Flask 数据库 连接池、DBUtils、http 连接池
1、DBUtils 简介、使用
DBUtils 简介
DBUtils 是一套用于管理 数据库 "连接池" 的Python包,为 "高频度、高并发" 的数据库访问提供更好的性能,可以自动管理连接对象的创建和释放。并允许对非线程安全的数据库接口进行线程安全包装和连接。该连接可在各种多线程环境中使用。
使用场景:如果使用的是流行的对象关系映射器 SQLObject 或 SQLAlchemy 之一,则不需要 DBUtils,因为它们带有自己的连接池。SQLObject 2 (SQL-API) 实际上是从 DBUtils 中借用了一些代码,将池化分离到一个单独的层中。
DBUtils 提供两种外部接口:
- PersistentDB :提供线程专用的数据库连接,并自动管理连接。
- PooledDB :提供线程间可共享的数据库连接,并自动管理连接。
另外,实际使用的数据库驱动也有所依赖,比如SQLite数据库只能使用PersistentDB作连接池。 下载地址:http://www.webwareforpython.org/downloads/DBUtils/
使用 DBUtils 数据库 连接池
安装:pip install DBUtils
示例:MySQLdb 模块使用
连接池对象只初始化一次,一般可以作为模块级代码来确保。 PersistentDB 的连接例子:
import DBUtils.PersistentDB# maxusage 则为一个连接最大使用次数
persist = DBUtils.PersistentDB.PersistentDB(dbpai=MySQLdb,maxusage=1000,**kwargs)# 获取连接池
conn = persist.connection() # 关闭连接池
conn.close() 参数 dbpai 指定使用的数据库模块,兼容 DB-API 。下面是支持 DB-API 2 规范的数据库模块
pip install pymysql(mysql)
pip install pymssql(sqlserver)
pip install cx_Oracle(oracle)
pip install phoenixdb(hbase)
pip install sqlite3(sqlite3 python自带)
DBUtils 仅提供给了连接池管理,实际的数据库操作依然是由符合 DB-API 2 标准的目标数据库模块完成的。
示例:pymysql 模块使用
PooledDB 使用方法同 PersistentDB,只是参数有所不同。
- dbapi :数据库接口
- mincached :启动时开启的空连接数量
- maxcached :连接池最大可用连接数量
- maxshared :连接池最大可共享连接数量
- maxconnections :最大允许连接数量
- blocking :达到最大数量时是否阻塞
- maxusage :单个连接最大复用次数
- setsession :用于传递到数据库的准备会话,如 [”set name UTF-8″] 。
conn = pooled.connection()
cur = conn.cursor()
cur.execute(sql)
res = cur.fetchone()
cur.close() # 或者 del cur
conn.close() # 或者 del conn
import pymysql
from dbutils.pooled_db import PooledDB# 定义连接参数
pool = PooledDB(creator=pymysql,maxconnections=6,mincached=2,maxcached=5,blocking=True,host='localhost',user='root',passwd='123456',db='mydb',port=3306,charset='utf8mb4'
)def main():# 从连接池获取连接conn = pool.connection()cursor = conn.cursor()# 执行 SQL 语句sql = "SELECT * FROM students"cursor.execute(sql)result = cursor.fetchall()# 处理查询结果for row in result:print(row)# 关闭游标和连接cursor.close()conn.close()if __name__ == '__main__':main()
示例:面向对象 使用 DBUtils
"""
使用DBUtils数据库连接池中的连接,操作数据库
"""
import json
import pymysql
import datetime
from DBUtils.PooledDB import PooledDB
import pymysqlclass MysqlClient(object):__pool = None;def __init__(self, mincached=10, maxcached=20, maxshared=10, maxconnections=200, blocking=True,maxusage=100, setsession=None, reset=True,host='127.0.0.1', port=3306, db='test',user='root', passwd='123456', charset='utf8mb4'):""":param mincached:连接池中空闲连接的初始数量:param maxcached:连接池中空闲连接的最大数量:param maxshared:共享连接的最大数量:param maxconnections:创建连接池的最大数量:param blocking:超过最大连接数量时候的表现,为True等待连接数量下降,为false直接报错处理:param maxusage:单个连接的最大重复使用次数:param setsession:optional list of SQL commands that may serve to preparethe session, e.g. ["set datestyle to ...", "set time zone ..."]:param reset:how connections should be reset when returned to the pool(False or None to rollback transcations started with begin(),True to always issue a rollback for safety's sake):param host:数据库ip地址:param port:数据库端口:param db:库名:param user:用户名:param passwd:密码:param charset:字符编码"""if not self.__pool:self.__class__.__pool = PooledDB(pymysql,mincached, maxcached,maxshared, maxconnections, blocking,maxusage, setsession, reset,host=host, port=port, db=db,user=user, passwd=passwd,charset=charset,cursorclass=pymysql.cursors.DictCursor)self._conn = Noneself._cursor = Noneself.__get_conn()def __get_conn(self):self._conn = self.__pool.connection();self._cursor = self._conn.cursor();def close(self):try:self._cursor.close()self._conn.close()except Exception as e:print(e)def __execute(self, sql, param=()):count = self._cursor.execute(sql, param)print(count)return count@staticmethoddef __dict_datetime_obj_to_str(result_dict):"""把字典里面的datatime对象转成字符串,使json转换不出错"""if result_dict:result_replace = {k: v.__str__() for k, v in result_dict.items() if isinstance(v, datetime.datetime)}result_dict.update(result_replace)return result_dictdef select_one(self, sql, param=()):"""查询单个结果"""count = self.__execute(sql, param)result = self._cursor.fetchone()""":type result:dict"""result = self.__dict_datetime_obj_to_str(result)return count, resultdef select_many(self, sql, param=()):"""查询多个结果:param sql: qsl语句:param param: sql参数:return: 结果数量和查询结果集"""count = self.__execute(sql, param)result = self._cursor.fetchall()""":type result:list"""[self.__dict_datetime_obj_to_str(row_dict) for row_dict in result]return count, resultdef execute(self, sql, param=()):count = self.__execute(sql, param)return countdef begin(self):"""开启事务"""self._conn.autocommit(0)def end(self, option='commit'):"""结束事务"""if option == 'commit':self._conn.autocommit()else:self._conn.rollback()if __name__ == "__main__":mc = MysqlClient()sql1 = 'SELECT * FROM shiji WHERE id = 1'result1 = mc.select_one(sql1)print(json.dumps(result1[1], ensure_ascii=False))sql2 = 'SELECT * FROM shiji WHERE id IN (%s,%s,%s)'param = (2, 3, 4)print(json.dumps(mc.select_many(sql2, param)[1], ensure_ascii=False))
不用 连接池
import MySQLdb
conn= MySQLdb.connect(host='localhost',user='root',passwd='pwd',db='myDB',port=3306)
#import pymysql
#conn = pymysql.connect(host='localhost', port='3306', db='game', user='root', password='123456', charset='utf8')
cur=conn.cursor()
SQL="select * from table1"
r=cur.execute(SQL)
r=cur.fetchall()
cur.close()
conn.close()使用 连接池
import MySQLdb
from DBUtils.PooledDB import PooledDB
#5为连接池里的最少连接数
pool = PooledDB(MySQLdb,5,host='localhost',user='root',passwd='pwd',db='myDB',port=3306) # 以后每次需要数据库连接就是用connection()函数获取连接就好了
conn = pool.connection()
cur=conn.cursor()
SQL="select * from table1"
r=cur.execute(SQL)
r=cur.fetchall()
cur.close()
conn.close()多线程 使用 连接池
import sys
import threading
import MySQLdb
import DBUtils.PooledDBconnargs = { "host":"localhost", "user":"user1", "passwd":"123456", "db":"test" }
def test(conn):try:cursor = conn.cursor()count = cursor.execute("select * from users")rows = cursor.fetchall()for r in rows: passfinally:conn.close()def testloop():print ("testloop")for i in range(1000):conn = MySQLdb.connect(**connargs)test(conn)def testpool():print ("testpool")pooled = DBUtils.PooledDB.PooledDB(MySQLdb, **connargs)for i in range(1000):conn = pooled.connection()test(conn)def main():t = testloop if len(sys.argv) == 1 else testpoolfor i in range(10):threading.Thread(target = t).start()if __name__ == "__main__":main()虽然测试方式不是很严谨,但从测试结果还是能感受到 DBUtils 带来的性能提升。当然,我们我们也可以在 testloop() 中一直重复使用一个不关闭的 Connection,但这却不适合实际开发时的情形。
2、Flask 配置,蓝图,数据库连接池,上下文原理
Flask之配置文件,蓝图,数据库连接池,上下文原理:https://www.cnblogs.com/yunweixiaoxuesheng/p/8418135.html
配 置
方式一,使用字典方式配置
app.config['SESSION_COOKE_NAME'] = 'session_liling'
方式二,引入文件,设置
from flask import Flask
app = Flask(__name__)
app.config.from_pyfile('settings.py') # 引用settings.py中的AAAA
print(app.config['AAAA']) # 123# settings.py
AAAA = 123
方法三,使用环境变量设置,推荐使用
from flask import Flask
app = Flask(__name__)
import os
os.environ['FLASK-SETTINGS'] = 'settings.py'
app.config.from_envvar('FLASK-SETTINGS')
方式四,通过对象方式导入使用,可根据不同环境选择不同的配置,推荐使用
from flask import Flask
app = Flask(__name__)
app.config.from_object('settings.BaseConfig')
print(app.config['NNNN']) # 123
# settings.pyclass BaseConfig(object): # 公用配置
NNNN = 123
class TestConfig(object):
DB = '127.0.0.1'
class DevConfig(object):
DB = '192.168.1.1'
class ProConfig(object):
DB = '47.18.1.1'
不同的文件 引用配置
from flask import Flask,current_appapp = Flask(__name__)app.secret_key = 'adfadsfhjkhakljsdfh'app.config.from_object('settings.BaseConfig')@app.route('/index')
def index():print(current_app.config['NNNN'])return 'xxx'if __name__ == '__main__':app.run()instance_path、instance_relative_config
from flask import Flask,current_appapp = Flask(__name__,instance_path=None,instance_relative_config=False)
# 默认 instance_relative_config = False 那么 instance_relative_config和instance_path都不会生效
# instance_relative_config=True,instance_path才会生效,app.config.from_pyfile('settings.py')将会失效
# 配置文件找的路径,按instance_path的值作为配置文件路径
# 默认instance_path=None,None会按照当前路径下的instance文件夹为配置文件的路径
# 如果设置路径,按照设置的路径查找配置文件。app.config.from_pyfile('settings.py')@app.route('/index')
def index():print(current_app.config['NNNN'])return 'xxx'if __name__ == '__main__':app.run()蓝 图
对应用程序的目录结构进行分配,一般适用于小中型企业

