文献阅读:LIMA: Less Is More for Alignment
- 文献阅读:LIMA: Less Is More for Alignment
- 1. 内容简介
- 2. 实验设计
- 1. 整体实验设计
- 2. 数据准备
- 3. 模型准备
- 4. metrics设计
- 3. 实验结果
- 1. 基础实验
- 2. 消解实验
- 3. 多轮对话
- 4. 结论 & 思考
- 文献链接:https://arxiv.org/abs/2305.11206
1. 内容简介
这篇文章是Meta在今年5月发的一篇文章,算是对LLM进行的一个黑盒分析吧。核心来说,这篇文章就是想要探究一下为什么LLM能够拥有如此强大的能力。
众所周知,自打从BERT开始,NLP大模型的范式就是大语料预训练加小数据集finetune。虽然GPT3短暂的抛弃了finetune而倡导直接的zero-shot learning,但是从FLAN开始,后期的InstructGPT,ChatGPT以及现今还没有公开技术细节的GPT4,无一不是走的两阶段训练:第一阶段进行大数据上的预训练,第二阶段做instruct learning或者RLHF。
但是,具体到两个阶段具体都产生了多大的贡献,事实上还算是一个黑盒,尽管直觉上我们都知道,真正产生核心作用的必然是大数据的预训练过程,不过后续的finetune过程到底可以产生多大的影响却不是很确定,文中就是对这个点进行了细致地考察,然后初步得到结果如下:
- LLM的核心还是在于预训练,后续只需要用少量的高质量标注数据进行LLM的finetune就能够获得堪比SOTA的模型效果。
下面,我们来具体看一下文章的细节。
2. 实验设计
1. 整体实验设计
首先,我们来看一下文中的实验整体设计。
由于文中要考察的是finetune对模型整体效果的影响,因此文中整体的实验设计思路就是减小finetune数据集,用一个精选的小数据集进行模型的finetune,即文中的LIMA模型,然后和现有的一些常用的大模型进行效果比较,检查这个方法训练得到的模型能否大幅提升模型的效果,以及能够抗衡现有的常见大模型。
2. 数据准备
因此,这里对于finetune使用的数据的质量的要求就很高。文中也是用了一个章节来介绍数据的构造方式。
首先,我们给出文中的总的finetune数据分布如下:

可以看到:
- 文中的finetune主要使用了1000条数据
- 其中,这一千条数据当中,有200条是人工写作的,剩下的800条来自于网上的高质量数据集中的高分数据。
3. 模型准备
然后,关于模型的准备方面,文中主要是使用Meta自己的LLaMa 65B模型然后进行finetune。具体就是使用上述提到的1000条数据进行15个epoch的finetune。
而作为对照模型,文中主要使用了如下几个模型作为对照组:
- Alpaca 65B
- Davinci003
- Bard
- Claude
- GPT4
4. metrics设计
最后,关于实验的metrics设计方面,文中其实给的比较简单,基本就是300个样本交给标注员进行side by side比较。
除此之外,考虑到人工标注的不稳定性,文中还使用GPT4来进行side by side比较判断,从而增加结论的可靠性。
3. 实验结果
下面,我们来看一下文中的具体实验结果。
1. 基础实验
我们首先给出基础的实验结果如下:

可以看到:
- LIMA模型击败了Alpaca 65B以及Davinci003模型
- 虽然LIMA模型没有击败BARD模型,但是有58%(人工标注)和53%(GPT4标注)的概率可以生成不差于BARD模型的结果
- 模型效果逊于Claude模型以及GPT4模型
而除了考察LIMA模型和其他模型的比较之外,文中还考察了一下LIMA自身回答的好坏,抽样50个样本之后,人工分析其效果如下:

可以看到:
- 只有12%的样本没有通过测试,而获得优秀评价的样本占比达到了50%。
最后,关于safety问题,LIMA通过了80%的safety测试,但是依然会出现差错,尤其当文本描述并不直接的时候。
下面,我们给出一些LIMA的具体case如下:

2. 消解实验
然后,文中还做了一些消解实验,研究了一下LIMA为何使用如此小量的数据就能获得如此好的效果。
具体而言,文中做了下面三个维度的消解实验:
- 标注数据的prompt的diversity
- 标注数据的质量
- 标注数据的数量
给出文中的实验结果如下:

可以看到:
- prompt的diversity以及数据本身的质量会显著影响模型的效果;
- 相对的,标注数据的数量方面却没有表现出明显的变化,从2k到32k的数据,模型效果都相差无几。
3. 多轮对话
最后,文中还考察了多轮对话当中LIMA的效果。
由于前期的实验当中并没有涉及多轮对话的训练语料,所以这里新增了30条多轮对话的数据进行模型训练,然后考察finetune前后在10个测试集上的测试结果如下:

可以看到:
- 经过少量多轮对话进行finetune之后,模型在多轮对话上的表现明显提升。
下面是文中给出的一个具体的case展示:

4. 结论 & 思考
综上,我们可以看到:
- 对于LLM而言,其所有的知识基本上都是在预训练阶段就已经完成了,finetune阶段的作用更多的是导出LLM在特定方向上的能力,而非是增加其知识。
- 因此,对于LLM的finetune而言,数据质量的影响远高于数据量的影响,少量高质量的数据就足以令模型在特定领域发挥出足够优秀的效果。
- 不过,数据量少的代价也就是效果的不稳定,这一点在文中的讨论部分也有提及,少量数据虽然可以优化对应任务上的效果,但是会弱化模型的泛化能力。
Anyway,这些讨论的前提都是LLM可以载入并且进行finetune,这一点可能就劝退大部分人了,因此这篇文章可能也就是看看了,围观一下大佬们的实验结论就是了……
相关文章:
文献阅读:LIMA: Less Is More for Alignment
文献阅读:LIMA: Less Is More for Alignment 1. 内容简介2. 实验设计 1. 整体实验设计2. 数据准备3. 模型准备4. metrics设计 3. 实验结果 1. 基础实验2. 消解实验3. 多轮对话 4. 结论 & 思考 文献链接:https://arxiv.org/abs/2305.11206 1. 内容简…...
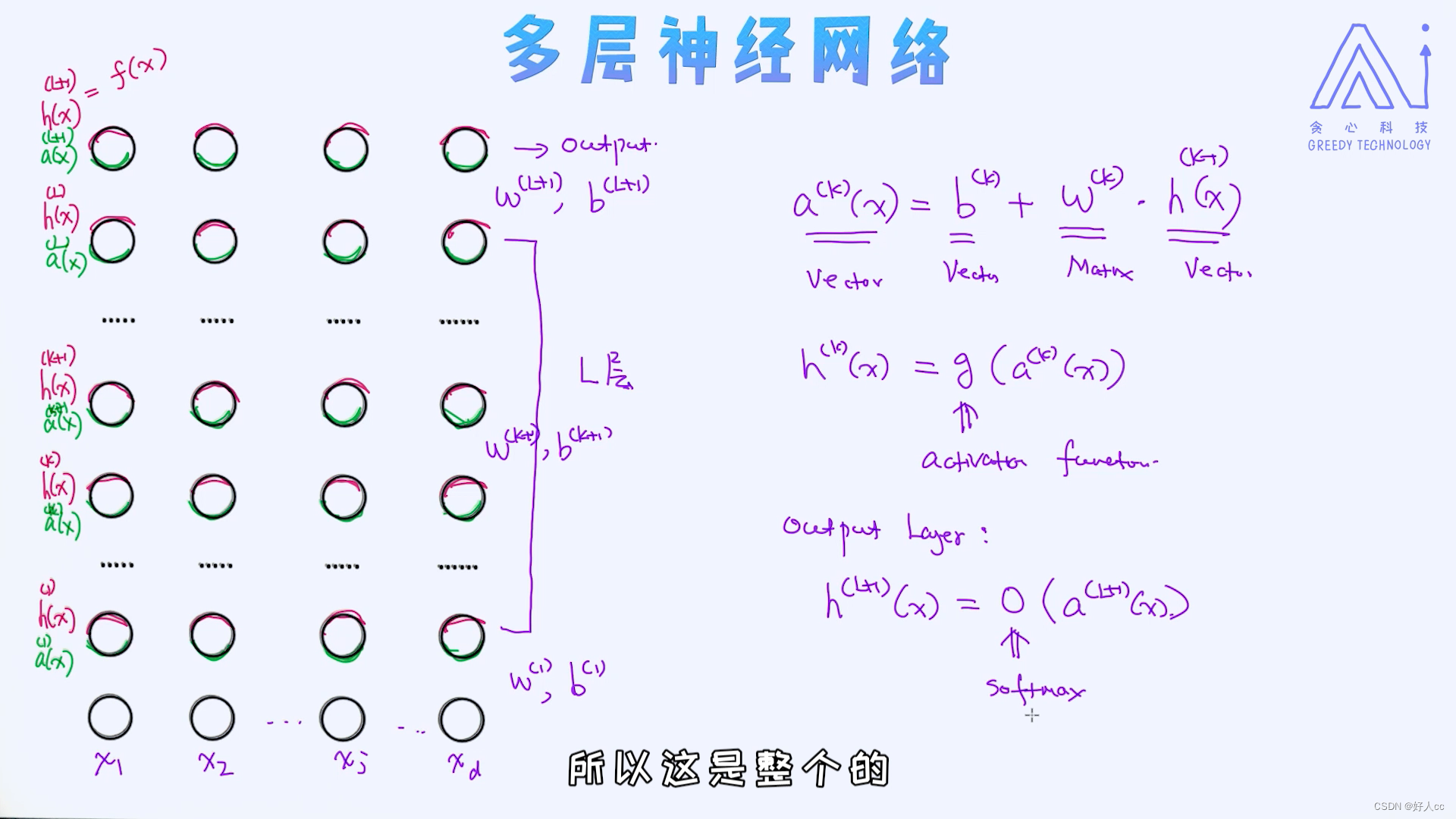
机器学习第十四课--神经网络
总结起来,对于深度学习的发展跟以下几点是离不开的: 大量的数据(大数据)计算资源(如GPU)训练方法(如预训练) 很多时候,我们也可以认为真正让深度学习爆发起来的是数据和算力,这并不是没道理的。 由于神经网络是深度学习的基础,学…...
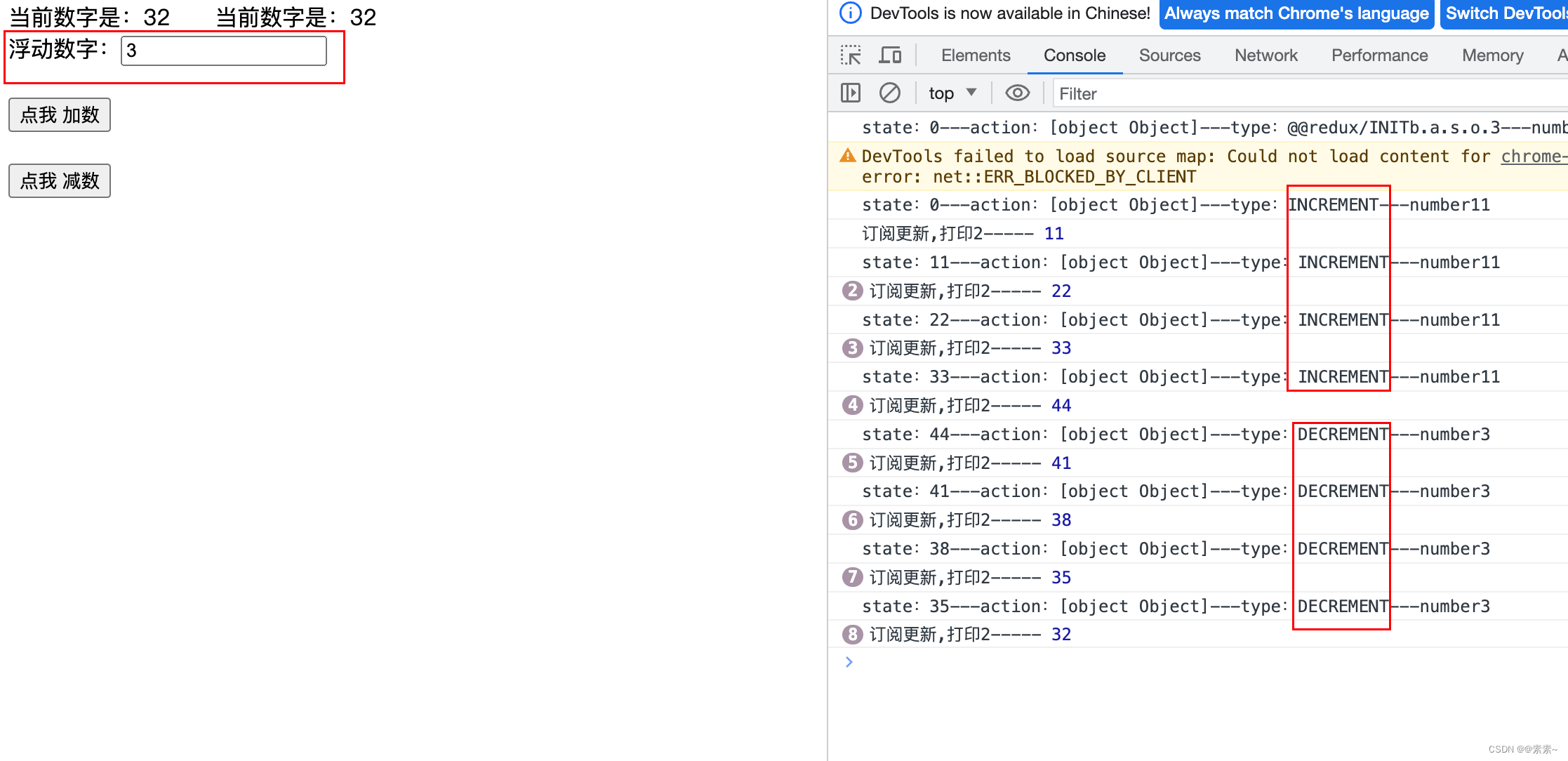
React(react18)中组件通信04——redux入门
