LINUX -SQL笔记(自学用)
1.安装
sudo apt-get install mysql-server
sudo mysql -u root -p
2.关系模型
在关系数据库中,一张表中的每一行数据被称为一条记录。一条记录就是由多个字段组成的。
每一条记录都包含若干定义好的字段。同一个表的所有记录都有相同的字段定义。
对于关系表,有个很重要的约束,就是任意两条记录不能重复。不能重复不是指两条记录不完全相同,而是指能够通过某个字段唯一区分出不同的记录,这个字段被称为主键。
1.记录一旦插入到表中,主键最好不要再修改。
2.不使用任何业务相关的字段作为主键。
3.作为主键最好是完全业务无关的字段,我们一般把这个字段命名为id。
常见的可作为id字段的类型有:
1.自增整数类型:
2.全局唯一GUID类型
联合主键
关系数据库实际上还允许通过多个字段唯一标识记录,即两个或更多的字段都设置为主键,这种主键被称为联合主键。
对于联合主键,允许一列有重复,只要不是所有主键列都重复即可。量不使用联合主键,因为它给关系表带来了复杂度的上升。
外键:数据与另一张表关联起来,这种列称为外键。
索引:可以加快查询速度,唯一索引,唯一约束
查询数据
1.基本查询
SELECT * FROM <表名>;
SELECT * FROM students;
使用SELECT * FROM students时,SELECT是关键字,表示将要执行一个查询,*表示“所有列”,FROM表示将要从哪个表查询,
2.条件查询
SELECT * FROM <表名> WHERE <条件表达式>SELECT * FROM students WHERE score >= 80;
SELECT * FROM students WHERE score >= 80 AND gender = 'M';
SELECT * FROM students WHERE score >= 80 OR gender = 'M';
SELECT * FROM students WHERE NOT class_id = 2;//class_id <> 2
SELECT * FROM students WHERE (score < 80 OR score > 90) AND gender = 'M';//如果不加括号,条件运算按照NOT、AND、OR的优先级进行,即NOT优先级最高,其次是AND,最后是OR。加上括号可以改变优先级。
3.投影查询
如果我们只希望返回某些列的数据,而不是所有列的数据,我们可以用SELECT 列1, 列2, 列3 FROM …,让结果集仅包含指定列。这种操作称为投影查询。
可以给每一列起个别名,这样,结果集的列名就可以与原表的列名不同。SELECT 列1 别名1, 列2 别名2, 列3 别名3 FROM …
SELECT id, score, name FROM students;
SELECT id, score points, name FROM students;
SELECT id, score points, name FROM students WHERE gender = 'M';
4.排序
SELECT id, name, gender, score FROM students ORDER BY score;//按score从低到高
SELECT id, name, gender, score FROM students ORDER BY score DESC;//按照成绩从高到底排序,我们可以加上DESC表示“倒序”
SELECT id, name, gender, score FROM students ORDER BY score DESC, gender;//score列有相同的数据,要进一步排序,可以继续添加列名。SELECT id, name, gender, score
FROM students
WHERE class_id = 1
ORDER BY score DESC;//带WHERE条件的ORDER BY 一个关键词一行清晰表达
5.分页查询
分页实际上就是从结果集中“截取”出第M~N条记录。这个查询可以通过LIMIT <M~N> OFFSET <M>子句实现.
查询第一页
SELECT id, name, gender, score
FROM students
ORDER BY score DESC
LIMIT 3 OFFSET 0;//结果集从0号记录开始,最多取3条。注意SQL记录集的索引从0开始。查询第二页
SELECT id, name, gender, score
FROM students
ORDER BY score DESC
LIMIT 3 OFFSET 3;//跳过头3条记录,也就是对结果集从3号记录开始查询,把OFFSET设定为3
6.聚合查询
统计总数、平均数这类计算,SQL提供了专门的聚合函数,使用聚合函数进行查询,就是聚合查询,它可以快速获得结果。
查询students表一共有多少条记录为例,我们可以使用SQL内置的COUNT()函数查询
SELECT COUNT(*) FROM students;//聚合的计算结果虽然是一个数字,但查询的结果仍然是一个二维表,只是这个二维表只有一行一列,并且列名是COUNT(*)。SELECT COUNT(*) num FROM students;//通常,使用聚合查询时,我们应该给列名设置一个别名,便于处理结果SELECT COUNT(*) boys FROM students WHERE gender = 'M';
聚合函数:
SUM 计算某一列的合计值,该列必须为数值类型
AVG 计算某一列的平均值,该列必须为数值类型
MAX 计算某一列的最大值
MIN 计算某一列的最小值SELECT AVG(score) average FROM students WHERE gender = 'M';如果聚合查询的WHERE条件没有匹配到任何行,COUNT()会返回0,而SUM()、AVG()、MAX()和MIN()会返回NULL:对于聚合查询,SQL还提供了“分组聚合”的功能:
SELECT COUNT(*) num FROM students GROUP BY class_id;SELECT name, class_id, COUNT(*) num FROM students GROUP BY class_id;//把name放入结果集SELECT class_id, gender, COUNT(*) num FROM students GROUP BY class_id, gender;//使用多个列进行分组
7.多表查询(笛卡尔查询)
由于结果集是目标表的行数乘积,对两个各自有100行记录的表进行笛卡尔查询将返回1万条记录,对两个各自有1万行记录的表进行笛卡尔查询将返回1亿条记录。
