Python中TensorFlow的长短期记忆神经网络(LSTM)、指数移动平均法预测股票市场和可视化...
原文链接:http://tecdat.cn/?p=23689
本文探索Python中的长短期记忆(LSTM)网络,以及如何使用它们来进行股市预测(点击文末“阅读原文”获取完整代码数据)。
相关视频
在本文中,你将看到如何使用一个被称为长短时记忆的时间序列模型。LSTM模型很强大,特别是在保留长期记忆方面。在本文中,你将解决以下主题。
理解为什么你需要能够预测股票价格的变动。
下载数据 - 使用从雅虎财经收集的股市数据
分割训练-测试数据,并进行数据归一化
应用单步预测技术。
讨论LSTM模型。
用当前的数据预测和可视化未来的股票市场
为什么你需要时间序列模型?
你希望对股票价格进行正确的建模,所以作为一个股票买家,你可以合理地决定何时买入股票,何时卖出股票以获得利润。这就是时间序列模型的作用。你需要好的机器学习模型,它可以观察一连串数据的历史,并正确预测该序列的未来数据。
提示:股票市场的价格是高度不可预测和波动的。这意味着数据中没有一致的模式,使你能够近乎完美地模拟股票价格随时间变化。
然而,我们不要一味地认为这只是一个随机的或者随机的过程,机器学习没有希望。我们至少对数据进行建模,做出的预测与数据的实际行为相关。换句话说,你不需要未来确切的股票价值,而是需要股票价格的变动(也就是说,如果它在不久的将来会上涨或下跌)。
# 可用的库
import numpy as np
import tensorflow as tf下载数据
股票价格有几种不同的变量。它们是
开盘:当天的开盘股票价格
收盘价:当天的收盘股价
高点:数据中最高的股票价格
低点:当天的最低股价
获取数据
你要利用航空公司的股票市场价格来进行预测,所以你把股票代码设置为 "AAL"。此外,你还定义了一个url\_string,它将返回一个JSON文件,其中包含航空公司过去20年的所有股市数据,以及一个file\_to_save,它是你保存数据的文件。
接下来,指定条件:如果你还没有保存数据,从你在url\_string中设置的URL中抓取数据;把日期、低点、高点、成交量、收盘价、开盘价存储到一个pandas DataFrame df中,把它保存到file\_to_save。
# 从URL中抓取数据# 将日期、低点、高点、成交量、收盘价、开盘价存储到Pandas DataFrame中#提取股票市场数据df = pd.DataFrame(columns=\['Date', 'Low', 'High', 'Close', ' Open'\]) print('数据保存到:%s'%file\_to\_save) # 如果数据已经存在,只需从CSV中加载即可否则。print('文件已经存在,从CSV中加载数据')df = pd.read\_csv(file\_to_save)数据探索
在这里你将把收集的数据输出到DataFrame中。你还应该确保数据是按日期排序的,因为数据的顺序在时间序列建模中至关重要。
# 按日期对数据框架进行排序
df = df.sort_values('Date')# 仔细检查结果
df.head()
数据可视化
现在让我们来看看是什么样的数据。
plot(range(df.shape\[0\]),(df)/2.0)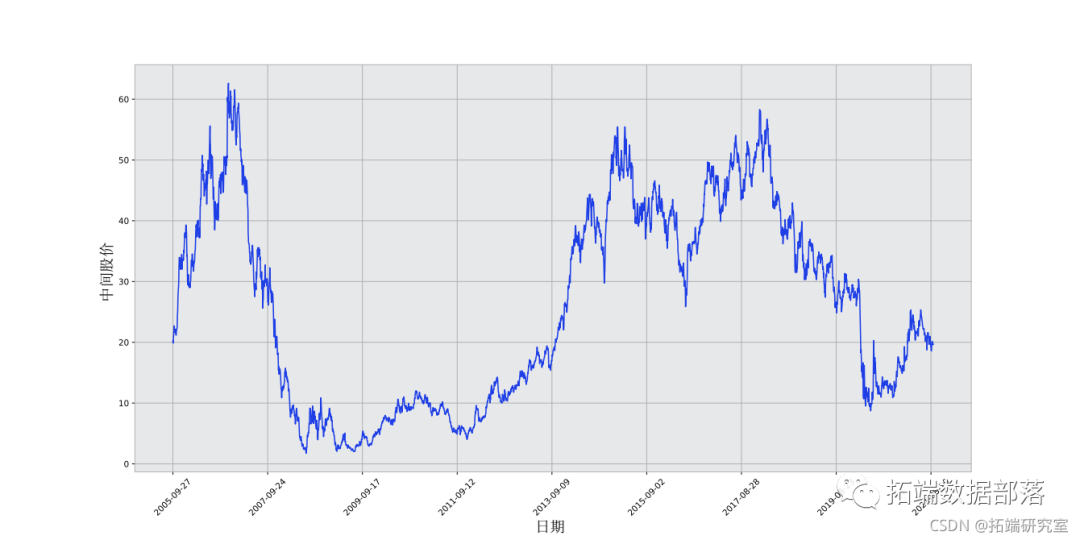
这张图已经说明了很多问题。我选择这家公司而不是其他公司的原因是,这张图随着时间的推移,股票价格有不同表现行为。这将使模型学习更加稳健,并且给你一个价格变化来测试对各种情况的预测有多好。
另一个需要注意的是,接近2017年的数值要比接近20世纪70年代的数值高得多,而且波动也大。因此,你需要确保数据在整个时间范围内表现为类似的价格范围,需要将数据标准化。
点击标题查阅相关内容

