计算机竞赛 深度学习乳腺癌分类
文章目录
- 1 前言
- 2 前言
- 3 数据集
- 3.1 良性样本
- 3.2 病变样本
- 4 开发环境
- 5 代码实现
- 5.1 实现流程
- 5.2 部分代码实现
- 5.2.1 导入库
- 5.2.2 图像加载
- 5.2.3 标记
- 5.2.4 分组
- 5.2.5 构建模型训练
- 6 分析指标
- 6.1 精度,召回率和F1度量
- 6.2 混淆矩阵
- 7 结果和结论
- 8 最后
1 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 深度学习乳腺癌分类
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
2 前言
乳腺癌是全球第二常见的女性癌症。2012年,它占所有新癌症病例的12%,占所有女性癌症病例的25%。
当乳腺细胞生长失控时,乳腺癌就开始了。这些细胞通常形成一个肿瘤,通常可以在x光片上直接看到或感觉到有一个肿块。如果癌细胞能生长到周围组织或扩散到身体的其他地方,那么这个肿瘤就是恶性的。
以下是报告:
- 大约八分之一的美国女性(约12%)将在其一生中患上浸润性乳腺癌。
- 2019年,美国预计将有268,600例新的侵袭性乳腺癌病例,以及62,930例新的非侵袭性乳腺癌。
- 大约85%的乳腺癌发生在没有乳腺癌家族史的女性身上。这些发生是由于基因突变,而不是遗传突变
- 如果一名女性的一级亲属(母亲、姐妹、女儿)被诊断出患有乳腺癌,那么她患乳腺癌的风险几乎会增加一倍。在患乳腺癌的女性中,只有不到15%的人的家人被诊断出患有乳腺癌。
3 数据集
该数据集为学长实验室数据集。
搜先这是图像二分类问题。我把数据拆分如图所示
dataset train
benign
b1.jpg
b2.jpg
//
malignant
m1.jpg
m2.jpg
// validation
benign
b1.jpg
b2.jpg
//
malignant
m1.jpg
m2.jpg
//…
训练文件夹在每个类别中有1000个图像,而验证文件夹在每个类别中有250个图像。
3.1 良性样本


