【大数据】Doris 构建实时数仓落地方案详解(一):实时数据仓库概述
本系列包含:
- Doris 构建实时数仓落地方案详解(一):实时数据仓库概述
- Doris 构建实时数仓落地方案详解(二):Doris 核心功能解读
- Doris 构建实时数仓落地方案详解(三):Doris 实时数仓设计
Doris 构建实时数仓落地方案详解(一):实时数据仓库概述
- 1.数据仓库的发展历程
- 2.数据仓库技术的发展
- 3.数仓的相关技术栈
- 4.OLAP 查询
- 5.MPP 架构
- 6.实时数仓定义
- 7.实时数仓的难点
数据仓库的概念可以追溯到 20 世纪 80 年代,当时 IBM 的研究人员提出了商业数据仓库的概念。数据仓库概念的提出,是为了解决和数据流相关的各种问题,特别是多重数据复制带来的高成本问题。
1.数据仓库的发展历程
数据仓库之父 Bill Inmon 在 1991 年出版的《Building the Datla Warehouse》一书中首次提出了 数据仓库 的概念。Inmon 将数据仓库描述为 一个面向主题的、集成的、随时间变化的、非易失的数据集合,用于支持管理者的决策过程。这个定义一直延续至今,Bill Inmon 也被称为数据仓库之父。
大约在 2000 年前后数据仓库开始进入中国,最开始主要集中在银行业和电信业。银行业建设数据仓库的动力来自于监管要求和 1104 监管报送系统,电信业的动力主要是推动省市级子公司汇总数据到总公司,构建统一的财务分析报表。两个行业的应用,为数据仓库概念在中国的普及奠定了基础。
在 2010 年以后,随着大数据技术的发展扩展到其它行业。互联网、零售、制造、医疗行业等各行各业都在推广数据仓库。
2.数据仓库技术的发展
在 2010 年前后,数据仓库系统主要由 数据库、ETL 平台、BI 工具 三个商业套件组成。常见的数据库主要是 Oracle、DB2、Teradata,对应的 ETL 平台分别是 DataStage、Informatica、ETL Automation,主流的商业 BI 平台主要是 BIEE、Cognos、BO。对于以上这些名词可能今天的听众都很陌生,但是在 2010 年前后,这些就是数据仓库的代名词。我本人也只是在商业数仓的鼎盛时期入行参与了一些项目,除了今年 3 月宣布退出中国市场的 Teradata 没有接触过,但是其它的商业组件我都深入学习和实战过。
与此同时,随着移动互联网的兴起,以 BAT 为代表的互联网企业高喊着 “去 IOE” 口号,推动数据仓库从商业时代走向了开源时代,也从单体架构走向分布式架构。这里面最具代表性的就是阿里巴巴和腾讯公司分别 2009 年引入 Hadoop 集群,并且持续迭代升级并一直使用至今。互联网公司引入 Hadoop 体系的原因也很简单,因为传统的商业数据库已经无法满足互联网企业的数据存储计算需求了。传统的商业数据库扩展能力有限,硬件价格高昂,并发执行能力不足,Hadoop 则刚好可以解决这些痛点,加上 HiveQL 可以满足大部分数据开发的需求,因此 Hive 数仓逐步替代了商业数据库。但是前期 Hadoop、Hive、Sqoop 等开源软件并不成熟,需要投入大量的技术研发来完善这些软件,修复其中的 Bug,优化某些模块的性能或者功能,这个过程也比较缓慢,所以前期大家对 Hadoop 和 Hive 的感受都是很难用、不稳定。我本人第一次在项目中接触 Hive 是在 2016 年底,当时是腾讯旗下的微众银行,用的是腾讯内部优化过的 Hive 0.13 版本,互联网公司也是在那一年开始引入 Kafka。
后面的故事大家基本上都知道了,2016 年前后,随着 Hive 2.3 和 Hive 3.0 版本的发布,Hadoop 体系逐渐走向成熟稳定,Hortonworks 和 Cloudera 公司分别为 Hadoop 生态贡献了 Tez 引擎、Ambari 管理平台和 Impala 引擎,与此同时,内存计算引擎 Spark 强势崛起,为 Hive 提高了新的强大动力;Hive 母公司 Facebook 又进一步开源了 MPP 框架的查询引擎 Presto,大幅提升了 Hive 数仓的查询能力。
3.数仓的相关技术栈
站在当前时间点,我们谈论的 Hive 数仓,一般默认包括 HDFS 存储系统、Yarn 资源管理平台、Hive 元数据管理、Spark 计算引擎、Presto 查询引擎,这些构成了离线数仓的技术栈。
这里简单介绍一下各个技术栈的功能和作用:
-