R语言Keras用RNN、双向RNNs递归神经网络、LSTM分析预测温度时间序列、 IMDB电影评分情感

左右滑动查看更多
01
02

03
04

将数据分割成训练集和测试集
你将使用通过取一天中最高和最低价格的平均值计算出的中间价格。
现在你可以把训练数据和测试数据分开。训练数据将是时间序列的前4000个数据点,其余的将是测试数据。
train_data = mid\[:4000\]
test_data = mid\[4000:\]标准化数据
现在你需要定义标准化来规范数据。将训练和测试数据变化为[data\_size, num\_features]的维度。
将测试数据和训练数据相对于训练数据归一。scaler = MinMaxScaler()由于你先前的观察,即不同时间段的数据有不同的值范围,通过将全序列分割成窗口来标准化数据。如果你不这样做,早期的数据将接近于0,对学习过程不会有太大的价值。这里你选择了一个800的窗口大小。
提示:在选择窗口大小时,不要太小,因为当你进行窗口标准化时,会在每个窗口的最末端引入一个断点,因为每个窗口都是独立标准化的。
# 用训练数据和平滑数据训练
window_size = 800
scaler.transform(train\_data\[di:di+window\_size,:\])将数据重塑为[data_size]的形状。
# 重塑训练和测试数据
reshape(-1)# 对测试数据进行标准化处理
scaler.transform(test_data).reshape(-1)现在你可以使用指数移动平均线对数据进行平滑处理。
请注意,你应该只平滑训练数据。
# 现在进行指数移动平均平滑处理
# 所以数据会比原来的锯齿状数据有一个更平滑的曲线EMA = gamma\*train\[i\] + (1-gamma)\*EMAtrain\[i\] = EMA通过平均法进行单步超前预测
平均法允许你通过将未来的股票价格表示为以前观察到的股票价格的平均值来进行预测(通常是提前一个时间步)。下面看两种平均技术;标准平均法和指数移动平均法。你将对这两种算法产生的结果进行定性(目测)和定量(平均平方误差)的评估。
平均平方误差(MSE)的计算方法是:取前一步的真实值和预测值之间的平方误差,并对所有的预测值进行平均。
标准平均
可以通过首先尝试将其作为一个平均计算问题的模型来理解这个问题的难度。首先,尝试预测未来的股票市场价格(例如,xt+1),作为一个固定大小的窗口(例如,xt-N,...,xt)(例如之前的100天)内先前观察到的股票市场价格的平均值。此后,尝试更高级的 "指数移动平均 "方法,看看它的效果如何。然后,进入长短期记忆模型
首先,正常的平均数。
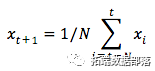
换句话说,你说t+1的预测是你在t到t-N的窗口内观察到的所有股票价格的平均值。
pred.append(np.mean(train\[idx-window_size:idx\]))mse\_errors.append((std\_avg\[-1\]-train\[pred_idx\])**2)MSE: 0.00418看一下下面的平均结果。它与股票的实际行为相当接近。接下来,你将看到一个更准确的一步预测方法。
plt.plot(std\_avg\_pred)plt.legend(fontsize=18)
plt.show()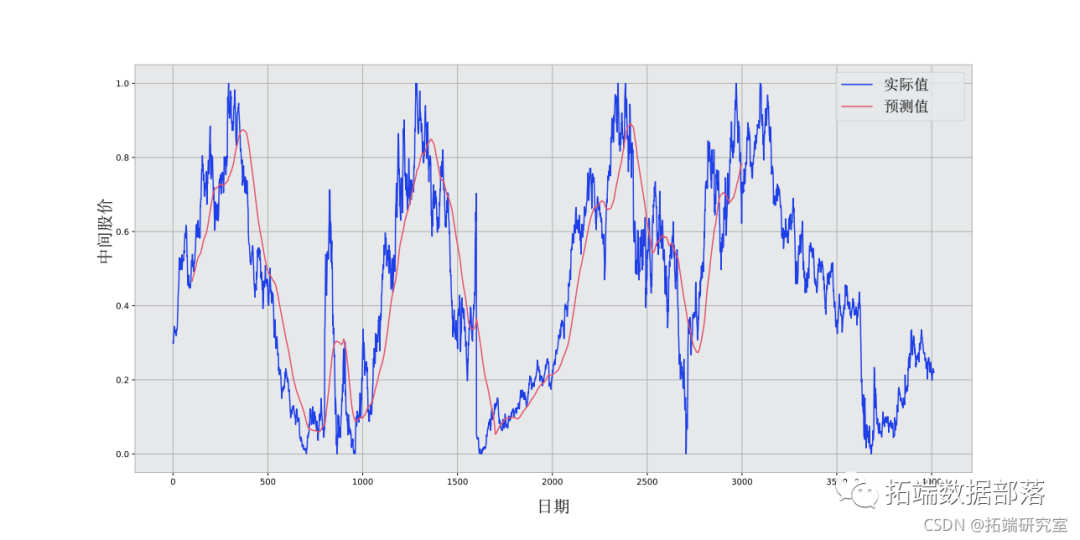
那么,上面的图表(和MSE)说明了什么?
似乎对于非常短的预测(提前一天)来说,这个模型还不算太差。鉴于股票价格不会在一夜之间从0变化到100,这种行为是合理的。接下来,使用指数移动平均线。
指数移动平均线
你可能已经在互联网上看到一些文章,使用非常复杂的模型,并预测了几乎准确的股票市场行为。但是请注意! 这些只是视觉上的错觉,并不是由于学到了有用的东西。你将在下面看到如何用一个简单的平均法来复制这种行为。
在指数移动平均法中,你计算xt+1为。

其中 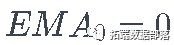 和
和  是在一段时间内保持的指数移动平均数值。.
是在一段时间内保持的指数移动平均数值。.
上述公式基本上是计算t+1时间步长的指数移动平均线,并将其作为超前一步的预测。γ决定最近的预测对EMA的贡献是什么。例如,γ=0.1只能得到当前值的10%进入EMA。因为你只取最近的一小部分,它允许保留你在平均数中很早看到的更早的值。请看下面用于预测向前一步的情况。
for idx in range(1,N):mean = mean\*dec + (1.0-de)\*train\[idx-1\]pred.append(mean)MSE: 0.00003plt.plot(mid_data)
plt.plot(pred)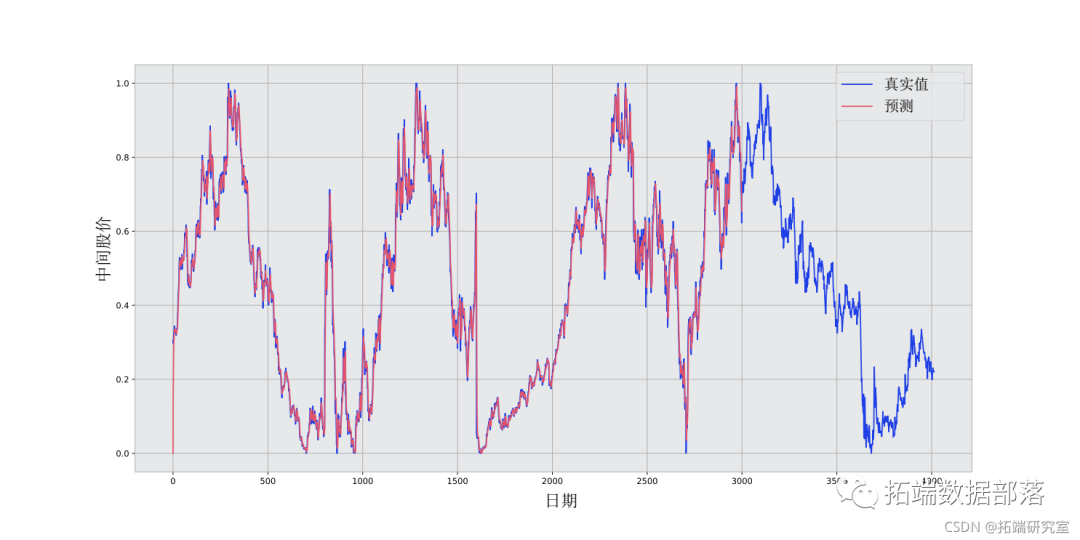
如果指数式移动平均数这么好,为什么还需要更好的模型?
拟合结果很好,遵循真实的分布(并且由非常低的MSE证明)。实际上,仅凭第二天的股票市场价格是没有意义的。就我个人而言,我想要的不是第二天的确切股市价格,而是未来30天的股市价格是上涨还是下跌。尝试这样做,你会发现EMA方法的缺陷。
现在尝试在窗口中进行预测(比如你预测未来2天的窗口,而不是仅仅预测未来一天)。然后你会意识到EMA会有多大的误差。下面是一个例子。
预测超过一步的未来股价
我们假设数值,比如xt=0.4,EMA=0.5,γ=0.5
假设你得到的输出有以下公式

