Logstash、sharding-proxy组件高级配置
记录Logstash数据同步插件在分库分表场景下相关高可用、高并发配置
一、Logstash
1.配置文件控制任务数
vim /etc/logstash/logstash.yml
pipeline.workers: 24
pipeline.batch.size: 10000
pipeline.batch.delay: 10
Logstash建议在修改配置项以提高性能的时候,每次只修改一个配置项并观察其性能和资源消耗(cpu、io、内存)。性能检查项包括:
1、检查input和output设备
1)、CPU
2)、Memory
3)、io
2、磁盘io
3、网络io
4、检查jvm堆
5、检查工作线程设置
2.配置说明
Logstash持久化到磁盘,当发生异常情况,比如logstash重启,有可能发生数据丢失,可以选择logstash持久化到磁盘,修改之前重启logstash数据丢失,修改之后重启logstash数据不丢失。
以下是具体操作:
queue.type: persisted
path.queue: /usr/share/logstash/data #队列存储路径;如果队列类型为persisted,则生效
queue.page_capacity: 250mb #队列为持久化,单个队列大小
queue.max_events: 0 #当启用持久化队列时,队列中未读事件的最大数量,0为不限制
queue.max_bytes: 1024mb #队列最大容量
queue.checkpoint.acks: 1024 #在启用持久队列时强制执行检查点的最大数量,0为不限制
queue.checkpoint.writes: 1024 #在启用持久队列时强制执行检查点之前的最大数量的写入事件,0为不限制
queue.checkpoint.interval: 1000 #当启用持久队列时,在头页面上强制一个检查点的时间间隔优化input,filter,output的线程模型。
增大 filter和output worker 数量 通过启动参数配置 -w 48 (等于cpu核数),logstash正则解析极其消耗计算资源,而我们的业务要求大量的正则解析,因此filter是我们的瓶颈。
官方建议线程数设置大于核数,因为存在I/O等待。
增大 woker 的 batch_size 150 -> 3000 通过启动参数配置 -b 3000内存
logstash是将输入存储在内存之中,worker数量 * batch_size = n * heap (n 代表正比例系数)
Logstash的优化相关配置
默认配置 —> pipeline.output.workers: 1官方建议是等于 CPU 内核数
可优化为 —> pipeline.output.workers: 不超过pipeline 线程数
默认配置 —> pipeline.workers:** 2
可优化为 —> pipeline.workers: CPU 内核数(或几倍 cpu 内核数)**实际 output 时的线程数
默认配置 —> pipeline.output.workers: 1 可优化为 —> pipeline.output.workers: 不超过 pipeline 线程数每次发送的事件数
默认配置 ---> pipeline.batch.size: 125 可优化为 ---> pipeline.batch.size: 1000发送延时
默认配置 ---> pipeline.batch.delay: 5 可优化为 ---> pipeline.batch.size: 10参考建议
# pipeline线程数,官方建议是等于CPU内核数 pipeline.workers: 24 # 实际output时的线程数 pipeline.output.workers: 24 # 每次发送的事件数 pipeline.batch.size: 3000 # 发送延时 pipeline.batch.delay: 5注意:当batch.size增大,es处理的事件数就会变少,写入也就越快了。此问题用以下办法解决
就是你的bulk线程池处理不过来你的请求。处理方案:调整你es集群的bulk队列大小(默认为50),或增加你的es内存解决办法 :
官方的建议是提高每次批处理的数量,调节传输间歇时间。当batch.size增大,es处理的事件数就会变少,写入也就愉快了。