3.2 病变样本


4 开发环境
- scikit-learn
- keras
- numpy
- pandas
- matplotlib
- tensorflow
5 代码实现
5.1 实现流程
完整的图像分类流程可以形式化如下:
我们的输入是一个由N个图像组成的训练数据集,每个图像都有相应的标签。
然后,我们使用这个训练集来训练分类器,来学习每个类。
最后,我们通过让分类器预测一组从未见过的新图像的标签来评估分类器的质量。然后我们将这些图像的真实标签与分类器预测的标签进行比较。
5.2 部分代码实现
5.2.1 导入库
import json
import math
import os
import cv2
from PIL import Image
import numpy as np
from keras import layers
from keras.applications import DenseNet201
from keras.callbacks import Callback, ModelCheckpoint, ReduceLROnPlateau, TensorBoard
from keras.preprocessing.image import ImageDataGenerator
from keras.utils.np_utils import to_categorical
from keras.models import Sequential
from keras.optimizers import Adam
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import cohen_kappa_score, accuracy_score
import scipy
from tqdm import tqdm
import tensorflow as tf
from keras import backend as K
import gc
from functools import partial
from sklearn import metrics
from collections import Counter
import json
import itertools
5.2.2 图像加载
接下来,我将图像加载到相应的文件夹中。
def Dataset_loader(DIR, RESIZE, sigmaX=10):IMG = []read = lambda imname: np.asarray(Image.open(imname).convert("RGB"))for IMAGE_NAME in tqdm(os.listdir(DIR)):PATH = os.path.join(DIR,IMAGE_NAME)_, ftype = os.path.splitext(PATH)if ftype == ".png":img = read(PATH)img = cv2.resize(img, (RESIZE,RESIZE))IMG.append(np.array(img))return IMGbenign_train = np.array(Dataset_loader('data/train/benign',224))
malign_train = np.array(Dataset_loader('data/train/malignant',224))
benign_test = np.array(Dataset_loader('data/validation/benign',224))
malign_test = np.array(Dataset_loader('data/validation/malignant',224))
5.2.3 标记
之后,我创建了一个全0的numpy数组,用于标记良性图像,以及全1的numpy数组,用于标记恶性图像。我还重新整理了数据集,并将标签转换为分类格式。
benign_train_label = np.zeros(len(benign_train))
malign_train_label = np.ones(len(malign_train))
benign_test_label = np.zeros(len(benign_test))
malign_test_label = np.ones(len(malign_test))X_train = np.concatenate((benign_train, malign_train), axis = 0)
Y_train = np.concatenate((benign_train_label, malign_train_label), axis = 0)
X_test = np.concatenate((benign_test, malign_test), axis = 0)
Y_test = np.concatenate((benign_test_label, malign_test_label), axis = 0)s = np.arange(X_train.shape[0])
np.random.shuffle(s)
X_train = X_train[s]
Y_train = Y_train[s]s = np.arange(X_test.shape[0])
np.random.shuffle(s)
X_test = X_test[s]
Y_test = Y_test[s]Y_train = to_categorical(Y_train, num_classes= 2)
Y_test = to_categorical(Y_test, num_classes= 2)
5.2.4 分组
然后我将数据集分成两组,分别具有80%和20%图像的训练集和测试集。让我们看一些样本良性和恶性图像
x_train, x_val, y_train, y_val = train_test_split(X_train, Y_train, test_size=0.2, random_state=11
)w=60
h=40
fig=plt.figure(figsize=(15, 15))
columns = 4
rows = 3for i in range(1, columns*rows +1):ax = fig.add_subplot(rows, columns, i)if np.argmax(Y_train[i]) == 0:ax.title.set_text('Benign')else:ax.title.set_text('Malignant')plt.imshow(x_train[i], interpolation='nearest')
plt.show()

5.2.5 构建模型训练
我使用的batch值为16。batch是深度学习中最重要的超参数之一。我更喜欢使用更大的batch来训练我的模型,因为它允许从gpu的并行性中提高计算速度。但是,众所周知,batch太大会导致泛化效果不好。在一个极端下,使用一个等于整个数据集的batch将保证收敛到目标函数的全局最优。但是这是以收敛到最优值较慢为代价的。另一方面,使用更小的batch已被证明能够更快的收敛到好的结果。这可以直观地解释为,较小的batch允许模型在必须查看所有数据之前就开始学习。使用较小的batch的缺点是不能保证模型收敛到全局最优。因此,通常建议从小batch开始,通过训练慢慢增加batch大小来加快收敛速度。
我还做了一些数据扩充。数据扩充的实践是增加训练集规模的一种有效方式。训练实例的扩充使网络在训练过程中可以看到更加多样化,仍然具有代表性的数据点。
然后,我创建了一个数据生成器,自动从文件夹中获取数据。Keras为此提供了方便的python生成器函数。
BATCH_SIZE = 16train_generator = ImageDataGenerator(zoom_range=2, # 设置范围为随机缩放rotation_range = 90,horizontal_flip=True, # 随机翻转图片vertical_flip=True, # 随机翻转图片)
下一步是构建模型。这可以通过以下3个步骤来描述:
-
我使用DenseNet201作为训练前的权重,它已经在Imagenet比赛中训练过了。设置学习率为0.0001。
-
在此基础上,我使用了globalaveragepooling层和50%的dropout来减少过拟合。
-
我使用batch标准化和一个以softmax为激活函数的含有2个神经元的全连接层,用于2个输出类的良恶性。
-
我使用Adam作为优化器,使用二元交叉熵作为损失函数。
def build_model(backbone, lr=1e-4):model = Sequential()model.add(backbone)model.add(layers.GlobalAveragePooling2D())model.add(layers.Dropout(0.5))model.add(layers.BatchNormalization())model.add(layers.Dense(2, activation='softmax'))model.compile(loss='binary_crossentropy',optimizer=Adam(lr=lr),metrics=['accuracy'])return modelresnet = DenseNet201(weights='imagenet',include_top=False,input_shape=(224,224,3) )model = build_model(resnet ,lr = 1e-4) model.summary()
让我们看看每个层中的输出形状和参数。