代码:
# crm/__init__.py
# 创建flask项目,用蓝图注册不同的模块from flask import Flask
from .views import account
from .views import orderapp = Flask(__name__)app.register_blueprint(account.account)
app.register_blueprint(order.order)------------------------------------------------------------------------
# manage.py
# 启动文件
import crmif __name__ == '__main__':crm.app.run()------------------------------------------------------------------------
# crm/views/account.py
# 视图函数模块,Blueprint,将函数引入app
from flask import Blueprintaccount = Blueprint('account',__name__,url_prefix='/xxx')@account.route('/login')
def login():return 'Login'Flask 数据库 连接池
:https://www.cnblogs.com/TheLand/p/9178305.html
ORM ( 对象关系映射 )
ORM(Object-Relational Mapping,对象关系映射)是一种编程技术,用于在关系型数据库和面向对象编程语言之间建立映射关系。它允许开发人员使用面向对象的方式来操作数据库,而无需直接编写或执行 SQL 查询。
ORM 提供了一个抽象层,将数据库表格映射为对象,并提供了一组方法和工具,以便于进行数据库的增删改查操作。开发人员可以通过使用对象和方法来表示和操作数据,而不必关心底层的 SQL 语句和数据库细节。
常见的 ORM 框架包括:
- SQLAlchemy:是 python 操作数据库的一个库,能够进行 orm 映射,是一个功能强大的 Python ORM 框架,支持多种数据库后端,提供了高级的查询功能和事务管理等特性。是为高效和高性能的数据库访问设计,实现了完整的企业级持久模型。SQLAlchemy 的理念是,SQL 数据库的量级和性能重要于对象集合;而对象集合的抽象又重要于表和行。
- Flask-SQLAlchemy:Flask-SQLAlchemy 是一个与 Flask 框架集成的 SQLAlchemy 扩展,它简化了在 Flask 应用程序中使用 SQLAlchemy 进行数据库操作的过程。它提供了一组简单而强大的工具和功能,使得与数据库的交互变得更加轻松和高效。
- Django ORM:Django 框架自带的 ORM,提供了简单易用的接口,支持多种数据库后端,并具有强大的查询和模型关联功能。
- Hibernate:Java 领域中最流行的 ORM 框架,为 Java 对象和关系型数据库之间提供了映射和管理。
使用 ORM 的好处包括:
- 提高开发效率:ORM 提供了面向对象的编程接口,使得开发人员能够更快速地进行数据库操作,减少了编写和调试 SQL 语句的工作量。
- 跨数据库平台:ORM 框架通常支持多种数据库后端,使得开发人员能够轻松地切换或同时使用不同的数据库系统。
- 数据库抽象和安全性:ORM 隐藏了底层的数据库细节,提供了一层抽象,有助于维护和管理数据库结构,并提供了安全性保护,如参数绑定和防止 SQL 注入。
- 更好的可维护性和可测试性:使用 ORM 可以提高代码的可读性和可维护性,使得进行单元测试和集成测试更加容易。
注意:ORM 并不能解决所有数据库问题。在某些情况下,复杂的查询和性能要求可能需要直接使用原生 SQL。因此,根据具体的需求和场景,谨慎选择和使用合适的 ORM 框架。
为什么 使用 数据库 连接池
- 多连接:如果不用连接池时,每次操作都要链接数据库,链接次数过多,数据库会耗费过多资源,数量过大的话,数据库会过载,导致程序运行缓慢。
- 单连接:在程序中全局创建连接,导致程序会一直使用一个连接,避免了反复连接造成的问题。但是多线程时就得加锁。这样就变成串行,没法实现并发
解决方法:
- 方式 1:为每一个线程创建一个链接(是基于本地线程来实现的。thread.local),每个线程独立使用自己的数据库链接,该线程关闭不是真正的关闭,本线程再次调用时,还是使用的最开始创建的链接,直到线程终止,数据库链接才关闭。如果线程比较多还是会创建很多连接
- 方式 2:创建一个链接池,为所有线程提供连接,使用时来进行获取,使用完毕后在放回到连接池。假设最大链接数有10个,其实也就是一个列表,当你pop一个,人家会在append一个,链接池的所有的链接都是按照排队的这样的方式来链接的。链接池里所有的链接都能重复使用,共享的, 即实现了并发,又防止了链接次数太多
基于 DBUtils 数据库连接池
数据库连接池避免每次操作都要连接数据库,一直使用一个连接,多线程也会出现问题,可加锁,但变为串行
import pymysql
import threading
from threading import RLockLOCK = RLock()
CONN = pymysql.connect(host='127.0.0.1',port=3306,user='root',password='123',database='ok1',charset='utf8'
)def task(arg):with LOCK:cursor = CONN.cursor()cursor.execute('select * from book')result = cursor.fetchall()cursor.close()print(result)for i in range(10):t = threading.Thread(target=task, args=(i,))t.start()
线程之间 的 数据隔离
"本地线程" 可以实现线程之间的数据隔离。保证每个线程都只有自己的一份数据,在操作时不会影响别人的,即使是多线程,自己的值也是互相隔离的
import threading
import time# 本地线程对象
local_values = threading.local()def func(num):"""# 第一个线程进来,本地线程对象会为他创建一个# 第二个线程进来,本地线程对象会为他创建一个{线程1的唯一标识:{name:1},线程2的唯一标识:{name:2},}:param num: :return: """local_values.name = num # 4# 线程停下来了time.sleep(2)# 第二个线程: local_values.name,去local_values中根据自己的唯一标识作为key,获取value中name对应的值print(local_values.name, threading.current_thread().name)for i in range(5):th = threading.Thread(target=func, args=(i,), name='线程%s' % i)th.start()
模式一:每个线程创建一个连接
基于threading.local实现创建每个连接。
每个线程会创建一个连接,该线程没有真正关闭。
再次调用该线程时,还是使用原有的连接。
线程真正终止的时候,连接才会关闭。
from DBUtils.PersistentDB import PersistentDB
import pymysqlPOOL = PersistentDB(creator=pymysql, # 使用链接数据库的模块maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]ping=0,# ping MySQL服务端,检查是否服务可用。# 如:0 = None = never, 1 = default = whenever it is requested, 2 = when a cursor is created, 4 = when a query is executed, 7 = alwayscloseable=False,# 如果为False时, conn.close() 实际上被忽略,供下次使用,再线程关闭时,才会自动关闭链接。如果为True时, conn.close()则关闭链接,那么再次调用pool.connection时就会报错,因为已经真的关闭了连接(pool.steady_connection()可以获取一个新的链接)threadlocal=None, # 本线程独享值得对象,用于保存链接对象,如果链接对象被重置host='127.0.0.1',port=3306,user='root',password='123',database='pooldb',charset='utf8'
