云原生丨一文教你基于Debezium与Kafka构建数据同步迁移(建议收藏)
文章目录
- 前言
- 一、安装部署
- Debezium架构
- 部署示意图
- 安装部署
- 二、数据迁移
- Postgres迁移到Postgres
- MySQL迁移到PostgresSQL
前言
在项目中,我们遇到已有数据库现存有大量数据,但需要将全部现存数据同步迁移到新的数据库中,我们应该如何处理呢?
本期我们就基于Debezium与Kafka构建数据同步。
一、安装部署
Debezium架构

Debezium 是一个基于不同数据库中提供的变更数据捕获功能(例如,PostgreSQL中的逻辑解码)构建的分布式平台。 Debezium是通过Apache Kafka连接部署的。
Kafka Connect是一个用于实现和操作的框架运行时。
源连接器,如Debezium,它将数据摄取到Kafka中(在我们的接下来实际的例子中,Debezium将Mysql数据摄取到Kafka中);
接收连接器,它将数据从Kafka主题写入到其他到系统,这个系统可以有多种,在我们例子中,会将Kafka主题写入到PostgreSQL数据库中。
部署示意图

- Zookeeper:Zookeeper容器,用于构建Kafka环境;
- Kafka:Kafka容器,数据库的变更信息以topic的形式保存在kafka中;
- Kafka-ui:kafka的UI页面容器,可以直观的查看kafka中的Brokers,Topics,Consumers等信息;
- Connect:Debezium的Connect容器,对接Kafka的Connect,通过Source Connector将数据同步到Kafka中,通过Sink Connect消费Kafka的topic消息;
- Debezium Connector:Source Connector插件,以Jar包的形式部署在Connect中,Debezium自带有MongoDB,MySQL,PostgreSQL,SQL Server,Oracle,Db2连接器;
- DBC connector:Sink Connector插件,以Jar包的形式部署在Connect中,本次部署安装的是JDBC连接器,将Kafka上的数据同步到数据库中;
- Debezium-ui:Debezium connect的ui页面容器。用于创建和显示Source Connector
- Source Database:数据迁移来源方数据库。本次部署中使用的是MySQL和Postgres(10+版本);
- Target Database:数据库迁移目标数据库。本次部署中使用的是Postgres。
安装部署
本次部署需要先安装Docker。
Debezium使用Docker安装部署,如下⬇
docker-compose.yaml
version: '2'
services:zookeeper:image: quay.io/debezium/zookeeper:2.0ports:- 2181:2181- 2888:2888- 3888:3888kafka:image: quay.io/debezium/kafka:2.0ports:- 9092:9092links:- zookeeperenvironment:- ZOOKEEPER_CONNECT=zookeeper:2181connect:image: quay.io/debezium/connect:2.0ports:- 8083:8083- 5005:5005links:- kafkaenvironment:- BOOTSTRAP_SERVERS=kafka:9092- GROUP_ID=1- CONFIG_STORAGE_TOPIC=my_connect_configs- OFFSET_STORAGE_TOPIC=my_connect_offsets- STATUS_STORAGE_TOPIC=my_source_connect_statuseskafka-ui:image: provectuslabs/kafka-ui:latestports:- "9093:8080"environment:- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka:9092links:- kafkadebezium-ui:image: debezium/debezium-ui:2.0ports:- "8080:8080"environment:- KAFKA_CONNECT_URIS=http://connect:8083links:- connect
部署命令:
docker-compose -f docker-compose.yaml -p debezium up -d
部署完成后,Docker容器列表,如下:

-
Kafka-ui访问地址:http://localhost:9093
-
Debezium-ui访问地址:http://localhost:8080
Source Connector和Sink Connector都是以JAR包的方式,存在于Connect容器的/kafka/connect目录下。
Connect容器自带有Debezium的官方Source Connector:
- debezium-connector-db2
- debezium-connector-mysql
- debezium-connector-postgres
- debezium-connector-vitess
- debezium-connector-mongodb
- debezium-connector-oracle
- debezium-connector-sqlserver
需要自行注册Sink Connector:Kafka-Connect-JDBC(新建Kafka-Connect-JDBC目录,下载JAR包放入此目录,重启Conenct)。
注册Sink Connector
# docker容器中新建kafka-connect-jdbc目录
docker exec 容器id mkdir /kafka/connect/kafka-connect-jdbc
# 下载jar包到本地
wget https://packages.confluent.io/maven/io/confluent/kafka-connect-jdbc/5.3.2/kafka-connect-jdbc-5.3.2.jar
# 拷贝jar包到docker容器
docker cp kafka-connect-jdbc-5.3.2.jar 容器id:/kafka/connect/kafka-connect-jdbc
# 重启connect容器
docker restart 容器id
二、数据迁移

