数据分析回头看2——重复值检查/元素替换/异常值筛选
0、前言:
- 这部分内容是对Pandas的回顾,同时也是对Pandas处理异常数据的一些技巧的总结,不一定全面,只是自己在数据处理当中遇到的问题进行的总结。
1、当数据中有重复行的时候需要检测重复行:
- 方法:使用pandas中的duplicated方法,在该方法中有两个参数subset和keep,subset需要提供一个列表,列表中每个元素是一个列名,keep有三个可选项(‘first’,‘last’,False)
- 示例
import pandas as pd# 创建一个包含重复行的示例数据框
data = {'A': [6, 2, 3, 4, 6], 'B': [11, 10, 9, 10, 11]}
df = pd.DataFrame(data)display(df)# 使用duplicated方法检测重复行
duplicates = df.duplicated(subset=['A'])
print(duplicates)
print('='*30)
# 使用duplicated方法检测重复行
duplicates = df.duplicated(subset=['A'],keep=False)
print(duplicates)
print('='*30)
# 使用duplicated方法检测重复行
duplicates = df.duplicated(subset=['A'],keep="first")
print(duplicates)
print('='*30)
# 使用duplicated方法检测重复行
duplicates = df.duplicated(subset=['A'],keep='last')
print(duplicates)
print('='*30)
# 使用duplicated方法检测重复行
duplicates = df.duplicated(subset=['A','B'])
print(duplicates)
print('='*30)

2、删除重复行:
- 方法用pandas中的duplicated方法加loc索引即可
- 注意:删除重复列就没有比较快捷的方法了,就需要一一比较然后用drop方法删除对应列
data = [[1,2,3,4],[5,6,7,8],[1,2,3,4]]
df = pd.DataFrame(data,columns=list('ABCD'),index=[1,2,3])
display(df)# 查找重复行
re = df.duplicated(subset=['A','B','C','D'],keep='first')
display(~re)# 删除
df_new = df.loc[~re].copy()
display(df_new)

3、需要替换DataFrame元素中的值:核心思想就是映射,借助python中的字典。
- 替换中主要用到的思路就是映射,映射的含义是创建一个映射关系列表,把values元素和一个特定的标签或者字符串绑定,从其含义就可以看出和python中的字典非常像。
- 方法1:使用replace,特点是可以替换整个DataFrame中的值,会生成一个新数组。要替换原来的数组就要重新给原来的数组把replace之后的新数组赋值过去,当然先选中需要替换的列然后再替换也是可以的。
# 测试
df = DataFrame(data=[[1,2,34,5,6],[1,2,34,5,6],[1,2,34,5,6]],index=[1,2,3],columns=['语文','数学','英语','化学','科技']
)
display(df)
a = df.replace({1:'x',5:100}).copy()
display(a)

- 方法2:使用map,主要针对DataFrame中的列进行处理,其特点有3,第一可以通过已有列生成一个新列,第二适合处理某一个单独列,第三map函数中可以使用lambda函数或者自定义函数。但有个前提就是map中要处理哪一列,就要给列中所有元素给出对应的映射,不能有的给了,有的没给,没给的会修改为NaN值,这种方法会生成新列,没法修改原来的列,要修改原来的列就要给原来的列重新赋值map生成的新列
# 测试
df = DataFrame(data=[[1,2,34,5,6],[10,2,34,7,6],[15,2,34,5,6]],index=[1,2,3],columns=['语文','数学','英语','化学','科技']
)
display(df)
# 通过已有列生成新列
df['化学改'] = df.loc[:,'化学'].map({5:50,7:90})
display(df)
# 单独处理某一列
df['语文改'] = df.loc[:,'语文'].map({1:10,15:10})
display(df)
# 单独处理某一列
df['语文2改'] = df.loc[:,'语文'].map({1:10,15:10,10:10})
display(df)
# 映射函数
def n(x):if x > 60:return '及格'else:return "不及格"
df['数学判断'] = df.loc[:,'数学'].map(n)
display(df)
df['化学判断'] = df.loc[:,'化学改'].map(lambda x: '合格' if x>60 else '不合格')
display(df)