SELECT * FROM students, classes;//每一行都两两拼在一起返回。结果集的列数是students表和classes表的列数之和,行数是students表和classes表的行数之积。SELECTstudents.id sid,students.name,students.gender,students.score,classes.id cid,classes.name cname
FROM students, classes;
//投影查询的“设置列的别名”来给两个表各自的id和name列起别名SELECTs.id sid,s.name,s.gender,s.score,c.id cid,c.name cname
FROM students s, classes c;
//用表名.列名这种方式列举两个表的所有列实在是很麻烦,所以SQL还允许给表设置一个别名SELECTs.id sid,s.name,s.gender,s.score,c.id cid,c.name cname
FROM students s, classes c
WHERE s.gender = 'M' AND c.id = 1;//多表查询也是可以添加WHERE条件
8.连接查询
连接查询是另一种类型的多表查询。连接查询对多个表进行JOIN运算,简单地说,就是先确定一个主表作为结果集,然后,把其他表的行有选择性地“连接”在主表结果集上。
内连接
SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score
FROM students s
INNER JOIN classes c
ON s.class_id = c.id;
//希望结果集同时包含所在班级的名称,上面的结果集只有class_id列,缺少对应班级的name列。
//存放班级名称的name列存储在classes表中,只有根据students表的class_id,找到classes表对应的行,再取出name列,就可以获得班级名称。
//这时,连接查询就派上了用场。我们先使用最常用的一种内连接——INNER JOIN来实现:
注意INNER JOIN查询的写法是:
先确定主表,仍然使用FROM <表1>的语法;
再确定需要连接的表,使用INNER JOIN <表2>的语法;
然后确定连接条件,使用ON <条件…>,这里的条件是s.class_id = c.id,表示students表的class_id列与classes表的id列相同的行需要连接;
可选:加上WHERE子句、ORDER BY等子句。
使用别名不是必须的,但可以更好地简化查询语句。
外连接
SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score
FROM students s
RIGHT OUTER JOIN classes c
ON s.class_id = c.id;//INNER JOIN只返回同时存在于两张表的行数据。//RIGHT OUTER JOIN返回右表都存在的行。如果某一行仅在右表存在,那么结果集就会以NULL填充剩下的字段。//LEFT OUTER JOIN则返回左表都存在的行。//FULL OUTER JOIN,它会把两张表的所有记录全部选择出来,并且,自动把对方不存在的列填充为NULL。
修改数据
1.INSERT
INSERT INTO <表名> (字段1, 字段2, ...) VALUES (值1, 值2, ...)
INSERT INTO students (class_id, name, gender, score) VALUES (2, '大牛', 'M', 80);SELECT * FROM students;//查询并观察结果:
INSERT INTO students (class_id, name, gender, score) VALUES(1, '大宝', 'M', 87),(2, '二宝', 'M', 81);SELECT * FROM students;
2.UPDATE
UPDATE <表名> SET 字段1=值1, 字段2=值2, ... WHERE ...;
//更新id=1的记录
UPDATE students SET name='大牛', score=66 WHERE id=1;
-- 查询并观察结果:
SELECT * FROM students WHERE id=1;
//更新id=5,6,7的记录
UPDATE students SET name='小牛', score=77 WHERE id>=5 AND id<=7;
-- 查询并观察结果:
SELECT * FROM students;
//在UPDATE语句中,更新字段时可以使用表达式。
UPDATE students SET score=score+10 WHERE score<80;
-- 查询并观察结果:
SELECT * FROM students;UPDATE语句可以没有WHERE条件,整个表的所有记录都会被更新。
3.DELETE
DELETE FROM <表名> WHERE ...;
//删除id=1的记录
DELETE FROM students WHERE id=1;
-- 查询并观察结果:
SELECT * FROM students;DELETE FROM students WHERE id>=5 AND id<=7;
-- 查询并观察结果:
SELECT * FROM students;不带WHERE条件的DELETE语句会删除整个表的数据:DELETE FROM students;
MYSQL
EXIT仅仅断开了客户端和服务器的连接,MySQL服务器仍然继续运行
1.管理MYSQL
SHOW DATABASES;
//information_schema、mysql、performance_schema和sys是系数据库,不要改动。CREATE DATABASE test;//创建一个新数据库test
DROP DATABASE test;//删除USE test;//切换当前数据库SHOW TABLES;//列出当前数据库的所有表
DESC students;//查看一个表的结构SHOW CREATE TABLE students;//查看创建表的SQL语句
创建表使用 CREATE TABLE 语句,而删除表使用 DROP TABLE 语句修改表比较复杂
ALTER TABLE students ADD COLUMN birth VARCHAR(10) NOT NULL;
//students表新增一列birth
