【大数据存储与处理】1. hadoop单机伪分布安装和集群安装
0. 写在前面
0.1 软件版本
hadoop2.10.2
ubuntu20.04
openjdk-8-jdk
0.2 hadoop介绍
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算 .—百度词条hadoop
1. 创建hadoop用户
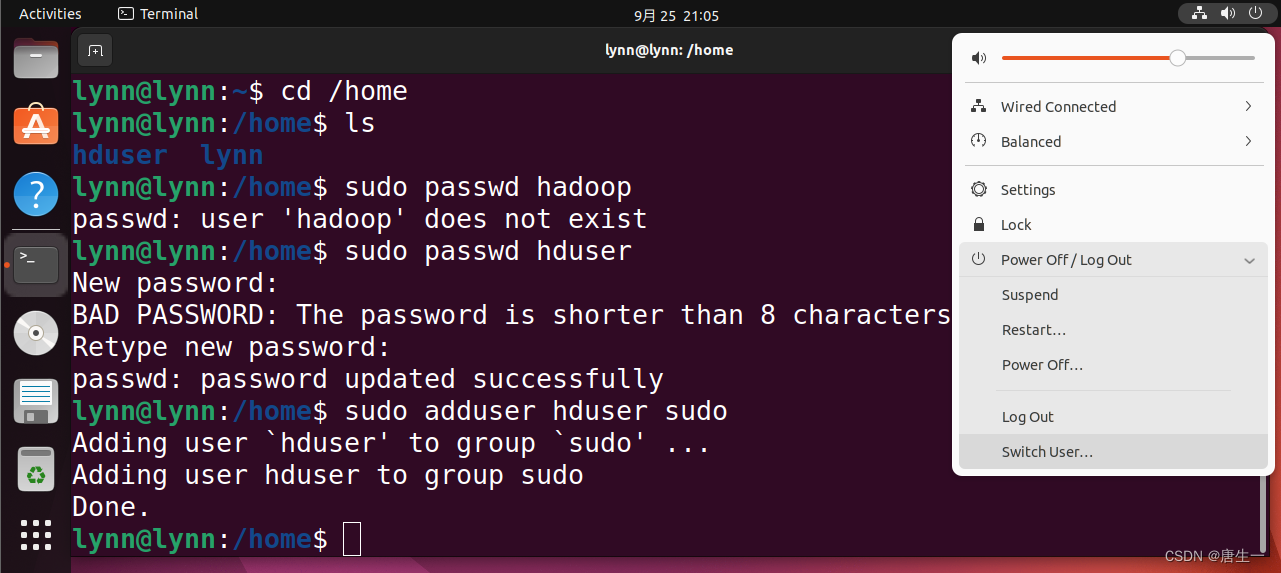
lynn@lynn:~$ sudo useradd -m hduser -s /bin/bash # 创建用户hduser 并指定使用bash终端作为shell
lynn@lynn:~$ cd /home
lynn@lynn:~$ ls
hduser lynn # 代表用户创建成功
lynn@lynn:~$ sudo passwd hduser # 设置密码
lynn@lynn:~$ sudo adduser hduser sudo # 为hduser增加管理员权限
Adding user `hduser' to group `sudo' ...
Adding user hduser to group sudo
Done.
# 然后切换用户登录
2. 安装java
注意,已经切换到了hduser用户,lynn主机下
hduser@lynn:~$ sudo apt-get update # 更新包
# The "unable to lock directory /var/lib/apt/lists/" error on Ubuntu typically occurs when the APT package management system is already running or has crashed.如果出现unable to lock,多数是因为APT包管理系统正在运行或崩溃,可尝试重启
# hduser@lynn:~$ ps aux | grep -i apt # 可使用此命令查看哪些安装在使用apt,如果有则等待这些安装完成
# The error in Ubuntu may be displayed below:
# /var/lib/dpkg/lock
# /var/lib/dpkg/lock-frontend
# /var/lib/apt/lists/lock
# /var/cache/apt/archives/lock
# These are lock files, which could prevent two instances of apt or dpkg from using the same files simultaneously.
# This could occur if an installation is needed or did not finish. Just remove the lock files.
# To delete or erase the lock files, use the rm command:
# sudo rm /var/lib/dpkg/lock
# sudo rm /var/lib/apt/lists/lock
# sudo rm /var/cache/apt/archives/lock
hduser@lynn:~$ sudo apt search jdk # 查找jdk包,也可以直接运行下一条命令
# 安装openjdk-8-jdk版本
hduser@lynn:~$ sudo apt install openjdk-8-jdk
# 安装完成之后查看一下版本号,确认安装成功
hduser@lynn:~$ java -version
hduser@lynn:~$ javac -version
hduser@lynn:~$ update-alternatives --display java # 查看已安装的java版本列表
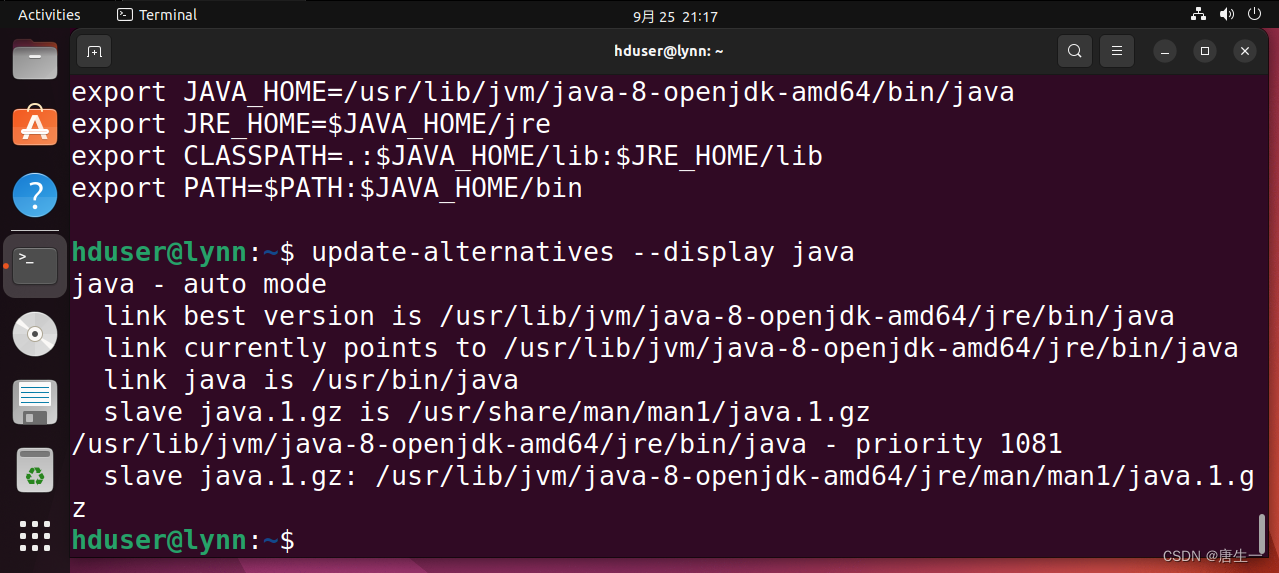
hduser@lynn:~$ sudo gedit .bashrc # 设置环境变量
# 在弹出的窗口最后增加如下语句:
# export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/bin/java # 设置Java的运行程序
# export JRE_HOME=$JAVA_HOME/jre
# export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
# export PATH=$PATH:$JAVA_HOME/bin
hduser@lynn:~$ source .bashrc # 使环境变量生效3. 安装hadoop
从清华镜像源网站下载hadoop2.10.2版本
hduser@lynn:~$ sudo tar -zxvf hadoop-2.10.2.tar.gz
hduser@lynn:~$ sudo mv hadoop-2.10.2 /usr/local/hadoop
hduser@lynn:~$ sudo gedit ~/.bashrc # 设置hadoop环境变量,如果gedit打开失败,试试重启终端
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
