LLaMa
文章目录
- Problems
- 403
- 代码文件
- LLaMA: Open and Efficient Foundation Language Models
- 方法
- 预训练数据
- 结构
- 优化器
- 一些加速的方法
- 结果
- Common Sense Reasoning
- Closed-book Question Answering
- Reading Comprehension
- Massive Multitask Language Understanding
- Instruction Finetuning
- 附录
- Question Answering
- Generations from LLaMA-65B
- Generations from LLaMA-I
- Llama 2: Open Foundation and Fine-Tuned Chat Models
- pretraining methodology
- Pretraining Data
- Training Details
- fine-tuning methodology
- Supervised Fine-Tuning(SFT)
- Reinforcement Learning with Human Feedback (RLHF)
Problems
403
reclone and request.
代码文件
两个测试样例:
example_text_completion.py: 文本补全示例;example_chat_completion.py: 对话生成示例.
torchrun --nproc_per_node 1 example_text_completion.py \--ckpt_dir llama-2-7b/ \--tokenizer_path tokenizer.model \--max_seq_len 128 --max_batch_size 4
torchrun --nproc_per_node 1 example_chat_completion.py \--ckpt_dir llama-2-7b-chat/ \--tokenizer_path tokenizer.model \--max_seq_len 512 --max_batch_size 6
ckpt_dir: 模型文件路径
tokenizer_path: 分词器文件路径
对于示例一, prompt中提供了需要补全的文本.
对于示例二, prompt以字典形式组织对话. 每个item包含role和content两个关键字.
role:user: 用户, 用以输入文本;role:assistant: 系统, 用以输出文本;role:system: 对系统生成对话的要求;
LLaMA: Open and Efficient Foundation Language Models
发展:
scale models -> scale data -> fast inference and scale tokens
本文的要点:
通过在更多的token上训练, 使得在不同推理开销下, 达到最佳的性能.
方法
LLaMA采用Auto Regression的方式进行预训练.
预训练数据
公开数据.

tokenizer的方法为: bytepair encoding(BPE). 总共包含1.4T个tokens.
结构
采用了之前一些被证明可行的方法:
- RMSNorm from GPT3;
- SwiGLU from PaLM;
- RoPE from GPTNeo.
优化器
- AdamW ( β 1 = 0.9 , β 2 = 0.95 , w e i g h t d e c a y = 0.1 \beta_1=0.9, \beta_2=0.95, weight~decay=0.1 β1=0.9,β2=0.95,weight decay=0.1);
- warmup 2000 step and cosine learning rate schedule;
- gradient clippping = 1.0;
一些加速的方法
- causal multi-head attention;
- reduce the amount of activations that recomputed during the backward pass.
2048块80G的A100训练21天.
结果
Common Sense Reasoning
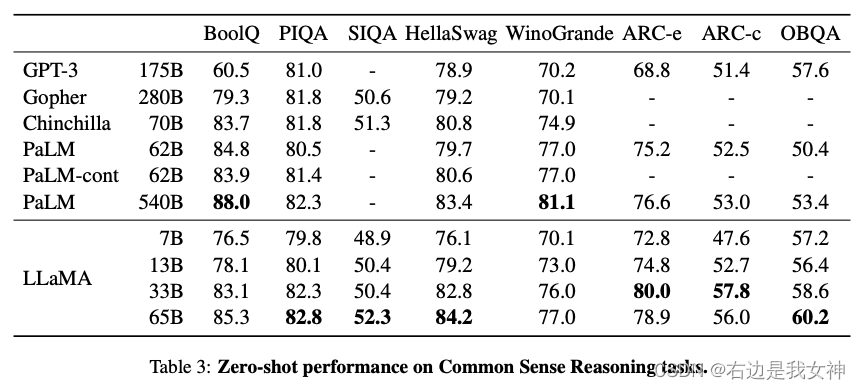
zero-shot.
CSR : 基于问题和常识性选择, 让模型做出判断.

Closed-book Question Answering


不依赖于外部信息源, 只凭借训练时学习得到的信息完成问答任务.
自由文本的评估指标. exact match perfromance
Reading Comprehension


Massive Multitask Language Understanding
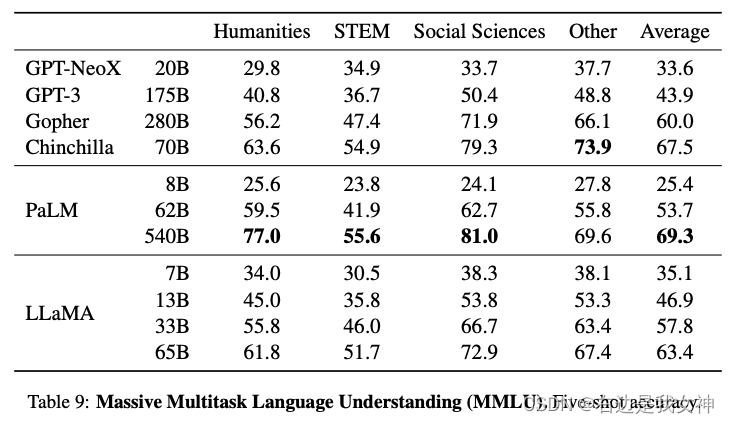

