【深度学习实验】前馈神经网络(九):整合训练、评估、预测过程(Runner)
目录
一、实验介绍
二、实验环境
1. 配置虚拟环境
2. 库版本介绍
三、实验内容
0. 导入必要的工具包
1. __init__(初始化)
2. train(训练)
3. evaluate(评估)
4. predict(预测)
5. save_model
6. load_model
7. 代码整合
一、实验介绍
二、实验环境
本系列实验使用了PyTorch深度学习框架,相关操作如下:
1. 配置虚拟环境
conda create -n DL python=3.7 conda activate DLpip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib conda install scikit-learn2. 库版本介绍
| 软件包 | 本实验版本 | 目前最新版 |
| matplotlib | 3.5.3 | 3.8.0 |
| numpy | 1.21.6 | 1.26.0 |
| python | 3.7.16 | |
| scikit-learn | 0.22.1 | 1.3.0 |
| torch | 1.8.1+cu102 | 2.0.1 |
| torchaudio | 0.8.1 | 2.0.2 |
| torchvision | 0.9.1+cu102 | 0.15.2 |
三、实验内容
ChatGPT:
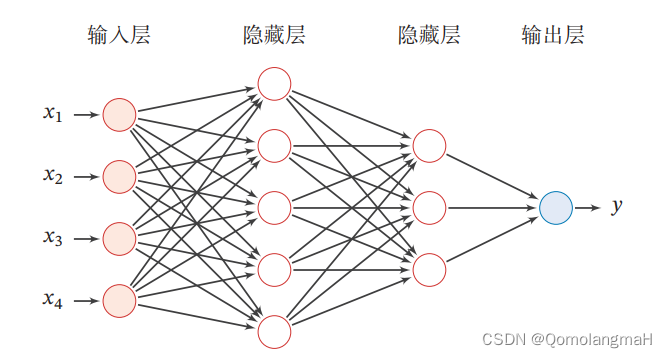
前馈神经网络(Feedforward Neural Network)是一种常见的人工神经网络模型,也被称为多层感知器(Multilayer Perceptron,MLP)。它是一种基于前向传播的模型,主要用于解决分类和回归问题。
前馈神经网络由多个层组成,包括输入层、隐藏层和输出层。它的名称"前馈"源于信号在网络中只能向前流动,即从输入层经过隐藏层最终到达输出层,没有反馈连接。
以下是前馈神经网络的一般工作原理:
输入层:接收原始数据或特征向量作为网络的输入,每个输入被表示为网络的一个神经元。每个神经元将输入加权并通过激活函数进行转换,产生一个输出信号。
隐藏层:前馈神经网络可以包含一个或多个隐藏层,每个隐藏层由多个神经元组成。隐藏层的神经元接收来自上一层的输入,并将加权和经过激活函数转换后的信号传递给下一层。
输出层:最后一个隐藏层的输出被传递到输出层,输出层通常由一个或多个神经元组成。输出层的神经元根据要解决的问题类型(分类或回归)使用适当的激活函数(如Sigmoid、Softmax等)将最终结果输出。
前向传播:信号从输入层通过隐藏层传递到输出层的过程称为前向传播。在前向传播过程中,每个神经元将前一层的输出乘以相应的权重,并将结果传递给下一层。这样的计算通过网络中的每一层逐层进行,直到产生最终的输出。
损失函数和训练:前馈神经网络的训练过程通常涉及定义一个损失函数,用于衡量模型预测输出与真实标签之间的差异。常见的损失函数包括均方误差(Mean Squared Error)和交叉熵(Cross-Entropy)。通过使用反向传播算法(Backpropagation)和优化算法(如梯度下降),网络根据损失函数的梯度进行参数调整,以最小化损失函数的值。
前馈神经网络的优点包括能够处理复杂的非线性关系,适用于各种问题类型,并且能够通过训练来自动学习特征表示。然而,它也存在一些挑战,如容易过拟合、对大规模数据和高维数据的处理较困难等。为了应对这些挑战,一些改进的网络结构和训练技术被提出,如卷积神经网络(Convolutional Neural Networks)和循环神经网络(Recurrent Neural Networks)等。
本系列为实验内容,对理论知识不进行详细阐释
(咳咳,其实是没时间整理,待有缘之时,回来填坑)
0. 导入必要的工具包
import torch
from torch import nn
import torch.nn.functional as F
# 绘画时使用的工具包
import matplotlib.pyplot as plt
# 导入鸢尾花数据集
from sklearn.datasets import load_iris
# 构建自己的数据集,继承自Dataset类
from torch.utils.data import Dataset, DataLoader1. __init__(初始化)
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):self.model = modelself.optimizer = optimizerself.loss_fn = loss_fn# 用于计算评价指标self.metric = metric# 记录训练过程中的评价指标变化self.dev_scores = []# 记录训练过程中的损失变化self.train_epoch_losses = []self.dev_losses = []# 记录全局最优评价指标self.best_score = 0- 五个参数:
- model(模型)
- optimizer(优化器)
- loss_fn(损失函数)
- metric(评价指标)
- 其他可选参数。
- 该类还定义了一些用于记录训练过程中的指标变化和全局最优指标的属性:
- self.dev_scores(记录验证集评价指标的变化)
- self.train_epoch_losses(记录训练集损失的变化)
- self.dev_losses(记录验证集损失的变化)
- self.best_score(记录全局最优评价指标)
2. train(训练)
