五、核支持向量机算法(NuSVC,Nu-Support Vector Classification)(有监督学习)
和支持向量分类(Nu-Support Vector Classification),与 SVC 类似,但使用一个参数来控制支持向量的数量,其实现基于libsvm
一、算法思路
本质都是SVM中的一种优化,原理都类似,详细算法思路可以参考博文:三、支持向量机算法(SVC,Support Vector Classification)(有监督学习)
二、官网API
官网API
class sklearn.svm.NuSVC(*, nu=0.5, kernel='rbf', degree=3, gamma='scale', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr', break_ties=False, random_state=None)
导包:from sklearn.svm import NuSVC
①边际误差分数nu
边际误差分数的上限和支持向量分数的下限,用来控制支持向量的数目和边际误差;nu范围应为(0,1],默认值为0.5
具体官网详情如下:

使用方法
NuSVC(nu=0.5)
②核函数kernel
‘linear’:线性核函数,速度快;只能处理数据集样本线性可分,不能处理线性不可分。
‘poly’:多项式核函数,可将数据集样本升维,从低维空间映射到高维空间;参数较多,计算量大
‘rbf’:高斯核函数,和多项式核函数一样,可将样本升维;相较于多项式核函数来说,参数较少;默认值
'sigmoid’:sigmoid 核函数;当选用 sigmoid 核函数时,SVM 可实现的是多层神经网络
‘precomputed’:核矩阵;使用用户给定的核函数矩阵(n*n)
也可以自定义自己的核函数,然后进行调用即可
具体官网详情如下:

使用方法
NuSVC(kernel='sigmoid')
③多项式核函数的阶数degree
多项式核函数的阶数;该参数只对多项式核函数(poly)有用;若是其他的核函数,系统会自动忽略该参数
具体官网详情如下:

使用方式
NuSVC(kernel='poly',degree=2)
④核系数gamma
rbf、poly 和 sigmoid核函数的核系数,该参数只针对这三个核函数,需要注意
‘scale’:默认值,具体的计算公式看下面的详细官网详情
‘auto’:具体的计算公式看下面的详细官网详情
或者是其他的浮点数均可
具体官网详情如下:

使用方式
NuSVC(gamma='auto')
⑤随机种子random_state
如果要是为了对比,需要控制变量的话,这里的随机种子最好设置为同一个整型数
具体官网详情如下:

