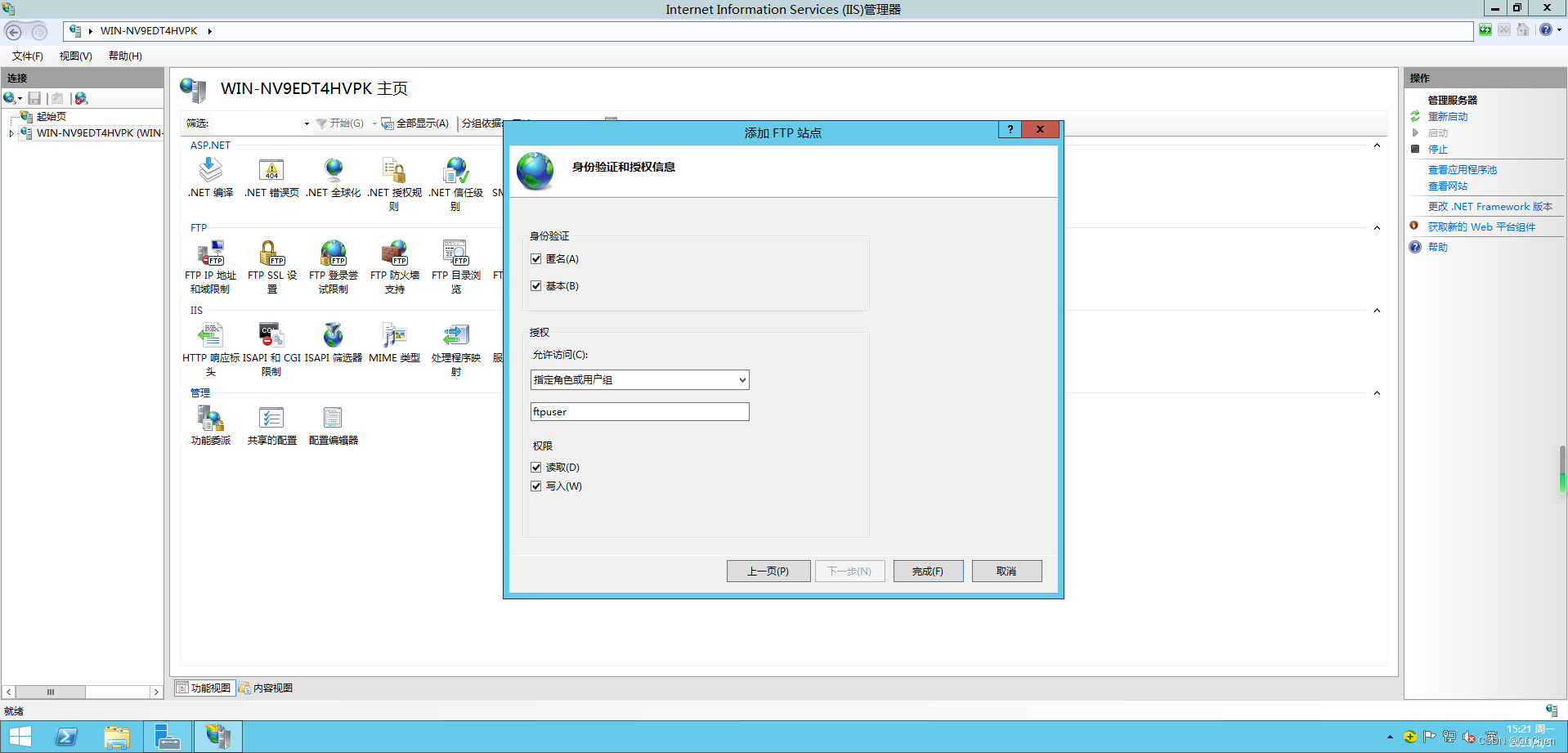
【Windows Server 2012 R2搭建FTP站点】
打开服务器管理器——添加角色和功能 下一步 下一步 下一步 选择FTP服务器,勾上FTP服务和FTP扩展,点击下一步 安装 安装完成关闭 打开我们的IIS服务器 在WIN-XXX主页可以看到我们的FTP相关菜单 右键WIN-XXXX主页,添加FTP站点 输入站点名称-FT…...

python教程:使用gevent实现高并发并限制最大并发数
嗨喽~大家好呀,这里是魔王呐 ❤ ~! python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取 import time import gevent from gevent.pool import Pool from gevent import monkey # 一,定义最大并发数 p Pool(20) # 二,导入gevent…...

