Linux之perf(7)配置
Linux之perf(7)配置类命令
Author:Onceday Date:2023年9月23日
漫漫长路,才刚刚开始…
注:该文档内容采用了GPT4.0生成的回答,部分文本准确率可能存在问题。
参考文档:
- Tutorial - Perf Wiki (kernel.org)
- perf(1) - Linux manual page (man7.org)
- perf-test(1) - Linux manual page (man7.org)
- perf-version(1) - Linux manual page (man7.org)
- perf-config(1) - Linux manual page (man7.org)
文章目录
- Linux之perf(7)配置类命令
- 1. perf version输出版本信息
- 2. perf test 测试
- 3. perf config 配置
- 3.1 颜色配置(colors.*)
- 3.2 内核文件超时(core.*, core.proc-map-timeout)
- 3.3 交互式输出(tui., gtk.)
- 3.4 编译id(buildid.*, buildid.dir)
- 3.5 编译id缓存(buildid-cache.*)
- 3.6 perf数据标注(annotate.*)
- 3.7 显示源代码(annotate.hide_src_code)
- 3.8 显示地址偏移量(annotate.use_offset)
- 3.9 跳转箭头(annotate.jump_arrows)
- 3.10 显示行号(annotate.show_linenr)
- 3.11 跳转分支数目(annotate.show_nr_jumps)
- 3.12 百分比显示(annotate.show_total_period)
- 3.13 绝对数量(annotate.show_nr_samples)
- 3.14 消耗计算方式(hist.*, hist.percentage)
- 3.15 标题显示方式(ui.*, ui.show-headers)
- 3.16 调用栈显示(call-graph.*)
- 3.17 条目打印风格(call-graph.print-type)
- 3.18 控制链打印顺序(call-graph.order)
- 3.19 report参数(report.*, report.sort_order)
- 3.20 事件组展示(report.group)
- 3.21 top参数(top.*)
- 3.22 帮助手册查看(man.*, man.viewer)
- 3.23 分页选择(pager.*)
- 3.24 内存分配器(kmem.*, kmem.default)
- 3.25 record参数(record.*)
- 3.26 diff参数(diff.*)
- 3.27 trace参数(trace.*)
- 3.28 ftrace参数(ftrace.*)
- 3.29 llvm参数(llvm.*)
- 3.30 其他参数
1. perf version输出版本信息
如果没有给出任何选项,则在标准输出中打印出该版本。
如果给出了选项--build-options,则在标准输出中打印内编译库的状态。
# perf version --build-options
perf version 6.2.16dwarf: [ on ] # HAVE_DWARF_SUPPORTdwarf_getlocations: [ on ] # HAVE_DWARF_GETLOCATIONS_SUPPORTglibc: [ on ] # HAVE_GLIBC_SUPPORTsyscall_table: [ on ] # HAVE_SYSCALL_TABLE_SUPPORTlibbfd: [ OFF ] # HAVE_LIBBFD_SUPPORTdebuginfod: [ OFF ] # HAVE_DEBUGINFOD_SUPPORTlibelf: [ on ] # HAVE_LIBELF_SUPPORTlibnuma: [ on ] # HAVE_LIBNUMA_SUPPORT
numa_num_possible_cpus: [ on ] # HAVE_LIBNUMA_SUPPORTlibperl: [ OFF ] # HAVE_LIBPERL_SUPPORTlibpython: [ OFF ] # HAVE_LIBPYTHON_SUPPORTlibslang: [ on ] # HAVE_SLANG_SUPPORTlibcrypto: [ on ] # HAVE_LIBCRYPTO_SUPPORTlibunwind: [ on ] # HAVE_LIBUNWIND_SUPPORTlibdw-dwarf-unwind: [ on ] # HAVE_DWARF_SUPPORTzlib: [ on ] # HAVE_ZLIB_SUPPORTlzma: [ on ] # HAVE_LZMA_SUPPORTget_cpuid: [ on ] # HAVE_AUXTRACE_SUPPORTbpf: [ on ] # HAVE_LIBBPF_SUPPORTaio: [ on ] # HAVE_AIO_SUPPORTzstd: [ OFF ] # HAVE_ZSTD_SUPPORTlibpfm4: [ OFF ] # HAVE_LIBPFMlibtraceevent: [ OFF ] # HAVE_LIBTRACEEVENT
2. perf test 测试
perf test命令用于执行各种健壮性测试,最初通过链接的例程执行,但也会寻找一个包含更多形式的脚本测试的目录。
要获取可用测试的列表,可以使用 perf test list。如果指定了测试名称的一部分,将显示所有包含该部分的测试。
如果要运行特定的测试,可以提供测试名称的片段或者从perf test list获取的编号。
简单来说,这是一种用于验证和测试系统性能的工具,能够帮助开发者找出可能存在的问题并进行针对性的优化。
perf test [<options>] [{list <test-name-fragment>|[<test-name-fragments>|<test-numbers>]}]
下面是支持的选项:
-s, --skip, Tests to skip (comma separated numeric list).
-v, --verbose, Be more verbose.
-F, --dont-fork, Do not fork child for each test, run all tests within single process--dso, Specify a DSO for the "Symbols" test.
3. perf config 配置
查看或者设置perf配置文件里面的变量值。
perf config [<file-option>] [section.name[=value] ...]
or
perf config [<file-option>] -l | --list
下面是支持的选项:
-l, --listShow current config variables, name and value, for allsections.
--userFor writing and reading options: write to user$HOME/.perfconfig file or read it.
--systemFor writing and reading options: write to system-wide$(sysconfdir)/perfconfig or read it.
perf配置文件包含许多变量,用于更改每个工具的各个方面,包括输出、磁盘使用情况等。
$HOME /Perfconfig文件用于存储每个用户的配置。$(sysconfdir)/perfconfig文件可以用来存储系统范围的默认配置。一种方法是通过将PERF_CONFIG环境变量设置为/dev/null来禁用读取配置文件,或者通过设置该变量来提供备用配置文件。
当读取或写入时,默认情况下从系统和用户配置文件中读取这些值,选项--system和--user可用于告诉命令仅从该位置读取或写入。
该文件由部分组成。每一节的名称以方括号括起,并一直持续到下一节开始。每个变量必须在一个节中,并具有name = value的形式,例如:
[section]name1 = value1name2 = value2
节名区分大小写,可以包含除换行符以外的任何字符(双引号"和反斜杠必须分别转义为\"和\\)。节标题不能跨越多行。
下面是一个配置文件的例子:
# # This is the config file, and # a # and ; character indicates a comment #
[colors]# Color variablestop = red, defaultmedium = green, defaultnormal = lightgray, defaultselected = white, lightgrayjump_arrows = blue, defaultaddr = magenta, defaultroot = white, blue[tui]# Defaults if linked with libslangreport = onannotate = ontop = on[buildid]# Default, disable using /dev/nulldir = ~/.debug[annotate]# Defaultshide_src_code = falseuse_offset = truejump_arrows = trueshow_nr_jumps = false[help]# Format can be man, info, web or htmlformat = manautocorrect = 0[ui]show-headers = true[call-graph]# fp (framepointer), dwarfrecord-mode = fpprint-type = graphorder = callersort-key = function[report]# Defaultssort_order = comm,dso,symbolpercent-limit = 0queue-size = 0children = truegroup = trueskip-empty = true[llvm]dump-obj = trueclang-opt = -g
在annotate属性中可以隐藏源码的显示:
perf config annotate.hide_src_code=true
如果想一次修改多个配置数据:
perf config ui.show-headers=false kmem.default=slab
在用户配置中修改report显示的顺序:
perf config --user report.sort-order=srcline
改变系统配置中的选中行的前景色和背景色,如下:
perf config --system colors.selected=yellow,green
查询record使用的回调栈记录模式,如下:
perf config call-graph.record-mode
可以一次查询多个键值对数据:
perf config report.queue-size call-graph.order report.children
查询指定用户或者系统的配置数据:
perf config --user call-graph.sort-order
perf config --system buildid.dir
3.1 颜色配置(colors.*)
用于自定义TUI中报告、顶部和注释输出中使用的颜色的变量。它们应该指定前景和背景颜色,用逗号分隔,例如:
medium = green, lightgray
如果要使用控制终端配置的颜色,可以使用默认值:
medium = default, lightgray
可用的颜色如下:
red, yellow, green, cyan, gray, black, blue, white, default, magenta, lightgray
以下是具体可以配置的颜色分类:
colors.top,Top是指超过5%的消耗开销百分比。这个变量的值指定颜色的百分比。基本键值是前景色红色和背景色默认值。colors.medium,中等是指开销百分比大于0.5%。默认值为绿色和Default。colors.normal,正常是指除了top, medium, selected之外的其余开销百分比。默认值为浅灰色和Default。colors.selected,这将为子命令(top、report、annotate)中的条目列表中的当前条目选择颜色。默认值是黑色和浅灰色。colors.jump_arrows,汇编代码清单(如jns、jmp、jane等)上跳转箭头的颜色。默认值是蓝色。colors.addr,这将从注释中选择地址的颜色。默认值是洋红色,默认值。colors.root,子命令(top、report)输出中标题的颜色。默认值是白色、蓝色。
3.2 内核文件超时(core.*, core.proc-map-timeout)
设置解析/proc/<pid>/maps文件的超时时间(毫秒)。可以被支持的子命令上的--proc-map-timeout选项覆盖。默认超时时间为500ms。
3.3 交互式输出(tui., gtk.)
可以在这里配置的子命令有top、report和annotate。这些值是布尔值,例如:
[tui]top = true
将使TUI为’top’子命令的默认值。如果在工具构建时检测到所需的库,这些库将可用。
3.4 编译id(buildid.*, buildid.dir)