Mathematical reasoning 和 Code Generation就不再赘述.
Instruction Finetuning
待补充
附录
Question Answering

对于Natural Questions 和 TriviaQA 使用1-shot设定. 预先打印字符串:Answer these questions:\n在问题和答案之前.
Generations from LLaMA-65B
Without instruction finetuning.
Prompts are in bold.
Only present part of them.


Generations from LLaMA-I

Llama 2: Open Foundation and Fine-Tuned Chat Models
LLAMA2 : 新的训练数据组织形式, 更大的预训练语料库, 更长的上下文, grouped-query attention.
LLAMA2 : 针对对话场景的微调版本.
pretraining methodology
Pretraining Data
- a new mix of data , not including data from Meta’s products or services;
- 移除包含私人信息的数据;
- 2 trillion tokens and up-sampling the most factual sources.
Training Details
除了RMSNorm, RoPE and SwiGLU, 增加了GQA.
其余与LLaMA 1一致.
fine-tuning methodology
Supervised Fine-Tuning(SFT)
使用公开的instruction tuning data.
提取高质量的部分数据, 模型的效果仍然得到提升. Quality is All You Need.
发现人类写的注释和模型生成+人工检查的注释效果差不多.
微调细节:
- cosine learning rate schedule;
- initial lr = 2e-5;
- weight decay = 0.1;
- batch size = 64;
- sequence length = 4096.
Reinforcement Learning with Human Feedback (RLHF)
人类从模型的两个输出中选择喜欢的一个. 该反馈随后用于训练一个奖励模型. 该模型学习人类的偏好模式.
相关文章:
LLaMa
文章目录 Problems403 代码文件LLaMA: Open and Efficient Foundation Language Models方法预训练数据结构优化器一些加速的方法 结果Common Sense ReasoningClosed-book Question AnsweringReading ComprehensionMassive Multitask Language Understanding Instruction Finetu…...

API(九)基于协程的并发编程SDK
一 基于协程的并发编程SDK 场景: 收到一个请求会并发发起多个请求,使用openresty提供的协程说明: 这个是高级课程,如果不理解可以先跳过遗留: APSIX和Kong深入理解openresty 标准lua的协程 ① 早期提供的轻量级协程SDK ngx.thread ngx…...
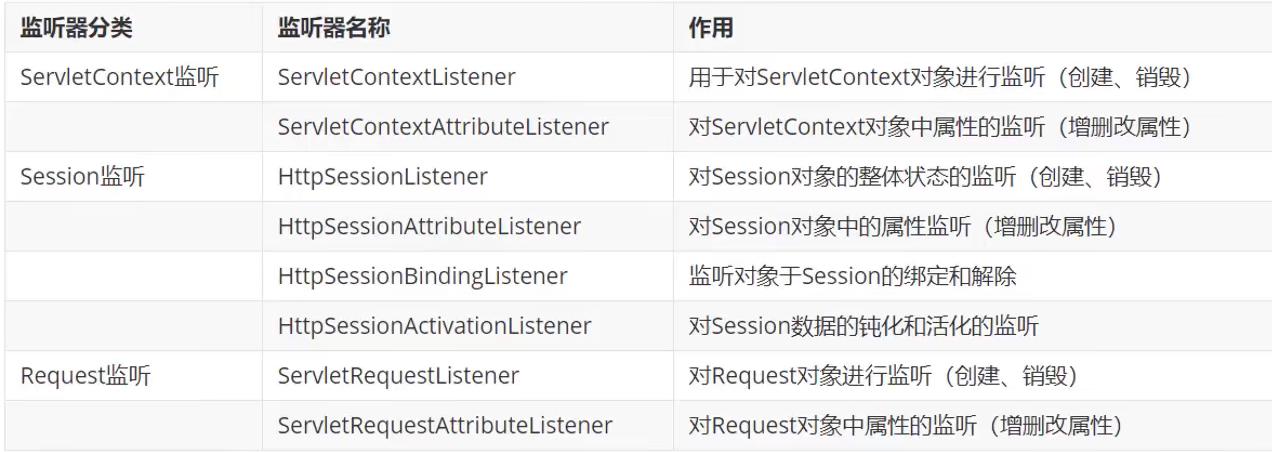
JavaWeb 学习笔记 7:Filter
JavaWeb 学习笔记 7:Filter 1.快速开始 使用过滤器的方式与 Servlet 类似,要实现一个Filter接口: WebFilter("/*") public class FirstFilter implements Filter {public void init(FilterConfig filterConfig) throws ServletE…...