ALTER TABLE students CHANGE COLUMN birth birthday VARCHAR(20) NOT NULL;
//修改birth列,例如把列名改为birthday,类型改为VARCHAR(20)
ALTER TABLE students DROP COLUMN birthday;
//ALTER TABLE students DROP COLUMN birthday;
实用SQL语句
插入或替换
REPLACE INTO students (id, class_id, name, gender, score) VALUES (1, 1, '小明', 'F', 99);
//若id=1的记录不存在,REPLACE语句将插入新记录,否则,当前id=1的记录将被删除,然后再插入新记录。
插入或更新
INSERT INTO students (id, class_id, name, gender, score) VALUES (1, 1, '小明', 'F', 99) ON DUPLICATE KEY UPDATE name='小明', gender='F', score=99;
//若id=1的记录不存在,INSERT语句将插入新记录,否则,当前id=1的记录将被更新,更新的字段由UPDATE指定。
插入或忽略
INSERT IGNORE INTO students (id, class_id, name, gender, score) VALUES (1, 1, '小明', 'F', 99);
//若id=1的记录不存在,INSERT语句将插入新记录,否则,不执行任何操作。
快照
- 对class_id=1的记录进行快照,并存储为新表students_of_class1:
CREATE TABLE students_of_class1 SELECT * FROM students WHERE class_id=1;
写入查询结果集
CREATE TABLE statistics (id BIGINT NOT NULL AUTO_INCREMENT,class_id BIGINT NOT NULL,average DOUBLE NOT NULL,PRIMARY KEY (id)
);
INSERT INTO statistics (class_id, average) SELECT class_id, AVG(score) FROM students GROUP BY class_id;强制使用指定索引
ELECT * FROM students FORCE INDEX (idx_class_id) WHERE class_id = 1 ORDER BY id DESC;
事务
数据库事务具有ACID这4个特性:
A:Atomic,原子性,将所有SQL作为原子工作单元执行,要么全部执行,要么全部不执行;
C:Consistent,一致性,事务完成后,所有数据的状态都是一致的,即A账户只要减去了100,B账户则必定加上了100;
I:Isolation,隔离性,如果有多个事务并发执行,每个事务作出的修改必须与其他事务隔离;
D:Duration,持久性,即事务完成后,对数据库数据的修改被持久化存储。
对于单条SQL语句,数据库系统自动将其作为一个事务执行,这种事务被称为隐式事务。
要手动把多条SQL语句作为一个事务执行,使用BEGIN开启一个事务,使用COMMIT提交一个事务,这种事务被称为显式事务,例如,把上述的转账操作作为一个显式事务:
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
COMMIT;
COMMIT是指提交事务,即试图把事务内的所有SQL所做的修改永久保存。如果COMMIT语句执行失败了,整个事务也会失败。
我们希望主动让事务失败,这时,可以用ROLLBACK回滚事务,整个事务会失败:
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
ROLLBACK;
Isolation Level
脏读(Dirty Read)
不可重复读(Non Repeatable Read)
幻读(Phantom Read)
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;在使用 “READ UNCOMMITTED” 隔离级别的事务中:
事务可以读取当前由其他事务修改的数据,这可能导致脏读、不可重复读和幻读等问题。数据被读取时不会加锁,允许其他事务同时修改相同的数据。
这个级别提供了最高程度的并发性,但牺牲了数据的一致性和完整性。
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;在Read Committed隔离级别下,一个事务可能会遇到不可重复读(Non Repeatable Read)的问题。
不可重复读是指,在一个事务内,多次读同一数据,在这个事务还没有结束时,如果另一个事务恰好修改了这个数据,那么,在第一个事务中,两次读取的数据就可能不一致。
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;在Repeatable Read隔离级别下,一个事务可能会遇到幻读(Phantom Read)的问题。
幻读是指,在一个事务中,第一次查询某条记录,发现没有,但是,当试图更新这条不存在的记录时,竟然能成功,并且,再次读取同一条记录,它就神奇地出现了。
Serializable是最严格的隔离级别。在Serializable隔离级别下,所有事务按照次序依次执行,因此,脏读、不可重复读、幻读都不会出现。
虽然Serializable隔离级别下的事务具有最高的安全性,但是,由于事务是串行执行,所以效率会大大下降,应用程序的性能会急剧降低。如果没有特别重要的情景,一般都不会使用Serializable隔离级别。
相关文章:
)
LINUX -SQL笔记(自学用)
1.安装 sudo apt-get install mysql-server sudo mysql -u root -p2.关系模型 在关系数据库中,一张表中的每一行数据被称为一条记录。一条记录就是由多个字段组成的。 每一条记录都包含若干定义好的字段。同一个表的所有记录都有相同的字段定义。 对于关系表&#…...
【Spark】win10配置IDEA、saprk、hadoop和scala
终于,要对并行计算下手了哈哈哈。 一直讲大数据大数据,我单次数据处理量大概在1t上下,是过亿级的轨迹数据。 用python调用multiprogress编写的代码,用多线程也要一个多月跑完。 我对这个效率不太满意,希望能快一点再快…...
