MySQL的高级SQL语句
目录
一、高级SQL语句
1、select 查询表中一个或多个字段的数据
2、distinct 不显示重复的数据记录
3、where 有条件查询
4、and与or 且与或
5、in 显示在某个范围值内 的字段的信息
6、between 显示两个值范围内的数据记录
7、order by 对字段进行排序
8、group by 对字段进行分组汇总
9、having 用于过滤由group by语句返回的记录集
10、like 模糊查询
11、别名 字段别名,表格别名
12、exists 用来测试内查询有没有产生任何结果
二、多表查询
内连接(inner join)
左连接(left join)
右连接(right join)
联集 ( union | union all )
取两个表无交集的值
1、取左表中存在,而右表中不存在的数据
2、取右表中存在,而左表中不存在的数据
三、函数
1、数学函数
2、聚合函数
3、字符串函数
四、视图
1、创建视图
2、删除视图
五、case语句及正则表达匹配
1、case语句
2、空值(NULL)与无值(“”)的区别
3、正则匹配
六、存储过程
1、存储过程的优点
2、创建存储过程
3、存储过程中的参数
1)IN输入参数
2)OUT输出参数
3)INOUT输入输出参数
4、删除存储过程
5、存储过程的控制语句
1)条件语句
2)循环语句
一、高级SQL语句
1、select 查询表中一个或多个字段的数据
语法:select 字段1,字段2,... from 表名;
例:select store_name from store_info;
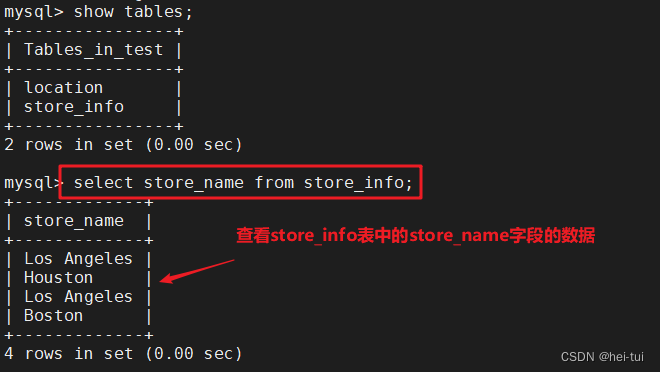
2、distinct 不显示重复的数据记录
语法:select distinct 字段 from 表名;
例:select distinct store_name from store_info;

3、where 有条件查询
语法:select 字段 from 表名 where 条件表达式;
例:select store_name from store_info where sales>1000;

4、and与or 且与或
语法:select 字段 from 表名 where 条件1 and|or 条件2;
例:select store_name from store_info where sales >200 and sales <1000;


5、in 显示在某个范围值内 的字段的信息
语法:select 字段 from 表名 where 字段 in (值1,值2,....);
例:select store_name from store_info where store_name ('Los Angeles','Houston');

6、between 显示两个值范围内的数据记录
语法:select 字段 from 表名 where 字段 between 值1 and 值2;
例:select store_name,sales from store_info where sales between 300 and 1000;

7、order by 对字段进行排序
默认升序 (asc) 的排序方式,使用desc实现降序排序
语法:select 字段 from 表名 [ where 条件 ] order by 字段 asc|desc;
例:select * from store_info order by sales desc;

8、group by 对字段进行分组汇总
语法:select 字段 from 表名 group by 字段;
例:select store_name,sum(sales),date from store_info group by store_name;

9、having 用于过滤由group by语句返回的记录集
通俗来说,就是用来过滤出符合条件的group by语句所返回的内容
语法:select 字段 from 表名 group by 字段 having 条件表达式; #条件表达式必须是使用函数的条件表达式
例: select store_name,sum(sales),date from store_info group by store_name having sum(sales) > 500;

10、like 模糊查询
使用通配符进行模糊查询
通配符
%:百分号表示零个、一个或多个字符
_:下划线表示单个字符
语法:select 字段 from 表名 where 字段 like '模糊查询的内容';
例:select store_name from store_info where store_name like '_os%';

11、别名 字段别名,表格别名
语法:select 别名2.字段 [as] 别名1 from 表名 [as] 别名2;
例:select A.store_name name from store_info as A ;

12、exists 用来测试内查询有没有产生任何结果
类似布尔值是否为真,如果有的话,系统就会执行外查询中的SQL语句。若是没有的话,那整个 SQL 语句就不会产生任何结果。
语法:select 字段1 from 表1 where exists (select 字段2 from 表2 where 条件表达式 )
例:SELECT SUM(Sales) FROM Store_Info WHERE EXISTS (SELECT * FROM location WHERE Region = 'West');

二、多表查询
多表查询方式:内连接、左连接、右连接、联集
内连接(inner join)
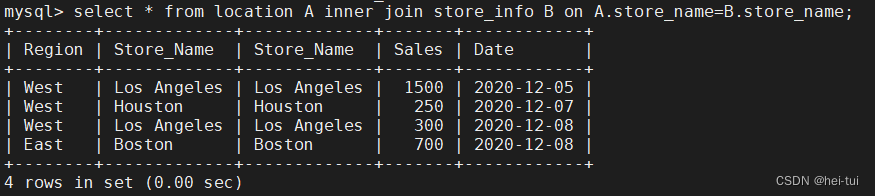
语法:select * from 表1 inner join 表2 on 表1.字段=表2.字段
例:select * from location A inner join store_info B on A.store_name=B.store_name;
左连接(left join)
语法:select * from 表1 left join 表2 on 表1.字段=表2.字段
例:select * from location A left join store_info B on A.store_name=B.store_name;

右连接(right join)
语法:select * from 表1 right join 表2 on 表1.字段=表2.字段
例:select * from location A right join store_info B on A.store_name=B.store_name;

