Centos7原生hadoop环境,搭建Impala集群和负载均衡配置
Centos7原生hadoop环境,搭建Impala集群和负载均衡配置
impala介绍
Impala集群包含一个Catalog Server (Catalogd)、一个Statestore Server (Statestored) 和若干个Impala Daemon (Impalad)。Catalogd主要负责元数据的获取和DDL的执行,Statestored主要负责消息/元数据的广播,Impalad主要负责查询的接收和执行。
Impalad又可配置为coordinator only、 executor only 或coordinator and executor(默认)三种模式。Coordinator角色的Impalad负责查询的接收、计划生成、查询的调度等,Executor角色的Impalad负责数据的读取和计算。默认配置下每个Impalad既是Coordinator又是Executor。生产环境建议做好角色分离,即每个Impalad要么是Coordinator要么是Executor。

Impala集群内部的元数据同步的机制 是从catalog批量收集一批表的元数据,通过statestore广播到coordinator。catalog在收集元数据的时候需要为每个表加一个读锁,如果这时候某一个表有跑批的任务,或者因为其他原因加了写锁,那么收集线程加读锁的逻辑就会被阻塞住,这就导致对应的 coordinator上的这些查询得不到执行(处于created状态)。
集群规划
| 节点名称 | impala-catalogd | impala-statestored | impala-server |
|---|---|---|---|
| node01 | √ | √ | √ |
| node02 | × | × | √ |
| node03 | × | × | √ |
配置本地yum源
1. 在node01节点上安装httpd服务器
#yum方式安装httpds服务器
[root@node01 ~]# yum install -y httpd
#启动httpd服务器
[root@node01 ~]# systemctl start httpd
#查看httpd转态是否启动
[root@node01 ~]# systemctl status httpd
2. 配置yum源
- 上传下载好的impala的压缩包cdh5.14.0-centos7.tar.gz到/var/www/html/目录
- 解压 tar -zxvf cdh5.14.0-centos7.tar.gz
- 配置yum源:cd /etc/yum.repo/
- vim local.repo
#需要与文件名保持一致
[local]
name=local_yum
#访问当前源的地址信息
baseurl=http://node01/cdh/5.14.0/
#为0不做gpg校验
gpgcheck=0
#当前源是否可用,为1则可用,为0则禁用
enabled=1

- 导入秘钥认证
-
防止后边安装失败(这里有个小坑),每个节点都执行
-
rpm --import /var/www/html/cdh/RPM-GPG-KEY-cloudera
-
安装impala
- node01节点安装 impala-catalogd、impala-statestored、 impala-server(impala-Deamon)
[root@node01 ~]# yum install -y impala impala-server impala-state-store impala-catalog impala-shell

- node02节点安装impala-server(impala-Deamon)
yum install -y impala-server impala-shell
3.node03节点安装impala-server(impala-Deamon)
yum install -y impala-server impala-shell

修改hive的配置
1.修改hive-site.xml配置
-
cd /opt/yjx/apache-hive-3.1.2-bin/
-
vim hive-site.xml
<!--指定metastore地址,之前添加过可以不用添加 -->
<property><name>hive.metastore.uris</name><value>thrift://node01:9083</value>
</property>
<property><name>hive.metastore.client.socket.timeout</name><value>3600</value>
</property>
2.分发hive安装目录到集群中其它节点
-
scp hdfs-site.xml node02:$PWD scp hdfs-site.xml node03:$PWD
修改hadoop的配置
-
在所有节点创建一下这个目录mkdir -p /var/lib/hadoop-hdfs
-
cd /opt/yjx/hadoop-3.1.2/etc/hadoop/
-
vim hdfs-site.xml
-
<!--添加如下内容 --> <!--打开短路读取开关 --> <!-- 打开短路读取配置--> <property><name>dfs.client.read.shortcircuit</name><value>true</value> </property> <!--这是一个UNIX域套接字的路路径,将⽤用于DataNode和本地HDFS客户机之间的通信 --> <property><name>dfs.domain.socket.path</name><value>/var/lib/hadoop-hdfs/dn_socket</value> </property> <!--block存储元数据信息开发开关 --> <property><name>dfs.datanode.hdfs-blocks-metadata.enabled</name><value>true</value> </property> <property><name>dfs.client.file-block-storage-locations.timeout</name><value>30000</value> </property> -
分发到其他节点
-
scp hdfs-site.xml node02:$PWD scp hdfs-site.xml node03:$PWD
创建impala配置的软连接
impala中跟Hadoop,Hive相关的配置使用Yum方式安装Impala时默认的Impala配置文件目录为/etc/impala/conf目录,Impala的使用要依赖Hadoop,Hive框架,所以需要把HDFS,Hive的配置文件告知Impala,执行下面的命令,把HDFS和Hive的配置文件软链接到/etc/impala/conf下(所有节点执行)
-
所有节点均执行
-
ln -s /opt/yjx/hadoop-3.1.2/etc/hadoop/core-site.xml /etc/impala/conf/core-site.xml ln -s /opt/yjx/hadoop-3.1.2/etc/hadoop/hdfs-site.xml /etc/impala/conf/hdfs-site.xml ln -s /opt/yjx/apache-hive-3.1.2-bin/conf/hive-site.xml /etc/impala/conf/hive-site.xml
impala的自身配置(所有节点)
-
创建日志目录mkdir -p /var/logs/impala/
-
chown impala:impala /var/logs/impala/
修改配置