React(react18)中组件通信04——redux入门 1. 前言1.1 React中组件通信的其他方式1.2 介绍redux1.2.1 参考官网1.2.2 redux原理图1.2.3 redux基础介绍1.2.3.1 action1.2.3.2 store1.2.3.3 reducer 1.3 安装redux 2. redux入门例子3. redux入门例子——优…...
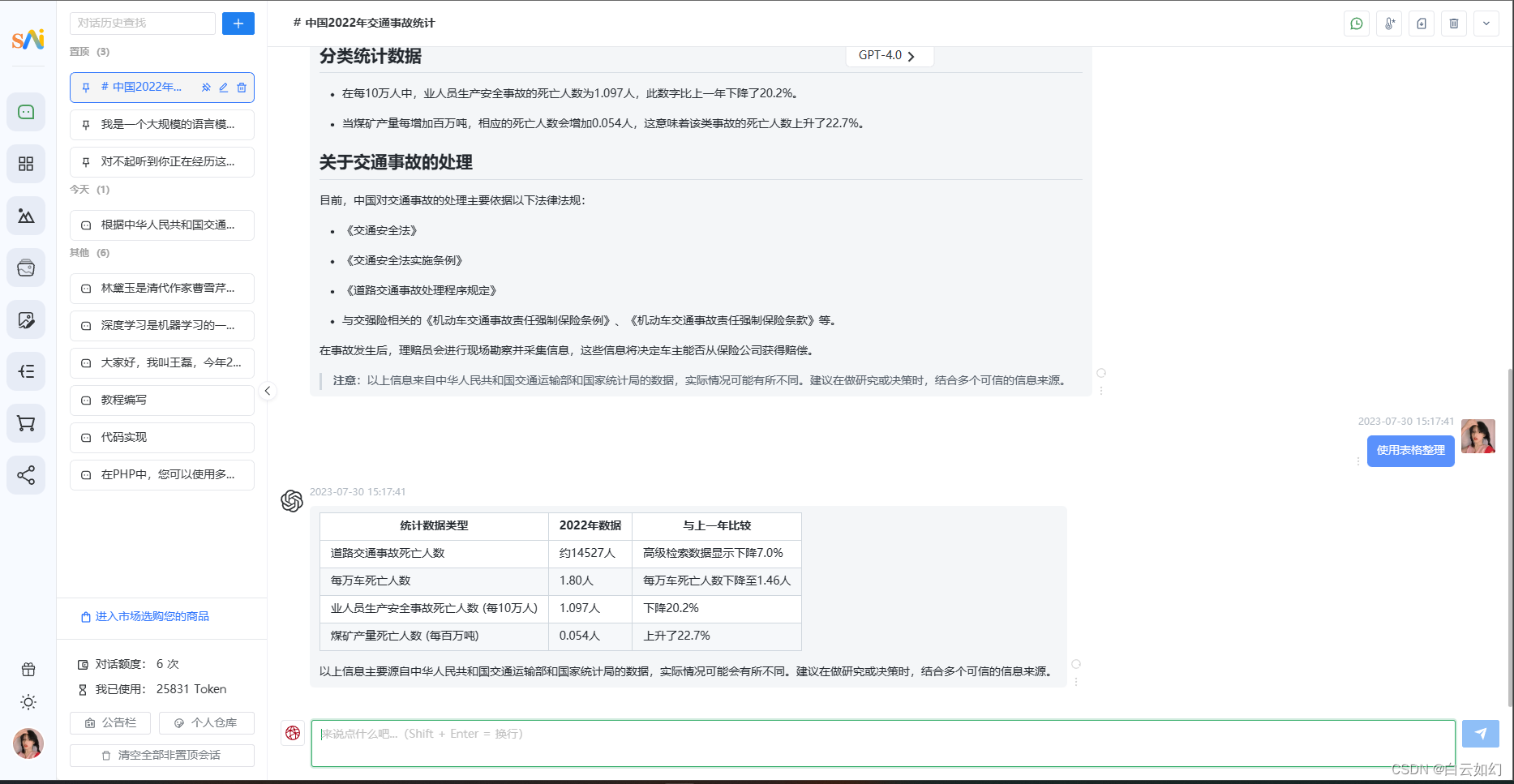
最新AI创作系统+ChatGPT网站源码+支持GPT4.0+支持ai绘画+支持国内全AI模型
一、AI创作系统 SparkAi系统是基于很火的GPT提问进行开发的Ai智能问答系统。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作ChatGPT系统?小编这里写一个详细图文教程吧&#x…...

