【python】考前复习,python基础语法知识点整理
文章目录
- 1.常量与表达式
- 2.变量和数据类型
- 创建变量
- 数据类型
- 动态类型
- 数据类型的转换
- 3.注释
- 4.字符串
- 字符串的定义方式
- 字符串的拼接
- 字符串的格式化①
- 字符串格式化的精度控制
- 字符串的格式化②
- 对表达式进行格式化
- 5.从控制台输入(input)
- 6.运算符
- 算术运算符
- 赋值运算符
- 布尔类型和比较运算符
- 7.条件语句
- if语句
- if else语句
- if elif else语句
- 判断语句的嵌套
- 8.循环
- while循环
- 循环语句的嵌套
- for循环
- range语句
- continue和break
- 9.函数
- 函数是什么
- 函数的定义与调用
- 函数的传入参数
- 函数的返回值
- None类型
- 函数的嵌套调用
- 变量在函数中的作用域
- 10.列表(list)
- 列表的定义
- 列表的下标访问
- 嵌套列表的下标
- 列表的常用方法
- 11.元组(tuple)
- 元组的定义
- 定义只有一个元素的元组
- 元组的下标访问
- 元组的常用方法
- 12.再识字符串(str)
- 字符串的下标索引
- 字符串的常用方法
- 13.集合(set)
- 集合的定义
- 集合的常用方法
- 14.字典(dict)
- 字典的定义
- 字典的常用方法
- 15.文件操作
- 文件编码
- 文件的打开
- 文件的读取
- 文件的关闭
- with open()
- 文件的写入
- 文件的追加
- 16.异常处理
- 异常的捕获
- 捕获指定的异常
- 捕获多个异常
- 捕获全部的异常
- else和finally
- 异常的传递性
- 17.结语
1.常量与表达式
print(1) #这里的1就是一个常量
print(1+2+3) #这里的1+2+3就是一个表达式
常量与表达式很简单,用的也不多,了解即可
2.变量和数据类型
变量就是用来保存数据的,如果一个数据我们要经常用到,创建一个变量把这个数据保存起来,在后面使用的时候就会很方便.
创建变量
#语法:
变量名 = 数据
这里的 = 不是 数学中比较相等,而是赋值运算
变量的命名规则:
- 变量名必须由数字,字母和下划线构成 不能是表达式
- 不能以数字开头
- 不能以关键字作为变量名
数据类型
变量的类型:为了对不同的变量进行区分
Python中的数据类型只有整型(int),浮点型(float)和字符串类型
需要注意的是:
- Python中的int的取值范围是无穷的
- Python中的float是双精度浮点数
- 字符串类型要把数据用单引号或者双引号包起来
- 字符串的类型是可以拼接的,就是把一个字符串拼接到最后一个字符串的末尾,从而得到一个更大的字符串 字符串使用 + 进行拼接
动态类型
动态类型的意思是python中的数据类型是可以变化的
a = 1
print(type(a))
# 输出结果:<class 'int'>
a = 1.5
print(type(a))
# 输出结果:<class 'float'>
a = "hello world"
print(type(a))
# 输出结果:<class 'str'>
数据类型的转换
数据类型转换这个在平时使用的也是非常多的
数据类型的转换的语法为:
# 要转换为的数据类型(变量名)
num = 1
str(num)
str_num = str(num)
# 对于转换后的数据类型建议用个变量接收一下
print(type(num)) # 输出 <class 'int'>
print(type(str_num)) # 输出 <class 'str'>
print(str_num) # 输出 1
所以要注意 数据类型的转换不会更改最初的变量类型,而是得到一个修改数据类型后的数据,如果要使用这个数据需要用另外一个变量进行接受
整数 浮点数 字符串之间可以相互转换,但是不能随便转换
需要注意:
- 任何数据类型都可以转换为字符串
- 字符串要想转换为数字,那么这个字符串中必须只有数字
- 浮点数转整数,会丢失到小数部分
3.注释
注释一边起到 对代码的进行解释说明的作用
代码的注释一共有三种方式
| python中的注释 | 符号 |
|---|---|
| 行注释 | # |
| 文档字符串 | “”“注释的内容”""或’‘‘注释的内容’’(三个双/单引号作为开头结尾,不能混用) |
4.字符串
字符串的定义方式
字符串的定义方式有三种:
# 字符串的定义方式
str1 = 'python'
str2 = "python"
str3 = """python"""
其中str3这个定义方式和注释的写法是一样的,当有变量接受时,它就是个字符串,如果没有则是注释
如果想要的定义字符串里本身包含单引号或双引号,要怎么进行解决
有三种方法:
- 单引号定义,字符串可以包换双引号
- 双引号定义,字符串可以包换单引号
- 使用 \ (转义字符)
示例:
str1 = "'python'"
str2 = '"python"'
str3 = "\"python"print(str1)
print(str2)
print(str3)
# 输出结果:
# 'python'
# "python"
# "python
字符串的拼接
字符串的拼接就是将两个及以上的字符串拼接成为一个更大的字符串,字符串的拼接要使用 +
示例:
print("人生苦短," + "我学python")
str = "python"
print("人生苦短,"+"我学"+str)
# 输出结果:
# 人生苦短,我学python
# 人生苦短,我学python
需要注意的是字符串的拼接,只能是字符串类型的数据进行拼接,而不能和非字符串类型的数据进行拼接
字符串的格式化①
为了解决字符串无法和非字符串类型进行拼接这个问题,这个时候就可以使用字符串的格式化
| 符号表示 | 描述 |
|---|---|
| %s | 将内容转换为字符串,放入占位的位置 |
| %d | 将内容转换为整数,放入占位的位置 |
| %f | 将内容转换为浮点型,放入占位的位置 |
例如:%s
- % 是指我要占位
- s 是指将变量转化为字符串放入占位的地方
示例如下:
str1 = "python"
print("我要学%s" %str1)
str2 = 2023
print("现在是%s年,我要学%s" % (str2,str1))
# 输出结果:
# 我要学python
# 现在是2023年,我要学python
注意:当只有多个字符串使用占位符进行拼接时,需要使用括号将变量括起来,变量与变量之间用逗号隔开
字符串格式化的精度控制
精度控制主要是针对数字,符号表示为 m.n
- m: 空置宽度,设置的宽度小于数字本身,则不生效(很少用)
- n: 控制小数点精度,要求是数字,进行四舍五入
示例
a = 11
b = 123456
c = 12.345
print("设置数字宽度为5,a为:%5d" %a)
print("设置数字宽度为5,b为:%5d" %b)
print("设置宽度为6,小数精度为2位,c为:%7.2f" %c)
print("宽度不限制,小数精度为2位,c为:%.2f" %c)# 输出结果:
# 设置数字宽度为5,a为: 11
# 设置数字宽度为5,b为:123456
# 设置宽度为6,小数精度为2位,c为: 12.35
# 宽度不限制,小数精度为2位,c为:12.35
# 注: .也算一个宽度
上面示例的输出结果里面有空格,显示的效果不是很明显,因此建议使用编译器尝试运行一下
字符串的格式化②
虽然使用占位符能够拼接字符串,还能精度控制,但是python还为我们提供了另外一种拼接字符串的方式
语法格式:f"内容{变量}"
这里的f就是format ,格式化的意思
示例:
num1 = "python"
print(f"人生苦短,我学{num1}")
num2 = 100
num3 = 41.9
print(f"张三有{num2}元,网购花了{num3}元")# 输出结果为:
# 人生苦短,我学python
# 张三有100元,网购花了41.9元
这种格式化字符串的方式,什么类型都可以进行格式化,但不会对精度进行控制
对表达式进行格式化
对代码中只用到一次的变量,我们就不用定义变量进行赋值了,而是直接使用表达式进行表示
