MySQL高级语句(第二部分)
- MySQL高级语句(第二部分)
- 一、视图表 create view
- 1、视图表概述
- 2、视图表能否修改?(面试题)
- 3、基本语法
- 3.1 创建
- 3.2 查看
- 3.3 删除
- 4、通过视图表求无交集值
- 二、case语句
- 三、空值(null) 和 无值(’ ') 的区别
- 四、正则表达式
- 五、存储过程
- 1、简介
- 2、存储过程的优点
- 3、创建存储过程的步骤
- 4、存储过程相关命令
- 4.1 创建存储过程
- 4.2 调用存储过程
- 4.3 查看存储过程
- 4.4 删除存储过程
- 5、存储过程的参数
- 5.1 in
- 5.2 out
- 5.3 inout
- 6、存储过程的控制语句
- 6.1 条件语句if-then-else...end if
- 6.2 循环语句while .... end while
MySQL高级语句(第二部分)
一、视图表 create view
1、视图表概述
视图,可以被当作是虚拟表或存储查询。
视图跟表格的不同是,表格中有实际储存数据记录,而视图是建立在表格之上的一个架构,它本身并不实际储存数据记录。
临时表在用户退出或同数据库的连接断开后就自动消失了,而视图不会消失。
视图不含有数据,只存储它的定义,它的用途一般可以简化复杂的查询。
比如你要对几个表进行连接查询,而且还要进行统计排序等操作,写sql语句会很麻烦的,用视图将几个表联结起来,然后对这个视图进行查询操作,就和对一个表查询一样,很方便。
2、视图表能否修改?(面试题)
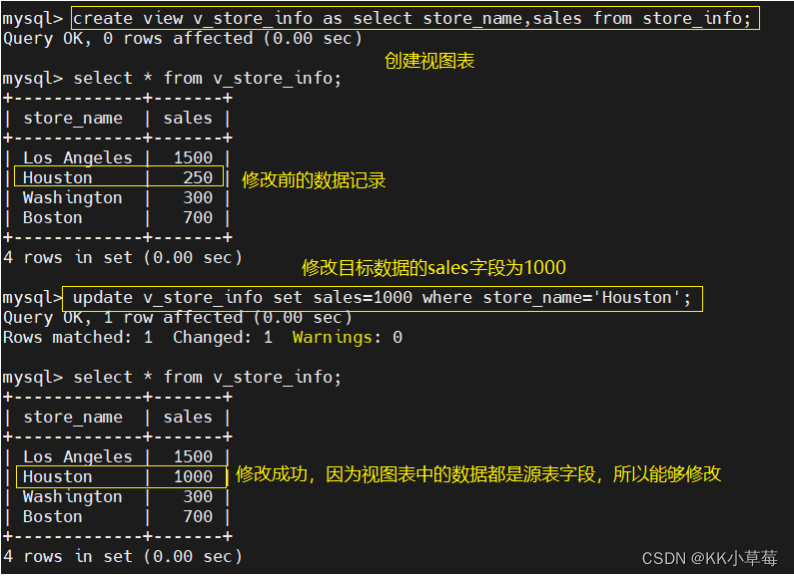
视图表保存的是select语句的定义,视图表的表数据能否修改,视情况而定font>。
如果 select 语句查询的字段是没有被处理过的源表字段,则可以通过视图表修改源表数据;
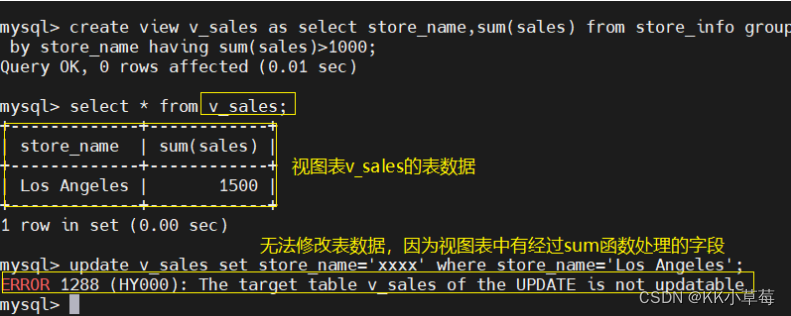
如果select 语句查询的字段是被 group by语句或 函数 处理过的字段,则不可以直接修改视图表的数据。
create view v_store_info as select store_name,sales from store_info;
select * from v_store_info;
update v_store_info set sales=1000 where store_name='Houston';
 在这里插入图片描述
在这里插入图片描述
create view v_sales as select store_name,sum(sales) from store_info group by store_name having sum(sales)>1000;
select * from v_sales;
update v_sales set store_name='xxxx' where store_name='Los Angeles';
3、基本语法
3.1 创建
语法:create view "视图表名" as "select 语句";
举例
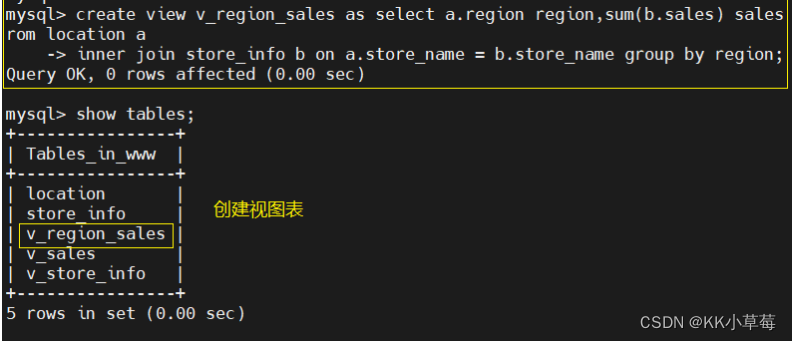
create view v_region_sales as select a.region region,sum(b.sales) sales from location a
inner join store_info b on a.store_name = b.store_name group by region;
#创建视图表
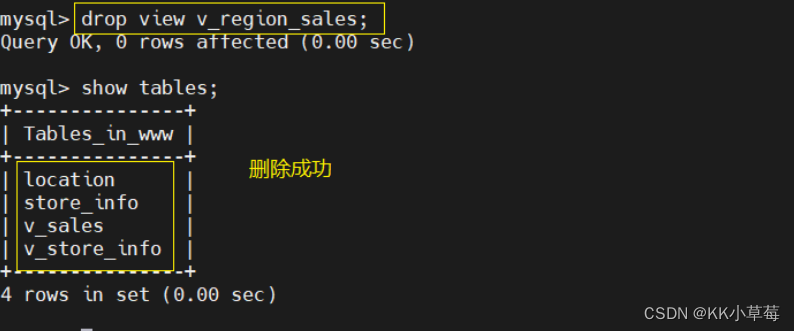
show tables;
3.2 查看
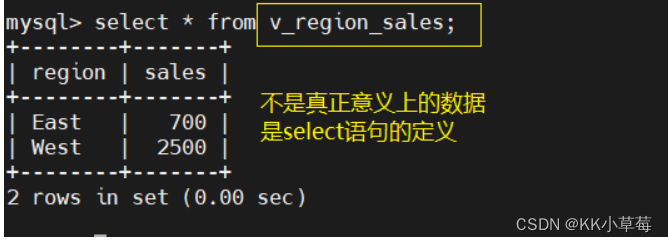