联集 ( union | union all )
语法:[SELECT 语句 1] UNION [SELECT 语句 2];
[SELECT 语句 1] UNION ALL [SELECT 语句 2];
例:SELECT Store_Name FROM location UNION SELECT Store_Name FROM store_info;
例:SELECT Store_Name FROM location UNION ALL SELECT Store_Name FROM store_info;

取两个表无交集的值
1、取左表中存在,而右表中不存在的数据
语法:select 字段 from 左表 where 字段 not in (select 字段 from 右表)
如:select store_name from location where store_name not in (select store_name from store_info);

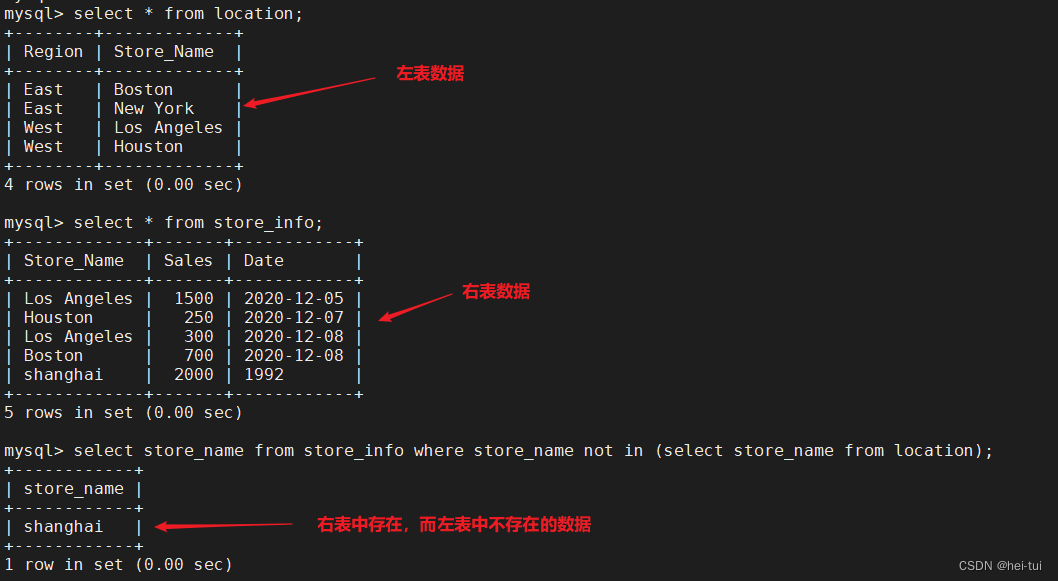
2、取右表中存在,而左表中不存在的数据
语法:select 字段 from 右表 where 字段 not in (select 字段 from 左表)
如:select store_name from store_info where store_name not in (select store_name from location);
三、函数
1、数学函数
| 函数 | 解释 |
| abs(x) | 返回 x 的绝对值 |
| rand() | 返回 0 到 1 的随机数 |
| mod(x,y) | 返回 x 除以 y 以后的余数 |
| power(x,y) | 返回 x 的 y 次方 |
| round(x) | 返回离 x 最近的整数 |
| round(x,y) | 保留 x 的 y 位小数四舍五入后的值 |
| sqrt(x) | 返回 x 的平方根 |
| truncate(x,y) | 返回数字 x 截断为 y 位小数的值 |
| ceil(x) | 返回大于或等于 x 的最小整数 |
| floor(x) | 返回小于或等于 x 的最大整数 |
| greatest(x1,x2...) | 返回集合中最大的值,也可以返回多个字段的最大的值 |
| least(x1,x2...) | 返回集合中最小的值,也可以返回多个字段的最小的值 |
例子:
SELECT abs(-1), rand(), mod(5,3), power(2,3), round(1.89);
SELECT round(1.8937,3), truncate(1.235,2), ceil(5.2), floor(2.1), least(1.89,3,6.1,2.1);

2、聚合函数
| 函数 | 解释 |
| avg() | 返回指定列的平均值 |
| conut() | 返回指定列中非 NULL 值的个数 |
| min() | 返回指定列的最小值 |
| max() | 返回指定列的最大值 |
| sum() | 返回指定列的所有值之和 |
例1:SELECT avg(Sales) FROM store_info;

例2:SELECT count(Store_Name) FROM store_info;

例3:SELECT count(DISTINCT Store_Name) FROM store_info;

例4:SELECT max(Sales) FROM store_info;

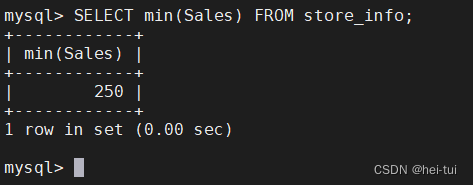
例5:SELECT min(Sales) FROM store_info;
例6:SELECT sum(Sales) FROM store_info;