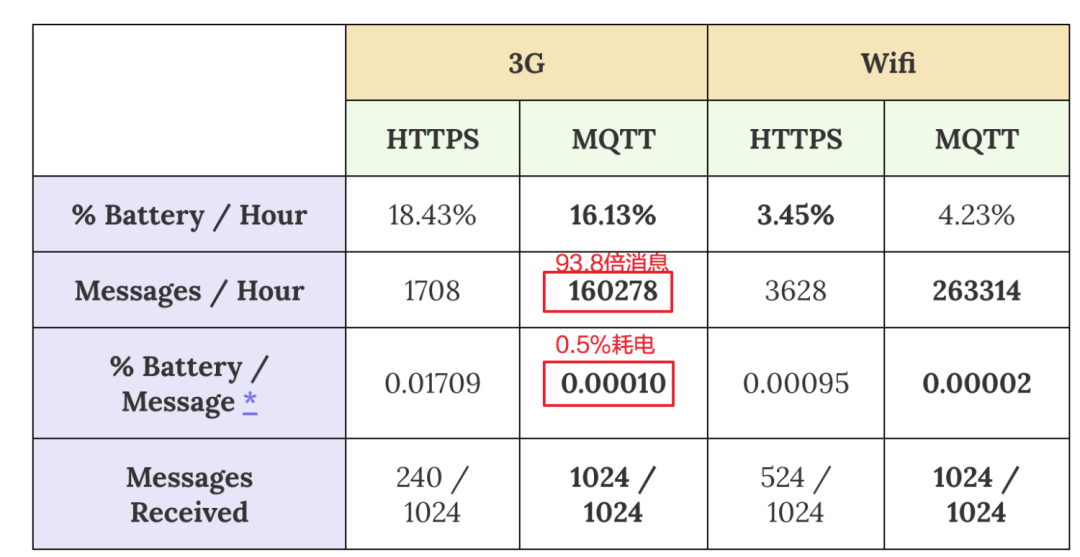
MQTT 协议概要
01 MQTT协议 MQTT(消息队列遥测传输) 是基于 TCP/IP 协议栈而构建的支持在各方之间异步通信的消息协议。MQTT在空间和时间上将消息发送者与接收者分离,因此可以在不可靠的网络环境中进行扩展。虽然叫做消息队列遥测传输,但它与消息…...

向量数据库X云计算驱动大模型落地电商行业,Zilliz联合AWS探索并贡献成熟解决方案
近日,由Zilliz 联合亚马逊云科技举办的【向量数据库 X 云计算 驱动大模型落地电商行业】活动在上海落幕,获得业内专业人士的广泛好评。 众所周知,大模型技术的发展正加速对千行万业的改革和重塑,向量数据库作为大模型的海量记忆体、云计算作为大模型的大算力平台,是大模型…...

【vue2】解决Vuex刷新页面数据丢失的问题
最近写vue2 项目需要用到vuex, 但遇到一个问题,存进store里的数据刷新就丢失了,于是乎百度解决。将自己的感受与解决方法记录下来。 数据丢失的原因 vuex存储的数据只是在页面中,相当于全局变量,页面刷新的时候vuex里的数据会重…...
小皮面板配置Xdebug,调试单个php文件
小皮面板配置Xdebug 首先下载phpstrom,和小皮面板 打开小皮面板,选中好要使用的php版本 然后点击【管理】> 【php扩展】> 【xdebug】 然后打开选中好版本的php位置 D:\Program_Files\phpstudy_pro\Extensions\php\php7.4.3nts打开php.ini文件…...
版本控制系统:Perforce Helix Core -2023
Perforce Helix Core是领先的版本控制系统,适用于需要加速大规模创新的团队。存储并跟踪您所有数字资产的更改,从源代码到二进制再到IP。连接您的团队,让他们更快地行动,更好地构建。 通过 Perforce 版本控制加速创新 Perforce H…...

回归预测 | Matlab实现基于MIC-BP最大互信息系数数据特征选择算法结合BP神经网络的数据回归预测
回归预测 | Matlab实现基于MIC-BP最大互信息系数数据特征选择算法结合BP神经网络的数据回归预测 目录 回归预测 | Matlab实现基于MIC-BP最大互信息系数数据特征选择算法结合BP神经网络的数据回归预测效果一览基本介绍研究内容程序设计参考资料 效果一览 基本介绍 Matlab实现基于…...

Hive-命令行CDH访问开启kerberos的hive
1.通过hive用户访问 切换用户为hive [rootslave conf]# su - hive 上一次登录:五 4月 12 13:59:19 CST 2019pts/1 上 [hiveslave ~]$命令行直接输入hive就可以进入hive [hiveslave ~]$ hive log4j:WARN No such property [maxFileSize] in org.apache.log4j.Dail…...
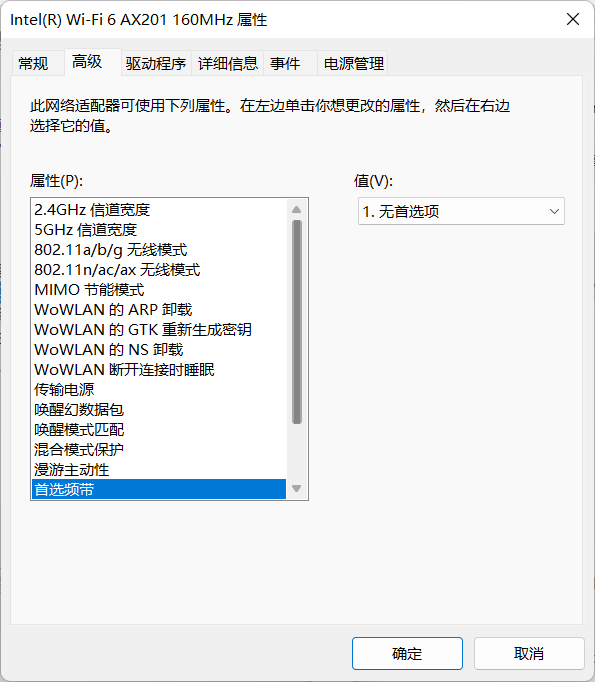
手机能搜到某个wifi,电脑搜不到解决方法(也许有用)
方法一:更新驱动 下载驱动大师、驱动精灵等等驱动软件,更新网卡驱动 方法二 按 win 键,打开菜单 搜索 查看网络连接(win11版本是搜这个名字) 点击打开是这样式的 然后对 WLAN右击->属性->配置->高级 这…...