)def func():# conn = SteadyDBConnection()conn = POOL.connection()cursor = conn.cursor()cursor.execute('select * from tb1')result = cursor.fetchall()cursor.close()conn.close() # 不是真的关闭,而是假的关闭。 conn = pymysql.connect() conn.close()conn = POOL.connection()cursor = conn.cursor()cursor.execute('select * from tb1')result = cursor.fetchall()cursor.close()conn.close()import threadingfor i in range(10):t = threading.Thread(target=func)t.start()模式二:线程复用连接池 (推荐)
创建一个连接池,为所有线程提供连接,线程使用连接时获取连接,使用完毕放回连接池。
线程不断地重用连接池里的连接。
import time
import pymysql
import threading
from DBUtils.PooledDB import PooledDB, SharedDBConnectionPOOL = PooledDB(creator=pymysql, # 使用链接数据库的模块maxconnections=6, # 连接池允许的最大连接数,0和None表示不限制连接数mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建maxcached=5, # 链接池中最多闲置的链接,0和None不限制maxshared=3,# 链接池中最多共享的链接数量,0和None表示全部共享。# PS: 无用,因为pymysql和MySQLdb等模块的 threadsafety都为1,所有值无论设置为多少,# _maxcached永远为0,所以永远是所有链接都共享。blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]# ping MySQL服务端,检查是否服务可用。# 如:0 = None = never, 1 = default = whenever it is requested, # 2 = when a cursor is created, 4 = when a query is executed, 7 = alwaysping=0,host='127.0.0.1',port=3306,user='root',password='123456',database='flask_test',charset='utf8'
)def func():# 检测当前正在运行连接数的是否小于最大链接数,如果不小于则:等待或报raise TooManyConnections异常# 否则# 则优先去初始化时创建的链接中获取链接 SteadyDBConnection。# 然后将SteadyDBConnection对象封装到PooledDedicatedDBConnection中并返回。# 如果最开始创建的链接没有链接,则去创建一个SteadyDBConnection对象,# 再封装到PooledDedicatedDBConnection中并返回。# 一旦关闭链接后,连接就返回到连接池让后续线程继续使用。# PooledDedicatedDBConnectionconn = POOL.connection()# print(th, '链接被拿走了', conn1._con)# print(th, '池子里目前有', pool._idle_cache, '\r\n')cursor = conn.cursor()cursor.execute('select * from userinfo')result = cursor.fetchall()print(result)conn.close()conn = POOL.connection()# print(th, '链接被拿走了', conn1._con)# print(th, '池子里目前有', pool._idle_cache, '\r\n')cursor = conn.cursor()cursor.execute('select * from userinfo')result = cursor.fetchall()conn.close()func()上下文管理
所谓上下文,像考试题目根据上下文,回答一下问题。
程序中,泛指的外部环境,像wsgi来的网络请求,而且通常只有上文。
flask中的上下文,被使用在 current_app,session,request 上。
flask 本地线程
from flask import sessiontry:from greenlet import getcurrent as get_ident # grenlet协程模块
except ImportError:try:from thread import get_identexcept ImportError:from _thread import get_ident # get_ident(),获取线程的唯一标识class Local(object): # 引用session中的LocalStack下的Local__slots__ = ('__storage__', '__ident_func__') # __slots__该类在外面调用时,只能调用定义的字段,其他的不能调用def __init__(self):# object.__setattr__为self设置值,等价于self.__storage__ = {}# 为父类object中包含的__steattr__方法中的self.__storage__ = {}# 由于类内包含__steattr__,self.xxx(对象.xxx)时会自动会触发__steattr__,# 当前__steattr__中storage = self.__storage__又会像self.xxx要值,故会造成递归# 所以在父类中__steattr__方法赋值,避免self.xxx调用__setattr__造成的递归object.__setattr__(self, '__storage__', {})object.__setattr__(self, '__ident_func__', get_ident) # 赋值为协程def __iter__(self):return iter(self.__storage__.items())def __release_local__(self):self.__storage__.pop(self.__ident_func__(), None)def __getattr__(self, name):try:return self.__storage__[self.__ident_func__()][name]except KeyError:raise AttributeError(name)def __setattr__(self, name, value):ident = self.__ident_func__() # 获取单钱线程(协程)的唯一标识storage = self.__storage__ # {}try:storage[ident][name] = value # { 111 : {'stack':[] },222 : {'stack':[] } }except KeyError:storage[ident] = {name: value}def __delattr__(self, name):try:del self.__storage__[self.__ident_func__()][name]except KeyError:raise AttributeError(name)_local = Local() # flask的本地线程功能,类似于本地线程,如果有人创建Local对象并,设置值,每个线程里一份
_local.stack = [] # _local.stack会调用__setattr__的self.__ident_func__()取唯一标识等
特殊栈
from flask import sessiontry:from greenlet import getcurrent as get_ident