- 方法3:使用rename方法替换DataFrame中的行索引和列索引
# 测试
df = DataFrame(data=[[1,2,34,5,6],[10,2,34,7,6],[15,2,34,5,6]],index=[1,2,3],columns=['语文','数学','英语','化学','科技']
)
display(df)
df1 = df.rename(index={1:'zhang'},columns={'语文':'YuWen'}).copy()
display(df1)

- 方法4:factorize() 是一个在 pandas 中的函数,它可以将分类或者标签数据转换为数值形式。这个函数会返回两个值:一个整数序列(表示分类的整数代码)和一个包含分类标签的字符串系列。
重要参数:na_option:如何处理缺失值。可以设为 ‘drop’(默认),‘keep’ 或 ‘ignore’。如果设为 ‘keep’,缺失值将被视为一个特殊的类别。如果设为 ‘drop’,含有缺失值的行将被完全忽略。如果设为 ‘ignore’,含有缺失值的行仍然会被编码,但结果可能不是整数。注意:factorize() 会返回一个新的列,如果要修改原来的列,就要给原来的列重新赋值
da = pd.DataFrame([['a','v','e'],['b','c','d']],columns=['a','b','c'],index=[1,2])
display(da)
i,j = da.a.factorize()
display(i,j)
da.a = a
display(da)
da.c,k = da.loc[:,'c'].factorize()
display(k)
display(da)

4、异常值筛选:
- 使用describe()函数查看每一列的描述性统计量
# 测试
df = DataFrame(data=[[1,2,34,5,6],[10,2,34,7,6],[15,2,34,5,6]],index=[1,2,3],columns=['语文','数学','英语','化学','科技']
)
display(df)
df.describe()

- 使用std()函数可以求得DataFrame对象每一列的标准差(较为简单不做示例)
- 使用info()可以获取数据中是否有空值
- 异常值筛选思路:先确定异常值,然后通过条件判断获取异常值
df = DataFrame(data={'height': np.random.randint(120,260,size=5),'weight': np.random.randint(40,150,size=5)}
)
df.loc[:,'weight']=[180,500,600,111,120]
display(df)
pro = df.loc[:,'weight']>180
display(df.loc[:'weight'][pro])

- unique() 方法,可以对某一列或一行数据去重(较为简单不做示例)
- df.query : 按条件查询,可以在DataFrame中以字符串的形式编写表达式来选择或过滤特定的行和列。
# 测试
df = DataFrame(data=[[1,2,34,5,6],[10,2,34,7,6],[15,2,34,5,6]],index=[1,2,3],columns=['语文','数学','英语','化学','科技']
)
display(df)
a = df.query("数学==2").copy()
display(a)
b = df.query("化学==5 and 语文==1").copy()
display(b)