现代发行版中的每个可执行库和共享库都带有一个基于内容的标识符,如果可用,将插入到一个属性中。数据文件头来,在分析的时候找到需要做什么,做符号解析、代码注释等。
记录工具还在每个用户目录$HOME/.debug/中存储二进制文件、共享库、/proc/kallsyms和/proc/kcore文件的硬链接或副本,以便在分析时使用。buildid.Dir变量可用于更改此目录缓存位置,或者完全禁用它。
如果你想禁用它,设置buildid.dir为/dev/null,默认为$HOME/.debug。
3.5 编译id缓存(buildid-cache.*)
buildid-cache.* 是 perf config 中的配置变量,它们与构建 ID 缓存有关。构建 ID 缓存用于存储和管理与构建 ID 相关的二进制文件。
buildid-cache.debuginfod=URLs 是一个特定的配置变量,用于指定在检索 perf.data 二进制文件时使用的 debuginfod URLs。它的语法与 DEBUGINFOD_URLS 变量相同。例如:
buildid-cache.debuginfod=http://192.168.122.174:8002
在这个例子中,http://192.168.122.174:8002 是用于获取二进制文件的 debuginfod 服务器的 URL。
Debuginfod 是一个网络服务器和客户端,用于分发编译时生成的调试信息。通过这种方式,可以在需要时获取二进制文件的调试信息,而无需在本地存储所有的调试信息。
3.6 perf数据标注(annotate.*)
annotate.* 是 perf config 中的配置变量,它们用于控制来自特定程序的汇编代码行中的地址、跳转函数和源代码。
以下是各个变量的详细解释:
-
annotate.addr2line:用于文件名和行号的 addr2line 二进制文件。addr2line是一个工具,它将程序计数器值转换为源代码文件名和行号。在perf中,它用于将地址信息转换为源代码的文件名和行号。 -
annotate.objdump:用于反汇编和注解的 objdump 二进制文件。objdump是一个程序,用于显示二进制文件的各种信息。在perf中,它用于反汇编和注解二进制文件。 -
annotate.disassembler_style:用于改变默认的反汇编器样式到 binutils 支持的其他值,比如 “intel”。具体可以查看 objdump 手册页中的-M选项帮助。这个配置允许用户改变反汇编输出的样式。例如,“intel” 样式会使反汇编输出更接近 Intel 的汇编语法。 -
annotate.offset_level是perf config中的一个配置选项,用于控制显示指令旁边的偏移量的级别。默认值是 1,意味着只有跳转目标将在指令旁边显示偏移量。当设置为 2 时,调用指令也将显示其偏移量。3 或更高的级别将为所有指令显示偏移量。此选项适用于 tui(文本用户接口)和 stdio2 浏览器。
-
annotate.demangle是一个配置选项,用于将符号名称解析到人类可读的形式。默认值是 true。 -
annotate.demangle_kernel是一个配置选项,用于将内核符号名称解析到人类可读的形式。默认值是 true。
3.7 显示源代码(annotate.hide_src_code)
annotate.hide_src_code 是 perf config 中的一个配置选项,用于控制在注解中是否显示源代码。
如果分析的程序有源代码,这个选项可以让 annotate 打印出汇编代码列表,同时显示源代码。例如,让我们看一部分程序。有四行代码。如果此选项为 true,那么它们可以在没有程序源代码的情况下打印出来,如下所示:
│ push %rbp
│ mov %rsp,%rbp
│ sub $0x10,%rsp
│ mov (%rdi),%rdx
但是,如果此选项为 ‘false’,那么这部分的源代码也可以一并打印出来。默认值是 ‘false’。例如:
│ struct rb_node *rb_next(const struct rb_node *node)
│ {
│ push %rbp
│ mov %rsp,%rbp
│ sub $0x10,%rsp
│ struct rb_node *parent;
│
│ if (RB_EMPTY_NODE(node))
│ mov (%rdi),%rdx
│ return n;
此选项适用于 tui(文本用户接口)和 stdio2 浏览器。
3.8 显示地址偏移量(annotate.use_offset)
annotate.use_offset 是 perf config 中的一个配置选项,用于控制是否使用偏移量来显示地址。
根据加载函数的首地址,可以使用偏移量。而不是使用汇编代码的原始地址,打印的地址可以是从基地址减去的地址。让我们来举一个例子。如果基地址是 0XFFFFFFFF81624d50,如下所示:
ffffffff81624d50 <load0>
汇编代码上的一个地址有一个特定的绝对地址,如下所示:
ffffffff816250b8:│ mov 0x8(%r14),%rdi
但是,如果 use_offset 为 ‘true’,则会打印出从基地址减去的地址。默认值是 true。此选项仅适用于 TUI(文本用户接口)。
368:│ mov 0x8(%r14),%rdi
此选项适用于 tui(文本用户接口)和 stdio2 浏览器。
3.9 跳转箭头(annotate.jump_arrows)
annotate.jump_arrows 是 perf config 中的一个配置选项,用于控制是否在显示跳转指令时打印箭头。
在汇编代码中,可能会有跳转指令。根据 jump_arrows 的布尔值,可以打印或不打印代表指令跳转到何处的箭头,如下所示:
│ ┌──jmp 1333
│ │ xchg %ax,%ax
│1330:│ mov %r15,%r10
│1333:└─→cmp %r15,%r14
如果 jump_arrow 为 ‘false’,则不会打印箭头,如下所示。默认值是 ‘false’。
│ ↓ jmp 1333
│ xchg %ax,%ax
│1330: mov %r15,%r10
│1333: cmp %r15,%r14
此选项适用于 tui(文本用户接口)浏览器。
3.10 显示行号(annotate.show_linenr)
annotate.show_linenr 是 perf config 中的一个配置选项,用于控制是否在显示源代码时打印行号。
当显示源代码时,如果此选项为 true,则会打印行号,如下所示:
│1628 if (type & PERF_SAMPLE_IDENTIFIER) {
│ ↓ jne 508
│1628 data->id = *array;
│1629 array++;
│1630 }
然而,如果此选项为 ‘false’,则不会打印行号,如下所示。默认值是 ‘false’。
│ if (type & PERF_SAMPLE_IDENTIFIER) {
│ ↓ jne 508
│ data->id = *array;
│ array++;
│ }
此选项适用于 tui(文本用户接口)和 stdio2 浏览器。
3.11 跳转分支数目(annotate.show_nr_jumps)
annotate.show_nr_jumps 是 perf config 中的一个配置选项,用于控制是否显示跳转到某地址的分支数量。让我们看一部分汇编代码:
│1382: movb $0x1,-0x270(%rbp)
如果使用此选项,可以打印跳转到该地址的分支数量,如下所示。默认值是 ‘false’:
│1 1382: movb $0x1,-0x270(%rbp)
此选项适用于 tui(文本用户接口)和 stdio2 浏览器。
3.12 百分比显示(annotate.show_total_period)
annotate.show_total_period 是 perf config 中的一个配置选项,用于控制在汇编代码行中显示的是样本总数还是百分比值。
在指令基础上比较两个记录时,如果提供了此选项,将显示属于汇编代码行的样本总数。如果此选项为 true,则打印的是总周期数,而不是百分比值,如下所示:
302 │ mov %eax,%eax
但是,如果此选项为 ‘false’,则打印的是对应于开销的百分比值。默认值是 ‘false’,示例如下:
99.93 │ mov %eax,%eax
此选项适用于 tui(文本用户接口)、stdio2 和 stdio 浏览器。
3.13 绝对数量(annotate.show_nr_samples)
annotate.show_nr_samples 是 perf config 中的一个配置选项,用于控制是否打印样本的绝对数量。
默认情况下,perf annotate 显示的是样本的百分比。此选项可以用于打印样本的绝对数量。例如,当设置为 false 时:
Percent│
74.03 │ mov %fs:0x28,%rax
当设置为 true 时:
Samples│
6 │ mov %fs:0x28,%rax
此选项适用于 tui(文本用户接口)、stdio2 和 stdio 浏览器。
3.14 消耗计算方式(hist.*, hist.percentage)
hist.* 和 hist.percentage 是 perf config 中的配置选项,用于控制计算过滤条目开销的方式 - 这意味着只有在存在过滤器(通过 comm、dso 或符号名称)时,此选项的值才有效。
假设以下示例:
Overhead Symbols
........ .......
33.33% foo
33.33% bar
33.33% baz
这是原始的开销,我们将过滤掉第一个 ‘foo’ 条目。‘relative’ 的值会将 ‘bar’ 和 ‘baz’ 的开销提高到各自的 50.00%,而 ‘absolute’ 会显示他们当前的开销(33.33%)。
3.15 标题显示方式(ui.*, ui.show-headers)
ui.* 和 ui.show-headers 是 perf config 中的配置选项,用于控制在报告和顶部显示列标题(如 Overhead 和 Symbol)。
如果此选项为 false,则它们将被隐藏。此选项仅应用于 TUI(文本用户界面)。
3.16 调用栈显示(call-graph.*)
call-graph.* 是 perf config 中的一个配置选项,用于控制调用图的处理(通过 -g/–call-graph 选项获得)。
call-graph.record-mode是一个配置选项,用于控制用户空间的模式,可以是 fp(帧指针)、dwarf 和 lbr。dwarf 值只有在系统上存在 libunwind(或最新版本的 libdw)时才有效;lbr 值只对某些 CPU 有效。内核空间的方法不是由此选项控制,而是由内核配置(CONFIG_UNWINDER_*)控制。call-graph.dump-size是一个配置选项,用于控制为了进行后续展开而要转储的堆栈的大小。默认值是 8192(字节)。当在 record-mode 中使用 dwarf 时,如果省略,则将使用默认大小。call-graph.sort-key是perf config中的一个配置选项,用于确定比较调用链的方式。如果调用链包含相同的信息,则它们会被合并。sort-key 的值可以是 function 或 address。默认值是 function。call-graph.threshold是一个配置选项,当有许多调用链时,它会打印大量的行。因此,perf 会忽略某个开销(阈值)以下的小调用链,此选项控制该阈值。默认值是 0.5(%)。开销是根据 call-graph.print-type 的值计算的。call-graph.print-limit是一个配置选项,表示为单个直方图条目打印的调用链的最大行数。默认值为 0,表示无限制。
3.17 条目打印风格(call-graph.print-type)
call-graph.print-type 是 perf config 中的一个配置选项,用于控制显示每个调用链条目开销的方式。print-types 可以是 graph(图形绝对)、fractal(图形相对)、flat 和 folded。假设以下示例:
Overhead Symbols
........ .......
40.00% foo|---foo||--50.00%--bar| main|--50.00%--bazmain
这个输出是 ‘fractal’ 格式。‘foo’ 来自 ‘bar’ 和 ‘baz’,各占一半,所以 ‘fractal’ 为每个显示 50.00%(意味着它假定 ‘foo’ 的总消耗为 100%)。
‘graph’ 使用 ‘foo’ 的绝对开销值作为总数,所以每个 ‘bar’ 和 ‘baz’ 的调用链将有 20.00%的消耗。如果使用 ‘flat’,则调用链的单列和线性曝光。‘folded’ 意味着调用链在一行中显示,由分号分隔。
3.18 控制链打印顺序(call-graph.order)
call-graph.order 是 perf config 中的一个配置选项,用于控制调用链的打印顺序。
默认值是 callee,这意味着先打印 callee,然后是它的调用者,依此类推。caller 则以相反的顺序打印。
如果此选项未设置,并且 report.children 或 top.children 设置为 true(或给出了等效的命令行选项),则在执行 ‘perf report’ 或 ‘perf top’ 时,此选项的默认值将更改为 ‘caller’。其他命令仍将默认为 ‘callee’。
3.19 report参数(report.*, report.sort_order)
report.* 和 report.sort_order 是 perf config 中的配置选项,允许从 “comm,dso,symbol” 更改默认的排序顺序,例如 “sym,dso” 可能更适合内核开发人员。