具体的worker/output.workers数量建议等于CPU数,batch.size/batch.delay根据实际的数据量逐渐增大来测试最优值。总结
通过设置 -w 参数指定 pipeline worker 数量,也可直接修改配置文件 logstash.yml。这会提高 filter 和 output 的线程数,如果需要的话,将其设置为 cpu 核心数的几倍是安全的,线程在 I/O 上是空闲的。
默认每个输出在一个 pipeline worker 线程上活动,可以在输出 output 中设置 workers 设置,不要将该值设置大于
pipeline worker 数。
还可以设置输出的 batch_size 数,例如 ES 输出与 batch size 一致。
filter 设置 multiline 后,pipline worker 会自动将为 1,如果使用 filebeat,建议在 beat中就使用 multiline,如果使用 logstash 作为 shipper,建议在 input 中设置 multiline,不要在filter 中设置 multiline
还有请注意插件连接池的数量设置,比如mysql最大连接数,单个脚本文件中的配置设置
3.logstash-jdbc-output插件
链接池偶尔报错:HikariPool-1 – Connection is not available, request timed out after 39985ms.
记录:调试相关插件配置,最终发现是因为logstash work数过大,CPU配置,任务配置文件中关于线程,连接池配置不合理导致
二、Sharding-proxy
点击查看proxys属性配置
主要是修改连接池,一个是proxy自己的连接池,一个是每个分片库配置使用的最大连接池,别太大,理解以下CPU抢占,线程搞太多反而影响效率,也不能太小,太小吞吐量太差
相关文章:
Logstash、sharding-proxy组件高级配置
记录Logstash数据同步插件在分库分表场景下相关高可用、高并发配置 一、Logstash 1.配置文件控制任务数 vim /etc/logstash/logstash.yml pipeline.workers: 24 pipeline.batch.size: 10000 pipeline.batch.delay: 10 Logstash建议在修改配置项以提高性能的时候,每…...
【Elasticsearch】简单搜索(三)
简介:Elasticsearch(ES)是一个开源的分布式搜索和分析引擎,用于快速存储、搜索和分析大量数据。它具有高性能、可扩展性和灵活性的特点,被广泛用于构建实时搜索、日志分析、数据可视化等应用。 这篇文章主要介绍检索相…...
【PMP/软考】软件需求的三个主要层次:业务需求、用户需求和功能需求解释及实例解析
简述 当进行需求分析时,通常着重考虑三个主要层次:业务需求、用户需求和功能需求。业务需求关注项目与组织战略目标的一致性,用户需求明确最终用户的期望,而功能需求定义具体的系统功能和特性。这三个层次为项目管理和软件工程提…...
Linux基础知识 总结
Linux基础知识 总结 1、Clion的简单介绍 CLion是以IntelliJ为基础,专为开发C及C所设计的跨平台IDE,可以在Windows、Linux及MacOS使用,这里我是在ubuntu 16.0.4基础上安装。2、下载 Linux版Clion的.tar.gz的压缩包 wget https://download.j…...
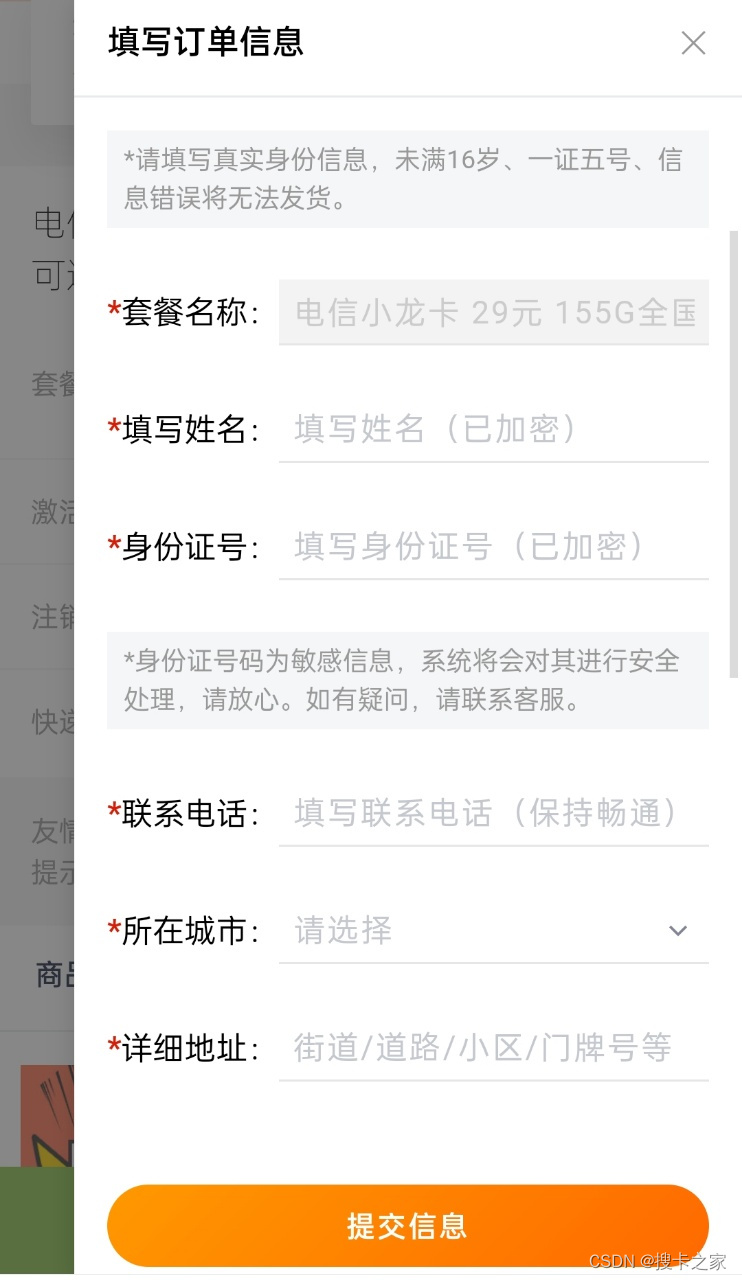
网上申请流量卡要不要身份证?填写的信息安全吗?
网上申请流量卡要不要身份证?当然是要的! 现在直接从营业厅办理流量卡的很少了,都是直接在网上申请大流量卡,在这里小编提醒大家,在网上申请大流量卡和激活时都是需要提供个人证件的。 申请时提供身份证号是为了运营…...
关于计算机缺失vcruntime140.dll文件的解决方法分享
在计算机系统中,DLL(动态链接库)是一种特殊的文件类型,它包含了可以被多个程序共享的代码和数据。其中,VCRuntime140.dll是一个由Microsoft Visual C Redistributable package提供的运行时库文件,它为许多M…...

