哈希表题目:设计哈希映射
文章目录
- 题目
- 标题和出处
- 难度
- 题目描述
- 要求
- 示例
- 数据范围
- 前言
- 解法一
- 思路和算法
- 代码
- 复杂度分析
- 解法二
- 思路和算法
- 代码
- 复杂度分析
题目
标题和出处
标题:设计哈希映射
出处:706. 设计哈希映射
难度
3 级
题目描述
要求
不使用任何内建的哈希表库设计一个哈希映射。
实现 MyHashMap\texttt{MyHashMap}MyHashMap 类:
- MyHashMap()\texttt{MyHashMap()}MyHashMap() 用空映射初始化对象。
- voidput(intkey,intvalue)\texttt{void put(int key, int value)}void put(int key, int value) 向哈希映射插入一个键值对 (key,value)\texttt{(key, value)}(key, value)。如果 key\texttt{key}key 已经存在于映射中,则更新其对应的值 value\texttt{value}value。
- intget(intkey)\texttt{int get(int key)}int get(int key) 返回特定的 key\texttt{key}key 所映射的 value\texttt{value}value;如果映射中不包含 key\texttt{key}key 的映射,返回 -1\texttt{-1}-1。
- voidremove(key)\texttt{void remove(key)}void remove(key) 如果映射中存在 key\texttt{key}key 的映射,则移除 key\texttt{key}key 和它所对应的 value\texttt{value}value。
示例
示例 1:
输入:
["MyHashMap","put","put","get","get","put","get","remove","get"]\texttt{["MyHashMap", "put", "put", "get", "get", "put", "get", "remove", "get"]}["MyHashMap", "put", "put", "get", "get", "put", "get", "remove", "get"]
[[],[1,1],[2,2],[1],[3],[2,1],[2],[2],[2]]\texttt{[[], [1, 1], [2, 2], [1], [3], [2, 1], [2], [2], [2]]}[[], [1, 1], [2, 2], [1], [3], [2, 1], [2], [2], [2]]
输出:
[null,null,null,1,-1,null,1,null,-1]\texttt{[null, null, null, 1, -1, null, 1, null, -1]}[null, null, null, 1, -1, null, 1, null, -1]
解释:
MyHashMapmyHashMap=newMyHashMap();\texttt{MyHashMap myHashMap = new MyHashMap();}MyHashMap myHashMap = new MyHashMap();
myHashMap.put(1,1);\texttt{myHashMap.put(1, 1);}myHashMap.put(1, 1); // myHashMap\texttt{myHashMap}myHashMap 现在为 [[1,1]]\texttt{[[1,1]]}[[1,1]]
myHashMap.put(2,2);\texttt{myHashMap.put(2, 2);}myHashMap.put(2, 2); // myHashMap\texttt{myHashMap}myHashMap 现在为 [[1,1],[2,2]]\texttt{[[1,1], [2,2]]}[[1,1], [2,2]]
myHashMap.get(1);\texttt{myHashMap.get(1);}myHashMap.get(1); // 返回 1\texttt{1}1,myHashMap\texttt{myHashMap}myHashMap 现在为 [[1,1],[2,2]]\texttt{[[1,1], [2,2]]}[[1,1], [2,2]]
myHashMap.get(3);\texttt{myHashMap.get(3);}myHashMap.get(3); // 返回 -1\texttt{-1}-1(未找到),myHashMap\texttt{myHashMap}myHashMap 现在为 [[1,1],[2,2]]\texttt{[[1,1], [2,2]]}[[1,1], [2,2]]
myHashMap.put(2,1);\texttt{myHashMap.put(2, 1);}myHashMap.put(2, 1); // myHashMap\texttt{myHashMap}myHashMap 现在为 [[1,1],[2,1]]\texttt{[[1,1], [2,1]]}[[1,1], [2,1]](更新已有的值)
myHashMap.get(2);\texttt{myHashMap.get(2);}myHashMap.get(2); // 返回 1\texttt{1}1,myHashMap\texttt{myHashMap}myHashMap 现在为 [[1,1],[2,1]]\texttt{[[1,1], [2,1]]}[[1,1], [2,1]]
myHashMap.remove(2);\texttt{myHashMap.remove(2);}myHashMap.remove(2); // 删除键为 2\texttt{2}2 的数据,myHashMap\texttt{myHashMap}myHashMap 现在为 [[1,1]]\texttt{[[1,1]]}[[1,1]]
myHashMap.get(2);\texttt{myHashMap.get(2);}myHashMap.get(2); // 返回 -1\texttt{-1}-1(未找到),myHashMap\texttt{myHashMap}myHashMap 现在为 [[1,1]]\texttt{[[1,1]]}[[1,1]]
数据范围
- 0≤key≤106\texttt{0} \le \texttt{key} \le \texttt{10}^\texttt{6}0≤key≤106
- 最多调用 104\texttt{10}^\texttt{4}104 次 put\texttt{put}put、get\texttt{get}get 和 remove\texttt{remove}remove
前言
这道题和「设计哈希集合」非常相似,区别在于这道题存储的不是 key\textit{key}key 本身,而是 (key,value)(\textit{key}, \textit{value})(key,value) 的键值对。这道题也可以使用「设计哈希集合」的解法。
解法一
思路和算法
由于 key\textit{key}key 和 value\textit{value}value 的取值范围是 [0,106][0, 10^6][0,106],因此可以创建长度为 106+110^6 + 1106+1 的整型数组表示哈希表,数组中的下标为 key\textit{key}key 的元素值表示 key\textit{key}key 映射的 value\textit{value}value,value≥0\textit{value} \ge 0value≥0 表示存在 key\textit{key}key 的映射,value<0\textit{value} < 0value<0 表示不存在 key\textit{key}key 的映射,当 value<0\textit{value} < 0value<0 时一定有 value=−1\textit{value} = -1value=−1。
构造方法中,将数组初始化为长度 106+110^6 + 1106+1 的数组,并将数组中的全部元素初始化为 −1-1−1。
对于 put\textit{put}put 操作,将数组中的下标为 key\textit{key}key 的元素设为 value\textit{value}value。