Apache Hadoop:Apache Hadoop 是一个开源的分布式计算框架,提供了可扩展的存储和处理大规模数据的能力。它的核心组件包括 Hadoop Distributed File System(HDFS)、MapReduce 和 Yarn 资源管理组件,主要用于离线数仓数据存储和资源调度。
-
Apache Hive:Apache Hive 是基于 Hadoop 的数据仓库基础架构,提供了类似 SQL 的查询语言(HiveQL),使用户可以通过 SQL 风格的语法进行数据查询和分析。它支持将结构化数据映射到 Hadoop 集群上的 HDFS,并利用 MapReduce、Spark、Tez 等计算引擎进行查询和数据加工。
-
Sqoop:一个短命而重要的 Hadoop 组件,用于从关系型数据库抽取数据到 Hive 数仓中或者从 Hive 数仓中导出数据到关系型数据库。Sqoop 是一个非常重要的组件,但是不知道出于什么原因,很早就停止了更新,目前国内基本上都是用阿里巴巴开源的 DataX 替代其功能。
-
Apache Spark:Apache Spark 是一个快速、通用的大数据处理引擎,可用于构建离线数据仓库和实时数据分析系统。Spark 提供了高性能的数据处理和分析能力,并支持多种编程语言,如 Scala、Java 和 Python。
-
Apache Kylin:Apache Kylin 是一个开源的分布式分析引擎,专门用于构建 OLAP(联机分析处理)数据仓库。它支持在 Hadoop 上构建多维数据模型,提供快速的查询性能和高度可扩展性。这是一款由国人主导和开源的大数据项目,也是一款专注于 OLAP 查询的 Apache 顶级开源项目。
-
Presto:Presto 是一个分布式 SQL 查询引擎,可用于构建大规模数据仓库和数据查询引擎。它支持在多个数据源上执行高性能的查询,包括 Hive、MySQL、PostgreSQL 等。
4.OLAP 查询
说完数据仓库,就要说说 OLAP 查询了。在传统的数据仓库架构里,ETL 是在数据仓库之外,OLAP 在数据仓库之内的。在 Hadoop 体系引入数据仓库领域以后,大大提升了数据 ETL 处理的能力、集群的扩展能力、数据存储的稳定性,但是牺牲了数据的查询能力。所以就诞生了 OLAP 查询这个专业领域。
在离线数仓技术中,除了前面介绍的 Kylin、Presto、Impala、Druid 都是为了解决 OLAP 查询而设计的,但是这些基于 HDFS 设计的 OLAP 引擎 都只是加速了查询速度,还没能达到令人满意或者令人惊艳的速度。于是,ClickHouse 和 Doris 横空出世,一举成为了 OLAP 领域的王者。
-
ClickHouse 是俄罗斯的 Yandex 于 2016 年开源的用于在线分析查询的数据管理系统,是一款基于 MPP 架构的列式存储数据库,能够使用 SQL 查询语句实时生成数据分析结果。ClickHouse 的全称是 Click Stream,Data WareHouse。ClickHouse 也是第一款实现向量化查询引擎的开源数据库,也是一款专注于 OLAP 查询的数据库。ClickHouse 直接将 OLAP 查询的耗时压缩到了亚秒级。
-
Apache Doris 也是一个 MPP 架构的、专门用于 OLAP 查询的数据库产品。Apache Doris 不仅可以满足多种数据分析需求,如固定历史报表,实时数据分析,交互式数据分析,探索式数据分析,而且集群扩展能力非常突出,可以支持 10 PB 以上的超大数据集。另外,Apache Doris 对实时数据的支持也非常强大,因此是一款综合能力非常强的数据库。由于 Apache Doris 是本次分享的重点,所以这里只是简单介绍一下,后面再展开。
这里插入一个知识点,也是我在整理 PPT 的时候看到的一个总结。ClickHouse 为什么快?这里总结了几个点,其中最主要的是:C++ 语言可以利用硬件优势,底层数据选择列存储,支持向量化查询引擎,利用单节点的多核并行处理能力,数据写入时建立一级、二级和稀疏索引。这些特点为新兴的 OLAP 查询数据库研发指明了方向,这也是 Doris 的基本特点。
5.MPP 架构
再说说第三个概念,MPP 架构。MPP(Massively Parallel Processing)是大规模并行处理框架的简称。MPP 是 Shared Nothing 架构,是将任务并行地分散到多个服务器和节点上,在每个节点上的计算完成后,将各部分的结果汇总在一起得到最终的结果。