相关文章:
数据分析回头看2——重复值检查/元素替换/异常值筛选
0、前言: 这部分内容是对Pandas的回顾,同时也是对Pandas处理异常数据的一些技巧的总结,不一定全面,只是自己在数据处理当中遇到的问题进行的总结。 1、当数据中有重复行的时候需要检测重复行: 方法:使用p…...
什么是OSPF?为什么需要OSPF
【微|信|公|众|号:厦门微思网络】 【微思网络www.xmws.cn,成立于2002年,专业培训21年,思科、华为、红帽、ORACLE、VMware等厂商认证及考试,以及其他认证PMP、CISP、ITIL等】 什么是OSPF? 开放式最短路径优…...
轻量级的日志采集组件 Filebeat 讲解与实战操作
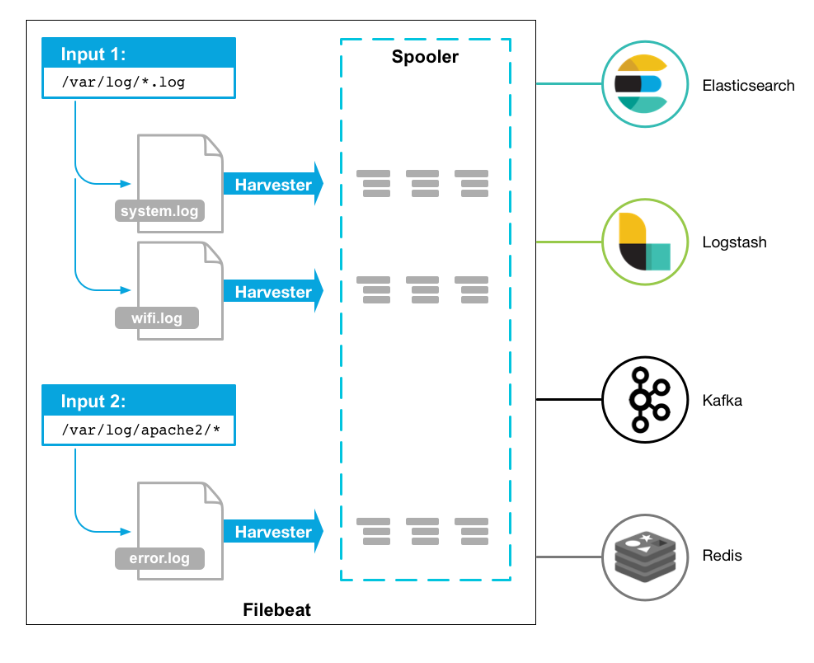
文章目录 一、概述二、Kafka 安装三、Filebeat 安装1)下载 Filebeat2)Filebeat 配置参数讲解3)filebeat.prospectors 推送kafka完整配置1、filebeat.prospectors2、processors3、output.kafka 4)filebeat.inputs 与 filebeat.pros…...

C# 委托和事件
C# 委托和事件 委托匿名方法事件 委托 当要把方法传送给其他方法时,需要使用委托。首先定义要使用的委托,对于委托,定义它就是告诉编译器这种类型的委托代表了哪种类型的方法,然后创建该委托的一个或多个实例。编译器在后台将创建…...
)
数据结构与算法之字典: Leetcode 349. 两个数组的交集 (Typescript版)
两个数组的交集 https://leetcode.cn/problems/intersection-of-two-arrays/description/ 题目和解题参考 https://blog.csdn.net/Tyro_java/article/details/133279737 使用字典来解题的算法实现 字典:顾名思义,像新华字典一样可查找,基…...
动态规划 part 16)
day-56 代码随想录算法训练营(19)动态规划 part 16
538.两个字符串的删除操作 思路一: 1.dp存储:以word1[i-1]结尾,word2[j-1]结尾,最少进行dp[i][j]次操作2.动态转移方程: if(word1[i-1]word2[i-1]) dp[i][j]dp[i-1][j-1]; else dp[i][j]min(dp[i-1][…...

蓝桥等考Python组别四级005
第一部分:选择题 1、Python L4 (15分) 字符“0”的ASCII码值为48,则字符“5”的ASCII码值为( )。 3953120240正确答案:B 2、Python L4 (15分) 下面哪个是Python中正确的变量名?( ) ABC#sup01Trueif正确答案:B...

【Linux】diff 命令
【Linux】diff 命令——并排格式输出 功能 diff 以逐行的方式,比较文本文件的异同处。 如果指定要比较目录,则 diff 会比较目录中相同文件名的文件,但不会比较其中子目录 diff [参数] [文件A] [文件B]diff [参数] [目录A] [目录B]【参数】…...

【51单片机】9-定时器和计数器
1.定时器的介绍 1.什么是定时器 (1)SoC的一种内部的外设【在单片机里面,但是在CPU外面】 (2)定时器就是CPU的”闹钟“ 2.什么是计数器 (1)定时器就是用计数的原始实现的 (2…...

2023年海南省职业院校技能大赛(高职组)信息安全管理与评估赛项规程
2023年海南省职业院校技能大赛(高职组) 信息安全管理与评估赛项规程 一、赛项名称 赛项名称:信息安全管理与评估 英文名称:Information Security Management and Evaluation 赛项组别:高等职业教育 赛项归属产业&…...