华为乾坤区县教育安全云服务解决方案(2)
本文承接: https://blog.csdn.net/qq_37633855/article/details/133276200?spm1001.2014.3001.5501 重点讲解华为乾坤区县教育安全云服务解决方案的部署流程。 华为乾坤区县教育安全云服务解决方案(2) 课程地址解决方案部署整体流程组网规划…...

PL/SQL异常抓取
目录 1. -- 什么是异常 2. 如何捕获预定义异常? 3.捕获异常的两个函数 SQLCODE :为错误代码返回一个数值 SQLERRM : 返回字符串的数据,包含了与错误相关的信息. 1. -- 什么是异常 DECLARE V_JOB EMP.JOB%TYPE; BEGIN SELECT JOB INTO V_JOB FROM EMP WHERE JOB CLERK; D…...

Java 18的未来:新特性和编程实践
文章目录 引言新特性预览1. 基于值的类的进一步改进2. 模式匹配的增强3. 新的垃圾回收器4. 扩展的模块系统5. 更强大的异步编程 编程实践示例1:基于值的类示例2:模式匹配的增强示例3:新的垃圾回收器 结论 🎉欢迎来到Java学习路线专…...
)
2024快手校招面试真题汇总及其解答(三)
11. 联合索引 联合索引是指包含多个列的索引,与之概念相对的是单列索引,仅包含一个数据列。在大多数情况下,建立多列索引的好处都要多于单列索引。 联合索引的优点 联合索引的优点如下: 提高查询效率:联合索引可以提高查询效率,特别是对于复杂的查询条件。减少磁盘IO:…...