-
report.percent-limit配置选项与 call-graph.threshold 大致相同,但适用于直方图条目。开销低于此百分比的条目将不会被打印。默认值为 0。如果 percent-limit 为 10,则只有开销超过 10% 的条目才会被打印。 -
report.queue-size是一个配置选项,用于设置内部事件队列的最大分配大小,以便对事件进行排序。默认值为 0,表示无限制。 -
report.children是一个配置选项,children 指的是从另一个函数调用的函数。如果此选项为 true,perf report 将累积 children 的调用链,并显示(累积的)总开销以及自身开销。请参阅 perf report 手册。默认值为 true。 -
report.skip-empty是perf config中的一个配置选项,它可以改变默认的处理空结果的统计行为。如果将其设置为 true,那么perf report --stat将不会显示 0 的统计结果。这可以帮助减少不必要的输出,特别是在大量统计数据中,空结果可能会干扰重要数据的查看。
3.20 事件组展示(report.group)
report.group 是 perf config 中的一个配置选项,用于一起显示事件组信息。开启此选项后,注意每个组中的事件都有一列,如 ref-cycles 和 cycles:
# group: {ref-cycles,cycles}
# ========
#
# Samples: 7K of event 'anon group { ref-cycles, cycles }'
# Event count (approx.): 6876107743
#
# Overhead Command Shared Object Symbol
# ................ ....... ................. ...................
#
99.84% 99.76% noploop noploop [.] main
0.07% 0.00% noploop ld-2.15.so [.] strcmp
0.03% 0.00% noploop [kernel.kallsyms] [k] timerqueue_del
在上面的输出示例中,每个事件组中的事件(ref-cycles 和 cycles)都有一个列,并显示其过载、命令、共享对象和符号。
3.21 top参数(top.*)
top.* 和 top.children 与 report.children 的功能相同。因此,如果启用了此选项,top 命令的输出将默认具有 Children 过载列以及 Self 过载列。默认值为 true。
top.call-graph 与 call-graph.record-mode 相同,只不过它仅适用于 top 子命令。此选项仅设置解开方法。要使 perf top 实际使用它,必须指定命令行选项 -g。这意味着,你需要在启动 perf top 时手动添加 -g 选项,以启用调用图功能。
3.22 帮助手册查看(man.*, man.viewer)
man.* 和 man.viewer 是 perf config 中的配置选项,可以指定在调用 help 子命令时用于查看手册页的工具。支持的工具有 man、woman(与 emacs 客户端一起使用)和 konqueror。默认是 man。
新的 man 观看器工具也可以使用 ‘man..cmd’ 添加,或者使用 ‘man..path’ 配置选项使用不同的路径。
3.23 分页选择(pager.*)
pager.* 和 pager.<subcommand> 是 perf config 中的配置选项,当子命令在标准输入输出上运行时,根据此值决定是否使用分页器。默认值未指定。这意味着,除非用户明确设置,否则 perf 不会假设是否使用分页器来显示子命令的输出。
3.24 内存分配器(kmem.*, kmem.default)
kmem.* 和 kmem.default 是 perf config 中的配置选项,用于决定在未使用 --slab 或 --page 选项的情况下,应分析哪个分配器。默认值是 slab。
在内核内存分析 (kmem) 中,slab 和 page 是两种常见的内存分配方法。slab 分配器以对象为单位进行内存分配,适用于存储大小固定的数据结构;page 分配器以页面为单位进行内存分配,适用于大块内存的分配。根据这个选项,perf 工具将默认分析 slab 分配器的使用情况。
3.25 record参数(record.*)
record.* 和 record.build-id 是 perf config 中的配置选项,可以设置为 cache、no-cache、skip 或 mmap。cache 用于对数据进行后处理,并将二进制文件保存/更新到 build-id 缓存(在 ~/.debug 中)。这是默认设置。但是,如果此选项设置为 no-cache,它将不会更新 build-id 缓存。skip 跳过后处理,不更新缓存。mmap 跳过后处理,并从 MMAP 事件中读取 build-ids。
record.call-graph 与 call-graph.record-mode 相同,只不过它仅适用于 record 子命令。此选项仅设置解开方法。要使 perf record 实际使用它,必须指定命令行选项 -g。
record.aio 使用 n 个控制块在异步(Posix AIO)跟踪写入模式中(n 默认值:1,最大值:4)。
record.debuginfod 指定在缓存 perf.data 二进制文件时使用的 debuginfod URL,其语法与 DEBUGINFOD_URLS 变量相同,例如:
http://192.168.122.174:8002
如果 URL 是 ‘system’,则使用 DEBUGINFOD_URLS 系统环境变量的值。
3.26 diff参数(diff.*)
diff.* 和 diff.order 是 perf config 中的配置选项,用于设置对结果进行排序的列数。默认值为 0,表示按基线排序。将其设置为 1 将按 delta(或选定的其他计算方法)对结果进行排序。
diff.compute 是一个配置选项,用于设置计算差异结果的方法。可能的值有 delta、delta-abs、ratio 和 wdiff。默认值是 delta。
这些选项在使用 perf diff 命令对性能数据进行比较时非常有用。可以通过调整这些选项来改变结果的排序和计算方式,以便更好地理解性能数据的差异。
3.27 trace参数(trace.*)
trace.* 和 trace.add_events 是 perf config 中的配置选项,允许添加一组事件来补充用户指定的事件,或者如果未指定任何事件,则使用它作为默认事件。初始用例是添加 augmented_raw_syscalls.o 来激活寻找系统调用指针内容的 perf trace 逻辑,该逻辑在正常跟踪点载荷之后。
trace.args_alignment 是对齐参数列表的列数,默认值为 70,strace 默认使用 40,为零则无对齐。
trace.no_inherit 不跟踪子线程。
trace.show_arg_names 是否打印系统调用参数名称?如果不是,则设置 trace.show_zeros。
trace.show_duration 显示系统调用持续时间。
trace.show_prefix 如果设置为是,将在表格中显示常见的字符串前缀。默认情况下,会移除像 “MAP_SHARED” 这样的事物中的常见前缀,只显示 “SHARED”。
trace.show_timestamp 显示系统调用开始的时间戳。
trace.show_zeros 不压制等于零的系统调用参数。
trace.tracepoint_beautifiers 使用 “libtraceevent” 来使用该库增强跟踪点参数,“libbeauty”(默认)用于在类似 strace 的 sys_enter+sys_exit 行中使用相同的参数美化器。
3.28 ftrace参数(ftrace.*)
ftrace.* 和 ftrace.tracer 是 perf config 中的配置选项,可以用于在既未指定 -G 也未指定 -F 选项时选择默认的跟踪器。可能的值有 function 和 function_graph。
在 perf 工具中,function 跟踪器会记录所有的函数调用,而 function_graph 跟踪器则会记录函数调用的层级关系。你可以根据需要选择合适的跟踪器作为默认设置。
3.29 llvm参数(llvm.*)
llvm.* 和 llvm.clang-path 是 perf config 中的配置选项,用于指定 clang 的路径。如果省略,将从 $PATH 中搜索。
llvm.clang-bpf-cmd-template 是命令行模板。下面的行显示其默认值。环境变量用于传递选项。
"$CLANG_EXEC -DKERNEL -DNR_CPUS=$NR_CPUS " \
"-DLINUX_VERSION_CODE=$LINUX_VERSION_CODE " \
"$CLANG_OPTIONS $PERF_BPF_INC_OPTIONS $KERNEL_INC_OPTIONS " \
"-Wno-unused-value -Wno-pointer-sign " \
"-working-directory $WORKING_DIR " \
"-c \"$CLANG_SOURCE\" -target bpf $CLANG_EMIT_LLVM -O2 -o - $LLVM_OPTIONS_PIPE"
llvm.clang-opt 是传递给 clang 的选项。
llvm.kbuild-dir 是 kbuild 目录。如果未设置,使用 /lib/modules/uname -r/build。如果故意设置为 “”,则跳过内核头文件自动检测器。
llvm.kbuild-opts 是在检测内核头文件选项时传递给 make 的选项。
llvm.dump-obj 启用 perf dump 由 LLVM 编译的 BPF 对象文件。
llvm.opts 是传递给 llc 的选项。
这些选项为 perf 工具提供了灵活的配置,可以灵活地根据需要设置编译选项,对 BPF 程序进行定制化的编译和调试。
3.30 其他参数
samples.* 和 samples.context 是 perf config 中的配置选项,用于在 perf report sample context 浏览器中定义显示样本周围多少 ns 的时间。
scripts.* 任何选项定义了一个脚本,该脚本被添加到交互式 perf 浏览器的脚本菜单中,其输出被显示。选项的名称是名称,值是脚本命令行。脚本接收与完整的 perf 脚本相同的选项,特别是 -i perfdata 文件,--cpu,--tid。
convert.* 和 convert.queue-size 限制了 ordered_events 队列的大小,因此我们可以控制没有适当结束轮次事件的 perf 数据文件的分配大小。
stat.* 和 stat.big-num(布尔值)改变 “–big-num” 的默认值。要使 “–no-big-num” 成为默认值,设置 “stat.big-num=false”。
intel-pt.*、intel-pt.cache-divisor、intel-pt.mispred-all 如果设置,Intel PT 解码器将在所有分支上设置 mispred 标记。
intel-pt.max-loops 如果设置且非零,是在不消耗任何跟踪包的情况下解码的最大无条件分支数。如果超过最大值,将会有一个 “Never-ending loop” 错误。默认值是 100000。
auxtrace.* 和 auxtrace.dumpdir 仅适用于 s390。可以使用此选项更改保存辅助跟踪缓冲区的目录。例如,auxtrace.dumpdir=/tmp。如果目录不存在或文件类型错误,将使用当前目录。
itrace.* 和 debug-log-buffer-size 使用选项 --itrace=d+e 时要输出的日志大小(以字节为单位)。参考 perf-script(1) 或 perf-report(1) 的 itrace 选项。默认值是 16384。
daemon.* 和 daemon.base 是守护程序数据的基础路径。所有会话数据都存储在此路径下。
session-<NAME>.* 和 session-<NAME>.run 为守护程序定义新的记录会话。值是没有记录关键字的记录命令行。
相关文章:
配置)
Linux之perf(7)配置
Linux之perf(7)配置类命令 Author:Onceday Date:2023年9月23日 漫漫长路,才刚刚开始… 注:该文档内容采用了GPT4.0生成的回答,部分文本准确率可能存在问题。 参考文档: Tutorial - Perf Wiki (kernel.org)perf(1)…...
14:00面试,14:06就出来了,问的问题过于变态了。。。
从小厂出来,没想到在另一家公司又寄了。 到这家公司开始上班,加班是每天必不可少的,看在钱给的比较多的份上,就不太计较了。没想到5月一纸通知,所有人不准加班,加班费不仅没有了,薪资还要降40%…...
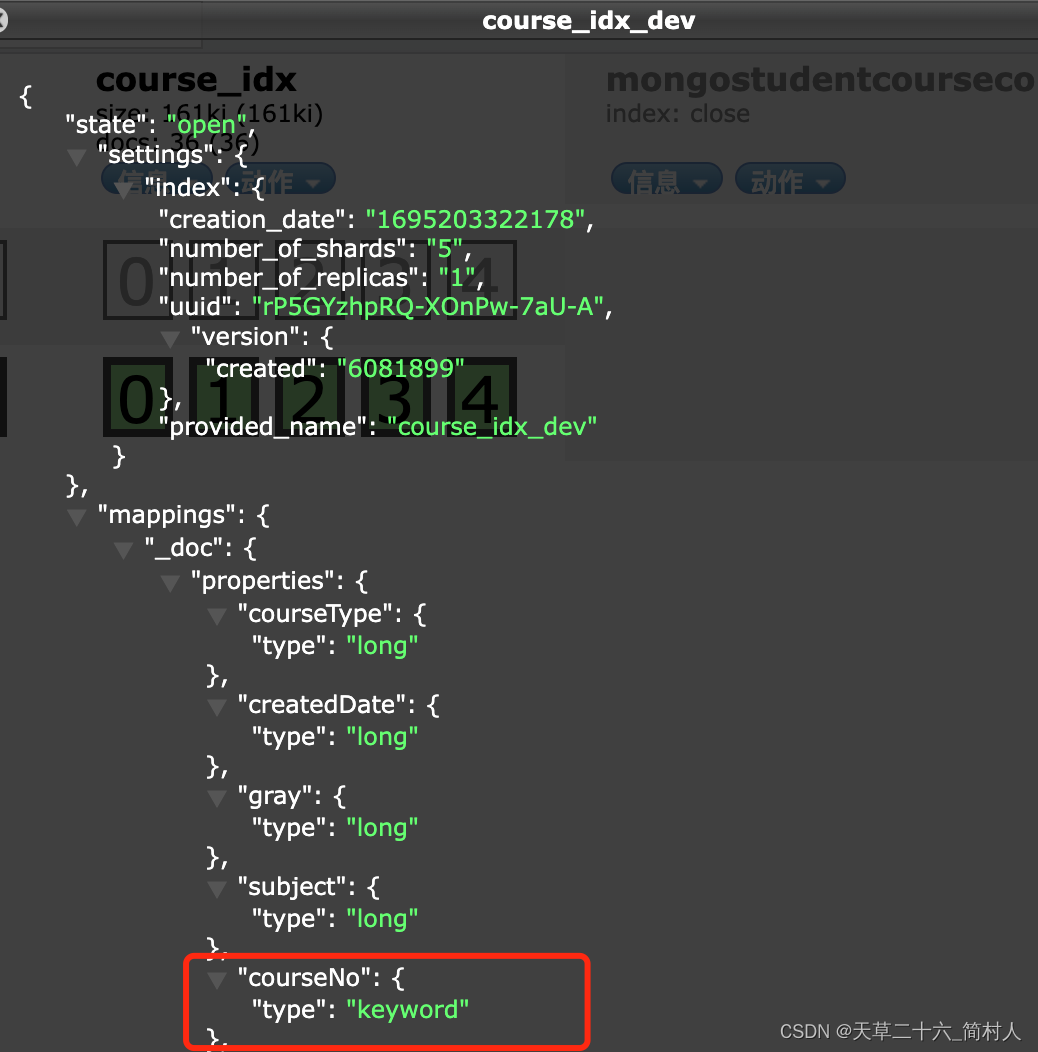
JPA的注解@Field指定为Keyword失败,导致查询不到数据
一、背景 使用 jpa 对es操作,查询条件不生效,需求是批量查询课程编号。说白了,就是一个In集合的查询。在es里,如果是精准匹配是termQuery,比如: queryBuilder.filter(QueryBuilders.termQuery(“schoolId…...