react+umi项目中引入antd组件报错:“Button”不能用作 JSX 组件解决方案
具体报错信息 “Button”不能用作 JSX 组件。 Its type ‘(props: IProps) > React.ReactElement’ is not a valid JSX element type. 不能将类型“(props: IProps) > React.ReactElement”分配给类型“(props: any, deprecatedLegacyContext?: any) > ReactNode”。…...

常用算法模板
目录 快读、快输 快读、快输 #include <cstdio> #define Re register int #define LD double// 读整数 inline void in(Re &x) {int f 0; x 0; char c getchar();while (c < 0 || c > 9) f | c -, c getchar();while (c > 0 && c < 9) x …...

最全跨境独立站建站详细步骤解析
对于跨境电商卖家来说,无论是规避“鸡蛋放在同一个篮子里”的风险,还是追求更多的销售额和利润,多平台、多站点的布局都是其至关重要的战略。加之市场的变化带来了新的发展机遇,这也使得如今很多出海企业都在抢占独立站新风口。然…...
提升群辉AudioStation音乐体验,实现公网音乐播放
文章目录 本教程解决的问题是:按照本教程方法操作后,达到的效果是本教程使用环境:1 群晖系统安装audiostation套件2 下载移动端app3 内网穿透,映射至公网 很多老铁想在上班路上听点喜欢的歌或者相声解解闷儿,于是打开手…...
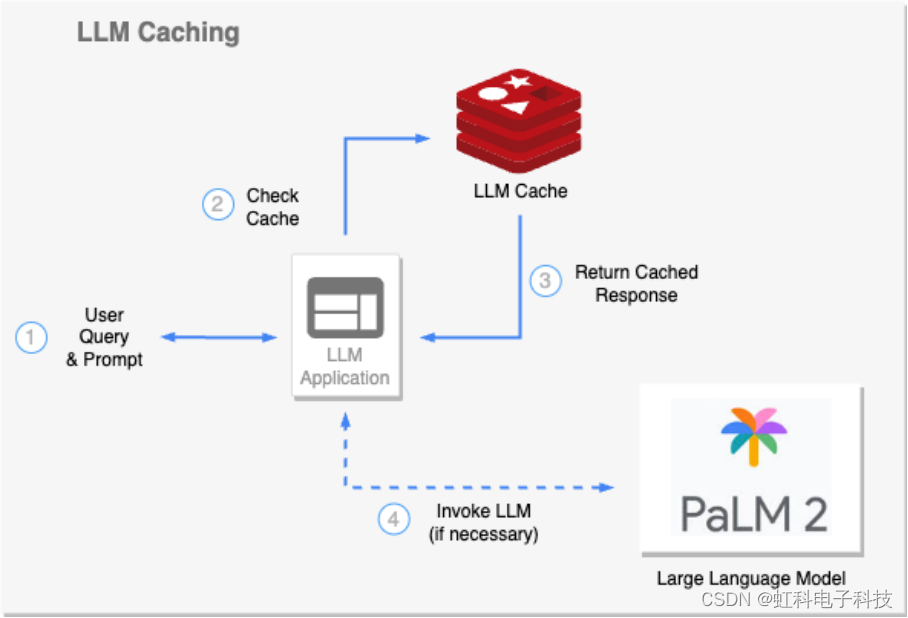
虹科分享 | 谷歌Vertex AI平台使用Redis搭建大语言模型
文章来源:虹科云科技 点此阅读原文 基础模型和高性能数据层这两个基本组件始终是创建高效、可扩展语言模型应用的关键,利用Redis搭建大语言模型,能够实现高效可扩展的语义搜索、检索增强生成、LLM 缓存机制、LLM记忆和持久化。有Redis加持的大…...
)
VS Code 代码跳转到定义(.js 和 .vue文件跳转)
vscode 代码跳转到定义(.js 和 .vue文件跳转) 在日常的开发工作中,我们经常需要跳转到方法或变量的定义处,以便更好地理解和修改代码。VS Code 是目前比较流行的开发工具,然而它默认情况下并不支持这个功能,…...

