NPU上PyTorch模型训练问题案例
在昇腾AI处理器上训练PyTorch框架模型时,可能由于环境变量设置问题、训练脚本代码问题,导致打印出的堆栈报错与实际错误并不一致、脚本运行异常等问题,那么本期就分享几个关于PyTorch模型训练问题的典型案例,并给出原因分析及解决方法:
1、在训练模型时报错“Inner Error xxxx”,但打印的堆栈报错信息与实际错误无关
2、在模型训练时报错“terminate called after throwing an instance of 'c10::Error' what(): 0 INTERNAL ASSERT”
3、在模型训练时报错“MemCopySync:drvMemcpy failed.”
01 在训练模型时报错“Inner Error xxxx”,但打印的堆栈报错信息与实际错误无关
问题现象描述
报错截图举例:
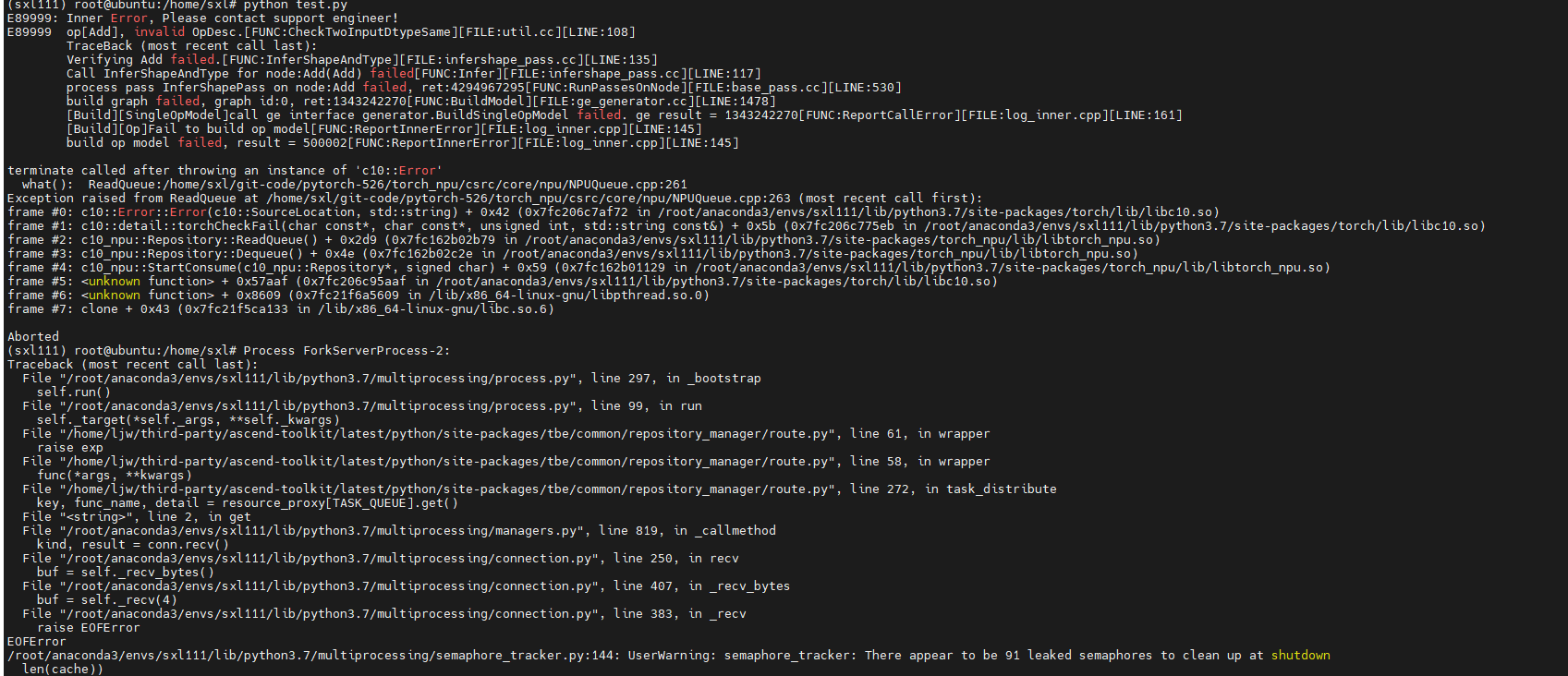
原因分析
NPU模型训练时默认为异步运行,因此打印出的堆栈报错与实际错误并不一致。如果想要打印出与实际错误相对应的堆栈报错信息,需要修改环境变量将运行模式改为同步运行。
解决措施
可以在以下方案中选择一种来解决该问题,然后再次运行模型,即可得到与实际错误一致的堆栈报错信息:
1、将环境变量TASK_QUEUE_ENABLE设置为0:
export TASK_QUEUE_ENABLE=02、若用户使用的PyTorch为2.1版本,也可将环境变量ASCEND_LAUNCH_BLOCKING修改为为1:
export ASCEND_LAUNCH_BLOCKING=102 在模型训练时报错“terminate called after throwing an instance of 'c10::Error' what(): 0 INTERNAL ASSERT”
问题现象描述
报错示例如下:
terminate called after throwing an instance of 'c10::Error' what(): 0 INTERNAL ASSERT FAILED at /***/pytorch/c10/npu/NPUStream.cpp:146, please report a bug to PyTorch. Could not compute stream ID for Oxffff9f77fd28 on device -1 (something has gone horribly wrong!) (NPUStream_getStreamId at /***/pytorch/c10/npu/NPUStream.cpp:146
frame #0: c10::Error::Error(c10::SourceLocation, std::__cxxll::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) + 0x74 (0xffffa0c11fe4 in /usr/local/lib64/python3.7/site.packages/torch/lib/libc10.so)原因分析
执行代码后出现报错。
import torch
import torch_npu
def test_cpu(): input = torch.randn(2000, 1000).detach().requires_grad_() output = torch.sum(input) output.backward(torch.ones_like(output))
def test_npu(): input = torch.randn(2000, 1000).detach().requires_grad_().npu() output = torch.sum(input) output.backward(torch.ones_like(output))
if __name__ == "__main__": test_cpu() torch_npu.npu.set_device("npu:0") test_npu()在运行backward运算时,若没有设置device,程序会自动默认初始化device为0,相当于执行了set_device("npu:0")。由于目前不支持切换device进行计算,若再通过set_decice()方法手动设置device设备,则可能出现该错误。
解决措施
在运行backward运算前,通过set_decice()方法手动设置device。
原代码如下:
if __name__ == "__main__":
test_cpu()
torch_npu.npu.set_device("npu:0")
test_npu()
修改后代码如下:
if __name__ == "__main__":
torch_npu.npu.set_device("npu:0")
test_cpu()
test_npu()
03 在模型训练时报错“MemCopySync:drvMemcpy failed.”
问题现象描述
- shell脚本报错信息如下:
RuntimeError: Run:/usr1/workspace/PyTorch_Apex_Daily_c20tr5/CODE/aten/src/ATen/native/npu/utils/OpParamMaker.h:280 NPU error,NPU error code is:500002
[ERROR] RUNTIME(160809)kernel task happen error, retCode=0x28, [aicpu timeout].
