【kafka实战】03 SpringBoot使用kafka生产者和消费者示例
本节主要介绍用SpringBoot进行开发时,使用kafka进行生产和消费
一、引入依赖
<dependencies><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>com.google.code.gson</groupId><artifactId>gson</artifactId><version>2.8.6</version></dependency>
</dependencies>
二、添加topic
使用offset explore软件,添加一个topic

三、配置文件
server:port: 8080
spring:kafka:consumer:# Kafka服务器bootstrap-servers: 192.168.56.201:9092# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D#auto-commit-interval: 2s# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费分区的记录# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据(在消费者启动之后生成的记录)# none:当各分区都存在已提交的offset时,从提交的offset开始消费;只要有一个分区不存在已提交的offset,则抛出异常auto-offset-reset: latest# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量enable-auto-commit: false# 键的反序列化方式#key-deserializer: org.apache.kafka.common.serialization.StringDeserializerkey-deserializer: org.apache.kafka.common.serialization.StringDeserializer# 值的反序列化方式value-deserializer: org.apache.kafka.common.serialization.StringDeserializer# 这个参数定义了poll方法最多可以拉取多少条消息,默认值为500。如果在拉取消息的时候新消息不足500条,那有多少返回多少;如果超过500条,每次只返回500。# 这个默认值在有些场景下太大,有些场景很难保证能够在5min内处理完500条消息,# 如果消费者无法在5分钟内处理完500条消息的话就会触发reBalance,# 然后这批消息会被分配到另一个消费者中,还是会处理不完,这样这批消息就永远也处理不完。# 要避免出现上述问题,提前评估好处理一条消息最长需要多少时间,然后覆盖默认的max.poll.records参数# 注:需要开启BatchListener批量监听才会生效,如果不开启BatchListener则不会出现reBalance情况max-poll-records: 100properties:# 两次poll之间的最大间隔,默认值为5分钟。如果超过这个间隔会触发reBalancemax:poll:interval:ms: 600000# 当broker多久没有收到consumer的心跳请求后就触发reBalance,默认值是10ssession:timeout:ms: 10000listener:# 在侦听器容器中运行的线程数,一般设置为 机器数*分区数concurrency: 4# 自动提交关闭,需要设置手动消息确认ack-mode: manual_immediate# 消费监听接口监听的主题不存在时,默认会报错,所以设置为false忽略错误missing-topics-fatal: false# 两次poll之间的最大间隔,默认值为5分钟。如果超过这个间隔会触发reBalancepoll-timeout: 600000producer:# Kafka服务器bootstrap-servers: 192.168.56.201:9092# 发生错误后,消息重发的次数,开启事务必须设置大于0。retries: 3# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。# 开启事务时,必须设置为allacks: all# 当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。batch-size: 16384# 生产者内存缓冲区的大小。buffer-memory: 1024000# 键的序列化方式key-serializer: org.apache.kafka.common.serialization.StringSerializer# 值的序列化方式value-serializer: org.apache.kafka.common.serialization.StringSerializer四、生产者代码
@Slf4j
@RestController
@RequestMapping("/msg")
public class SendMessageController {@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;@GetMapping("send")public String send() {for (int i = 0; i < 100; i++) {OrderInfo orderInfo = new OrderInfo();orderInfo.setAddress("成都市高新区");orderInfo.setOrderId(String.valueOf(i));orderInfo.setProductName("华为P60:" + i);kafkaTemplate.send("order.topic", "order:" + i, new Gson().toJson(orderInfo));}return "success";}
}
五、消费者代码
消费者代码采用手动ack的方式
@Slf4j
@Component
public class KafkaOrderConsumer {@KafkaListener(topics = "order.topic", groupId = "orderGroup")public void consumeOrder(ConsumerRecord<String, String> record, Acknowledgment ack) {log.info("消费订单消息key={},value={}", record.key(), record.value());ack.acknowledge();}
}
代码git仓库:https://gitee.com/syk1234/mqdmo
相关文章:
【kafka实战】03 SpringBoot使用kafka生产者和消费者示例
本节主要介绍用SpringBoot进行开发时,使用kafka进行生产和消费 一、引入依赖 <dependencies><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><depen…...
Only file and data URLs are supported by the default ESM loader
1.版本问题 说明:将node版本提高就可以了。 2.nvm 说明:如果不想重复安装node版本,那么可以参考本人的nvm文档. nvm版本控制工具_FOREVER-Q的博客-CSDN博客...
LeetCode01
LeetCode01 两数之和 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和 为目标值 target 的那两个整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。 你…...