3、字符串函数
| 函数 | 解释 |
| trim() | 返回去除指定格式的值 |
| concat(x,y) | 将提供的参数 x 和 y 拼接成一个字符串 |
| substr(x,y) | 获取从字符串 x 中的第 y 个位置开始的字符串,跟substring()函数作用相同 |
| substr(x,y,z) | 获取从字符串 x 中的第 y 个位置开始长度为 z 的字符串 |
| length(x) | 返回字符串 x 的长度 |
| replace(x,y,z) | 将字符串 z 替代字符串 x 中的字符串 y |
| upper(x) | 将字符串 x 的所有字母变成大写字母 |
| lower(x) | 将字符串 x 的所有字母变成小写字母 |
| left(x,y) | 返回字符串 x 的前 y 个字符 |
| right(x,y) | 返回字符串 x 的后 y 个字符 |
| repeat(x,y) | 将字符串 x 重复 y 次 |
| space(x) | 返回 x 个空格 |
| strcmp(x,y) | 比较 x 和 y,返回的值可以为-1,0,1 |
| reverse(x) | 将字符串 x 反转 |
trim()函数
语法:SELECT TRIM ([ [位置] [要移除的字符串] FROM ] 字符串);
#[位置]:的值可以为 LEADING (起头), TRAILING (结尾), BOTH (起头及结尾)。
#[要移除的字符串]:从字串的起头、结尾,或起头及结尾移除的字符串。缺省时为空格。例1:SELECT TRIM(LEADING 'Ne' FROM 'New York');

concat () 函数
#如sql_mode开启了PIPES_AS_CONCAT,"||"视为字符串的连接操作符而非或运算符,和字符串的拼接函数Concat相类似,这和Oracle数据库使用方法一样的
例2:SELECT concat(Region, Store_Name) FROM location WHERE Store_Name = 'Boston';
例3:SELECT Region || ' ' || Store_Name FROM location WHERE Store_Name = 'Boston';

substr () 函数
例4:SELECT substr(Store_Name,3) FROM location WHERE Store_Name = 'Los Angeles';
例5:SELECT substr(Store_Name,2,4) FROM location WHERE Store_Name = 'New York';

length() 函数
例6:SELECT Region,length(Store_Name) FROM location;

replace () 函数
例7:SELECT REPLACE(Region,'ast','astern')FROM location;

四、视图
视图,可以被当作是虚拟表或存储查询。
视图跟表格的不同是,表格中有实际储存数据记录,而视图是建立在表格之上的一个架构,它本身并不实际储存数据记录。
临时表在用户退出或同数据库的连接断开后就自动消失了,而视图不会消失。
视图不含有数据,只存储它的定义,它的用途一般可以简化复杂的查询。比如你要对几个表进行连接查询,而且还要进行统计排序等操作,写SQL语句会很麻烦的,用视图将几个表联结起来,然后对这个视图进行查询操作,就和对一个表查询一样,很方便。
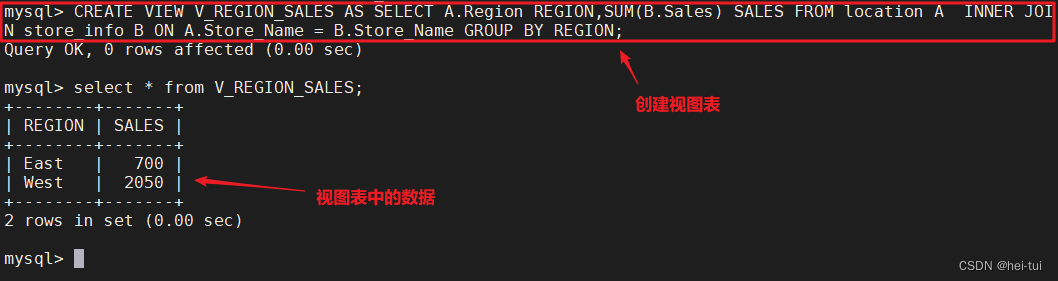
1、创建视图
语法:create view 视图表名 as select语句;
如:CREATE VIEW V_REGION_SALES AS SELECT A.Region REGION,SUM(B.Sales) SALES FROM location A INNER JOIN Store_Info B ON A.Store_Name = B.Store_Name GROUP BY REGION;
SELECT * FROM V_REGION_SALES;
2、删除视图
语法:drop view 视图表名;
如:DROP VIEW V_REGION_SALES;

注意:在创建视图表时,后面的select语句所查询的字段是原表中的字段时,视图表中的数据是可以修改的;
若在创建视图表时,后面的select语句所查询的字段是通过聚合函数处理过的或被处理过的数据,视图表中的数据是不可以修改的。
五、case语句及正则表达匹配
1、case语句
case是 SQL 用来做为 IF-THEN-ELSE 之类逻辑的关键字
语法:
SELECT CASE ("字段名")
WHEN "条件1" THEN "结果1"
WHEN "条件2" THEN "结果2"
...
[ELSE "结果N"]
END
FROM "表名";
如: select store_name,case store_name
-> when 'Los Angeles' then sales*2
-> when 'Boston' then 2000
-> else sales
-> end
-> "New Sales",date from store_info;

