MySQL缓冲池Buffer Pool
前言
在应用系统中,为加速数据访问,会把高频的数据放在「缓存」(Redis、MongoDB)里,减轻数据库的压力。在操作系统中,为了减少磁盘IO,同时为了快速响应,引入了「缓冲池」(buffer pool)机制。
MySQL作为一个存储系统,为提高性能,减少磁盘IO,同样具有「缓冲池」(buffer pool)机制。
介绍
Buffer Pool作为InnoDB内存结构的四大组件之一,是InnoDB存储引擎层的缓冲池。Buffer Pool以Page页为单位,缓存最热的数据页(data page)与索引页(index page),Page页默认大小16K,BP的底层采用链表数据结构管理Page。
Buffer Pool默认大小 128M。
Buffer Pool 除了缓存「索引页」和「数据页」,还包括日志缓存 log buffer( undo 页 、redo log),插入缓存、自适应哈希索引、锁信息等。
也就是说,所有数据页的读写操作都需要通过buffer pool进行,innodb 读操作,先从buffer_pool中查看数据的数据页是否存在,如果不存在,则将page从磁盘读取到buffer pool中。innodb 写操作,先把数据和日志写入 buffer pool 和 log buffer,再由后台线程以一定频率将 buffer 中的内容刷到磁盘,「这个刷盘机制叫做Checkpoint」。
写操作的事务持久性由redo log 落盘保证,buffer pool只是为了提高读写效率。
Buffer Pool控制块
为了更好管理的缓存页,Buffer Pool有一个「描述数据的区域」叫控制块。InnoDB 为每一个缓存的数据页都创建了一个单独的区域,记录的数据页的元数据信息,包括数据页所属表空间、数据页编号、缓存页在Buffer Pool中的地址,链表节点信息、一些锁信息以及 LSN 信息等。
「控制块和缓存页是一一对应的,它们都被存放到 Buffer Pool 中,其中控制块被存放到 Buffer Pool 的前边,缓存页被存放到 Buffer Pool 后边」,控制块大概占缓存页大小的5%,16 * 1024 * 0.05 = 819个字节左右。
但是需要注意的是,一般数据页虽然有默认大小,但是有的数据页会超出大小,如果剩余空间不够一堆控制块和缓冲页,那么就部分空间就属于碎片空间。
Buffer Pool的管理
Buffer Pool里有三个链表,LRU链表,free链表,flush链表,InnoDB正是通过这三个链表的使用来控制数据页的更新与淘汰的」。
1、Buffer Pool的初始化
当启动 Mysql 服务器的时候,需要完成对 Buffer Pool 的初始化过程,即分配 Buffer Pool 的内存空间,把它划分为若干对控制块和缓存页。
划分空间后,Buffer Pool的缓存页是都是空的,当要对数据执行增删改查的操作的时候,才会把数据对应的页从磁盘文件里读取出来,放入Buffer Pool中的缓存页中。当BufferPool中间有的页数据持久化到硬盘后,这些数据页又会被空闲出来。
- 「申请空间」
Mysql 服务器启动,就会根据设置的Buffer Pool大小(innodb_buffer_pool_size)超出一些,去操作系统「申请一块连续内存区域」作为Buffer Pool的内存区域。- 「划分空间」
当内存区域申请完毕之后,数据库就会按照默认的缓存页的16KB的大小以及对应的800个字节左右的控制块的大小,在Buffer Pool中划分**「成若干个【控制块&缓冲页】对」**。
2、Free链表
Free链表即空闲链表,是一个双向链表,由一个基础节点和若干个子节点组成,记录空闲的数据页对应的控制块信息。说白了,Free链表的设计是为了找到空闲的缓存页。
1)节点信息
「基节点」
- 基础节点是一块单独申请的内存空间(约占40字节)。并不在Buffer Pool的连续内存空间里。基础节点会引用链表的头节点和尾节点。