计算机网络高频面试题集锦
问题1:谈一谈对OSI七层模型和TCP/IP四层模型的理解? 回答点:七层模型每层对应的作用及相关协议、为什么分层、为什么有TCP/IP四层模型 参考: 1、OSI七层参考模型是一个ISO组织所提出的一个标准参考分层模型,它按照数…...
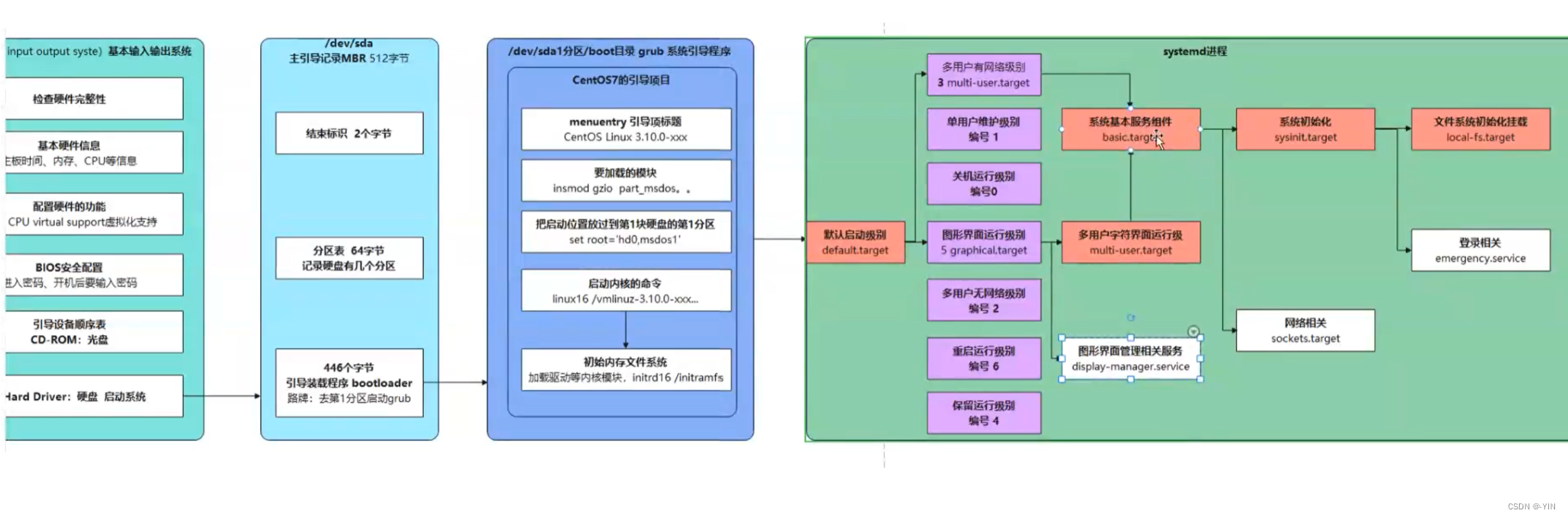
Linux启动过程详解 Xmind导图笔记
参考大佬博客: 简要描述linux系统从开机到登陆界面的启动过程 Linux启动过程详解 Bootloader详解 来源:从BIOS开始画图了解Linux启动过程——老杨Linux...