多线程带来的的风险-线程安全
多线程带来的的风险-线程安全 ~~ 多线程编程中,最难的地方,也是一个最重要的地方,还是一个最容易出错的地方,更是一个面试中特别爱考的地方.❤️❤️❤️ 线程安全的概念 万恶之源,罪魁祸首是多线程的抢占式执行,带来的随机性.~~😕😕&…...

Kafka 面试题
Kafka 面试题 Q:讲一下Kafka。 Kafka 入门一篇文章就够了 Kafka的简单理解 Q:消息队列,有哪些使用场景及用途? 解耦,削峰,限流。 Q:Kafka相对其他消息队列,有什么特点? 持久化:Kafka的持久化…...
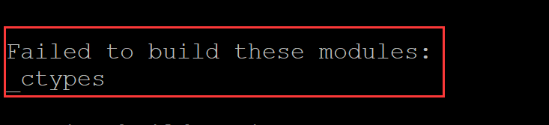
离线部署 python 3.x 版本
文章目录 离线部署 python 3.x 版本1. 下载版本2. 上传到服务器3. 解压并安装4. 新建软连信息5. 注意事项 离线部署 python 3.x 版本 1. 下载版本 python 各版本下载地址 本次使用版本 Python-3.7.0a2.tgz # linux 可使用 wget 下载之后上传到所需服务器 wget https://www.py…...