-
cd /etc/default/ scp impala node02:$PWD scp impala node03:$PWD
-
创建目录用于存放mysql的连接驱动mkdir -p /usr/share/java/
-
创建软连接
ln -s /opt/yjx/apache-hive-3.1.2-bin/lib/mysql-connector-java-5.1.32-bin.jar /usr/share/java/mysql-connector-java.jar
修改bigtop的JAVA_HOME路径
#修改bigtop的JAVA_HOME路径
[root@node01 ~]# vim /etc/default/bigtop-utils
[root@node02 ~]# vim /etc/default/bigtop-utils
[root@node03 ~]# vim /etc/default/bigtop-utils
#添加JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_231-amd64
启动集群
-
启动zookeeper
-
zkServer.sh start -
启动Hadoop
-
start-all.sh -
启动Hive
-
# 启动元数据服务 nohup hive --service metastore > /dev/null 2>&1 & #启动hiveServer2 nohup hiveserver2 > /dev/null 2>&1 & #客户端测试 -
启动impala
-
[root@node01 ~]# service impala-state-store start [root@node01 ~]# service impala-catalog start [root@node01 ~]# service impala-server start -
[root@node02 ~]# service impala-catalog start -
[root@node03 ~]# service impala-server start -
验证Impala是否启动
-
ps -ef | grep impala -
浏览器Web界面验证
-
#访问impalad管理界面
http://node01:25000/

说明: 如果进程数启动不对,web页面打不开,去指定的日志目录。
-
jps时出现空白的进程或者process information unavailable
-
解决办法
-
#解决办法(注意只删除后缀为impala的即可) [root@node01 bin]# rm -rf /tmp/hsperfdata_impala* [root@node02 bin]# rm -rf /tmp/hsperfdata_impala* [root@node03 bin]# rm -rf /tmp/hsperfdata_impala*
-
Impala的负载均衡
Impala主要有三个组件,分别是statestore,catalog和impalad,对于Impalad节点,每一个节点都可以接收客户端的查询请求,并且对于连接到该Impalad的查询还要作为Coordinator节点(需要消耗一定的内存和CPU)存在,为了保证每一个节点的资源开销的平衡需要对于集群中Impalad节点做一下负载均衡。
Cloudera官方推荐的代理方案是HAProxy,这里我们也使用这种方式实现负载均衡。实际生产中建议选择一个非Impala节点作为HAProxy安装节点。
1.选择一台机器安装haProxy,这里选择node01安装
-
yum install -y haproxy
- 修改haproxy.cfg配置文件,在配置文件中增加如下内容
-
vim /etc/haproxy/haproxy.cfg
-
#--------------------------------------------------------------------- # Global settings #--------------------------------------------------------------------- global# to have these messages end up in /var/log/haproxy.log you will# need to:## 1) configure syslog to accept network log events. This is done# by adding the '-r' option to the SYSLOGD_OPTIONS in# /etc/sysconfig/syslog## 2) configure local2 events to go to the /var/log/haproxy.log# file. A line like the following can be added to# /etc/sysconfig/syslog## local2.* /var/log/haproxy.log#log 127.0.0.1 local2chroot /var/lib/haproxypidfile /var/run/haproxy.pidmaxconn 4000user haproxygroup haproxydaemon# turn on stats unix socketstats socket /var/lib/haproxy/stats#--------------------------------------------------------------------- # common defaults that all the 'listen' and 'backend' sections will # use if not designated in their block #--------------------------------------------------------------------- defaultsmode httplog globaloption httplogoption dontlognulloption http-server-closeoption forwardfor except 127.0.0.0/8option redispatchretries 3timeout http-request 10stimeout queue 3mtimeout connect 5000stimeout client 3600stimeout server 3600stimeout http-keep-alive 10s#健康检查时间timeout check 10smaxconn 3000#--------------------------------------------------------------------- # main frontend which proxys to the backends #--------------------------------------------------------------------- frontend main *:5000acl url_static path_beg -i /static /images /javascript /stylesheetsacl url_static path_end -i .jpg .gif .png .css .jsuse_backend static if url_staticdefault_backend app#--------------------------------------------------------------------- # static backend for serving up images, stylesheets and such #--------------------------------------------------------------------- backend staticbalance roundrobinserver static 127.0.0.1:4331 check #--------------------------------------------------------------------- # round robin balancing between the various backends #--------------------------------------------------------------------- backend appbalance roundrobinserver app1 127.0.0.1:5001 checkserver app1 127.0.0.1:5002 check#--------------配置 impala-jdbc ------------------------------------------------------- listen impala :25001balance roundrobinoption tcplogmode tcp#bind 0.0.0.0:21051#listen impalajdbcserver impala_jdbc_01 node02:21050 checkserver impala_jdbc_02 node03:21050 check#--------------配置impala-shell------------------------------------------------------- listen impala :25002balance leastconnoption tcplogmode tcp#listen impalashellserver impala_shell_01 node01:21000 checkserver impala_shell_02 node02:21000 checkserver impala_shell_03 node03:21000 check #--------------配置 impala-hue ------------------------------------------------------- #listen impala :25003#balance source#option tcplog#mode tcp#server impala_hue_01 host01:21050 check#server impala_hue_02 host02:21050 check #-----web ui---------------------------------------------------------------- listen stats :1080balancestats uri /statsstats refresh 30s #管理界面访问IP和端口#bind 0.0.0.0:1080mode http#定义管理界面#listen status
3.检查配置是否正确
/usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg
-
开启HAProxy代理服务
开启: systemctl start haproxy.service 查看状态: systemctl status haproxy.service 关闭: systemctl stop haproxy.service 重启: systemctl restart haproxy.service 开机自启动: chkconfig haproxy on -
访问监控页面
http://node01:1080/stats