示例:
print("1*1 = %d" % (1*1))
print(f"1*1 = {1*1}")
print("浮点数在python中的类型名是: %s" % type(1.23))# 输出结果:
# 1*1 = 1
# 1*1 = 1
# 浮点数在python中的类型名是: <class 'float'>
5.从控制台输入(input)
input从键盘读入输入的内容,可以使用变量对输入的内容进行接收
需要注意一点,input输入的语句接收的内容都是字符串类型,即使你输入的整数,浮点数,如果想要得到整数,浮点数类型的数据,则需要数据类型转换
num1 = input("你的兴趣爱好是:")
print(num1)
num2 = input()
num3 = input()
print(f"num1的数据类型是:{type(num1)}")
print(f"num2的数据类型是:{type(num2)}")
print(f"num3的数据类型是:{type(num3)}")
# 输出结果:
# 你的兴趣爱好是:唱跳rap篮球 (用户进行输入)
# 唱跳rap篮球
# 15 (用户进行输入)
# 12.54 (用户进行输入)
# num1的数据类型是:<class 'str'>
# num2的数据类型是:<class 'str'>
# num3的数据类型是:<class 'str'>
6.运算符
算术运算符
| 运算符 | 描述 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
| // | 整除 |
| % | 取余 |
| ** | 指数(次方) |
算术运算符中和数学中的运算符是差不多的,但是有一点需要注意: / 这个运算符,在其它语言中例如C/Java 中 这个 / 是整数的意思,但是在python中不一样,python中的这个 / 和数学上的是一样的,例如 5/2在python中的结果就是 2.5 得到的结果是一个浮点数
赋值运算符
赋值运算符就是 “=” 就是将一个数据赋值给另一个变量
其中,还有一些复合赋值运算符
| 运算符 | 实例 |
|---|---|
| += | b+=a 等价于 b=b+a |
| -= | b-=a 等价于 b=b-a |
| *= | b*=a 等价于 b=b*a |
| /= | b/=a 等价于 b=b/a |
| %= | b%=a 等价于 b=b%a |
| **= | b**=a 等价于 b=b**a |
| //= | b//=a 等价于 b=b//a |
布尔类型和比较运算符
布尔类型用于表示 真和假
比较运算符用于计算 真和假
其实布尔类型属于数字类型,但取值只有两个:True(真)和False(假) 在数字中对应的就是1和0
下面来看比较运算符 其实很好理解,看一下代码及输出结果:
ret1 = 1 < 2
ret2 = 1 > 2
print(ret1)
print(ret2)
print(f"ret1的类型是: {type(ret1)}")
print(f"ret2的类型是: {type(ret2)}")
# 输出结果:
# True
# False
# ret1的类型是: <class 'bool'>
# ret2的类型是: <class 'bool'>
这个类似与数学中判断命题真假,真就是True 假就是False
比较运算符有以下这些:
| 运算符 | 描述 |
|---|---|
| == | 判断内容是否相等 |
| != | 判断内容是否不相等 |
| > | 判断大于号左边的值是否大于右边 |
| < | 判断小于号左边的值是否小于右边 |
| >= | 判断大于号左边的值是否大于等于右边 |
| <= | 判断小于号左边的值是否小于等于右边 |
注: 满足就返回True,反之则返回False
7.条件语句
布尔类型和比较运算符学习条件语句的基础
if语句
# 语法格式:
if 判断条件:如果为True,执行代码
先看代码:
a = 5
b = 7
print(f"a = {a}")
print(f"b = {b}")
if a < b:print("5 < 7")print("5 < 7为True,所以输出")if a > b:print("5 > 7")print("5 > 7为False,所以不输出")print("不受条件控制的影响")
# 输出结果
# a = 5
# b = 7
# 5 < 7
# 5 < 7为True,所以输出
# 不受条件控制的影响
其实语法格式很简单,但是有一些点需要注意:
- 判断条件的结果必须为True或者False
- Python中有着严格的缩进,if语句与if语句为真时要执行的代码是不对齐的,if语句为真要执行的代码前面有着4个空格
- if语句中可以写多条语句,但是只有在条件为True时 才会执行
- 不要忘记判断条件后面的 “冒号”
if else语句
# 语法格式
if 判断语句:执行语句
else:执行语句
先看代码:
a = 5
b = 7
if a < b:print("a < b")
if a >= b:print("a >= b")if a < b:print("a < b")
else:print("a >= b")
# 输出结果
# a < b
# a < b
- else 不需要条件判断语句,只要if条件不满足就回去执行else里面的语句
- else 的代码块也要进行缩进
if elif else语句
学习过其它编程语言的同学,应该知道判断语句应该是 if else if和else,elif其实就是else if的缩写,但是在python中没有else if
语法格式如下:
if 判断条件:条件满足执行代码
elif 判断条件:条件满足执行代码
elif 判断条件:条件满足执行代码
...
else:条件满足执行代码 # 这里的条件满足 是指else上面的判断语句均不满足
- elif 可以写多个
- 判断条件时是依次执行的,只要有一个条件满足 后面的就不会执行
- 注意缩进
来看个案例:
val = int(input("请输入成绩: "))
if val < 60:print("成绩评定为: 不及格")
elif val < 70: print("成绩评定为: 及格")
elif val < 85:print("成绩评定为: 良好")
else:print("成绩评定为: 优秀")# 输出结果:
# 请输入成绩: 80
# 成绩评定为: 良好
注意: 上面的 val < 70 其实可以理解为 60 <= val <= 70 因为如果val < 60的话就直接 输出:成绩评定为: 不及格 也不会去对后面的条件进行判断了 能进行 val < 70这个条件判断 说明val一定是大于等于60的. val<85同上
还可以将input语句直接写在判断条件中,但是不建议这样写,可读性变差了
判断语句的嵌套
判断语句是可以嵌套的,比如在一个if else语句中再塞一个if elif else语句也都是没问题的.不过最好不要嵌套太多的条件判断语句,可读性不好. 尽量还是要追求简洁
8.循环
循环在我们平时生活中也是很常见的,例如:音乐的轮播,循环广告牌等
while循环
# 语法:
while 条件:条件为真,执行代码只要条件满足,代码就会无限去执行...
条件为假,退出循环
循环语句首先会对条件进行判断,如果条件为真,就会执行while语句中的代码,每次执行完就会重新判断条件是否为真(True),如果为真就继续为真,如果为假(False)退出循环- 设置好循环条件,如果条件一直为真,就会一直执行while里面的代码,不会退出循环
- 注意缩进
示例:
# 循环输出1~100之间的所有奇数
i = 1
while i < 100:print(i)i += 2
# 输出结果:
# 1
# 3
# ...
# 97
# 99
在i自增到101的时候,不满足条件 i < 99 了,因此退出循环,程序结束
因此,如果在代码的最后加一个输出i的值的语句,输出的结果就是101
循环语句的嵌套
循环语句和条件判断语句一样,可以嵌套
接下来通过示例打印九九惩罚口诀表讲解如何嵌套
# 打印九九乘法口诀表
i = 1
while i < 10:j = iwhile j < 10:print(f"{i} * {j} = {i*j}")j += 1i += 1