「子节点」
- 每个子节点就是个空闲缓存页的控制块的地址信息,也就是说只要一个缓存页空闲,那它的控制块就会被放入free链表。每个控制块块里都有两个指针free_pre(指向上一个节点),free_next(指向下一个节点)。
磁盘页加载到BufferPool的缓冲池流程
- 从free链表中,获取头节点,取出一个空闲的控制块以及对应缓冲页
- 把磁盘上的数据页读取到对应的缓存页,同时把相关的一些描述数据写入缓存页的控制块(例如:页所在的表空间、页号之类的信息)
- 把该控制块对应的free链表节点从链表中移除,表示该缓冲页已经被使用了
2)如何确定数据页是否被缓存
数据库提供了一个数据页缓存哈希表,以表空间号+数据页号作为key,缓存页的控制块地址作为value。
也就是说,如果要使用缓冲页,就会先去数据页缓冲哈希表中查找,表中存在的话,再根据控制块的地址去找缓冲页,如果没找到缓冲页,那么就会先读取数据页数据,从空闲列表中获取空闲的缓冲页就行写入,写入完毕之后,移出空闲链表,并更新控制块的地址信息。
大致过程:
- 通过sql语句中的数据库名和表名可以知道要加载的数据页处于哪个表空间。
- 「根据表空间号、表名称本身通过一致性算法得到索引根节点数据页号」。
- 进而根据根节点的数据页号,通过B+tree一层一层往下找,最后找到想要的数据页,再从数据页缓存哈希表得到对应缓存页地址。
- 通过缓存页地址就可以在Buffer Pool池中定位到缓存页。
3、LRU链表
当free链表的所有子节点都没有,但是Buffer pool的大小是固定的,就会从LRU链表中获取相对非热点数据的节点,来做数据覆盖。
基于此,InnoBD采用了LRU(Least recently used)算法,将频繁访问的数据放在链表头部,而不怎么访问的数据链表末尾,空间不够的时候就从尾部开始淘汰,从而腾出空间。
LRU算法的目的就是为让被访问的缓存页能够尽量排到靠前的位置。LRU链表本质上也是有控制块组成的。
当数据库从磁盘加载一个数据页到Buffer Pool中的时候,会将一些变动信息也写到控制块中,并且将控制块从Free链表中脱离加入到LRU链表中。
当访问的页在 Buffer Pool 里,就将该页对应的控制块移动到 LRU 链表的头部节点。
当访问的页不在 Buffer Pool 里,除了要把控制块放入到 LRU 链表的头部,还要淘汰 LRU 链表末尾的节点。
LRU链表区域划分
LRU链表是Msyql 基于 LRU 设计了冷热数据分离的处理方案,分为young区域和old区域,young区域位于链表头部(5/8),存放热点数据。old区域,位于链表尾部(3/8),存放非热点数据。
存放规则
**每次有数据被加载到buffer pool后,先插入到old区域的头部,并标记第一次访问的时间,后续如果在访问到当前页,并且访问时间间隔大于设置的间隔时间innodb_old_blocks_time(默认1s),才会把当前页给提高到young区域。**通过这种方式,就避免了全部扫描导致的只访问一次的数据页覆盖掉热点数据的问题。
但是热点区域的数据被频繁访问,如果young区域每次访问某一页,就把当前页移动到young区域的head,会导致LRU链表频繁的变形,因此mysql又做了一个优化:young区域前1/4被访问不会被移动到头部,只有后面的3/4被访问才会移动到头部。
4、Flush链表
对数据的读写都是先对Buffer Pool中的缓存页进行操作,然后在通过后台线程将脏页写入到磁盘,持久化到磁盘中,即刷脏。
脏页:当执行写入操作时,先更新的是缓存页,此时缓存页跟磁盘页的数据就会不一致,这就是常说的脏页
Flush链表与Free链表的结构很类似,也由基节点与子节点组成。Flush链表是一个双向链表,链表节点是被修改过的缓存页对应的控制块。Flush链表作用:帮助定位脏页,需要刷盘的缓存页。