【AI视野·今日Robot 机器人论文速览 第三十五期】Mon, 18 Sep 2023
AI视野今日CS.Robotics 机器人学论文速览 Mon, 18 Sep 2023 Totally 44 papers 👉上期速览✈更多精彩请移步主页 Interesting: 📚GelSplitter, 基于近红外与可见光融合实现高精度surfaceNormal重建的触觉传感器。(from 华中科技大学) 基于分光镜的紧凑型…...

Elasticsearch 在bool查询中使用分词器
1. 创建索引 test setting和mappings 设置了自定义分词映射规则。 PUT /test {"settings": {"analysis": {"filter": {"my_synonym": {"type": "synonym","updateable": true,"synonyms_path&qu…...
在Python中创建相关系数矩阵的6种方法
相关系数矩阵(Correlation matrix)是数据分析的基本工具。它们让我们了解不同的变量是如何相互关联的。在Python中,有很多个方法可以计算相关系数矩阵,今天我们来对这些方法进行一个总结 Pandas Pandas的DataFrame对象可以使用c…...

物联网、工业大数据平台 TDengine 与苍穹地理信息平台完成兼容互认证
当前,在政府、军事、城市规划、自然资源管理等领域,企业对地理信息的需求迅速增加,人们需要更有效地管理和分析地理数据,以进行决策和规划。在此背景下,“GIS 基础平台”应运而生,它通常指的是一个地理信息…...

this.$nextTick()的使用场景
事件循环机制: 同步代码执行->查找异步队列,推入执行栈,执行Vue.nextTick[事件循环1]->查找异步队列,推入执行栈,执行Vue.nextTick[事件循环2]->查找异步队列,推入执行栈,执行Vue.nex…...

idea(第一次)启动项目,端口变成了8080
先上配置 server:port: 9569 spring:profiles:active: dev 该排查的问题也都没问题,重启idea也试过了,还是8080 解决办法:点击右侧的maven ,左上角的重新导入 reimport all maven projects 我又没有改动pom文件,居然还要点这…...
M1 MacOS构建方法)
brpc 学习(一)M1 MacOS构建方法
tags: brpc categories: brpc 写在前面 实习阶段初次接触到 RPC 这样一种协议, 以及 brpc 这样一个很棒的框架, 但是当时没时间认真深入学习, 就是围绕使用 demo 开发, 还是有点不知其所以然的, 最近抽空来学习一下 brpc, 首要的一点就是在开发机上构建项目, 并且能够跑起来,…...

Python 与 Qt c++ 程序共享内存,传递图片
python 代码 这里Python 使用 shared_memory QT 使用 QSharedMemory 简单协议: 前面4个字节是 图片with,height,0,0 后面是图片数据 import sys import struct def is_little_endian():x0x12345678y struct.pack(I,x)return y[0]0x78print(f"is_little_end…...

【2023年中国研究生数学建模竞赛华为杯】E题 出血性脑卒中临床智能诊疗建模 问题分析、数学模型及代码实现
【2023年中国研究生数学建模竞赛华为杯】E题 出血性脑卒中临床智能诊疗建模 1 题目 1.1 背景介绍 出血性脑卒中指非外伤性脑实质内血管破裂引起的脑出血,占全部脑卒中发病率的10-15%。其病因复杂,通常因脑动脉瘤破裂、脑动脉异常等因素,导致…...
)
2024字节跳动校招面试真题汇总及其解答(五)
17.TCP的拥塞控制 TCP 的拥塞控制是指在 TCP 连接中,发送端和接收端通过协作来控制网络中数据包的流量,避免网络拥塞。TCP 的拥塞控制是 TCP 协议的重要组成部分,它可以确保 TCP 连接的稳定性和可靠性。 TCP 的拥塞控制主要有以下几个目的: 防止网络拥塞:当网络中的数据…...

如何撤销某个已经git add的文件以及如何撤销所有git add提交的文件?
如果你想撤销已经添加(git add)到暂存区的单个文件,可以使用 git reset 命令。以下是具体的命令格式: git reset <file>在这里,<file> 是你想要从暂存区中移除的文件名。比如,如果你想要撤销已…...
JVM高级性能调试
标准的JVM是配置为了高吞吐量,吞吐量是为了科学计算和后台运行使用,而互联网商业应用,更多是为追求更短的响应时间,更低的延迟Latency(说白了就是更快速度),当用户打开网页没有快速响应…...