在训练模型之前,定义一个或多个回调函数很有用。非常方便的是:ModelCheckpoint和ReduceLROnPlateau。
-
ModelCheckpoint:当训练通常需要多次迭代并且需要大量的时间来达到一个好的结果时,在这种情况下,ModelCheckpoint保存训练过程中的最佳模型。
-
ReduceLROnPlateau:当度量停止改进时,降低学习率。一旦学习停滞不前,模型通常会从将学习率降低2-10倍。这个回调函数会进行监视,如果在’patience’(耐心)次数下,模型没有任何优化的话,学习率就会降低。

该模型我训练了60个epoch。
learn_control = ReduceLROnPlateau(monitor='val_acc', patience=5,verbose=1,factor=0.2, min_lr=1e-7)filepath="weights.best.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=1, save_best_only=True, mode='max')history = model.fit_generator(train_generator.flow(x_train, y_train, batch_size=BATCH_SIZE),steps_per_epoch=x_train.shape[0] / BATCH_SIZE,epochs=20,validation_data=(x_val, y_val),callbacks=[learn_control, checkpoint]
)
6 分析指标
评价模型性能最常用的指标是精度。然而,当您的数据集中只有2%属于一个类(恶性),98%属于其他类(良性)时,错误分类的分数就没有意义了。你可以有98%的准确率,但仍然没有发现恶性病例,即预测的时候全部打上良性的标签,这是一个不好的分类器。
history_df = pd.DataFrame(history.history)
history_df[['loss', 'val_loss']].plot()history_df = pd.DataFrame(history.history)
history_df[['acc', 'val_acc']].plot()

6.1 精度,召回率和F1度量
为了更好地理解错误分类,我们经常使用以下度量来更好地理解真正例(TP)、真负例(TN)、假正例(FP)和假负例(FN)。
精度反映了被分类器判定的正例中真正的正例样本的比重。
召回率反映了所有真正为正例的样本中被分类器判定出来为正例的比例。
F1度量是准确率和召回率的调和平均值。
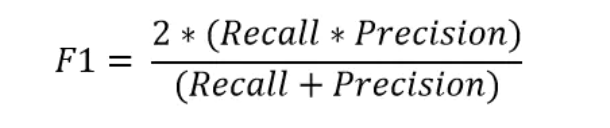
6.2 混淆矩阵
混淆矩阵是分析误分类的一个重要指标。矩阵的每一行表示预测类中的实例,而每一列表示实际类中的实例。对角线表示已正确分类的类。这很有帮助,因为我们不仅知道哪些类被错误分类,还知道它们为什么被错误分类。
from sklearn.metrics import classification_report
classification_report( np.argmax(Y_test, axis=1), np.argmax(Y_pred_tta, axis=1))from sklearn.metrics import confusion_matrixdef plot_confusion_matrix(cm, classes,normalize=False,title='Confusion matrix',cmap=plt.cm.Blues):if normalize:cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]print("Normalized confusion matrix")else:print('Confusion matrix, without normalization')print(cm)plt.imshow(cm, interpolation='nearest', cmap=cmap)plt.title(title)plt.colorbar()tick_marks = np.arange(len(classes))plt.xticks(tick_marks, classes, rotation=55)plt.yticks(tick_marks, classes)fmt = '.2f' if normalize else 'd'thresh = cm.max() / 2.for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):plt.text(j, i, format(cm[i, j], fmt),horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")plt.ylabel('True label')plt.xlabel('Predicted label')plt.tight_layout()cm = confusion_matrix(np.argmax(Y_test, axis=1), np.argmax(Y_pred, axis=1))cm_plot_label =['benign', 'malignant']
plot_confusion_matrix(cm, cm_plot_label, title ='Confusion Metrix for Skin Cancer')