def train(self, train_loader, dev_loader=None, **kwargs):# 将模型设置为训练模式,此时模型的参数会被更新self.model.train()num_epochs = kwargs.get('num_epochs', 0)log_steps = kwargs.get('log_steps', 100)save_path = kwargs.get('save_path', 'best_mode.pth')eval_steps = kwargs.get('eval_steps', 0)# 运行的step数,不等于epoch数global_step = 0if eval_steps:if dev_loader is None:raise RuntimeError('Error: dev_loader can not be None!')if self.metric is None:raise RuntimeError('Error: Metric can not be None')# 遍历训练的轮数for epoch in range(num_epochs):total_loss = 0# 遍历数据集for step, data in enumerate(train_loader):x, y = datalogits = self.model(x.float())loss = self.loss_fn(logits, y.long())total_loss += lossif log_steps and global_step % log_steps == 0:print(f'loss:{loss.item():.5f}')loss.backward()self.optimizer.step()self.optimizer.zero_grad()# 每隔一定轮次进行一次验证,由eval_steps参数控制,可以采用不同的验证判断条件if (epoch + 1) % eval_steps == 0:dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)print(f'[Evalute] dev score:{dev_score:.5f}, dev loss:{dev_loss:.5f}')if dev_score > self.best_score:self.save_model(f'model_{epoch + 1}.pth')print(f'[Evaluate]best accuracy performance has been updated: {self.best_score:.5f}-->{dev_score:.5f}')self.best_score = dev_score# 验证过程结束后,请记住将模型调回训练模式self.model.train()global_step += 1# 保存当前轮次训练损失的累计值train_loss = (total_loss / len(train_loader)).item()self.train_epoch_losses.append((global_step, train_loss))print('[Train] Train done')3. evaluate(评估)
def evaluate(self, dev_loader, **kwargs):assert self.metric is not None# 将模型设置为验证模式,此模式下,模型的参数不会更新self.model.eval()global_step = kwargs.get('global_step', -1)total_loss = 0self.metric.reset()for batch_id, data in enumerate(dev_loader):x, y = datalogits = self.model(x.float())loss = self.loss_fn(logits, y.long()).item()total_loss += lossself.metric.update(logits, y)dev_loss = (total_loss / len(dev_loader))self.dev_losses.append((global_step, dev_loss))dev_score = self.metric.accumulate()self.dev_scores.append(dev_score)return dev_score, dev_loss4. predict(预测)
predict方法用于模型的阶段,输入数据x,返回模型对输入的预测结果。
def predict(self, x, **kwargs):self.model.eval()logits = self.model(x)return logits5. save_model
def save_model(self, save_path):torch.save(self.model.state_dict(),save_path)6. load_model
def load_model(self, model_path):self.model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))7. 代码整合