2、空值(NULL)与无值(“”)的区别
- 无值的长度为 0,不占用空间的;而 NULL 值的长度是 NULL,是占用空间的。
- IS NULL 或者 IS NOT NULL,是用来判断字段是不是为 NULL 或者不是 NULL,不能查出是不是无值的。
- 无值的判断使用=''或者<>''来处理。<> 代表不等于。
- 在通过 count()指定字段统计有多少行数时,如果遇到 NULL 值会自动忽略掉,遇到无值会加入到记录中进行计算。
3、正则匹配
| 匹配模式 | 描述 |
| ^ | 匹配文本的开始字符 ‘^bd’ 匹配以 bd 开头的字符串 |
| $ | 匹配文本的结束字符 ‘qn$’ 匹配以 qn 结尾的字符串 |
| . | 匹配任何单个字符 ‘s.t’ 匹配任何 s 和 t 之间有一个字符的字符串 |
| * | 匹配零个或多个在它前面的字符 ‘fo*t’ 匹配 t 前面有任意个 o |
| + | 匹配前面的字符 1 次或多次 ‘hom+’ 匹配以 ho 开头,后面至少一个m 的字符串 |
| 字符串 | 匹配包含指定的字符串 ‘clo’ 匹配含有 clo 的字符串 |
| p1|p2 | 匹配 p1 或 p2 ‘bg|fg’ 匹配 bg 或者 fg |
| [abcd] | 匹配字符集合中的任意一个字符 ‘[abcd]’ 匹配 a 或者 b 或者 c或者d |
| [^abcd] | 匹配不在括号中的任何字符 ‘[^abcd]’ 匹配不包含 a 或者 b或者 c或者d 的字符串 |
| {n} | 匹配前面的字符串 n 次 ‘g{2}’ 匹配含有 2 个 g 的字符串 |
| {n,m} | 匹配前面的字符串至少 n 次,至多m 次 ‘f{1,3}’ 匹配 f 最少 1 次,最多 3 次 |
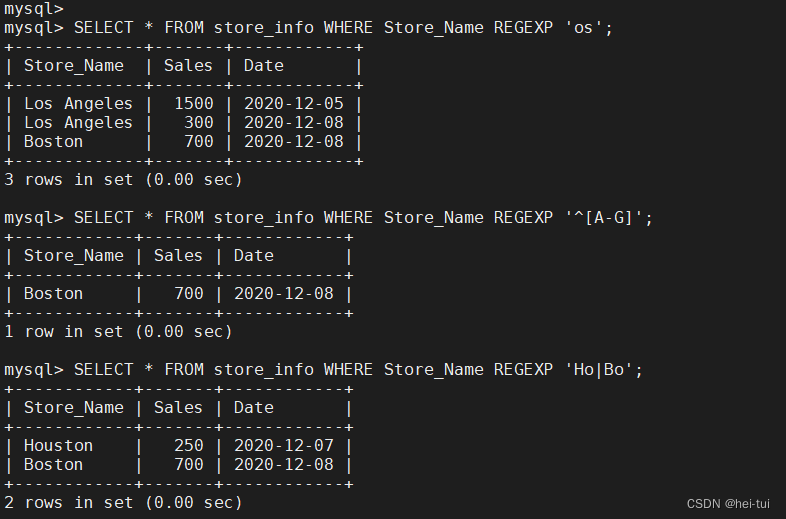
语法:select 字段 from 表名 where 字段 regexp {模式};
如:SELECT * FROM Store_Info WHERE Store_Name REGEXP 'os';
SELECT * FROM Store_Info WHERE Store_Name REGEXP '^[A-G]';
SELECT * FROM Store_Info WHERE Store_Name REGEXP 'Ho|Bo';
六、存储过程
存储过程是一组为了完成特定功能的SQL语句集合。
存储过程在使用过程中是将常用或者复杂的工作预先使用SQL语句写好并用一个指定的名称存储起来,这个过程经编译和优化后存储在数据库服务器中。当需要使用该存储过程时,只需要调用它即可。存储过程在执行上比传统SQL速度更快、执行效率更高。
1、存储过程的优点
1、执行一次后,会将生成的二进制代码驻留缓冲区,提高执行效率
2、SQL语句加上控制语句的集合,灵活性高
3、在服务器端存储,客户端调用时,降低网络负载
4、可多次重复被调用,可随时修改,不影响客户端调用
5、可完成所有的数据库操作,也可控制数据库的信息访问权限
2、创建存储过程
#首先使用delimiter修改语句的结束符,可以是$$,##,!!等自定义的符号delimiter $$#其次开始创建存储过程create procedure 存储过程名()->begin #关键字begin开始->SQL语句序列->end$$ #存储过程的结束语句#最后再将SQL的语句结束符改回来成分号“;”delimiter ;#调用存储过程call 存储过程名#查看存储过程show create peocedure 存储过程名;或show procedure status 存储过程名\G如:
delimiter ##
create procedure proc1()
->begin
->create table t1 (id int,name varchar(20),age int,primary key(id));
->insert into t1 values(1,'张三',18);
->insert into t1 values(2,'李四',19);
->insert into t1 values(3,'王五',20);
->end##
delimiter ;
call proc1();

3、存储过程中的参数
IN 输入参数:表示调用者向过程传入值(传入值可以是字面量或变量)
OUT 输出参数:表示过程向调用者传出值(可以返回多个值)(传出值只能是变量)
INOUT 输入输出参数:既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量)
1)IN输入参数
实例:
delimiter $$
create procedure proc2(in inname char(16))
->begin
->select * from store_info where store_name=inname;
->end$$
delimiter ;
call proc2('Boston');

2)OUT输出参数
实例:
delimiter $$
mysql> create procedure prco3(in inname varchar(20),out outage int)
-> begin
-> select age into outage from t1 where inname=name;
-> end$$
delimiter ;
call proc3('李四',@age);
select @age;

3)INOUT输入输出参数
实例:
delimiter $$
mysql>creater procedure proc4(inout inage int)
->begin
->select age into inage from t1 where age>inage;
->end$$
delimiter ;
set @age=19;
call proc4(@age);
seect @age;

4、删除存储过程
语法:drop procedure if exists 存储过程名;
#仅当存在时删除,不添加 IF EXISTS 时,如果指定的过程不存在,则产生一个错误
实例:
drop procedure if exists prco3;