数据迁移经历以下几个步骤:
1)启动源数据库;
2)注册Source Connector,Source Connector监听Source Database的数据变动,发布数据到Kafka的Topic中,一个表对应一个Topic,Topic中包含对表中某条记录的某个操作(新增,修改,删除等);
3)启动目标数据库;
4)注册Sink Connector,Sink Connector消费Kafka中的Topic,通过JDBC连接到Target Database,根据Topic中的信息,对表记录执行对应操作。
Postgres迁移到Postgres
- 1.启动源数据库-Postgres
本次部署通过容器的方式启动:
docker run -d --name source-postgres -p 15432:5432 -e POSTGRES_PASSWORD=123456 -e POSTGRES_USER=debe postgres:12.6
- 2.注册Source Connecto
通过Debezium UI页面进行注册。




需要注意的有以下几点:
Debezium Postgres类型的Source Connector支持的Postgres需要将wal_level修改为logical;修改Postgres中的Postgresql.conf文件中的配置(wal_level = logical)并重启Postgres;
Postgres需要支持解码插件,Debezium官方一共提供了两个解码插件:
Decoderbufs:Debezium默认配置,由Debezium维护;
Pgoutput:Postgres 10+版本自带;使用此插件时,需要配置plugin.name=pgoutput
- 3.启动目标数据库-Postgre
docker run -d --name target-postgres -p 25432:5432 -e POSTGRES_PASSWORD=123456 -e POSTGRES_USER=debe postgres:12.6
- 4.注册Sink Connector
通过Connect提供的API进行注册
新增Connector
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d \
'{"name": "sink-connector-postgres","config": {"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector","tasks.max": "1","topics": "postgres.public.test_source","connection.url": "jdbc:postgresql://10.3.73.160:25432/postgres?user=debe&password=123456","transforms": "unwrap","transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState","transforms.unwrap.drop.tombstones": "false","auto.create": "true","insert.mode": "upsert","delete.enabled": "true","pk.fields": "id","pk.mode": "record_key"}
}'
- 5.验证数据迁移过程
源数据库中的表数据迁移到Kafka
新建表test_source和test_source1
test_source&test_source1.sql
-- test_source
create table if not exists public.test_source
(id integer not nullconstraint test_source_pkprimary key,name varchar(64)
);alter table public.test_sourceowner to debe;insert into public.test_source (id, name) values (1, 'a');
-- test_source1
create table if not exists public.test_source1
(id integer not nullconstraint test_source1_pkprimary key,name varchar(64)
);alter table public.test_source1owner to debe;insert into public.test_source1 (id, name) values (1, 'a1');
Kafka新建数据前 ⬇

Kafka新建数据后 ⬇


源数据库中新建表test_source和表test_source1后,Kafka中出现了两个Topic:
postgres.public.test_source和postgres.public.test_source1,与这两个表一一对应,topic中的message对应着对表中记录的操作(新增1条记录)。
监听的表可通过连接器配置进行过滤,比如配置"table.include.list": “public.test_source”,就只会出现一个Topic:postgres.public.test_source
Kafka中的数据迁移到目标数据库


注册Sink Connector后,Kafka中会新增一个Customer,对postgres.public.test_source进行消费(sink connector配置中的"topics": "postgres.public.test_source"指定);
对应的源数据库(sink connector配置中的"connection.url": "jdbc:postgresql://10.3.73.160:25432/postgres?user=debe&password=123456"指定)会新增一个表public.test_source,该表中的数据和源数据库中的public.test_source始终保持同步。
MySQL迁移到PostgresSQL
- 1.启动源数据库-mysql
本次部署通过docker启动:
docker run -d --name source-mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=debezium -e MYSQL_USER=mysqluser -e MYSQL_PASSWORD=mysqlpw debezium/example-mysql:2.0
- 2.注册Source Connector
启动MySQL数据源连接注册
注册MySQL数据源有两种方式:
1、在Debezium UI中直接添加
2、调用Kafka API 注册
在Debezium UI中直接添加