所以你有 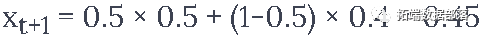
所以 
所以下一个预测Xt+2变成了

这就是 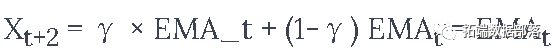
或者在这个例子中, 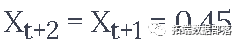
所以,无论你对未来进行多少步预测,你都会在所有未来的预测步中不断得到相同的答案。
你有一个解决方案,可以输出有用的信息,就是看看基于动量的算法。它们根据过去最近的数值是上升还是下降(不是准确的数值)进行预测。例如,它们会说第二天的价格可能会降低,如果过去几天的价格一直在下降,这听起来很合理。然而,我们使用一个更复杂的模型:LSTM模型。
这些模型已经在时间序列预测领域非常热门,因为它们在时间序列数据的建模方面非常出色。你将看到数据中是否真的隐藏有你可以利用的模式。
LSTM简介:对股票走势进行远期预测
长短期记忆模型是极其强大的时间序列模型。它们可以预测未来任意步。LSTM模块(或单元)有5个基本组成部分,使其能够对长期和短期数据进行建模。
单元状态(ct)--这代表了单元的内部记忆,它同时存储了短期记忆和长期记忆
_隐藏状态_(ht)--这是根据当前输入、以前的_隐藏状态_和当前的单元输入计算出来的输出状态信息,你最终会用它来预测未来的股市价格。此外,隐藏状态可以决定只检索存储在单元状态中的短期或长期或两种类型的记忆来进行下一次预测。
输入门(it)--决定当前输入的信息有多少流向单元状态
遗忘门(ft)--决定有多少来自当前输入和前一个单元状态的信息流入当前单元状态
输出门(ot)--决定多少信息从当前单元状态流入隐藏状态,因此,如果需要,LSTM可以只挑选长期记忆或短期记忆和长期记忆。
TensorFlow为实现时间序列模型提供了一个不错的API(称为RNN API)。
数据生成器
你首先要实现一个数据生成器来训练你的模型。这个数据生成器将有一个名为.unroll\_batches(...)的方法,它将输出一组依次获得的num\_unrollings批次的输入数据,其中一个批次的数据大小为[batch_size, 1]。那么每一批输入数据都会有一个相应的输出数据批。
例如,如果num\_unrollings=3,batch\_size=4,一组unrolled批次。
输入数据
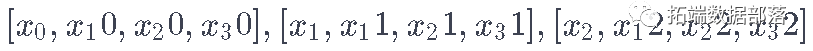
输出数据:

数据增强(_Data_ _Augmentation_)
数据增强(_Data_ _Augmentation_)又称为数据增广。另外,为了使你的模型稳健,你不会让x\_t的输出总是x\_t+1。相反,你将从x\_t+1,x\_t+2,...,xt+N的集合中随机抽取一个输出,其中N是一个小窗口大小。
这里你要做以下假设:
x\_t+1,x\_t+2,...,xt+N不会彼此相距很远。
我个人认为这对股票走势预测来说是一个合理的假设。
下面你直观地说明一批数据是如何产生的。
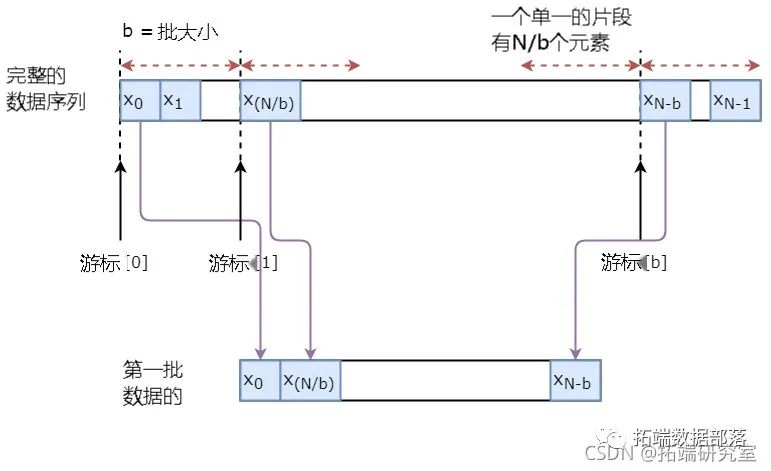