语法:select * from 视图表名;
select * from v_region_sales;
3.3 删除
语法:drop view 视图表名;
drop view v_region_sales;
4、通过视图表求无交集值
create view 视图表名 as select distinct 字段 from 左表 union all select distinct 字段 from 右表;select 字段 from 视图表名 group by 字段 having count(字段)=1;
#先建立视图表
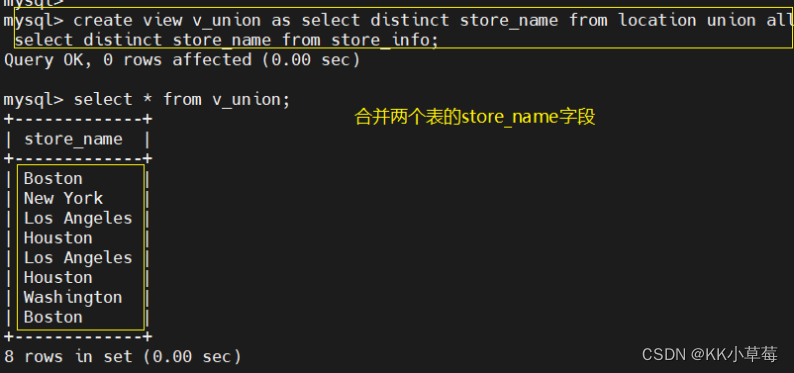
create view v_union as select distinct store_name from location union all select distinct store_name from store_info;
#合并两个表的store_name字段
select * from v_union;
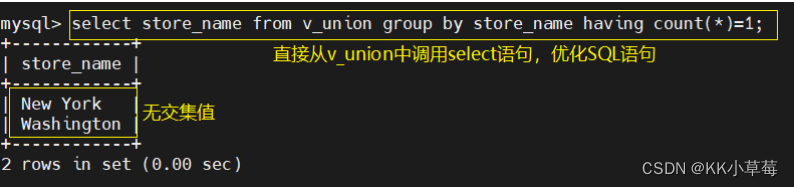
#再通过视图表求无交集
select store_name from v_union group by store_name having count(*)=1;
#直接从v_union中调用select语句,优化SQL语句
二、case语句
在MySQL中,CASE语句用于根据给定条件对数据进行条件判断和分支选择。
它可以在SELECT、UPDATE、DELETE语句中使用,也可以用于表达式中。
语法:
select case ("字段名")when "条件1" then "结果1"when "条件2" then "结果2"...[else "结果n"]end
from "表名";# "条件" 可以是一个数值或是公式。 else 子句则并不是必须的。
#举个例子
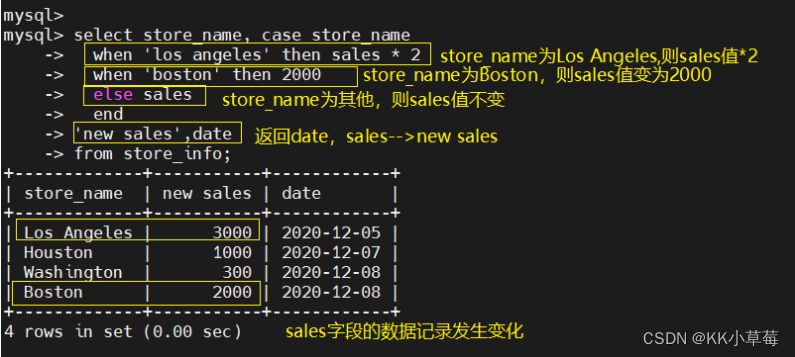
select store_name, case store_name when 'los angeles' then sales * 2 when 'boston' then 2000else sales end
'new sales',date
from store_info;#将'sales的值作为new sales的值返回
三、空值(null) 和 无值(’ ') 的区别
(1)无值的长度为 0,不占用空间的;而 null 值的长度是 null,是占用空间的;
(2)is null 或者 is not null,是用来判断字段是不是为 null 或者不是 null,不能查出是不是无值的;
(3)无值的判断使用=’ ‘或者<>’ '来处理,<> 和 !=代表不等于;
(4)在通过 count( )指定字段统计有多少行数时,如果遇到 NULL 值会自动忽略掉,遇到无值会加入到记录中进行计算。
create table city (id int,name varchar(20));
insert into city values (1,'beijing'),(2,'nanjing'),(3,'tianjing');
insert into city values (4,'');
insert into city values (5,'wuhan');
insert into city (id) values (6);
insert into city values (7,'shanghai');
insert into city (id) values (8);
insert into city values (9,'jiuquan');
select * from city;
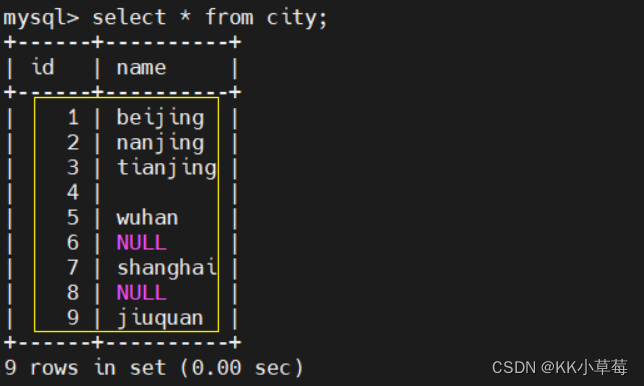