class Runner(object):def __init__(self, model, optimizer, loss_fn, metric, **kwargs):self.model = modelself.optimizer = optimizerself.loss_fn = loss_fn# 用于计算评价指标self.metric = metric# 记录训练过程中的评价指标变化self.dev_scores = []# 记录训练过程中的损失变化self.train_epoch_losses = []self.dev_losses = []# 记录全局最优评价指标self.best_score = 0# 模型训练阶段def train(self, train_loader, dev_loader=None, **kwargs):# 将模型设置为训练模式,此时模型的参数会被更新self.model.train()num_epochs = kwargs.get('num_epochs', 0)log_steps = kwargs.get('log_steps', 100)save_path = kwargs.get('save_path','best_mode.pth')eval_steps = kwargs.get('eval_steps', 0)# 运行的step数,不等于epoch数global_step = 0if eval_steps:if dev_loader is None:raise RuntimeError('Error: dev_loader can not be None!')if self.metric is None:raise RuntimeError('Error: Metric can not be None')# 遍历训练的轮数for epoch in range(num_epochs):total_loss = 0# 遍历数据集for step, data in enumerate(train_loader):x, y = datalogits = self.model(x.float())loss = self.loss_fn(logits, y.long())total_loss += lossif log_steps and global_step%log_steps == 0:print(f'loss:{loss.item():.5f}')loss.backward()self.optimizer.step()self.optimizer.zero_grad()# 每隔一定轮次进行一次验证,由eval_steps参数控制,可以采用不同的验证判断条件if (epoch+1)% eval_steps == 0:dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)print(f'[Evalute] dev score:{dev_score:.5f}, dev loss:{dev_loss:.5f}')if dev_score > self.best_score:self.save_model(f'model_{epoch+1}.pth')print(f'[Evaluate]best accuracy performance has been updated: {self.best_score:.5f}-->{dev_score:.5f}')self.best_score = dev_score# 验证过程结束后,请记住将模型调回训练模式 self.model.train()global_step += 1# 保存当前轮次训练损失的累计值train_loss = (total_loss/len(train_loader)).item()self.train_epoch_losses.append((global_step,train_loss))print('[Train] Train done')# 模型评价阶段def evaluate(self, dev_loader, **kwargs):assert self.metric is not None# 将模型设置为验证模式,此模式下,模型的参数不会更新self.model.eval()global_step = kwargs.get('global_step',-1)total_loss = 0self.metric.reset()for batch_id, data in enumerate(dev_loader):x, y = datalogits = self.model(x.float())loss = self.loss_fn(logits, y.long()).item()total_loss += loss self.metric.update(logits, y)dev_loss = (total_loss/len(dev_loader))self.dev_losses.append((global_step, dev_loss))dev_score = self.metric.accumulate()self.dev_scores.append(dev_score)return dev_score, dev_loss# 模型预测阶段,def predict(self, x, **kwargs):self.model.eval()logits = self.model(x)return logits# 保存模型的参数def save_model(self, save_path):torch.save(self.model.state_dict(),save_path)# 读取模型的参数def load_model(self, model_path):self.model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))相关文章:
【深度学习实验】前馈神经网络(九):整合训练、评估、预测过程(Runner)
目录 一、实验介绍 二、实验环境 1. 配置虚拟环境 2. 库版本介绍 三、实验内容 0. 导入必要的工具包 1. __init__(初始化) 2. train(训练) 3. evaluate(评估) 4. predict(预测) 5. save_model 6. load_model 7. 代码整合 一、实验介绍 二、实验环境 本系列实验使用…...