Java 获取豆瓣电影TOP250
对于爬虫,Java并不是最擅长的,但是也可以实现,此次主要用到的包有hutool和jsoup。 hutool是一个Java工具包,它简化了Java的各种API操作,包括文件操作、类型转换、HTTP、日期处理、JSON处理、加密解密等。它的目标是使…...
)
笔试面试相关记录(5)
(1)不包含重复字符的最长子串的长度 #include <iostream> #include <string> #include <map>using namespace std;int getMaxLength(string& s) {int len s.size();map<char, int> mp;int max_len 0;int left 0;int i …...
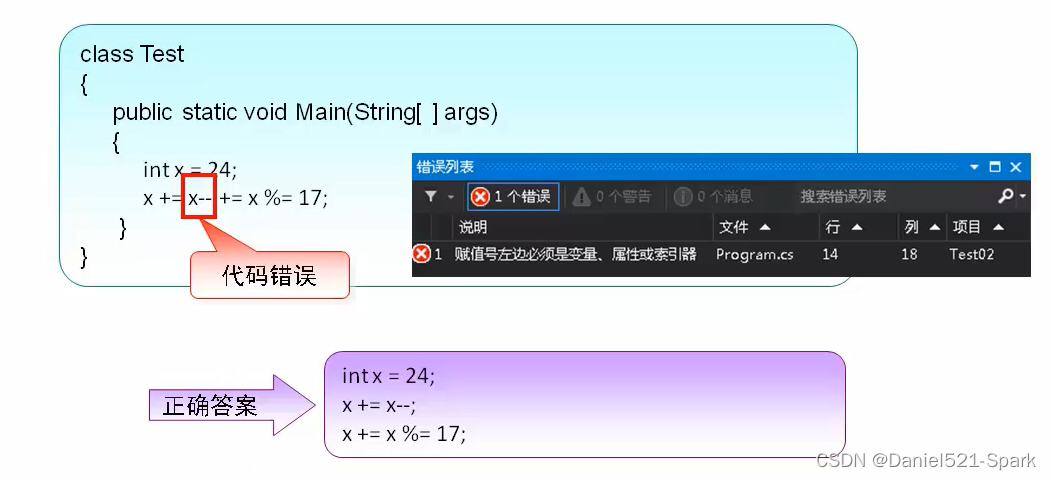
四、C#—变量,表达式,运算符(2)
🌻🌻 目录 一、表达式1.1 什么是表达式1.2 表达式的基本组成 二、运算符2.1 算术运算符2.1.1 使用 / 运算符时的注意事项2.1.2 使用%运算符时的注意事项 2.2 赋值运算符2.2.1 简单赋值运算符2.2.2 复合赋值运算符 2.3 关系运算符2.4 逻辑运算符2.4.1 逻辑…...
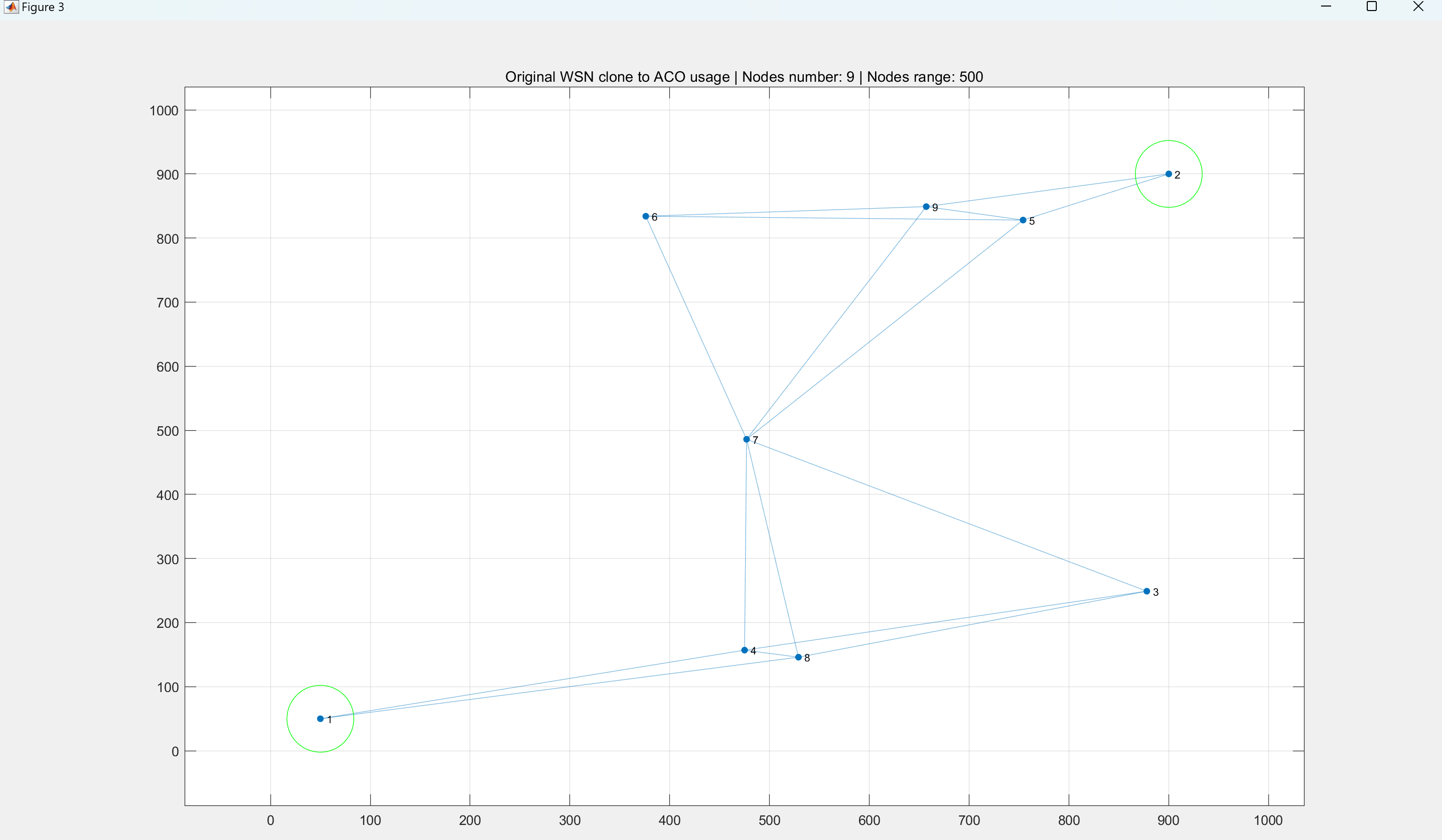
【WSN】基于蚁群算法的WSN路由协议(最短路径)消耗节点能量研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
JVM的内存分配及垃圾回收
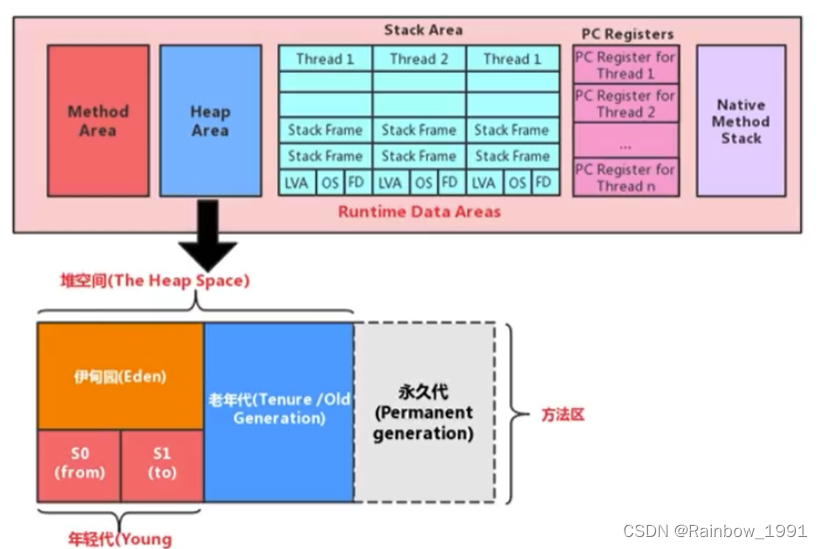
内存分配 在了解Java的内存管理前,需要知道JVM中的内存分配。 栈 存储局部变量。在方法的定义中或在方法中声明的变量为局部变量;栈内存中的数据在该方法结束(返回或抛出异常或方法体运行到最后)时自动释放栈中存放的数据结构为…...