hduser@lynn:~$ source ~/.bashrc # 使环境变量生效
3.0 配置SSH
# 安装ssh
hduser@lynn:~$ sudo apt-get install ssh
hduser@lynn:~$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
# -t 指定要生成的密钥类型
# -P 表示密码,''表示不指定密码进行连接
# -f 是密钥生成之后保存的位置
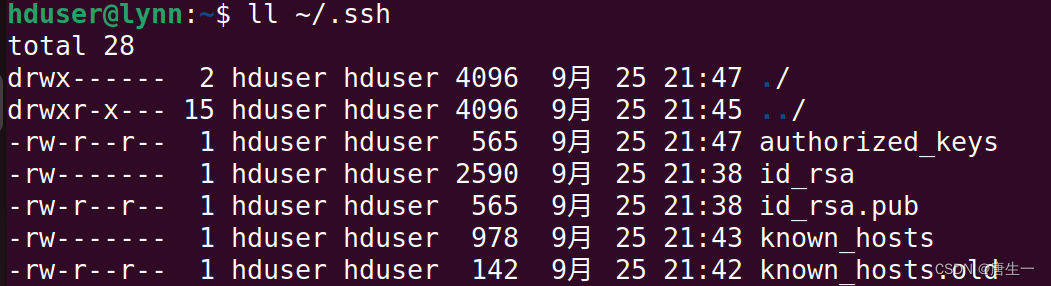
hduser@lynn:~$ cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys # 拷贝公钥到要进行免密登录的机器上
hduser@lynn:~$ ssh localhost # 登录本机
hduser@lynn:~$ ll ~/.ssh # 查看相关文件
3.1 单机伪分布模式
在一台运行linux的单机上,用伪分布方式,用不同的进程模拟分布运行下的NameNode、DataNode、JobTracker、TaskTracker等各类节点。
3.1.1 配置hadoop-env
hduser@lynn:~$ sudo gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh
修改JAVA_HOME:
原来是:export JAVA_HOME=${JAVA_HOME}
修改为:export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd65
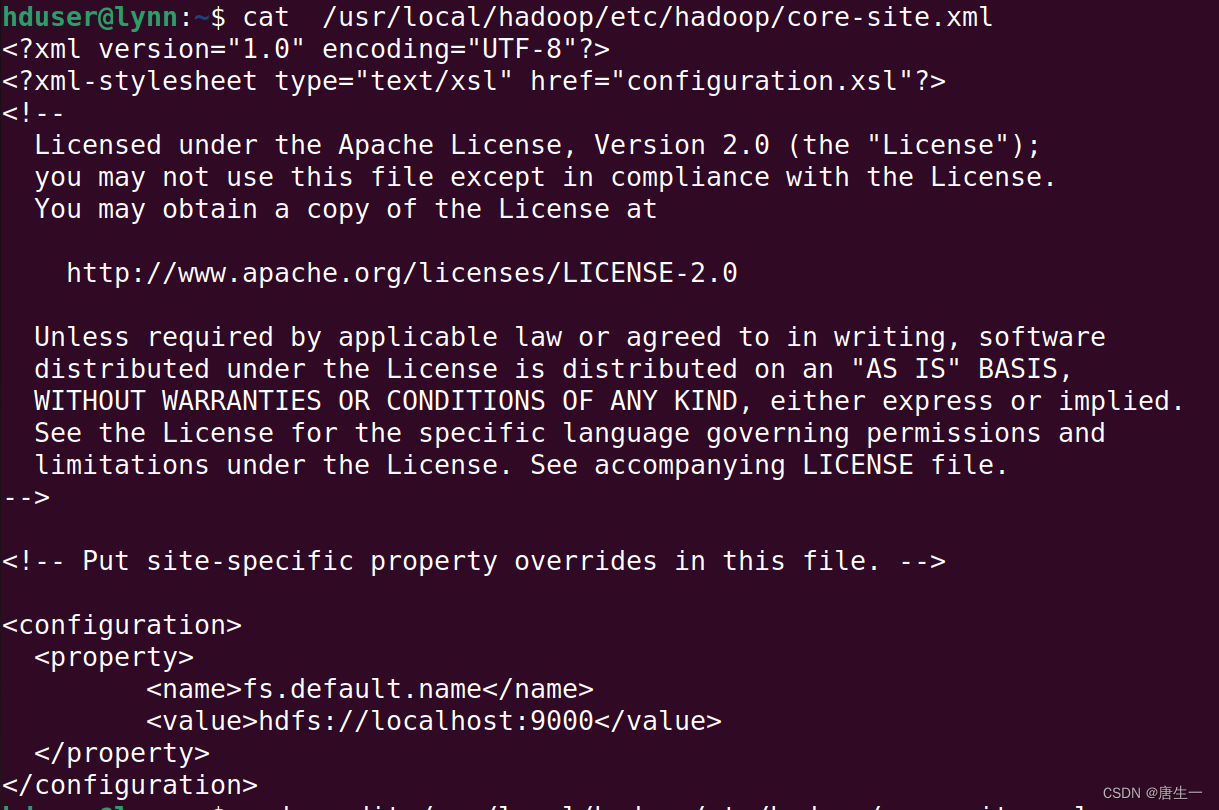
3.1.2 配置core-site.xml
设置HDFS的默认名称
hduser@lynn:~$ sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration><property><name>fs.default.name</name><value>hdfs://localhost:9000</value></property>
</configuration>
3.1.3 设置yarn-site.xml
hduser@lynn:~$ sudo gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value>
</property>
<property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
3.1.4 编辑mapred-site.xml
hduser@lynn:~$ sudo cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
hduser@lynn:~$ sudo gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
</configuration>
3.1.5 设置hdfs-site.xml
hdfs-site.xml 用于设置HDFS分布式文件系统的相关配置。Single Node Cluster中只有一台服务器,所以需要身兼NameNode和DataNode.
hduser@lynn:~$ sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration><property><!--设置备份数量为3--><name>dfs.replication</name><value>3</value> </property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value></property>
</configuration>
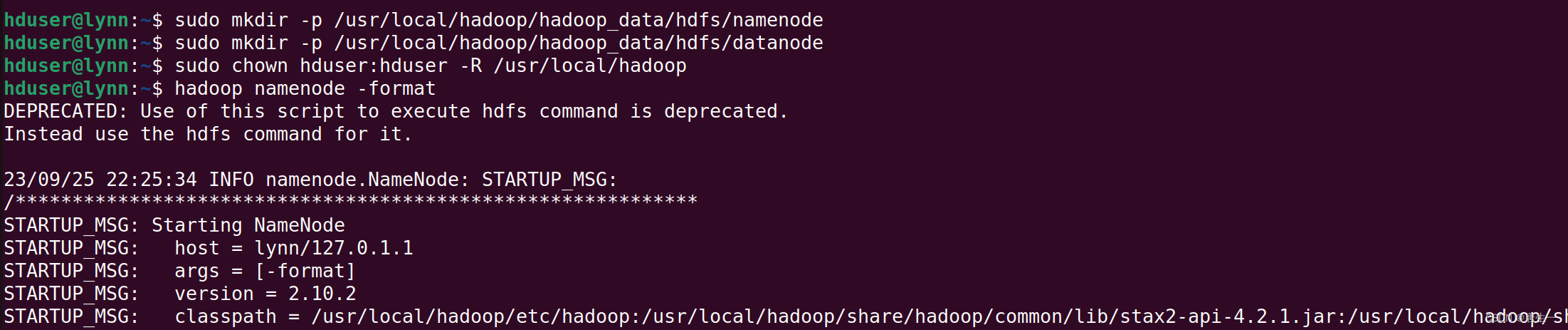
3.1.6 创建hdfs目录并格式化HDFS文件系统
# 创建NameNode数据存储目录
hduser@lynn:~$ sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
# 创建DataNode数据存储目录
hduser@lynn:~$ sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
# 将hadoop目录的所有者更改为hduser
hduser@lynn:~$ sudo chown hduser:hduser -R /usr/local/hadoop
# 格式化namenode-将HDFS格式化
hduser@lynn:~$ hadoop namenode -format
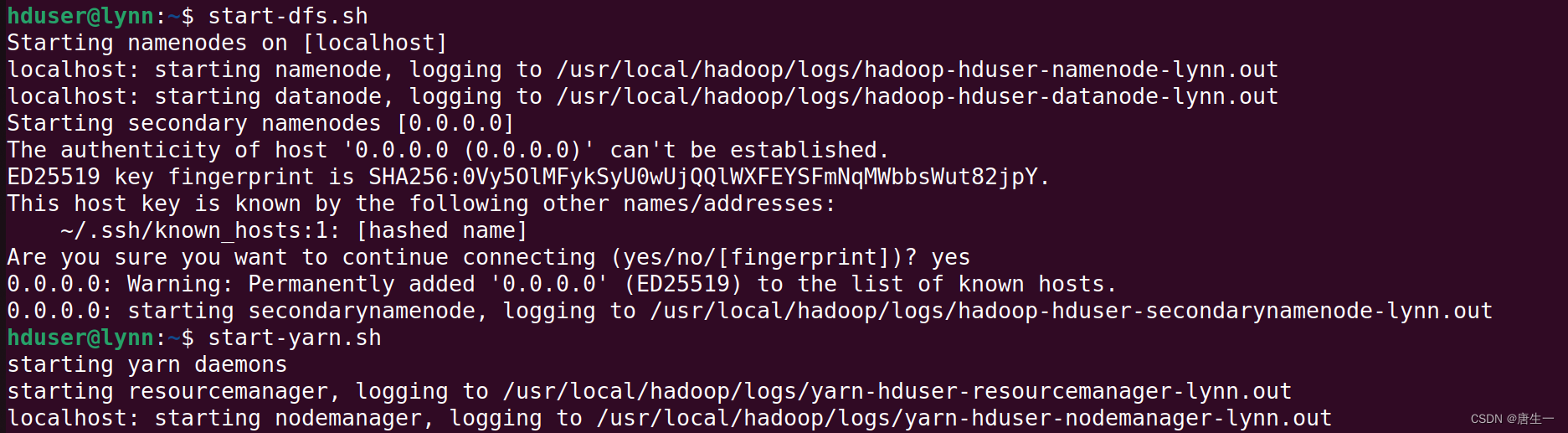
3.1.7 启动HDFS
# 启动hdfs
hduser@lynn:~$ start-dfs.sh
# 启动YARN
hduser@lynn:~$ start-yarn.sh
# jps可以列出运行的所有java虚拟机进程
hduser@lynn:~$ jps