选择MySQL数据源

调用Kafka API注册
新增Connector
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d \
'{"name": "inventory-connector","config": {"connector.class": "io.debezium.connector.mysql.MySqlConnector","tasks.max": "1","topic.prefix": "dbserver1","database.hostname": "mysql","database.port": "3306","database.user": "debezium", //数据库用户名"database.password": "dbz", //数据库密码"database.server.id": "184054","database.include.list": "inventory", //数据源覆盖范围"schema.history.internal.kafka.bootstrap.servers": "kafka:9092","schema.history.internal.kafka.topic": "schema-changes.inventory","transforms": "route","transforms.route.type": "org.apache.kafka.connect.transforms.RegexRouter","transforms.route.regex": "([^.]+)\\.([^.]+)\\.([^.]+)","transforms.route.replacement": "$3"}
}'

验证Source Connector注册结果
注册连接前:

注册连接后:

多出来的Topics信息是MySQL source表信息,连接MySQL数据库可见表:


UI for Apache Kafka中可以看到Messages同步信息。

访问Debezium UI(http://localhost:8080/ )可以看到MySQL的连接。

- 3.启动目标数据库-Postgres
本次部署采用Docker方式启动:
docker run -d --name target-postgres -p 5432:5432 -e POSTGRES_USER=postgresuser -e POSTGRES_PASSWORD=postgrespw -e POSTGRES_DB=inventory debezium/postgres:9.6
- 4.注册Sink Connector (通过API接口)
新增Connector
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d \
'{"name": "jdbc-sink","config": {"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector","tasks.max": "1","topics": "customers", //迁移目标主题(这里是按照表来订阅的)"connection.url": "jdbc:postgresql://postgres:5432/inventory?user=postgresuser&password=postgrespw","transforms": "unwrap","transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState","transforms.unwrap.drop.tombstones": "false","auto.create": "true","insert.mode": "upsert","delete.enabled": "true","pk.fields": "id","pk.mode": "record_key"}
}'

注册PostgreSQL connector后,不会在Debezium中显示Connector client 信息,但可以在UI for Apache Kafka中看到:

- 5.验证数据迁移过程
完成安装步骤后,以Customers表为例,做CUD操作语句,实现MySQL数据库同步数据到PostgreSQL 。
Mysql 数据库现有数据:


手动在MySQL数据库Customers表中添加一条数据 ⬇
customers.sql
insert into customers(id,first_name,last_name,email) values(1005,'test','one','123456@qq.com');

在PostgreSQL数据库中Customers多出一条数据:

Kafka中Messages新增一条数据,完成数据同步:

可以看到消费如下信息:
topics-customers.json
{"schema": {"type": "struct","fields": [{"type": "struct","fields": [{"type": "int32","optional": false,"field": "id"},{"type": "string","optional": false,"field": "first_name"},{"type": "string","optional": false,"field": "last_name"},{"type": "string","optional": false,"field": "email"}],"optional": true,"name": "dbserver1.inventory.customers.Value","field": "before"},{"type": "struct","fields": [{"type": "int32","optional": false,"field": "id"},{"type": "string","optional": false,"field": "first_name"},{"type": "string","optional": false,"field": "last_name"},{"type": "string","optional": false,"field": "email"}],"optional": true,"name": "dbserver1.inventory.customers.Value","field": "after"},{"type": "struct","fields": [{"type": "string","optional": false,"field": "version"},{"type": "string","optional": false,"field": "connector"},{"type": "string","optional": false,"field": "name"},{"type": "int64","optional": false,"field": "ts_ms"},{"type": "string","optional": true,"name": "io.debezium.data.Enum","version": 1,"parameters": {"allowed": "true,last,false,incremental"},"default": "false","field": "snapshot"},{"type": "string","optional": false,"field": "db"},{"type": "string","optional": true,"field": "sequence"},{"type": "string","optional": true,"field": "table"},{"type": "int64","optional": false,"field": "server_id"},{"type": "string","optional": true,"field": "gtid"},{"type": "string","optional": false,"field": "file"},{"type": "int64","optional": false,"field": "pos"},{"type": "int32","optional": false,"field": "row"},{"type": "int64","optional": true,"field": "thread"},{"type": "string","optional": true,"field": "query"}],"optional": false,"name": "io.debezium.connector.mysql.Source","field": "source"},{"type": "string","optional": false,"field": "op"},{"type": "int64","optional": true,"field": "ts_ms"},{"type": "struct","fields": [{"type": "string","optional": false,"field": "id"},{"type": "int64","optional": false,"field": "total_order"},{"type": "int64","optional": false,"field": "data_collection_order"}],"optional": true,"name": "event.block","version": 1,"field": "transaction"}],"optional": false,"name": "dbserver1.inventory.customers.Envelope","version": 1},"payload": {"before": null,"after": {"id": 1005,"first_name": "test","last_name": "one","email": "123456@qq.com"},"source": {"version": "2.0.1.Final","connector": "mysql","name": "dbserver1","ts_ms": 1672024796000,"snapshot": "false","db": "inventory","sequence": null,"table": "customers","server_id": 223344,"gtid": null,"file": "mysql-bin.000003","pos": 392,"row": 0,"thread": 16,"query": null},"op": "c","ts_ms": 1672024796396,"transaction": null}
}
重要的部分是 “payload” json 中信息:
- source 中会展示“版本”,“数据源”等信息;
- after 代表变动信息;
- “op” 操作信息,例如“c” 代表创建;
需要注意的是,结果的json格式是Debezium定义好的格式。
Debezium json格式通常前面定义Schema信息,最后才是实际的载荷(payload)信息。
详细格式定义可以查看:https://debezium.io/documentation/reference/1.6/connectors/mysql.html
通过以上步骤,我们在Docker环境上使用Debezium实现了数据同步到kafaka。本期关于数据同步迁移的内容就到这里了,建议大家收藏学习!~
相关文章:
云原生丨一文教你基于Debezium与Kafka构建数据同步迁移(建议收藏)
文章目录前言一、安装部署Debezium架构部署示意图安装部署二、数据迁移Postgres迁移到PostgresMySQL迁移到PostgresSQL前言 在项目中,我们遇到已有数据库现存有大量数据,但需要将全部现存数据同步迁移到新的数据库中,我们应该如何处理呢&…...
顶象APP加固的“蜜罐”技术有什么作用
目录 蜜罐有很多应用模式 蜜罐技术让App加固攻守兼备 顶象端加固的三大功能 为了捕获猎物,猎人会在设置鲜活的诱饵。被诱惑的猎物去吃诱饵时,就会坠入猎人布置好的陷阱,然后被猎人擒获,这是狩猎中常用的一种手段。在业务安全防…...

训练一个ChatGPT需要多少数据?
“风很大”的ChatGPT正在席卷全球。作为OpenAI在去年底才刚刚推出的机器人对话模型,ChatGPT在内容创作、客服机器人、游戏、社交等领域的落地应用正在被广泛看好。这也为与之相关的算力、数据标注、自然语言处理等技术开发带来了新的动力。自OpenAI发布ChatGPT以来&…...

【GlobalMapper精品教程】053:打开dbf文件并生成有坐标系的shp数据
本文讲解在globalmapper汇总打开dbf文件并生成有坐标系的shp数据。 文章目录一、dbf文件解读二、打开dbf文件二、另存为shp文件一、dbf文件解读 我们可以通过Excel或FME等多种软件查看dbf的结构,字段有:Name,kind,Lat,…...