【QandA C++】内存泄漏、进程地址空间、堆和栈、内存对齐、大小端和判断、虚拟内存等重点知识汇总
目录 内存泄漏 内存模型 、进程地址空间 堆和栈的区别 内存对齐 大端小端及判断 虚拟内存有什么作用 内存泄漏 概念: 是指因为疏忽或错误造成程序未能释放已经不再使用的内存的情况, 内存泄漏并不是指内存在物理上的消失, 而是应用程序分配了某段内存后, 因为设计错误…...
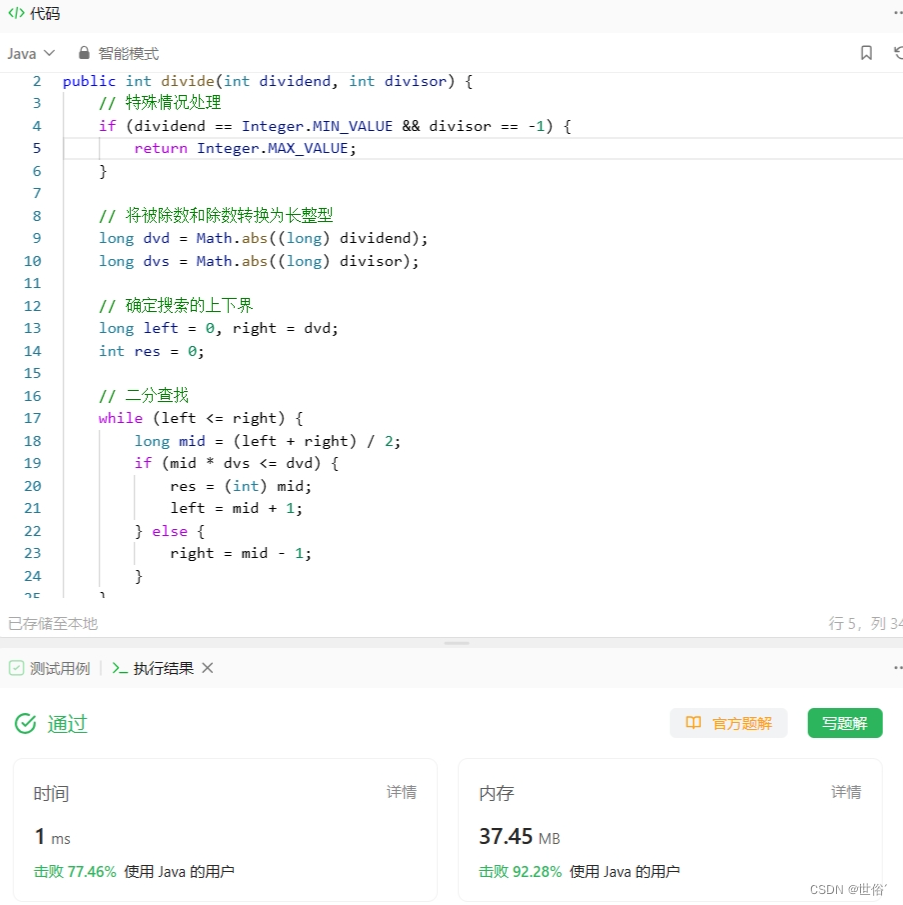
怒刷LeetCode的第12天(Java版)
目录 第一题 题目来源 题目内容 解决方法 方法一:贪心 第二题 题目来源 题目内容 解决方法 方法一:双指针 