Java-day18(网络编程)
网络编程 1.概述 Java提供跨平台的网络类库,可以实现无痛的网络连接,程序员面对的是一个统一的网络编程环境 网络编程的目的:直接或间接地通过网络协议与其他计算机进行通信 网络编程的两个主要问题: 1.如何准确定位网络上一台…...
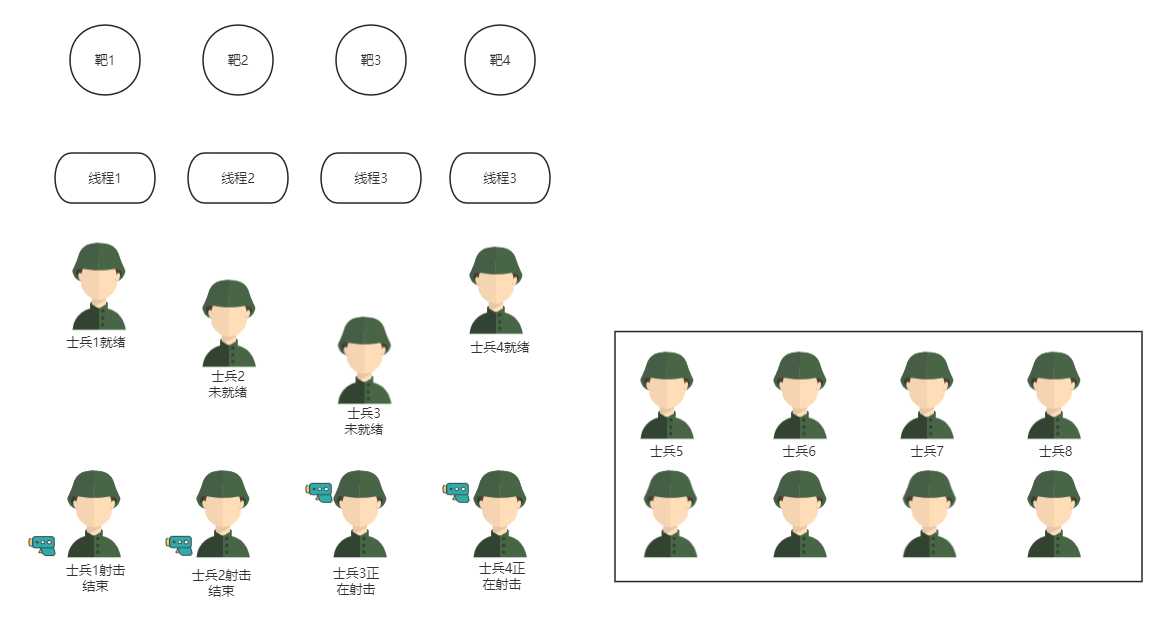
Java多线程编程-栅栏CyclicBarrier实例
前言 本文是基于《Java多线程编程实战指南-核心篇》第五章个人理解,源码是摘抄作者的源码,源码会加上自己的理解。读书笔记目前笔者正在更新如下, 《Java多线程编程实战指南-核心篇》,《How Tomcat Works》,再到《spr…...
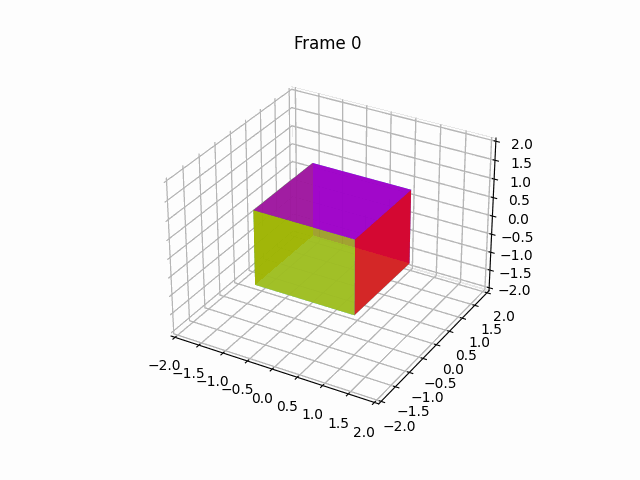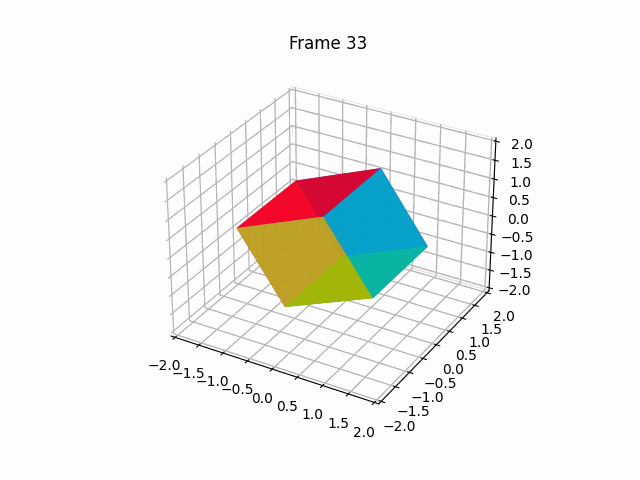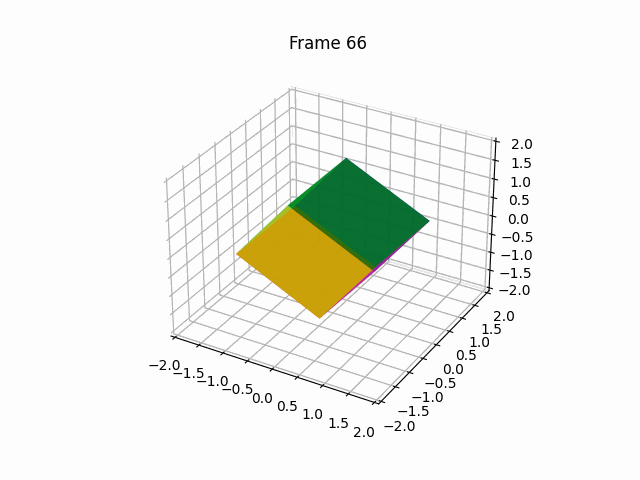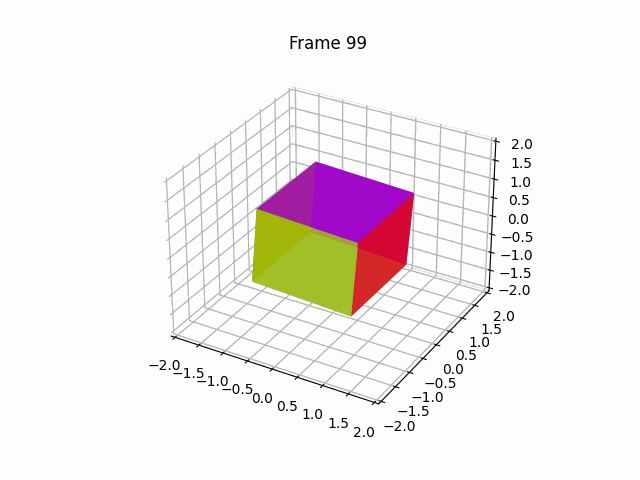