定义超参数
在本节中,你将定义几个超参数。D是输入的维度。这很简单,因为你把之前的股票价格作为输入,并预测下一个股票价格,这应该是1。
然后你有num\_unrollings,这是一个与用于优化LSTM模型的通过时间的反向传播(BPTT)有关的超参数。这表示你在一个优化步骤中考虑多少个连续的时间步骤。可以认为,不是通过查看单个时间步骤来优化模型,而是通过查看num\_unrollings时间步骤来优化网络。越大越好。
然后,你有batch_size。批量大小是指在一个时间步长中考虑多少个数据样本。
接下来你定义num_nodes,它代表每个单元中隐藏神经元的数量。你可以看到,在这个例子中,有三层LSTMs。
D = 1 # 数据的维度。因为你的数据是一维的,所以是1
unrollings = 50 # 未来的时间步数。
batch_size = 500 # 一个批次中的样本数
num_nodes = \[200,200,150\] # 我们所使用的深层LSTM堆栈中每一层的隐藏节点数量
n\_layers = len(num\_nodes) # 层的数量
dropout = 0.2 # 丢弃量定义输入和输出
接下来你要为训练输入和标签定义占位符。你有一个输入占位符的列表,其中每个占位符都包含一个批次的数据。而列表中有num_unrollings占位符,这些占位符将被一次性用于一个优化步骤。
#输入数据
train\_inputs, train\_outputs = \[\],\[\]定义LSTM和回归层的参数
你将有三层LSTM和一个线性回归层,用w和b表示,它采取最后一个长短期记忆单元的输出,并输出下一个时间步骤的预测。此外,你可以让dropout实现LSTM单元,因为它们可以提高性能,减少过拟合。
计算LSTM输出并将其传递到回归层以获得最终预测结果
在这一节中,你首先创建TensorFlow变量(c和h),这些变量将保持长短时记忆单元的状态和隐藏状态。然后,你将训练输入的列表转换为[unrollings, batch\_size, D]的形状。然后用ynamic\_rnn函数计算LSTM输出,并将输出分割成num张量列表。
# 创建单元格状态和隐藏状态变量保持LSTM的状态for li in range(n):c.append(tf.Variable(tf.zeros(\[batch\_size, num\_nodes\[li\]\])))h.append(tf.Variable(tf.zeros(\[batch\_size, num\_nodes\[li\]\])))# 做几次张量转换,因为函数dynamic_rnn要求输出必须是一种特定的格式。损失计算和优化器
现在,要计算损失。对于每一批预测和真实输出,都要计算出平均平方误差。而你把所有这些均方差损失加在一起(不是平均)。最后,定义你要使用的优化器来优化神经网络。在这种情况下,你可以使用Adam,它是一个非常新的、表现良好的优化器。
# 在计算损失时,你需要注意准确的形式,因为你计算的是所有未滚动的步的损失
# 因此,取每个批的平均误差,并得到所有未滚动步的总和range(n)\]):for ui in range(nums):loss += tf.mean(0.5*(splits\[ui\]-train\[ui\])**2)
预测相关的计算
在这里,你定义了预测相关的TensorFlow操作。首先,定义一个用于输入的占位符(sample\_inputs),然后与训练阶段类似,你定义预测的状态变量(sample\_c和sample\_h)。最后,你用dynamic\_rnn函数计算预测结果,然后通过回归层(w和b)发送输出。你还应该定义reset\_sample\_state操作,它可以重置单元状态和隐藏状态。
# 为预测阶段保持LSTM状态
for li in range(n_layers):sample\_c.append(tf.Variable(tf.zeros(\[1, num\_nodes\[li\]\]))sample\_h.append(tf.Variable(tf.zeros(\[1, num\_nodes\[li\]\])))
运行LSTM
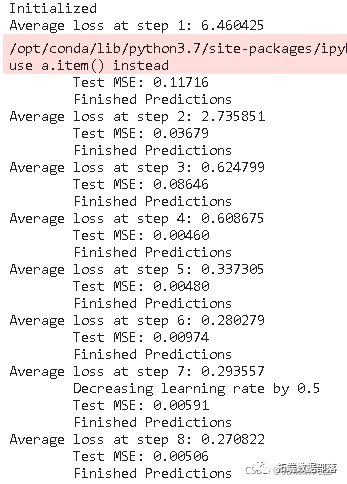
在这里,你将训练并预测几个历时的股票价格走势,并观察预测结果是否随着时间的推移而变得更好或更差。
在时间序列上定义一个测试起点集(test\_points\_seq)来评估模型。
对于每个训练轮数
对于训练数据的完整序列长度
通过迭代测试点之前的num_unrollings数据点来更新LSTM状态
连续进行n\_predict\_once步骤的预测,将之前的预测作为当前输入。
计算预测的n\_predict\_once点与这些时间戳的真实股票价格之间的MSE损失
展开一组num_unrollings的批次
用未滚动的批次训练神经网络
计算平均训练损失
对于测试集的每个起点
...

预测可视化
你可以看到MSE损失是如何随着训练量的增加而下降的。这是一个好兆头,表明模型正在学习一些有用的东西。你可以将网络的MSE损失与你做标准平均时得到的MSE损失(0.004)进行比较。你可以看到,LSTM比标准平均法做得更好。而且你知道,标准平均法(虽然不完美)合理地遵循了真实的股票价格变动。
best_epoch = 28 # 用得到最佳结果的epoch# 绘制预测值随时间变化的情况
# 绘制低α值的旧预测和高α值的新预测plt.plot(xval,yval)# 预测你得到的最佳测试预测值
plt.plot(range(df.shap),mid_data)plt.plot(xval,yval)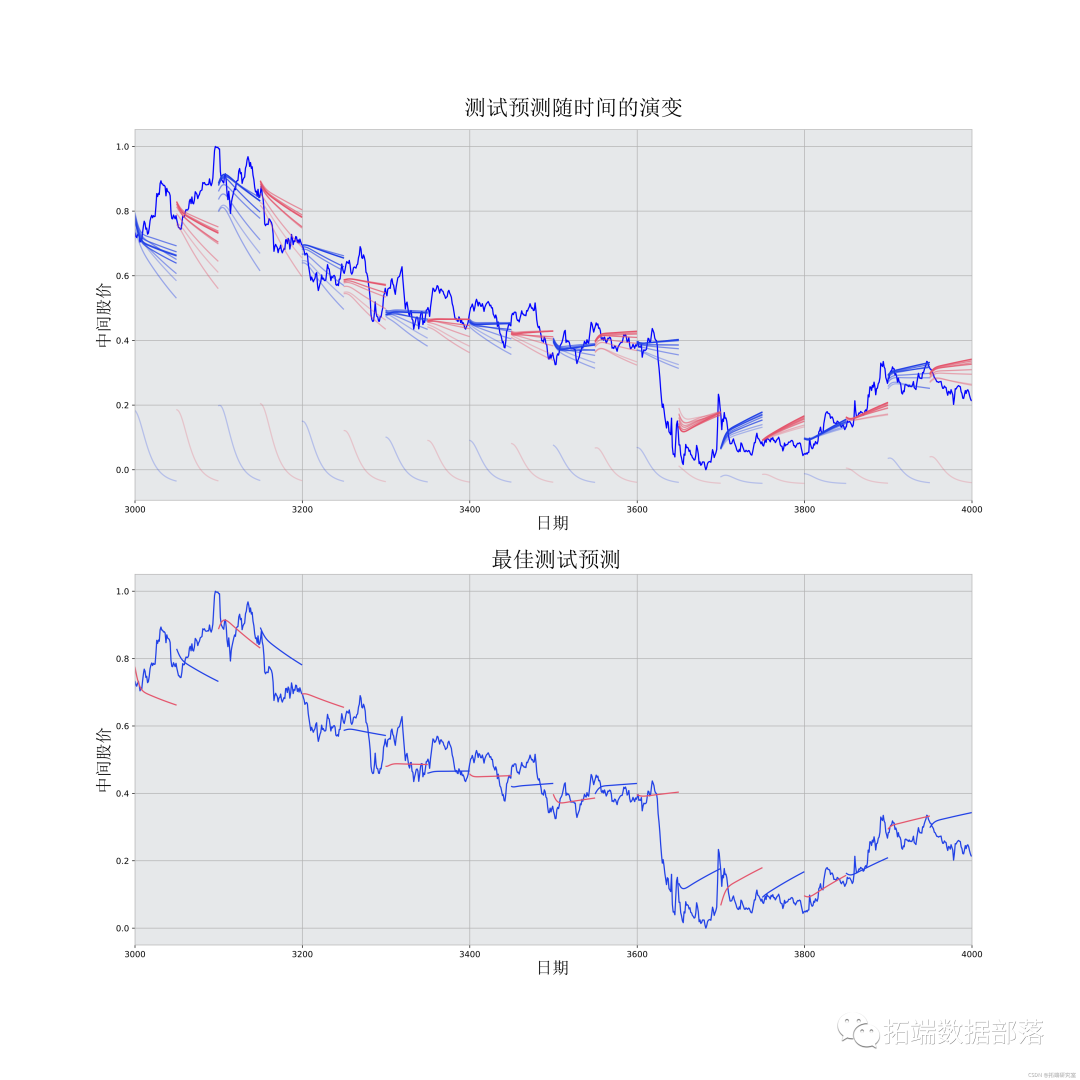
虽然不完美,但LSTM似乎能够在大多数时候正确预测股票价格行为。请注意,你所做的预测大致在0和1.0的范围内(也就是说,不是真实的股票价格)。这没关系,因为你预测的是股票价格的走势,而不是价格本身。
总结
在本教程中,首先介绍了你为什么需要为股票价格建模的动机。接着是解释数据。然后两种平均技术,它们允许你对未来一步进行预测。接下来你看到,当你需要预测超过一步的未来时,这些方法是无用的。此后,讨论了如何使用LSTM来进行未来多步的预测。最后,将结果可视化,看到模型(虽然不完美)在正确预测股票价格走势方面相当出色。
在这里,我陈述一下本教程的几个收获。
股票价格/走势预测是一项极其困难的任务。我个人认为,不应该把任何一个股票预测模型视为理所当然,盲目地依赖它们。然而模型可能在大多数时候能够正确预测股票价格走势,但不总是如此。
不要被外面那些显示预测曲线与真实股票价格完全重合的文章所迷惑。这可以用一个简单的平均技术来复制,在实践中它是没有用的。更明智的做法是预测股票价格的变动。
该模型的超参数对你获得的结果非常敏感。因此,要做的一件非常好的事情是对超参数运行一些超参数优化技术(例如,网格搜索/随机搜索)。下面我列出了一些最关键的超参数
优化器的学习率
层数和每层的隐藏单元的数量
优化器。我发现Adam的表现最好
模型的类型。你可以尝试GRU/标准LSTM和评估性能差异。