7 结果和结论

在这个博客中,学长我演示了如何使用卷积神经网络和迁移学习从一组显微图像中对良性和恶性乳腺癌进行分类,希望对大家有所帮助。
8 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
计算机竞赛 深度学习乳腺癌分类
文章目录 1 前言2 前言3 数据集3.1 良性样本3.2 病变样本 4 开发环境5 代码实现5.1 实现流程5.2 部分代码实现5.2.1 导入库5.2.2 图像加载5.2.3 标记5.2.4 分组5.2.5 构建模型训练 6 分析指标6.1 精度,召回率和F1度量6.2 混淆矩阵 7 结果和结论8 最后 1 前言 &…...

docker-compose搭建的mysql,如何定时备份数据
一、前言 使用docker-compose搭建的mysql中自带了mysqldump,所以在服务器上如何使用容器中的mysqldump命令是实现备份的原理,下面是主要实现的命令 docker exec -it mysql mysqldump -u root -p$mysql_password $database_name > $backup_file二、备…...

webpack:关于处理html文件的插件html-webpack-plugin、add-asset-html-webpack-plugin
简介 add-asset-html-webpack-plugin 将 JavaScript或CSS文件添加到由html-webpack-plugin插件生成的HTML中去。 html-webpack-plugin 默认配置会在出口目录中(通过output.path选项配置)生成一个index.html文件; 生成的index.html文件将会…...

如何两个不同的脚本文件之间传递参数
两个不同的Shell脚本之间如何访问传递的参数取决于它们是如何调用的。如果一个Shell脚本1调用另一个Shell脚本2并且想要将参数传递给被调用的脚本2,可以使用以下方法: 方法1:通过位置参数传递参数 这是一种常见的方法,其中一个脚…...

一篇文章彻底搞懂熵、信息熵、KL散度、交叉熵、Softmax和交叉熵损失函数
文章目录 一、熵和信息熵1.1 概念1.2 信息熵公式 二、KL散度和交叉熵2.1 KL散度(相对熵)2.2 交叉熵 三、Softmax和交叉熵损失函数3.1 Softmax3.2 交叉熵损失函数 一、熵和信息熵 1.1 概念 1. 熵是一个物理学概念,它表示一个系统的不确定性程度,或者说是…...
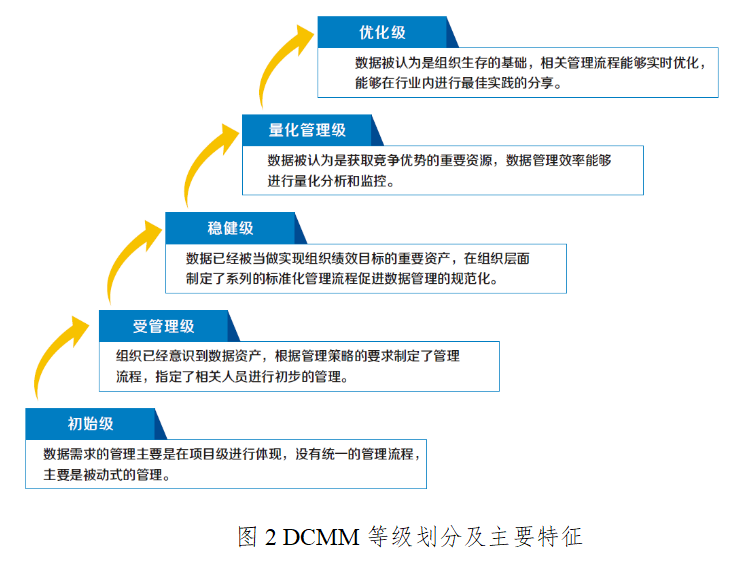
[架构之路-223]:数据管理能力成熟度评估模型DCMM简介
目录 一、背景 二、评估依据 三、评估内容 四、主要适用对象 五、能力等级 六、不同层次的文件: 一、背景 信息技术与经济社会的交汇融合引发了数据爆发式增长。数据蕴含着重要的价值,已成为国家基础性战略资源,正日益对全球生产、流通…...
)
十大排序算法的实现(C/C++)
以下是十大经典排序算法的简单 C 实现: 冒泡排序(Bubble Sort): 思想:重复地遍历要排序的列表,比较相邻的两个元素,如果它们的顺序错误就交换它们。时间复杂度:最坏情况和平均情况…...
HTML+CSS综合案例一新闻详情
<!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>新闻详情</title><style>h1{text-align…...