【100天精通Python】Day67:Python可视化_Matplotlib 绘制动画,2D、3D 动画 示例+代码
1 绘制2D动画(animation) Matplotlib是一个Python绘图库,它提供了丰富的绘图功能,包括绘制动画。要绘制动画,Matplotlib提供了FuncAnimation类,允许您创建基于函数的动画。下面是一个详细的Matplotlib动画示…...

变量、常量以及与其他语言的差异 - Go语言从入门到实战
知识点 源码文件以_test结尾:xxx_test.go测试方法名以Test开头:func TestXXX(t *testing.T){…} 利用单元测试来写代码段,保存之后会自动运行程序返回结果,可以快速实践得到反馈。 编写测试程序 接下来练习一下,怎…...
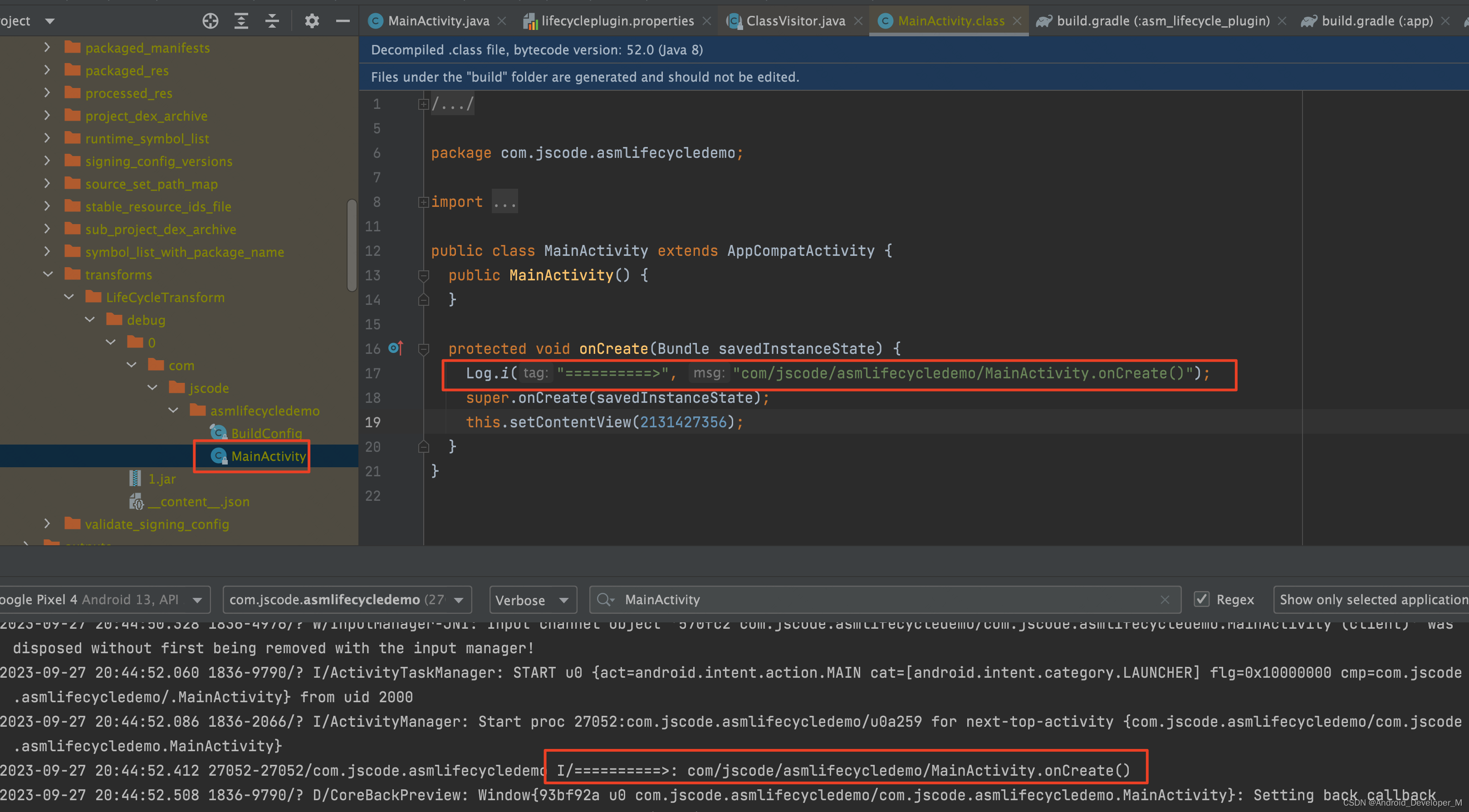
Android 编译插桩操纵字节码