本文摘选《Python中TensorFlow的长短期记忆神经网络(LSTM)、指数移动平均法预测股票市场和可视化》,点击“阅读原文”获取全文完整资料。


点击标题查阅往期内容
RNN循环神经网络 、LSTM长短期记忆网络实现时间序列长期利率预测
结合新冠疫情COVID-19股票价格预测:ARIMA,KNN和神经网络时间序列分析
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
用PyTorch机器学习神经网络分类预测银行客户流失模型
PYTHON用LSTM长短期记忆神经网络的参数优化方法预测时间序列洗发水销售数据
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
R语言深度学习卷积神经网络 (CNN)对 CIFAR 图像进行分类:训练与结果评估可视化
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言深度学习Keras循环神经网络(RNN)模型预测多输出变量时间序列
R语言KERAS用RNN、双向RNNS递归神经网络、LSTM分析预测温度时间序列、 IMDB电影评分情感
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言中的神经网络预测时间序列:多层感知器(MLP)和极限学习机(ELM)数据分析报告
R语言深度学习:用keras神经网络回归模型预测时间序列数据
Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
R语言KERAS深度学习CNN卷积神经网络分类识别手写数字图像数据(MNIST)
MATLAB中用BP神经网络预测人体脂肪百分比数据
Python中用PyTorch机器学习神经网络分类预测银行客户流失模型
R语言实现CNN(卷积神经网络)模型进行回归数据分析
SAS使用鸢尾花(iris)数据集训练人工神经网络(ANN)模型
【视频】R语言实现CNN(卷积神经网络)模型进行回归数据分析
Python使用神经网络进行简单文本分类
R语言用神经网络改进Nelson-Siegel模型拟合收益率曲线分析
R语言基于递归神经网络RNN的温度时间序列预测
R语言神经网络模型预测车辆数量时间序列
R语言中的BP神经网络模型分析学生成绩
matlab使用长短期记忆(LSTM)神经网络对序列数据进行分类
R语言实现拟合神经网络预测和结果可视化
用R语言实现神经网络预测股票实例
使用PYTHON中KERAS的LSTM递归神经网络进行时间序列预测
python用于NLP的seq2seq模型实例:用Keras实现神经网络机器翻译
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类
欲获取全文文件,请点击左下角“阅读原文”。


![]()

相关文章:
Python中TensorFlow的长短期记忆神经网络(LSTM)、指数移动平均法预测股票市场和可视化...
原文链接:http://tecdat.cn/?p23689 本文探索Python中的长短期记忆(LSTM)网络,以及如何使用它们来进行股市预测(点击文末“阅读原文”获取完整代码数据)。 相关视频 在本文中,你将看到如何使用…...

多线程的学习第二篇
多线程 线程是为了解决并发编程引入的机制. 线程相比于进程来说,更轻量 ~~ 更轻量的体现: 创建线程比创建进程,开销更小销毁线程比销毁进程,开销更小调度线程比调度进程,开销更小 进程是包含线程的. 同一个进程里的若干线程之间,共享着内存资源和文件描述符表 每个线程被独…...
git之撤销工作区的修改和版本回溯
有时候在工作区做了一些修改和代码调试不想要了,可如下做 (1)步骤1:删除目录代码,确保.git目录不能修改 (2)git log 得到相关的commit sha值 可配合git reflog 得到相要的sha值 (3)执行git reset --hard sha值,可以得到时间轴任意版本的代码 git reset --hard sha值干净的代…...

sed awk使用简介
简介 本文主要介绍 Linux 系统的两个神级工具:sed 和 awk ,他们是Linux高手们必备的技能,很值得我们去研究的东西。 这里是我在网上书上收集的相关资料,因为这两个工具很有名也很重要,所以这些资料会帮助我更好的了解…...
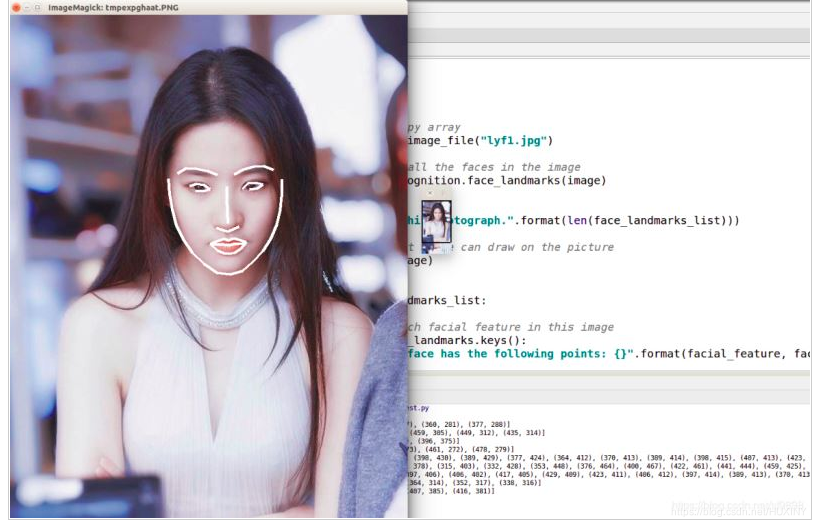
竞赛选题 基于深度学习的人脸识别系统
前言 🔥 优质竞赛项目系列,今天要分享的是 基于深度学习的人脸识别系统 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng-senior/…...