图像亮度调整
非线性方式 调整图像的方法有很多,最常用的方法就是对图像像素点的R、G、B三个分量同时进行增加(减少)某个值,达到调整亮度的目的。即改变图像的亮度,实际就是对像素点的各颜色分量值做一个平移。这种方法属于非线性的…...
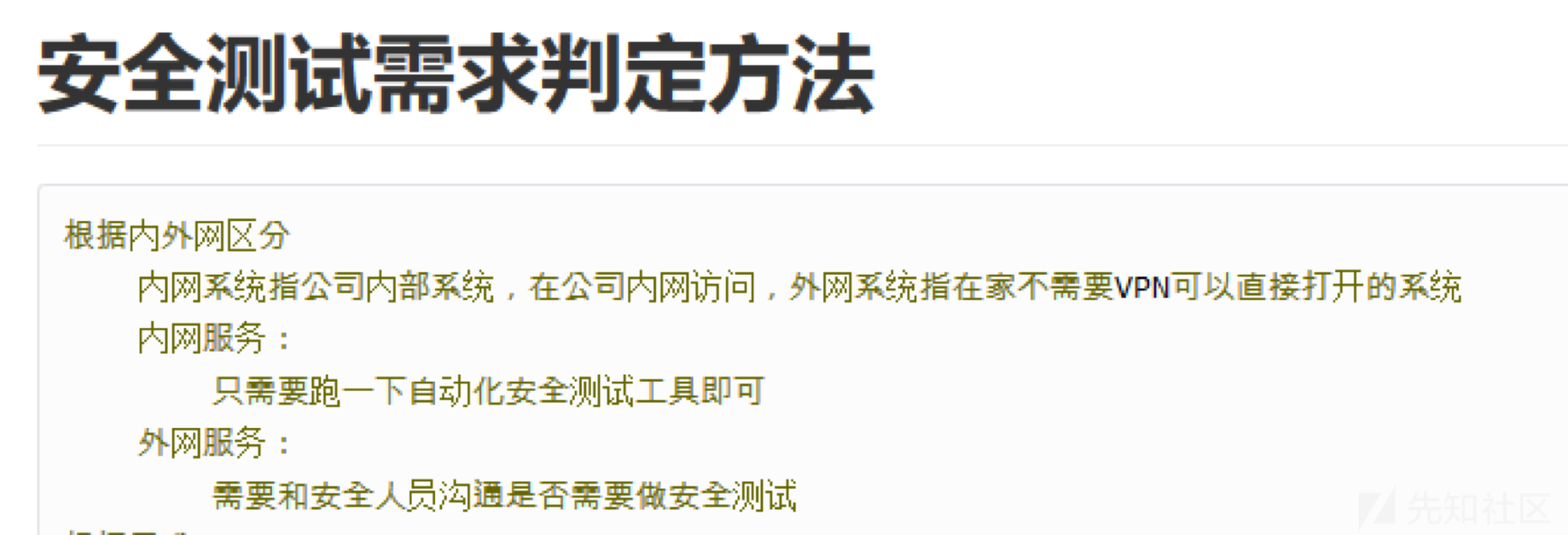
精简版SDL落地实践
一、前言一般安全都属于运维部下面,和上家公司的运维总监聊过几次一些日常安全工作能不能融入到DevOps中,没多久因为各种原因离职。18年入职5月一家第三方支付公司,前半年在各种检查中度过,监管形势严峻加上大领导对安全的重视(主…...
第一回:Matplotlib初相识
一、认识matplotlib Matplotlib是一个Python 2D绘图库,能够以多种硬拷贝格式和跨平台的交互式环境生成出版物质量的图形,用来绘制各种静态,动态,交互式的图表。 Matplotlib可用于Python脚本,Python和IPython Shell、…...

怎么找回电脑删除的图片
怎么找回电脑删除的图片?图片作为一种非常简单方便的文件,经常被用来辅助我们的日常工作和学习。但在我们整理电脑时,如果我们不小心手一抖就删除了一些重要的图片,遇到这种事我们要如何才能恢复呢? 众所周知,简单的删除并不会完…...

【Linux】进程状态与进程优先级
目录一.进程状态1.阻塞:2.挂起:具体情况3.具体操作系统状态变化R:运行状态(running)S:休眠状态(sleeping)D:磁盘休眠状态(Disk sleep)T:暂停状态(stopped)暂停进程继续进程t:追踪暂停状态(traci…...