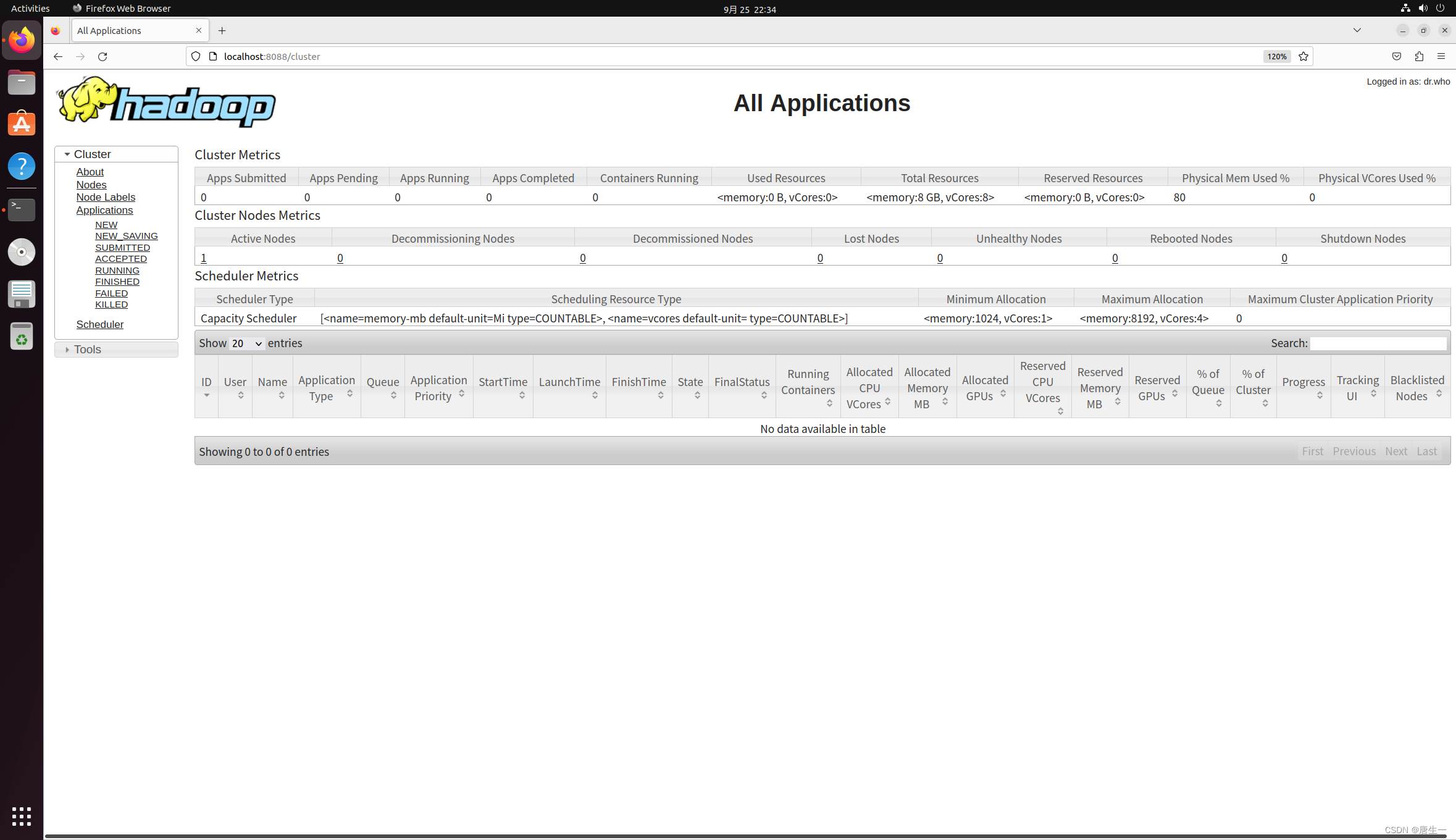
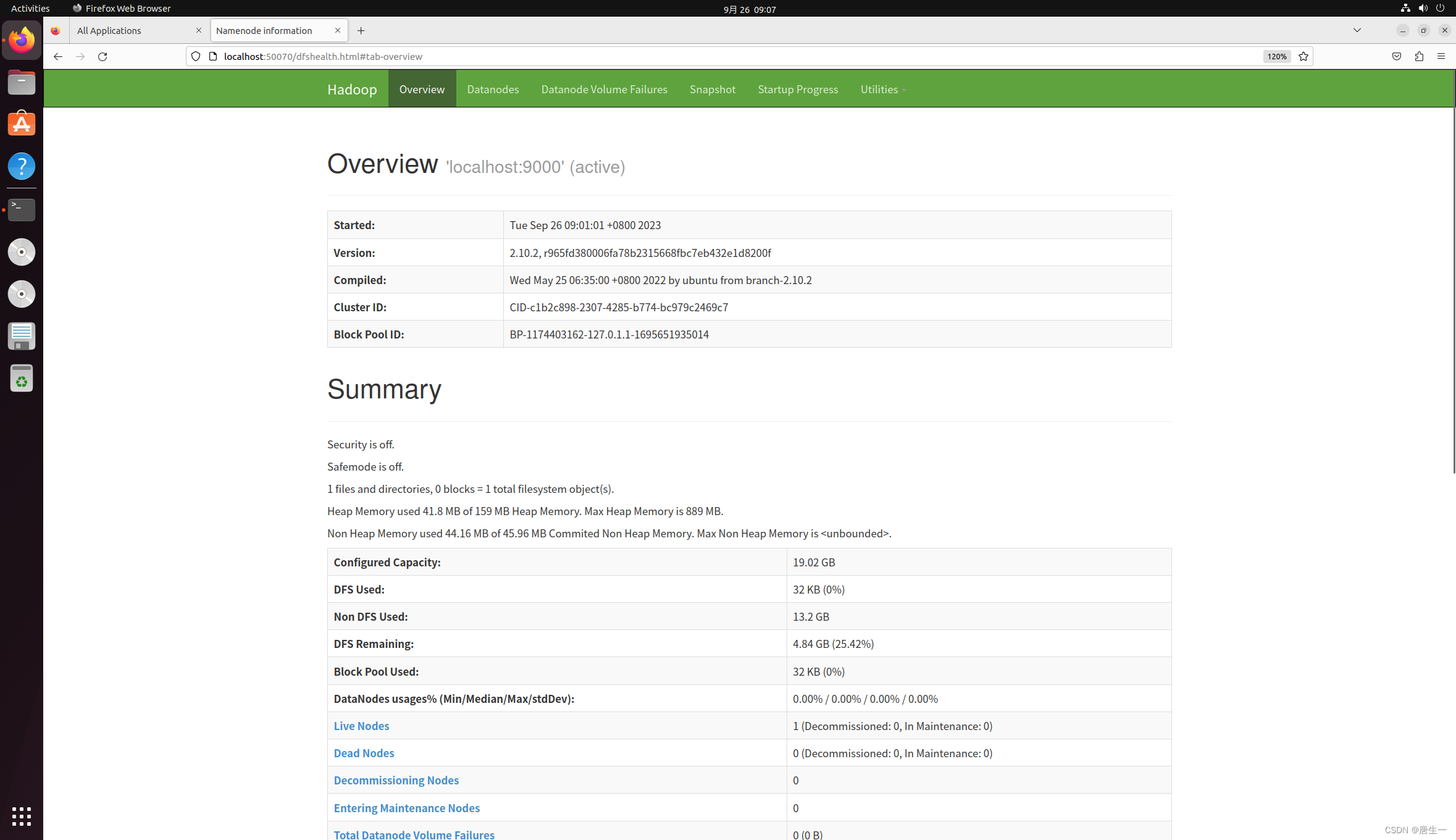
3.1.8 查看集群状态
http://localhost:8088
 http://localhost:50070
http://localhost:50070
3.2 集群分布方式
在真实的集群环境下安装运行hadoop系统,集群的每个节点可以运行linux.
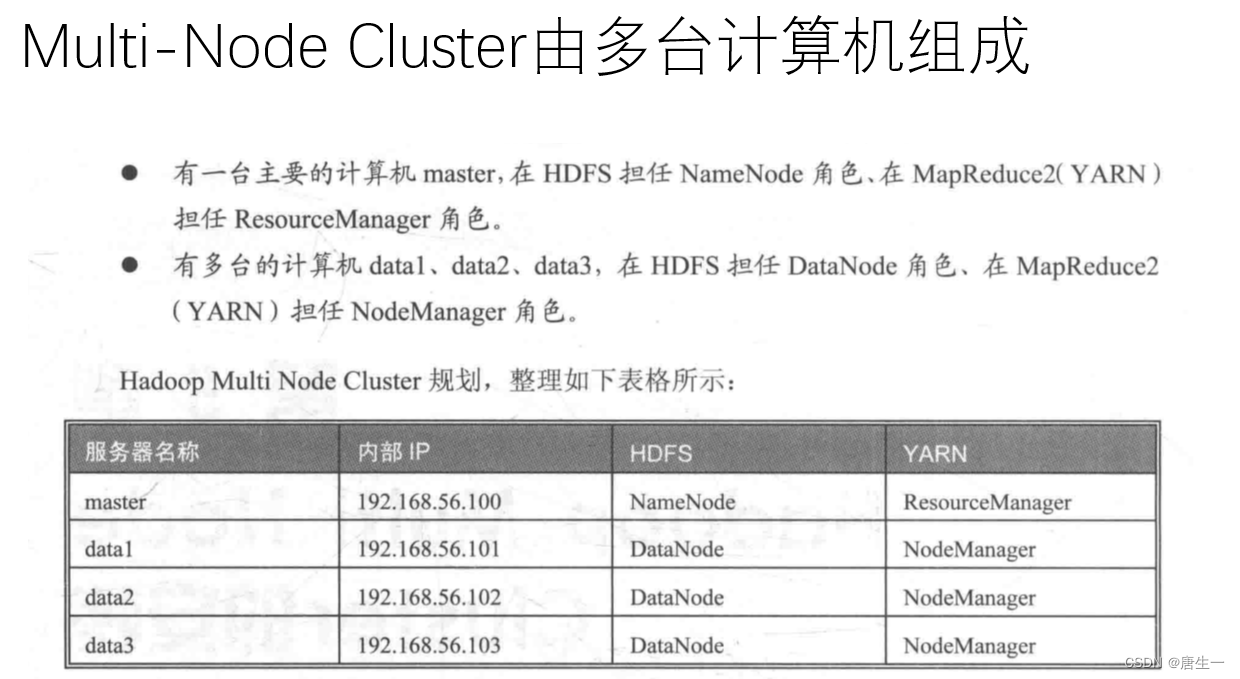
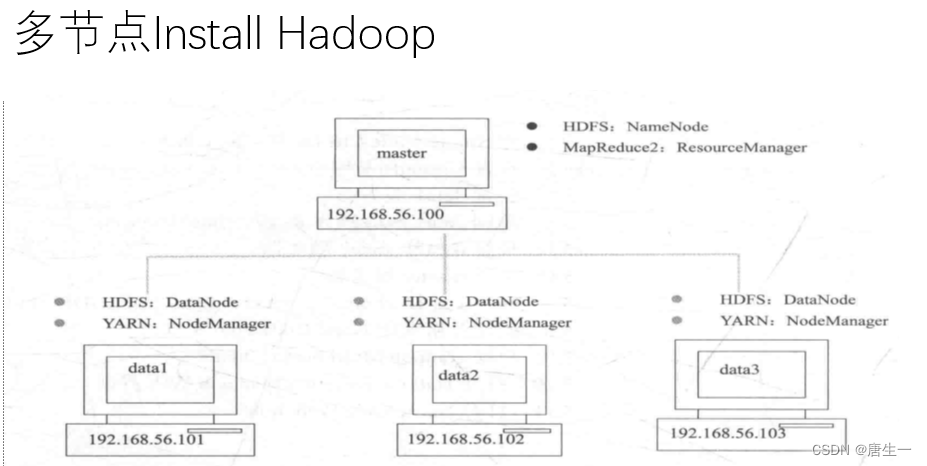
将在VMware上创建4台虚拟机,分别是master,data1,data2,data3
将在每一台虚拟机设置两张网卡:
- 网卡1:设置为NAT网卡,可以通过host主机连接到外部网络internet
- 网卡2:设置为“仅主机模式”,用于创建内部网络,内部网络连接4台虚拟主机与Host主机
- IP地址:master 192.168.56.100
data1 192.168.56.101
data2 192.168.56.102
data3 192.168.56.103
3.2.1 创建data1节点
从刚才创建的Single node clutch节点克隆出data1节点。选择创建完整克隆,命名为data1.
添加网卡
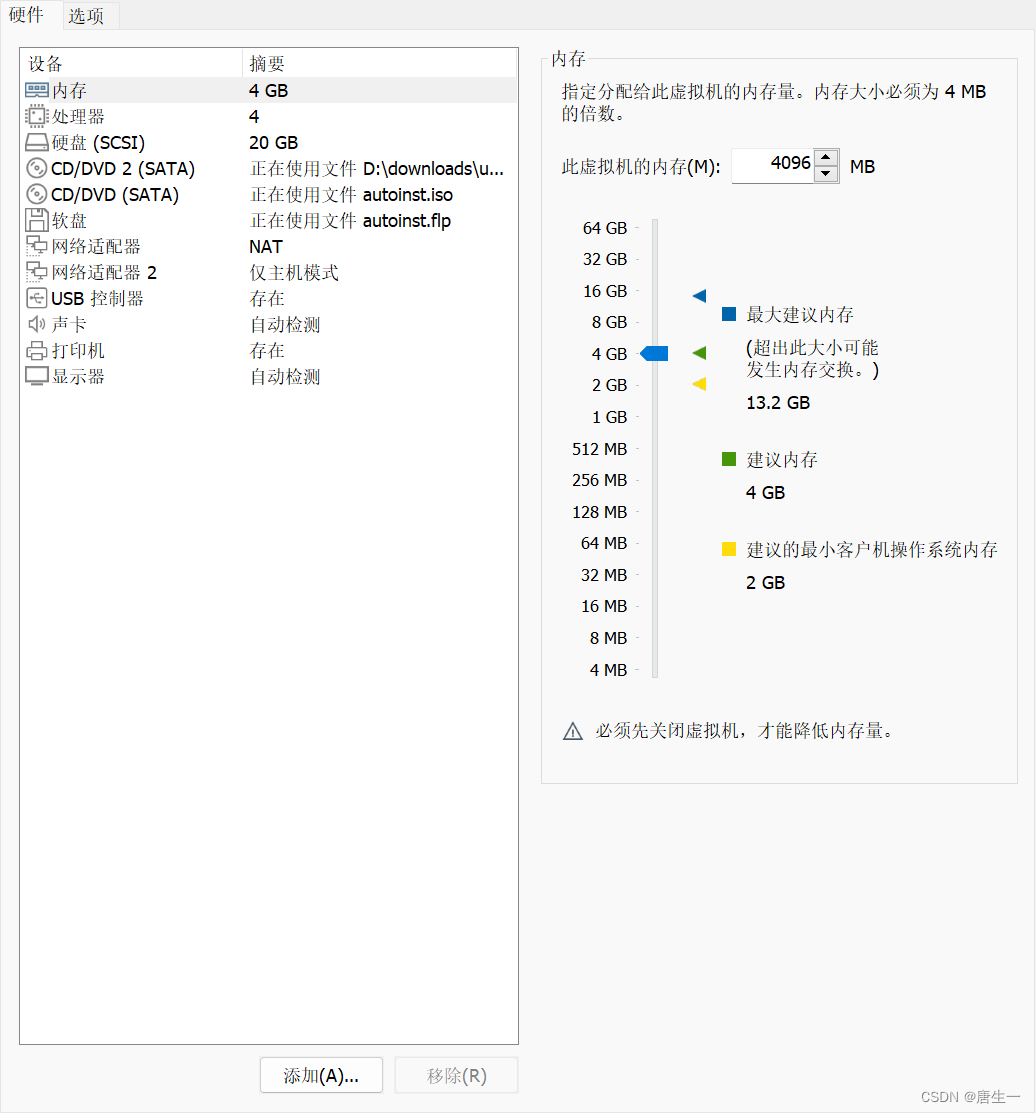
3.2.1.1 设置固定IP
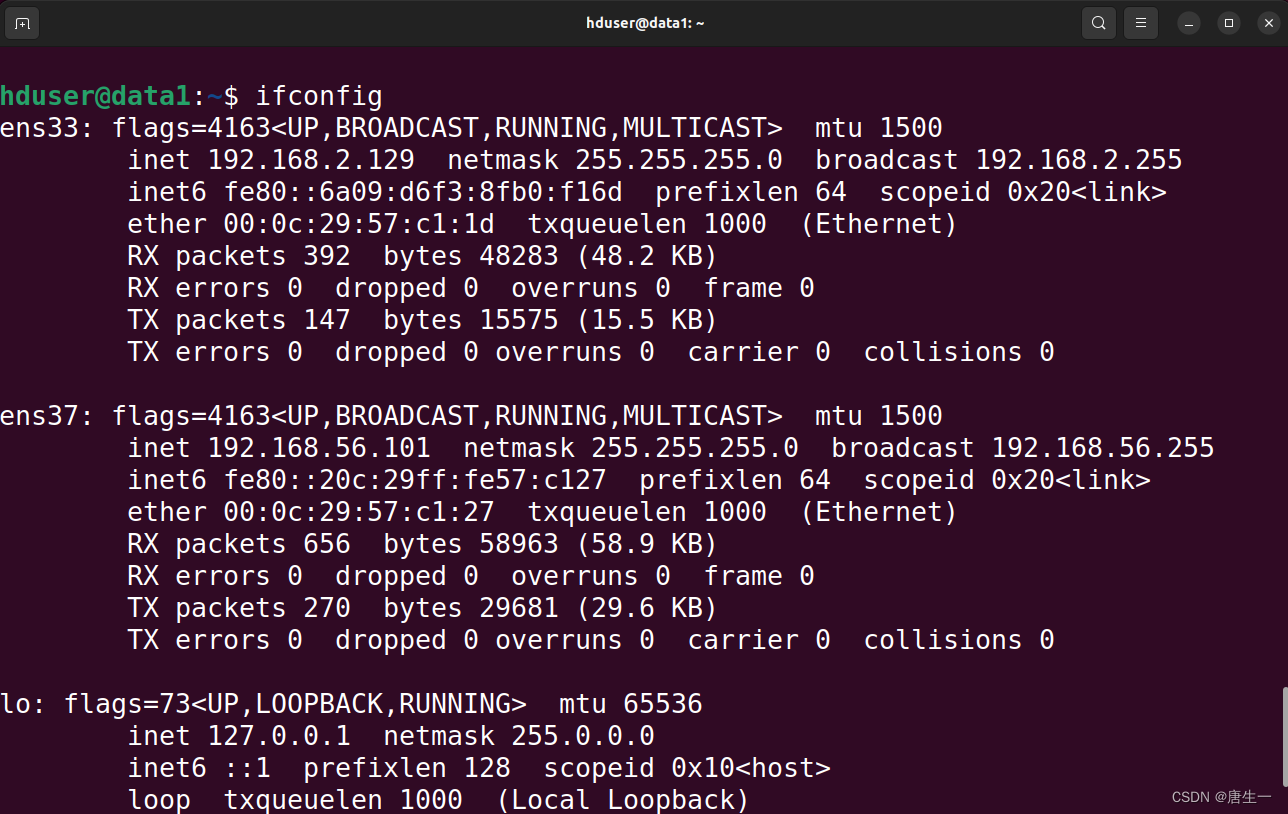
# 查看data1中的网卡
hduser@lynn:/$ ifconfig
# 显示分别是ens33,ens37
# ens33是ubuntu默认的NAT的网卡
# 对应我们集群使用的网卡为ens37
# 配置静态IP
hduser@lynn:/$ sudo gedit /etc/netplan/01-network-manager-all.yaml
network:ethernets:ens37:addresses: [192.168.56.101/24] # 注意冒号后面需要有空格dhcp4: nooptional: truegateway4: 192.168.56.1nameservers:addresses: [192.168.56.1,114.114.114.114] # 114.114.114.114是电信的version: 2renderer: NetworkManager
hduser@lynn:/$ sudo netplan apply
hduser@lynn:/$ ifconfig
3.2.1.2 编辑主机名和hosts文件
# 编辑hostname主机名 设置data1
hduser@lynn:/$ sudo gedit /etc/hostname
data1
# 编辑hosts文件
hduser@lynn:/$ sudo gedit /etc/hosts
192.168.56.100 master
192.168.56.101 data1
192.168.56.102 data2
192.168.56.103 data3
3.2.1.3 编辑core-site.xml,yarn-site.xml,mapred-site.xml,hdfs-site.xml
hduser@lynn:/$ sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml<configuration><property><name>fs.default.name</name><value>hdfs://master:9000</value></property>