[ERROR] RUNTIME(160809)aicpu kernel execute failed, device_id=0, stream_id=512, task_id=24, fault so_name=, fault kernel_name=, extend_info=.
Error in atexit._run_exitfuncs:
Traceback (most recent call last):
File "/usr/local/python3.7.5/lib/python3.7/site-packages/torch/__init__.py", line 429, in _npu_shutdown torch._C._npu_shutdown()
RuntimeError: npuSynchronizeDevice:/usr1/workspace/PyTorch_Apex_Daily_c20tr5/CODE/c10/npu/NPUStream.cpp:806 NPU error, error code is 0- 日志报错信息如下:
[ERROR] RUNTIME(12731,python3.7):2021-02-02-22:23:56.475.679 [../../../../../../runtime/feature/src/npu_driver.cc:1408]12828 MemCopySync:drvMemcpy failed: dst=0x108040288000, destMax=1240, src=0x7fe7649556d0, size=1240, kind=1, drvRetCode=17!
[ERROR] RUNTIME(12731,python3.7):2021-02-02-22:23:56.475.698 [../../../../../../runtime/feature/src/logger.cc:113]12828 KernelLaunch:launch kernel failed, kernel=140631803535760/ArgMinWithValue_tvmbin, dim=32, stream=0x55b22b3def50
[ERROR] RUNTIME(12731,python3.7):2021-02-02-22:23:56.475.717 [../../../../../../runtime/feature/src/api_c.cc:224]12828 rtKernelLaunch:ErrCode=207001, desc=[module new memory error], InnerCode=0x70a0002原因分析
样例脚本如下:
import torch
import torch_npu
def test_sum(): xs_shape = [22400, 8] ys_shape = [22400, 8] gt_bboxes_shape = [22400, 8,4] xs = torch.rand(xs_shape).npu() ys = torch.rand(ys_shape).npu() gt_bboxes = torch.rand(gt_bboxes_shape).npu().half() left = xs - gt_bboxes[..., 0] right = gt_bboxes[..., 2] - xs top = ys - gt_bboxes[..., 1] bottom = gt_bboxes[..., 3] - ys # stream = torch_npu.npu.current_stream() # stream.synchronize() # left, top 结果是fp32, right, bottom 结果是fp16, # print(left.dtype, top.dtype, right.dtype, bottom.dtype) bbox_targets = torch.stack((left, top, right, bottom), -1) #报错位置在这里 # stream.synchronize() bbox_targets = torch.sum(bbox_targets)根据shell和日志报错信息,两者报错信息不匹配。shell报错是在同步操作中和AI CPU错误,而日志报错信息却是在min算子(内部调用ArgMinWithValue_tvmbin),二者报错信息不对应。一般这类问题出现的原因是由于日志生成的报错信息滞后。报错信息滞后可能是由于AI CPU算子的异步执行,导致报错信息滞后。
解决措施
对于该报错需要根据实际的错误来定位,可参考如下步骤进行处理:
1、通过关闭多任务算子下发后,发现结果不变,推断在shell脚本报错位置和日志报错算子之前就已出现错误。
2、根据报错加上stream同步操作,缩小错误范围,定位错误算子。stream同步操作的作用在于其要求代码所运行到的位置之前的所有计算必须为完成状态,从而定位错误位置。
3、通过在代码中加上stream同步操作,确定报错算子为stack。
4、打印stack所有参数的shape、dtype、npu_format,通过构造单算子用例复现问题。定位到问题原因为减法计算输入参数数据类型不同,导致a - b和b - a结果的数据类型不一致,最终在stack算子中报错。
5、将stack入参数据类型转换为一致即可临时规避问题。
相关文章:
NPU上PyTorch模型训练问题案例
在昇腾AI处理器上训练PyTorch框架模型时,可能由于环境变量设置问题、训练脚本代码问题,导致打印出的堆栈报错与实际错误并不一致、脚本运行异常等问题,那么本期就分享几个关于PyTorch模型训练问题的典型案例,并给出原因分析及解决…...