方法二:KMP算法 方法三:indexOf方法 方法四:Boyer-Moore算法 方法五:Rabin-Karp算法…...
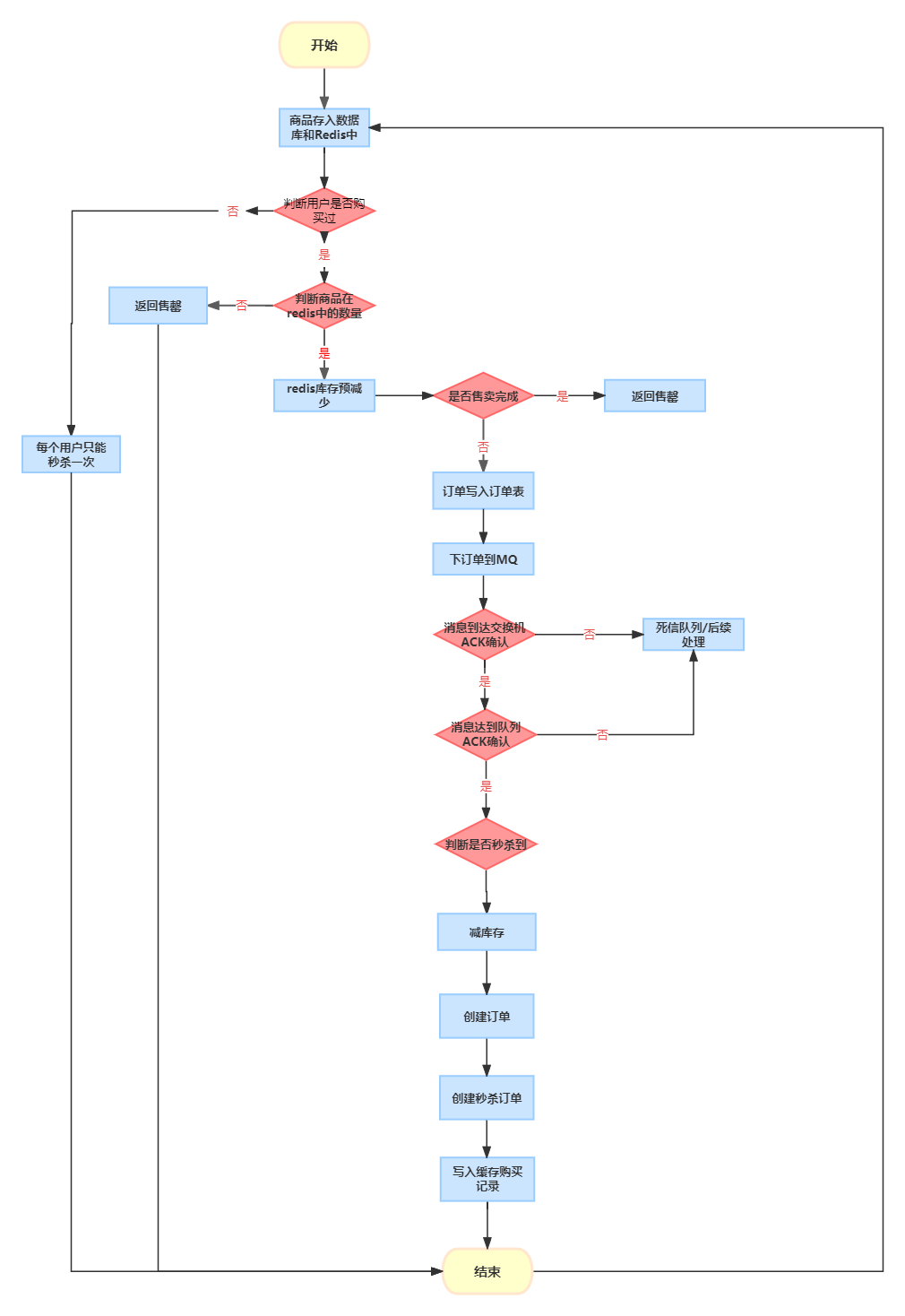
RabbitMQ实现秒杀场景示例
本文章通过MQ队列来实现秒杀场景 整体的设计如下图,整个流程中对于发送发MQ失败和发送到死信队列的数据未做后续处理 1、首先先创建MQ的配置文件 Configuration public class RabbitConfig {public static final String DEAD_LETTER_EXCHANGE "deadLetterE…...