基节点:和free链表一样,连接首尾结点,并记录存储了有多少个描述信息块。
子节点:每个节点是脏页对应的控制块,即只要一个缓存页被修改,那它的控制块就会被放入Flush链表,每个控制块块里都有两个指针pre(指向上一个节点),next(指向下一个节点)
写入过程
- 更新Buffer Pool中的数据页,一次内存操作
- 将更新操作顺序写Redo log,一次磁盘顺序写操作(顺序写Redo log,每秒几万次)
其他
1、Change Buffer 写缓存
在MySQL5.5之前,叫插入缓冲(Insert Buffer),只针对INSERT做了优化;现在对DELETE和UPDATE也有效,叫做写缓冲(Change Buffer)。
**它是一种应用在非唯一普通索引页(non-unique secondary index page)不在缓冲池中,对页进行了写操作,并不会立刻将磁盘页加载到缓冲池,而仅仅记录缓冲变更(Buffer Changes),等未来数据被读取时,再将数据合并(Merge)恢复到缓冲池中的技术。**写缓冲的目的是降低写操作的磁盘IO,提升数据库性能。
1)数据修改操作的步骤:
- 第一步:修改一条数据时,首先判断该条数据是否存在于
Buffer Pool之中。- 如果在,直接修改
Buffer Pool中的相关数据。 - 如果不在,首先在磁盘中读取该条数据到
Change Buffer之中,而后在Change Buffer中修改该数据,同时写入Redo Log之中(为了防止数据丢失),等下一次查询该条数据时,合并至Buffer Pool中。
- 如果在,直接修改
- 第二步:
Change Buffer中数据修改之后,什么时候合并数据呢?- 第一种方式:当修改的这条数据被查询的时候,合并到
Buffer Pool。 - 第二种方式:MySQL 数据库中的
Master Thread合并(周期默认:10s)。 - 第三种方式:当 MySQL 数据库关闭时,通过
Redo Log合并到磁盘中。
- 第一种方式:当修改的这条数据被查询的时候,合并到
2)change buffer 只适用于非唯一普通索引页?
**如果索引设置了唯一属性,在进行修改操作的时候,innodb必须进行唯一性检查,也就是说,即便索引页不在缓冲池中,磁盘的读取也是不可避免的。**此时就应该直接把相应的页放入缓冲池然后进行修改,而没有必要进行“写缓冲”这多余操作。
3)change buffer中数据刷新的触发时机?
- 相关数据页被访问
- 后台线程,在数据库空闲时
- 数据库缓冲池不够用
- 数据库正常关闭
- redo log写满
2、Log Buffer 日志缓冲
日志缓冲区(Log Buffer)是MySQL中用于存储事务日志(Transaction Log)的缓冲区。它在数据库执行事务时起到关键的作用。
当在MySQL中对InnoDB表进行更改时,这些更改首先存储在InnoDB日志缓冲区的内存中,然后写入通常称为重做日志(redo logs)的InnoDB日志文件中。redo日志缓冲区是内存存储区域,用于保存要写入磁盘上的日志文件的数据。日志缓冲区大小由innodb_log_buffer_size 变量定义,默认大小为16MB。
日志缓冲区的内容定期刷新到磁盘。较大的日志缓冲区可以运行大型事务,而无需在事务提交之前将重做日志数据写入磁盘。因此,如果有更新,插入或删除许多行的事务,则增加日志缓冲区的大小可以节省磁盘I/O。
MySQL 数据库在系统磁盘上保存的数据是有序的(典型就是按照主键 ID),如果每一次修改数据直接操作磁盘的话,会导致很多数据的位置发生更改(也就是我们常说的:随机 IO),但是
Redo log中保存的数据是有序的(顺序IO),不会产生随机 IO,所以使用Redo log暂时保存数据是确保数据不丢失时的最好办法。
3、Doublewrite Buffer 双写缓冲