出现 conda虚拟环境默认放在C盘 解决方法
目录 1. 问题所示2. 原理分析3. 解决方法3.1 方法一3.2 方法二1. 问题所示 通过conda配置虚拟环境的时候,由于安装在D盘下,但是配置的环境默认都给我放C盘 通过如下命令:conda env list,最后查看该环境的确在C盘下 2. 原理分析 究其根本原因,这是因为默认路径没有足够的…...

Ubuntu Postgresql开机自启动服务
1. 建立service文件 sudo vim /etc/systemd/system/postgresql.service2. postgresql service文件 [Unit] DescriptionPostgreSQL 14 database server Documentationman:postgres(1) Documentationhttp://www.postgresql.org/docs/14/static/ Afternetwork.target[Service] T…...

COTS即Commercial Off-The-Shelf 翻译为“商用现成品或技术”或者“商用货架产品”
COTS 使用“不再做修理或改进”的模式出售的商务产品 COTS即Commercial Off-The-Shelf 翻译为“商用现成品或技术”或者“商用货架产品”,指可以采购到的具有开放式标准定义的接口的软件或硬件产品,可以节省成本和时间。 中文名 商用现成品或技术 外文…...
idea开发Springboot出租车管理系统VS开发mysql数据库web结构java编程计算机网页源码maven项目
一、源码特点 springboot 出租车管理系统是一套完善的完整信息系统,结合springboot框架和bootstrap完成本系统,对理解JSP java编程开发语言有帮助系统采用springboot框架(MVC模式开发), 系统具有完整的源代码和数据…...

Linux nohup
nohup 命令用于在 Linux 中将命令或程序在后台运行,并且在终端关闭后仍然保持运行。 nohup命令 描述 nohup 命令用于将命令或程序以不受终端挂断影响的方式在后台运行。 语法 nohup command [arguments] &参数 command:要在后台运行的命令或程…...
Linux 常见问题
1. 使用 sudo 命令时,提示 is not in the sudoers file. 是由于对应用户没有添加到 sudoers 文件中,可以在该文件中指定用户权限。运行以下命令即可打开该文件: visudo 添加上对应用户的权限 Ctrl x 退出保存即可。 2. Debian 新建的普通用…...