本文讲解如何编译插桩操纵字节码。 就使用 ASM 来实现简单的编译插桩效果,通过插桩实现在每一个 Activity 打开时输出相应的 log 日志。实现思路 过程主要包含两步: 1、遍历项目中所有的 .class 文件 如何找到项目中编译生成的所有 .class 文件&#…...
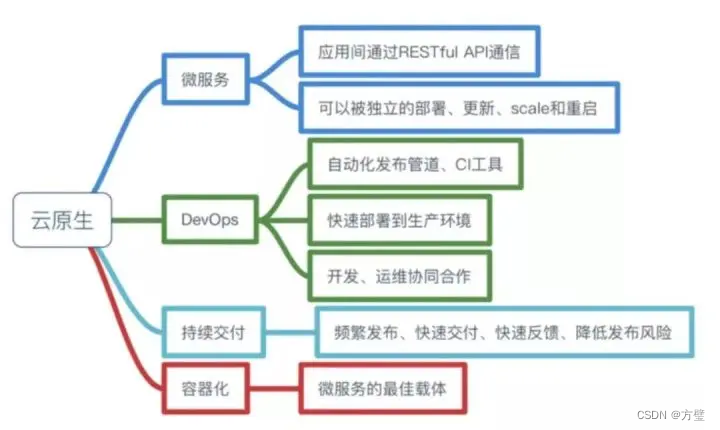
云原生的简单理解
一、何谓云原生? 一种构建和运行应用软件的方法 应用程序从设计之初即考虑到云的环境,原生为云而设计,在云上以最佳姿势运行,充分利用和发挥云平台的弹性分布式优势。 二、包括以下四个要素 采用容器化部署:实现云平…...
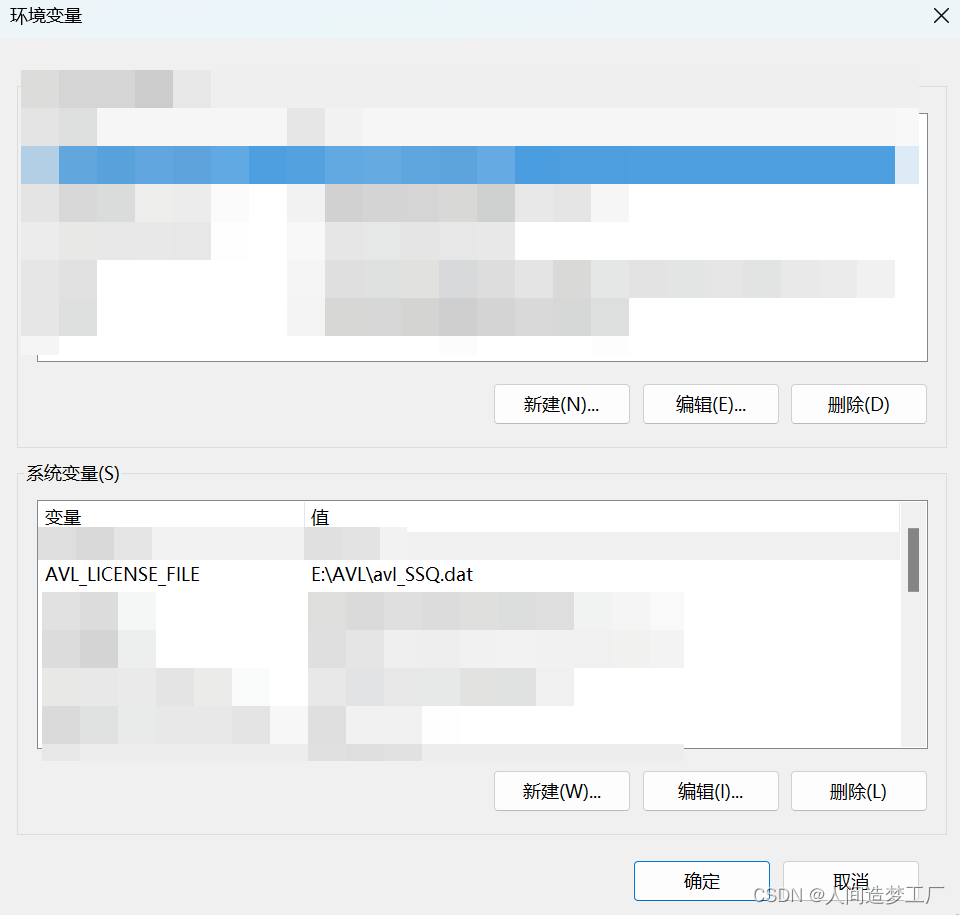
AVL Cruise 2020.1 安装教程
文章目录 安装包安装破解 安装包 链接:https://pan.baidu.com/s/1GxbeDj_SyvKFyPeTsstvTQ?pwd6666 提取码:6666 安装 安装文件: 双击setup.exe: 一直netx,中间要修改两次路径,第一次是安装位置…...