except ImportError:try:from thread import get_identexcept ImportError:from _thread import get_ident # 获取线程的唯一标识 get_ident()class Local(object):__slots__ = ('__storage__', '__ident_func__')def __init__(self):# self.__storage__ = {}# self.__ident_func__ = get_identobject.__setattr__(self, '__storage__', {})object.__setattr__(self, '__ident_func__', get_ident)def __iter__(self):return iter(self.__storage__.items())def __release_local__(self):self.__storage__.pop(self.__ident_func__(), None)def __getattr__(self, name):try:return self.__storage__[self.__ident_func__()][name]except KeyError:raise AttributeError(name)def __setattr__(self, name, value):ident = self.__ident_func__() # 获取当前线程(协程)的唯一标识storage = self.__storage__ # {}try:storage[ident][name] = value # { 111:{'stack':[] },222:{'stack':[] } }except KeyError:storage[ident] = {name: value}def __delattr__(self, name):try:del self.__storage__[self.__ident_func__()][name]except KeyError:raise AttributeError(name)_local = Local()
_local.stack = []
使用 flask 中的 stack 和 local
from functools import partial
from flask.globals import LocalStack, LocalProxy_request_ctx_stack = LocalStack()class RequestContext(object):def __init__(self, environ):self.request = environdef _lookup_req_object(name):top = _request_ctx_stack.topif top is None:raise RuntimeError(_request_ctx_stack)return getattr(top, name)# 实例化了LocalProxy对象,_lookup_req_object参数传递
session = LocalProxy(partial(_lookup_req_object, 'session'))"""
local = {“标识”: {'stack': [RequestContext(),]}
}
"""
_request_ctx_stack.push(RequestContext('c1')) # 当请求进来时,放入print(session) # 获取 RequestContext('c1'), top方法
print(session) # 获取 RequestContext('c1'), top方法
_request_ctx_stack.pop() # 请求结束pop
示例:
from functools import partial
from flask.globals import LocalStack, LocalProxyls = LocalStack()class RequestContext(object):def __init__(self, environ):self.request = environdef _lookup_req_object(name):top = ls.topif top is None:raise RuntimeError(ls)return getattr(top, name)session = LocalProxy(partial(_lookup_req_object, 'request'))ls.push(RequestContext('c1')) # 当请求进来时,放入
print(session) # 视图函数使用
print(session) # 视图函数使用
ls.pop() # 请求结束popls.push(RequestContext('c2'))
print(session)ls.push(RequestContext('c3'))
print(session)
Flask SQLAlchemy 使用 连接池
Flask SQLAlchemy 提供了内置的连接池功能,可以方便地配置和使用。
在Flask应用中,我们可以通过配置 SQLALCHEMY_POOL_SIZE 参数来设置连接池的大小。连接池的大小决定了同时打开的数据库连接的数量。例如,我们可以将连接池的大小设置为10:
app.config['SQLALCHEMY_POOL_SIZE'] = 10
from flask_sqlalchemy import SQLAlchemyapp = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://user:password@localhost/db_name'
db = SQLAlchemy(app)# 创建模型类
class User(db.Model):id = db.Column(db.Integer, primary_key=True)name = db.Column(db.String(50))# 添加数据到数据库
user = User(name='John')
db.session.add(user)
db.session.commit()# 查询数据
all_users = User.query.all()# 更新数据
user = User.query.filter_by(name='John').first()
user.name = 'Jane'
db.session.commit()# 删除数据
user = User.query.filter_by(name='Jane').first()
db.session.delete(user)
db.session.commit()
3、flask http 连接池
Flask 本身并不提供内置的 HTTP 连接池功能,但可以使用第三方库来实现在 Flask 中使用 HTTP 连接池。其中一个常用的库是 urllib3,它提供了高级的连接池管理功能。
示例:在 Flask 中使用 urllib3 来创建和管理 HTTP 连接池:
安装:pip install urllib3
from flask import Flask
import urllib3app = Flask(__name__)"""
使用 urllib3.PoolManager() 创建了一个连接池管理器对象 http,然后使用 http.request() 方法发送了一个 GET 请求。
您可以根据需要进行配置和自定义,例如设置最大连接数、超时时间、重试策略等。以下是一个示例,展示了如何进行自定义设置:
"""@app.route('/index_1')
def index_1():http = urllib3.PoolManager()response = http.request('GET', 'http://api.example.com')return response.data"""
对连接池进行了一些自定义配置,包括最大连接数、每个连接的最大数量、连接和读取的超时时间以及重试策略。
使用 urllib3 可以更好地控制和管理 HTTP 连接,提高 Flask 应用程序的性能和效率。
"""@app.route('/index_2')
def index_2():http = urllib3.PoolManager(num_pools=10, # 最大连接数maxsize=100, # 每个连接的最大数量timeout=urllib3.Timeout(connect=2.0, read=5.0), # 连接和读取的超时时间retries=urllib3.Retry(total=3, backoff_factor=0.1, status_forcelist=[500, 502, 503, 504]) # 重试策略)response = http.request('GET', 'http://api.example.com')return response.data
相关文章:
Flask 数据库 连接池、DBUtils、http 连接池
1、DBUtils 简介、使用 DBUtils 简介 DBUtils 是一套用于管理 数据库 "连接池" 的Python包,为 "高频度、高并发" 的数据库访问提供更好的性能,可以自动管理连接对象的创建和释放。并允许对非线程安全的数据库接口进行线程安全包装…...