</configuration>
hduser@lynn:/$ sudo gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml <configuration>
<!--设置ResouceManager主机与NodeManager的连接地址,NodeManager通过这个地址向ResourceManager汇报运行情况-->
<property><name>yarn.resourcemanager.resource-tracker.address</name><value>master:8025</value></property><!--设置ResourceManager与ApplicationMaster的连接地址,ApplicationMaster通过这个地址向ResourceManager申请资源、释放资源等--><property><name>yarn.resourcemanager.scheduler.address</name><value>master:8030</value></property>
<!--设置ResourceManager与客户端的连接地址,客户端通过该地址ResourceManger注册应用程序、删除程序等--><property><name>yarn.resourcemanager.address</name><value>master:8050</value></property>
</configuration>
hduser@lynn:/$ sudo gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml
# mapred-site.xml用于设置监控Map与Reduce程序的JobTracker任务分配情况,以及TaskTracker任务运行状况
# 修改设置mapreduce.job.tracker的连接地址为master:54311<configuration>
<property><name>mapred.job.tracker</name><value>master:54311</value>
</property>
</configuration>
hduser@lynn:/$ sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>3</value> </property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value></property>
</configuration>
3.2.2 创建data2,data3,master节点
克隆data1到data2,data3,master
3.2.2.1 分别设置每个主机的固定IP
hduser@data1:/$ sudo gedit /etc/netplan/01-network-manager-all.yamlens37:# 只需要更改此处的IP地址,data2为192.168.56.102# data3为192.168.56.103# master为192.168.56.100addresses: [192.168.56.102/24]dhcp4: nooptional: true
# 使设置生效
hduser@data1:/$ sudo netplan apply
# 查看网卡信息,确认ip地址无误
hduser@data1:/$ ifconfig
3.2.2.2 设置每个主机的主机名
# data2设置为data2;data3设置为data3,master设置为master
hduser@data1:/$ sudo gedit /etc/hostname