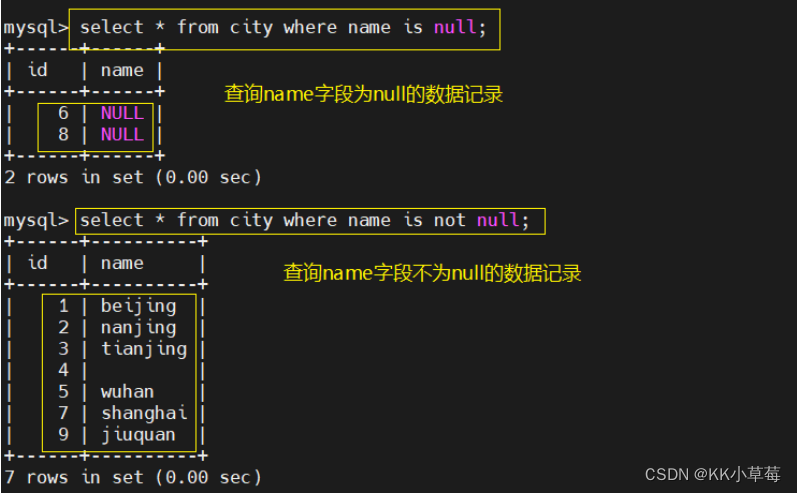
select * from city where name is null;
select * from city where name is not null;
#判断字段是不是为 null 或者不是 null
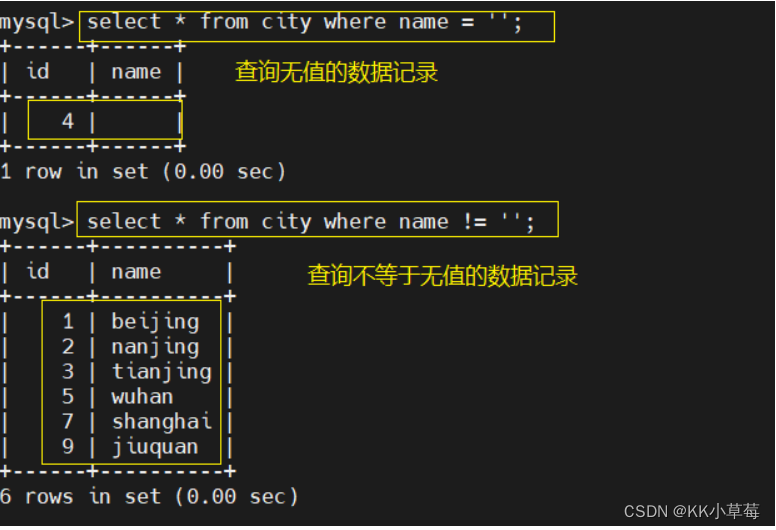
select * from city where name = '';
select * from city where name != '';
#判断无值
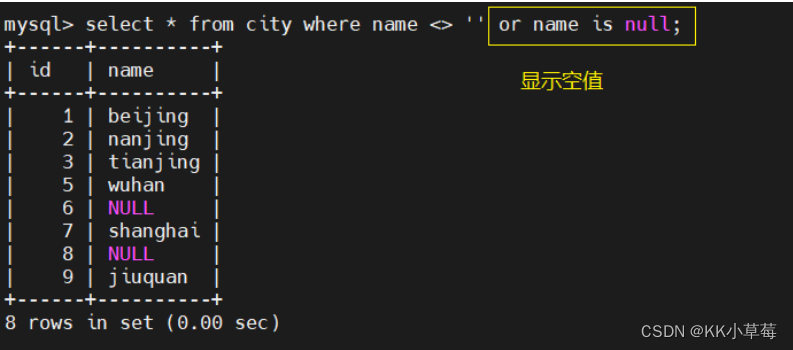
select * from city where name <> '' or name is null;
#显示空值
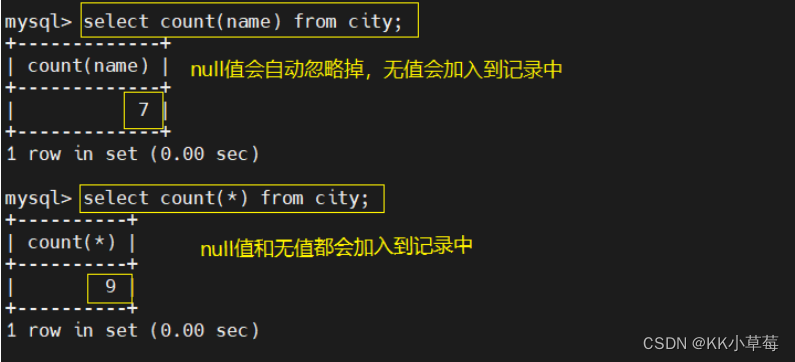
select count(name) from city;
# NULL值会自动忽略掉,无值会加入到记录中
select count(*) from city;
#null值和无值都会加入到记录中
四、正则表达式
语法:select "字段" from "表名" where "字段" regexp {匹配模式};
匹配模式不区分大小写
| 匹配模式 | 描述 | 实例 |
|---|---|---|
| ^ | 匹配文本的开始字符 | ‘^bd’ 匹配以 bd 开头的字符串 |
| $ | 匹配文本的结束字符 | ‘qn$’ 匹配以 qn 结尾的字符串 |
| . | 匹配任何单个字符 | ‘s.t’ 匹配任何 s 和 t 之间有一个字符的字符串 |
| * | 匹配零个或多个在它前面的字符 | ‘fo*t’ 匹配 t 前面有任意个 o |
| + | 匹配前面的字符 1 次或多次 | ‘hom+’ 匹配以 ho 开头,后面至少一个m 的字符串 |
| 字符串 | 匹配包含指定的字符串 | ‘clo’ 匹配含有 clo 的字符串 |
| p1|p2 | 匹配 p1 或 p2 | ‘clo’ 匹配含有 clo 的字符串 |
| […] | 匹配字符集合中的任意一个字符 | ‘[abc]’ 匹配 a 或者 b 或者 c |
| [^…] | 匹配不在括号中的任何字符 | [^ a b] 匹配不包含 a 或者 b 的字符串 |
| {n} | 匹配前面的字符串 n 次 | ‘g{2}’ 匹配含有 2 个 g 的字符串 |
| {n,m} | 匹配前面的字符串至少 n 次,至多m 次 | ‘f{1,3}’ 匹配 f 最少 1 次,最多 3 次 |
举例
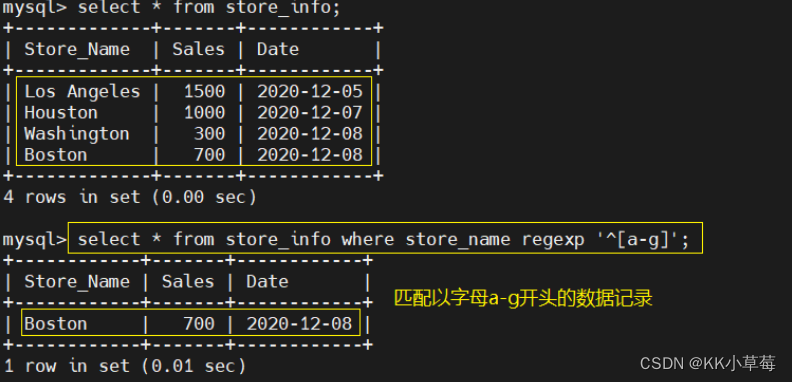
select * from store_info where store_name regexp '^[a-g]';
#匹配以字母a-g开头的数据记录
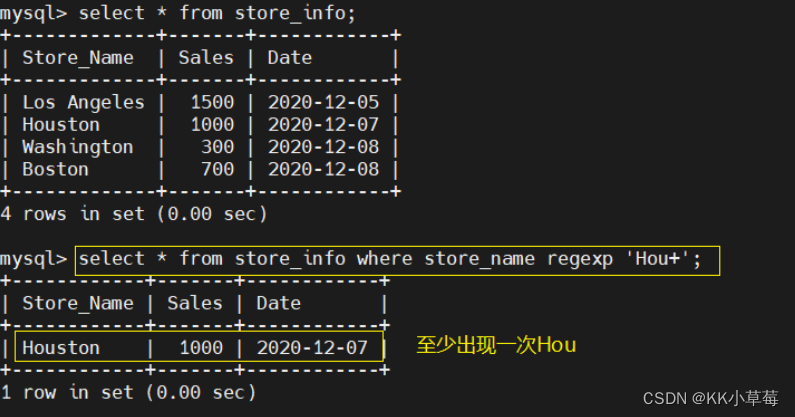
select * from store_info where store_name regexp 'Hou+';
#至少出现一次Hou
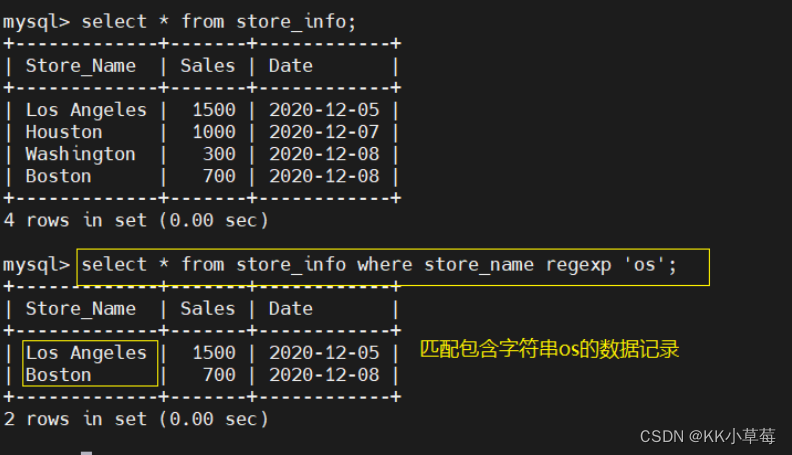
select * from store_info where store_name regexp 'os';
#匹配包含字符串os的数据记录
select * from store_info where store_name regexp 'ho|bo';
select * from store_info where store_name regexp 'Ho|Bo';
#匹配store_info表中包含ho或者bo的数据记录
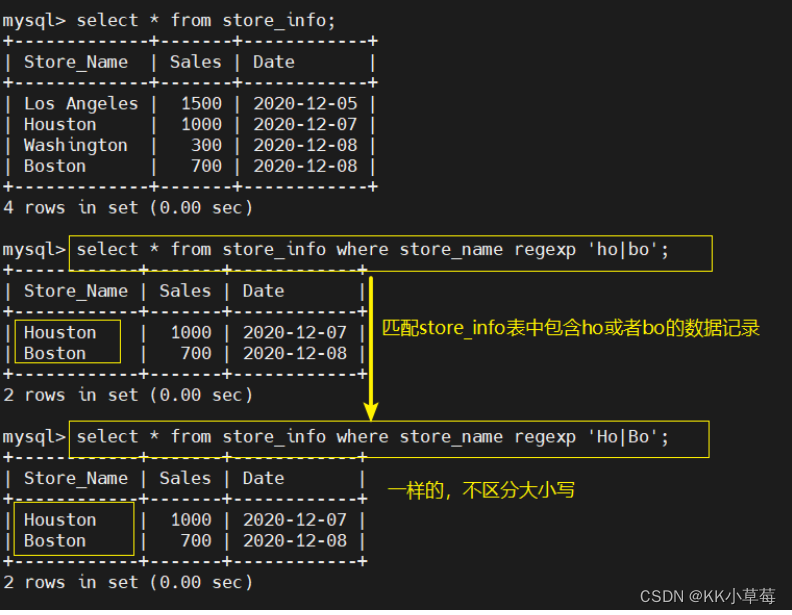