注意:
- 这里的i=j 和 j+=1都是在循环1里的,而不是循环2
- 循环1控制i从1到9
- 循环2控制j从i到9
for循环
python中的for循环和其它语言中的for循环还不太一样,虽然和while循环功能是差不多的,但还有一些区别:
- while循环的循环条件是可以自定义的
- for循环一种"轮询"机制,对一批内容追个处理
# 语法
for 临时变量 in 临时处理数据集:条件为真时执行代码
条件为假退出循环
示例:
str1 = "python"
for ch in str1:# 使用ch这个临时变量,逐个取出str1中的每一个字符print(ch)
# 输出:
# p
# y
# t
# h
# o
# n
for循环无法定义循环条件,只能逐个去除数据进行处理- 注意缩进问题
range语句
# 语法:
range(num)
# 获取一个从0开始,到num(不包括num)结束的数字序列range(num1,num2)
# 获得一个从num1开始到num2(不包括num2)的数字序列range(num1,num2,step)
# 获得一个从num1开始到num2(不包括num2)的数字序列
# 但是每个数字之间的步长为step
示例1:
for x in range(3):print(x)
# 输出结果:
# 0
# 1
# 2
示例2:
for x in range(2,5):print(x)
# 输出结果:
# 2
# 3
# 4
示例3:
for x in range(1,10,3):print(x)
# 输出结果:
# 1
# 4
# 7
特别提醒:如果要用区间的话,在计算机中基本上都是左闭右开的区间,这一点需要注意
continue和break
continue的作用:中断本次循环,直接进入下一次循环
continue用于:for循环和while循环,效果时相同的
示例:
# 输出0~9之间的所有奇数
for x in range(10):if x % 2 == 0:continueprint(x)
# 输出结果:
# 1
# 3
# 5
# 7
# 9
用x对2取余,如果等于0说明是偶数,就中断本次循环,直接进入下一个循环,以此来达到输出0~9之间的所有奇数的效果
9.函数
函数是什么
函数是 组织好的,可重复使用的具有某种功能的特定代码段
使用函数的好处:
- 将功能封装好在函数内,可随时且重复的去调用
- 提高代码的复用性,提高效率
函数的定义与调用
# 函数定义的语法
def 函数名(形参..):函数体 # 也就是函数要实现的功能return 返回值# 函数的调用
函数名()
# 如果有参数要传参
# 如果有返回值可以用变量进行接受返回值
参数和返回值可以省略- 函数必须先定义再使用
示例:
def func():print("hello python")func()
# 输出结果:
# hello python
函数的传入参数
刚才介绍了函数没有参数的情况,现在说一下有参数的情况
示例:
def add(x, y):print(f"{x}+{y}={x+y}")add(2, 5)
函数定义时的参数叫形式参数(形参),参数之间要使用逗号隔开函数调用时传的2和5这种的叫实际参数(实参),也就是函数调用时真正使用的参数,按照顺序进行传入参数,参数之间使用逗号隔开- 形参的数量是没有限制的
函数的返回值
之前的求两数之和的示例是直接输出的,没有返回值.
如果我想要得到两个之和就要使用函数的返回值了
# 使用方法:
def 函数名(形参..):函数体 # 也就是函数要实现的功能return 返回值变量 = 函数名(形参..)
示例:
def add(x, y):return x + yret = add(2, 3)
print(ret)
# 输出:
# 5
函数在执行完return语句后,如果后面还有语句的话,那么后面是不会执行的
None类型
如果函数没有写return语句,那么函数的返回值就是None
None就是空的,没有意义的意思
示例:
def func():print("hello python")ret = func()
print(f"无返回值的函数,返回的值为:{ret}")
print(f"无返回值的的函数,返回值的数据类型为:{type(ret)}")
# 输出结果
# hello python
# 无返回值的函数,返回的值为:None
# 无返回值的的函数,返回值的数据类型为:<class 'NoneType'>
函数的嵌套调用
函数也是可以嵌套调用的,就是在一个函数中调用另外一个函数
示例:
def fun2():print(2)def func1():print(1)fun2()func1()
# 输出结果:
# 1
# 2
变量在函数中的作用域
变量主要分为两类:全局变量和局部变量
局部变量是 在函数体内部定义一个变量,这个变量
只在函数体内部生效
局部变量的作用:用于保存变量,代码执行完后临时变量就销毁了
示例:
def func():num = 12print(num)print(num)
# 这么写会报错
# 因此num的作用域只在函数体内部
全局变量是 在函数体内外都能生效的变量,定义在函数外即可
示例2:
num = 1
def func1():print(num)def func2():num = 12print(num)func1()
func2()
print(num)
# 输出结果:
# 1
# 12
# 1
局部变量的优先级大于全局变量
因为fun2里的num是局部变量,局部优先,因此会输出12,而且不会改变外面全局变量num的值
如果要在函数体内部改变全局变量的值,则需要使用global关键字
示例:
num = 1
def func():global numnum = 12print(num)func()
print(num)
# 输出结果:
# 12
# 12
global关键字的作用:将函数内部声明的变量变为全局变量
10.列表(list)
列表是python中内置的
可变序列,是包含若干元素的有序连续内存空间
所有的元素存放在 [] 中
元素之间用逗号隔开
列表的定义
列表的定义有两种方式:
使用字面值创建列表使用list()创建列表
实例:
# 使用使用字面值创建列表
# []就代表一个空列别
a = []
print(type(a))# 使用list()创建列表
b = list()
print(type(b))# 输出的结果为:
# <class 'list'>
# <class 'list'>
列表可以在定义时进行初始化,但与C/Java等里面的数组不同的是,数组只能放同一类型的变量,例如整型数组就只能放整数类型的元素,而列表不同,列表可以存放不同数据类型的元素
示例:
a = [1,2,3]
print(a)
# 输出[1, 2, 3]b = list((1,2,3))
print(b)
# 输出[1, 2, 3]c = [1,1.2,"ads",False,[1,2,3]];#也可以存放列表的数据
print(c)
# 输出[1, 1.2, 'ads', False, [1, 2, 3]]
列表的下标访问
对列表的元素,可以通过 列表名[下标] 这种形式进行访问
注意:这里的下标都是从0开始的 ,下标的有效范围是0到列表长度-1
如果超出下标的有效范围,那么就会出现异常
列表的长度可以直接使用内置函数len(列表名)获取
len()不止能求列表的长度,也可以求字符串、元组、字典等这个类型的长度
# 下标的范围[0,2]
a = [1,2,3]
print(len(a))
# 输出结果:3
print(a[1]) #对列表的元素进行访问
# 输出结果:2
a[2] = 5 #对列表的元素进行修改
print(a)
# 输出结果:[1, 2, 5]
python中的下标也可以写成负数的形式
a = [1,2,3]
print(a[len(a)-1])
# 输出结果:3
print(a[-1])
# 输出结果:3
对于这里面的-1可以理解为len(列表名)-1把len(列表名)这个给省略了,也可以理解为是倒数第一个元素,只要能记住,大家怎么理解都行
如果是用负数表示下标,那么下标的有效范围就是[-len(列表名),-1]
嵌套列表的下标
在讲列表定义的时候说过列表的元素类型不限制,当然也就可以在列表中存放列表