如何提升网站排名优化(百度SEO优化,轻松提升排名)
在当今互联网时代,拥有一个优秀的网站是很重要的。而一个网站如果能够在搜索引擎上的排名很靠前,那么将会带来更多的流量、更多的用户和更多的利润。那么如何提升网站排名优化呢?蘑菇号www.mooogu.cn 百度SEO优化的5个规则 1.关键词选取要合…...

CountDownLatch 和 CyclicBarrier 用法以及区别
在使用多线程执行任务时,通常需要在主线程进行阻塞等待,直到所有线程执行完毕,主线程才能继续向下执行,主要有以下几种可选方式 1. 调用 main 线程的 sleep 方法 一般用于预估线程的执行时间,在主线程内执行线程sleep…...
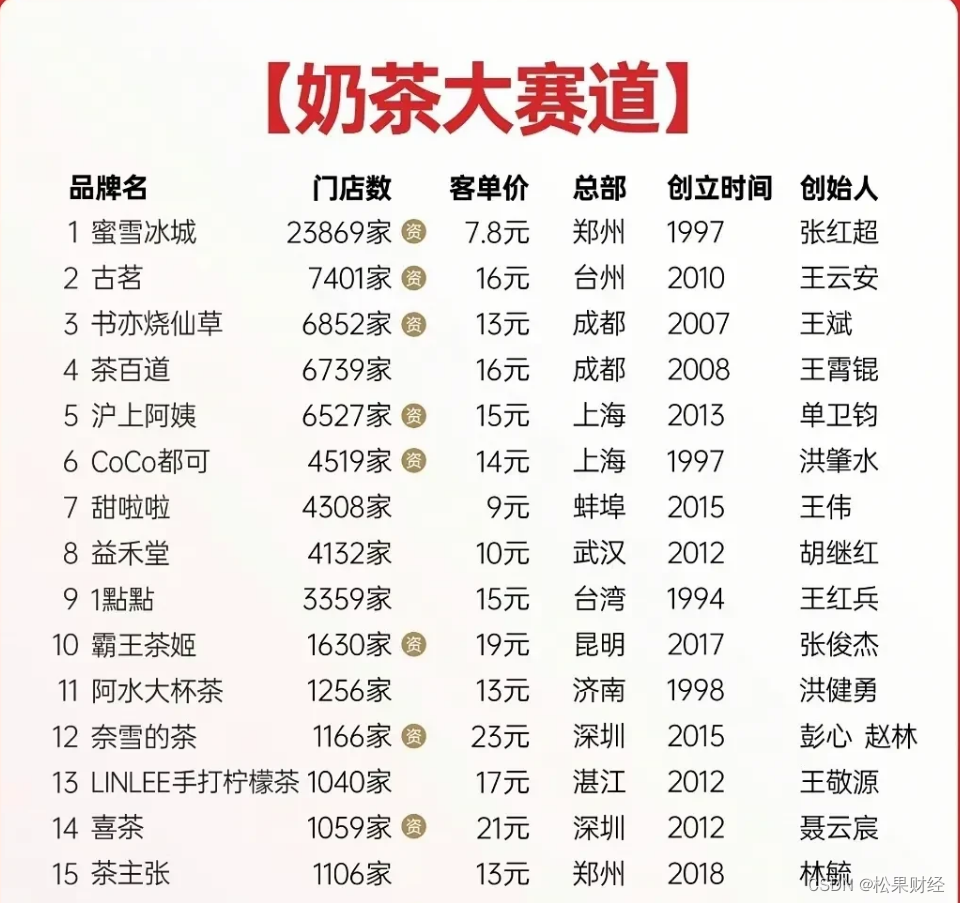
9.9喝遍“茶、奶、果、酒”,茶饮价格战是因为“无活可整”?
“家人们谁懂啊,周一瑞幸周二奈雪周三茶百道周四库迪周五古茗周六coco,9块9根本喝不完!” 紧随咖啡的9.9大战,茶饮们也在今年加速“蜜雪冰城化”,9.9变成了一种潮流。伴随着茶百道、coco、奈雪的茶等品牌把9.9玩出了更…...

echarts 学习网址
1、PPChart 网址:PPChart - 让图表更简单 2、YX-Chartlib 网址:http://chartlib.datains.cn3、isqqw 网址:echarts图表集4、makeapie 网址:makeapie echarts社区图表可视化案例5、Chart.Top 网址:chart.top - 让图…...

android源码编译
整包编译 导入环境变量 source ./build/envsetup.shlunch:选择平台编译选项make:执行编译 编译单个apk 进入到apk mk所在路径 mma...