Python+Qt生日提醒
PythonQt生日提醒如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助!前言这篇博客针对<<PythonQt生日提醒>>编写代码,代码整洁,规则,易读。 学习与应用推荐首选。文章目…...
第二章 编写MBR主引导记录
主引导记录(MBR,Master Boot Record)是采用MBR分区表的硬盘的第一个扇区,即C/H/S地址的0柱面0磁头1扇区,也叫做MBR扇区 计算机的启动过程 为什么程序要载入内存 CPU的硬件电路被设计成只能运行处于内存中的程序&…...
Android 9.0 仿ios的hotseat效果修改hotseat样式
1.概述 在9.0的系统rom定制化的产品中,在launcher3的定制化需求中,有很多功能需求点需要开发,在对一下ui的定制化的过程中,会参考ios的样式进行定制化,所以最近项目需求 要求仿ios的hotseat的样式来进行产品的定制,开发一款仿ios的hotseat,所以需要对hotseat进行分析,然…...

量化私募投资百亿头部量化私募企业在招岗位:AI算法工程师21/22/23届,校招/秋招/社招都看年base60-200万
量化私募投资百亿头部量化私募企业在招岗位:AI算法工程师21/22/23届,校招/秋招/社招都看年base60-200万bonuscut965制度应届需要985本硕博有3年以上相关ai算法经验可放宽学历"岗位职责:base 北京 上海 杭州 深圳1. 利用机器学习、深度学习和人工智能…...

百度西交大大数据菁英班目标检测竞赛
来源:投稿 作者:LSC 编辑:学姐 数据介绍 数据集共包括40000张训练图像和1000张测试图像,每张训练图像对应xml标注文件: 共包含3类:0:head, 1:helmet, 2:person。 提交格式要求,提交名为pred_r…...
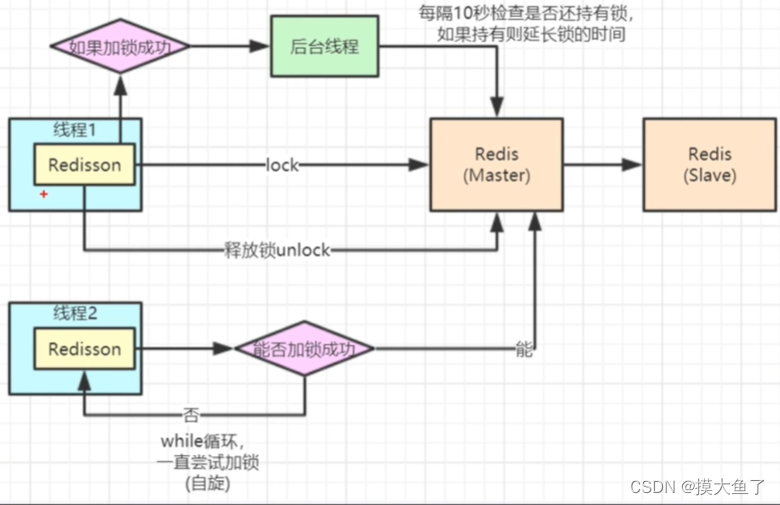
Redisson实现分布式锁
目录Redisson简介Redisson实现分布式锁步骤引入依赖application.ymlRedisson 配置类Redisson分布式锁实现Redisson简介 Redis 是最流行的 NoSQL 数据库解决方案之一,而 Java 是世界上最流行(注意,没有说“最好”)的编程语言之一。…...

【HID基础知识】
蓝牙HID基础知识 一:定义 HID是Human Interface Device的缩写,由其名称可以了解HID设备是直接与人交互的设备,例如键盘、鼠标与游戏手柄等。 蓝牙HID 是属于蓝牙协议里面的一个profile, 不管在蓝牙2.0 2.1 3.0还是4.0,5.0的蓝牙中…...

工赋开发者社区 | 工业数字孪生:西门子工业网络与设备虚拟调试案例(TIA+MCD+SINETPLAN)
PART1案例背景及基本情况新生产系统的设计和实施通常是耗时且高成本的过程,完成设计、采购、安装后,在移交生产运行之前还需要一个阶段,即调试阶段。如果在开发过程中的任何地方出现了错误而没有被发现,那么每个开发阶段的错误成本…...
将闲置的Ipad作为Windows的副屏(Twomon SE)
目录一、前言二、方法第一步 安装软件第二步 使用步骤三、注意一、前言 在看网课的时候,总有种不得劲的感觉,来来回回的切换就很糟心~~无意间看见闲置的板砖(Ipad),计上心来-- _ – 期间也尝试过免费的软件ÿ…...