一般情况下,Linux文件系统的页大小是4KB,而我们知道 mysql的页大小为16KB(oracle为8KB),这就说明,mysql将buffer pool中的一页数据刷到磁盘里面,需要写4个文件系统页。
但是这个操作并不是原子性的,如果写到一半断电,就会发生“页数据损坏”。
Doublewrite Buffer又名双写缓冲区,是内存+磁盘结构,内存结构是由128个页组成,大小为16KB × 128 = 2MB,“Double”的由来是因为数据写两次磁盘:一次是写DWB的内存区域(此过程分两次写入,每次写入16KB × 64 = 1MB的数据,会分两次刷入磁盘),一次是直接写入Data File(.ibd)。
MySQL 8.0较MySQL 5.6、5.7版本的Doublewrite Buffer产生了一些新的变化,DWB磁盘结构的数据存放从共享系统表空间中分离出来,存放在单独的.dblwr文件中;
如何修复页数据损坏?
采用double write buffer 来进行修复,Doublewrite Buffer是为了保证因系统页损坏导致的MySQL数据丢失的保证方案。redo log无法修复这类页数据损坏异常。(修复的前提是页数据正确并且redo日志正常。) double write buffer 和传统的buffer不同,它分为内存和磁盘两层架构。
工作流程如下(刷盘):
- 页数据先通过memcpy函数拷贝至内存中的Doublewrite Buffer中;
- Doublewrite Buffer的内存里的数据页,会fsync刷到Doublewrite Buffer的磁盘上,分两次写入磁盘共享表空间中(连续存储,顺序写,性能很高),每次写1MB;
- Doublewrite Buffer的内存里的数据页,再刷到数据磁盘存储.ibd文件上(离散写)
两次磁盘写会不会影响性能?
- 内存copy到DWB的内存区域,速度很快
- DWB的内存写到DWB的磁盘,属于顺序追加写,速度也快
- 刷磁盘,随机写,但是本来就需要进行。
- 另外,128页工2M的DWB,会分两次刷入磁盘,每次最多64页,数据量小,执行快,因此综合来看,虽然性能有影响,但是影响不大。
小结
InnoDB Doublewrite Buffer是InnoDB的一个重要特性,用于保证MySQL数据的可靠性和一致性。它的实现原理是通过将要写入磁盘的数据先写入到Doublewrite Buffer中的内存缓存区域,然后再写入到磁盘的两个不同位置,来避免由于磁盘损坏等因素导致数据丢失或不一致的问题。
疑问
1、MySQL 是怎么判断脏页的?
脏页的控制块同时存在于 LRU 链表和 Flush 链表。
2、触发刷脏页的条件
1)redo log快写满的时候
2)为了保证MySQL中的空闲页面的数量,Page Cleaner线程会从LRU 链表尾部淘汰一部分页面作为空闲页。如果对应的页面是脏页的话,就需要先将页面Flush到磁盘。
3)MySQL中脏页太多的时候。innodb_max_dirty_pages_pct 表示的是Buffer Pool最大的脏页比例,默认值是75%,当脏页比例大于这个值时会强制进行刷脏页,保证系统有足够可用的Free Page。
4)MySQL实例正常关闭的时候,也会触发MySQL把内存里面的脏页全部刷新到磁盘。
总结
Buffer Pool 里有三种数据页页和链表来管理数据,Free Page(空闲页)、Clean Page(干净页)、Dirty Page(脏页)。
Free Page(空闲页)。表示此数据页未被使用,是空的,其控制块位于 Free 链表;
Clean Page(干净页)。表示此数据页已被使用,缓存了数据, 其控制块位于LRU 链表。
**Dirty Page(脏页)。表示此数据页【已被使用】且【已经被修改】,数据页中数据和磁盘上的数据已经不一致。脏页的控制块同时存在于 LRU 链表和 Flush 链表。**当脏页上的数据写入磁盘后,内存数据和磁盘数据一致,那么该页就变成了干净页。
相关文章:

MySQL缓冲池Buffer Pool
前言 在应用系统中,为加速数据访问,会把高频的数据放在「缓存」(Redis、MongoDB)里,减轻数据库的压力。在操作系统中,为了减少磁盘IO,同时为了快速响应,引入了「缓冲池」(buffer pool)机制。 MySQL…...

springboot实现发送邮箱验证码
准备工作 在邮箱官网开放SMTP授权,获取相应密钥,才可以进行发送邮件 这里以网易163邮箱为例,登录邮箱后,依次点击“设置-POP3/SMTP/IMAP” ,然后开启SMTP服务。这时候会提示一个授权码,例如:H…...

ESP8266使用记录(三)
通过udp把mpu6050数据发送到PC端 /********************************************************************** 项目名称/Project : 零基础入门学用物联网 程序名称/Program name : ESP8266WiFiUdp_12 团队/Team : 太极创客团队 / Taichi-Maker (w…...

基于微信小程序的在线视频课程学习平台设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言用户微信端的主要功能有:管理员的主要功能有:具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding)有保障的售后福利 代码参考源码获取 前言 💗博主介绍:✌全网粉…...
——点云添加高斯噪声)
CloudCompare 二次开发(15)——点云添加高斯噪声
目录 一、概述二、代码集成三、结果展示一、概述 不依赖任何第三方点云相关库,使用CloudCompare编程实现点云添加高斯噪声。添加高斯噪声的算法原理见:PCL 点云添加高斯噪声并保存。 二、代码集成 1、mainwindow.h文件public中添加: void doActionAddGassNoise(); //…...

一波免费、好用的API接口分享
全国快递物流地图轨迹查询:【H5物流轨迹、单号识别】通过物流单号和收寄件地址,自动评估物流时效,并在地图中展示包裹运输轨迹。包括顺丰、圆通、申通等主流快递公司。自动识别快递公司及单号,实时查询,稳定高效&#…...

Android App ~ LiveData
LiveData 两种更新数据方式 setValue(T value)postValue(T value) setValue()只能在主线程中调用,postValue()可以在任何线程中调用。 MutableLiveData 1.首先LiveData其实与数据实体类(POJO类)是一样的东西,它负责暂存数据. 2.其次LiveData其实也是一个观察者…...

全球第4大操作系统(鸿蒙)的软件后缀.hap
system exe 2022-12-01 04:38:38 首页 > 操作系统 145|0条评论 鸿蒙OS兼容已有安卓程序:这事不稀奇。 其实一个系统兼容另外系统的可执行程序并非新鲜事,比如linux下的wine和crossover可以兼容许多win系统的.exe程序。 作为回应,Wind…...

算法练习第六十四天
LCR 184. 设计自助结算系统 - 力扣(LeetCode) 总结:利用一个双端维护队列一个往后递减的队列,对头是最大值,每次进入一个新值时就一直和队尾元素比较将比新的值小的数排出,这样能保证留在队列中的数都是会…...

安卓系列机型 框架LSP 安装步骤 支持多机型 LSP框架通用安装步骤【二】
安卓玩机教程---全机型安卓4----安卓12 框架xp edx lsp安装方法【一】 低版本可以参考上个博文了解相关安装方法。 LSP框架优点 简单来说装lsp框架的优点在于可以安装各种模块。包括 但不限于系统优化 加速 游戏开挂等等的模块。大致相当于电脑的扩展油猴 Lspos…...

实现一个宽高自适应的正方形
.square {width: 10%;height: 10vw;background: tomato; }.square {width: 20%;height: 0;padding-top: 20%;background: orange; }.square {width: 30%;overflow: hidden;background: yellow; } .square::after {content: ;display: block;margin-top: 100%; }...

shell脚本命令
Shell命令是在类Unix操作系统中使用的命令行解释器(shell)中执行的命令。Shell命令可以用于执行系统命令、操作文件、进行文本处理、管理进程等。以下是一些常见的Shell命令: 1. ls:列出当前目录下的文件和文件夹。 2. cd&#x…...
)
Vue2023 面试归纳及复习(2)
1 vue3中的动态组件和KeepAlive组件 动态组件component <component>动态组件是一种可以根据数据变化而动态加载不同组件的方式。使用动态组件可以有效地减少代码复杂度,提高组件的复用性和灵活性。 动态组件通过一个特殊的属性is来实现动态加载,…...
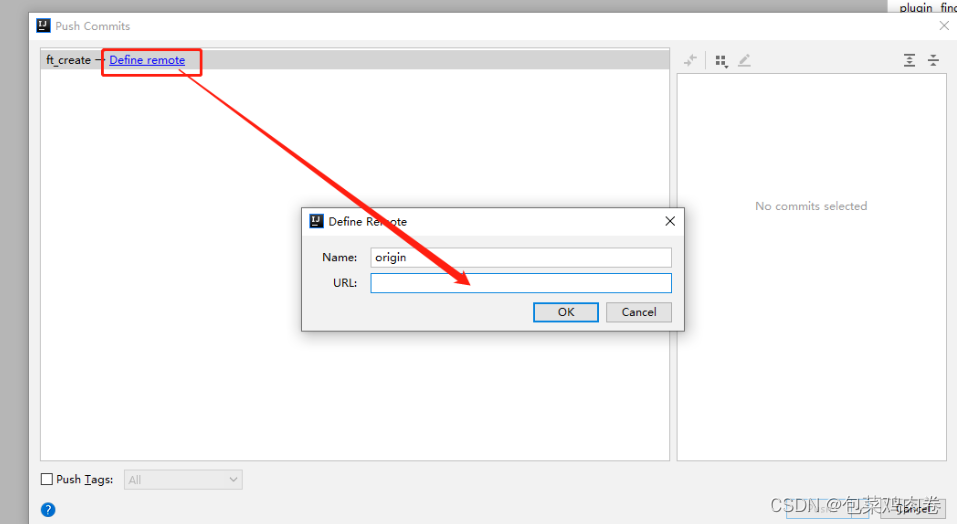
idea 本地项目上传到 Git 步骤
第一步:菜单栏 VCS——>import into Version control——>Create git Repository——>弹出框找到选中自己项目——>点击Ok 第二步:选中项目右键 ——>git——>Add 文件会变成绿色表示成功 第三步:VCS——>commit——>ok 提交到…...