3.2.3 设置master服务器
3.2.3.1 设置hdfs-site.xml
因为master现在只是单纯的NameNode,删除DataNode的HDFS设置
hduser@master:~$ sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>3</value> </property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value></property>
</configuration>
3.2.3.2 编辑masters文件和slaves文件
masters文件主要是告诉hadoop系统哪一台服务器是NameNode.
slaves文件主要是告诉hadoop系统哪些服务器是DataNode.
hduser@master:~$ sudo gedit /usr/local/hadoop/etc/hadoop/masters
master
hduser@master:~$ sudo gedit /usr/local/hadoop/etc/hadoop/slaves
data1
data2
data3
3.2.4 测试
- 启动master,data1,data2,data3四个节点
- 从master主机连接到data1
hduser@master:~$ ssh data1
- 创建HDFS目录datanode,对data2及data3重复此操作.
hduser@data1:~$ sudo rm -rf /usr/local/hadoop/hadoop_data/hdfs/
[sudo] password for hduser:
hduser@data1:~$ mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
hduser@data1:~$ sudo chown -R hduser:hduser /usr/local/hadoop
hduser@data1:~$ exit
logout
Connection to data1 closed.
- 重新创建并格式化NameNode HDFS目录
# 创建NameNode目录
hduser@master:~$ sudo rm -rf /usr/local/hadoop/hadoop_data/hdfs
[sudo] password for hduser:
hduser@master:~$ mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
hduser@master:~$ sudo chown -R hduser:hduser /usr/local/hadoop
# 格式化
hduser@master:~$ hdfs namenode -format
- 启动hadoop multinode cluster
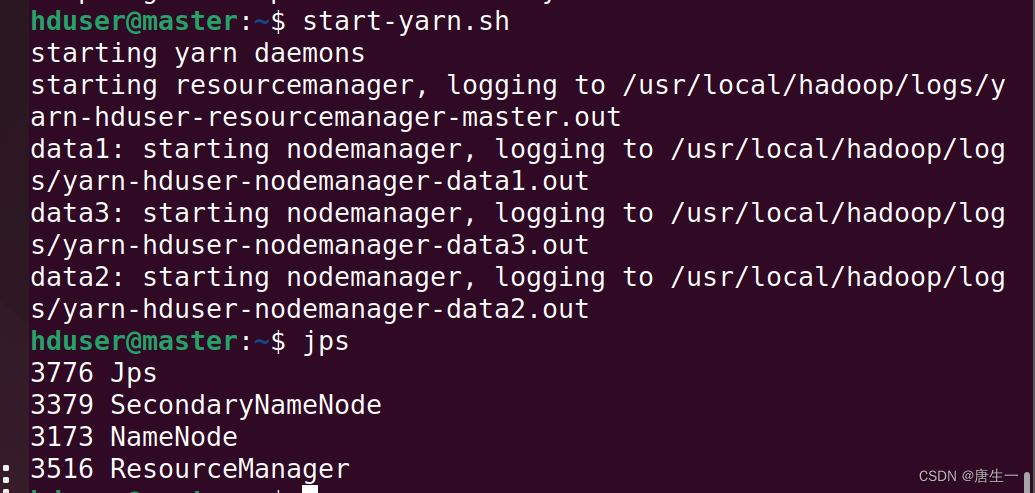
hduser@master:~$ start-dfs.sh
hduser@master:~$ start-yarn.sh
hduser@master:~$ jps
- 可以看见master服务器的状态:
HDFS功能:Namenode,SecondaryNameNode
MapReduce2(YARN): ResourceManager
- 查看数据服务器节点data1(DataNode)进程的状态
在data1的终端上输入jps
HDFS:DataNode
MapReduce2(YARN
: NodeManager