idea Terminal 回退历史版本 Git指令 git reset
——————强制回滚历史版本—————— 一、idea Terminal 第一步:复制版本号 (右击项目–> Git --> Show History -->选中要回退的版本–>Copy Revision Number,直接复制;) 第二步:ide…...
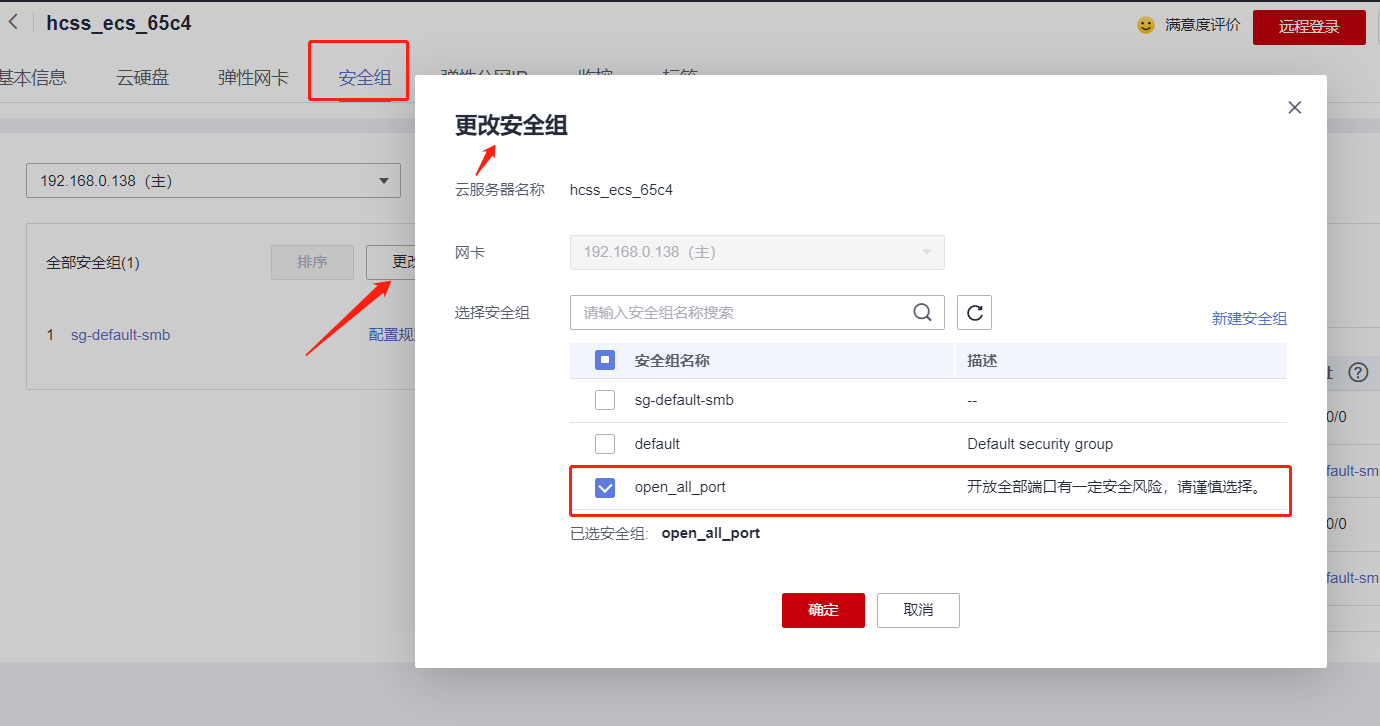
华为云云耀云服务器L实例评测|华为云上安装监控服务Prometheus三件套安装
文章目录 华为云云耀云服务器L实例评测|华为云上试用监控服务Prometheus一、监控服务Prometheus三件套介绍二、华为云主机准备三、Prometheus安装四、Grafana安装五、alertmanager安装六、三个服务的启停管理1. Prometheus、Alertmanager 和 Grafana 启动顺序2. 使用…...

C语言基础知识点(八)联合体和大小端模式
以下程序的输出是() union myun {struct { int x, y, z;} u;int k; } a; int main() {a.u.x 4;a.u.y 5;a.u.z 6;a.k 0;printf("%d\n", a.u.x); } 小端模式 数据的低位放在低地址空间,数据的高位放在高地址空间 简记ÿ…...

一个线程运行时发生异常会怎样?
如果一个线程在运行时发生异常而没有被捕获(即未被适当的异常处理代码处理),则会导致以下几种情况之一: 线程终止:线程会立即终止其执行,并将异常信息打印到标准错误输出(System.err)。这通常包括异常的类型、堆栈跟踪信息以及异常消息。 ThreadDeath 异常:在某些情况…...

CSS中去掉li前面的圆点方法
1. 引言 在网页开发中,我们经常会使用无序列表(<ul>)来展示一系列的项目。默认情况下,每个列表项(<li>)前面都会有一个圆点作为标记。然而,在某些情况下,我们可能希望去…...