Day 01 python学习笔记
1、引入 让我们先写第一个python程序(如果是纯小白的话) 因为我们之前安装了python解释器 所以我们直接win r ---->输入cmd(打开运行终端) >python #(在终端中打开python解释器)>>>pri…...

CSharp Library develop histroy
1. .NET FRAMEWORK 发展版本 版本 完整版本号 发行日期 Visual Studio Windows 默认安装 1.0 1.0.3705.0 2002-02-13 Visual Studio .NET 2002 Windows XP Media Center Edition Windows XP Tablet PC Edition 1.1 1.1.4322.573 2003-04-24 Visual Studio .NET 2…...

林木种苗生产vr虚拟实训教学降低培训等待周期
林业种植管理在保护水土流失、气候变化及经济社会发展中发挥重要的作用,林业教学往往需要进入林区进行实操察验,在安全性、时间及效率上难以把控,因此有更多林业畜牧院校创新性地引进VR虚拟现实技术。 在林业领域,实地调查是获取准…...
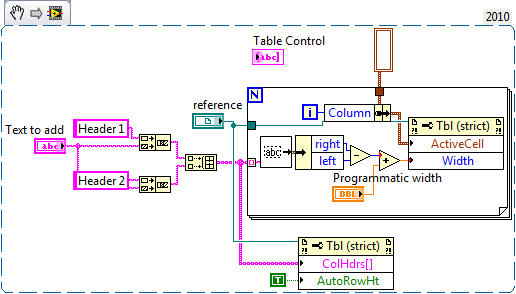
LabVIEW在运行时调整表控件列宽
LabVIEW在运行时调整表控件列宽 如何在LabIEW中运行时调整表控件的列宽大小? 在VI运行时,有两种不同的方法可以更改表中列的宽度。首先,可以使用鼠标手动更改它们;其次,可以从框图中以编程方式更改它们。 手动更改列宽 只有在…...