前文说到的 Teradata 是业界最早的知名 MPP 架构的数据库,之后是 Greenplum 以及和 Greenplum 架构类似 GBase、GaussDB 等都是 MPP 架构。Hadoop 体系的 Presto、HAWQ、Impala 都宣称是 MPP 架构,还有前面说到的 Clickhouse 和 Doris 两个新生物种。由于MPP 家族越来越庞大,加上 Hadoop 生态的跨界 “打劫”,所以现在很难定义什么是 MPP 架构。MPP 架构和 Hadoop 架构在一定层次上走向融合,目前最大的区别就在于计算资源的分配上。Hadoop 架构还遵从 Yarn 分配资源,而 MPP 架构都是独立使用本地内存和 CPU。再就是过程备份和失败重试机制,Hadoop 都会保留中间计算过程,计算失败的部分节点有自动重试机制,而 MPP 架构一般是一次性过程,如果执行失败了就会告诉用户执行失败,以此换取更好的查询性能。
6.实时数仓定义
最后再来说说实时数仓。传统的数据仓库都是利用夜间的业务低峰期来完成数据的 ETL 加工处理,并且为白天的日常分析提供数据支撑,所以在这个应用前提下,数据仓库默认都是按天计算和加工数据的,俗称 T+1 数仓。但是随着业务的发展和技术的成熟,我们不再满足于今天看昨天的数据,而是想要今天就看到今天的数据,于是就有了实时数仓的概念。实时数仓是指数据的实时性更高、延迟性低的数据仓库,一般是统计当天发生的业务数据。实时数仓一般包括按小时执行的小时级、分钟级的延时的准实时和秒级延时纯实时数仓。
从前面的介绍我们可以看出,早期的 Hive 数仓技术并不完善,连实时 OLAP 查询都很难做到,所以要做到实时数仓就更加难上加难。所以 Kafka 诞生这么多年,实时数仓还要等到 Flink 火爆才流行起来。纯实时数据仓库是指能够以近乎实时的方式处理和分析数据的数据仓库。它的目标是将数据的捕获、处理和分析的速度提高到接近实时的水平,以支持实时决策和洞察。
纯实时数据仓库颠覆了离线数仓的架构,包括数据采集、数据加工、数据查询和分析都需要采用一套新的技术栈。
-
在 数据采集 方面,要做到较低延迟的采集数据,常用的方法是读取数据库变更日志(也叫 CDC)或者直接接入在线的 Kafka 数据流。
-
在 数据加工 方面,实时数据一般采用 Apache Flink 或者 Spark Streaming 来完成数据加工,中间过程数据一般保存在 Kafka。
-
在 实时数据查询 方面,一般只支持将数据汇总写入 MySQL 等关系型数据库或者 Redis 缓存,以便于快速获取结果。为了支持更快的查询,我们也可以将数据写入 Clickhouse 和 Doris 进行查询。
这种加工虽然可以做到数据的秒级延迟,但是 牺牲了数据的准确性和数据分析维度,高度聚合的数据虽然可以满足一些场景的使用,但是无法进一步分析和深挖数据价值。所以大多数情况下,我们会在实时架构和离线架构之间做一个折中处理,就前半部分实时,后半部分离线。数据接入实时,数据加工采用离线微批处理。如果交易系统无法支持 CDC 变更日志,我们甚至可以基于数据的创建时间和修改时间,做微批的增量数据抽取。微批处理的好处在于:数据准确度比实时高,技术比较成熟,开发运维成本低。具体的实现方法我们将在第三部分展开。
实时数仓的应用场景也是在逐步丰富的,我在工作中遇到的主要有:
-
实时业务监控和预警。避免线上业务中断未能及时发现造成的损失。
-