Python:获取当前目录下所有文件夹名称及文件夹下所有文件名称
获取当前目录下所有文件夹名称 def get_group_list(folder_path):group_list []for root, dirs, files in os.walk(folder_path):for dir in dirs:group_list.append(dir)return group_list获取文件夹下所有文件名称 def get_file_list(folder_path, group_name):file_list …...
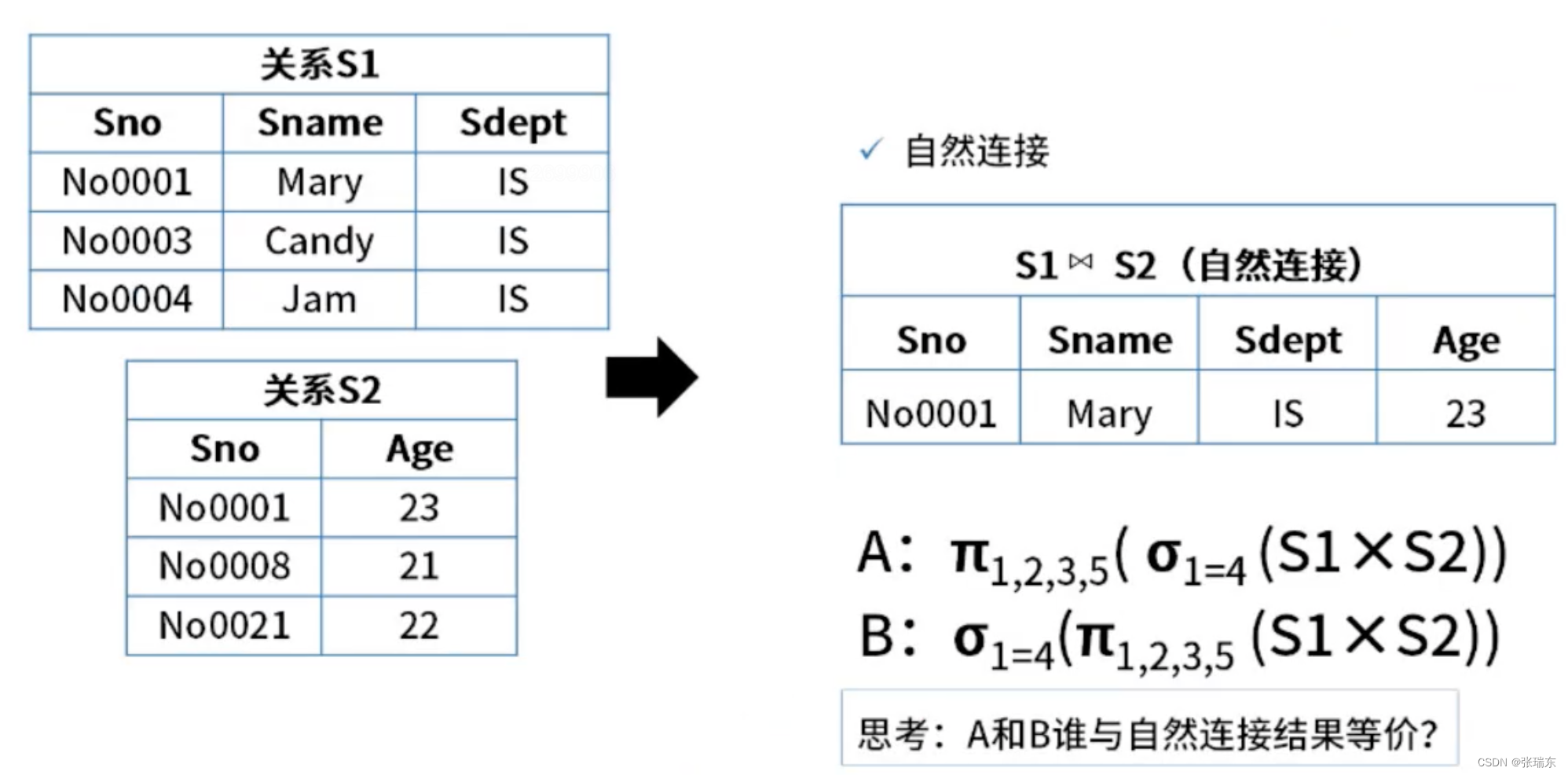
系统架构设计师-数据库系统(1)
目录 一、数据库模式 1、集中式数据库 2、分布式数据库 二、数据库设计过程 1、E-R模型 2、概念结构设计 3、逻辑结构设计 三、关系代数 1、并交差 2、投影和选择 3、笛卡尔积 4、自然连接 一、数据库模式 1、集中式数据库 三级模式: (1)外…...

Docker的相关知识介绍以及mac环境的安装
一、什么是Docker 大型项目组件较多,运行环境也较为复杂,部署时会碰到一些问题: 依赖关系复杂,容易出现兼容性问题开发、测试、生产环境有差异 Docker就是来解决这些问题的。Docker是一个快速交付应用、运行应用的技术&#x…...
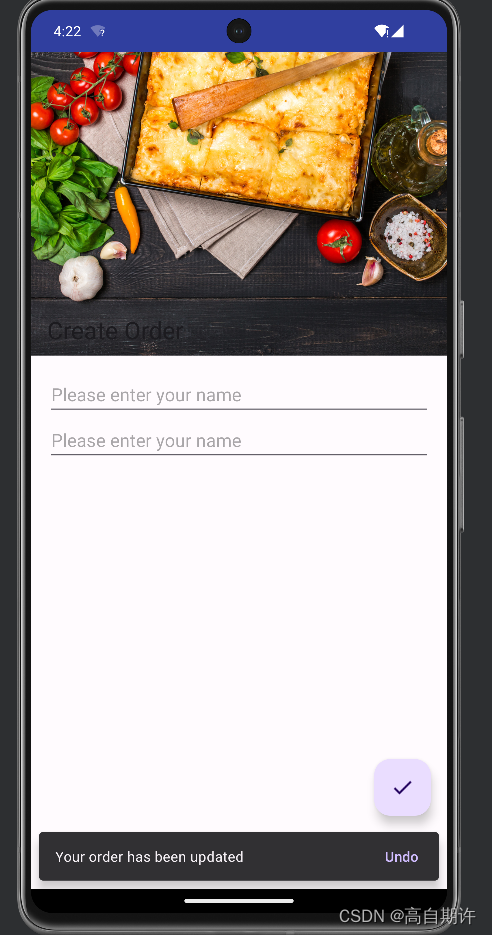
Android设计支持库
本文所有的代码均存于 https://github.com/MADMAX110/BitsandPizzas 设计支持库(Design Support Library)是 Google 在 2015 年的 I/O 大会上发布的全新 Material Design 支持库,在这个 support 库里面主要包含了 8 个新的 Material Design …...