【从0学习Solidity】41. WETH
【从0学习Solidity】41. WETH 博主简介:不写代码没饭吃,一名全栈领域的创作者,专注于研究互联网产品的解决方案和技术。熟悉云原生、微服务架构,分享一些项目实战经验以及前沿技术的见解。关注我们的主页,探索全栈开发…...
微信小程序的无限瀑布流写法
微信小程序的无限瀑布流实现总算做完了,换了好几种方法,过程中出现了各种BUG。 首先官方有瀑布流的插件(Skyline /grid-view),不是原生的我就不想引入,因为我的方块流页面已经搭好了,引入说不定…...

前有CAP理论,后有BASE理论,分布式系统理论基石
🧑💻作者名称:DaenCode 🎤作者简介:CSDN实力新星,后端开发两年经验,曾担任甲方技术代表,业余独自创办智源恩创网络科技工作室。会点点Java相关技术栈、帆软报表、低代码平台快速开…...
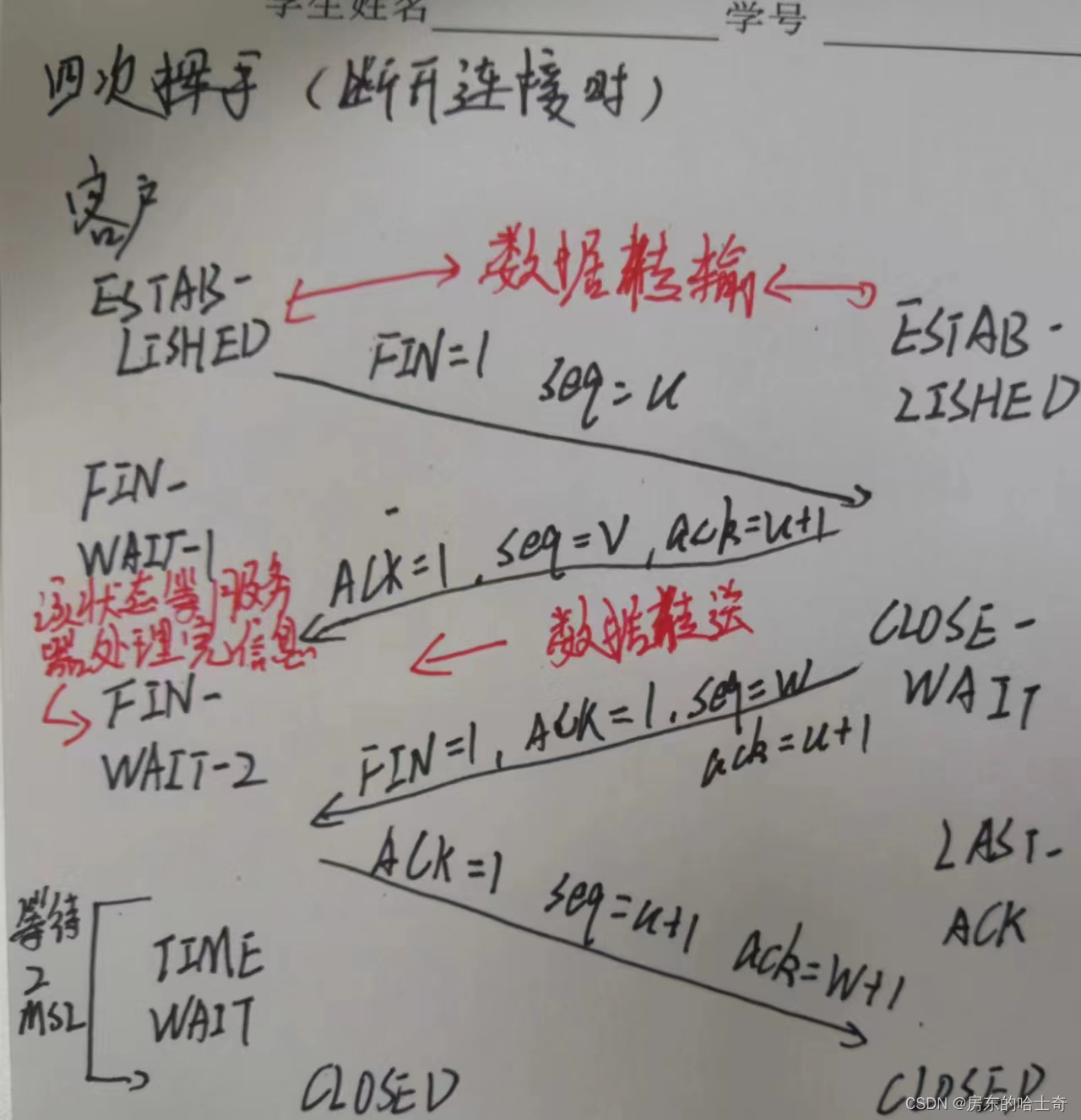
HTTP、TCP、SOCKET三者之间区别和原理
7层网络模型 网络在世界范围内实现互联的标准框架 7层为理想模型,一般实际运用没有7层 详细内容 HTTP属于7层应用层 BSD socket属于5层会话层 TCP/IP属于4成传输层 TCP/IP协议 三次握手 笔者解析: 第一次握手:实现第一步需要客户端主动…...