示例:
a = [[1, 2, 3], [4, 5, 6]]
对于这种列表里面是嵌套的列表,也是支持下标索引的
例如:
a = [[1, 2, 3], [4, 5, 6]]
print(a[0][1])
# 输出结果:
# 2
上面的代码可以分成两步进行理解:
- 可以把[1,2,3]和[4,5,6]看出是a列表中的两个元素,a[0]就是得到[1,2,3]这个列表
- a[0][1]就相当于访问了[1,2,3]这个列表的第二个元素,所以输出结果为2
列表的常用方法
以下是列表中一些常用的内置函数:
| 方法 | 说明 |
|---|---|
| 列表名.append(x) | 将元素x添加到列表的最后位置 |
| 列表名.extend(L) | 将列表L中的所有元素添加到列表的尾部 |
| 列表名.insert(index,x) | 在列表的index位置插入元素x |
| 列表名.remove(x) | 在列表中删除首次出现的元素x |
| 列表名.pop([index]) | 删除并返回列表对象的指定位置的元素,默认为最后一个元素 |
| 列表名.clear() | 删除列表中所有元素,但保留列表对象 |
| 列表名.index(x) | 返回第一个值为x的元素下标,做不存在x,则抛出异常 |
| 列表名.count(x) | 返回指定元素x在列表中的个数 |
| 列表名.reverse() | 对列表元素进行原地翻转 |
| 列表名.sort(key=None,reverse=False) | 对列表元素进行原地排序 |
| 列表名.copy() | 对列表元素进行浅拷贝 |
| len(列表名) | 统计列表中元素的个数 |
11.元组(tuple)
元组和列表一样可以存放多个,不同数据类型的元素
与列表最大的不同就是:列表是可变的,而元组不可变
元组的定义
元组的定义: 使用()定义元组,元素之间使用逗号隔开
a = (1, 2, True, "python")
b = ((1, 2, 3), (4, 5, 6))
元组也是可以嵌套的
如果想要定义空元组,也可以使用关键字tuple进行定义
示例:
a = ()
b = tuple()
print(a)
print(type(a))
print(b)
print(type(b))# 输出结果:
# ()
# <class 'tuple'>
# ()
# <class 'tuple'>
如果用tuple 定义元组,实际上是得到了元组的类对象
定义只有一个元素的元组
如果要定义只有一个元素的元组,需要在元素的后面加一个 "逗号"
示例:
str1 = ("python")
print(type(str1))str2 = ("python",)
print(type(str2))# 输出结果:
# <class 'str'>
# <class 'tuple'>
一定不能省略逗号,如果省略,就不是元组了
元组的下标访问
其实元组的下标访问和列表是一样的,掌握了列表的下标访问,那元组也就不在话下了
元组的常用方法
| 方法 | 描述 |
|---|---|
| 元组名.index(x) | 查询x在元组中的下标,如果存在返回下标,否则会报错 |
| 元组名.count(x) | 统计x在元组中出现的次数 |
| len(元组名) | 返回元组的元素个数 |
12.再识字符串(str)
虽然之前介绍了字符串,但是是以数据类型的角度来介绍字符串的,而现在要以数据容器的视角来看字符串
字符串是字符的容器,可以存放任意多个字符
字符串的下标索引
字符串也可以通过下标进行访问里面的字符
从前往后,下标从0开始从后往前,下标从-1开始
示例:
str1 = "python"
print(f"2下标的字符是: {str1[2]}")
print(f"-2下标的字符是: {str1[-2]}")# 输出结果:
# 2下标的字符是: t
# -2下标的字符是: o
字符串和元组一样,是无法修改的数据容器
如果想要通过下标进行修改特定的字符,编译器则会报错
字符串的常用方法
| 方法 | 描述 |
|---|---|
| 字符串.index(要查找字符串) | 查找特定字符串的下标索引 |
| 字符串.replace(字符串1,字符串2) | 将全部的字符串1都替换为字符串2,但不会修改原本的字符串,而是得到一个新字符串 |
| 字符串.split(分割符字符串) | 按照指定分隔符字符串,将字符串分成多个字符串,并存在列表中,字符串本身不变,而是得到一个新的列表对象 |
| 字符串.strip(字符串) | ()里字符串可以传也可以不传,不传参就是去除前后空格,传参则去除前后指定字符串,这里依旧不修改字符串本身,而是得到一个新的字符串 |
| 字符串.count(字符串) | 统计某个字符串在字符串中出现的次数 |
| len(字符串) | 得到字符串的长度 |
13.集合(set)
集合是一种
无序可变的容器对象
集合最大的特点:同一个集合内元素是不允许有重复的
集合的定义
集合的定义使用 {} ,但{}不能用于定义空集合!!! 可以使用set()定义一个空集合
元素之间用逗号隔开
a = set()
# 自动去重
b = {1,"python",2.3,1,"python",2.3,1,"python",2.3,"python"}
print(type(a))
print(b)
print(type(b))# 输出结果:
# <class 'set'>
# {1, 2.3, 'python'}
# <class 'set'>
集合是不支持下标索引访问
集合的常用方法
| 方法 | 描述 |
|---|---|
| 集合.add(元素) | 集合内添加一个元素 |
| 集合.remove(元素) | 删除集合内指定的元素 |
| 集合.pop() | 从集合内随机取出一个元素 |
| 集合.clear() | 清除集合 |
| 集合1.difference(集合2) | 得到一个新的集合,包含两个集合的差集,原集合不变 |
| 集合1.difference_update(集合2) | 从集合1中删除集合2中存在的元素,集合1改变,集合2不变 |
| 集合1.union(集合2) | 得到一个新的集合,内含两个集合的所有元素,原集合不变 |
| len(集合) | 统计集合中(去重后)元素的个数 |
14.字典(dict)
字典的定义
字典的定义也是使用 {} 定义空字典也可以使用dict()
不过字典元素的类型则需要是 键值对(key : value)
key和value可以是任意类型的,但是key不能是字典
字典中不允许key重复
a = {}
b = dict()
c = {"张三":95, "李四":89,"王五":97}
print(type(a))
print(type(b))
print(c)
print(type(c))# 输出结果:
# <class 'dict'>
# <class 'dict'>
# {'张三': 95, '李四': 89, '王五': 97}
# <class 'dict'>
键和值之间用 : 分割
每个键值对之间用逗号分割
字典不支持下标索引访问元素,但是可以通过Key值找到对应的Value值
# 语法:
字典名[Key]
使用起来和下标索引访问是差不多的
示例:
a = {"张三":95, "李四":89,"王五":97}
print(a["张三"])# 输出结果:
# 95
字典的常用方法
| 方法 | 描述 |
|---|---|
| 字典[Key] = Value | 如果Key存在,就是修改元素. 如果不存在,就相当于新增一个元素 |
| 字典.pop(Key) | 取出对应的Value,同时删除Key和Value |
| 字典.clear() | 清空字典 |
| 字典.keys() | 取出字典中所有的Key,一般用于for循环遍历字典 |
| len(字典) | 统计字典中元素的个数 |
15.文件操作
文件操作就太好用代码进行演示,因此每个人的电脑里的文件都是不一样的,所有就没怎么有示例了. 见谅!
文件主要有三个操作:打开文件,读写文件和关闭文件
文件编码
编码(coding)是指用代码来表示各组数据资料,使其成为可利用计算机进行处理和分析的信息。
文件的编码有很多,例如:GBK,Unicode,UTF-8等等