【6 ElementUI Tabs控件第二个tab页签Div宽度缩小的问题】
背景 在使用ElementUI的Tabs 控件时,发现第二个tabs 内容的Div宽度用的百分比,然后就会缩小,导致内容变形,这边的处理方法就是拿到一个tabs 内容的div的offsetWidth,然后将这个width赋值给第二个Div的width即可。 代…...
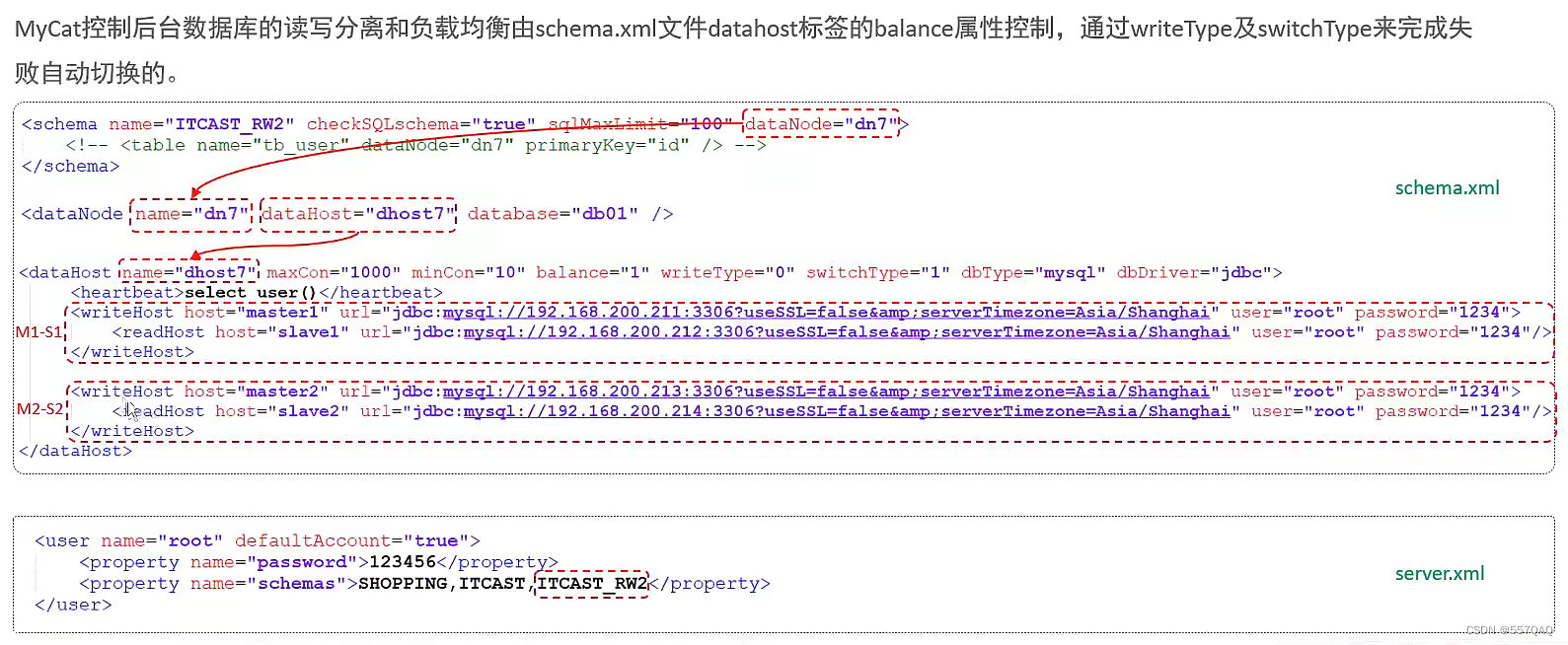
读写分离MySQL
利用Mycat控制后台数据库的读写分离和负载均衡 利用主从复制思想,实现读写分离,主库写,从库读 从库最好不要写,因为从库写入的数据不能同步到主库,只有主库写的数据才能同步到从库 balance属性值对应的含义(负载均衡) 一主一从读写分离的弊端 主节点Master宕机以后,业务系统…...
MySQL数据库用户管理
MySQL数据库用户管理 1、数据库权限1.1什么是数据库权限1.2数据库权限分类1.3用户管理 2、用户授权2.1grant提权2.2查看权限2.3撤销权限 3、修改密码3.1修改当前用户密码3.2修改其他用户密码3.3修改root密码 4、远程登录4.1远程登录4.2软件远程登录 5、总结 1、数据库权限 1.1…...