仕达利恩飞讯软件TPM设备管理项目正式启动,向数字化再迈一步
9月25日,仕达利恩(惠州)科技有限公司(以下简称“仕达利恩”)设备智能数采项目启动会成功召开,仕达利恩首席崔浩渊、杨翠琼次长携项目主要负责人共同出席本次启动会。为解决仕达利恩现阶段生产过程中的设备管理、设备配件仓管理以及…...
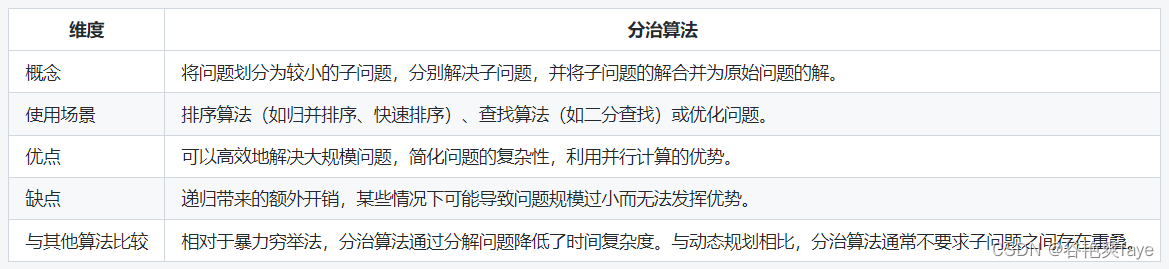
【算法】分治法
文章目录 概念原理和步骤代码示例 总结 概念 分治法(Divide and Conquer)是一种算法设计策略,其思想是将一个大问题划分为若干小规模的子问题,然后递归地解决每个子问题,并将它们的解合并起来以得到原始问题的解。分治…...
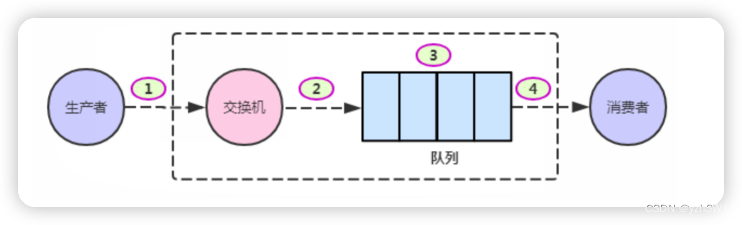
Rabbit消息的可靠性
生产者重连 消费者重试 Confirm模式简介 消息的confirm确认机制,是指生产者投递消息后,到达了消息服务器Broker里面的exchange交换机,则会给生产者一个应答,生产者接收到应答,用来确定这条消息是否正常的发送到Broker…...

Java中的网络编程是什么?
Java中的网络编程是指使用Java编程语言进行网络通信的过程和技术。它允许Java程序在互联网或局域网上进行数据交换、通信和传输。 Java提供了许多类和接口,用于实现网络编程。主要的网络编程相关的类在java.net包中可以找到。以下是一些常用的类和接口:…...

Oracle 常用命令大全
数据库 ----数据库启动 & 关闭 启动数据库 SQL> startup nomount; SQL> alter database mount; SQL> alter database open;关闭数据库 SQL> shutdown immediate;更多内容请参考:Oracle数据库启动和关闭 ----连接数据库 登陆普通用…...

Mysql 开启ssl连接
本文是针对Mysql 5.7版本以上数据库 1. 检查当前SSL / TLS状态 我们将使用-h指定IPv4本地环回接口,以强制客户端与TCP连接,而不是使用本地套接字文件。 这将允许我们检查TCP连接的SSL状态: mysql -u root -p -h 127.0.0.1键入以下内容以显示SSL / TLS变量的状态: SHOW …...