对于 get\textit{get}get 操作,返回数组中的下标为 key\textit{key}key 的元素。
对于 remove\textit{remove}remove 操作,将数组中的下标为 key\textit{key}key 的元素设为 −1-1−1。
需要说明的是,该解法虽然实现简单,但是不适合在面试中使用。
代码
class MyHashMap {int[] map;public MyHashMap() {map = new int[1000001];Arrays.fill(map, -1);}public void put(int key, int value) {map[key] = value;}public int get(int key) {return map[key];}public void remove(int key) {map[key] = -1;}
}
复杂度分析
-
时间复杂度:构造方法的时间复杂度是 O(C)O(C)O(C),各项操作的时间复杂度都是 O(1)O(1)O(1),其中 CCC 是 key\textit{key}key 的取值范围的元素个数,这道题中 C=106+1C = 10^6 + 1C=106+1。
构造方法需要创建长度为 CCC 的数组并将每个元素设为初始值,时间复杂度是 O(C)O(C)O(C)。
各项操作只需要对数组中的一个元素赋值或返回元素值,时间复杂度是 O(1)O(1)O(1)。 -
空间复杂度:O(C)O(C)O(C),其中 CCC 是 key\textit{key}key 的取值范围的元素个数,这道题中 C=106+1C = 10^6 + 1C=106+1。需要创建长度为 CCC 的数组表示哈希集合。
解法二
思路和算法
哈希表的常见实现方法是链表数组,数组的每个下标对应哈希函数可以映射到的索引,当出现哈希冲突时,使用链地址法解决哈希冲突。
用 BASE\textit{BASE}BASE 表示链表数组的长度,则可以使用一个简单的哈希函数:hash(x)=xmodBASE\text{hash}(x) = x \bmod \textit{BASE}hash(x)=xmodBASE,每个键经过哈希函数映射之后的值一定在范围 [0,BASE−1][0, \textit{BASE} - 1][0,BASE−1] 内。为了将哈希函数的值尽可能均匀分布,降低哈希冲突的频率,链表数组的长度应选择质数。此处取链表数组的长度为 101310131013。
由于哈希表存储的元素包含键和值,因此链表中存储的元素为键值对。
构造方法中,将链表数组初始化为长度 BASE\textit{BASE}BASE 的链表数组,并将链表数组中的全部元素初始化为空链表。
对于各项操作,首先计算 key\textit{key}key 对应的哈希值,得到链表数组的下标,根据下标在链表数组中得到相应的链表,然后在链表中执行相应操作。
对于 put\textit{put}put 操作,在链表数组中得到相应的链表之后,遍历链表,如果遇到元素的键等于 key\textit{key}key 则将元素的值设为 value\textit{value}value 并直接返回,如果遍历结束没有遇到元素的键等于 key\textit{key}key 则在链表末尾添加元素 (key,value)(\textit{key}, \textit{value})(key,value)。
对于 get\textit{get}get 操作,在链表数组中得到相应的链表之后,遍历链表,如果遇到元素的键等于 key\textit{key}key 则返回元素的值,如果遍历结束没有遇到元素的键等于 key\textit{key}key 则返回 −1-1−1。
对于 remove\textit{remove}remove 操作,在链表数组中得到相应的链表之后,遍历链表,如果遇到元素的键等于 key\textit{key}key 则将其删除,如果遍历结束没有遇到元素的键等于 key\textit{key}key 则不执行任何操作。
实现方面,为了提升运行效率,使用迭代器遍历链表和执行删除操作。
代码
class MyHashMap {private class Entry {private int key;private int value;public Entry(int key, int value) {this.key = key;this.value = value;}public int getKey() {return key;}public int getValue() {return value;}public void setValue(int value) {this.value = value;}}private static final int BASE = 1013;private LinkedList<Entry>[] map;public MyHashMap() {map = new LinkedList[BASE];for (int i = 0; i < BASE; i++) {map[i] = new LinkedList<Entry>();}}public void put(int key, int value) {int index = key % BASE;LinkedList<Entry> list = map[index];Iterator<Entry> iterator = list.iterator();while (iterator.hasNext()) {Entry entry = iterator.next();if (entry.getKey() == key) {entry.setValue(value);return;}}list.offerLast(new Entry(key, value));}public int get(int key) {int index = key % BASE;LinkedList<Entry> list = map[index];Iterator<Entry> iterator = list.iterator();while (iterator.hasNext()) {Entry entry = iterator.next();if (entry.getKey() == key) {return entry.getValue();}}return -1;}public void remove(int key) {int index = key % BASE;LinkedList<Entry> list = map[index];Iterator<Entry> iterator = list.iterator();while (iterator.hasNext()) {Entry entry = iterator.next();if (entry.getKey() == key) {iterator.remove();break;}}}
}
复杂度分析
-
时间复杂度:构造方法的时间复杂度是 O(BASE)O(\textit{BASE})O(BASE),各项操作的时间复杂度都是 O(nBASE)O\Big(\dfrac{n}{\textit{BASE}}\Big)O(BASEn),其中 nnn 是哈希集合中的元素个数,BASE\textit{BASE}BASE 是链表数组的长度。
构造方法需要创建长度为 BASE\textit{BASE}BASE 的数组并将每个元素设为初始值,时间复杂度是 O(BASE)O(\textit{BASE})O(BASE)。
各项操作需要根据哈希函数计算哈希值,然后遍历链表。计算哈希值需要 O(1)O(1)O(1) 的时间,假设哈希值分布均匀,每个链表的平均长度是 O(nBASE)O\Big(\dfrac{n}{\textit{BASE}}\Big)O(BASEn),因此需要 O(nBASE)O\Big(\dfrac{n}{\textit{BASE}}\Big)O(BASEn) 的时间遍历哈希表。 -
空间复杂度:O(n+BASE)O(n + \textit{BASE})O(n+BASE),其中 nnn 是哈希集合中的元素个数,BASE\textit{BASE}BASE 是链表数组的长度。存储 nnn 个元素需要 O(n)O(n)O(n) 的空间,链表数组需要 O(BASE)O(\textit{BASE})O(BASE) 的空间。
相关文章:

哈希表题目:设计哈希映射
文章目录题目标题和出处难度题目描述要求示例数据范围前言解法一思路和算法代码复杂度分析解法二思路和算法代码复杂度分析题目 标题和出处 标题:设计哈希映射 出处:706. 设计哈希映射 难度 3 级 题目描述 要求 不使用任何内建的哈希表库设计一个…...

力扣解法汇总1238. 循环码排列
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接: 力扣 描述: 给你两个整数 n 和 start。你的任务是返回任意 (0,1,2,,...,2^n-1) 的排列 p&…...
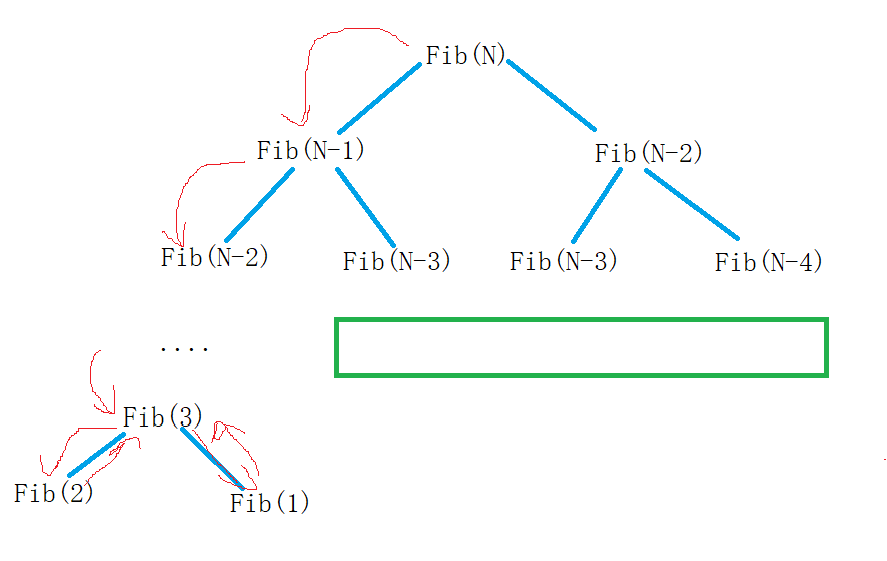
[数据结构]时间复杂度与空间复杂度
[数据结构]时间复杂度与空间复杂度 如何衡量一个算法的好坏 long long Fib(int N) {if(N < 3)return 1;return Fib(N-1) Fib(N-2); } 这是一个求斐波那契数列的函数,使用递归的方法求得,虽然代码看起来很简洁,但是简洁真的就好吗&#…...