大模型深挖数据要素价值:算法、算力之后,存储载体价值凸显
文 | 智能相对论 作者 | 叶远风 18.8万亿美元,这是市场预计2030年AI推动智能经济可产生的价值总和,其中大模型带来的AI能力质变无疑成为重要的推动力量。 大模型浪潮下,业界对AI发展的三驾马车——算力、算法、数据任何一个维度的关注都到…...

AI文章,AI文章生成工具
在互联网时代,随着信息爆炸式增长,文章的需求愈发旺盛。从博客、新闻、社交媒体到企业宣传,文字作为传达信息、吸引受众的工具变得愈发重要。但问题是,对于很多人来说,创作一篇高质量的文章并不容易。时间、创意、写作…...
mac有必要用清理软件吗?有哪些免费的清理工具
当我们谈到Mac电脑时,很多人都会觉得它比Windows系统更加稳定和高效,也更不容易积累垃圾文件。但实际上,任何长时间使用的操作系统都会逐渐积累不必要的文件和缓存。那么,对于Mac用户来说,有必要使用专门的清理软件吗&…...
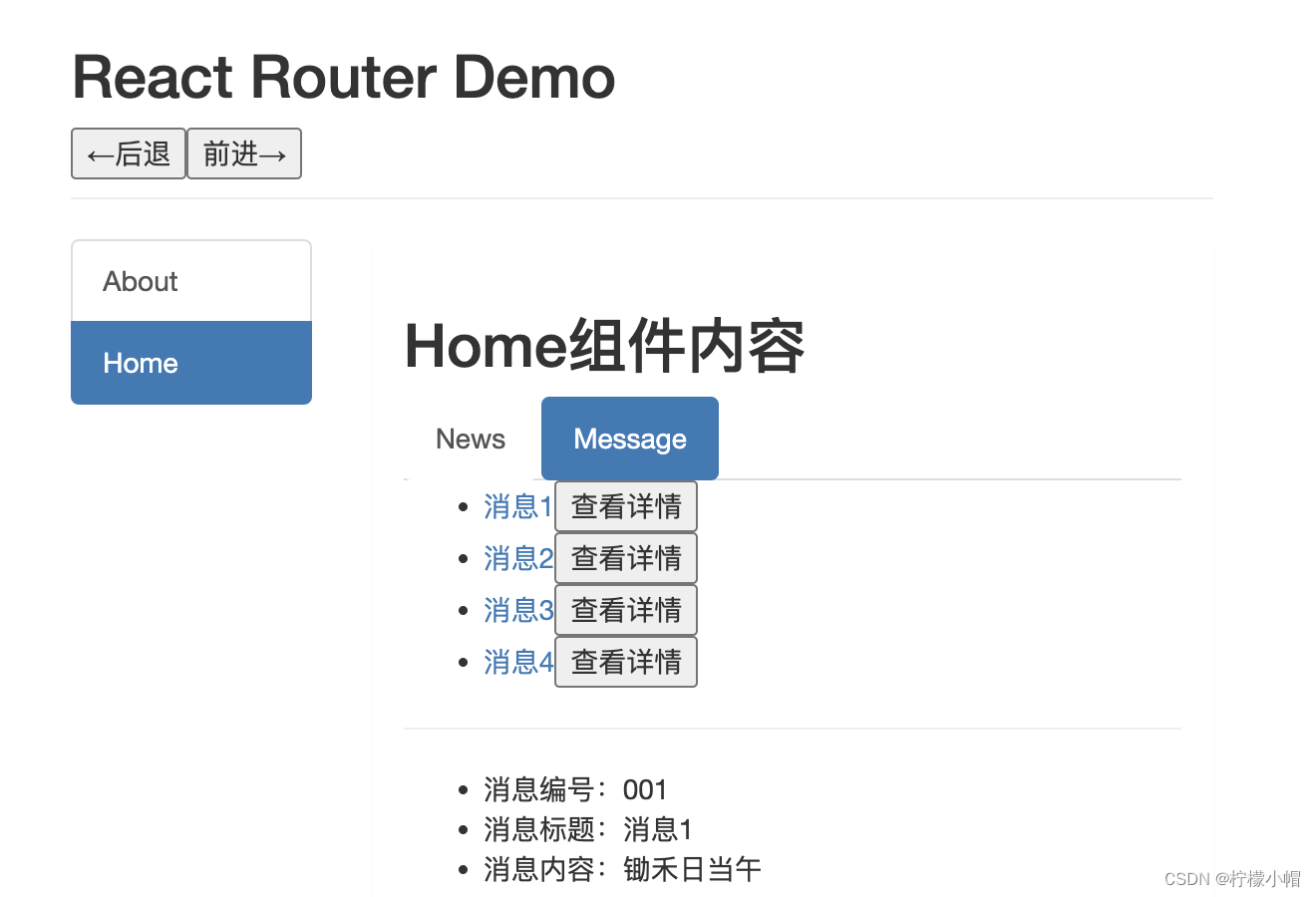
React 全栈体系(十八)
第九章 React Router 6 二、代码实战 6. 路由的 params 参数 6.1 routes /* src/routes/index.js */ import About from "../pages/About"; import Home from "../pages/Home"; import Message from "../pages/Message"; import News from &q…...