Qt5开发及实例V2.0-第十七章-Qt版MyWord字处理软件
Qt5开发及实例V2.0-第十七章-Qt版MyWord字处理软件 第17章-Qt版MyWord字处理软件17.1 运行界面17.1.1 菜单设计基本操作17.1.2.MyWord系统菜单 17.2 工具栏设计17.2.1 与菜单对应的工具条17.2.2 附加功能的工具条 这段代码的作用是加载系统标准字号集,只要在主窗体构…...

机器视觉工程师们,常回家看看
我们在这个社会上扮演着多重角色,有时候我们很难平衡好这些角色之间的关系。 人们常言,积善成德,改变命运。善修者,懂得积累,懂得改变命运的重要性。 我曾年少不知父母之不易。一路依靠,一路成长。 所谓…...

网络隔离下实现的文件传输,现有的方式真的安全吗?
在当今的信息化时代,网络安全已经成为了各个企业和机构不可忽视的问题。为了保护内部数据和系统不受外部网络的攻击和泄露,一些涉及国家安全、商业机密、个人隐私等敏感信息的企业和机构,通常会对内外网进行隔离,即建立一个独立的…...
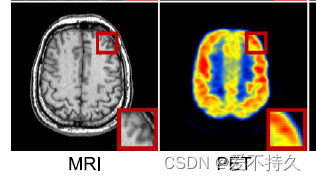
[医学图像知识]CT图和PET图的成像表现形式
1.CT图通常来说是单通道灰色图,用灰度值表示了结构对于x射线的吸收程度。 2.PET/SPECT图最初也是灰度图,用灰度值表示细胞的反射gama射线的程度,但是为了更好的观测不同细胞等的区别,通常将灰度图转化为了 伪彩色图像。 找个例子…...
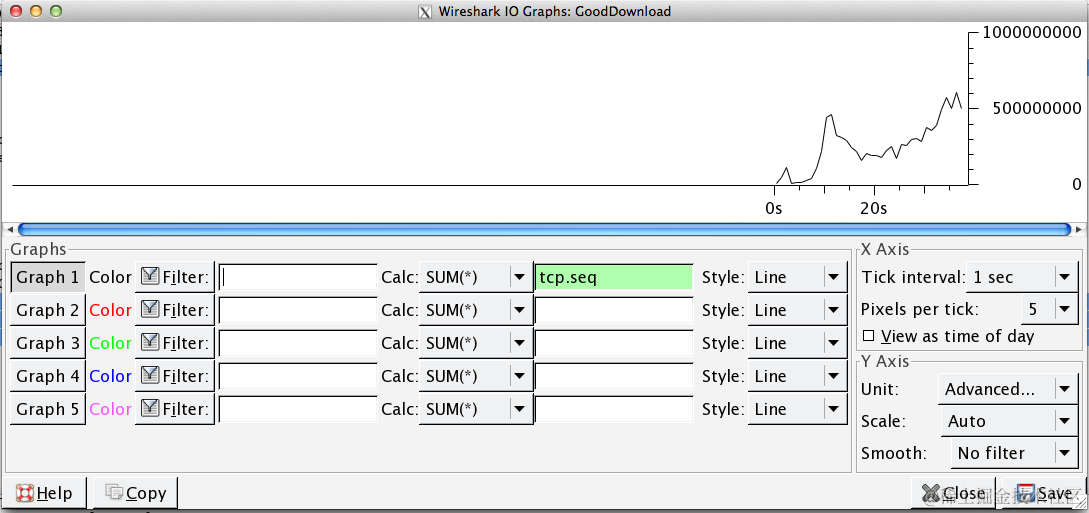
聊聊wireshark的进阶使用功能 | 京东云技术团队
1. 前言 emmm,说起网络知识学习肯定离不来wireshark工具,这个工具能够帮助我们快速地定位网络问题以及帮助正在学习网络协议这块的知识的同学验证理论与实际的一大利器,平时更多的只是停留在初步的使用阶段。也是利用部门内部的网络兴趣小组…...