使用方式
NuSVC(random_state=42)
⑥最终构建模型
NuSVC(nu=0.5,kernel=‘rbf’,gamma=‘auto’,random_state=42)
三、代码实现
①导包
这里需要评估、训练、保存和加载模型,以下是一些必要的包,若导入过程报错,pip安装即可
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import joblib
%matplotlib inline
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.svm import NuSVC
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
②加载数据集
数据集可以自己简单整个,csv格式即可,我这里使用的是6个自变量X和1个因变量Y
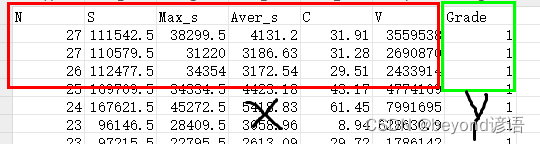
fiber = pd.read_csv("./fiber.csv")
fiber.head(5) #展示下头5条数据信息
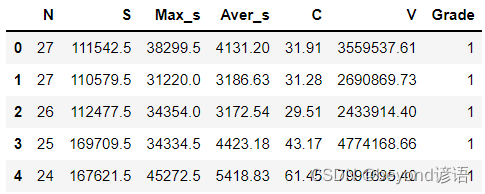
③划分数据集
前六列是自变量X,最后一列是因变量Y
常用的划分数据集函数官网API:train_test_split
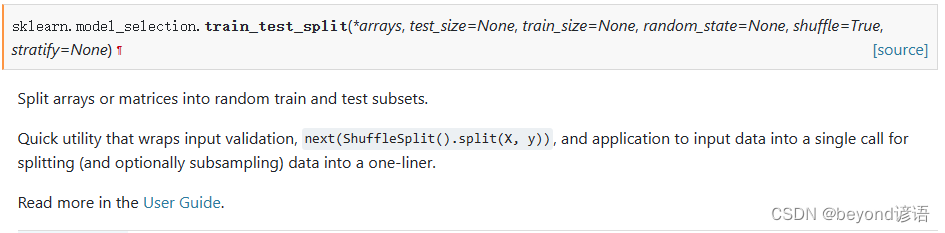
test_size:测试集数据所占比例
train_size:训练集数据所占比例
random_state:随机种子
shuffle:是否将数据进行打乱
因为我这里的数据集共48个,训练集0.75,测试集0.25,即训练集36个,测试集12个
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']X_train, X_test, y_train, y_test = train_test_split(X,Y,train_size=0.75,test_size=0.25,random_state=42,shuffle=True)print(X_train.shape) #(36,6)
print(y_train.shape) #(36,)
print(X_test.shape) #(12,6)
print(y_test.shape) #(12,)
④构建NuSVC模型
参数可以自己去尝试设置调整
nusvc = NuSVC(nu=0.5,kernel='rbf',gamma='auto',random_state=42)
⑤模型训练
就这么简单,一个fit函数就可以实现模型训练
nusvc.fit(X_train,y_train)
⑥模型评估
把测试集扔进去,得到预测的测试结果
y_pred = nusvc.predict(X_test)
看看预测结果和实际测试集结果是否一致,一致为1否则为0,取个平均值就是准确率
accuracy = np.mean(y_pred==y_test)
print(accuracy)
也可以通过score得分进行评估,计算的结果和思路都是一样的,都是看所有的数据集中模型猜对的概率,只不过这个score函数已经封装好了,当然传入的参数也不一样,需要导入accuracy_score才行,from sklearn.metrics import accuracy_score
score = nusvc.score(X_test,y_test)#得分
print(score)
⑦模型测试
拿到一条数据,使用训练好的模型进行评估
这里是六个自变量,我这里随机整个test = np.array([[16,18312.5,6614.5,2842.31,25.23,1147430.19]])
扔到模型里面得到预测结果,prediction = nusvc.predict(test)
看下预测结果是多少,是否和正确结果相同,print(prediction)
test = np.array([[16,18312.5,6614.5,2842.31,25.23,1147430.19]])
prediction = nusvc.predict(test)
print(prediction) #[2]
⑧保存模型
nusvc是模型名称,需要对应一致
后面的参数是保存模型的路径
joblib.dump(nusvc, './nusvc.model')#保存模型
⑨加载和使用模型
nusvc_yy = joblib.load('./nusvc.model')test = np.array([[11,99498,5369,9045.27,28.47,3827588.56]])#随便找的一条数据
prediction = nusvc_yy.predict(test)#带入数据,预测一下
print(prediction) #[4]
完整代码
模型训练和评估,不包含⑧⑨。
from sklearn.svm import NuSVC
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_splitfiber = pd.read_csv("./fiber.csv")
# 划分自变量和因变量
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']
#划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, Y, random_state=0)nusvc = NuSVC(nu=0.5,kernel='rbf',gamma='auto',random_state=42)
nusvc.fit(X_train,y_train)#模型拟合
y_pred = nusvc.predict(X_test)#模型预测结果
accuracy = np.mean(y_pred==y_test)#准确度
score = nusvc.score(X_test,y_test)#得分
print(accuracy)
print(score)test = np.array([[23,97215.5,22795.5,2613.09,29.72,1786141.62]])#随便找的一条数据
prediction = nusvc.predict(test)#带入数据,预测一下
print(prediction)
相关文章:
五、核支持向量机算法(NuSVC,Nu-Support Vector Classification)(有监督学习)
和支持向量分类(Nu-Support Vector Classification),与 SVC 类似,但使用一个参数来控制支持向量的数量,其实现基于libsvm 一、算法思路 本质都是SVM中的一种优化,原理都类似,详细算法思路可以参考博文:三…...
个人废品回收小程序制作步骤详解
在当今的环保时代,个人废品回收小程序的发展显得尤为重要。为了满足这一需求,本文将详细介绍如何制作一个个人废品回收小程序。 第一步,进入乔拓云网后台,点击【轻应用小程序】进入设计小程序页面。在这个页面,你可以看…...