【Spring Boot】实战:实现Session共享
🌿欢迎来到@衍生星球的CSDN博文🌿 🍁本文主要学习实现Session共享 🍁 🌱我是衍生星球,一个从事集成开发的打工人🌱 ⭐️喜欢的朋友可以关注一下🫰🫰🫰,下次更新不迷路⭐️💠作为一名热衷于分享知识的程序员,我乐于在CSDN上与广大开发者交流学习。 💠我…...
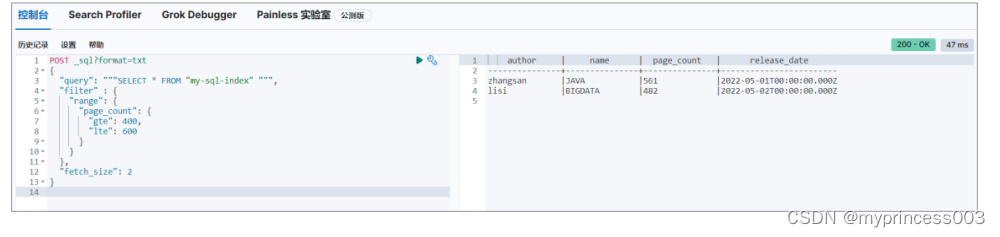
3、Elasticsearch功能使用
第4章 功能使用 4.1 Java API 操作 随着 Elasticsearch 8.x 新版本的到来,Type 的概念被废除,为了适应这种数据结构的改 变,Elasticsearch 官方从 7.15 版本开始建议使用新的 Elasticsearch Java Client。 4.1.1 增加依赖关系 <propertie…...
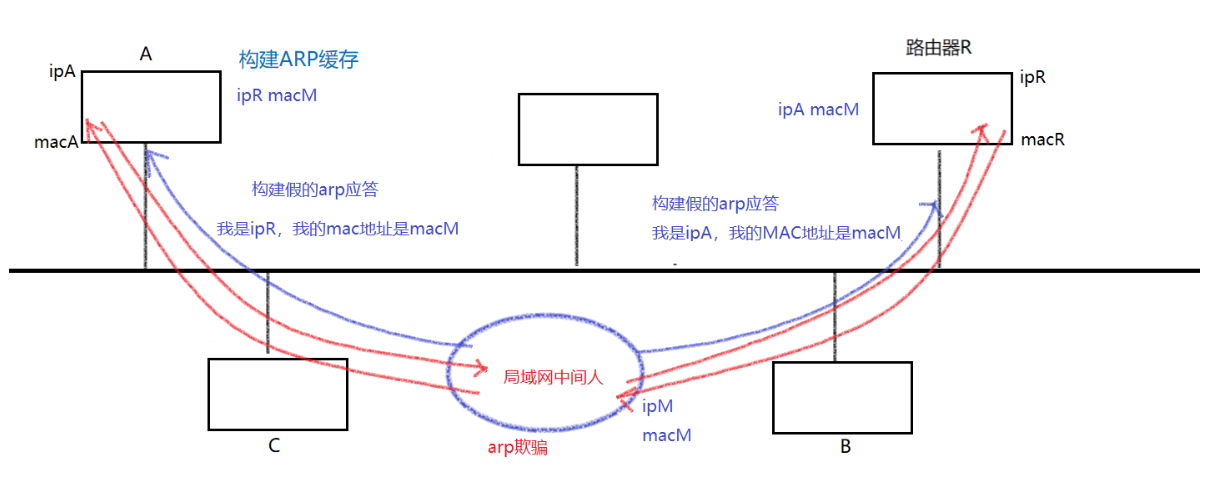
数据链路层协议
文章目录 数据链路层协议0. 数据链路层解决的问题1. 以太网协议(1) 认识以太网(2) 以太网帧格式<1> 两个核心问题 (3) 认识MAC地址(4) 局域网通信原理(5) MTU<1> 认识MTU<2> MTU对IP协议的影响<3> MTU对UDP协议的影响<4> MTU对TCP协议的影响<…...