flutter项目中常用第三方模块
flutter项目中常用第三方模块 持续更新中序言关于第三方模块安装flutter_native_splash使用方式模块配置 flutter_localizations模块配置使用方式 get_storage模块配置使用方式 get模块配置使用方式 持续更新中 序言 本章介绍项目中常用第三方模块,方便快速构建项目…...
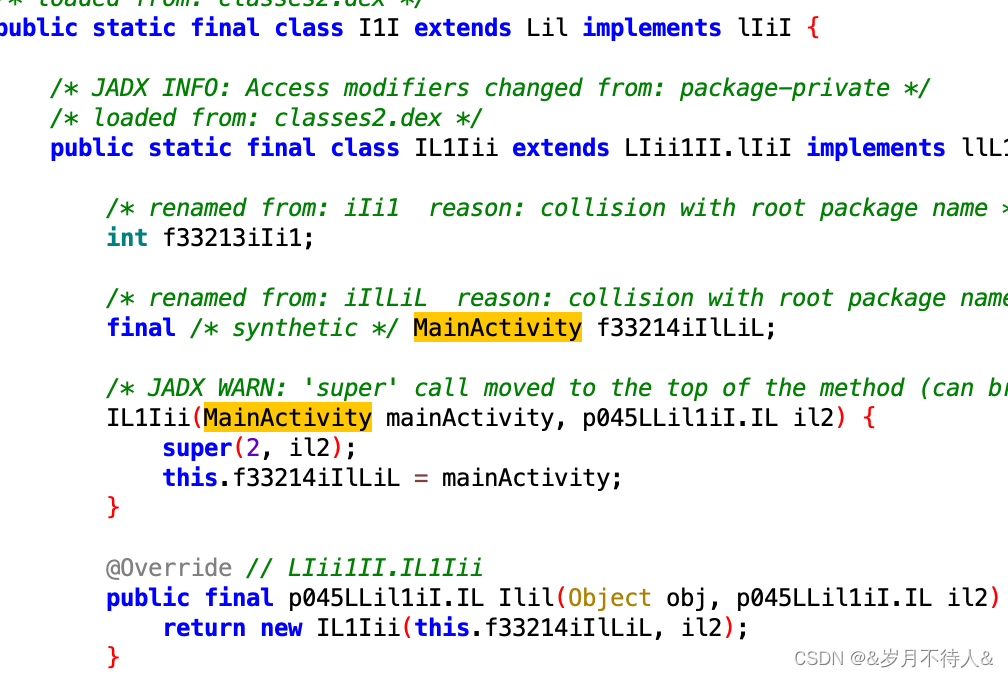
Android 混淆使用及其字典混淆(Proguard)
1.使用背景 ProGuard能够通过压缩、优化、混淆、预检等操作,检测并删除未使用的类,字段,方法和属性,分析和优化字节码,使用简短无意义的名称来重命名类,字段和方法。从而使代码更小、更高效、更难进行逆向工程。 Android代码混淆…...
)
FL Studio自带的Edison插件,才是隐藏的降噪神器!手把手教你清除录音底噪(含参数设置避坑指南)
FL Studio隐藏神器Edison:专业级降噪全流程实战指南 在家庭录音棚里,空调的嗡嗡声、电脑风扇的呼啸、电路底噪的嘶嘶声——这些不受欢迎的"伴奏"总是如影随形。当你在FL Studio中回放刚录制的人声或乐器时,这些背景噪音往往会毁掉整…...