APK的反编译,签名,对齐
APK的反编译,签名,对齐 – WhiteNights Site 2023年9月22日 标签:Android, 应用开发 记录下相关的命令行参数。 APK的打包与解包 java -jar apktool.jar 首先,需要一个jar包,以我在用的为例:apktool_2.8.…...
:信号机制)
Django(20):信号机制
目录 信号的工作机制信号的应用场景两个简单例子Django常用内置信号如何放置信号监听函数代码自定义信号第一步:自定义信号第二步:触发信号第三步:将监听函数与信号相关联 信号的工作机制 Django 框架包含了一个信号机制,它允许若…...

31.链表练习题(2)(王道2023数据结构2.3.7节16-25题)
【前面使用的所有链表的定义在第29节】 试题16:两个整数序列A,B存在两个单链表中,设计算法判断B是否是A的连续子序列。 bool Pattern(LinkList L1,LinkList L2){ //此函数实现比较L1的子串中是否有L2LNode *p, *q; //工作在L1,p记录L1子串…...

排序算法之归并排序
一、归并排序的形象理解 原题链接 示例代码 void merge_sort(int q[], int l, int r) {if (l > r) return;int mid l r >> 1;merge_sort(q, l, mid), merge_sort(q, mid 1, r);int k 0, i l, j mid 1;while (i < mid && j < r) //第一处if (q[i]…...

macOS 下 Termius 中文显示为乱码
👨🏻💻 热爱摄影的程序员 👨🏻🎨 喜欢编码的设计师 🧕🏻 擅长设计的剪辑师 🧑🏻🏫 一位高冷无情的编码爱好者 大家好,我是 DevO…...

【NotebookLM艺术学研究加速器】:20年数字人文专家亲授5大冷启动技巧,3天构建专属艺术文献知识图谱
更多请点击: https://intelliparadigm.com 第一章:NotebookLM艺术学研究辅助的范式革命 NotebookLM 作为 Google 推出的基于用户上传文档进行深度语义理解的 AI 助手,正悄然重构艺术学研究的知识生产逻辑。它不再依赖通用网络语料࿰…...
)
Arcmap专题制图保姆级教程:从横向页面布局到网格样式自定义(附南海小图制作)
Arcmap专题制图全流程实战:从页面布局到南海小图制作 当你面对一堆地理数据却不知如何转化为专业地图时,Arcmap的专题制图功能就是你的救星。不同于简单的数据可视化,专题制图需要兼顾科学性与美学表达,既要准确传达空间信息&…...

3分钟掌握Illustrator批量替换神器:ReplaceItems.jsx终极效率指南
3分钟掌握Illustrator批量替换神器:ReplaceItems.jsx终极效率指南 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 还在为Illustrator中重复的替换操作烦恼吗?…...

多尺度地理加权回归MGWR:如何用Python解决空间异质性分析难题
多尺度地理加权回归MGWR:如何用Python解决空间异质性分析难题 【免费下载链接】mgwr Multiscale Geographically Weighted Regression (MGWR) 项目地址: https://gitcode.com/gh_mirrors/mg/mgwr 多尺度地理加权回归(Multiscale Geographically W…...

如何高效配置编程字体:Maple Mono的进阶优化方案
如何高效配置编程字体:Maple Mono的进阶优化方案 【免费下载链接】maple-font Maple Mono: Open source monospace font with round corner, ligatures and Nerd-Font icons for IDE and terminal, fine-grained customization options. 带连字和控制台图标的圆角等…...

掌握Flash逆向工程:JPEXS免费反编译工具完全指南
掌握Flash逆向工程:JPEXS免费反编译工具完全指南 【免费下载链接】jpexs-decompiler JPEXS Free Flash Decompiler 项目地址: https://gitcode.com/gh_mirrors/jp/jpexs-decompiler 在Flash技术逐渐淡出历史舞台的今天,无数经典的Flash动画、游戏…...

3步掌握小红书内容高效采集:XHS-Downloader完全指南
3步掌握小红书内容高效采集:XHS-Downloader完全指南 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&#…...

如何用WeChatExporter一键备份微信聊天记录:完整图文教程
如何用WeChatExporter一键备份微信聊天记录:完整图文教程 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否担心换手机后珍贵的微信聊天记录会消失&#…...

2026年AI自动剪辑视频软件怎么选择?5款自动剪辑软件对比
对很多短视频创作者来说,真正耗时的不是拍摄,而是后期剪辑。素材整理、卡点、粗剪、字幕和批量导出,往往会占用大量时间。因此,“AI能不能自动剪辑视频”成为越来越多人在2026年搜索的问题。尤其对于新手、电商运营或内容团队而言…...

工程化AI编程:claude-code-blueprint项目实战与最佳实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“claude-code-blueprint”,作者是lethilu4796。乍一看这个标题,你可能会觉得这又是一个普通的代码生成工具或者AI辅助编程的脚本。但当我深入研究了它的源码和使用方式后&…...