盘点双电机驱动技术
对于电动汽车来说,双电机相对于单电机加主减速器或变速箱的方案在提高驱动效率方面的优势: 第一,单电机在低速、高速轻载等情况下,效率降低比较严重。 电动机的高效区间虽然比内燃机大得多,但是汽车的转速和转矩要求…...

ubuntu下用pycharm专业版连接AI服务器及其docker环境
一:用pycharm专业版连接AI服务器 1、首先在自己电脑上新建一个文件夹,后续用于映射服务器上自己所要用的项目文件 2、用pycharm专业版打开该文件夹,作为一个项目打开 3、然后在工具->部署->配置 4、配置中形式如下: 点击左…...

深度学习嵌入操作优化与DAE架构实践
1. 嵌入操作与DAE架构的核心挑战在深度学习推荐系统和图神经网络中,嵌入操作(Embedding Operations)占据了超过60%的计算时间。这类操作本质上是一种特殊的稀疏-密集张量乘法(SpMM),其计算模式具有两个显著…...

长期使用Taotoken Token Plan套餐对项目开发成本的实际影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐对项目开发成本的实际影响 1. 从按需付费到固定预算的转变 在项目开发中引入大模型能力…...

终极Markdown浏览器扩展:如何打造完美的文档阅读体验
终极Markdown浏览器扩展:如何打造完美的文档阅读体验 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer Markdown Viewer是一款功能强大的浏览器扩展,专为开发…...

点支承幕墙玻璃破裂故障分析
点支承幕墙玻璃破裂故障分析 【作 者】:龙文志 【摘 要】:本文从点支承幕墙玻璃破裂故瘴出发,系统阐述了点支承幕墙玻璃破裂故障多于其它玻璃幕墙的原因,提出了点支承玻璃幕墙设计时,除对玻璃面板的大面应力进行计算分析外,同时也应该对玻璃孔边应力进行设计分析;为了…...

云原生技能图谱:构建开发者能力模型与学习路径
1. 项目概述:一个面向云原生时代的技能图谱仓库最近在整理团队内部的技术分享材料时,我偶然发现了一个在开发者社区里讨论度颇高的开源项目:prevu-cloud/skills。乍一看这个名字,你可能会觉得它只是一个普通的“技能列表”或者“学…...

Visual Studio Code搭建c语言编译环境下载c/c++ Runner插件编译报错问题
安装版本默认是最新插件。下载如果无法编译就换版本。最后换到1.5.5版本就编译成功了。耗时2小时解决无法编译报错。process_begin: CreateProcess(NULL, ./build\Debug/outDebug "", ...) failed. make (e2): 系统找不到指定的文件。...

CoPaw:让AI代码助手深度适配个人项目与团队规范的工程化实践
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫CoPaw,作者是 alexgzx。光看名字可能有点摸不着头脑,但如果你对 AI 辅助编程、代码生成或者想提升自己的开发效率感兴趣,那这个项目绝对值得你花时间研究一下。简单来说…...

我的Claude Code不再被封号,Taotoken提供了稳定可靠的替代方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 我的Claude Code不再被封号,Taotoken提供了稳定可靠的替代方案 作为一名频繁使用Claude Code进行代码生成和审查的个人…...

Boss直聘职位数据自动化采集:Python爬虫架构设计与工程实践
1. 项目概述与核心价值最近在技术社区里,看到不少朋友在讨论一个叫longsizhuo/BossZhiPin_Job_Search的项目。光看名字,你大概就能猜到,这是一个跟“Boss直聘”和“职位搜索”相关的自动化工具。作为一个在招聘数据分析和自动化领域摸爬滚打了…...
)
乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓)
更多请点击: https://intelliparadigm.com 第一章:乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓) ElevenLabs 官方文档中仅标注 ur 为乌尔…...