5、存储过程的控制语句
1)条件语句
if-then-else....end if
实例:
DELIMITER $$
CREATE PROCEDURE proc6(IN pro int)
-> begin
-> declare var int;
-> set var=pro*2;
-> if var>=10 then
-> update t set id=id+1;
-> else
-> update t set id=id-1;
-> end if;
-> end $$delimiter ;
call proc6(6);
select * from t;
2)循环语句
while ... end while
实例:
delimiter $$
create procedure proc7()
->begin
->declare var int(10);
->set var=0;
->create table t2(id int,name char(10));
->while var <5
->do
->insert into t2 values(var,concat('a',var));
->set var=var+1;
->end while;
->end $$delimiter ;
call proc7();
select * from t2;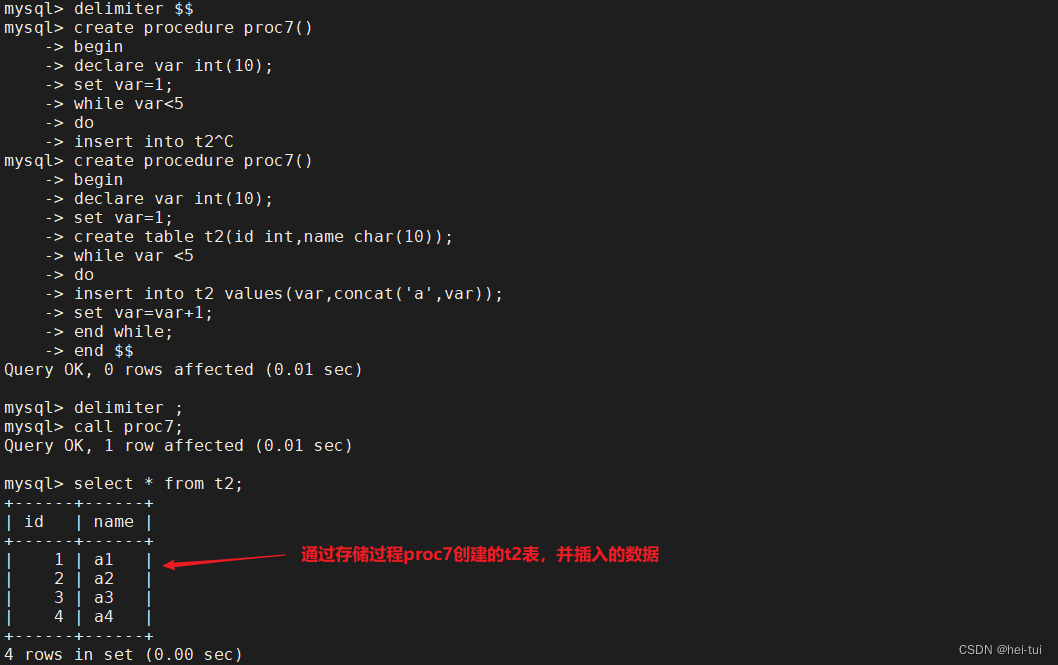
相关文章:
MySQL的高级SQL语句
目录 一、高级SQL语句 1、select 查询表中一个或多个字段的数据 2、distinct 不显示重复的数据记录 3、where 有条件查询 4、and与or 且与或 5、in 显示在某个范围值内 的字段的信息 6、between 显示两个值范围内的数据记录 7、order by 对字…...

基于人脸5个关键点的人脸对齐(人脸纠正)
摘要:人脸检测模型输出人脸目标框坐标和5个人脸关键点,在进行人脸比对前,需要对检测得到的人脸框进行对齐(纠正),本文将通过5个人脸关键点信息对人脸就行对齐(纠正)。 一、输入图像…...

vue3中两个el-select下拉框选项相互影响
vue3中两个el-select下拉框选项相互影响 1、开发需求2、代码2.1 定义hooks文件2.2 在组件中使用 1、开发需求 如图所示,在项目开发过程中,遇到这样一个需求,常规时段中选中的月份在高峰时段中是禁止选择的状态,反之亦然。 2、代…...
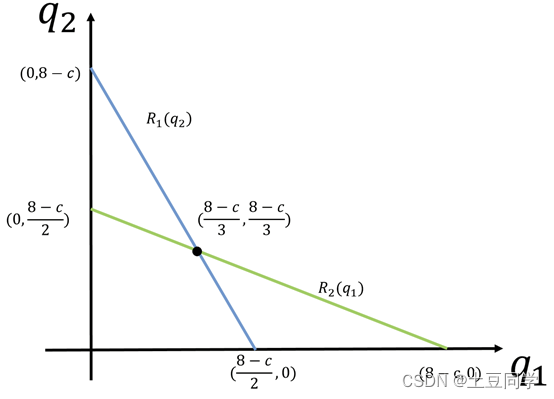
博弈论——反应函数
反应函数 1 引言 谢老师的《经济博弈论》书中对反应函数并没有给出一般笼统的定义,而是将其应用与古诺模型并给出了相关解释:反应函数是指在无限策略的古诺博弈模型中,博弈方的策略有无限多种,因此各个博弈方的最佳对策也有无限…...
UE5读取json文件
一、下载插件 在工程中启用 二、定义读取外部json文件的函数,参考我之前的文章 ue5读取外部文件_艺菲的博客-CSDN博客 三、读取文件并解析为json对象 这里Load Text就是自己定义的函数,ResourceBundle为一个字符串常量,通常是读取的文件夹…...
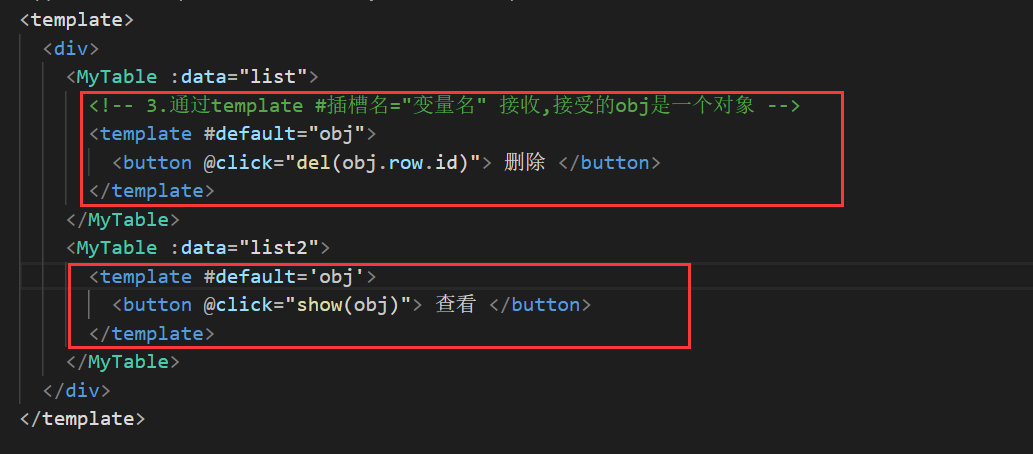
Vue中的插槽--组件复用,内容自定义
插槽 文章目录 插槽插槽-默认插槽插槽-后备内容(设置默认值)插槽-具名插槽插槽–作用域插槽 插槽-默认插槽 作用:让组件内部的一些结构支持自定义 需求:要在页面中显示一个对话框,封装成一个组件(对话框有很多功能是类…...