select * from store_info where store_name regexp 'b{1}';
#匹配出现一次字母b的
五、存储过程
存储过程也叫做数据库脚本(MySQL脚本,SQL脚本)
1、简介
存储过程是一组为了完成特定功能的sql语句集合。
存储过程在使用过程中是将常用或者复杂的工作预先使用sql语句写好并用一个指定的名称存储起来,这个过程经编译和优化后存储在数据库服务器中。当需要使用该存储过程时,只需要调用它即可。存储过程在执行上比传统sql速度更快、执行效率更高。
2、存储过程的优点
(1)执行一次后,会将生成的二进制代码驻留缓冲区,提高执行效率
(2)sql语句加上控制语句的集合,灵活性高
(3)在服务器端存储,客户端调用时,降低网络负载
(4)可多次重复被调用,可随时修改,不影响客户端调用
(5)可完成所有的数据库操作,也可控制数据库的信息访问权限
3、创建存储过程的步骤
1)先修改SQL语句结束符
delimiter $$
2)创建存储过程
3)把结束符改回分号
delimiter ;
4)调用存储过程
call 存储过程名;
4、存储过程相关命令
4.1 创建存储过程
delimiter $$
#将语句的结束符号从分号;临时改为两个$$(可以是自定义)
create procedure proc()
#创建存储过程,过程名为proc,不带参数
-> begin
#过程体以关键字 begin 开始
-> select * from store_info;
#过程体语句
-> end $$
#过程体以关键字 end 结束
delimiter ;
#将语句的结束符号恢复为分号delimiter $$
create procedure proc()
-> begin
->.....(要执行的命令)
-> select * from store_info;
-> end $$
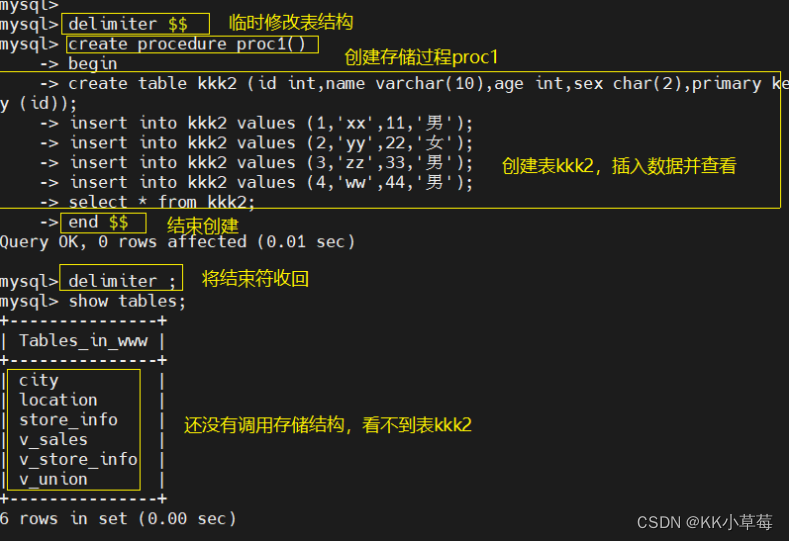
delimiter ; #举例delimiter $$
create procedure proc1()
begin
create table kkk2 (id int,name varchar(10),age int,sex char(2),primary key (id));
insert into kkk2 values (1,'xx',11,'男');
insert into kkk2 values (2,'yy',22,'女');
insert into kkk2 values (3,'zz',33,'男');
insert into kkk2 values (4,'ww',44,'男');
select * from kkk2;
end $$delimiter ;
show tables;
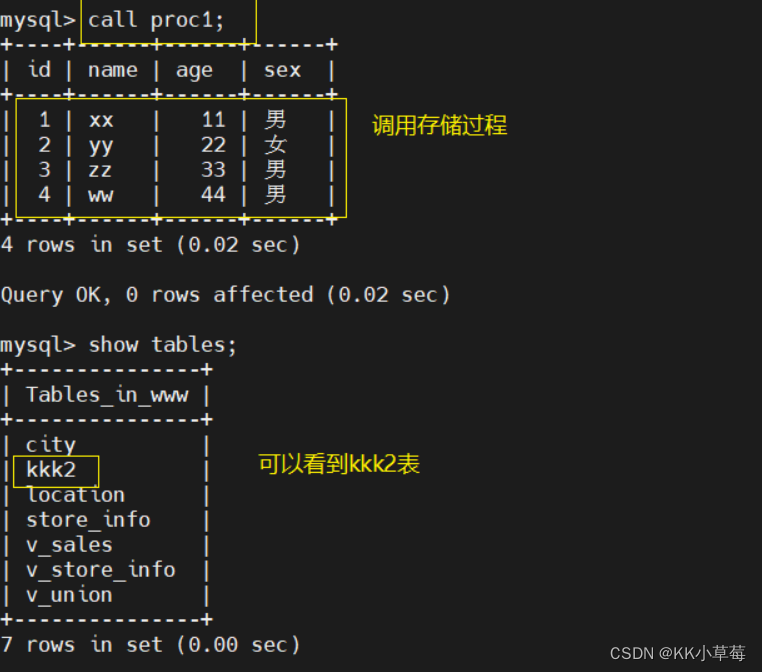
4.2 调用存储过程
call 存储过程名;
call proc1;
#调用存储过程,才能看到创建的表和表数据
show tables;
4.3 查看存储过程
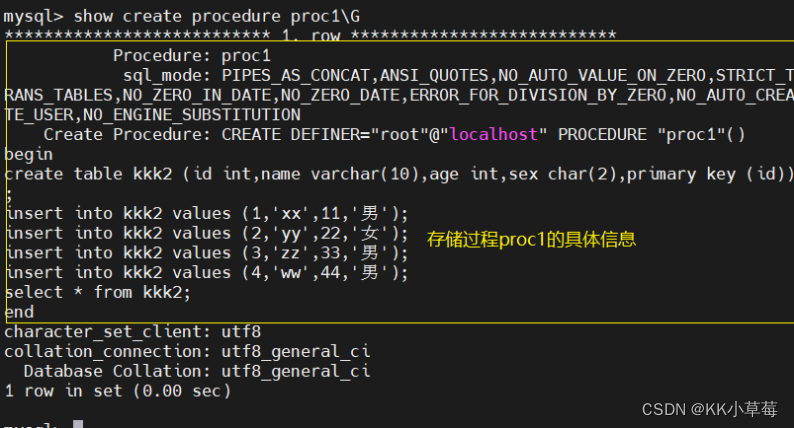
show create procedure [数据库.]存储过程名;
#查看某个存储过程的具体信息show create procedure 存储过程名\G;show procedure status [like '%存储过程名%'] \G;
#模糊匹配查看
4.4 删除存储过程
存储过程内容的修改方法是通过删除原有存储过程,之后再以相同的名称创建新的存储过程。
如果要修改存储过程的名称,可以先删除原存储过程,再以不同的命名创建新的存储过程。
语法
drop procedure if exists 存储过程名;
#仅当存在时删除
#不添加 if exists 时,如果指定的过程不存在,则报错