- 打开Hadoop ResouceManager Web界面 http://master:8088
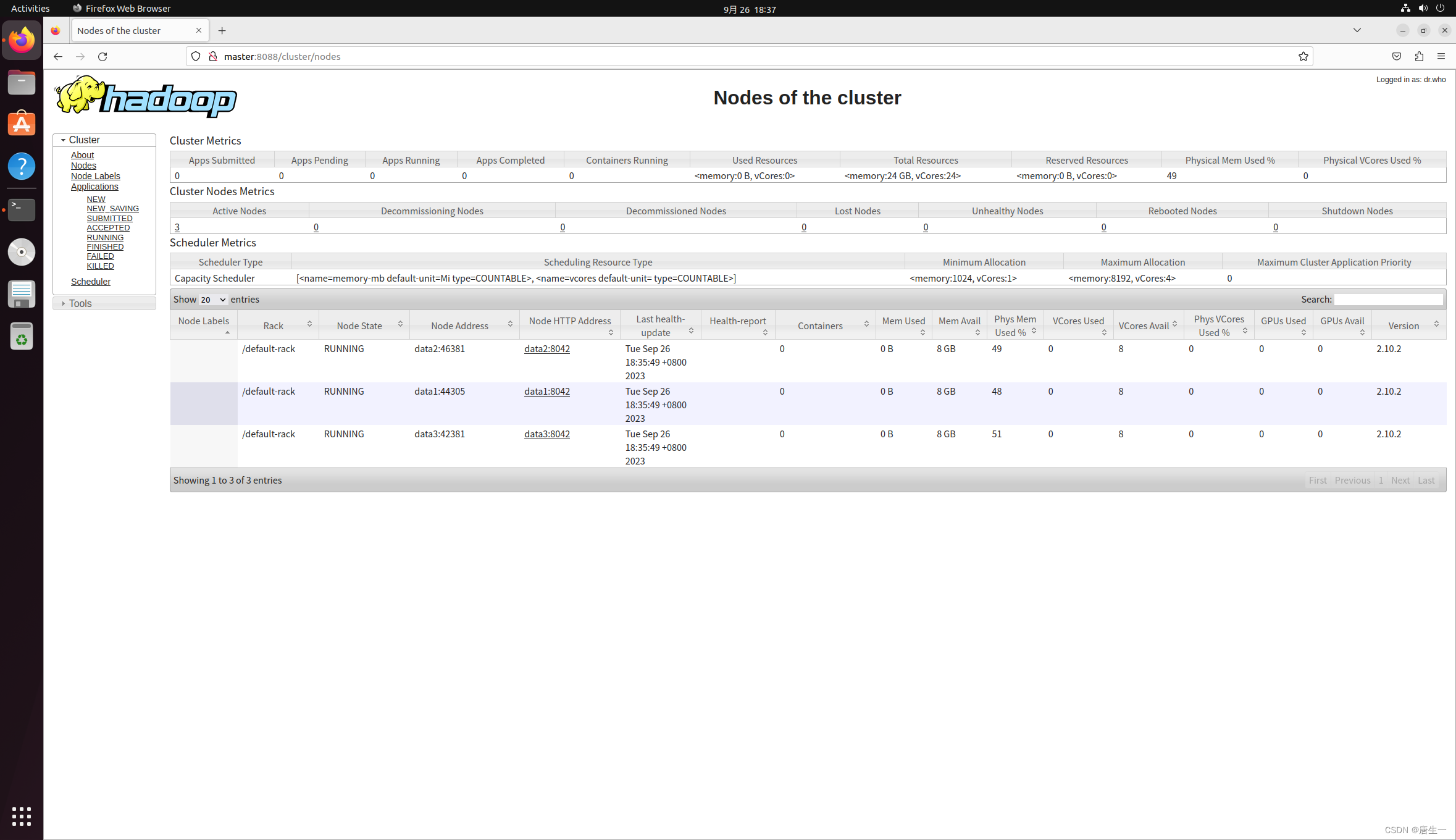
- 打开NameNode Web界面 http://master:50070/
相关文章:
【大数据存储与处理】1. hadoop单机伪分布安装和集群安装
0. 写在前面 0.1 软件版本 hadoop2.10.2 ubuntu20.04 openjdk-8-jdk 0.2 hadoop介绍 Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个…...