Python爬虫自动切换爬虫ip的完美方案
在进行网络爬虫时,经常会遇到需要切换爬虫ip的情况,以绕过限制或保护自己的爬虫请求。今天,我将为你介绍Python爬虫中自动切换爬虫ip的终极方案,让你的爬虫更加高效稳定。 步骤一:准备爬虫ip池 首先,你需要…...
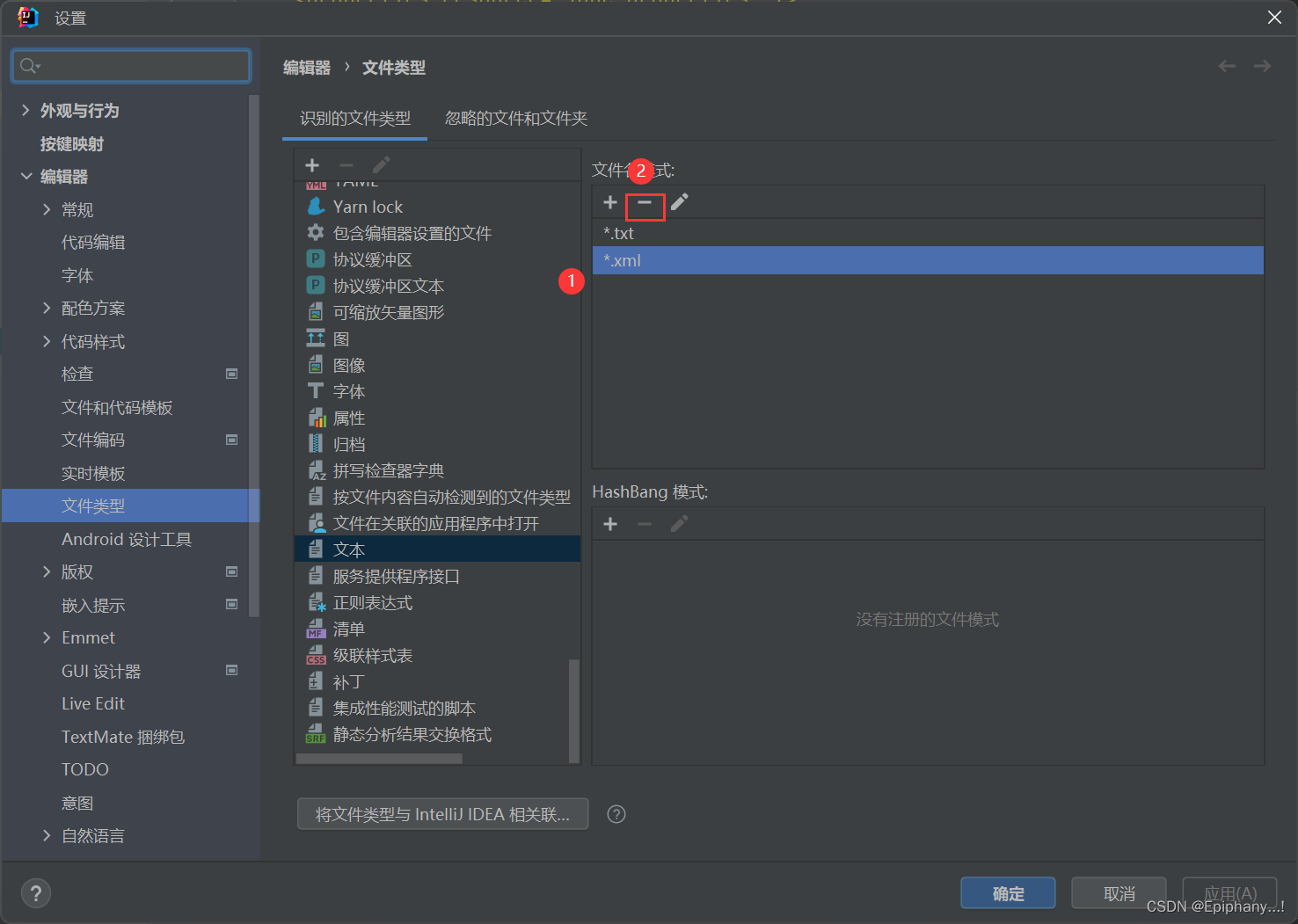
IDEA新建.xml文件显示为普通文本
情况如下: 1. 在XML文件中添加*.xml的文件名模式 2. 在文本中,选中*.xml进行删除...

linux的三剑客
1、grep命令 grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。它是Linux系统中一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。 shell脚本中也经常使用g…...

微信小程序部分知识点总结【2】
微信小程序的原理是什么 微信小程序的原理是基于一种轻量级的应用程序模型,它允许开发者在微信客户端内部创建和运行应用程序。微信小程序采用了类似网页的技术栈,主要由两部分组成:前端和后端。 前端部分使用HTML、CSS和JavaScript等标准的…...
基于springboot+vue的云南旅游网(前后端分离)
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战 主要内容:毕业设计(Javaweb项目|小程序等)、简历模板、学习资料、面试题库、技术咨询 文末联系获取 项目介绍…...