数组07-滑动窗口、HashMap
LeetCode——904. 水果成篮 你正在探访一家农场,农场从左到右种植了一排果树。这些树用一个整数数组 fruits 表示,其中 fruits[i] 是第 i 棵树上的水果 种类 。 你想要尽可能多地收集水果。然而,农场的主人设定了一些严格的规矩,…...
【C++杂货店】类和对象(上)
【C杂货店】类和对象(上) 一、面向过程和面向对象初步认识二、类的引入三、类的定义四、类的访问限定符及封装4.1 访问限定符4.2 封装 五、类的作用域六、类的实例化七、类对象模型7.1 类对象的存储规则7.2 例题7.3结构体内存对齐规则 八、this指针8.2 t…...
K8S笔记
...
数字化IT架构蓝图规划设计方案(附下载方式))
(122页PPT)数字化IT架构蓝图规划设计方案(附下载方式)
篇幅所限,本文只提供部分资料内容,完整资料请看下面链接 https://download.csdn.net/download/2501_92796370/92683861 资料解读:数字化 IT 架构蓝图规划设计方案 详细资料请看本解读文章的最后内容 在数字化转型浪潮下,运营商…...

碧蓝航线Alas自动化脚本:10分钟解放双手的智能游戏助手
碧蓝航线Alas自动化脚本:10分钟解放双手的智能游戏助手 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为每…...
)
STM32CubeMX实战:FSMC高效驱动ILI9488 LCD屏(基于STM32F407)
1. 环境准备与硬件连接 在开始配置FSMC驱动ILI9488 LCD屏之前,我们需要准备好开发环境和硬件设备。我使用的是STM32F407VET6核心板搭配3.5寸320x480分辨率的ILI9488控制器TFT LCD屏幕。这种组合在工业控制和消费电子领域非常常见,性价比高且性能稳定。 硬…...

程序员35岁转型记:我如何成为AI产品经理?
当“质量守卫者”遇见职业天花板如果你是一名软件测试工程师,你一定熟悉这样的场景:凌晨三点还在盯着自动化脚本的运行日志,白天反复和开发争论一个缺陷的定级,周报里写满了用例覆盖率和漏测率,但晋升答辩时评委却问你…...

冒险岛WZ文件解析:从数据迷宫到资源宝库的完整指南
冒险岛WZ文件解析:从数据迷宫到资源宝库的完整指南 【免费下载链接】WzComparerR2 Maplestory online Extractor 项目地址: https://gitcode.com/gh_mirrors/wz/WzComparerR2 你是否曾经好奇冒险岛游戏中那些精美的角色装备、华丽的地图场景和丰富的UI界面是…...

怎么快速降AI率?答辩前1周从60%降到10%以内实操指南!
怎么快速降AI率?答辩前1周从60%降到10%以内实操指南! 答辩前 1 周拿到 AI 率 65% 报告,是什么具体场景? 周一早上 9 点。我硕士答辩定在下周一上午 9 点——还有整整 7 天。导师周日晚发消息:「答辩前再送一次维普看…...
【Transformer系列】从One-Hot到Embedding:构建AI语言理解的基石
1. 从One-Hot编码说起:AI的第一堂语言课 想象你正在教一个外星人认识汉字。你拿出一本字典说:"这里有10万个字,每个字对应一个编号,猫是第12345号,狗是第67890号。"这就是最原始的One-Hot编码思想——用一串…...

紧急预警:2024Q3起PlayAI将下线v2.1旧版翻译协议!迁移倒计时47天,5类遗留系统升级避坑手册
更多请点击: https://intelliparadigm.com 第一章:PlayAI多语种同步翻译功能详解 PlayAI 的多语种同步翻译功能基于端到端神经机器翻译(NMT)架构与实时语音流处理引擎深度融合,支持中、英、日、韩、法、西、德、俄等…...

基于MCP协议构建AI记忆管理服务:原理、实现与应用实践
1. 项目概述:一个为AI应用量身定制的记忆管理工具最近在折腾AI应用开发,特别是那些需要长期对话或上下文关联的场景时,一个绕不开的痛点就是“记忆”问题。模型本身是健忘的,每次对话都是全新的开始。为了让AI能记住用户偏好、历史…...

B站成分检测器:3秒洞察评论区用户真实身份的智能工具
B站成分检测器:3秒洞察评论区用户真实身份的智能工具 【免费下载链接】bilibili-comment-checker B站评论区自动标注成分,支持动态和关注识别以及手动输入 UID 识别 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-comment-checker 在B站…...