- impala安装包链接: 提取码: k877
Haproxy的下载安装包离线安装步骤
下载安装Haproxy
下载地址:
https://src.fedoraproject.org/repo/pkgs/haproxy/
http://download.openpkg.org/components/cache/haproxy/
haproxy-1.8.10.tar.gz :
haproxy安装包下载 提取码: 6evh
(1)将下载下来的Haproxy放到Linux中, 解压文件
tar -zxvf haproxy-1.7.8.tar.gz
(2)yum安装GCC
yum install gcc-c++
(3)编译与安装Haproxy
进入Haproxy文件夹,编译执行命令:make TARGET=linux26
安装特定位置:make install PREFIX=/usr/local/haproxy
(4)进入创建的文件夹cd /usr/local/haproxy,修改配置
创建一个文件夹,mkdir conf config文件夹
进入该文件夹,在文件夹中,创建 一个文件执行命令: touch haproxy.cnf
编辑配置文件haproxy.cfg
Impala的常见错误
1.Impala不能创建表,提示权限的问题
-
[node02:21000] > create table person2(id int,name string,address string) row format delimited fields terminated by ','; Query: create table person2(id int,name string,address string) row format delimited fields terminated by ',' ERROR: ImpalaRuntimeException: Error making 'createTable' RPC to Hive Metastore: CAUSED BY: MetaException: Got exception: org.apache.hadoop.security.AccessControlException Permission denied: user=impala, access=EXECUTE, inode="/hive/warehouse":root:supergroup:drwxr-x---at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:399)at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkTraverse(FSPermissionChecker.java:315)at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:242)at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:193)at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkTraverse(FSPermissionChecker.java:606)at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkTraverse(FSDirectory.java:1801)at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkTraverse(FSDirectory.java:1819)at org.apache.hadoop.hdfs.server.namenode.FSDirectory.resolvePath(FSDirectory.java:676)at org.apache.hadoop.hdfs.server.namenode.FSDirStatAndListingOp.getFileInfo(FSDirStatAndListingOp.java:114)at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getFileInfo(FSNamesystem.java:3102)at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getFileInfo(NameNodeRpcServer.java:1154)at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.getFileInfo(ClientNamenodeProtocolServerSideTranslatorPB.java:966)at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:872)at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:818)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:422)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2678) -
为对应的目录赋权777,我的数仓路径 /hive/warehouse/
-
hdfs dfs -chmod -R 777 /hive/warehouse/