深入解析Keil MDK编译流程:从C代码到单片机运行的完整过程
1. 项目概述:从源码到芯片运行的旅程作为一名在嵌入式领域摸爬滚打了十多年的老工程师,我经常被问到这样一个问题:“我写的C代码,点一下MDK的‘Build’按钮,怎么就变成能在单片机里跑的程序了?” 这背后&am…...

BepInEx框架指南:从游戏玩家到模组开发者的完整升级路径
BepInEx框架指南:从游戏玩家到模组开发者的完整升级路径 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx 你是否曾经羡慕过那些能够为游戏添加新内容、修改界面、甚至创…...

5分钟掌握LXMusic音源配置:告别音乐资源匮乏的终极指南
5分钟掌握LXMusic音源配置:告别音乐资源匮乏的终极指南 【免费下载链接】LXMusic音源 lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/guoyue2010/lxmusic- 还在为找不到心仪歌曲而烦恼吗?你是否厌倦了…...

ICode竞赛Python闯关秘籍:用if else逻辑解锁三级训练场
1. ICode竞赛Python三级训练场通关指南 第一次接触ICode竞赛的Python三级训练场时,我和很多初学者一样被那些复杂的路径判断搞得晕头转向。直到我发现if else语句就像游戏中的"选择道具",整个编程过程突然变得清晰起来。ICode竞赛通过角色控制…...

终极免费解锁Cursor Pro高级功能:完整解决方案深度解析
终极免费解锁Cursor Pro高级功能:完整解决方案深度解析 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tr…...

2026年国产数据库大盘点与趋势:自主可控时代的数据库生态
一、2026年国产数据库市场概况 1. 市场发展现状 2026年国产数据库市场呈现稳步增长态势。在信创政策深化、数据安全法规完善的大背景下,数据库作为核心基础软件,其国产化进程持续推进。 2026年主要厂商市场表现: 金仓KES:在政务领…...
)
TVA驱动智能家居的视觉范式革命(4)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

大麦网Python抢票脚本终极指南:告别手速焦虑,轻松获取心仪门票
大麦网Python抢票脚本终极指南:告别手速焦虑,轻松获取心仪门票 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper 还在为心仪演唱会门票秒光而烦恼吗?还在为黄牛高…...

告别Keil/MDK!用Clion+插件打造STM32的现代化开发工作流
从Keil到Clion:STM32开发者的现代化工作流迁移指南 当稚晖君在B站展示他用Clion开发STM32的流畅体验时,整个嵌入式社区都为之震动。那个视频像一束光,照进了我们这些常年与Keil/MDK为伴的开发者世界——原来嵌入式开发可以如此优雅。但兴奋之…...