实时大屏。主要用于 618 或者双十一大促期间监控业绩目标达成情况。
-
实时机器人播报。通过实时数据加工,及时向相关同事通报当日业绩进展情况和排名。
-
移动端实时数据展现。方便领导、管理人员实时查看业绩完成情况。
-
实时自助分析。主要是给自助分析补充当日数据。
-
实时看板。例如,按照五分钟的粒度查看成交指标,并和同期进行对比,便于及时发现业务故障,比实时监控更直观。
-
实时数据接口。有一些数据对外的场景,需要实时提供最新的数据,便于跨系统对接,不过这种场景大多数在交易系统完成。
-
实时推荐。例如商品实时销售排行榜等。
7.实时数仓的难点
实时数仓的实现也有很多难点,我这里总结主要是三个点。
-
第一,多表关联,也叫多流
join。当其中一方数据延迟时,如果另外一边的流数据不在数据窗口范围中,将无法关联。例如销售订单父表和销售明细子表,如果业务系统出现明细表变更超出窗口范围的数据,双流join将会丢失数据,导致变更记录丢失。 -
第二,维度数据变更。当维度数据发生变化时,历史数据和新写入的数据将存在不一致。如果是离线数仓,我们一般用当日凌晨确定时间点的维度状态作为统一维度;如果是纯实时数仓,维度变化前后的数据将出现不一致,而历史数据按照新维度清洗将成为一大难题。
-
第三个点是数据失效。数据失效包括数据物理删除和状态变为无效。数据物理删除,是指交易系统直接删除了对应的记录,这个在增量数据处理和实时数据抽取中都是难点,幸运的是 CDC 日志可以捕获到删除的记录;状态变为无效是指原来有效的数据变为无效数据,例如订单支付后关单。对于数据失效,我们一般的处理方法是生成一条指标为负数的对冲记录,将汇总结果中的指标扣减掉。但是在计算成交人数等指标则无法做到剔除。
以上三种情况在传统方案的实时数仓领域是无解的,但是在 Apache Doris 时代,我们是可以很轻易的解决这些痛点。
相关文章:
【大数据】Doris 构建实时数仓落地方案详解(一):实时数据仓库概述
本系列包含: Doris 构建实时数仓落地方案详解(一):实时数据仓库概述Doris 构建实时数仓落地方案详解(二):Doris 核心功能解读Doris 构建实时数仓落地方案详解(三)&#…...
C++ list容器的实现及讲解
所需要的基础知识 对C类的基本了解 默认构造函数 操作符重载 this指针 引用 模板等知识具有一定的了解,阅读该文章会很轻松。 链表节点 template<class T>struct list_node{T _data;list_node<T>* _next;list_node<T>* _prev;list_node(const T&…...
前端项目练习(练习-002-NodeJS项目初始化)
首先,创建一个web-002项目,内容和web-001一样。 下一步,规范一下项目结构,将html,js,css三个文件放到 src/view目录下面: 由于html引入css和js时,使用的是相对路径,所以…...
C++QT day11
绘制时钟 widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QPaintEvent>//绘制事件类 #include <QDebug>//信息调试类 #include <QPainter>//画家类 #include <QTimer>//定时器类 #include <QTime> #include &…...