TCP/UDP
TCP:可靠的有序传输 TCP是一种面向连接的协议,旨在提供可靠、有序的数据传输。它通过以下方式实现这一目标: 1. 连接建立和维护 在使用TCP传输数据之前,必须先建立连接。这个过程包括三次握手,即客户端和服务器之间…...

c++内存对齐
原文在这里。https://blog.csdn.net/WangErice/article/details/103598081 但是内容有错误。我在自己的这里修改并变成红色了。 内存在使用过程并不是单一的依次排列,而是按照某种既定的规则来进行对齐,以方便快速访问.内存的对齐原则有以下三条&#…...
leetcode 33. 搜索旋转排序数组
2023.9.26 本题暴力法可以直接A,但是题目要求用log n的解法。 可以想到二分法,但是一般二分法适用于有序数组的,这里的数组只是部分有序,还能用二分法吗? 答案是可以的。因为数组是经过有序数组旋转得来的,…...

VCS flow学习
VCS VCS 是IC从业者常用软件,该篇文章是一个学习记录,会记录在使用过程中各种概念及options。 VCS Flow VCS Flow 可以分为Two-step Flow和Three-step Flow两类。 两步法 两步法只支持Verilog HDL和SystemVerilog的design,两步法主要包括…...
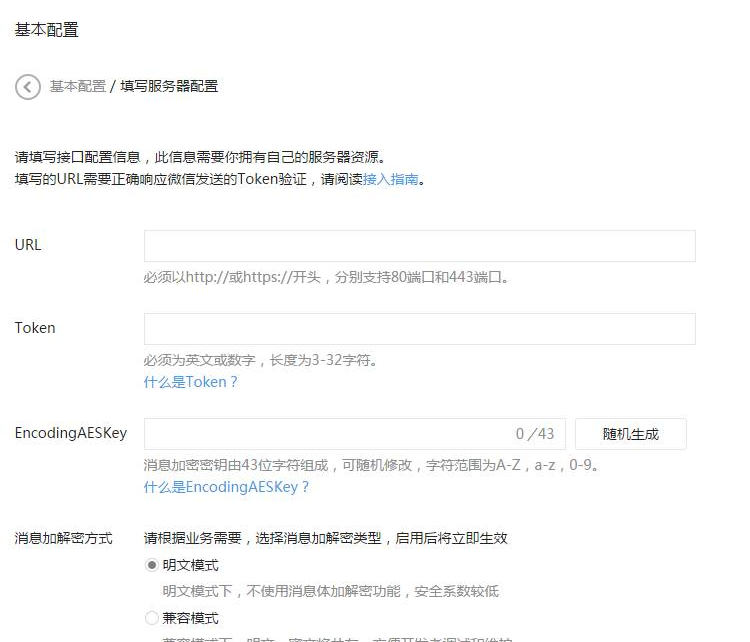
微信扫码关注公众号登录功能php实战分享
1、安装easywechat 基于easywechat框架开发,首先下载安装easywechat composer require overtrue/wechat 2、公众号配置 先去公众号后台基本配置/ 填写服务器配置配置接口,需要是线上能正确收到微信推送消息的地址,关注如果有关注、扫码、收到消息等事件都会推送到该地址…...