linux通过time命令统计代码编译时间
首先编写一个编译脚本 build.sh 内容如下: 然后执行time sh build.sh 编译完成后输出三个时间 time sh xxx.sh # 会返回3个时间数据 (1) real:从进程 ls 开始执行到完成所耗费的 CPU 总时间。该时间包括 ls 进程执行时实际使用的 CPU 时间,…...

logback日志是怎么保证多线程输出日志线程安全的
logback中的单例模式 logback日志框架使用了单例设计模式来进行日志输出。在logback中,Logger类是一个关键的组件,它负责记录和输出日志消息。 Logger类使用了单例设计模式,确保在一个应用程序中只存在一个Logger实例。这样做的好处是可以确…...

2022年统计用区划代码表SQL 01
行政区划代码为国家公布的六位县级以上行政区划代码 行政区编码的用途: APP里做城市级联选择根据身份证前六位获取用户所在城市区县 370786 昌邑市 370800 济宁市 370811 任城区 370812 兖州区 百度高德等接口通常都会返回adcode字段 (行政区编码)根据 行政区编…...

EM@基本初等函数@幂和根式@指数函数
abstract 基本初等函数幂和根式指数函数 指数和幂 正整指数幂 a n a^{n} an a ⋯ a ⏟ n 个 \underbrace{a\cdots{a}}_{n个} n个 a⋯a, n ∈ N n\in\mathbb{N^{}} n∈N 其中 a n a^{n} an称为** a a a的 n n n次幂** a a a叫做幂的底数, n n n叫做幂的指数 正整指数…...

时序预测 | MATLAB实现NGO-GRU北方苍鹰算法优化门控循环单元时间序列预测
时序预测 | MATLAB实现NGO-GRU北方苍鹰算法优化门控循环单元时间序列预测 目录 时序预测 | MATLAB实现NGO-GRU北方苍鹰算法优化门控循环单元时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 MATLAB实现NGO-GRU北方苍鹰算法优化门控循环单元时间序列预测&#…...

element 二次确认框,内容自定义处理
上代码: async inspectionTypeOff(row) {console.log(row.id);let taskArray await this.getTaskList(row.id); // 查询关联的任务console.log("taskArray", taskArray);let messageTip taskArray.length > 0? <div><p>确认禁用巡检项&…...

【软件设计师-中级——刷题记录4(纯干货)】
目录 进度管理工具Grantt图:程序语言基础:高级语言源程序模式: 每日一言:持续更新中... 个人昵称:lxw-pro 个人主页:欢迎关注 我的主页 个人感悟: “失败乃成功之母”,这是不变的道理…...

9.24 校招 实习 内推 面经
绿泡*泡: neituijunsir 交流裙 ,内推/实习/校招汇总表 1、自动驾驶一周资讯 - 小马智行在京开展“车内无人”出行服务商业化试点,余承东将升任车BU董事长 自动驾驶一周资讯 - 小马智行在京开展“车内无人”出行服务商业化试点࿰…...
持续更新)
第二章:25+ Python 数据操作教程(第二十五节用 PYTHON 和 R 制作祝福圣诞节)持续更新
这篇文章献给所有 Python 和 R 编程爱好者...通过以下程序在同行中炫耀您的知识。作为一名数据科学专业人士,您希望自己的愿望在圣诞节前夕变得特别。如果您观察代码,您还可以学到 1-2 个技巧,您可以在以后的日常任务中使用这些技巧。 方法 1:运行以下程序,看看我的意思 R…...
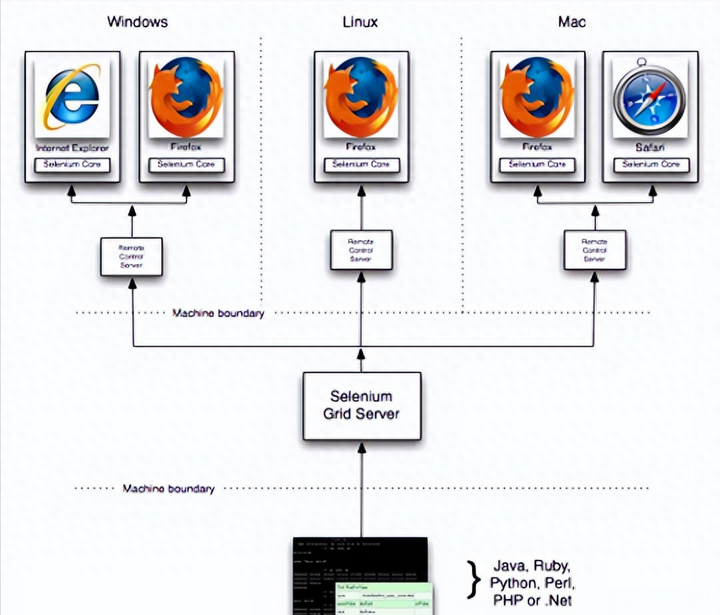
你是怎么理解自动化测试的?理解自动化测试的目的和本质
其实自动化测试很好理解,由两部分组成,“自动化”和“测试”,所以我们要理解自动化测试,就必须理解“自动化”和“测试”,只有理解了这些概念,才能更轻松的做好的自动化测试。其中“自动化”可以想象成通过…...

二十六、MySQL并发事务问题:脏读/不可重复读/幻读
1、事务的隔离级别 (1)隔离级别 Read uncommitted # 读,未提交 Read committed # 读,已提交 Repeatable Read(默认) # 可重复读 Serializable # 串读 (2)基础语法 set transaction isolation level 事…...