完全指南:mv命令用法、示例和注意事项 | Linux文件移动与重命名
文章目录 mv命令使用指南1. 简介什么是mv命令?mv命令的作用和功能是什么? 2. 基本用法基本语法格式如何移动文件?如何重命名文件?如何移动和重命名目录? 3. 高级用法使用通配符进行批量移动和重命名使用选项进行文件移…...
gitee生成公钥和远程仓库与本地仓库使用验证
参考文档: https://help.gitee.com/base/account/SSH%E5%85%AC%E9%92%A5%E8%AE%BE%E7%BD%AE(1)通过命令ssh-keygen 生成SSH key -t key类型 -c注释 ssh-keygen -t ed25519 -C "Gitee SSH Key" (2)按三次回车 (3)查看生成的 SSH 公钥和私钥: …...

请求后端接口413
当在进行HTTP请求时出现"413 Request Entity Too Large"错误时,通常是因为请求体的大小超过了服务器的配置限制。这个错误提示表明服务器拒绝接受过大的请求。 此时一般还未到后端服务,是被后端的ngnix代理服务器拦截的,所以可以检…...
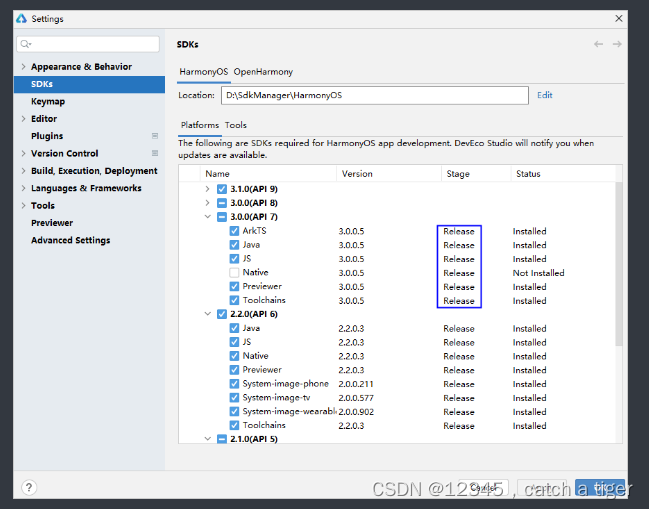
HarmonyOS之 开发环境搭建
一 鸿蒙简介: 1.1 HarmonyOS是华为自研的一款分布式操作系统,兼容Android,但又区别Android,不仅仅定位于手机系统。更侧重于万物物联和智能终端,目前已更新到4.0版本。 1.2 HarmonyOS软件编程语言是ArkTS,…...
QTC++ day12
注册登录界面 widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QIcon> #include <QPushButton> #include <QLineEdit> #include <QLabel> #include <QDebug> #include <QMessageBox>//消息对话框类 #inc…...