Stable DIffusion 炫酷应用 | AI嵌入艺术字+光影光效
目录 1 生成AI艺术字基本流程 1.1 生成黑白图 1.2 启用ControlNet 参数设置 1.3 选择大模型 写提示词 2 不同效果组合 2.1 更改提示词 2.2 更改ControlNet 2.2.1 更改模型或者预处理器 2.2.2 更改参数 3. 其他应用 3.1 AI光影字 本节需要用到ControlNet,可…...

C#通过重写Panel改变边框颜色与宽度的方法
在C#中,Panel控件是一个容器控件,用于在窗体或用户控件中创建一个可用于容纳其他控件的面板。Panel提供了一种将相关控件组合在一起并进行布局的方式。以下是Panel控件的详细使用方法: 在窗体上放置 Panel 控件: 在 Visual Studio 的窗体设计器中,从工具箱中拖动并放置一…...
Vue2+ElementUI 静态首页案例
源码 <template><div class"app-container home"><el-row type"flex" justify"space-around" class"row-bg"><el-card class"box-card cardDiv1"><el-col :span"5"><div clas…...
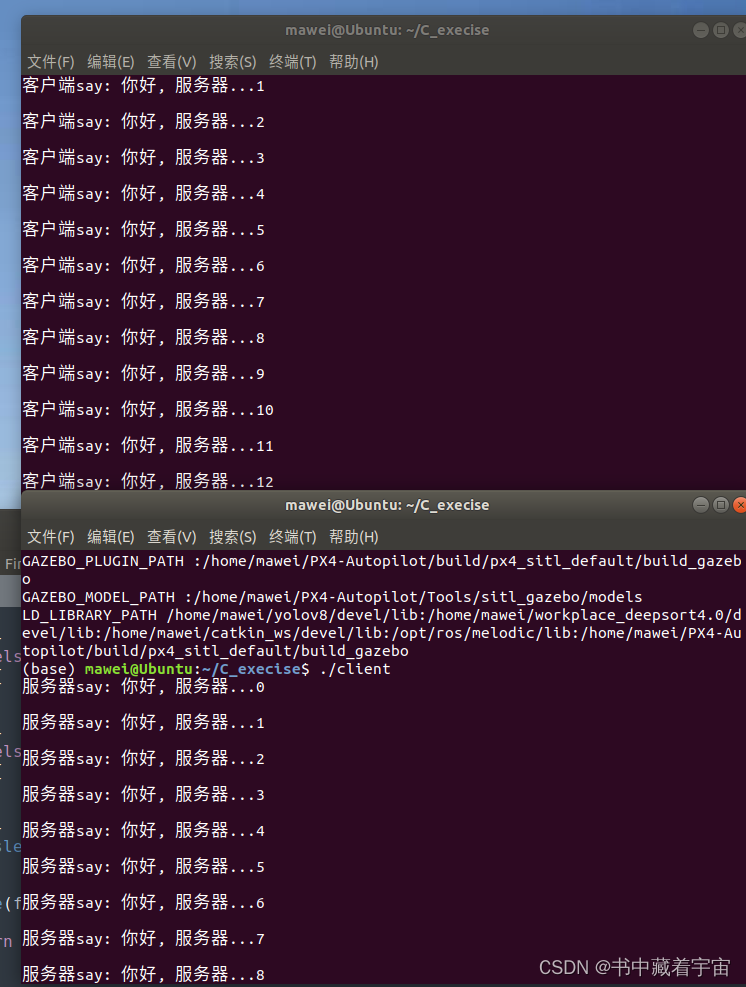
Linux的socket通信
关于套接字通信定义如下: 套接字对应程序猿来说就是一套网络通信的接口,使用这套接口就可以完成网络通信。网络通信的主体主要分为两部分:客户端和服务器端。在客户端和服务器通信的时候需要频繁提到三个概念:IP、端口、通信数据&…...