RK3588平台开发系列讲解(项目篇)视频监控之RTMP推流
文章目录 一、RTMP协议是什么二、RTMP 的原理三、Nginx 流媒体服务器四、FFmpeg 推流沉淀、分享、成长,让自己和他人都能有所收获!😄 📢 目前常见的视频监控和视频直播都是使用了 RTMP、RTSP、HLS、MPEG-DASH、WebRTC流媒体传输协议等。 视频监控项目组成,分为三部分:…...
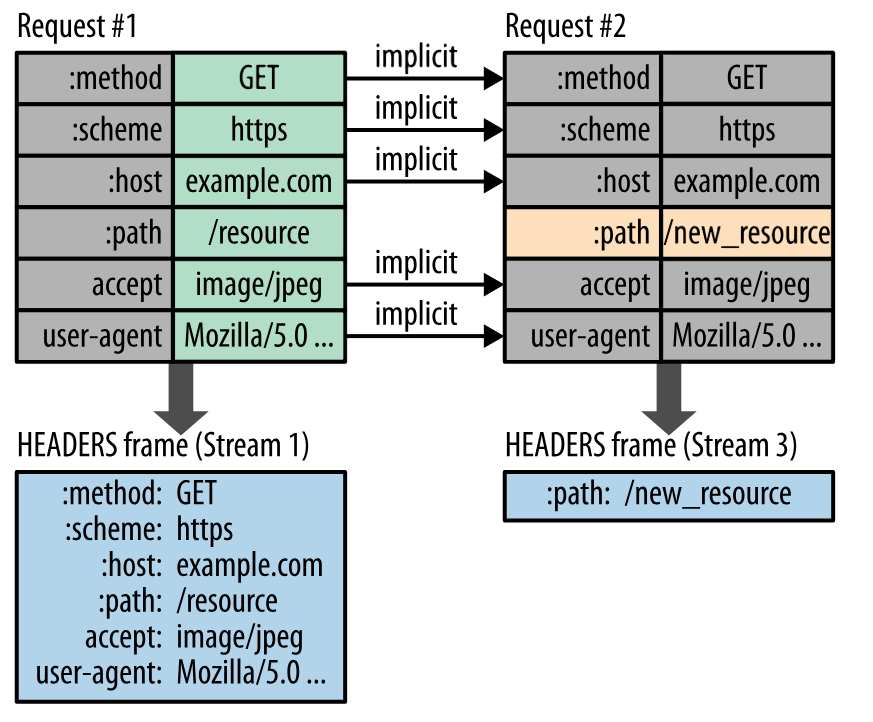
http基础教程(超详细)
HTTP HTTP 一 、基础概念 请求和响应报文URL 二、HTTP 方法 GETHEADPOSTPUTPATCHDELETEOPTIONSCONNECTTRACE 三、HTTP 状态码 1XX 信息2XX 成功3XX 重定向4XX 客户端错误5XX 服务器错误 四、HTTP 首部 通用首部字段请求首部字段响应首部字段实体首部字段 五、具体应用 连接管理…...

Vue3 <script setup> 单文件组件 组合式 API 相关语法
1.vue3使用vuex <script setup> import {ref} from "vue" import {useStore} from "vuex"//获取store const storeuseStore(); const count ref(0); //获取store状态 const type store.state.type //给count赋值 count.value1;</script>2.vue…...
为什么说网络安全是IT行业最后的红利?是风口行业?
前言 “没有网络安全就没有国家安全”。当前,网络安全已被提升到国家战略的高度,成为影响国家安全、社会稳定至关重要的因素之一。 网络安全行业特点 1、就业薪资非常高,涨薪快 2021年猎聘网发布网络安全行业就业薪资行业最高人均33.77万…...

DD5 进制转换
目录 一、题目 二、分析 三、代码 一、题目 进制转换_牛客题霸_牛客网 二、分析 三、代码 #include <iostream> #include <vector> #include <string> using namespace std; string Greater_than_Ten(int digit)//余数大于等于10的时候转换成对应的字母…...
之数据库提权-MySQL MOF提权)
操作系统权限提升(二十七)之数据库提权-MySQL MOF提权
MySQL MOF提权 MOF介绍 mof是windows系统的一个“托管对象格式”文件(位置:C:/windows/system32/wbem/mof/),其作用是每隔五秒就会去监控进程创建和死亡,mof目录下有两个文件夹(good与bad)。Windows server 2003及以下系统每5秒会执行一次mof目录下的文件,执行成功会…...

springcloud:四、nacos介绍+启动+服务分级存储模型/集群+NacosRule负载均衡
nacos介绍 nacos是阿里巴巴提供的SpringCloud的一个组件,算是eureka的替代品。 nacos启动 安装过程这里不再赘述,相关安装或启动的问题可以见我的另一篇博客: http://t.csdn.cn/tcQ76 单价模式启动命令:进入bin目录࿰…...
人生第一个java项目 学生管理系统
开始编程 建类 开始主要部分 main()部分 方法部分...

网盘下载新革命:九大平台一键直链,告别客户端束缚
网盘下载新革命:九大平台一键直链,告别客户端束缚 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

对比直接使用厂商 API 体验 Taotoken 在模型切换上的便利性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 体验 Taotoken 在模型切换上的便利性 在个人开发项目中接入大模型时,开发者通常面临一个选择&am…...

GARbro:跨平台视觉小说游戏资源解析与提取工具
GARbro:跨平台视觉小说游戏资源解析与提取工具 【免费下载链接】GARbro Visual Novels resource browser 项目地址: https://gitcode.com/gh_mirrors/ga/GARbro GARbro是一款专门用于解析和提取视觉小说游戏资源文件的跨平台开源工具,支持数百种游…...

3个按键冲突场景,Hitboxer如何帮你重获游戏控制权?
3个按键冲突场景,Hitboxer如何帮你重获游戏控制权? 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在激烈的游戏对战中,因为同时按下W和S键而突然卡住?或…...

在线Graphviz图表编辑器:3步创建专业技术流程图
在线Graphviz图表编辑器:3步创建专业技术流程图 【免费下载链接】GraphvizOnline Lets Graphviz it online 项目地址: https://gitcode.com/gh_mirrors/gr/GraphvizOnline 还在为复杂的技术图表绘制而烦恼吗?GraphvizOnline作为一款革命性的在线G…...

轻量级监控系统Monikhao:自托管部署与核心架构解析
1. 项目概述:一个轻量级、可自托管的监控解决方案最近在折腾个人服务器和家庭网络监控时,发现了一个挺有意思的项目:khaodius/monikhao。乍一看这个名字,可能会觉得有点陌生,但如果你对自建监控系统有需求,…...

英雄联盟智能助手Seraphine:告别手动查询,实现高效游戏决策自动化
英雄联盟智能助手Seraphine:告别手动查询,实现高效游戏决策自动化 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟排位赛中,你是否曾因错过接受对局而懊恼不已&a…...

从零构建团队技能仓库:结构化知识管理与VuePress实践
1. 项目概述:一个技能仓库的诞生与价值 最近在整理团队内部的技术资产时,我一直在思考一个问题:如何让那些散落在个人笔记、项目代码片段、会议纪要里的“隐性知识”和“最佳实践”沉淀下来,变成团队可复用、可传承的“显性资产”…...

如何3步获取百度网盘真实下载地址实现满速下载
如何3步获取百度网盘真实下载地址实现满速下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾被百度网盘的非会员下载速度困扰?当下载重要的工作文件、学…...

【2026最新】鸿蒙NEXT ArkUI实战:培训班管理系统UI界面开发全攻略
鸿蒙UI开发总是踩坑?ArkUI组件用法记不住?本文用15分钟带你彻底搞懂ArkUI核心组件、布局系统、自定义组件和交互动画,附完整培训班管理系统实战代码和踩坑记录,让你的鸿蒙App界面从此丝滑流畅!一、培训班管理界面设计1…...