Vue3中使用Proxy API取代defineProperty API的原因
目录 一、前言 二、defineProperty API的限制和问题 三、Proxy API的优势和特性 四、Vue3.0中使用Proxy API的原因 五、Proxy API的局限性和注意事项 一、前言 Vue3.0是Vue.js框架的最新版本,它在底层进行了许多重要的改进。其中最引人注目的变化之一是它转而…...
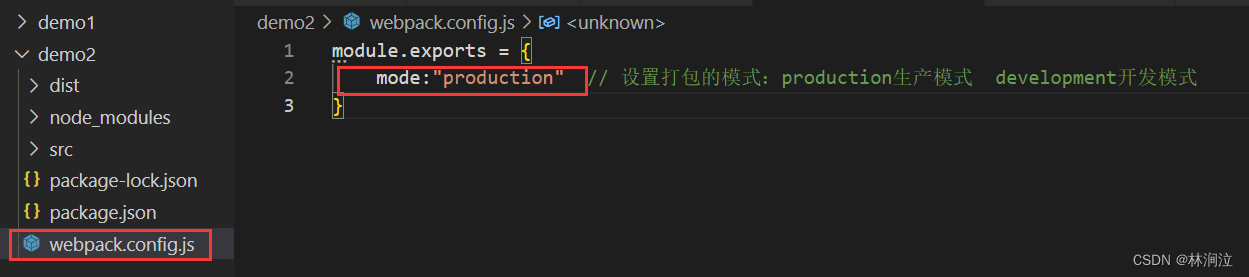
构建工具Webpack简介
一、构建工具 当我们习惯了Node中使用ES模块化编写代码以后,用原生的HTML、CSS、JS这些东西会感觉到各种不便。比如:不能放心的使用模块化规范(浏览器兼容性问题)、即使可以使用模块化规范也会面临模块过多时的加载问题。 这时候…...
Docker部署单点Elasticsearch与Kibana
一 、 创建网络 因为需要部署kibana容器,因此需要让es和kibana容器互联。这里创建一个网络: docker network create es-net # 创建一个网络名称为:es-net 二 、拉取并加载镜像 方式一 docker pull elasticsearch:7.12.1 版本为elasticsearch的7…...
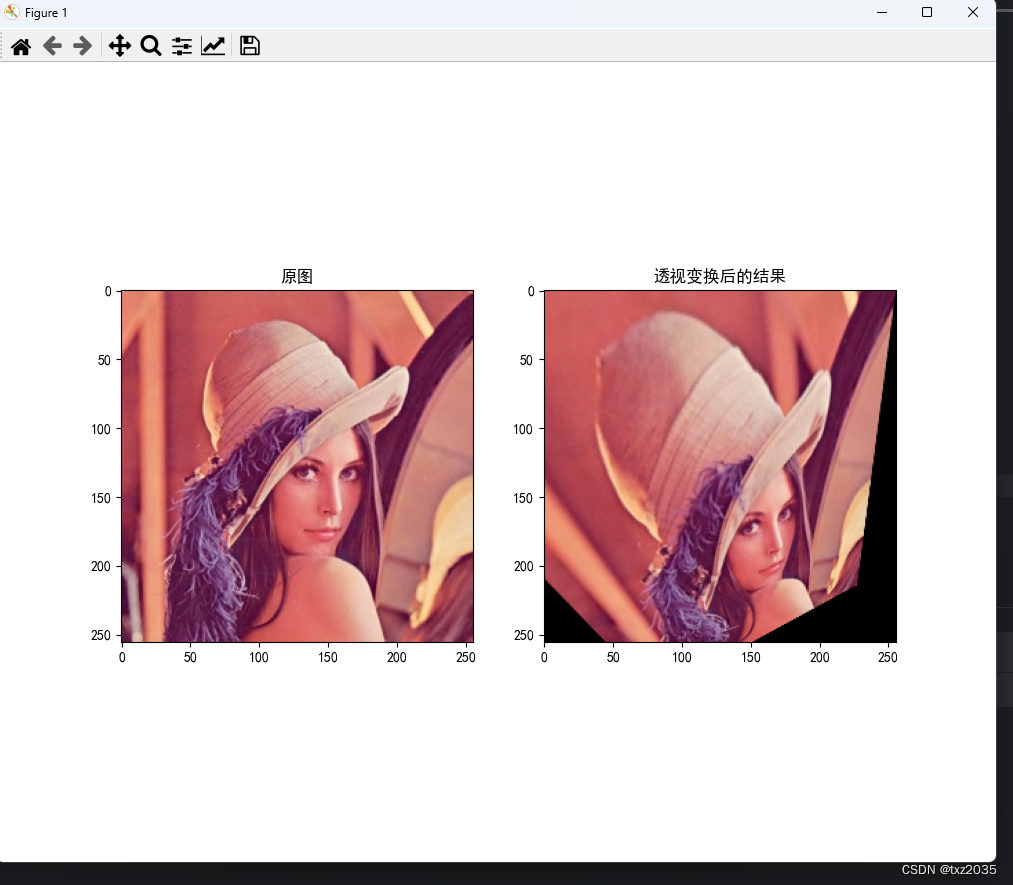
opencv实现仿射变换和透射变换
##1, 什么是仿射变换? 代码实现 import numpy as np import cv2 as cv import matplotlib.pyplot as plt#设置字体 from pylab import mpl mpl.rcParams[font.sans-serif] [SimHei]#图像的读取 img cv.imread("lena.png")#仿射变换 row…...
抖音seo账号矩阵源码系统
1. 开通多个抖音账号,并将它们归纳为一个账号矩阵系统。 2. 建立一个统一的账号管理平台,以便对这些账号进行集中管理,包括账号信息、内容发布、社区交互等。 3. 招募专业的运营团队,对每个账号进行精细化运营,包括内…...

性能优化之防抖
方法1:利用lodash库提供的防抖来处理 方法2:手写一个防抖函数来处理 需求:鼠标在盒子上移动,鼠标停止500ms之后,里面的数字才会变化1 方法一:利用lodash库实现防抖 <!DOCTYPE html> <html lang&…...