【Java 基础篇】Java实现文件搜索详解
文件搜索是计算机应用中的一个常见任务,它允许用户查找特定文件或目录,以便更轻松地管理文件系统中的内容。在Java中,您可以使用各种方法来实现文件搜索。本文将详细介绍如何使用Java编写文件搜索功能,以及一些相关的内容。 文件…...
会C++还需要再去学Python吗?
提到的C、数据结构与算法、操作系统、计算机网络和数据库技术等确实是计算机科学中非常重要的基础知识领域,对于软件开发和计算机工程师来说,它们是必备的核心知识。掌握这些知识对于开发高性能、可靠和安全的应用程序非常重要。Python作为一种脚本语言&…...
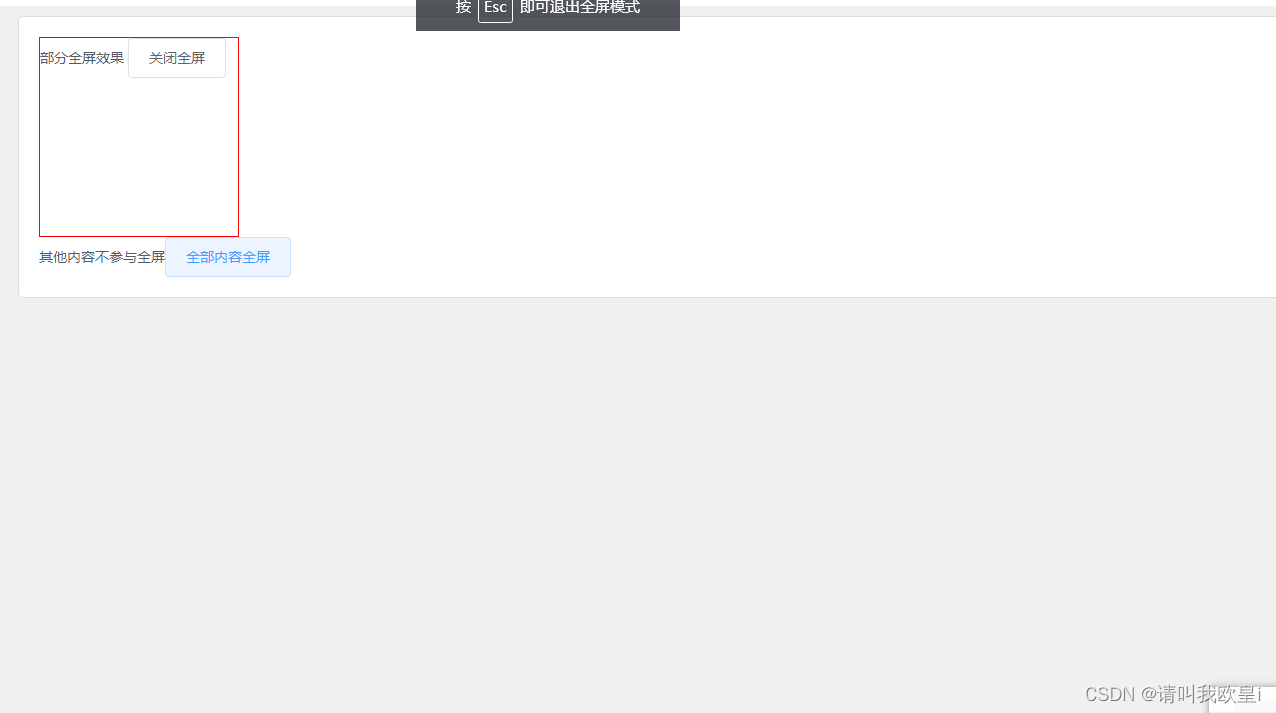
vue部分/所有内容全屏切换展示
需求:就是把一个页面的某一部分内容点击全屏操作按钮后全屏展示,并非所有内容全屏,所有内容的话那肯定就所有全屏展示啊,可以做切换 1.部分全屏代码 element.requestFullscreen();这个就是全屏的代码了,注意前面的ele…...

8.gec6818开发板通过并发多线程实现电子相册 智能家居 小游戏三合一完整项目
并发 前面编写的程序都是从mian函数开始,从上往下执行,称为顺序执行 假设一个程序需要I输入 C计算 P输出,以顺序执行三个上述程序,则其执行过程如下: 程序内部的语句是一条一条的执行,如果要运行多个程序…...

角度回归——角度编码方式
文章目录 1.为什么研究角度的编码方式?1.1 角度本身具有周期性1.2 深度学习的损失函数因为角度本身的周期性,在周期性的点上可能产生很大的Loss,造成训练不稳定1.3 那么如何处理边界问题呢:(以θ的边界问题为例&#x…...

【C# Programming】值类型、良构类型
值类型 1、值类型 值类型的变量直接包含值。换言之, 变量引用的位置就是值内存中实际存储的位置。 2、引用类型 引用类型的变量存储的是对一个对象实例的引用(通常为内存地址)。 复制引用类型的值时,复制的只是引用。这个引用非常小…...

ClawGuard:为Clawdbot AI智能体打造的安全监控与熔断防护系统
1. 项目概述:ClawGuard 是什么,以及为什么你需要它如果你正在使用或开发基于 Clawdbot 框架的 AI 智能体,那么“安全”和“可控”这两个词,大概率已经在你脑海里盘旋过无数次了。我接触过不少团队,从最初的兴奋于 AI 智…...

三维动画课程期末复盘:从零搭建我的马卡龙童话游乐场✨
当我按下 3ds Max 的渲染按钮,看着浅蓝的摩天轮缓缓转动、粉白的旋转木马跟着节奏起舞、淡紫色热气球轻轻飘动时,我才真正意识到:为期一学期的三维动画课程,就这样在我的指尖落下了帷幕。从刚打开软件连工具栏都认不全的 “小白”…...

练了半年演讲口才,汇报时还是结巴,说说我的真实感受
小林坐在会议室的角落,手心微微出汗。轮到他汇报季度项目进展时,他深吸一口气站起来——结果,开场白磕磕绊绊,PPT翻到第三页才找回节奏。散会后他苦笑着跟同事说:“演讲口才课我上了半年了,怎么还是这副德行…...

基于ChatGPT与Telethon的Telegram频道智能评论机器人开发指南
1. 项目概述与核心价值 如果你在运营Telegram频道,或者需要管理多个社群,肯定遇到过这样的场景:频道里每天都有大量新消息,你想保持活跃度、引导讨论,但手动回复每一条消息不仅耗时耗力,还很难保证回复的质…...
)
RT-Thread Sensor框架实战:5分钟搞定INA226电流电压功率监测(含I2C避坑指南)
RT-Thread Sensor框架实战:5分钟搞定INA226电流电压功率监测(含I2C避坑指南) 在嵌入式系统开发中,精准监测电流、电压和功率是许多应用场景的核心需求,无论是电池管理系统、智能硬件功耗分析,还是工业设备状…...

图像识别与目标检测:从概念到实战的全面解析
1. 项目概述:从“认脸”到“找茬”的认知跃迁在计算机视觉这个行当里干了十几年,我见过太多刚入行的朋友,甚至是一些有经验的开发者,对“图像识别”和“目标检测”这两个词傻傻分不清楚。经常有人拿着一个“识别猫狗”的需求过来&…...

深度重构黑苹果系统架构:OpenCore实战解析与性能优化
深度重构黑苹果系统架构:OpenCore实战解析与性能优化 【免费下载链接】Hackintosh 国光的黑苹果安装教程:手把手教你配置 OpenCore 项目地址: https://gitcode.com/gh_mirrors/hac/Hackintosh 在传统PC硬件与macOS系统兼容性的技术探索中…...

【PHP】编写php扩展
【PHP】编写php扩展 第一步 下载PHP的源代码,如php-5.4.16。解压后进入php-5.4.16/ext目录。输入 ./ext/_skel –extnamemyext,myext就是扩展的名称,执行后生成myext目录。 ext/_skel是PHP官方提供的用于生成php扩展骨架代码的工具。 cd myex…...

解决Claude Code频繁封号与Token不足的替代接入方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code频繁封号与Token不足的替代接入方案 1. 场景与核心思路 对于依赖Claude Code进行编程辅助的开发者而言࿰…...

个人开发者如何利用 Taotoken 管理多个项目的 AI 调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 个人开发者如何利用 Taotoken 管理多个项目的 AI 调用成本 对于独立开发者或自由职业者而言,同时维护多个小型项目是常…...