package.json属性
添加链接描述 一、必须属性 name 定义项目的名称,不能以".“和”_"开头,不能包含大写字母version 定义项目的版本号,格式为:大版本号.次版本号.修订号 二、描述信息 description 项目描述keywords 项目关键词author …...

C# 把m4a格式文件转为MP3格式
直接上代码: 先引用 using NAudio.Wave; using NAudio.Lame; 1, 文件列表来自于根目录里所有的m4a文件 string directloc "G:\mp3\MP3"; string[] fyles Directory.GetFiles(directloc); NAudio.Wave.BlockAlignReductionStream stream …...
【分享】Word文档如何批量转换成PDF?
Word格式比较容易编辑,是工作中经常用到的文档工具,有时候为了避免文档在传送中出现乱码,或者防止被随意更改,很多人会把Word文档转换成PDF,那Word文档要怎样转成PDF呢?如果Word文档很多,有没有…...

dedecms tag 伪静态 数字版本
织梦伪静态将tag标签的url设置成id的方法: 1、在网站根目录下的tags.php中18行找到: if(isset($tags[2])) $PageNo intval($tags[2]);在其下方加入代码: $tagid intval($tag); if(!empty($tagid)) {$row $dsql->GetOne("SELECT …...

mysql数据库ip被阻断
windos服务器还是 linux服务器没关系。 登录服务器mysql 授权法。 例如,你想myuser使用mypassword从任何主机连接到mysql服务器的话。 GRANT ALL PRIVILEGES ON *.* TO myuser% IDENTIFIED BY mypassword WITH GRANT OPTION如果你想允许用户myuser…...
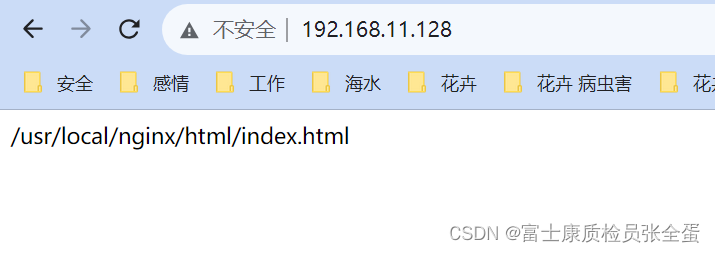
Nginx WEB访问与Linux授权约束
看到所有文件的权限都是没有的,即便所有的权限都没有即使nginx做了配置,这些都是正确的。那么在浏览器真正去访问的时候是不能访问的。 [rootjenkins html]# ls -l total 4 drwxr-xr-x 2 root root 23 Sep 16 17:43 dist ---------- 1 root root 33 Sep …...

影响独立服务器稳定运行的因素
影响独立服务器稳定运行的因素 独立服务器的稳定对于网站和运行的程序来说都是最重要的因素,不只是简单的影响网站的速度,也影响搜索引擎对网站的优化。试想一下,客户在访问网站时,网页长时间打不开,页面崩溃会导致客户…...
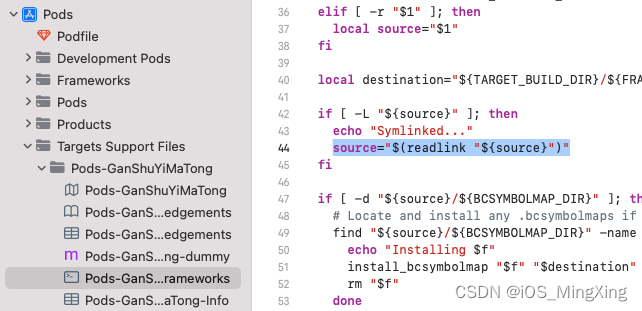
Xcode14.3.1打包报错Command PhaseScriptExecution failed with a nonzero exit code
真机运行编译正常,一打包就报错 rsync error: some files could not be transferred (code 23) at /AppleInternal/Library/BuildRoots/d9889869-120b-11ee-b796-7a03568b17ac/Library/Caches/com.apple.xbs/Sources/rsync/rsync/main.c(996) [sender2.6.9] Command PhaseScrip…...
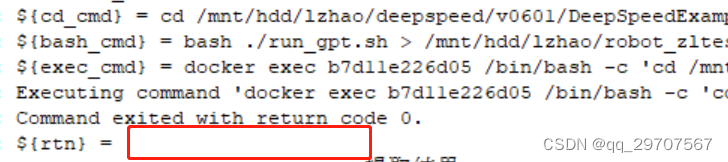
[RF学习记录][ssh library][execute Command】关键字的返回值
有时候需要判断通过ssh在远程机器上执行的命令是否正常,使用关键字Execute Command可以在远程机器上运行命令,但是默认不加任何参数的话,没有看到范返回值,而这个关键字是带了几个参数的,简单的试验了下这几个参数&…...