其中UTF-8是我们最常用的,UTF-8也被称为万国码,只要没有特殊要求都可以设置成UTF-8编码
文件的打开
python中,使用open()函数,可以打开一个文件或者创建一个新文件
# open函数的介绍:
f = open(name,mode,encoding)
name:就是要打开文件的文件名(也可以是文件所在的具体路径)mode:设置文件的访问模式:读取,写入,追加encoding:编码格式(推荐使用UTF-8)f是一个文件对象
mode的三种访问模式:
| 模式 | 描述 |
|---|---|
| r | 以只读的方式打开文件 |
| w | 对文件进行写入,如果文件存在,则会把原来的内容全部删掉,从头编辑,如果文件不存在,则会创建一个新文件 |
| a | 对文件进行追加,如果文件存在,则会在原内容后面追加新的内容,如果不存在,则会创建新文件并追加内容 |
open()函数中encoding的不是第三位,不能直接传参数,而是要用encoding="编码格式"
示例:
open("文件名", "访问模式", encoding="UTF-8")
注意上面的encoding
文件的读取
文件读取相关的方法有三个:
| 方法 | 描述 |
|---|---|
| 文件对象.read(num) | num表示要从文中取出的数据长度(单位是字节),如果没有传入num,就会读文件中的所有数据 |
| 文件对象.readlines() | 按照行的方式对整个文件内容进行一次性读取数据,并返回一个列表,每一行的数据为一个元素 |
| 文件对象.readline() | 每次只读取一行的数据 |
注意:在读取文件的时候会有一个文件指针记录读取的位置,下一次读就会从文件指针的地方开始读
例如:如果调用read()来读取文件,但没有把文件读完,在调用一次read()方法,那么会从上一次read()最后一读到的地方开始读取
除了上述的三种方法,也可以使用for循环来读取文件
# 使用方法:
# f是文件对象
for line in f:print(line)
文件的关闭
关闭文件可以使用
文件对象.close()方法
如果不关闭文件,程序不会停止,那么这个文件就会一直被编译器占用
为了避免忘记关闭文件,我们就可以使用with open这种写法
with open()
# 语法:
# f是文件对象
with open(name,mode) as f:进行文件操作
这种写法可以自动帮我们关闭文件
文件的写入
文件写入有三个步骤:1.打开文件 2.调用文件对象的write()方法 3.调用文件对象的flush()方法
示例:
# 1.打开文件 mode记得设置为"w"(写入)
f = open("文件名", "w", encoding="UTF-8")
# 2.调用文件对象的write()方法
f.write("hello python")
# 3.刷新缓冲区
f.flush()
注意:
调用write()方法,内容不会直接写到文件中,而是会先存储在缓冲区中调用flush()方法后,刷新缓冲区之后,文件才会真正写到文件中close()方法中是内置了flush()功能的,不调用flush()方法而调用close()方法也是可以将内容写入文件的write()方法写文件时,若文件存在,会将原文件中的内容给删掉,再写入内容.如果不存在,则会创建新文件并写入内容
文件的追加
文件的追加和上面的文件写入差不多,只需要将mode值改成"a"即可
"a"模式下,若文件不存在会创建文件,若文件存在,则会再原文件内容的后面追加新内容- 文件追加,依旧
要进行flush()操作
16.异常处理
异常:即便 Python 程序的语法是正确的,在运行它的时候,也有可能发生错误。运行期检测到的错误被称为异常。也就是我们常说的BUG
异常的捕获
如果程序有异常会有两种情况:
程序遇到异常终止运行对BUG进行提醒,程序继续运行
通常情况遇到BUG时都是第一种情况,但如果我们对异常进行捕获,就会出现第二种情况
捕获异常的作用:提前假设某处会出现异常,提前做好准备,当程序出现异常时,就可以提前做好准备
# 语法:
try:可能会出现异常的代码
except:出现异常后执行的代码
示例:
a = [1,2,3]
try:print(f"列表的第一个元素:{a(0)}")
except:print("列表使用[]来进行下标访问!")print(f"列表的第一个元素:{a[0]}")
# 输出结果:
# 列表使用[]来进行下标访问!
# 列表的第一个元素:1
上述代码我们可知:因为事先对try里面的代码进行处理了,try里面的代码出现异常时,try里面的代码没有被执行,而是直接去执行except里面的代码了,这就是异常的捕获
除了这种捕获异常外,我们还可以捕获指定的异常
捕获指定的异常
# 语法:
try:可能出现异常的代码
except 异常类型 as e:出现异常时执行的代码
try:print(a)
except NameError as e:print("变量未定义!")print(e)# 输出结果:
# 变量未定义!
# name 'a' is not defined
上述代码也只能变量未定义这个指定的异常,如果出现了别的异常,程序依旧会终止运行
捕获多个异常
捕获除了可以捕获指定的异常,还可以捕获多个异常
# 语法
try:可能出现异常的代码
except (异常1,异常2,...) as e:出现异常时执行的代码
示例:
b = [1,2,3]
try:print(b[5])print(a)
except (NameError,IndexError) as e:print("变量未定义 或者 下标索引错误")print(e)
捕获全部的异常
捕获全部的异常的异常方法有两个:
# 方法1:
try:可能出现异常的代码
except:出现异常时执行的代码
# 方法2:
try:可能出现异常的代码
except Exception as e:出现异常时执行的代码
Exception 是所有异常类的父类
else和finally
else 是程序没出现时执行的代码
示例1:
a = [1,2,3]
try:print(a[0])
except:print("出现异常了")
else:print("没有出现异常")
# 输出结果:
# 1
# 没有出现异常
示例2:
a = [1,2,3]
try:print(a[5])
except:print("出现异常了")
else:print("没有出现异常")
# 输出结果:
# 出现异常了
finally 里面的语句不管程序有没有异常都会执行
示例1(出有异常的情况):
a = [1,2,3]
try:print(a[5])
except:print("出现异常了")
else:print("没有出现异常")
finally:print("finally 里的语句一定会被执行")
# 输出结果:
# 出现异常了
# finally 里的语句一定会被执行
示例2(无异常的情况):
a = [1,2,3]
try:print(a[1])
except:print("出现异常了")
else:print("没有出现异常")
finally:print("finally 里的语句一定会被执行")
# 输出结果:
# 2
# 没有出现异常
# finally 里的语句一定会被执行
else和finally再捕获异常时可以写也可以不写
异常的传递性
异常是具有传递性的,这句话有点抽象,看下面这段代码:
def func1():a = [1,2,3]print(a[10])
def func2():func1()try:func2()
except Exception as e:print(e)
# 输出结果:
# list index out of range
这里程序出现异常了,虽然是func2()里出的问题,但func2()里面是调用的func1()函数,func1()中的打印下标索引越界了.但依旧被捕获到了.
异常从func1函数传递到了func2,然后被捕获到了,这就是异常的传递性
17.结语
这篇文章也是写了好久,因为是复习用的,有些地方其实讲的不那么仔细,如果有意见也可以提出,后面我也会不断对本文进行改进的
如果有需要,后面也可以单独写文章对某些知识点做更细致的讲解
文章比较长,可能有些地方写的不是很好,还请见谅!
感谢你的观看! 希望这篇文章能帮到你!
相关文章:

【python】考前复习,python基础语法知识点整理
文章目录1.常量与表达式2.变量和数据类型创建变量数据类型动态类型数据类型的转换3.注释4.字符串字符串的定义方式字符串的拼接字符串的格式化①字符串格式化的精度控制字符串的格式化②对表达式进行格式化5.从控制台输入(input)6.运算符算术运算符赋值运算符布尔类型和比较运算…...

3个月,入门网络安全并找到工作
在我进入大学之前,我一直对计算机感兴趣。虽然只是考了一个一般大学,但是选专业的时候还是选了计算机专业。 本来以为自己会在大学里学到很多有用的知识,并且能够很快找到一份好工作。但是,事实并不是这样。在大学期间,…...

你会用 TypeScript 的条件类型吗?
我们可以使用 TypeScript 中的条件类型来根据逻辑定义某些类型,就像是在编写代码那样。它采用的语法和我们在 JavaScript 中熟悉的三元运算符很像:condition ? ifConditionTrue : ifConditionFalse。我们来看看他是怎么工作的。 TypeScript 的条件类型…...

云原生丨一文教你基于Debezium与Kafka构建数据同步迁移(建议收藏)
文章目录前言一、安装部署Debezium架构部署示意图安装部署二、数据迁移Postgres迁移到PostgresMySQL迁移到PostgresSQL前言 在项目中,我们遇到已有数据库现存有大量数据,但需要将全部现存数据同步迁移到新的数据库中,我们应该如何处理呢&…...
顶象APP加固的“蜜罐”技术有什么作用
目录 蜜罐有很多应用模式 蜜罐技术让App加固攻守兼备 顶象端加固的三大功能 为了捕获猎物,猎人会在设置鲜活的诱饵。被诱惑的猎物去吃诱饵时,就会坠入猎人布置好的陷阱,然后被猎人擒获,这是狩猎中常用的一种手段。在业务安全防…...