5、存储过程的参数
| 参数 | 功能 |
|---|---|
| in 输入参数 | 表示调用者向过程传入值(传入值可以是字面量或变量) |
| out 输出参数 | 表示过程向调用者传出值(可以返回多个值)(传出值只能是变量) |
| inout 输入输出参数 | 既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量,传入传出值必须是同一数据类型) |
5.1 in
delimiter $$
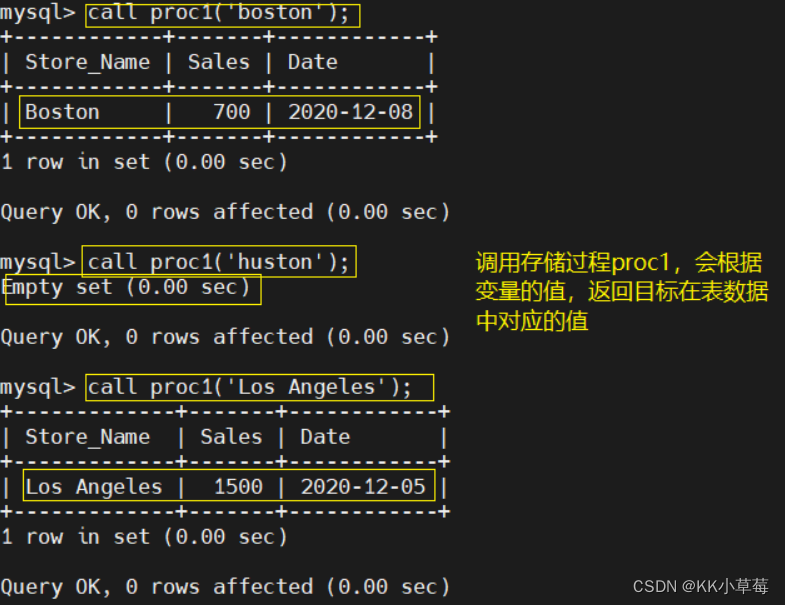
create procedure proc1(in in_name char(16)) begin select * from store_info where store_name = in_name;end $$
delimiter ; call proc1('boston');
call proc1('huston');
call proc1('Los Angeles');
#调用存储过程proc1,会根据变量的值,返回目标在表数据中对应的数据
#in_name为自定义变量名
5.2 out
基本格式delimiter $$
create procedure 存储过程名(in 传入参数名 传入参数数据类型,out 传出参数名 传出参数数据类型)
begin
select 字段 into 传出参数名 from 表名 where 字段=传入参数名;
end $$
delimiter ;call 存储过程名(参数值,@变量名)
#传出参数的值只能用变量获取
#举个例子delimiter $$
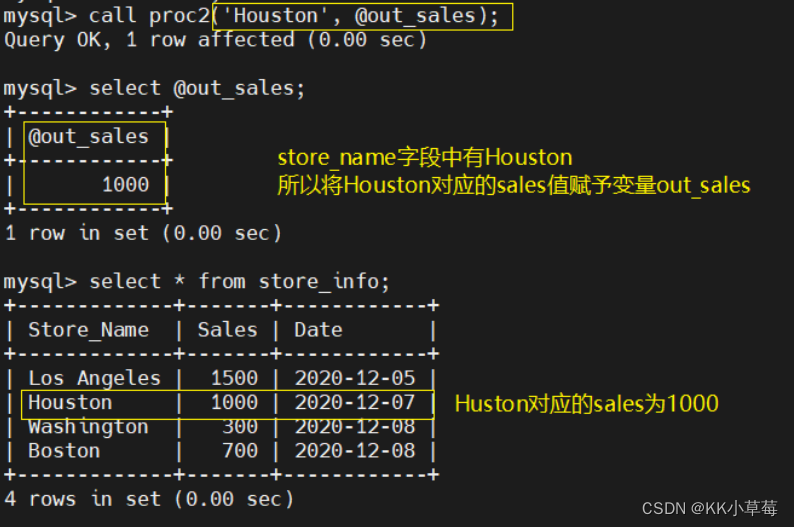
create procedure proc2(in myname char(10), out outname int)
begin
select sales into outname from store_info where store_name = myname;
end $$
delimiter ;
#建一个名为 proc1 的存储过程
#存储过程接收一个字符参数 myname,并将与其匹配的 store_info 表中的 sales 值存储到一个整数参数 outname 中call proc2('Houston', @out_sales);
select @out_sales;
5.3 inout
基本格式delimiter $$
create procedure 存储过程名(into 参数名 参数数据类型)
begin
select 字段 into 传出参数名 from 表名 where 字段=参数名;
end $$
delimiter ;set @变量名 传入值
#变量赋值,传入值
call 存储过程名(@变量名)
#传入传出参数的值只能用变量
select @变量名
#此时变量内容应该为传出值delimiter $$
create procedure proc3(inout insales int)
begin
select count(sales) into insales from store_info where sales < insales;
end $$
delimiter ;
set @inout_sales=1000;
call proc3(@inout_sales);
select @inout_sales;#创建了一个名为 proc4 的存储过程
#存储过程接受一个输入输出参数 insales,并通过查询 store_info 表获取 sales 值小于 insales 的记录数量,并将结果存储到参数 insales 中。
#通过 call 语句调用该存储过程,并使用 select 语句查看存储在变量 @inout_sales 中的值。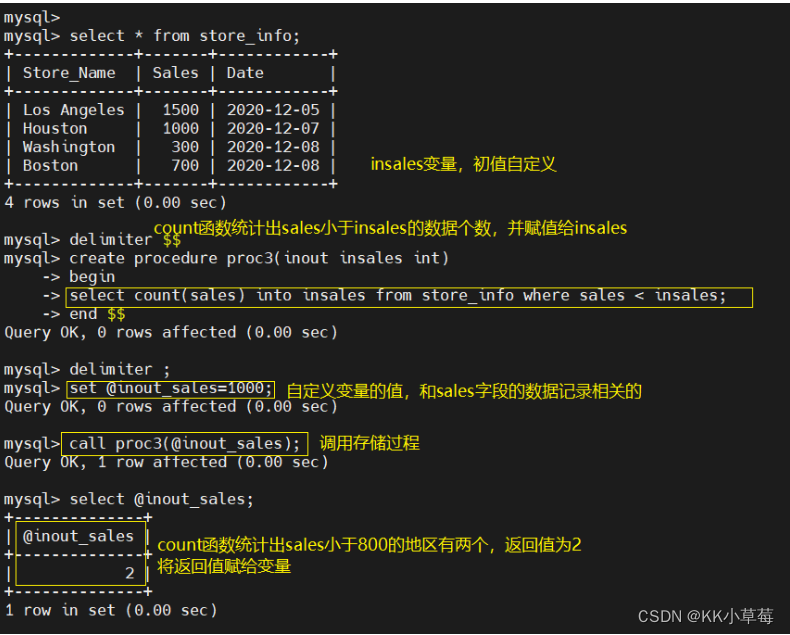
6、存储过程的控制语句
create table t (id int(10));
insert into t values(10);
6.1 条件语句if-then-else…end if
if 条件表达式 thenSQL语句序列1
elseSQL语句序列2
end if;
delimiter $$
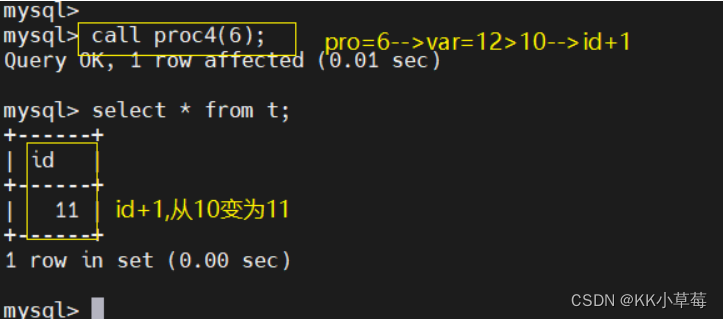
create procedure proc4(in pro int)
begin
declare var int;
set var=pro*2;
if var>=10 then
update t set id=id+1;
else
update t set id=id-1;
end if;
end $$delimiter ;call proc4(6);
#pro=6
#举例
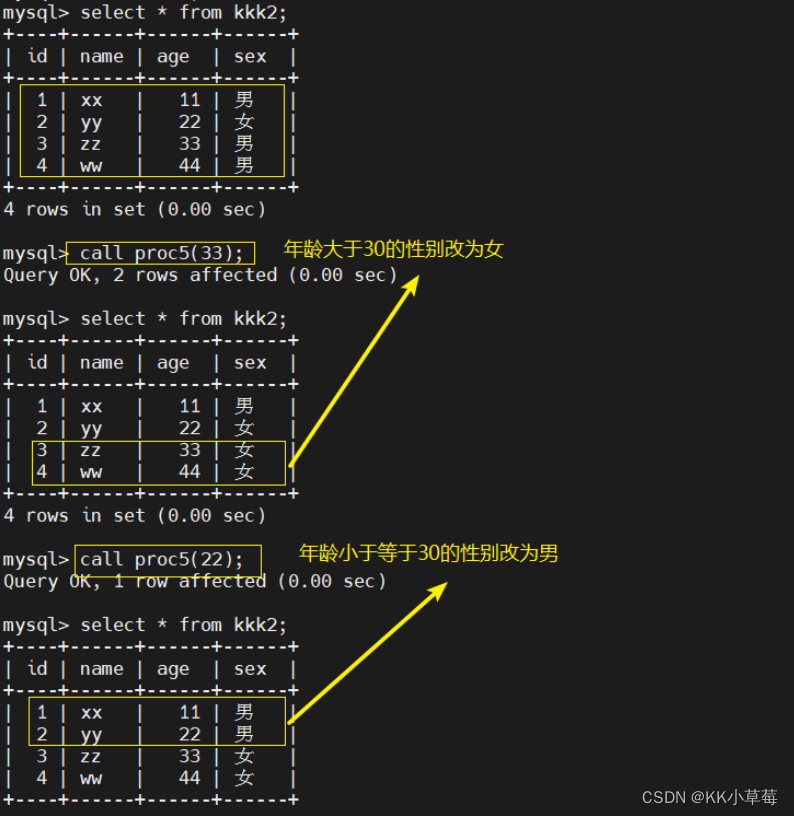
delimiter $$
create procedure proc5(in input_age int)
begin
if input_age > 30 then
update kkk2 set sex = '女' where age > 30;
else
update kkk2 set sex = '男' where age <= 30;
end if;
end $$delimiter ;
select * from kkk2;
call proc5(33);
select * from kkk2;
call proc5(22);
select * from kkk2;
6.2 循环语句while … end while
while 条件表达式
doSQL语句序列set 条件迭代表达式;
end while;
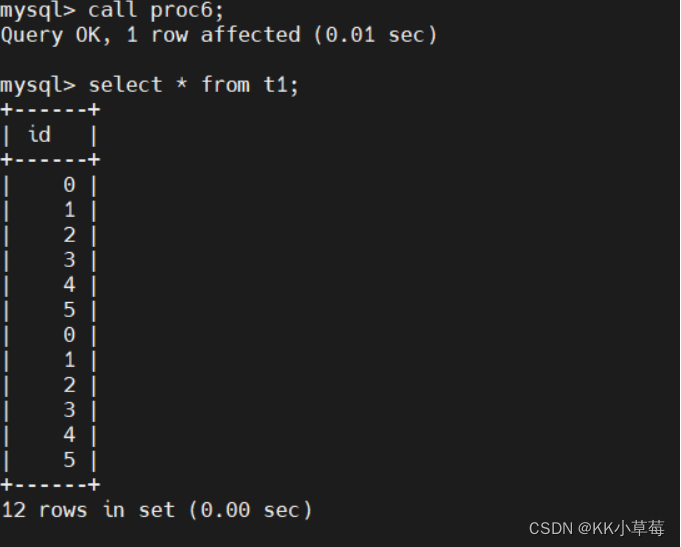
create table t1 (id int);delimiter $$
create procedure proc6()
begin
declare i int(10);
set i=0;
while i<6 do
insert into t1 values(i);
set i=i+1;
end while;
end $$ delimiter ;call proc6;
select * from t1;
举例:
#创建一张表,有一万条数据
#id name
#1 student1
#2 student2
delimiter $$
create procedure proc7()
begin
declare i int;
set i=1;
create table t2 (id int ,name varchar(20));
while i<=10000 do
insert into t2 values(i,concat('student',i));
set i=i+1;
end while;
end $$ #student+学号做拼接
delimiter ;call proc7;
select * from t2;