Java Stream流对List集合进行分页
有一种情况,我们有时不便在数据库层面进行分页。我们知道Mybatis的startPage();方法也是对数据库进行limit操作,有没有一种方式,只对List集合进行分页呢? 当然有,我们可以使用Stream流的方式对List集合进行操作&#…...
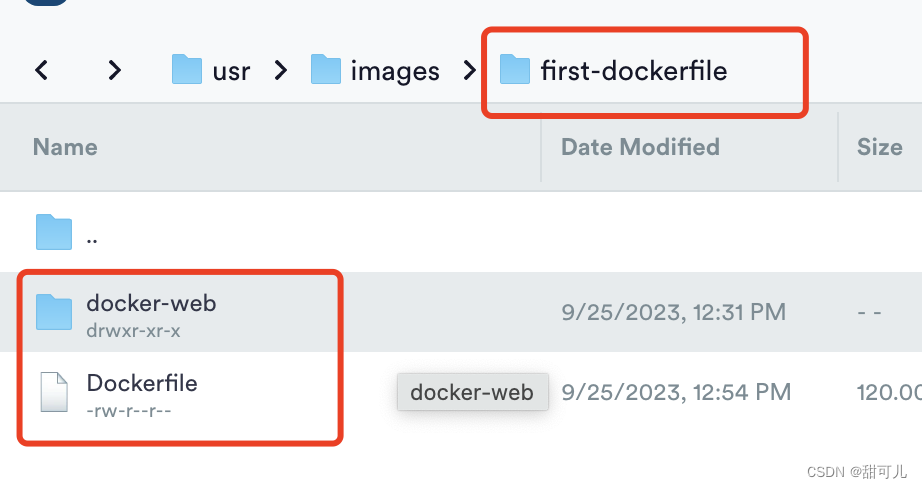
Docker(二)、linux环境Docker的部署以及构建镜像
linux环境Docker的部署以及构建镜像 一、docker部署1、快速部署常用的命令:1.1、demo-部署tomcat1.2、tomcat容器内部结构1.2.1、每个tomcat容器,都包含三个组件1.2.2、在容器内部执行命令 1.3、容器生命周期 二、Dockerfile构建镜像1、demo-Dockerfile自…...
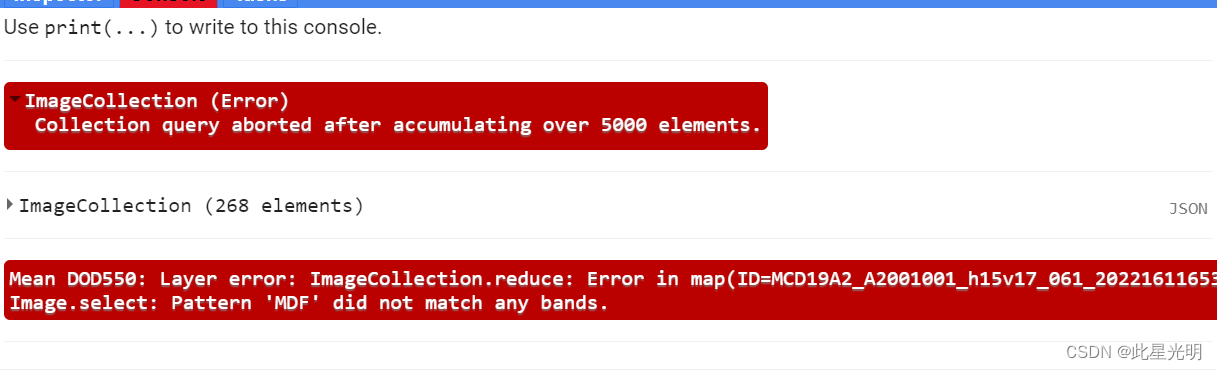
GEE错误——Image.select: Pattern ‘MDF‘ did not match any bands
问题 ImageCollection (Error) Collection query aborted after accumulating over 5000 elements. ImageCollection (268 elements) Mean DOD550: Layer error: ImageCollection.reduce: Error in map(ID=MCD19A2_A2001001_h15v17_061_2022161165308_01): Image.select: Patte…...

前端JavaScript入门到精通,javascript核心进阶ES6语法、API、js高级等基础知识和实战 —— JS基础(四)
开始吧,做时间的主人! 把时间分给睡眠,分给书籍,分给运动, 分给花鸟树木和山川湖海, 分给你对这个世界的热爱, 而不是将自己浪费在无聊的人和事上。 思维导图 函数 为什么需要函数 <!DO…...
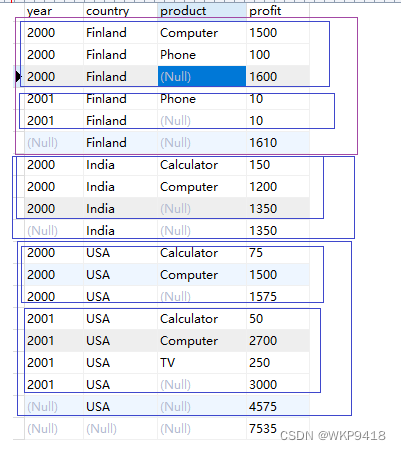
mysql超级聚合with rollup
超级聚合,是在group by的基础上,再次进行聚合。 它再次聚合的列,是select中没有用到聚合函数的列。 文章目录 例子1解释例子2表以及数据 例子1 mysql> SELECT year, country, product, SUM(profit) AS profitFROM salesGROUP BY year, c…...