训练一个ChatGPT需要多少数据?
“风很大”的ChatGPT正在席卷全球。作为OpenAI在去年底才刚刚推出的机器人对话模型,ChatGPT在内容创作、客服机器人、游戏、社交等领域的落地应用正在被广泛看好。这也为与之相关的算力、数据标注、自然语言处理等技术开发带来了新的动力。自OpenAI发布ChatGPT以来&…...

【GlobalMapper精品教程】053:打开dbf文件并生成有坐标系的shp数据
本文讲解在globalmapper汇总打开dbf文件并生成有坐标系的shp数据。 文章目录一、dbf文件解读二、打开dbf文件二、另存为shp文件一、dbf文件解读 我们可以通过Excel或FME等多种软件查看dbf的结构,字段有:Name,kind,Lat,…...

图像亮度调整
非线性方式 调整图像的方法有很多,最常用的方法就是对图像像素点的R、G、B三个分量同时进行增加(减少)某个值,达到调整亮度的目的。即改变图像的亮度,实际就是对像素点的各颜色分量值做一个平移。这种方法属于非线性的…...
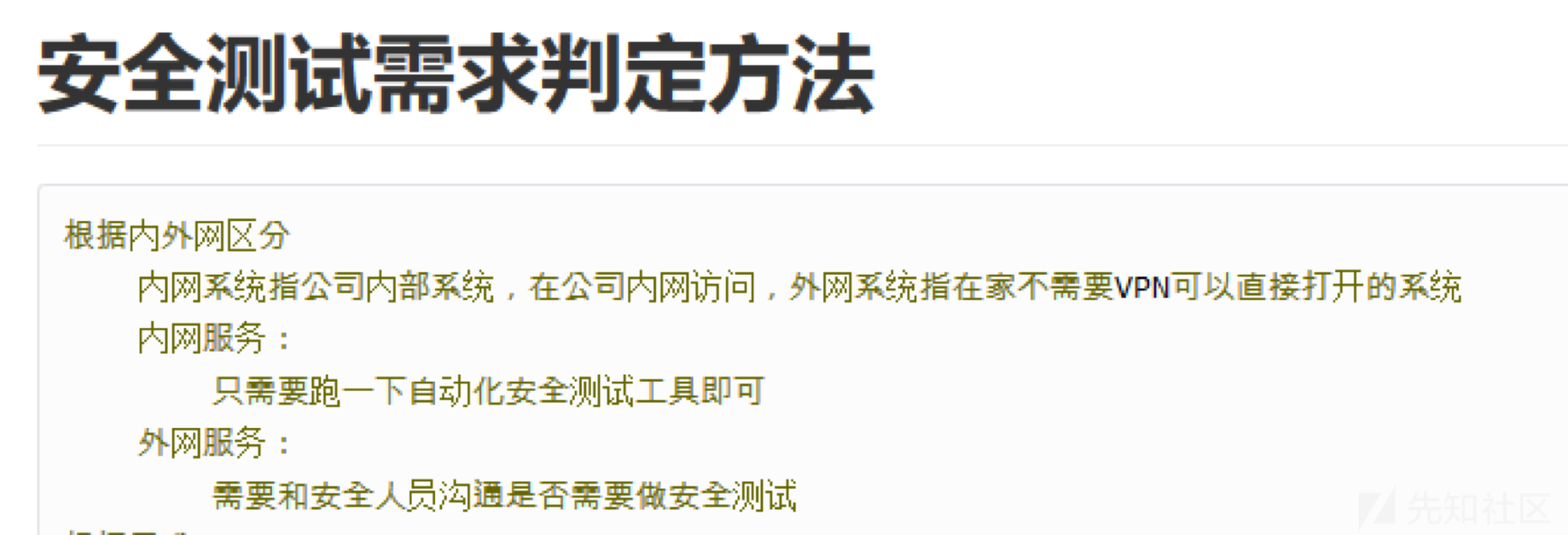
精简版SDL落地实践
一、前言一般安全都属于运维部下面,和上家公司的运维总监聊过几次一些日常安全工作能不能融入到DevOps中,没多久因为各种原因离职。18年入职5月一家第三方支付公司,前半年在各种检查中度过,监管形势严峻加上大领导对安全的重视(主…...
第一回:Matplotlib初相识
一、认识matplotlib Matplotlib是一个Python 2D绘图库,能够以多种硬拷贝格式和跨平台的交互式环境生成出版物质量的图形,用来绘制各种静态,动态,交互式的图表。 Matplotlib可用于Python脚本,Python和IPython Shell、…...

怎么找回电脑删除的图片
怎么找回电脑删除的图片?图片作为一种非常简单方便的文件,经常被用来辅助我们的日常工作和学习。但在我们整理电脑时,如果我们不小心手一抖就删除了一些重要的图片,遇到这种事我们要如何才能恢复呢? 众所周知,简单的删除并不会完…...

【Linux】进程状态与进程优先级
目录一.进程状态1.阻塞:2.挂起:具体情况3.具体操作系统状态变化R:运行状态(running)S:休眠状态(sleeping)D:磁盘休眠状态(Disk sleep)T:暂停状态(stopped)暂停进程继续进程t:追踪暂停状态(traci…...

Python+Qt生日提醒
PythonQt生日提醒如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助!前言这篇博客针对<<PythonQt生日提醒>>编写代码,代码整洁,规则,易读。 学习与应用推荐首选。文章目…...
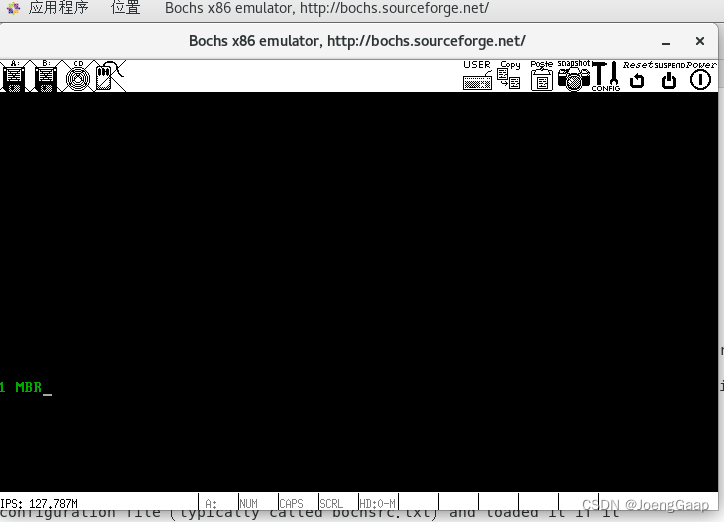
第二章 编写MBR主引导记录
主引导记录(MBR,Master Boot Record)是采用MBR分区表的硬盘的第一个扇区,即C/H/S地址的0柱面0磁头1扇区,也叫做MBR扇区 计算机的启动过程 为什么程序要载入内存 CPU的硬件电路被设计成只能运行处于内存中的程序&…...
Android 9.0 仿ios的hotseat效果修改hotseat样式
1.概述 在9.0的系统rom定制化的产品中,在launcher3的定制化需求中,有很多功能需求点需要开发,在对一下ui的定制化的过程中,会参考ios的样式进行定制化,所以最近项目需求 要求仿ios的hotseat的样式来进行产品的定制,开发一款仿ios的hotseat,所以需要对hotseat进行分析,然…...