002-第一代硬件系统架构确立及产品选型
第一代硬件系统架构确立及产品选型 文章目录 第一代硬件系统架构确立及产品选型项目介绍摘要硬件架构硬件结构选型及设计单片机选型上位机选型扯点别的 关键字: Qt、 Qml、 信号采集机、 数据处理、 上位机 项目介绍 欢迎来到我们的 QML & C 项目ÿ…...

Go基础语法:指针和make和new
8 指针、make、new 8.1 指针(pointer) Go 语言中没有指针操作,只需要记住两个符号即可: & 取内存地址* 根据地址取值 package mainimport "fmt"func main() {a : 18// 获取 a 的地址值并复制给 pp : &a// …...

039_小驰私房菜_Camera perfermance debug
全网最具价值的Android Camera开发学习系列资料~ 作者:8年Android Camera开发,从Camera app一直做到Hal和驱动~ 欢迎订阅,相信能扩展你的知识面,提升个人能力~ 一、抓取trace 1. adb shell "echo vendor.debug.trace.perf=1 >> /system/build.prop" 2. …...

Caché for Windows安装及配置
本文介绍在Windows上安装Cach的操作步骤。本文假设用户熟悉Windows目录结构、实用程序和命令。本文包含如下主要部分: 1)Cach安装...

代码随想录算法训练营20期|第四十六天|动态规划part08|● 139.单词拆分 ● 关于多重背包,你该了解这些! ● 背包问题总结篇!
139.单词拆分 感觉这个板块要重新刷,完全没有印象 class Solution {public boolean wordBreak(String s, List<String> wordDict) {Set<String> set new HashSet<>(wordDict);boolean[] dp new boolean[s.length() 1];dp[0] true;for (int i…...

系统安装(一)CentOS 7 本地安装
CentOS与Ubuntu并称为Linux最著名的两个发行版,但由于笔者主要从事深度学习图像算法工作,Ubuntu作为谷歌和多数依赖库的亲儿子占据着最高生态位。但最近接手的一个项目里,甲方指定需要在CentOS7上运行项目代码,笔者被迫小小cos了一…...

obsidian使用指南
插入代码块快捷键设置 插入代码块 用英文搜索快捷键名字 英文搜索的【Insert code block】对应的是 (6个点) 中文搜索的【代码块】对应的是 (2个点) 查看word、excel等非md文件设置 电脑端obsidian->设置->文件与链接->检测所有类型文件->…...
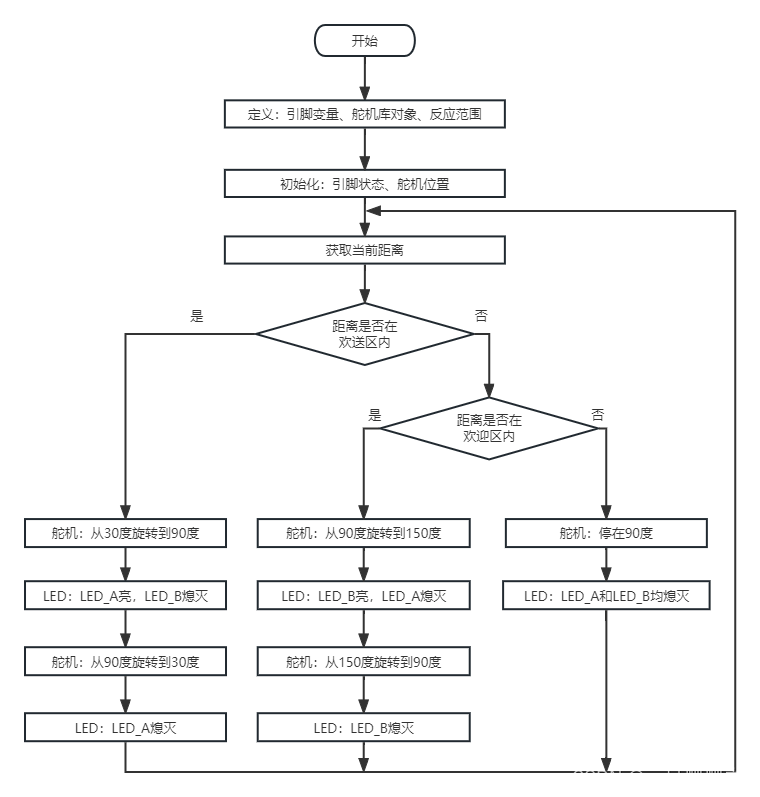
【ardunio】青少年机器人四级实操代码(2023年9月)
目录 一、题目 二、示意图 三、流程图 四、硬件连接 1、舵机 2、超声波 3、LED灯 五、程序 一、题目 实操考题(共1题,共100分) 1. 主题: 迎宾机器人 器件:Atmega328P主控板1块,舵机1个,超声波传感器1个&…...

MYSQL的存储过程
存储过程 存储过程是事先经过编译并存储在数据库中的一段 SQL 语句的集合,调用存储过程可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是有好处的。存储过程思想上很简单,就是…...