浅谈电动汽车充电桩设计与应用研究
安科瑞 华楠 摘要:目前,随着我国社会经济的快速发展,我国的各个领域都取得了突破性的发展,尤其是在电动汽车充电桩的设计方法,新型的电动汽车充电桩设计已经广泛的受到了人民群众的青睐与认可,而这种发展前…...

tensorflow Windows安装说明
TensorFlow官网教程 Tensorflow 2.10是最后一个在本地windows上支持GPU的版本。从2.11版本开始,需要在windows WLS2(适用于 Linux 的 Windows 子系统)上安装才能使用GPU。 在anaconda shell控制台中,切换至虚拟环境, 安装TensorFlow 这是用…...

独立开发者如何利用Taotoken应对不同客户项目的多样化模型需求
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken应对不同客户项目的多样化模型需求 作为一名独立开发者或小型工作室的成员,你很可能同时维…...
)
别再拍脑袋定样本量了!用Excel 5分钟搞定市场调研的样本容量计算(附置信区间模板)
别再拍脑袋定样本量了!用Excel 5分钟搞定市场调研的样本容量计算(附置信区间模板) 在快节奏的商业决策中,市场调研的可靠性往往取决于一个关键数字——样本量。产品经理小张最近就踩了坑:耗时两周完成的500份用户问卷&…...
)
ElevenLabs乌尔都文TTS接入全链路解析:从API密钥配置到自然停顿优化(含3个未公开参数)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs乌尔都文TTS接入全链路解析:从API密钥配置到自然停顿优化(含3个未公开参数) ElevenLabs 官方虽未在文档中明确标注乌尔都语(ur-PK)…...

通过curl命令直接测试Taotoken聊天补全接口的配置与调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接测试Taotoken聊天补全接口的配置与调用 在对接大模型服务时,有时我们希望在引入完整SDK之前ÿ…...

系统安装:安装Ubuntu 26.04 LTS
1. EFI以及UEFI,什么用途? https://baike.baidu.com/item/EFI/2025809 EFI(Extensible Firmware Interface,可扩展固件接口)是由英特尔公司开发的固件接口标准,用于替代传统BIOS以实现更高效的硬件初始化和…...

本地RAG系统实战:基于开源模型构建私有知识库问答应用
1. 项目概述与核心价值最近在折腾本地大模型应用的时候,发现了一个挺有意思的项目,叫Awareness-Local。这名字听起来有点玄乎,但说白了,它就是一个帮你把本地文件(比如PDF、Word、TXT,甚至图片里的文字&…...

Cursor配置管理:使用符号链接与CLI实现多项目环境一键切换
1. 项目概述:为什么我们需要管理Cursor的配置?如果你和我一样,每天大部分时间都泡在Cursor这个AI驱动的代码编辑器里,那你肯定遇到过这样的场景:早上打开电脑,准备开始一个全新的前端项目,你熟练…...
的开发详解五:SigmaStudio实战技巧与模块高效应用)
ADAU1701(含A2B)的开发详解五:SigmaStudio实战技巧与模块高效应用
1. SigmaStudio模块查找的终极技巧 第一次打开SigmaStudio时,面对左侧密密麻麻的模块列表,我完全懵了。就像走进一个巨大的图书馆却找不到分类标签,ADI把200多个算法模块分散在30多个分类里,光Volume Controls下面就有12种音量调节…...

开源ChatGPT API代理部署指南:低成本调用AI模型实战
1. 项目概述:一个开源ChatGPT API代理的诞生最近在折腾AI应用开发的朋友,估计都绕不开一个核心问题:如何稳定、低成本地调用类似ChatGPT这样的强大语言模型。官方API虽然稳定,但价格和网络限制让很多个人开发者和初创团队望而却步…...

电商客服机器人如何通过 Taotoken 动态选择性价比最优的模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 电商客服机器人如何通过 Taotoken 动态选择性价比最优的模型 在电商客服场景中,用户咨询的问题复杂度差异巨大。从简单…...