浮点数在内存中的存储——“C”
各位CSDN的uu们你们好呀,今天,小雅兰的内容是浮点数在内存中的存储,昨天我们已经写过了整型在内存中的存储,那么,浮点数在内存中是怎样存储的呢?现在,就让我们进入浮点数在内存中的存储的世界吧…...

华为OD机试 C++ 实现 - 租车骑绿岛
最近更新的博客 华为OD机试 - 入栈出栈(C++) | 附带编码思路 【2023】 华为OD机试 - 箱子之形摆放(C++) | 附带编码思路 【2023】 华为OD机试 - 简易内存池 2(C++) | 附带编码思路 【2023】 华为OD机试 - 第 N 个排列(C++) | 附带编码思路 【2023】 华为OD机试 - 考古…...

艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验
艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_m…...

Allegro等长设置翻车实录:拓扑模板法的3个坑与手工PinPair的救赎
Allegro等长设计避坑指南:从拓扑模板到精准PinPair的实战演进在高速PCB设计中,等长匹配如同精密钟表里的齿轮啮合,差之毫厘便可能导致整个系统时序崩塌。当设计从简单的点对点结构升级到多负载复杂拓扑时,Allegro用户常陷入两种典…...

告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略
告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略当开发者尝试在UniApp中实现沉浸式设计时,往往会遇到一个令人头疼的问题——默认的白色安全区和状态栏导致界面元素(如电池图标、信号强度)几乎不可见。…...

百考通智能任务书:贴合你的选题,拒绝空话假大空
毕业设计任务书是高校教学管理中的关键环节,它不仅标志着研究工作的正式启动,更是后续开题、实施、论文撰写和答辩全过程的行动依据。然而,许多学生在撰写时常常因不熟悉本专业写作规范、技术表达能力有限,或缺乏权威模板参考而陷…...

2605.VGGT-Omega 论文解读: 3D重建的Scaling Law, Register Attention效率革命 | Oxford+Meta CVPR26 Oral
VGGT-Omega: Scaling Feed-Forward 3D Reconstruction Jianyuan Wang, Minghao Chen, Shangzhan Zhang, Nikita Karaev, Johannes Schonberger, et al. Visual Geometry Group, Oxford Meta AI | CVPR 2026 Oral | arXiv 2605.15195 Paper | Project Page 一句话总结 VGGT-Om…...
上午题回忆与解析(非标答版))
2026上半年数据库系统工程师(软考)上午题回忆与解析(非标答版)
本文为考后回忆整理,非官方标准答案,旨在为考后对答案及下半年备考的同学提供参考。题目顺序和表述可能与原卷有出入,欢迎在评论区指正、补充。📊 整体考情分析 刚结束的2026年上半年数据库系统工程师考试,上午题的风格…...
)
别再死磕USB HID了!用ESP32的Arduino框架手把手教你实现蓝牙鼠标键盘(附完整代码)
ESP32蓝牙HID实战:零基础打造自定义键盘鼠标 手里那块吃灰的ESP32开发板终于能派上用场了!上周我用它做了个无线演示控制器,在会议室里走着就能翻PPT,同事们都问是怎么实现的。其实秘诀就在于ESP32的蓝牙HID功能——不需要任何USB…...

3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器
3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为热门PC游戏不支…...

从NLP到RAG:AI标书生成系统的技术架构与落地路径深度剖析
引言2026年2月,国家发改委等八部门联合印发《关于加快招标投标领域人工智能推广应用的实施意见》,明确到2026年底招标文件检测、智能辅助评标、围串标识别等重点场景在部分省市实现全覆盖。同一时期,《招标投标法》修订草案经国务院常务会议原…...

原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析
原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析 【免费下载链接】KCN-GenshinServer 基于GC制作的原神一键GUI多功能服务端。 项目地址: https://gitcode.com/gh_mirrors/kc/KCN-GenshinServer 你是否曾想过拥有一个完全由自己掌控的提瓦特大陆&am…...