相关文章:
MySQL高级语句(第二部分)
MySQL高级语句(第二部分)一、视图表 create view1、视图表概述2、视图表能否修改?(面试题)3、基本语法3.1 创建3.2 查看3.3 删除 4、通过视图表求无交集值 二、case语句三、空值(null) 和 无值(’ ) 的区别四、正则表达式五、存储过程1、简介…...
网页电子钟+网页计时器)
HTML计时事件(JavaScript)网页电子钟+网页计时器
setTimeout("函数","未来指定毫秒后调用函数"); clearTimeout(setTimeout("函数","未来指定毫秒后调用函数")); <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title>…...

使用群晖实现Videostation电影的大容量存储及分享教程
文章目录 1.使用环境要求2.制作视频分享链接3.制作永久固定视频分享链接 李哥和他的女朋友是一对甜蜜的情侣,但不幸的是,由于工作原因,他们目前分隔两地,无法常常亲密相伴。 这个距离让李哥特别怀念和女朋友一起在电影院观看电影的…...

后端大厂面试-15道题
1. 说说计算机存储结构 计算机存储结构通常包括这几个层次: 主存储器(Main Memory):也称为内存(RAM,Random Access Memory),主要用于存储当前正在执行的程序和数据。它是计算机中最…...
)
C++: 冒泡排序(Bubble Sort)
假设你有一列由数字组成的玻璃珠,这些珠子的重量不同,你希望将它们按照重量从轻到重排列。你会这样做: 从左到右,比较相邻的两颗珠子的重量。如果左边的珠子比右边的珠子重,就交换它们的位置。然后,继续向…...
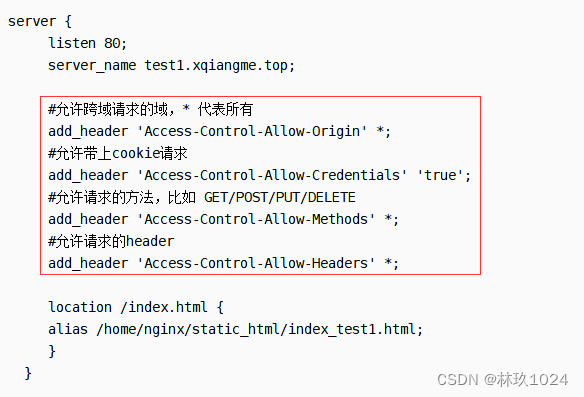
跨域的解决方案
文章目录 概念一、什么是跨域问题二、为什么会发生跨域问题三、跨域解决方案1、JSONP2、添加响应头3、Spring注解CrossOrigin4、配置文件(常用)5、nginx跨域 概念 一、什么是跨域问题 前端调用的后端接口不属于同一个域(域名或端口不同&…...