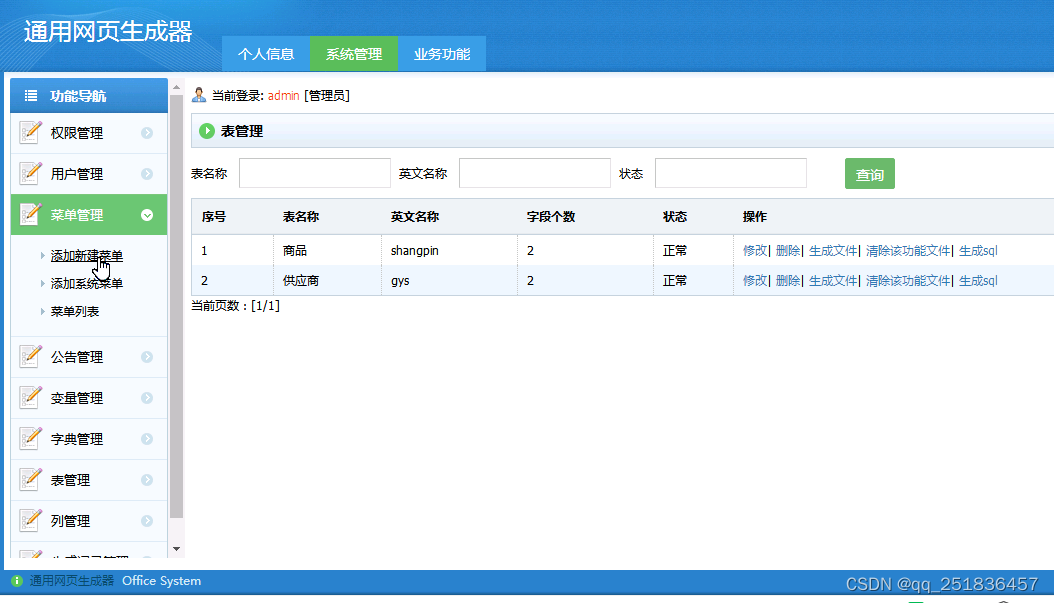
java版网页代码生成器系统myeclipse定制开发mysql数据库网页模式java编程jdbc生成无框架java web网页
一、源码特点 java版网页代码生成器系统是一套完善的web设计系统,对理解JSP java编程开发语言有帮助,系统具有完整的源代码,系统主要采用B/S模式开发。开发环境为 TOMCAT7.0,Myeclipse8.5开发,数据库为Mysql5.0,使…...
ElementUI实现登录注册啊,axios全局配置,CORS跨域
一,项目搭建 认识ElementUI ElementUI是一个基于Vue.js 2.0的桌面端组件库,它提供了一套丰富的UI组件,包括表格、表单、弹框、按钮、菜单等常用组件,具备易用、美观、高效、灵活等优势,能够极大的提高Web应用的开发效…...
面经分享 | 某康安全开发工程师
本文由掌控安全学院 - sbhglqy 投稿 一、反射型XSS跟DOM型XSS的最大区别 DOM型xss和别的xss最大的区别就是它不经过服务器,仅仅是通过网页本身的JavaScript进行渲染触发的。 二、Oracle数据库了解多吗 平常用的多的是MySQL数据库,像Oracle数据库也有…...