后缀表达式求值
后缀表达式,又称逆波兰式,指的是不包含括号,运算符放在两个运算对象的后面,所有的计算按运算符出现的顺序,严格从左向右进行。 运用后缀表达式进行计算的具体做法: 建立一个操作数栈S。然后从左到右读表达…...
基于springboot+vue的信息技术知识赛系统
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战 主要内容:毕业设计(Javaweb项目|小程序等)、简历模板、学习资料、面试题库、技术咨询 文末联系获取 项目介绍…...
基于YOLOv8模型的垃圾满溢检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型的垃圾满溢检测系统可用于日常生活中检测与定位车辆垃圾(garbage)、垃圾桶(garbage_bin)和垃圾满溢(overflow)目标,利用深度学习算法可实现图片、视频、摄像头等…...

面试算法14:字符串中的变位词
题目 输入字符串s1和s2,如何判断字符串s2中是否包含字符串s1的某个变位词?如果字符串s2中包含字符串s1的某个变位词,则字符串s1至少有一个变位词是字符串s2的子字符串。假设两个字符串中只包含英文小写字母。例如,字符串s1为&quo…...

中国社科院大学-美国杜兰大学金融管理硕士暨能源管理硕士项目2023年毕业典礼
中国社科院大学-美国杜兰大学金融管理硕士暨能源管理硕士项目2023年毕业典礼 2023年9月16日,中国社会科学院大学-美国杜兰大学金融管理硕士项目暨能源管理硕士项目2023年毕业典礼在我校望京校区成功举办。 张波副校长致辞 中国社会科学院大学副校长张波教授、杜兰大…...

蓝桥杯 题库 简单 每日十题 day10
01 最少砝码 最少砝码 问题描述 你有一架天平。现在你要设计一套砝码,使得利用这些砝码 可以出任意小于等于N的正整数重量。那么这套砝码最少需要包含多少个砝码? 注意砝码可以放在天平两边。 输入格式 输入包含一个正整数N。 输出格式 输出一个整数代表…...
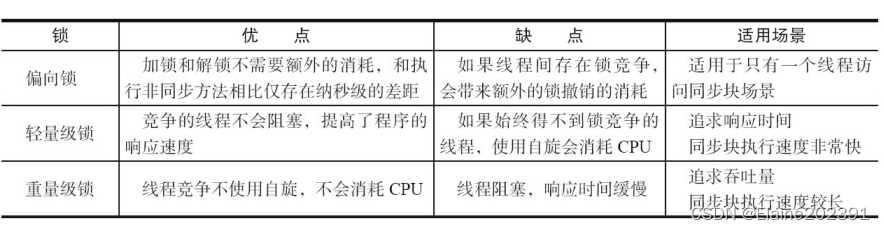
聊聊并发编程——多线程之synchronized
目录 一.多线程下数据不一致问题 二.锁和synchronized 2.1 并发编程三大特性 2.2引入锁概念 三.synchronized的锁实现原理 3.1 monitorenter和monitorexit 3.2synchronized 锁的升级 3.2.1偏向锁的获取和撤销 3.2.2轻量级锁的加锁和解锁 自适应自旋锁 轻量级锁的解锁…...

CompletableFuture-通用异步编程
演示Completable接口完全可以代替Future接口: CompletableFuture减少阻塞和轮询,可以传入回调对象,当异步任务完成或者发生异常时,自动 调用回调对象的回调方法。 package com.nanjing.gulimall.zhouyimo.test;import java.util…...
Vue3 封装 element-plus 图标选择器
一、实现效果 二、实现步骤 2.1. 全局注册 icon 组件 // main.ts import App from ./App.vue; import { createApp } from vue; import * as ElementPlusIconsVue from element-plus/icons-vueconst app createApp(App);// 全局挂载和注册 element-plus 的所有 icon app.con…...

超详细C语言实现——通讯录
目录 一、介绍 二、源代码 test.c: Contact.c: Contact.h: 代码运行结果: 三、开始实现 1.基本框架: 2.添加联系人: 3.显示联系人信息: 4.删除联系人信息: 5.查看指定联系人信息: 6.修改联系人…...

zabbix监控添加监控项及其监控Mysql、nginx
本届主要介绍添加监控项和修改中文乱码,监控mysql,nginx服务 一、zabbix监控添加监控项 1、配置agent服务器 在配置文件中添加: UserParameterlsq_userd,free -m | grep Mem | awk { print $3 } 服务器内存使用量 UserParameterdu,…...