MySQL学习大纲
了解 MySQL 的基础知识和命令是使用此数据库的前提。以下是一些必须了解的 MySQL 概念和命令,包括基础的 CRUD(创建,读取,更新,删除)操作,以及一些高级功能: 1. 安装和启动 命令su…...

【Ambari】银河麒麟V10 ARM64架构_安装Ambari2.7.6HDP3.3.1(HiDataPlus)
🍁 博主 "开着拖拉机回家"带您 Go to New World.✨🍁 🦄 个人主页——🎐开着拖拉机回家_大数据运维-CSDN博客 🎐✨🍁 🪁🍁 希望本文能够给您带来一定的帮助🌸文…...

驱动开发练习,platform实现如下功能
实验要求 驱动代码 #include <linux/init.h> #include <linux/module.h> #include <linux/platform_device.h> #include <linux/mod_devicetable.h> #include <linux/of_gpio.h> #include <linux/unistd.h> #include <linux/interrupt…...

QT之QString的用法介绍
QT之QString的用法介绍 成员函数常见用法 成员函数 1)QString &append(const QString &str) 将 str 字符串追加到当前字符串末尾,并返回修改后的 QString 对象的引用。 2)QString &prepend(const QString &str) 将 str 字符…...

基于Java+SpringBoot+Vue3+Uniapp前后端分离考试学习一体机设计与实现2.0版本(视频讲解,已发布上线)
博主介绍:✌全网粉丝4W,全栈开发工程师,从事多年软件开发,在大厂呆过。持有软件中级、六级等证书。可提供微服务项目搭建与毕业项目实战,博主也曾写过优秀论文,查重率极低,在这方面有丰富的经验…...

springboot 获取参数
1.获取简单参数 2.实体对象参数...

【笔记】离线Ubuntu20.04+mysql 5.7.36 + xtrabackup定时增量备份脚本
一、环境 ● Ubuntu版本查看 lsb_release -a● mysql 版本查看 mysql --version我的是ubuntu 20.04,mysql是5.7.36,所以要用 install_percona-xtrabackup-24 二、原理 备份 通过ubuntu自带的定时器运行增量备份脚本备份文件可以存储在映射后的其他…...

树哈希与换根dp:CF763D
采用的树哈希函数是: d p x w x ∑ y ∈ x d p y 2 w x 2 \Large dp_xw_x\times \sum_{y\in x}dp_y^2w_x^2 dpxwxy∈x∑dpy2wx2 发现从 x x x 到 y y y 时只有 x x x 与 y y y 的哈希值会变化,分别维护即可 #include<bits/stdc.h&…...
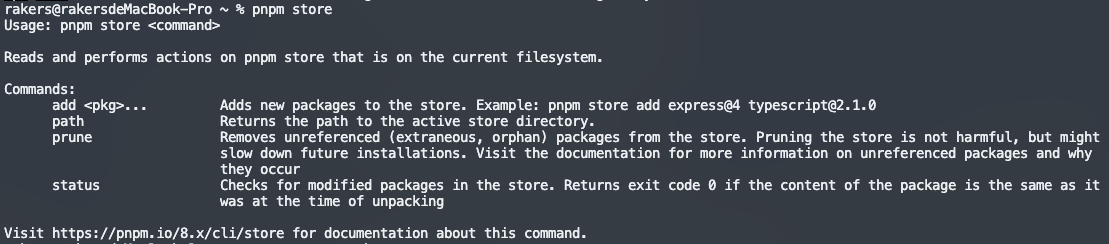
npm、yarn、pnpm如何清除缓存?
前端工程化创建项目会经常使用各种安装包管理工具,安装各种前端依赖包。例如,npm、yarn、pnpm等。时间一长,各种安装包管理工具的在安装依赖时,留下的缓存文件就会变得很大,以至于影响系统的运行,因此必要时…...