【Python入门教程】Python实现猜数字小游戏
今天跟大家分享一下很久之前自己做的一款猜数字小游戏,基本的循环判断语句即可实现,可以用来当练手或者消磨时间用。 大家在编代码的时候最重要就是先理清逻辑思路,例如应该套几层循环、分几个模块等等。然后在编码时可以先随意一点ÿ…...
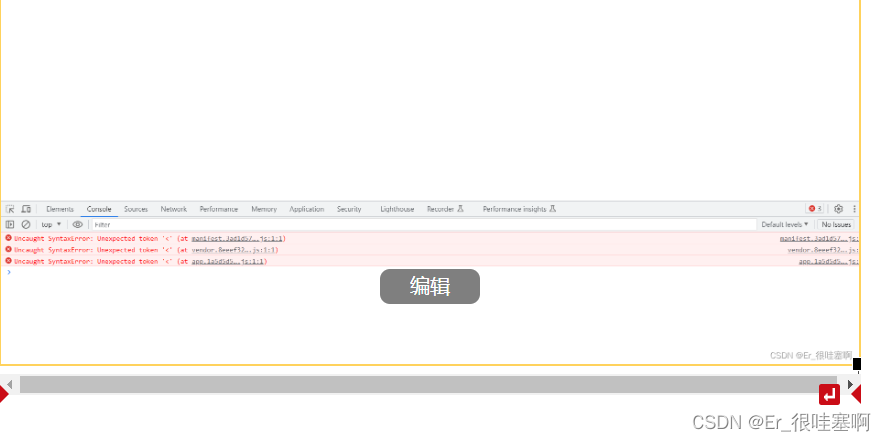
vue项目打包部署到服务器,报错。
这个是因为后端部署服务器时,名称没有对上,不是前端的问题,后端配置名称和前端的包名称保持一致就可以了。...

适用于初学者,毕业设计的5个c语言项目,代码已开源
C语言项目集 项目介绍 该项目适用于初学者学习c语言,也适用于高校学生课程设计,毕业设计参考。 项目并不能满足所有人的需求,可进行项目指导,定制开发。 开源地址 c语言项目代码地址 项目列表 该项目包含如下5个管理系统&am…...

告别手动Coding:用EB tresos Studio配置TC3xx芯片MCAL的保姆级图文指南
告别手动Coding:用EB tresos Studio配置TC3xx芯片MCAL的保姆级图文指南 当TC3xx系列芯片遇上AUTOSAR架构,传统寄存器级开发方式正在被图形化配置彻底革新。对于每天需要面对微控制器底层驱动的嵌入式工程师而言,EB tresos Studio提供的可视化…...

盲人出行辅助系统原型
我做了一个很有意义的盲人出行辅助系统原型,主要是结合现有导航OSRM/高德,实时感知前方潜在危险目标,辅助视障人士出行。 持续优化中(20260519),欢迎大家尝试,有一些想法也可以提出来。 开源地址…...
3分钟掌握Pixelle-Video:零基础AI视频制作终极指南
3分钟掌握Pixelle-Video:零基础AI视频制作终极指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 还在为视频制作烦恼吗&am…...

大模型微调实战:用LoRA技术微调LLaMA 2模型
在人工智能技术飞速发展的当下,大语言模型(LLM)在自然语言处理领域展现出了强大的能力。LLaMA 2作为Meta推出的开源大模型,凭借其出色的性能和广泛的适用性,成为了众多开发者和研究人员的首选。对于软件测试从业者而言…...

从开发板到工业边缘计算平台:UP Board二代的硬件解析与应用实战
1. 项目概述:从“开发板”到“边缘计算平台”的认知跃迁最近在整理手头的嵌入式设备,翻出了这块研扬的UP Board二代。说实话,第一次拿到它的时候,我下意识地还是把它归类为“一块性能不错的x86开发板”,就像树莓派之于…...

如何用Univer在3小时内构建企业级电子表格应用?5个实战技巧分享
如何用Univer在3小时内构建企业级电子表格应用?5个实战技巧分享 【免费下载链接】univer Build AI-native spreadsheets. Univer is a full-stack framework for creating and editing spreadsheets on both web and server. With Univer Platform, Univer Spreadsh…...

Perplexity+知网联合检索的7类失效场景全图谱:从DOI解析失败到CSSCI标识丢失的终极修复手册
更多请点击: https://intelliparadigm.com 第一章:Perplexity知网联合检索的失效机理总论 当用户尝试将 Perplexity AI 的实时网络推理能力与知网(CNKI)学术资源库进行协同调用时,系统级耦合在协议层、语义层与权限层…...

LAMMPS GPU加速踩坑实录:CUDA driver error 4报错,原来问题出在CPU核数上
LAMMPS GPU加速实战:从CUDA driver error 4报错到性能调优全解析 当你在深夜的实验室里盯着终端不断刷新的红色报错信息,那种挫败感我深有体会。作为一名长期使用LAMMPS进行分子动力学模拟的研究者,我清楚地记得第一次遇到"CUDA driver …...

基于姿态识别的互动健身系统:用烟花激励锻炼
1. 项目概述:当健身遇上烟花秀这个项目最让我兴奋的点在于:它把枯燥的健身动作变成了创造烟花的魔法。想象一下,当你做一个标准的深蹲,屏幕上会绽放出金色烟花;手臂举到完美角度时,紫色烟火会螺旋上升——这…...

终极SOCD解决方案:3分钟让你的游戏操作职业化
终极SOCD解决方案:3分钟让你的游戏操作职业化 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否在玩《街头霸王》时连招总是失败?在《Apex英雄》中急停转向时角色卡顿?《…...