Docker 部署 MongoDB 服务
拉取最新版本的 MongoDB 镜像: $ sudo docker pull mongo:latest在本地预先创建好 db 和 configdb 目录, 用于映射 MongoDB 容器内的 /data/db 和 /data/configdb 目录。 使用以下命令来运行 MongoDB 容器: $ sudo docker run -itd --name mongo --privilegedtru…...
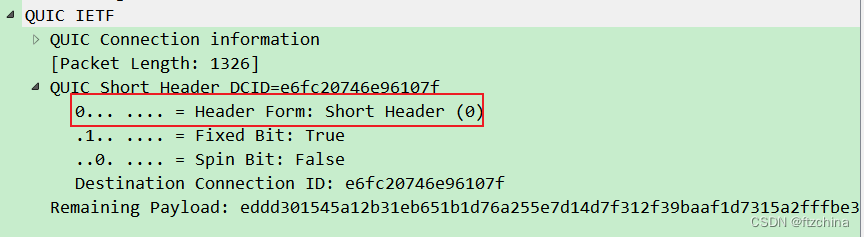
QUIC协议报文解析(三)
在前面的两篇文字里我们简单介绍了QUIC的发展历史,优点以及QUIC协议的连接原理。本篇文章将会以具体的QUIC报文为例,详细介绍QUIC报文的结构以及各个字段的含义。 早期QUIC版本众多,主要有谷歌家的gQUIC,以及IETF致力于将QUIC标准…...

HS2-HF_Patch:一键解决《Honey Select 2》三大核心问题的终极增强补丁
HS2-HF_Patch:一键解决《Honey Select 2》三大核心问题的终极增强补丁 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 厌倦了《Honey Select 2》原版…...

你的微信聊天记录,真的安全吗?揭秘永久保存数字记忆的开源方案
你的微信聊天记录,真的安全吗?揭秘永久保存数字记忆的开源方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHu…...

从LCD屏幕到车载摄像头:聊聊LVDS接口在你身边那些‘看不见’的应用
从LCD屏幕到车载摄像头:聊聊LVDS接口在你身边那些‘看不见’的应用 走在科技产品琳琅满目的商场里,你可能不会注意到,那些让你眼前一亮的4K显示屏、流畅的触控体验,甚至自动驾驶汽车里的"眼睛",背后都藏着一…...

产品经理必懂的博弈论:如何用帕累托最优和纳什均衡设计用户激励与平台规则
产品经理必懂的博弈论:如何用帕累托最优和纳什均衡设计用户激励与平台规则 在互联网产品的世界里,每天都有无数场看不见的博弈正在上演——司机与乘客的匹配、商家与消费者的互动、创作者与平台的共生。这些看似复杂的商业行为背后,往往遵循着…...

网络排障利器netstat:从TCP状态机到实战故障排查
1. 网络排障的“听诊器”:为什么是netstat?在服务器运维、后端开发或者日常处理网络问题的过程中,我们经常会遇到一些让人头疼的场景:服务端口明明启动了,客户端却死活连不上;服务器负载莫名飙升࿰…...

【免费下载】 MATLAB 3D 极坐标绘图示例:天线三维方向图【matlab下载】
MATLAB 3D 极坐标绘图示例:天线三维方向图 项目介绍 在科学计算和工程设计领域,MATLAB一直是数据可视化和仿真的强大工具。然而,当涉及到在三维空间中使用极坐标系统进行绘图时,MATLAB的标准绘图函数如surf和mesh就显得力不从心。…...

STM32体重秤电子秤称重超重报警Proteus仿真资源包
STM32体重秤电子秤称重超重报警Proteus仿真资源包 【下载地址】STM32体重秤电子秤称重超重报警Proteus仿真资源包 本资源包提供了基于STM32单片机的体重秤电子秤称重超重报警系统的完整解决方案。资源内容包括源代码、Proteus仿真文件以及全套相关资料,帮助用户快速…...

使用 Taotoken 后我的月度 API 成本下降了百分之三十
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 Taotoken 后我的月度 API 成本下降了百分之三十 作为一名独立开发者,我的项目需要调用多种大语言模型来完成不同的…...

【亲测免费】 使用S-Function函数实现离散PID控制器
使用S-Function函数实现离散PID控制器 【下载地址】使用S-Function函数实现离散PID控制器 本资源文件提供了使用S-Function函数实现离散PID控制器,并建立Simulink仿真模型的详细教程和代码。通过本资源,您将学习如何在Simulink中使用S-Function模块来实现…...
Linux屏幕取词翻译终极指南:CuteTranslation让你的跨语言阅读变得简单高效
Linux屏幕取词翻译终极指南:CuteTranslation让你的跨语言阅读变得简单高效 【免费下载链接】CuteTranslation Linux屏幕取词翻译软件 项目地址: https://gitcode.com/gh_mirrors/cu/CuteTranslation 你是否经常在Linux系统上阅读外文资料时遇到语言障碍&…...