12款最火的AI画图软件,助你探索创新设计
ChatGPT火爆出圈,AI画图软件也如雨后春笋般流行起来。各类AI画图的软件工具横空出世,设计师与其焦虑工作会不会被人工智能取代,不如践行“工欲善其事必先利其器”,开拓思路,打开格局,好好地探索下如何利用好…...
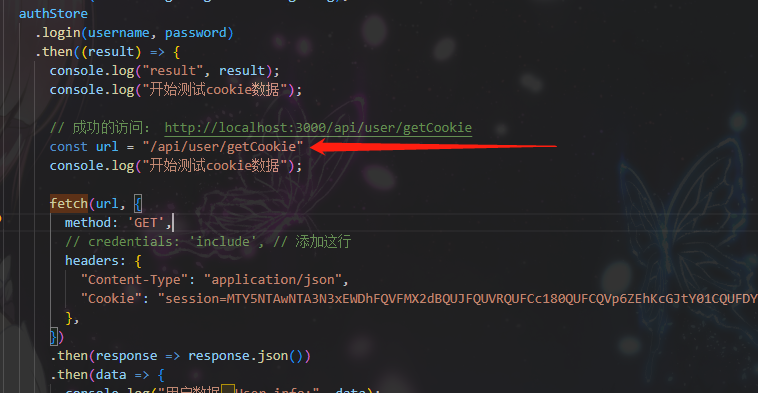
cookie信息无法获取问题研究
背景 在oneapi这个前后端都有的开源项目中,我想接入chatnextweb到oneapi的后端。 由于需要二开chatnextweb,添加登录注册功能,考虑到java后端的性能问题和内存占用,决定不重启写个服务,而是将登录注册接入到oneapi的…...
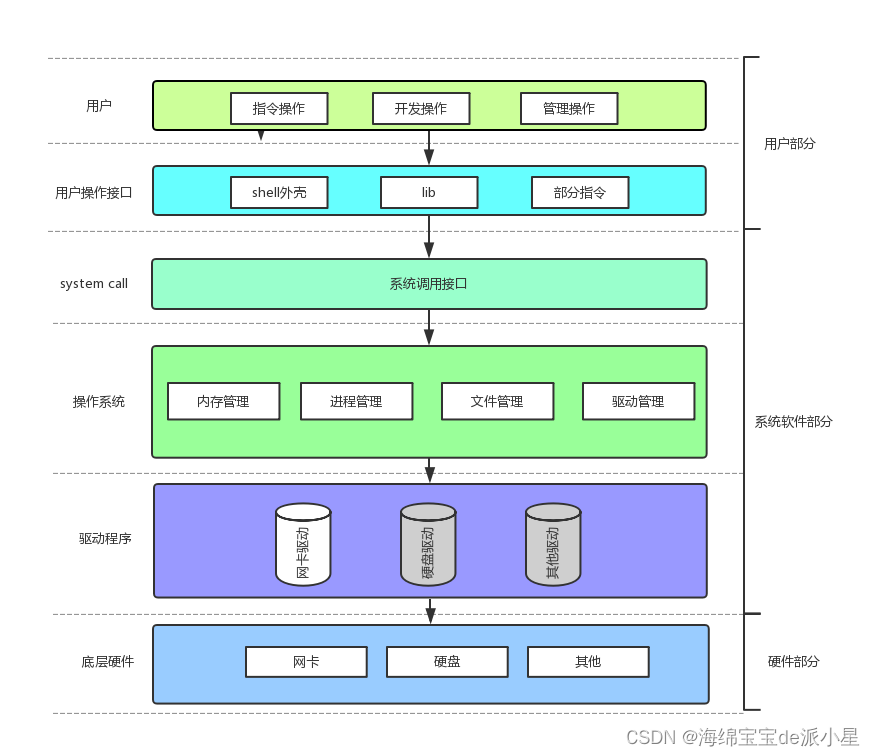
Linux:冯诺依曼系统和操作系统的概念
文章目录 冯诺依曼体系结构冯诺依曼体系的理解 操作系统操作系统的基本定位操作系统的理解1 操作系统的理解2总结 本篇主要总结的是操作系统的基本认知和一些概念 冯诺依曼体系结构 那么上图表示的就是冯诺依曼体系结构,那这个体系结构是什么?为什么要先…...