2.hdfs进入安全模式
- hdfs dfsadmin -safemode leave
3.启动datanode时日志发现如下报错信息
- 启动日志
023-09-17 03:04:54,358 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Starting DataNode with maxLockedMemory = 0
2023-09-17 03:04:54,435 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Opened streaming server at /0.0.0.0:9866
2023-09-17 03:04:54,461 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Balancing bandwidth is 10485760 bytes/s
2023-09-17 03:04:54,461 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Number threads for balancing is 50
2023-09-17 03:04:54,476 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Shutdown complete.
2023-09-17 03:04:54,477 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Exception in secureMain
java.io.IOException: The path component: '/var/lib/hadoop-hdfs' in '/var/lib/hadoop-hdfs/dn_socket' has permissions 0755 uid 993 and gid 991. It is not protected because it is owned by a user who is not root and not the effective user: '0'. This might help: 'chown root /var/lib/hadoop-hdfs' or 'chown 0 /var/lib/hadoop-hdfs'. For more information: https://wiki.apache.org/hadoop/SocketPathSecurityat org.apache.hadoop.net.unix.DomainSocket.validateSocketPathSecurity0(Native Method)at org.apache.hadoop.net.unix.DomainSocket.bindAndListen(DomainSocket.java:193)at org.apache.hadoop.hdfs.net.DomainPeerServer.<init>(DomainPeerServer.java:40)at org.apache.hadoop.hdfs.server.datanode.DataNode.getDomainPeerServer(DataNode.java:1195)at org.apache.hadoop.hdfs.server.datanode.DataNode.initDataXceiver(DataNode.java:1162)at org.apache.hadoop.hdfs.server.datanode.DataNode.startDataNode(DataNode.java:1417)at org.apache.hadoop.hdfs.server.datanode.DataNode.<init>(DataNode.java:501)at org.apache.hadoop.hdfs.server.datanode.DataNode.makeInstance(DataNode.java:2783)at org.apache.hadoop.hdfs.server.datanode.DataNode.instantiateDataNode(DataNode.java:2691)at org.apache.hadoop.hdfs.server.datanode.DataNode.createDataNode(DataNode.java:2733)at org.apache.hadoop.hdfs.server.datanode.DataNode.secureMain(DataNode.java:2877)at org.apache.hadoop.hdfs.server.datanode.DataNode.main(DataNode.java:2901)
2023-09-17 03:04:54,483 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1: java.io.IOException: The path component: '/var/lib/hadoop-hdfs' in '/var/lib/hadoop-hdfs/dn_socket' has permissions 0755 uid 993 and gid 991. It is not protected because it is owned by a user who is not root and not the effective user: '0'. This might help: 'chown root /var/lib/hadoop-hdfs' or 'chown 0 /var/lib/hadoop-hdfs'. For more information: https://wiki.apache.org/hadoop/SocketPathSecurity
-
解决办法: 由于前面的/var/lib/hadoop-hdfs的问题,需将其用户修改为root
-
# 三个节点都执行这个操作 [root@node01 ~]#chown root /var/lib/hadoop-hdfs/ [root@node02 ~]#chown root /var/lib/hadoop-hdfs/ [root@node03 ~]#chown root /var/lib/hadoop-hdfs/
4.namenode启动异常,日志显示
aused by: org.apache.hadoop.hdfs.server.namenode.RedundantEditLogInputStream$PrematureEOFException: got premature end-of-file at txid 27027; expected file to go up to 27152at org.apache.hadoop.hdfs.server.namenode.RedundantEditLogInputStream.nextOp(RedundantEditLogInputStream.java:197)at org.apache.hadoop.hdfs.server.namenode.EditLogInputStream.readOp(EditLogInputStream.java:85)at org.apache.hadoop.hdfs.server.namenode.EditLogInputStream.skipUntil(EditLogInputStream.java:151)at org.apache.hadoop.hdfs.server.namenode.RedundantEditLogInputStream.nextOp(RedundantEditLogInputStream.java:179)at org.apache.hadoop.hdfs.server.namenode.EditLogInputStream.readOp(EditLogInputStream.java:85)at org.apache.hadoop.hdfs.server.namenode.FSEditLogLoader.loadEditRecords(FSEditLogLoader.java:213)... 12 more
这个错误表明在处理 HDFS(Hadoop分布式文件系统)的编辑日志时遇到了意外的文件结尾。
要解决这个问题,您可以尝试以下方法:
-
检查文件完整性:检查导致错误的编辑日志文件是否完整。可能是由于文件损坏或丢失导致了预期范围之外的文件结尾。您可以尝试从备份中恢复丢失的文件或使用其他副本。
-
恢复缺失的日志段:如果确定存在缺失的日志段,您可以尝试使用辅助工具(如
hdfs oiv命令)来恢复缺失的事务日志。具体步骤可以参考 HDFS 文档和社区支持资源。 -
恢复备份:如果有可用的完整备份,您可以尝试将备份数据还原到新的文件系统中,并确保整个过程符合数据一致性和正确性的要求。
-
寻求专业支持:如果以上方法无法解决问题,建议您咨询 Hadoop 或 HDFS 的专业支持团队,他们可以提供更具体和针对性的解决方案。
请注意,在进行任何更改或修复操作之前,请务必备份重要数据,并确保在测试环境中进行验证,以避免进一步数据丢失或其他潜在问题。
-
经测试这个命令
hdfs oiv不行 -
看日志似乎是无法正常写入日志,namenode的元数据可能异常
-
# 使用这个命令修复元数据:hadoop namenode -recover,在出错的机器执行如下命令,一路按c或者y -
参考文章链接
5.impala启动出现空进程
-
说明: 如果进程数启动不对,web页面打不开,去指定的日志目录.
-
jps时出现空白的进程或者process information unavailable
-
#解决办法(注意只删除后缀为impala的即可) [root@node01 bin]# rm -rf /tmp/hsperfdata_impala* [root@node02 bin]# rm -rf /tmp/hsperfdata_impala* [root@node03 bin]# rm -rf /tmp/hsperfdata_impala*
-
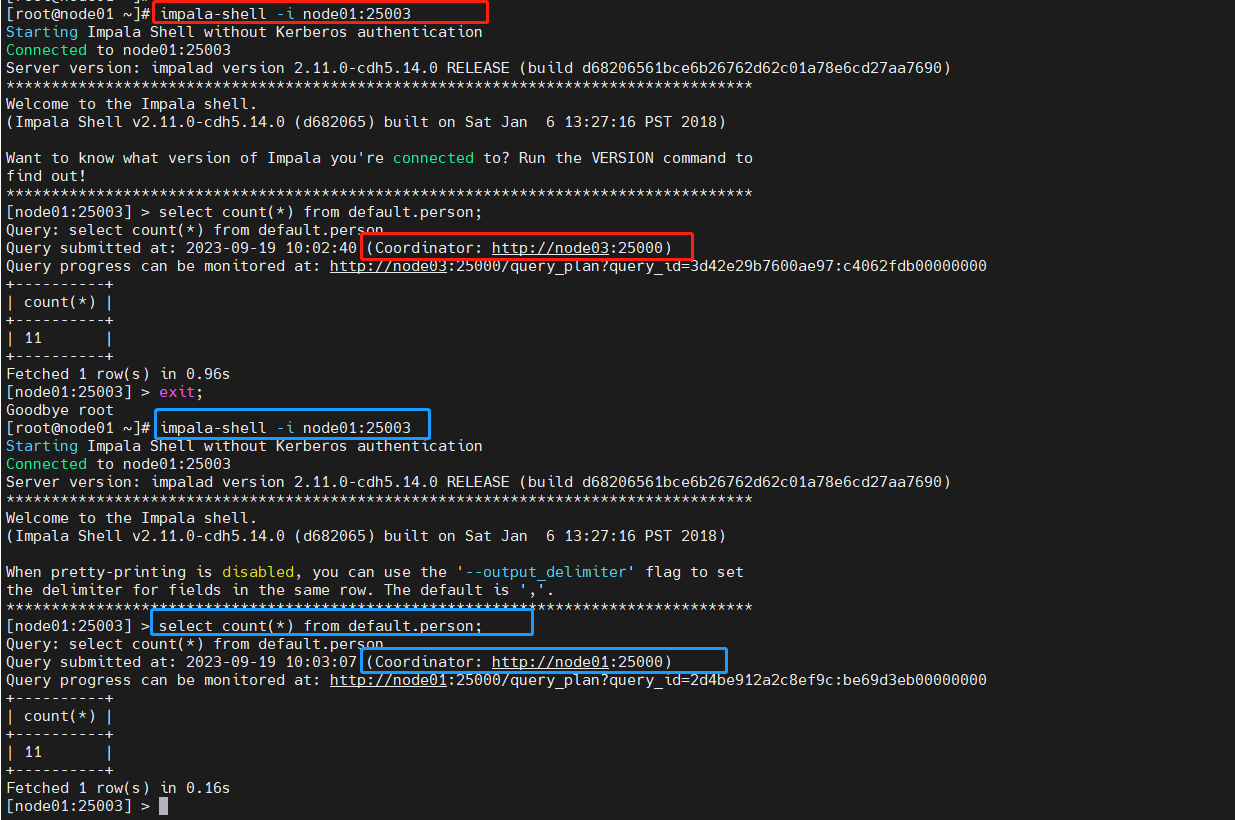
Haproxy负载均衡测试
impala-shell测试
-
在安装了Haproxy服务的节点执行命令:注意端口
25003是配置中绑定的路由端口 -
impala-shell -i node01:25003 -
看到我们指定的node01 节点,Haproxy转发至node02执行SQL