postgresql用户和角色
postgresql用户和角色 简述创建角色角色属性登录特权超级用户创建数据库创建角色启动复制密码修改角色属性 对象授权撤销授权组和成员删除角色 简述 PostgreSQL 通过角色的概念来控制数据库的访问权限。角色又包含了两种概念,具有登录 权限的角色称为用户ÿ…...
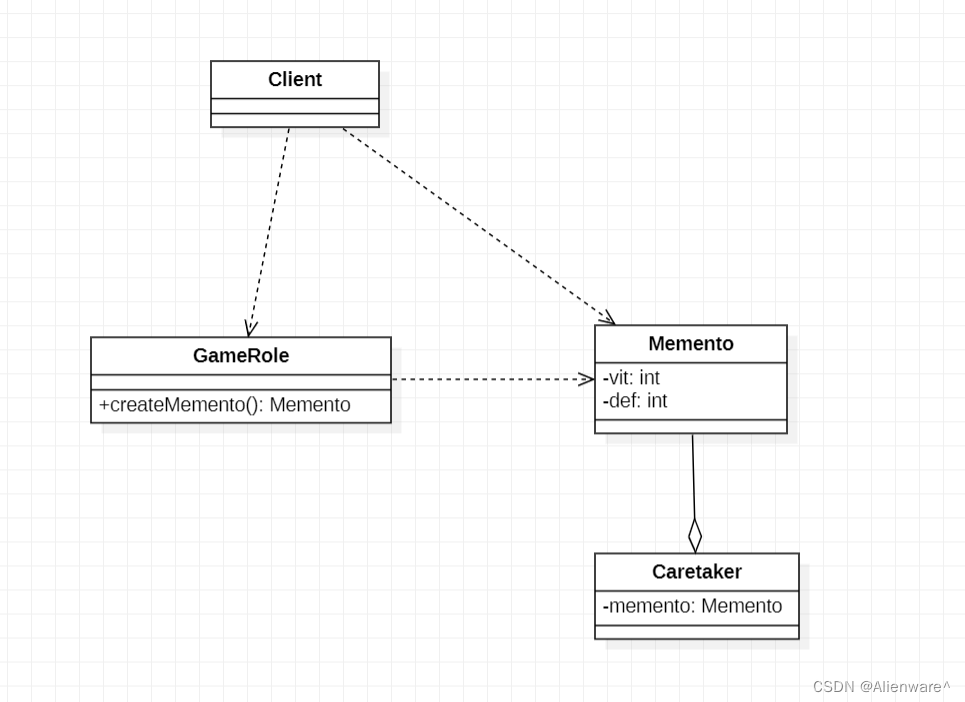
设计模式之备忘录模式
文章目录 游戏角色状态恢复问题传统方案解决游戏角色恢复传统的方式的问题分析备忘录模式基本介绍游戏角色恢复状态实例备忘录模式的注意事项和细节 游戏角色状态恢复问题 游戏角色有攻击力和防御力,在大战 Boss 前保存自身的状态(攻击力和防御力),当大…...
大数据Flink(八十八):Interval Join(时间区间 Join)
文章目录 Interval Join(时间区间 Join) Interval Join(时间区间 Join) Interval Join 定义(支持 Batch\Streaming):Interval Join 在离线的概念中是没有的。Interval Join 可以让一条流去 Jo…...

从IMC层到应力点:手把手教你用SEM/EDS给BGA焊点做一次‘体检’
从IMC层到应力点:手把手教你用SEM/EDS给BGA焊点做一次‘体检’ 当一块电路板上的BGA焊点出现异常时,往往就像人体某个关节出了问题——表面看不出明显伤痕,但功能已经受限。这时候,我们需要像医生一样,用专业设备给焊…...

CANN-MoE模型推理加速实战
MoE 模型推理加速实战:从入门到生产 MoE(Mixture of Experts)模型是当前大模型的主流架构,但它有个问题:8 个专家只激活 2 个,怎么让昇腾跑得更快?本文手把手教你。 一、前情提要:1 …...

阿西米尼常见副作用血小板减少及高血压的临床特征与管理
血小板减少与高血压是阿西米尼治疗慢性髓性白血病时患者报告频率最高的两项不良反应。两项副作用虽极少直接危及生命,却实实在在地影响着患者的日常功能与长期治疗依从性。ASCEMBL三期临床试验及其长期扩展研究的完整安全性数据,为这两项副作用勾勒出了精…...
)
告别手动描图!用AutoCAD Civil 3D 2024快速搞定两期土方横断面对比(附模板)
告别手动描图!用AutoCAD Civil 3D 2024快速搞定两期土方横断面对比(附模板) 在土木工程领域,土方量计算是项目成本控制与进度管理的关键环节。传统CAD手动绘制横断面的方式不仅耗时费力,更难以应对设计变更带来的反复修…...

JavaScript自动化PPT生成解决方案:PptxGenJS高效实践指南
JavaScript自动化PPT生成解决方案:PptxGenJS高效实践指南 【免费下载链接】PptxGenJS Build PowerPoint presentations with JavaScript. Works with Node, React, web browsers, and more. 项目地址: https://gitcode.com/gh_mirrors/pp/PptxGenJS 在当今数…...

别再死记硬背了!用NestJS + TypeORM实战‘用户-标签’系统,搞懂OneToMany和ManyToOne
NestJS TypeORM实战:构建高可维护的用户标签系统 在开发内容管理平台时,用户与标签的关联关系是典型的多对一建模场景。本文将带你从零实现一个基于NestJS和TypeORM的生产级用户标签系统,重点解析OneToMany和ManyToOne在实际项目中的最佳实践…...

终极指南:如何解锁光猫全部性能?RTL960x开源方案深度解析
终极指南:如何解锁光猫全部性能?RTL960x开源方案深度解析 【免费下载链接】RTL960x Hacking & Reverse Engineering RTL960x-based xPON ONTs to suit your OLT 项目地址: https://gitcode.com/gh_mirrors/rt/RTL960x RTL960x开源光猫固件是基…...

宏裕塑胶代理新日铁住金日本工程塑料全系列产品服务详解
宏裕塑胶代理新日铁住金系列产品专注于为制造业企业提供高性价比、稳定可靠的通用工程塑料原料,依托源头直采及技术赋能,为塑胶制品厂、汽车零部件厂等客户降低采购成本并保障全流程供应。宏裕塑胶代理新日铁住金核心功能与服务模块覆盖多个维度…...

YOLO-ONNX-Java 性能监控指标全面解析
YOLO-ONNX-Java 性能监控指标全面解析 概述 在计算机视觉应用中,性能监控是确保系统稳定运行的关键环节。YOLO-ONNX-Java 作为一个纯 Java 实现的 AI 视觉识别项目,提供了丰富的性能监控指标来帮助开发者优化系统性能。本文将深入解析该项目的性能监控指…...

Onyx Core API完全手册:RESTful接口详解与实战案例
Onyx Core API完全手册:RESTful接口详解与实战案例 【免费下载链接】Onyx Onyx 项目地址: https://gitcode.com/gh_mirrors/ony/Onyx Onyx Core是一个强大的企业级区块链平台,提供完整的RESTful API接口,让开发者能够轻松构建和管理区…...