OFDM-QPSK系统仿真避坑指南:如何正确设置SNR并解读星座图与误码率曲线
OFDM-QPSK系统仿真避坑指南:如何正确设置SNR并解读星座图与误码率曲线 在无线通信系统的仿真实践中,OFDM-QPSK组合因其抗多径干扰和频谱效率高的特点,成为研究者常用的验证模型。但许多初学者在MATLAB仿真中常遇到结果与理论不符的情况——星…...

Windows缩略图加载太慢?这款智能预加载工具让文件浏览快如闪电
Windows缩略图加载太慢?这款智能预加载工具让文件浏览快如闪电 【免费下载链接】WinThumbsPreloader-V2 WinThumbsPreloader is a powerful open source tool for quickly preloading thumbnails in Windows Explorer. 项目地址: https://gitcode.com/gh_mirrors/…...

Windows 和 Ubuntu 安装 OpenClaw 全攻略
文章目录【开场白】【先说结论:Windows 用户推荐走 WSL2】【Windows 安装:4 步搞定】第 1 步:装 WSL2第 2 步:更新系统第 3 步:一键装 OpenClaw第 4 步:初始化配置【WSL2 必做配置:让 OpenClaw …...
)
告别Modelsim命令行!用Notepad++插件NppExec一键检查Verilog语法(附详细配置命令)
硬件工程师的效率革命:Notepad与Verilog语法检查的终极整合方案 在数字电路设计领域,Verilog作为主流硬件描述语言,其语法检查是每位工程师日常工作中不可或缺的环节。传统工作流程中,工程师们不得不在文本编辑器与EDA工具之间频繁…...

在Blender中创建逼真流体模拟:FLIP Fluids插件完全指南
在Blender中创建逼真流体模拟:FLIP Fluids插件完全指南 【免费下载链接】Blender-FLIP-Fluids The FLIP Fluids addon is a tool that helps you set up, run, and render high quality liquid fluid effects all within Blender, the free and open source 3D crea…...

如何通过技术优化提升百度网盘macOS版下载体验
如何通过技术优化提升百度网盘macOS版下载体验 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 对于macOS用户来说,百度网盘下载速度限制一直…...

避坑指南:OpenMV形状识别参数调不好?从霍夫圆检测到find_rects的实战经验分享
OpenMV形状识别实战:从参数调优到多场景适配的深度解析 当你在实验室里用OpenMV官方例程完美识别出圆形贴片时,是否曾信心满满地将设备搬到车间现场,却发现识别率断崖式下跌?这种"实验室王者,现场青铜"的困…...
)
保姆级教程:用YOLOv8和Pyside6从零搭建一个火焰烟雾检测桌面应用(附完整源码和数据集)
从零构建火焰烟雾检测桌面应用:YOLOv8与Pyside6实战指南 在工业安全、家庭监控和实验室防护场景中,火焰与烟雾的早期检测至关重要。传统监控系统依赖人工值守或简单传感器,难以实现精准的实时预警。本文将带你用Python生态中最前沿的YOLOv8目…...

Excel数据导入实战:为缺失ID列批量生成标准UUID
1. 为什么需要为Excel数据批量生成UUID? 最近在处理一个数据迁移项目时,遇到了一个典型问题:从Navicat导出的Excel表格缺少主键列,导致后续数据导入时频频报错。这种情况在数据迁移、系统对接时特别常见。UUID(通用唯…...

如何打破课堂限制?JiYuTrainer让您的电脑重获自由
如何打破课堂限制?JiYuTrainer让您的电脑重获自由 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 当您在计算机课堂上被极域电子教室完全控制时,是否感到学…...