-
每次提交SQL任务协调节点都不一样,自动轮询
HDFS高可用集群中standBy 的NameNode无法启动—解决方案
在日常操作中发现自己的高可用hadoop集群,发现存在一台NamNode节点无法启动,但该节点上的DataNode仍可正常运行。其它的NameNode在正常运行。
- 启动日志如下:
Error: Gap in transactions. Expected to be able to read up until at least txid 27896 but unable to find any edit logs containing txid 27711
java.io.IOException: Gap in transactions. Expected to be able to read up until at least txid 27896 but unable to find any edit logs containing txid 27711
问题可能是由多个NameNode上的元数据信息不一致,解决方法如下:
1、停止HDFS集群。
2、删除每个NameNode节点上的data、logs。(我是在刚搭好HDFS集群遇到的这个问题,所有data和logs中的数据可直接删除。如果data和logs中存在重要的不能删除的数据,还请将数据迁移保存至别处,或使用其它方法进行解决)。
3、在每一个JournalNode节点上,输入以下命令启动journalnode服务。(我是在每一台NameNode上启动的)。
hdfs --daemon start journalnode
4、在一个NameNode节点上,对其元数据进行修复
hadoop namenode -recover
# 如果hdfs上没有重要数据可以直接格式化namenode
//格式化
hdfs namenode -format
//启动namenode
hdfs --daemon start namenode
5、在其它每一个NameNode节点上执行下面这句话,同步<第4步那个NameNode节点>的元数据信息。
hdfs namenode -bootstrapStandby
6、其它NameNode节点都去执行下面这句话启动NameNode——除<第4步那个NameNode节点>。
hdfs --daemon start namenode
然后通过jps就可以查看NameNode已经启动了。
参考博客
- https://blog.csdn.net/qq_42385284/article/details/88960678
相关文章:
Centos7原生hadoop环境,搭建Impala集群和负载均衡配置
Centos7原生hadoop环境,搭建Impala集群和负载均衡配置 impala介绍 Impala集群包含一个Catalog Server (Catalogd)、一个Statestore Server (Statestored) 和若干个Impala Daemon (Impalad)。Catalogd主要负责元数据的获取和DDL的执行,Statestored主要负…...