Python实现查询一个文件中的pdf文件中的关键字
要求,查询一个文件中的pdf文件中的关键字,输出关键字所在PDF文件的文件名及对应的页数。 import os import PyPDF2def search_pdf_files(folder_path, keywords):# 初始化结果字典,以关键字为键,值为包含关键字的页面和文件名列表…...
【计算机网络笔记一】网络体系结构
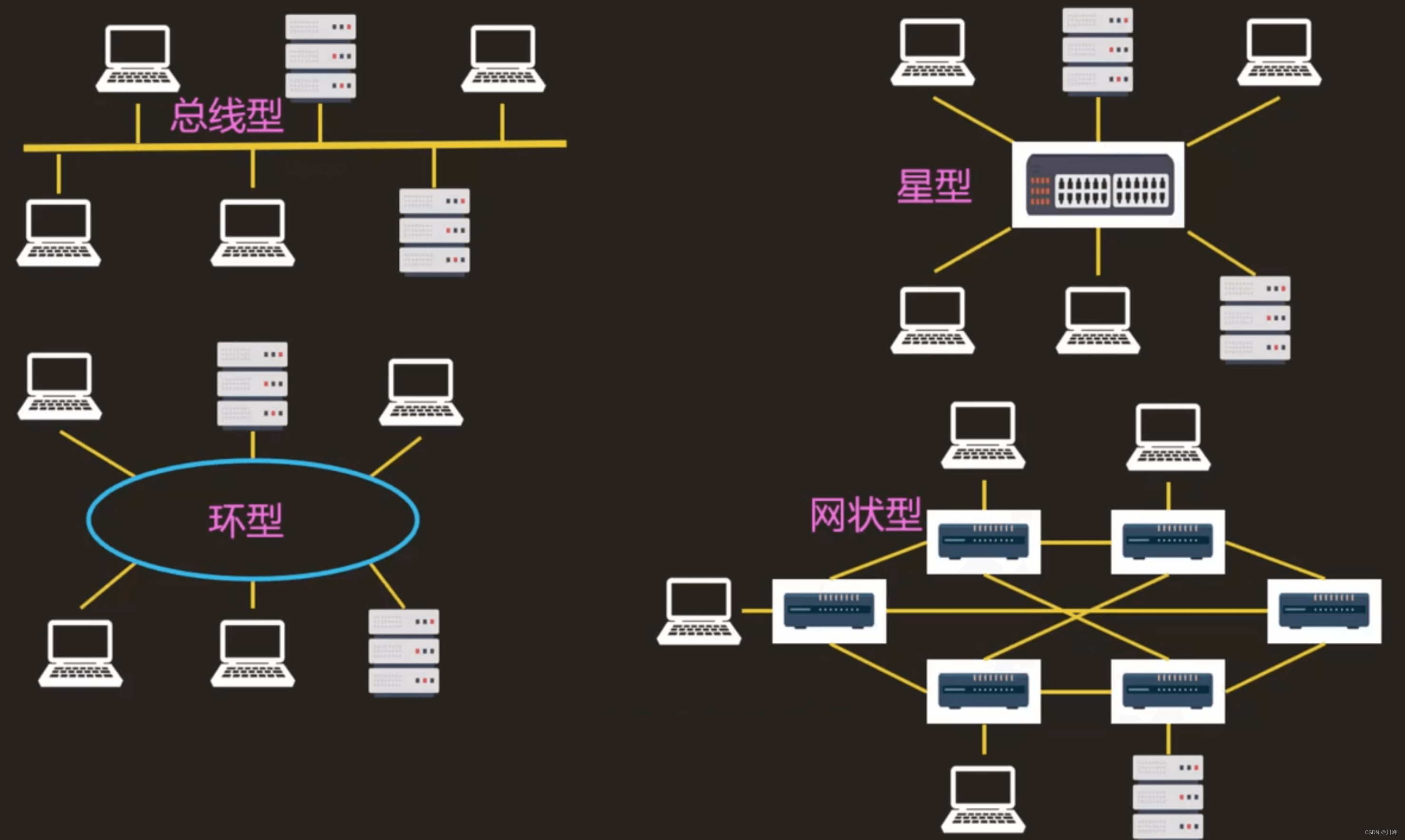
IP和路由器概念 两台主机如何通信呢? 首先,主机的每个网卡都有一个全球唯一地址,MAC 地址,如 00:10:5A:70:33:61 查看 MAC 地址: windows: ipconfig / alllinux:ifconfig 或者 ip addr 同一个网络的多…...