leetcode - 389. Find the Difference
Description You are given two strings s and t. String t is generated by random shuffling string s and then add one more letter at a random position. Return the letter that was added to t. Example 1: Input: s “abcd”, t “abcde” Output: “e” Expla…...
asp.net企业生产管理系统VS开发sqlserver数据库web结构c#编程Microsoft Visual Studio
一、源码特点 asp.net 企业生产管理系统 是一套完善的web设计管理系统,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为vs2010,数据库为sqlserver2008,使用c#语 言开发 二、功能介绍 (1)用户管理&…...

vue中或者react中的excel导入和导出
excel导入和导出是后台管理系统常见的功能。 当我们把信息化系统给用户使用时,用户经常需要把以前在excel里录入的数据导入的信息化系统里,这样为用户提供了很大的方便。 在用户使用信息化系统时,也需要把网页表格里的数据导出到excel里&…...

如何在Ubuntu的根目录下创建删除目录
首先进入根目录 cd /创建目录 sudo mkdir xxx然后可以用ls命令查看是否创建成功 我们创建了一个666的目录,接下来我们应该怎么删除呢? 删除 如果我们用普通删除的话,例如 rm 666 你会发现根本删除不掉;这时我们还是得用超级权…...
lv5 嵌入式开发-6 线程的取消和互斥
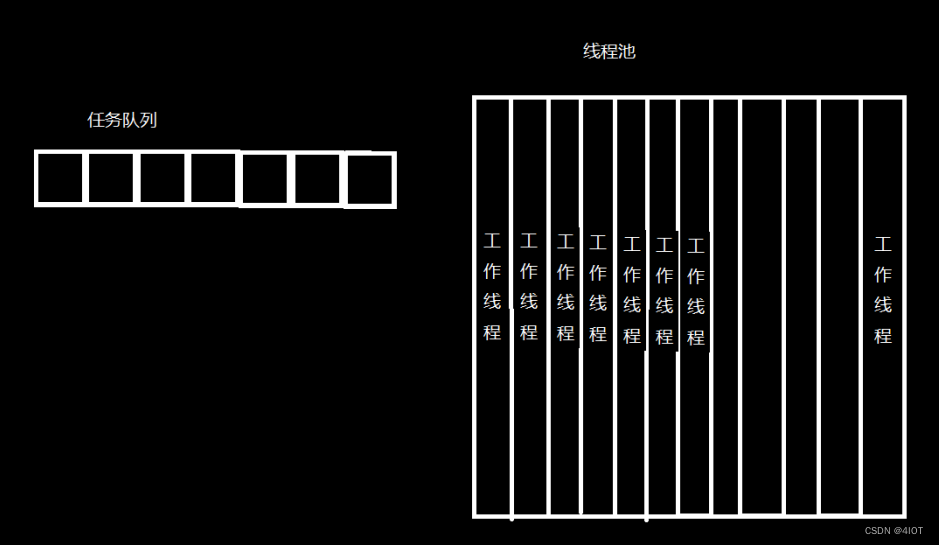
目录 1 线程通信 – 互斥 2 互斥锁初始化 – pthread_mutex_init 3 互斥锁销毁 pthread_mutex_destroy 4 申请锁 – pthread_mutex_lock 5 释放锁 – pthread_mutex_unlock 6 读写锁 7 死锁的避免 8 条件变量(信号量) 9 线程池概念和实现 9.1 …...

el-table实现穿梭功能
第一种 <template><el-row :gutter"20"><el-col :span"10"><!-- 搜索 --><div class"search-bg"><YcSearchInput title"手机号" v-model"search.phone" /><div class"search-s…...