如何在macOS上安装Go并搭建本地编程环境
引言 Go是一种诞生于挫折中的编程语言。在谷歌,开发人员厌倦了在为新项目选择语言时必须做出权衡。有些语言执行效率很高,但需要很长时间编译,而另一些语言易于编写,但在生产环境中运行效率很低。因此,谷歌发明了Go语…...
postgresql-存储过程
postgresql-存储过程 简述PL/pgSQL 代码块结构示例嵌套子块 声明与赋值控制结构IF 语句CASE 语句简单case语句搜索 CASE 语句 循环语句continuewhilefor语句遍历查询结果 foreach 游标游标传参 错误处理报告错误和信息检查断言 捕获异常自定义函数重载VARIADIC 存储过程示例事务…...

改造user ,使得userId相同视为一个对象,user是Key,User的username做value
如果您想要将具有相同userId的用户视为一个对象,其中User对象是键,而User对象的username是值,您可以使用Java的Map<User, String>数据结构来实现。以下是示例代码: java import java.util.*;class User {private int userI…...

力扣刷题-数组-滑动窗口法相关题目总结
209. 长度最小的子数组(最小滑窗) 给定一个含有 n 个正整数的数组和一个正整数 s ,找出该数组中满足其和 ≥ s 的长度最小的 连续 子数组,并返回其长度。如果不存在符合条件的子数组,返回 0。 示例: 输入&…...

Qt创建线程(线程池)
1.线程池可以创建线程统一的管理线程(统一创建、释放线程) 2.使用线程池方法实现点击开始按钮生成10000个随机数,然后分别使用冒泡排序和快速排序排序这10000个随机数,最后在窗口显示排序后的数字: mainwindow.h文件…...

【Java】泛型 之 使用泛型
使用ArrayList时,如果不定义泛型类型时,泛型类型实际上就是 Object: // 编译器警告: List list new ArrayList(); list.add("Hello"); list.add("World"); String first (String) list.get(0); String second (Strin…...

消费者NPS调查,帮您了解客户满意度!
随着市场竞争的日益激烈,了解消费者需求和对企业品牌的认知程度,对于企业的持续发展至关重要。您的客户对您的产品或服务有多满意?您是否想提升客户忠诚度,从而增加业务的持续增长?群狼调研(长沙产品包装测试)为您提供全新的消费者NPS调查服…...

Webpack监视文件修改,自动重新打包文件
方法一:使用watch监视文件变化 在终端中输入以下指令: npx webpack --watch 我们使用这种方法监听文件变化时只会监听我们计算机本地的文件变化,在开发场景中我们的项目是要部署到服务器中的,因此这种方式并不推荐。 方法二&…...
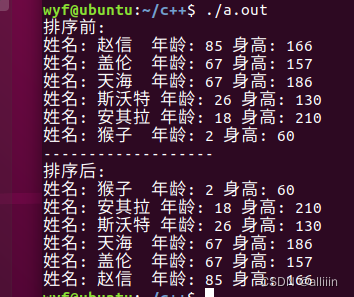
list容器排序案例
案例描述:将Perspn自定义数据类型进行排序,Person中属性有姓名、年龄、身高 排序规则:按照年龄进行升序,如果年龄相同按照身高进行降序 代码示例 #include <iostream> #include <string.h> #include <iterator> #include <vector…...

PHP使用Analysis中英文分词
1、下载Analysis,创建test.php测试 2、引入Analysis实现中文分词 <?php include "./Analysis/Analysis.php";$annew \WordAnalysis\Analysis(); $content"机器学习是一门重要的技术,可以用于数据分析和模式识别。"; //10分词数…...

视频汇聚/视频云存储/视频监控管理平台EasyCVR录像存储功能如何优化?具体步骤是什么?
视频云存储/安防监控EasyCVR视频汇聚平台基于云边端智能协同,支持海量视频的轻量化接入与汇聚、转码与处理、全网智能分发、视频集中存储等。视频监控系统EasyCVR拓展性强,视频能力丰富,具体可实现视频监控直播、视频轮播、视频录像、云存储、…...
Web服务(Web Service)
简介 Web服务(Web Service)是一种Web应用开发技术,用XML描述、发布、发现Web服务。它可以跨平台、进行分布式部署。 Web服务包含了一套标准,例如SOAP、WSDL、UDDI,定义了应用程序如何在Web上实现互操作。 Web服务的服…...

Java第4章 类的继承
目录 内容说明 章节内容 一、继承的概念 二、继承的使用 extends关键字...