[kubernetes/docker] failed to resolve reference ...:latest: not found
问题描述: pod一直pending, kubectl describe pod ... 显示: Warning Failed 9s (x3 over 63s) kubelet Failed to pull image "mathemagics/my-kube-scheduler": rpc error: code NotFound desc failed to pull and unpack image "docker…...
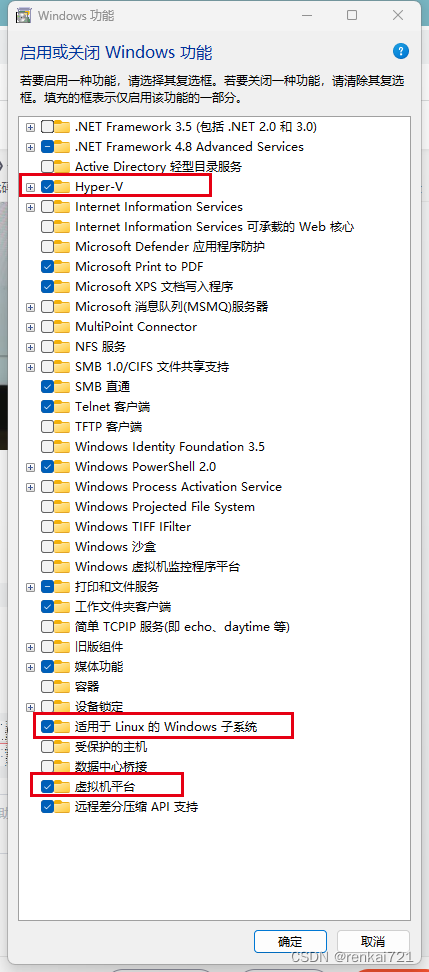
彻底解决win11系统0x80070032
经过各种尝试,终于找到原因。第一个是电脑加密软件,第二个是需要的部分功能没有开启,第三个BIOS设置。个人觉得第三个不重要。 解决方法 笔记本型号 笔记本型号是Thinkpad T14 gen2。进入BIOS的按键是按住Enter键。 1、关闭山丽防水墙服务…...

解决因为修改SELINUX配置文件出错导致Faild to load SELinux poilcy无法进入CentOS7系统的问题
一、问题 最近学习Kubernetes,需要设置永久关闭SELINUX,结果修改错了一个SELINUX配置参数,关机重新启动后导致无法进入CentOS7系统,卡在启动进度条界面。 二、解决 多次重启后,在启动日志中发现 Faild to load SELinux poilcy…...

flask中的跨域处理-方法二不使用第三方库
方法1(第三方库) pip install flask-cors from flask import Flask from flask_cors import CORSapp = Flask(__name__) CORS(app, resources={r"/api/*": {"origins": ["http://localhost:63342", "http://localhost:63345"]}})方…...

矿山定位系统-矿井人员定位系统在矿山自动化安全监控过程中的应用
一,矿井人员定位系统现阶段使用的必要性 1,煤矿开采是一项非常特殊的工作,现场属于非常复杂多变的环境,井下信号极差,数据传输非常不稳定,人员安全难以保证,煤矿企业一直在研究如何使用更合适的…...
JS-ECharts-前端图表 多层级联合饼图、柱状堆叠图、柱/线组合图、趋势图、自定义中线、平均线、气泡备注点
本篇博客背景为JavaScript。在ECharts在线编码快速上手,绘制相关前端可视化图表。 ECharts官网:https://echarts.apache.org/zh/index.html 其他的一些推荐: AntV:https://antv.vision/zh chartcube:https://chartcub…...

【eslint】屏蔽语言提醒
在 JavaScript 中,ESLint 是一种常用的静态代码分析工具,它用于检测和提醒代码中的潜在问题和风格问题。有时候,在某些特定情况下,你可能希望临时屏蔽或禁用某些 ESLint 的提醒信息,以便消除不必要的警告或避免不符合项…...

【python】入门第一课:了解基本语法(数据类型)
目录 一、介绍 1、什么是python? 2、python的几个特点 二、实例 1、注释 2、数据类型 2.1、字符串 str 2.2、整数 int 2.3、浮点数 float 2.4、布尔 bool 2.5、列表 list 2.6、元组 tuple 2.7、集合 set 2.8、字典 dict 一、介绍 1、什么是python&…...
csa从初阶到大牛(练习题2-查询)
新建2个文件d1.txt d2.txt ,使用vim打开d1.txt 输入“Hello World”字符串,将b1.txt 硬链接到b2.txt ,查看2个文件的硬连接数 # 新建文件d1.txt和d2.txt touch d1.txt d2.txt# 使用vim编辑d1.txt并输入文本"Hello World" vim d1.txt# 创建硬链接b2.…...