借助reCAPTCHA实现JavaScript验证码功能
前言 验证码(CAPTCHA)是一种常见的安全验证机制,常用于区分真实用户和机器人。使用验证码可以有效防止恶意登录、自动注册或者密码爆破等攻击。本文将借助reCAPTCHA第三方库来实现JavaScript验证码功能。 验证码的原理 验证码的核心思想是要…...
监控数据的采集方式及原理
采集方法使用频率从高到低依次是读取 /proc目录、执行命令行工具、远程黑盒探测、拉取特定协议的数据、连接到目标对象执行命令、代码埋点、日志解析。 读取 /proc目录 /proc是一个位于内存中的伪文件系统,而在该目录下保存的不是真正的文件和目录,而是…...

Vue路由与node.js环境搭建
目录 前言 一.Vue路由 1.什么是spa 1.1简介 1.2 spa的特点 1.3 spa的优势以及未来的挑战 2.路由的使用 2.1 导入JS依赖 2.2 定义两个组件 2.3 定义组件与路径对应关系 2.4 通过路由关系获取路由对象 2.5 将对象挂载到vue实例中 2.6 定义触发路由事件的按钮 2.7 定…...

VTOL无人机微多普勒特征分析与6G感知技术
1. VTOL无人机微多普勒特征分析的技术背景垂直起降(VTOL)无人机因其独特的飞行能力在军事和民用领域获得广泛应用,但同时也带来了空域管理的新挑战。传统雷达识别方法主要依赖目标的宏观运动特征,难以精确区分VTOL的不同飞行阶段。…...

Windows 11安卓子系统WSA:在电脑上流畅运行手机应用的完整指南
Windows 11安卓子系统WSA:在电脑上流畅运行手机应用的完整指南 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA 你是否曾想过在Windows电脑上直接…...

技术人必备的Chrome插件清单:第7个让调试效率翻倍
对于软件测试从业者而言,浏览器早已不是单纯的信息浏览窗口,而是集接口调试、性能分析、元素定位、辅助功能验证于一体的核心工作站。面对日益复杂的Web应用和紧迫的交付周期,一套精悍的Chrome插件组合往往能带来远超预期的效率回报。本文从测…...

Java SE 与 Spring Boot 在电商场景中的应用
面试:Java SE 与 Spring Boot 在电商场景中的应用 今天,我们将围绕一位求职者在一家电商公司的面试场景,与面试官进行一场激烈的技术问答。第一轮提问 面试官: 首先,请你简单介绍一下 JVM 的工作原理。 燕双非…...

2026AI大模型API聚合系统排行榜:四大主流中转API及特色玩家谁能脱颖而出?
随着AI技术大规模落地,AI大模型API聚合系统成为企业快速接入前沿智能能力、降低技术门槛的关键工具。目前市场上的服务商众多,企业在选择时往往会考虑稳定性、合规性、接入成本等因素。为了帮助企业解决这一难题,本文对当下主流的四大AI大模型…...

Windows Cleaner终极指南:3步解决C盘爆红和电脑卡顿难题
Windows Cleaner终极指南:3步解决C盘爆红和电脑卡顿难题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款专为Windows系统设计的…...

处理电商分类难题:我是如何用XGBoost为Otto数据集做多类别预测的
电商商品分类实战:XGBoost在Otto数据集上的高阶应用 当面对海量商品需要精准分类时,传统人工规则往往力不从心。Otto Group Product Classification Challenge正是这样一个典型场景——需要将数十万商品准确划分到93个类别中。本文将分享如何用XGBoost构…...

从等待到掌控:构建个人化网盘下载工作流的3个关键步骤
从等待到掌控:构建个人化网盘下载工作流的3个关键步骤 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...

家庭影院系统构建指南:从流媒体技术到硬件选型
1. 疫情下的娱乐变局:从影院到客厅的深度迁移作为一名长期关注消费电子与家庭娱乐领域的从业者,我亲历了过去几年行业最剧烈的震荡。疫情像一只无形的手,强行按下了社会运行的暂停键,却又为另一个赛道按下了加速键。当电影院的大门…...
)
告别手动改包!用Fiddler的Free HTTP插件实现自动化测试(附实战配置)
构建高效HTTP流量自动化测试体系:Fiddler Free HTTP插件深度实践 在持续交付和DevOps成为主流的今天,自动化测试已成为保障软件质量不可或缺的一环。然而,许多团队在接口测试环节仍面临重复劳动:每次测试都需要手动修改请求参数、…...