华为云云耀云服务器L实例评测 | Docker 部署 Reids容器
文章目录 一、使用Docker部署的好处二、Docker 与 Kubernetes 对比三、云耀云服务器L实例 Docker 部署 Redis四、可视化工具连接Redis⛵小结 一、使用Docker部署的好处 Docker的好处在于:在不同实例上运行相同的容器 Docker的五大优点: 持续部署与测试…...

聚观早报 | 杭州亚运开幕科技感拉满;腾讯官宣启动「青云计划」
【聚观365】9月25日消息 杭州亚运开幕科技感拉满 腾讯官宣启动「青云计划」 FF任命新全球CEO 比亚迪夺得多国销冠 iPhone 15/15 Pro销售低于预期 杭州亚运开幕科技感拉满 杭州第19届亚洲运动会开幕式23日晚在杭州奥体中心主体育馆举行,这届开幕式可谓科技感拉…...

Linux Gnome桌面无法打开终端Terminal
文章目录 前言排障解决方式一解决方式二 前言 由于不知名的原因,导致gonme桌面里打开terminal一直转圈,无法打开。 这里我的故障是已知的,我是因为要把英文改为中文。但是界面依旧是英文,同时导致终端无法打开。 此方式centos d…...
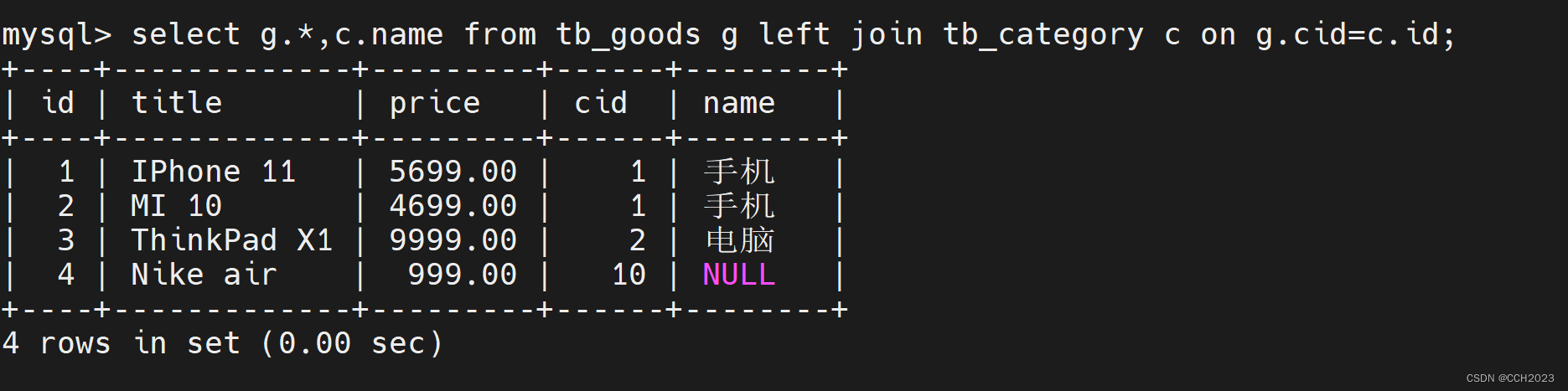