【视觉SLAM入门】8. 回环检测,词袋模型,字典,感知,召回,机器学习
"见人细过 掩匿盖覆” 1. 意义2. 做法2.1 词袋模型和字典2.1.2 感知偏差和感知变异2.1.2 词袋2.1.3 字典 2.2 匹配(相似度)计算 3. 提升 前言: 前端提取数据,后端优化数据,但误差会累计,需要回环检测构建全局一致的地图&…...

Gemini自动生成PPT实战手册:从零输入到专业演示文稿,3步完成95%的幻灯片工作流
更多请点击: https://intelliparadigm.com 第一章:Gemini自动生成PPT的核心原理与能力边界 Gemini 生成 PPT 的本质并非传统模板填充,而是基于多模态理解与结构化内容重构的端到端推理过程。其核心依赖于对用户输入(文本、大纲、…...

通过AxisApi中转站使用国外API大模型教程
前言:所有的国外大模型想不通过中转站直接使用,其实是很麻烦的的事情,就拿codex来说,需要一个谷歌账号,没有谷歌账号需要注册,注册还必须要使用国外的手机号码和验证码校验审核,流程很繁琐&…...

C++ 知识点22 函数模板
C 函数模板一、为什么要有函数模板?先看痛点:你要写两个交换函数,int 版、double 版:// int 交换 void swapInt(int &a, int &b) {int t a; a b; b t; } // double 交换 void swapDouble(double &a, double &b…...
)
从find到ind2sub:Matlab数据筛选后操作的完整工作流(以R2023b为例)
从find到ind2sub:Matlab数据筛选后操作的完整工作流(以R2023b为例) 在数据分析与科学计算领域,Matlab作为一款强大的工具,其矩阵操作能力尤为突出。面对大型矩阵或高维数组时,如何高效地定位并处理特定条件…...

如何实现一个延迟队列?
1. 基于 Sorted Set (ZSet) 的实现 这是最轻量级、最原生的 Redis 延迟队列实现方式。 核心思想:利用 ZSet 可以根据 score 进行排序的特性。我们将任务的预期执行时间戳作为 score,任务的具体内容(或任务 ID)作为 member。 生产…...

【信息科学与工程学】【通信工程】第四十三篇 骨干网方案设计-02跨境网络
一、方案 1.1 整体方案设计概要 设计的云网融合方案,综合考虑其全球互联需求、安全合规性、性能优化及跨国运营挑战: 1.1.1、需求分析 网络互联需求: 国内互通: 安全、稳定、低延迟连接中国大陆(严格合规要求)。 国际互通: 高性能连接美国(东西海…...

别再只调API了!微信支付Native/JSAPI开发中,订单号生成与回调处理的5个实战避坑点
微信支付开发实战:订单与回调的五个关键陷阱与解决方案 在移动支付领域,微信支付作为主流平台之一,其开发文档看似详尽,但实际落地时仍存在诸多"暗坑"。许多开发者过度关注支付接口调用本身,却忽视了订单生成…...

为什么顶尖投行/律所/药企已将Perplexity设为默认搜索端口?:拆解其底层Provenance Graph引擎与ChatGPT RAG架构的7层信任差
更多请点击: https://intelliparadigm.com 第一章:Perplexity与ChatGPT搜索范式的根本性分野 Perplexity 和 ChatGPT 代表两种截然不同的信息交互哲学:前者以**可验证的溯源驱动**为核心,后者以**生成连贯性优先**为设计原则。这…...

三步掌握MarkDownload:将网页内容高效转换为结构化笔记
三步掌握MarkDownload:将网页内容高效转换为结构化笔记 【免费下载链接】markdownload A Firefox and Google Chrome extension to clip websites and download them into a readable markdown file. 项目地址: https://gitcode.com/gh_mirrors/ma/markdownload …...

从Apple TV与Fire TV拆解看硬件成本、供应链策略与商业逻辑差异
1. 项目概述:一场跨越两年的硬件成本对决作为一名长期关注消费电子硬件设计与供应链的从业者,我始终对设备背后的物料成本(BOM)分析抱有浓厚兴趣。这不单单是看热闹,更是理解厂商商业策略、产品定位乃至未来迭代方向的…...