小米手机安装面具教程(Xiaomi手机获取root权限)
文章目录 1.Magisk中文网:2.某呼:3.最后一步打开cmd命令行输入的时候:4.Flash Boot 通包-Magisk(Flash Boot通刷包)5.小米Rom下载(官方刷机包)6.Magisk最新版本国内源下载 1.Magisk中文网: htt…...

DSU ON TREE
DSU ON TREE DSU:并查集 DSU ON TREE:树上启发式合并 我也不知道为啥树上并查集就是树上启发式合并 启发式合并的思想是每次把小的往大的合并,也就是最大化利用已有的答案(大的数组不用清空,在原基础上加上小的即可&…...

Java“对象”
Java:PO、VO、BO、DO、DAO、DTO、POJO PO持久化对象(Persistent Object) PO是持久化对象,用于表示数据库中的实体或表的映射通常与数据库表的结构和字段对应PO的属性对应数据库表的字段,可以进行持久化操作࿰…...

vuepress+gitee免费搭建个人在线博客(无保留版)
文章目录 最终效果,一睹为快!一、工具选型二、什么是VuePress三、准备工作3.1 node 安装3.2 Git安装3.3 Gitee账号注册 四、搭建步骤4.1 初始化VuePress4.2 安装VuePress4.3 初始化目录4.4 编写文章 五、部署到Gitee5.1 创建仓库5.2 个人空间地址设置4.3…...

Android 12.0 系统限制上网系列之iptables用IOemNetd实现app上网白名单的功能实现
1.前言 在12.0的系统rom定制化开发中,对于系统限制网络的使用,在system中netd网络这块的产品需要中,会要求设置app上网白名单的功能, liunx中iptables命令也是比较重要的,接下来就来在IOemNetd这块实现app上网白名单的的相关功能,就是在 系统中只能允许某个app上网,就是…...

Idea和DataGrip自定义常用代码模板,熟练使用快捷模板可促进开发效率
场景: 在实际工作中,我们不可能一个一个字母的去敲代码,为了提升开发效率,可以使用常用的快捷代码模板。idea和datagrip自带的有,我们也可以自定义快捷模板 一、Idea自定义代码模板、有些是基于 hutool 常用包 1、-&g…...

Vue.js :实现嵌套对话框的查看按钮
Vue.js :实现嵌套对话框的查看按钮 Vue.js 是一款流行的 JavaScript 框架,用于构建交互性强、响应式的前端应用程序。本博客将介绍如何使用 Vue.js 和 Element UI 库创建一个前端应用,其中包括了嵌套对话框的查看按钮,以及如何在…...

9.2.4 【MySQL】段的结构
段不对应表空间中某一个连续的物理区域,而是一个逻辑上的概念,由若干个零散的页面以及一些完整的区组成。像每个区都有对应的XDES Entry来记录这个区中的属性一样,定义了一个INODE Entry结构来记录段中的属性。 它的各个部分释义如下…...
怎么快速提取图片中的文字信息?怎么使用OCR图片文字提取一键提取文字
图片里的文字如何提取?一些图片中的文字信息是我们需要的,但是一个个输入太麻烦了,怎么将图片上的文字提取出来?Initiator是一款易于使用的小型 macOS OCR(光学字符识别)应用程序,可提取和识别 Mac 计算机屏幕上的任…...

Selenium隐藏浏览器特征
Selenium隐藏浏览器特征 Selenium特征1. CDP2. stealth.min.js3. undetected_chromedriver4. 操作已开启的浏览器4. 常见的隐藏Selenium特征的方法4.1 修改navigator.webdriver标志4.2 改变user-agent4.3 排除或关闭一些Selenium相关的开关4.4 代码展示4.5 总结 Selenium特征 …...