如何使用Java语言判断出geek是字符串参数类型,888是整数参数类型,[hello,world]是数组参数类型,2.5是双精度浮点数类型?
如何使用Java语言判断出geek是字符串参数类型,888是整数参数类型,[hello,world]是数组参数类型,2.5是双精度浮点数类型? Java是一种静态类型的编程语言,这意味着我们需要在编译时为变量指定具体的类型。但是ÿ…...

9.20华为机试-后端
1、丢失报文的位置 某通信系统持续向外发送报文,使用数组 nums 保存 n个最近发送的报文,用于在报文未达到对端的情况下重发。报文使用序号 sn 表示,序号 sn 按照报文发送顺序从小到大排序,相邻报文 sn 不完全连续且有可能相同。报…...

LC926. 将字符串翻转到单调递增(JAVA - 动态规划)
将字符串翻转到单调递增 题目描述动态规划 题目描述 难度 - 中等 LC926. 将字符串翻转到单调递增(JAVA - 动态规划) 如果一个二进制字符串,是以一些 0(可能没有 0)后面跟着一些 1(也可能没有 1)的形式组成的࿰…...

【高阶数据结构】哈希的应用 {位图;std::bitset;位图的应用;布隆过滤器;布隆过滤器的应用}
一、位图 1.1 位图概念 面试题 给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。【腾讯】 遍历查找:内存中无法存放40亿个整数(约占内存15-16G);时间复杂…...
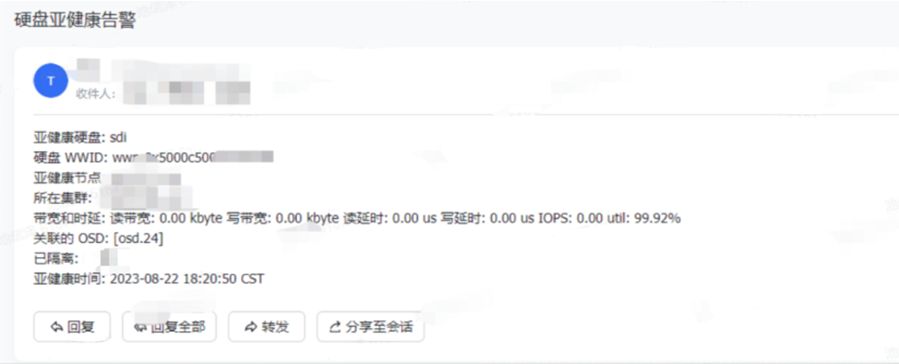
金融生产存储亚健康治理:升级亚健康 3.0 ,应对万盘规模的挑战
随着集群规模的不断扩大,硬盘数量指数级上升,信创 CPU 和操作系统、硬盘多年老化、物理搬迁等多种复杂因素叠加,为企业的存储亚健康管理增加了新的挑战。 在亚健康 2.0 的基础上,星辰天合在 XSKY SDS V6.2 实现了亚健康 3.0&#…...
C语言自定义类型讲解:结构体,枚举,联合(2)
🐵本篇文章将会对位段、枚举和联合的相关知识进行讲解 1. 位段📚 1.1 什么是位段 位段的声明和结构体类似,但是有两点不同: 1.位段的成员必须是int,unsigned int,signed int (C99之后也可以是其他成员&am…...

AI编程助手 Amazon CodeWhisperer 全面解析与实践
目录 引言Amazon CodeWhisperer简介智能编程助手智能代码建议代码自动补全 提升代码质量代码质量提升安全性检测 支持多平台多语言 用户体验和系统兼容性用户体验文档和学习资源个性化体验系统兼容性 功能全面性和代码质量功能全面性代码生成质量和代码安全性 CodeWhisperer的代…...

利用EXCEL进行XXE攻击
利用EXCEL进行XXE攻击 原因 原因 Microsoft Office从2007版本引入了新的开放的XML文件格式,新的XML文件格式基于压缩的ZIP文件格式规范,由许多部分组成。 我们可以将其解压缩到特定的文件夹中来查看其包含的文件夹和文件,可以发现其中多数是…...

芯片验证就是一次旅行
如果你国庆希望去一个你不曾去过的城市旅行,比如“中国苏州”。对游客来说,它是个蛮大的城市,有许多景点可以游玩,还有许多事情可以做。但实际上,即使最豪也最清闲的游客也很难看苏州的所有方方面面。同样的道理也适用…...
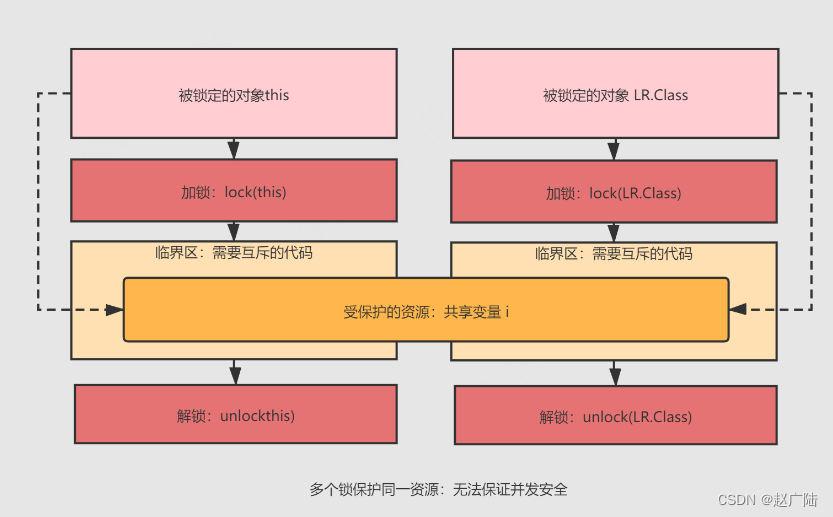
Java深入理解线程的三大特性
目录 1 CPU缓存导致可见性问题2 线程切换导致原子性问题3 性能优化导致有序性问题4 JMM(Java Memory Model)5 volatile6 synchronized 1 CPU缓存导致可见性问题 线程的三大特性: 可见性:Visibility有序性:Ordering原子性:Atomic…...
)
2025快手校招面试真题汇总及其解答(二)
6. hashmap数据结构 HashMap 是一种散列表,它是一种根据键值对来存储数据的数据结构。HashMap 的特点是插入、查找和删除操作的时间复杂度都是 O(1),因此它是一种非常高效的数据结构。 HashMap 的工作原理是将键值对存储在一个数组中,每个键值对都由一个哈希函数来映射到数…...