硕士应聘大专老师
招聘信息 当地人社局、学校(官方) 公众号(推荐): 辅导员招聘 厦门人才就业信息平台 高校人才网V 公告出完没多久就要考试面试,提前联系当地院校,问是否招人。 校招南方某些学校会直接去招老师。…...

Gram矩阵
Gram矩阵如何计算 Gram 矩阵是由一组向量的内积构成的矩阵。如果你有一组向量 v 1 , v 2 , … , v n v_1, v_2, \ldots, v_n v1,v2,…,vn,Gram 矩阵 G G G 的元素 G i j G_{ij} Gij 就是向量 v i v_i vi 和向量 v j v_j vj 的内积。数学上&#x…...
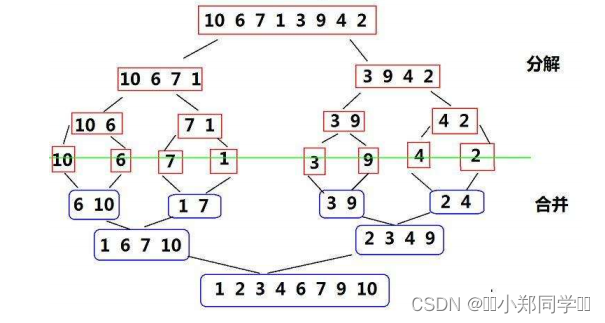
【数据结构】七大排序算法详解
目录 ♫什么是排序 ♪排序的概念 ♪排序的稳定性 ♪排序的分类 ♪常见的排序算法 ♫直接插入排序 ♪基本思想 ♪算法实现 ♪算法稳定性 ♪时间复杂度 ♪空间复杂度 ♫希尔排序 ♪基本思想 ♪算法实现 ♪算法稳定性 ♪时间复杂度 ♪空间复杂度 ♫直接选择排序 ♪基本思想 ♪算法…...