基于RAG与向量数据库的智能网页问答机器人构建实战
1. 项目概述:一个能“读懂”网页的智能问答机器人最近在折腾一个挺有意思的开源项目,叫web-qa-bot。简单来说,它就是一个能自动抓取网页内容,然后像人一样理解、消化,最后回答你问题的智能机器人。想象一下,…...

二供泵站设备全生命周期管理系统方案
在城镇居民二次供水管理体系中,泵房分散于各小区及大型建筑,管理部门长期面临“监管盲区、故障滞后、运维成本高”的突出矛盾。由于缺乏统一的远程监控手段,水泵运行状态、进出水压力、水箱液位、变频器参数等关键数据无法实时获取࿰…...

【审计专栏-监督监管】【信息科学与工程学】计算机科学与自动化——第一百五十篇 招投标领域中的应用数学02
编号 033 维度 内容 编号 033 领域 招投标数学分析 类型 餐饮工程“食材价格虚高”与“供应链绑定”式合谋识别 招投标领域 团餐服务、食材集中采购、厨房设备采购 子领域 学校食堂承包、机关单位食堂外包、大型活动供餐、中央厨房建设 招投标的行业 …...

LuaDec51终极指南:3步快速掌握Lua 5.1字节码反编译
LuaDec51终极指南:3步快速掌握Lua 5.1字节码反编译 【免费下载链接】luadec51 Lua Decompiler for Lua version 5.1 项目地址: https://gitcode.com/gh_mirrors/lu/luadec51 LuaDec51是一个强大的Lua 5.1字节码反编译工具,能够将编译后的Lua字节码…...

ChatGPT对话导出工具:一键保存结构化对话记录到Markdown
1. 项目概述:一个帮你“打包”对话记录的工具如果你经常使用ChatGPT的网页版进行深度对话,无论是用它来辅助编程、学习新知识,还是进行创意写作,你可能会遇到一个共同的痛点:那些充满价值的对话记录,被“锁…...

CentOS 7服务器上,从零搞定NVIDIA驱动和CUDA 11.1的保姆级避坑指南
CentOS 7服务器NVIDIA驱动与CUDA 11.1实战避坑手册 接手一台老旧GPU服务器时,最令人头疼的莫过于搭建深度学习环境。那些看似简单的安装步骤背后,往往隐藏着无数个让新手崩溃的"坑"。本文将带你穿越雷区,用最稳妥的方式在CentOS 7上…...
——GPIO输入实验)
STM32单片机学习(11)——GPIO输入实验
文章目录实验一:按住按键LED点亮实验题目要求接线与程序框架程序实现存在的问题 —— 按键抖动优化后的程序代码实验二:光敏电阻传感器控制LED实验光敏电阻光敏电阻传感器各部分元器件介绍比较器正极输入电压分析比较器负极输入电压分析最终结论临界状态…...

IDEA Diagrams保姆级教程:5分钟看懂Java类图,定位源码、分析依赖超实用
IDEA Diagrams实战指南:用类图透视Java项目架构 刚接手一个遗留Java项目时,面对层层嵌套的类关系和错综复杂的接口实现,很多开发者都会感到无从下手。这时候,IDEA内置的Diagrams功能就像一盏明灯,能够将抽象的代码结构…...

Taotoken用量看板如何让我们清晰掌握各模型消耗与团队使用习惯
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何让我们清晰掌握各模型消耗与团队使用习惯 作为团队管理者,在引入大模型能力支持业务开发时&#…...

从零上手Ranorex:录制、验证与参数化测试实战解析
1. Ranorex自动化测试入门指南 第一次接触Ranorex时,我和大多数测试工程师一样,被它强大的功能所震撼。作为一款专业的自动化测试工具,Ranorex能够显著提升测试效率,特别适合需要频繁回归测试的项目场景。记得我第一次用它完成计算…...