MySQL学习笔记15
1、内连接查询(重点): 基本语法: select 数据表1.字段列表,数据表2.字段列表 from 数据表1 inner join 数据表2 on 连接条件; 案例:获取产品表中每个产品的分类信息: mysql> select * from tb_goods …...
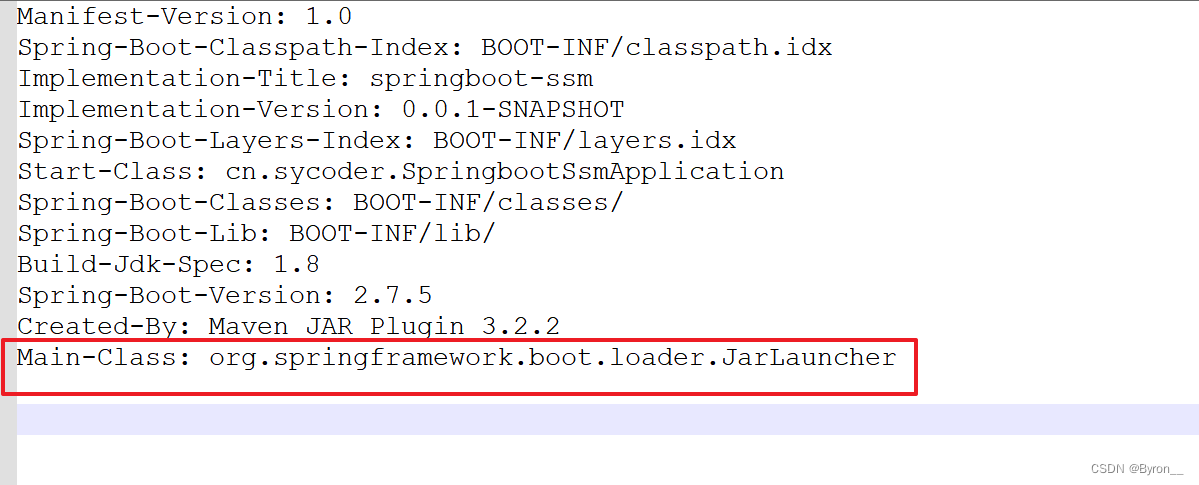
6、SpringBoot_项目的打包与运行
七、SpringBoot项目的打包与运行 1.目前项目怎么运行的 通过浏览器访问idea 将jar部署到服务器 2.maven 打包项目 命令 mvn package使用命令后会得到如下的jar 3.程序运行 命令 java -jar 项目.jar启动如下 4.springboot打包需要插件 插件 <plugin><group…...
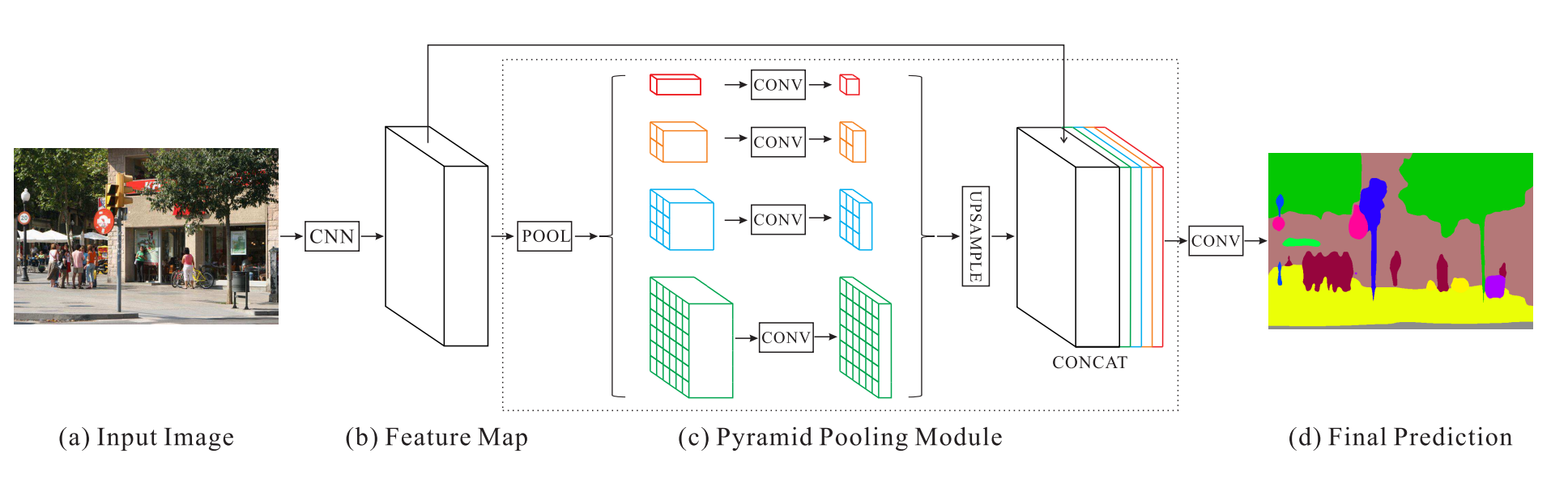
图像语义分割概述
图像语义分割概述 一、图像语义分割概念 图像语义分割(Image Semantic Segmentation)是一项计算机视觉任务,其目标是将输入的图像分割成多个区域,并为每个像素分配一个语义类别标签,以表示该像素属于图像中的哪个物体…...