OpenCV之VideoCapture
VideoCaptrue类对视频进行读取操作以及调用摄像头。 头文件: #include <opencv2/video.hpp> 主要函数如下: 构造函数 C: VideoCapture::VideoCapture(); C: VideoCapture::VideoCapture(const string& filename); C: VideoCapture::Video…...

ESP32微控制器与open62541库: 详细指南实现OPC UA通信协议_C语言实例
1. 引言 在现代工业自动化和物联网应用中,通信协议起着至关重要的作用。OPC UA(开放平台通信统一架构)是一个开放的、跨平台的通信协议,被广泛应用于工业4.0和物联网项目中。本文将详细介绍如何在ESP32微控制器上使用C语言和open…...
怎样快速打开github.com
访问这个网站很慢是因为有DNS污染,被一些别有用心的人搞了鬼了, 可以使用火狐浏览器开启火狐浏览器的远程dns解析就可以了.我试了一下好像单独这个办法不一定有用,要结合修改hosts文件方法,双重保障 好像就可以了...

【C#】.Net基础语法二
目录 一、字符串(String) 【1.1】字符串创建和使用 【1.2】字符串其他方法 【1.3】字符串格式化的扩展方法 【1.4】字符串空值和空对象比较 【1.5】字符串中的转移字符 【1.6】大写的String和小写的string 【1.7】StringBuilder类的重要性 二、数组(Array) 【2.1】声…...

NanoHttpd POST 请求中文乱码问题解决方案
解决方案 推荐做法:服务器端修正 在请求处理的 serve() 方法中,在调用 parseBody() 之前,显式确保 Content-Type 包含 charsetUTF-8: Override public Response serve(IHTTPSession session) {Map<String, String> files n…...

全自动洗衣机组态王与三菱PLC联机及仿真探索
全自动洗衣机组态王6.53,6.60和三菱PLC联机和仿真程序包最近在研究自动化控制领域相关内容,接触到了全自动洗衣机组态王 6.53、6.60 与三菱 PLC 的联机以及仿真程序包,感觉很有意思,今天就来和大家分享分享。 一、组态王与三菱 PLC 联机的意义…...

Keepalived实战:用MySQL主从高可用方案解决你的数据库单点故障
Keepalived与MySQL主从架构:构建零宕机数据库高可用方案 当数据库成为业务系统的核心支柱时,单点故障可能意味着灾难性的业务中断。我曾亲历一次凌晨3点的数据库故障,整个电商平台瘫痪两小时,损失超过七位数。这次教训让我深刻认识…...

OpenClaw部署指南:2026年百度云部署OpenClaw、配置百炼API、集成Skill、接入微信/QQ/飞书/钉钉步骤
OpenClaw部署指南:2026年百度云部署OpenClaw、配置百炼API、集成Skill、接入微信/QQ/飞书/钉钉步骤。OpenClaw(原Clawdbot)作为2026年主流的AI自动化助理平台,可通过阿里云轻量服务器实现724小时稳定运行,并快速接入钉…...
)
线程池项目(1)
推荐去看施磊老师的课程 需要课程或者代码的可以评论,看到会回复的,免费的并发与并行定义并发:多个线程在单核上轮流占用 CPU 时间片,物理上串行执行,但由于时间片较短,看起来像是同时执行。并行:多个线程在多核或多 C…...

OpenClaw+千问3.5-9B电商运营:自动生成商品详情与回复咨询
OpenClaw千问3.5-9B电商运营:自动生成商品详情与回复咨询 1. 为什么选择OpenClaw千问3.5-9B做电商自动化 去年双十一期间,我负责运营的个人店铺单日咨询量突破300条,手忙脚乱到凌晨三点还在回复客户问题。正是这段经历让我开始寻找自动化解…...

天华新能年营收75亿:净利同比降56% CFO离职 宁德时代是二股东
雷递网 雷建平 4月3日苏州天华新能源科技股份有限公司(简称:“天华新能”)日前发布财报。财报显示,天华新能2025年营收为75亿元。天华新能最近两年利润处于持续下滑状态,其中,2025年净利下降55.6%ÿ…...

RemotelyAnywhere远程桌面无法使用鼠标操作
问题描述RemotelyAnywhere远程桌面无法使用鼠标操作,点击一下就刷新页面,无法输入密码解决方案1、使用360浏览器打开页面2、使用兼容模式3、启用系统的TLS 1.2支持 (解决核心矛盾)这是最关键的一步,用来强制让电脑支持相对较新的TLS 1.2协议&…...

No data to show!vtune分析程序性能有结果无数据
使用vtune分析程序在保证程序复杂度能被采集数据,但是result页面没有数据显示,只有no data to show, the data is not sufficient.最后找到原因是使用的编译器vs的符号解释器与vtune有冲突,改用vs code成功出数据。为了让vtune成功显示数据用…...

OpenClaw+千问3.5-9B:自动化周报生成与数据分析
OpenClaw千问3.5-9B:自动化周报生成与数据分析 1. 为什么需要自动化周报 每周五下午三点,我的日历总会准时弹出提醒:"该写周报了"。这个重复了三年多的机械动作,消耗了我大量本该用于创造性工作的时间。直到上个月&am…...