量化私募投资百亿头部量化私募企业在招岗位:AI算法工程师21/22/23届,校招/秋招/社招都看年base60-200万
量化私募投资百亿头部量化私募企业在招岗位:AI算法工程师21/22/23届,校招/秋招/社招都看年base60-200万bonuscut965制度应届需要985本硕博有3年以上相关ai算法经验可放宽学历"岗位职责:base 北京 上海 杭州 深圳1. 利用机器学习、深度学习和人工智能…...

百度西交大大数据菁英班目标检测竞赛
来源:投稿 作者:LSC 编辑:学姐 数据介绍 数据集共包括40000张训练图像和1000张测试图像,每张训练图像对应xml标注文件: 共包含3类:0:head, 1:helmet, 2:person。 提交格式要求,提交名为pred_r…...
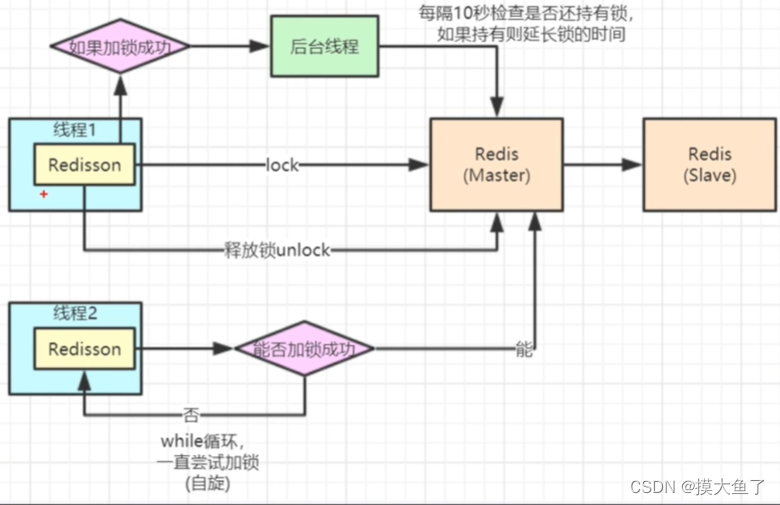
Redisson实现分布式锁
目录Redisson简介Redisson实现分布式锁步骤引入依赖application.ymlRedisson 配置类Redisson分布式锁实现Redisson简介 Redis 是最流行的 NoSQL 数据库解决方案之一,而 Java 是世界上最流行(注意,没有说“最好”)的编程语言之一。…...

【HID基础知识】
蓝牙HID基础知识 一:定义 HID是Human Interface Device的缩写,由其名称可以了解HID设备是直接与人交互的设备,例如键盘、鼠标与游戏手柄等。 蓝牙HID 是属于蓝牙协议里面的一个profile, 不管在蓝牙2.0 2.1 3.0还是4.0,5.0的蓝牙中…...

工赋开发者社区 | 工业数字孪生:西门子工业网络与设备虚拟调试案例(TIA+MCD+SINETPLAN)
PART1案例背景及基本情况新生产系统的设计和实施通常是耗时且高成本的过程,完成设计、采购、安装后,在移交生产运行之前还需要一个阶段,即调试阶段。如果在开发过程中的任何地方出现了错误而没有被发现,那么每个开发阶段的错误成本…...

Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 [特殊字符]
Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 🚀 【免费下载链接】spring-cloud-aws The New Home for Spring Cloud AWS 项目地址: https://gitcode.com/gh_mirrors/sp/spring-cloud-aws Spring Cloud AWS 是一个强大的开源框架&…...

64_《智能体微服务架构企业级实战教程》授权与认证之授权认证集成测试
前言 配套视频教程: 在 Bilibili课堂、CSDN课程、51CTO学堂 同步发售,提供:源码+部署脚本+文档。 bilibili课堂视频教程:智能体微服务架构企业级实战教程_哔哩哔哩_bilibili CSDN课程视频教程:智能体微服务架构企业级实战教程_在线视频教程-CSDN程序员研修院 51CTO学堂…...

③ AI副业第一步:如何找到适合自己的AI赚钱赛道
③ AI副业第一步:如何找到适合自己的AI赚钱赛道选对赛道,努力才有意义。选错赛道,越努力离钱越远。前言:为什么大多数人AI副业做不起来? 我观察了100想做AI副业的人,失败的原因高度一致: 失败路…...

本地柴油发电机组排行2023年最新榜单
柴油发电机是通过燃烧柴油驱动发动机,进而发电的设备,广泛应用于电力中断或无电网地区。1. 柴油发电机的核心工作原理是什么?柴油发电机是一种将化学能转化为电能的设备,其核心是柴油发动机与交流发电机的组合。当柴油在发动机内燃…...

浏览器 Profile 环境排查:Cookie、LocalStorage、网络出口与自动化任务配置清单
一、为什么浏览器环境经常“今天能用,明天失效”很多团队遇到登录状态丢失、页面配置异常、自动化任务失败时,会先怀疑网络、脚本或系统本身。但在实际项目里,问题经常不是单点故障,而是浏览器环境缺少稳定管理:对象常…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...

智慧树自动刷课助手:3步告别手动操作的学习效率工具
智慧树自动刷课助手:3步告别手动操作的学习效率工具 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的重复刷课操作而烦恼吗?智…...

Python UiAutomation实战:从网页数据抓取到桌面应用,一个库打通数据采集全链路
Python UiAutomation实战:打通数据采集全链路的智能解决方案 在数据驱动的商业环境中,企业常常面临跨平台数据采集的挑战——财务系统里的交易记录需要与网站后台的报表进行交叉分析,销售数据要从桌面软件导出后上传到云端处理系统。传统的人…...
)
别再只用鼠标了!用Leap Motion手势控制Unity游戏,保姆级配置避坑指南(2024版)
2024年Unity手势交互开发实战:Leap Motion从配置到游戏逻辑全解析在游戏开发领域,交互方式的创新往往能带来全新的体验。想象一下,玩家不再需要键盘鼠标,仅凭自然的手部动作就能操控游戏角色——这正是Leap Motion手势识别技术为U…...
)
Windows开机自动全屏打开指定网页?一个快捷方式参数就搞定(Chrome/Edge/Firefox教程)
Windows开机自动全屏展示网页的终极方案每次开机都要手动打开浏览器、输入网址、切换全屏模式?这种重复操作不仅浪费时间,还容易在重要演示时手忙脚乱。想象一下:电脑启动后自动全屏显示你的仪表盘、会议日程或是监控大屏,整个过程…...