ViT细节与代码解读
最近看到两篇解读ViT很好的文章,备忘记录一下: 先理解细节 1:再读VIT,还有多少细节是你不知道的 再理解代码 1:ViT源码阅读-PyTorch - 知乎...

Linux中软链接与硬链接的作用、区别、创建、删除
1、软链接与硬链接的作用 (1)软链接 软链接是Linux中常用的命令,它的功能是某一文件在另外一个位置建立一个同步的链接,相当于C语言中的指针,建立的链接直接指向源文件所在的地址,软链接不会另外占用资源,当同一文件需要在多个位置被用到的时候,就会使用到软连接。 …...
)
第一章:最新版零基础学习 PYTHON 教程(第十四节 - Python 条件和循环语句–Python 中的 with 语句)
在Python中,with语句用于异常处理,使代码更简洁、更具可读性。它简化了文件流等公共资源的管理。观察以下代码示例,了解使用 with 语句如何使代码更简洁。 Python3 # 文件处理# 1) 不使用with语句 file = open(文件路径, w) # 打开文件以进行写操作 file.write(你好,世界…...
安科瑞AMC16-DETT铁塔jizhan直流电能计量模块,直流计量用
安科瑞虞佳豪壹捌柒陆壹伍玖玖零玖叁 9月20日,在杭州亚运会火炬传递的现场,不少人通过网络与亲友连线,共同见证火炬传递的历史时刻。上午6时,杭州铁塔的一线通信保障人员共27人就已经在本次火炬传递收官点位奥体中心西广场附近&a…...

Faster-Whisper-GUI:高效本地语音识别与字幕生成终极指南
Faster-Whisper-GUI:高效本地语音识别与字幕生成终极指南 【免费下载链接】faster-whisper-GUI faster_whisper GUI with PySide6 项目地址: https://gitcode.com/gh_mirrors/fa/faster-whisper-GUI 在人工智能语音技术快速发展的今天,本地化语音…...

指纹采集器模块选型指南|如何选择合适的指纹采集模块
在做指纹门禁、指纹考勤、指纹保险箱或嵌入式终端时, 指纹采集器模块几乎是整个系统的核心。 模块选对了,项目推进顺畅;选错了,后期调试、售后问题不断。 本文不讲复杂参数,只从实际应用出发, 用最通俗的方…...

FPGA资源吃紧?看Artix7-35T如何“精打细算”实现MIPI视频解码与HDMI输出
Artix7-35T极限优化:在资源受限FPGA上实现MIPI-HDMI全流程处理 当医疗内窥镜或工业检测设备需要嵌入式图像处理时,工程师们常常面临一个残酷的现实:既要实现复杂的MIPI视频处理流水线,又不得不使用Artix7-35T这类入门级FPGA。这颗…...

Linux Shell生成随机文件:dd、openssl等工具实战与性能优化
1. 项目概述:为什么我们需要一个“随机”的固定大小文件?在日常的系统管理、开发测试,甚至是性能基准评测中,我们经常会遇到一个看似简单却非常实用的需求:快速生成一个指定大小的文件,并且希望文件内容是随…...

新手创业是注册公司好还是注册个体户好?
很多刚准备创业的朋友,最先纠结的问题就是:我到底是注册个体工商户,还是直接注册有限公司?一、先搞懂最核心的本质区别个体户属于个人经营模式,承担无限连带责任,简单说就是生意出问题,个人资产…...

载肌红蛋白的钆纳米Texaphyrin用于氧协同和成像引导的放射增敏治疗
北京大学王凡教授、中国科学院生物物理研究所史继云研究员和多伦多大学郑钢教授团队在《Nature Communications》(IF16.6)上发表题为“Myoglobin-loaded gadolinium nanotexaphyrins for oxygen synergy and imaging-guided radiosensitization therapy”…...

MTK手机用上高通QC快充,背后多出的那颗‘xmusb350’芯片到底在忙啥?
MTK手机为何需要外挂xmusb350芯片实现高通QC快充? 当你在电商平台搜索"支持QC快充的MTK手机"时,可能会发现一个有趣的现象:采用联发科处理器的机型在充电模块描述中,常会特别标注"搭载独立QC协议芯片"。这背后…...
)
别再只用Telnet了!手把手教你给思科路由器配置SSH远程登录(附Packet Tracer验证)
从Telnet到SSH:思科路由器安全远程管理实战指南 每次看到运维同事用Telnet登录路由器时,我都忍不住想提醒——这就像在咖啡馆用明信片写密码。作为从业十年的网络工程师,我见过太多因Telnet导致的安全事故。本文将用Packet Tracer带您完成从T…...

RT-Thread启动流程与BSP移植实战:从内核启动到硬件适配
1. 项目概述:从启动到适配,深入RT-Thread内核如果你刚开始接触RT-Thread,或者正打算把它移植到一个新的硬件平台上,那么“启动流程”和“板级支持”这两个问题,几乎是你绕不开的坎。这不仅仅是两个孤立的技术点&#x…...

从狼群狩猎到参数调优:GWO算法在机器学习超参数搜索中的保姆级指南
从狼群狩猎到参数调优:GWO算法在机器学习超参数搜索中的保姆级指南 在机器学习项目的最后阶段,我们常常会陷入超参数优化的泥潭。网格搜索耗时费力,随机搜索像买彩票,而贝叶斯优化又过于复杂。这时候,一群来自大自然的…...