Linux网络和安全:配置、远程访问与防御指南
文章目录 Linux 网络和安全引言网络配置IP地址配置配置网络接口防火墙设置安全性加强 Linux网络配置及端口管理网络配置命令端口管理 防火墙和安全性设置防火墙管理工具安全性设置 Linux远程访问技术:SSH和VPNSSHVPN Linux软件和服务网络工具文件传输VPN技术安全审计…...
如何搭建Linux环境
W...Y的主页 😊 代码仓库分享 💕 当我们想要搭建一个Linux系统,我们应该怎么使用呢? 今天我就带领大家搭建Linux系统!!! 目录 Linux环境安装 双系统(不推荐) poww…...
【解决方案】edge浏览器批量添加到集锦功能消失的解决方案
edge的集锦功能很好用,右键标签页会出现如下选项: 但在某次edge更新后,右键标签页不再出现该选项: 这里可以参考为什么我的Edge浏览器右键标签页没有“将所有标签页添加到集锦”功能? - Microsoft Community 一文提出…...
-每天学习10个方法)
JS操作字符串方法学习系列(1)-每天学习10个方法
目录 **字符串连接 (Concatenation)**:**字符串长度 (Length)**:**字符串查找 (Search)**:**字符串替换 (Replace)**:**字符串分割 (Split)**:**字符串大小写转换 (Case Conversion)**:**字符串切片 (Slice)**:**字符串删除空白 (Trim)**:**字符串检查开头和结尾 (Starts/EndsW…...
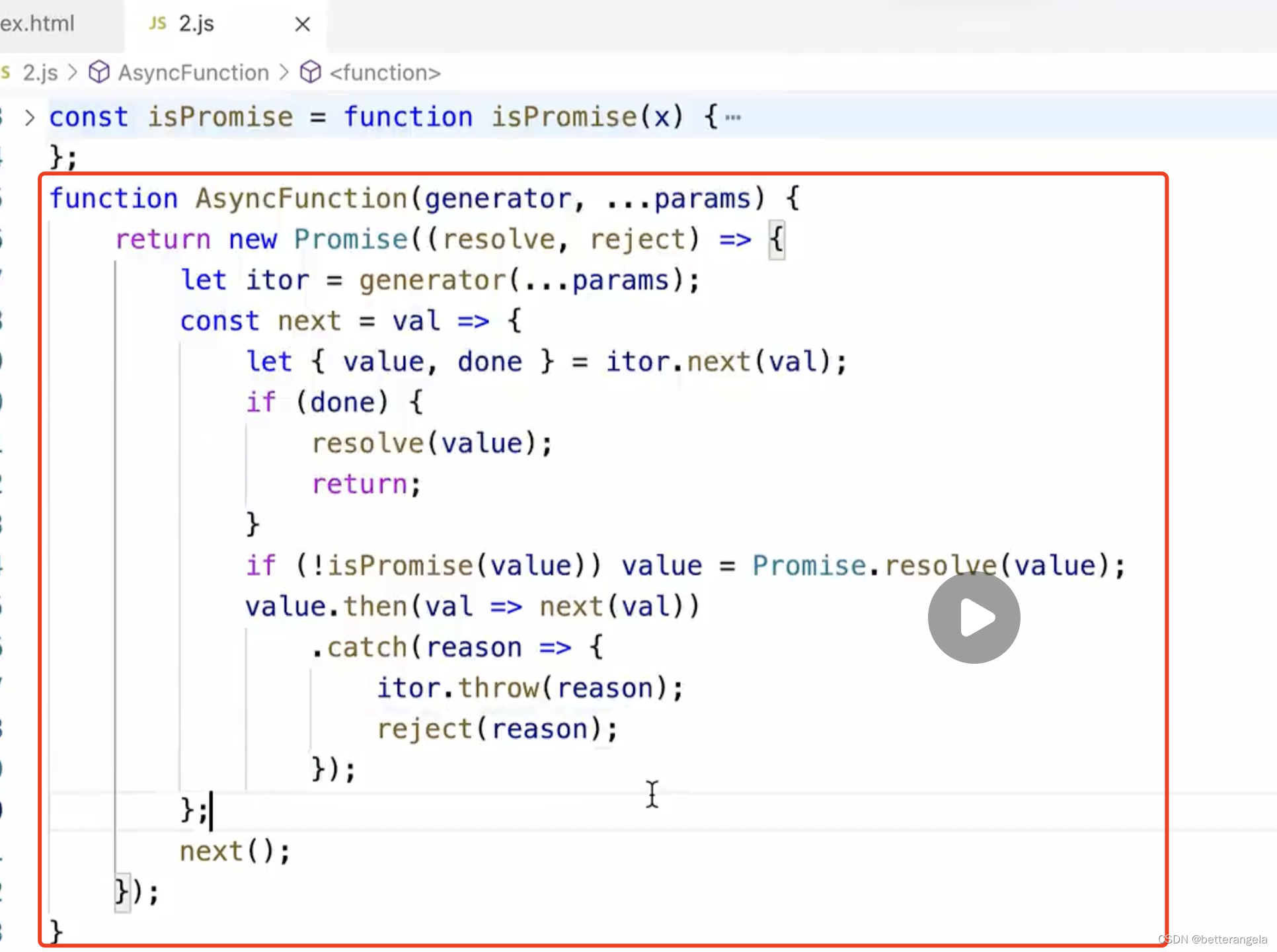
iterator和generator
iterator和generator iterator es6: let/const ...展开 迭代器 是一种机制,比如在控制台输出Iterator是没有这个类的,为不同的数据结构提供迭代循环的机制。 迭代器对象:具备next方法,next能够对你指定的数据进行迭代循环&#x…...
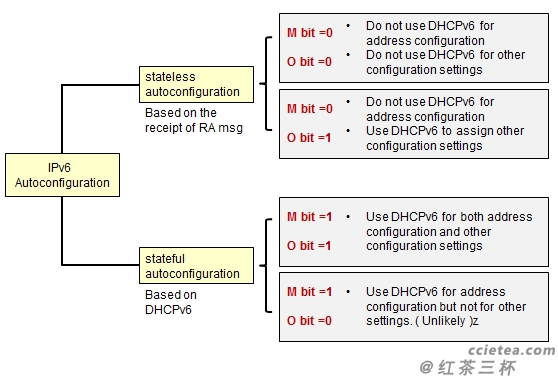
ipv6笔记及总结
1、路由器请求消息Router Solicitation和路由器通告Router Advertisement消息主要用于无状态地址的情况下,有状态的情况使用的是dhcpv6 server分配(例如:IPv6地址以及其他信息(DNS、域名等))。 2、关于IPv…...