Codeforces Round #848 (Div. 2)(A~D)
A. Flip Flop Sum给出一个只有1和-1的数组,修改一对相邻的数,将它们变为对应的相反数,修改完后数组的和最大是多少。思路:最优的情况是修改一对-1,其次是一个1一个-1,否则修改两个1。AC Code:#i…...
)
第十三届蓝桥杯Java B 组国赛 C 题——左移右移(AC)
目录1.左移右移1.题目描述2.输入格式3.输出格式4.样例输入5.样例输出6.数据范围6.原题链接2.解题思路3.Ac_code1.左移右移 1.题目描述 小蓝有一个长度为 NNN 的数组, 初始时从左到右依次是 1,2,3,…N1,2,3, \ldots N1,2,3,…N 。 之后小蓝对这个数组进行了 MMM 次操作, 每次…...

第14篇:系列二—Java抽象类/接口/枚举
目录 1、继承的定义(Inheritance) 2、继承的优点 2.1 易维护性 2.2 复用性 2.3 条理性...
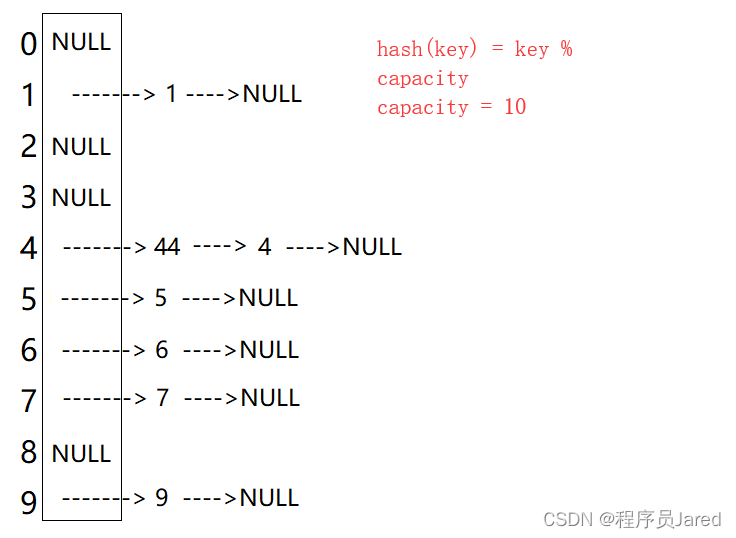
深入浅出C++ ——哈希
文章目录前言一、unordered系列关联式容器1. unordered_map2. unordered_set二、哈希1. 哈希概念2. 哈希冲突3. 哈希函数4. 哈希冲突解决方法三、模拟实现unordered系列容器1. 哈希表的改造2. 模拟实现 unordered_set3. 模拟实现 unordered_map前言 在C11中,STL又提…...