PHP生成带中文的图片
imagettftext() 函数是 PHP 中的一个内置函数,用于使用 TrueType 字体将文本写入图像。 句法: 数组imagettftext(资源$image,float $size,float $angle, int $x,int $y,…...
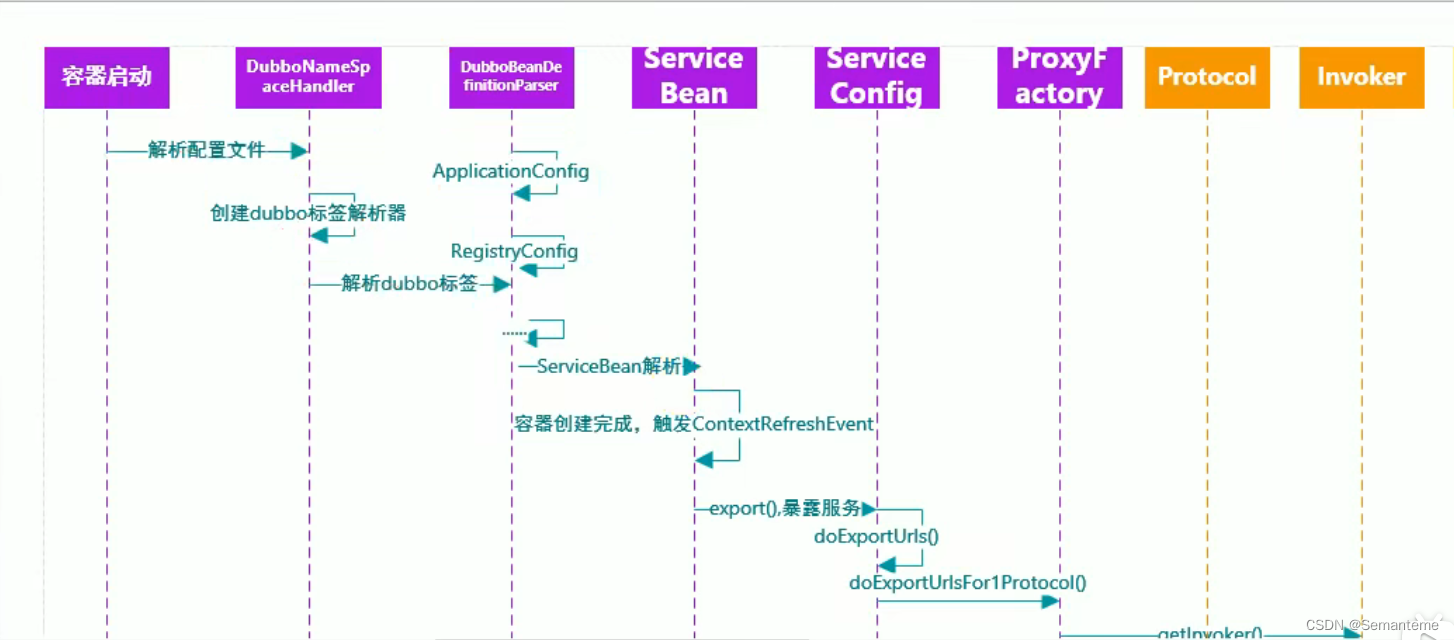
java框架-Dubbo
Dubbo整合Springboot BIO NIO Netty Dubbo 原理 在这里插入图片描述...
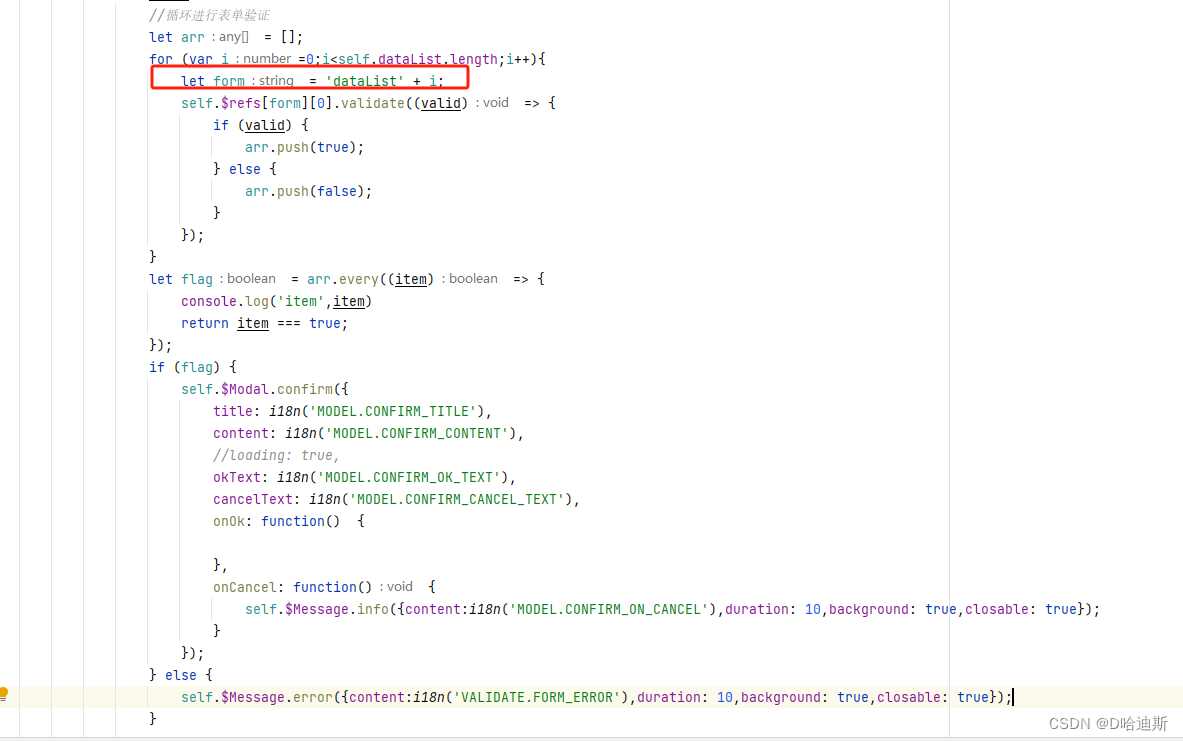
Vue+iview 组件中通过v-for循环动态生成form表单进行表单校验
在做项目时,需要根据需要动态添加或新增表单,同时还需要对表单做校验。详情如下图: 刚开始做表单验证的时候,对于这个动态的表单验证有点难搞,试了好几种方法都没有搞定。最后按照下面这种方法实现了,以此…...

树莓派5 vs 树莓派4:从硬件架构到应用场景的全面对比与实战指南
1. 项目概述:为什么我们需要重新审视树莓派5?如果你和我一样,从树莓派2、3、4一路用过来,每次新版本发布都像是一次“挤牙膏”式的升级,那么树莓派5的到来,绝对会打破你的固有印象。它不再仅仅是“更快一点…...

终极代码阅读神器:MultiHighlight智能高亮插件完整指南
终极代码阅读神器:MultiHighlight智能高亮插件完整指南 【免费下载链接】MultiHighlight Jetbrains IDE plugin: highlight identifiers with custom colors 🎨💡 项目地址: https://gitcode.com/gh_mirrors/mu/MultiHighlight 你是否…...

不只是优化和频率:用GaussView 5.0玩转HOMO/LUMO、电子密度与反应位点预测
不只是优化和频率:用GaussView 5.0玩转HOMO/LUMO、电子密度与反应位点预测 在计算化学领域,Gaussian和GaussView的组合堪称黄金搭档。但许多研究者往往止步于基础的几何优化和频率计算,未能充分挖掘这套工具在反应机理研究和论文写作中的潜力…...

Gerbv:专业PCB设计验证工具,开源免费的Gerber文件查看器终极方案
Gerbv:专业PCB设计验证工具,开源免费的Gerber文件查看器终极方案 【免费下载链接】gerbv Maintained fork of gerbv, carrying mostly bugfixes 项目地址: https://gitcode.com/gh_mirrors/ge/gerbv 当你面对复杂的PCB设计文件时,是否…...

从零到发刊:NotebookLM在有机合成路线设计中的7步闭环工作法,北大化学院实验室内部培训材料首次公开
更多请点击: https://codechina.net 第一章:NotebookLM化学研究辅助 NotebookLM 是 Google 推出的基于 AI 的研究协作者,专为深度阅读、知识整合与推理设计。在化学研究场景中,它可高效处理文献 PDF、实验记录、光谱数据报告及教…...

EVA-7M,支持GPS/GLONASS及低功耗省电模式的超紧凑型GNSS模块
简介今天我要向大家介绍的是 u-blox 的超紧凑型独立GNSS定位模块——EVA-7M。这是一款专为对成本和空间敏感的应用而设计的独立GNSS模块。该模块基于 u-blox 7 定位引擎(接收GPS、GLONASS、QZSS和SBAS信号)设计,采用行业最小的独立GNSS封装尺…...

从零构建私有数字保险库:硬件选型、加密策略与实战部署
1. 项目概述:从“0”开始的数字资产保险库在数字资产日益成为个人与企业核心财富的今天,如何安全、自主地保管这些资产,成为了一个绕不开的难题。无论是加密货币的私钥、重要的数字凭证、敏感的商业文档,还是家庭成员的密码本&…...

从Mid360到自主移动:基于Fast-LIO与Move_Base的机器人导航实战拆解
1. Mid360激光雷达与Fast-LIO的适配实战 第一次拿到Livox Mid360激光雷达时,我完全被它36059的超大视场角惊艳到了。这款固态激光雷达不仅体积小巧,而且完全不用担心传统机械式雷达的电机磨损问题。但真正开始用它做SLAM时,才发现实物开发和仿…...
)
别再手动启动了!分享一个我自用的RocketMQ Dashboard一键启动脚本(附源码解析)
解放双手:RocketMQ集群智能启动方案与Dashboard深度优化指南 1. 运维自动化的必要性 每次重启服务器后,面对需要依次启动NameServer、Broker和Dashboard的繁琐流程,相信不少RocketMQ使用者都经历过这样的痛苦:忘记启动某个组件导致…...

Windows 11系统优化终极指南:免费提升性能与隐私保护的完整方案
Windows 11系统优化终极指南:免费提升性能与隐私保护的完整方案 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutt…...