Git 精简快速使用
安装 Git 忽略,自行搜索 新建项目,或者在仓库拉取项目,进入到项目目录 Github 给出的引导,新项目和旧项目 echo "# testgit" >> README.md git init git add README.md git commit -m "first commit"…...

基于龙芯2K1000LA的可信计算在工业边缘安全中的实践
1. 项目概述:当“可信计算”遇上工业边缘 最近在做一个工业数据采集与边缘处理的项目,客户对数据安全的要求提到了前所未有的高度。他们不仅担心数据在传输过程中被窃取,更担心边缘设备本身被恶意篡改,导致采集的数据在源头就“失…...

STM32F103C8T6新手必看:SWD、JTAG、串口三种下载方式到底怎么选?
STM32F103C8T6开发入门:SWD、JTAG与串口下载方式深度解析 第一次接触STM32开发板时,面对板子上密密麻麻的接口和文档中提到的各种下载方式,很多新手都会感到迷茫。我清楚地记得自己刚开始学习时,拿着ST-Link调试器却不知道应该连接…...

OdinSerializer扩展开发完全手册:创建自定义序列化组件
OdinSerializer扩展开发完全手册:创建自定义序列化组件 【免费下载链接】odin-serializer Fast, robust, powerful and extendible .NET serializer built for Unity 项目地址: https://gitcode.com/gh_mirrors/od/odin-serializer OdinSerializer是一款专为…...

低空经济项目|Java无人机接单派单平台系统源码开发实战
随着低空经济产业的规范化发展,无人机应用已渗透到航拍、测绘、电力巡检、农业植保、应急救援等多个细分场景,市场对专业飞手的需求持续增长,但供需对接效率低下的痛点日益突出:需求方难以快速匹配具备合法资质的飞手,…...

Java后端开发德州扑克小酒馆小程序架构与源码解析
德州扑克小酒馆小程序的核心价值,在于依托休闲娱乐场景实现小酒馆线下引流,其Java后端的架构设计与源码实现,直接决定小程序的稳定性、可扩展性与合规性。 一、架构设计核心原则(贴合场景,合规优先) 德州…...

AI智能体协作命令行工具squads-cli:多智能体编排与自动化实战
1. 项目概述:一个面向AI智能体协作的命令行工具如果你最近在关注AI智能体(Agent)的开发,尤其是多智能体协作(Multi-Agent Collaboration)这个方向,那你很可能已经听说过或接触过一些相关的框架。…...

Circuit Playground开发板入门:从零到一玩转集成传感器与Arduino编程
1. 项目概述与核心价值如果你对电子制作和编程感兴趣,但一看到复杂的电路图和密密麻麻的代码就头疼,那么Circuit Playground可能就是为你量身打造的“入场券”。它不是一个需要你从零焊接电阻、电容的散件包,而是一块将所有常用传感器和交互元…...

VSCode性能优化实战:回归轻量编辑器,提升开发效率
1. 项目概述:为什么我们需要一个“经典体验”的VSCode? 如果你是一个从Sublime Text、Notepad或者更早的编辑器时代走过来的开发者,最近打开Visual Studio Code时,可能会感到一丝陌生。没错,VSCode变得越来越强大&…...

集成三相桥驱动的MCU:AiP8F7201电机控制方案解析
1. 项目概述:为什么我们需要“集成三相桥式驱动的微控制器”?在电机控制领域,尤其是消费电子、家电、工业自动化这些我们每天都会接触到的场景里,工程师们一直在和一堆“麻烦”作斗争。想象一下,你要设计一个驱动无刷直…...

AI Agent Harness Engineering 的安全攻防:你的智能体如何被欺骗、劫持与利用
AI Agent Harness Engineering 安全攻防深度解析:你的智能体如何被欺骗、劫持与利用 关键词 AI Agent安全、Harness工程、Prompt注入、工具劫持、智能体攻防、LLM安全、权限逃逸 摘要 随着AI Agent从概念验证走向大规模产业落地,作为智能体控制平面的Harness层已成为攻防…...