Linux应用回滚流程排查方法
Linux应用回滚流程排查方法本文面向具备一定 Linux 基础的技术人员,围绕应用回滚流程展开,重点讨论版本切换、配置恢复和数据兼容。在中级运维和系统管理工作中,这类主题常常与配置变更、资源状态、权限边界、自动化任务和业务影响交织在一起…...

告别DETR训练慢!手把手教你用Deformable Attention加速目标检测模型收敛
突破DETR训练瓶颈:Deformable Attention加速目标检测实战指南 当你在深夜盯着屏幕,看着DETR模型训练到第50个epoch时验证集指标仍在波动,是否曾怀疑自己的显卡在空转?Transformer架构在目标检测领域的革命性突破有目共睹ÿ…...

B站视频转文字终极指南:5分钟掌握高效知识管理神器
B站视频转文字终极指南:5分钟掌握高效知识管理神器 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 你是否曾为了一段精彩的B站课程内容࿰…...

初创团队如何利用 Taotoken 模型广场快速进行 AI 技术选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何利用 Taotoken 模型广场快速进行 AI 技术选型 对于资源有限的初创团队而言,在产品原型阶段快速验证想法是…...
实战:从理论到代码的寻优之旅)
【智能算法】淘金优化算法(GRO)实战:从理论到代码的寻优之旅
1. 淘金优化算法(GRO)初探:从挖矿到代码的奇妙映射 第一次听说淘金优化算法时,我脑海中立刻浮现出19世纪美国西部的淘金热场景。有趣的是,这个算法的发明者K Zolf团队正是从这段历史中获得灵感。想象一下,…...

基于红外传感器与CircuitPython的互动声光糖果碗制作指南
1. 项目概述:一个会“尖叫”的互动糖果碗又到了捣鼓点有趣玩意儿的时候了。作为一个喜欢在万圣节搞点小惊喜的创客,我总觉得光是发糖有点平淡。能不能让糖果碗自己“活”过来,在孩子们伸手时,用灯光和声音制造一点既有趣又不会太过…...
Trae日志占用、Trae logs删除、Trae缓存清理、Trae占用C盘、Trae AppData 清理)
Trae日志占用很大解决方法(Windows)Trae日志占用、Trae logs删除、Trae缓存清理、Trae占用C盘、Trae AppData 清理
Trae日志占用很大解决方法(Windows) 关键词:Trae日志占用、Trae logs删除、Trae缓存清理、Trae占用C盘、Trae AppData 清理最近清理电脑磁盘时,发现 C 盘莫名其妙少了十几个 G。作为长期写代码的人,我第一反应就是&…...

Linux Ext 调度器核心原理:BPF 驱动的自定义调度革命
简介 Linux 内核调度器自诞生以来,始终以通用公平调度(CFS)与硬实时调度(SCHED_DEADLINE/SCHED_FIFO)为核心,支撑服务器、桌面、嵌入式等全场景负载。但传统调度框架存在硬耦合、难扩展、定制成本极高的痛…...
)
NotebookLM化学辅助实战手册(附ACS期刊PDF解析模板+分子式自动标注插件)
更多请点击: https://kaifayun.com 第一章:NotebookLM化学研究辅助概述 NotebookLM 是 Google 推出的基于人工智能的文档理解与知识协作工具,专为研究者设计,支持对 PDF、TXT 等格式的科学文献进行语义索引、跨文档推理与可追溯问…...

FreeRTOS互斥信号量实战:用STM32CubeIDE解决多任务访问共享串口的优先级翻转问题
FreeRTOS互斥信号量实战:用STM32CubeIDE解决多任务访问共享串口的优先级翻转问题 在嵌入式系统开发中,多任务并发访问共享资源是一个常见且棘手的问题。想象一下这样的场景:你的STM32设备上有两个任务需要向同一个串口发送数据——一个高优先…...