Tina_Linux_系统裁剪_开发指南
文章目录Tina_Linux_系统裁剪_开发指南1 概述2 Tina系统裁剪简介2.1 boot0裁剪2.2 uboot裁剪2.3 内核裁剪2.3.1 删除不使用的功能2.3.2 删除不使用的驱动2.3.3 修改内核源代码2.3.3.1 size工具.2.3.3.2 ksize.py脚本2.3.3.3 nm命令2.3.3.4 kernel压缩方式.2.4 文件系统裁剪.2.4…...

算法刷题打卡第99天:至少在两个数组中出现的值
至少在两个数组中出现的值 难度:简单 给你三个整数数组 nums1、nums2 和 nums3 ,请你构造并返回一个 元素各不相同的 数组,且由 至少 在 两个 数组中出现的所有值组成。数组中的元素可以按 任意 顺序排列。 示例 1: 输入&…...

线程池面试题
1. 什么是线程池?为什么要使用线程池? 线程池是一种用于管理线程的技术,它可以在应用程序中重复使用一组线程来执行多个任务。线程池的优点包括提高应用程序的性能和可伸缩性、避免线程创建和销毁的开销、避免线程过多导致系统负担过重等。线…...

【学习笔记】NOIP爆零赛5
说实话是不想补题的。因为每一道题都贼难写,题解又通篇写着显然,然后自己天天搞竞赛又把注意力搞差了,调一道题又调半天,考试的题又难的要死 不会正解 ,部分分又写挂了 可能心态崩了就是从那场t1t1t1签到题考高精度数位…...

【数据结构】时间复杂度
🚀write in front🚀 📜所属专栏:初阶数据结构 🛰️博客主页:睿睿的博客主页 🛰️代码仓库:🎉VS2022_C语言仓库 🎡您的点赞、关注、收藏、评论,是对…...

vector的基本使用
目录 介绍: vector iterator 的使用 增删查改 增(push_back insert): 删(pop_back erase): swap: vector的容量和扩容: 排序(sort): 介绍ÿ…...

剑指 Offer 55 - I. 二叉树的深度
摘要 剑指 Offer 55 - I. 二叉树的深度 一、深度优先搜索 如果我们知道了左子树和右子树的最大深度l和r,那么该二叉树的最大深度即为:max(l,r)1。 而左子树和右子树的最大深度又可以以同样的方式进行计算。因此我们可以用「深度优先搜索」的方法来计…...
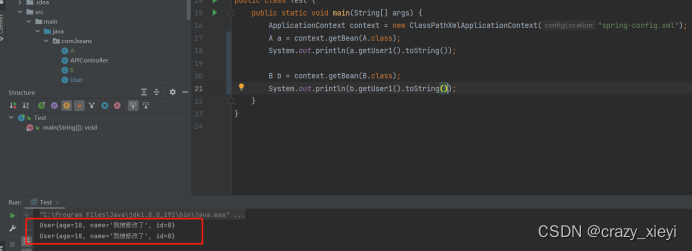
Bean的生命周期和作用域
Bean的生命周期Bean的执行流程:Bean 执行流程:启动Spring 容器 -> 实例化 Bean(分配内存空间,从无到有)-> Bean 注册到 Spring 中(存操作) -> 将 Bean 装配到需要的类中(取…...
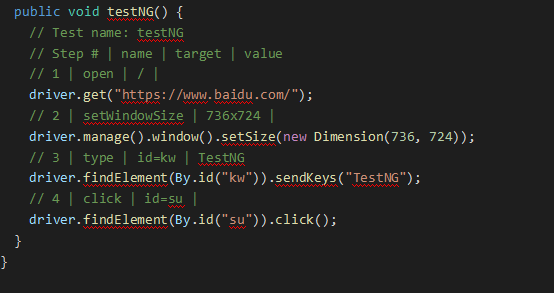
TestNG和Junit的区别,测试框架该如何选择?
要想知道两个框架的区别,首先分别介绍一下两个框架。 TestNG是一个java中的开源自动化测试框架,其灵感来自JUnit和NUnit,TestNG还涵盖了JUnit4整个核心的功能,但引入了一些新的功能,使其功能更强大,使用更…...