资源优化挑战:如何用轻量级字体解决嵌入式系统中文显示难题
资源优化挑战:如何用轻量级字体解决嵌入式系统中文显示难题 【免费下载链接】LxgwWenKai LxgwWenKai: 这是一个开源的中文字体项目,提供了多种版本的字体文件,适用于不同的使用场景,包括屏幕阅读、轻便版、GB规范字形和TC旧字形版…...

浅谈:区块链存在的三点隐患问题
上文我们讲了区块链这个话题,有读者可能会有疑问:如果说区块链技术如此完美,为什么我们现在还没有广泛地用上它呢?实际上,区块链技术还处于发展早期,还在讨论和推进当中,而区块链的技术发展也较…...

OpenClaw跨平台控制:ollama-QwQ-32B同步操作多台设备的配置
OpenClaw跨平台控制:ollama-QwQ-32B同步操作多台设备的配置 1. 为什么需要跨设备自动化控制 上个月我家里添置了三台不同用途的设备:一台用于媒体处理的Mac mini、一台跑深度学习模型的Linux服务器,还有一台Windows主机专门处理文档。每次需…...

MongoDB时间戳转换实战:从数字到标准时间格式的完整指南
1. MongoDB时间戳转换的核心概念 第一次接触MongoDB时间戳转换时,我也被各种时间格式搞得晕头转向。简单来说,MongoDB中的时间戳主要有三种存储形式:数字类型(如1655448286502)、字符串类型(如"165544…...

C语言开发环境哪家强?VSCode优势多,配置步骤快来看
当前存在多种C语言开发环境,其中最为专业的当属CLion,它能够运用各类AI辅助编程插件,然而无法免费使用,并且体积过于庞大。免费的像DevCpp等,体积较小,配置简便,只是无法接入AI辅助编程插件。VS…...

SenseVoice-small部署教程:WSL2子系统Windows本地开发环境完整搭建
SenseVoice-small部署教程:WSL2子系统Windows本地开发环境完整搭建 1. 前言:为什么要在本地部署语音识别? 如果你正在寻找一个能在自己电脑上离线运行的语音识别工具,那么你来对地方了。今天我要分享的是如何在Windows电脑上&am…...

Labview信号采集与分析系统:基础框架与二次开发的宝藏
Labview 信号采集与分析系统(含报告) 系统可作自己设计的基础框架,然后在基础上进行二次开发。 系统功能: (1)可采集传感器的真实信号; (2)可采集 labview 产生的模拟信号; (3&#…...
)
Linux下adb调试小米手机报错Exception的5种解决方法(附详细排查步骤)
Linux下adb调试小米手机报错Exception的5种深度解决方案 最近在Linux环境下用adb调试小米手机时,不少开发者遇到了Exception occurred while executing put这个让人头疼的错误。作为一名常年与adb打交道的开发者,我深知这种问题一旦出现,轻则…...

Gun.js数据验证终极指南:确保实时数据准确性的5大策略
Gun.js数据验证终极指南:确保实时数据准确性的5大策略 【免费下载链接】gun amark/gun: 是一个用于实现实时数据同步和通信的 JavaScript 库,可以方便地在 Web 应用中实现实时数据同步和通信。适合对 JavaScript、实时数据同步和想要实现实时数据同步的开…...

Windows包管理器Winget一键安装完整指南:告别繁琐手动配置
Windows包管理器Winget一键安装完整指南:告别繁琐手动配置 【免费下载链接】winget-install Install winget tool using PowerShell! Prerequisites automatically installed. Works on Windows 10/11 and Server 2022. 项目地址: https://gitcode.com/gh_mirrors…...