MySQL安全登录策略
MySQL密码复杂度策略设置 MySQL 系统自带有 validate_password 插件,此插件可以验证密码强度,未达到规定强度的密码则不允许被设置。MySQL 5.7 及 8.0 版本默认情况下貌似都不启用该插件,这也使得我们可以随意设置密码,比如设置为…...

优化模型验证23:带无人机停靠站的卡车无人机协同配送车辆路径问题、模型、gurobipy验证及结果可视化
带中转hub的卡车无人机车辆路径问题 模型来源为:Wang Z , Sheu J B . Vehicle routing problem with drones[J]. Transportation Research Part B: Methodological, 2019, 122(APR.):350-364. 问题描述: 这篇问题研究了一个带停靠站的卡车无人机路径问题,无人机仅能从起点…...

mongoTemplate Aggregation 多表联查 排序失效问题解决
目录说明说明 接着上一个文章的例子来说:mongoTemplate支持多表联查 排序 条件筛选 分页 去重分组 在按照上一个demo的代码执行后,可能会发生排序失效的问题,为什么说可能呢?每个人负责业务不同,不可能是最简单的dem…...

什么是智慧实验室?
智慧实验室是利用现代信息技术和先进设备将实验室实现智能化和智慧化的概念。通过将各种数据、信息和资源整合在一起,实现实验室设备的互联互通,数据的实时采集、传输、处理和分析,从而提高实验室的效率、精度和可靠性。一、智慧实验室包含多…...

组态王通用扫码枪配置
使用组态王扫码枪驱动,是绑定变量,扫码后直接就可以显示扫码内容。解决每次扫码输入数据时必须先用鼠标点进输入框内的问题。驱动安装先添加驱动,亚控网站的文件为 barcodescanner,这个文件是组态王通用扫码枪的驱动,但…...

千亿镁合金产业集群正在成形:成都、抚州、池州的新版图
一个新赛道的地理坐标 如果要在中国地图上标注一条正在成形的新兴产业集群走廊,高强镁合金这条线,值得被认真画出来。 成都龙泉驿——江西抚州临川——安徽池州高新区,三个坐标,三条生产线,一家公司,两年内…...
)
Postgresql基础实践教程(八)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 六十九、查找会员ID 27的向上推荐链 问题 查找会员ID 27的向上推荐链:即推荐该会员的人,以及推荐那个人的人,依此类推。返回会员ID、名字和姓氏。按会员ID降序排列。…...

从安装到排错:手把手解决Linux服务器上Nacos启动失败的十大常见问题
从安装到排错:手把手解决Linux服务器上Nacos启动失败的十大常见问题当你在Linux服务器上部署Nacos时,是否遇到过启动失败却无从下手的困境?作为阿里巴巴开源的服务发现和配置管理平台,Nacos在微服务架构中扮演着重要角色。然而&am…...

XZ1018,100V,40A,NMOS 封装:TO252
封装:TO252类型:NVDS:100V VGS: 20V ID:40ARDS(ON):10V <14mΩRDS(ON):4.5V <19mΩ型号: XZ1018 封装:TO252类型…...

实战解锁:在Blender中掌握专业级MMD动画制作全流程
实战解锁:在Blender中掌握专业级MMD动画制作全流程 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools MMD …...

使用curl命令调试Taotoken API接口的常见问题排查
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令调试Taotoken API接口的常见问题排查 基础教程类,面向所有需要通过HTTP直接与API交互的开发者,…...

AI Agent 为什么必须有“记忆系统”?
导语:大模型不是没有智商,而是经常没有“记性”。真正能长期干活的 Agent,不是靠无限拉长上下文,而是靠一套会压缩、会检索、会遗忘、会治理的外置记忆系统。一、先给结论:Agent 的记忆系统,本质是“上下文…...

DeTikZify:基于AI的TikZ图形程序自动生成技术深度解析
DeTikZify:基于AI的TikZ图形程序自动生成技术深度解析 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify DeTikZify是一款革命性的多模态…...

茉莉花插件:如何让中文文献管理效率提升300%
茉莉花插件:如何让中文文献管理效率提升300% 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为中文文献的元数据抓…...