Kafka 常见问题
文章目录
- kafka 如何确保消息的可靠性传输
- Kafka 高性能的体现
- 利用Partition实现并行处理
- 利用PageCache
- 如何提高 Kafka 性能
- 调整内核参数来优化IO性能
- 减少网络开销批处理
- 数据压缩降低网络负载
- 高效的序列化方式
kafka 如何确保消息的可靠性传输
消费端弄丢了数据
唯一可能导致消费者弄丢数据的情况,就是消费到了这个消息,然后还没处理就自动提交了offset,让kafka以为你已经消费好了这个消息。
对于消费端来说只要关闭自动提交offset,在处理完之后自己手动提交offset,就可以保证数据不会丢。但是此时确实还是会重复消费,比如你刚处理完,还没提交offset,结果自己挂了,此时肯定会重复消费一次,自己保证幂等性就好了。
kafka弄丢了数据
这块比较常见的一个场景:kafka某个broker宕机,然后重新选举partiton的leader,此时其他的follower刚好还有些数据没有同步,就少了一些数据。
一般要求设置如下4个参数:
给这个topic设置replication.factor参数:这个值必须大于1,要求每个partition必须有至少2个副本。
在kafka服务端设置min.insync.replicas参数:这个值必须大于1,这个是要求一个leader至少感知到有至少一个follower还跟自己保持联系,没掉队,这样才能确保leader挂了还有一个follower吧。
在producer端设置acks=all:这个是要求每条数据,必须是写入所有replica之后,才能认为是写成功了。
在producer端设置retries=MAX(很大很大很大的一个值,无限次重试的意思):这个是要求一旦写入失败,就无限重试,卡在这里了。
生产者会不会弄丢数据
如果按照上述的思路设置了ack=all,一定不会丢leader接收到消息,所有的follower都同步到了消息之后,才认为本次写成功了。如果没满足这个条件,生产者会自动不断的重试,重试无限次。
Kafka 高性能的体现
利用Partition实现并行处理
Kafka中每个Topic都包含一个或多个Partition,不同Partition可位于不同节点。同时Partition在物理上对应一个本地文件夹,每个Partition包含一个或多个Segment,每个Segment包含一个数据文件和一个与之对应的索引文件。在逻辑上,可以把一个Partition当作一个非常长的数组,可通过这个“数组”的索引(offset)去访问其数据。
一方面,由于不同Partition可位于不同机器,因此可以充分利用集群优势,实现机器间的并行处理。另一方面,由于Partition在物理上对应一个文件夹,即使多个Partition位于同一个节点,也可通过配置让同一节点上的不同Partition置于不同的disk drive上,从而实现磁盘间的并行处理,充分发挥多磁盘的优势。
利用多磁盘的具体方法是,将不同磁盘mount到不同目录,然后在server.properties中,将log.dirs设置为多目录(用逗号分隔)。Kafka会自动将所有Partition尽可能均匀分配到不同目录也即不同目录(也即不同disk)上。
Partition是最小并发粒度,Partition个数决定了可能的最大并行度。
利用PageCache
Page Cache,又称pcache,其中文名称为页高速缓冲存储器,简称页高缓。page cache的大小为一页,通常为4K。在linux读写文件时,它用于缓存文件的逻辑内容,从而加快对磁盘上映像和数据的访问。 是Linux操作系统的一个特色。
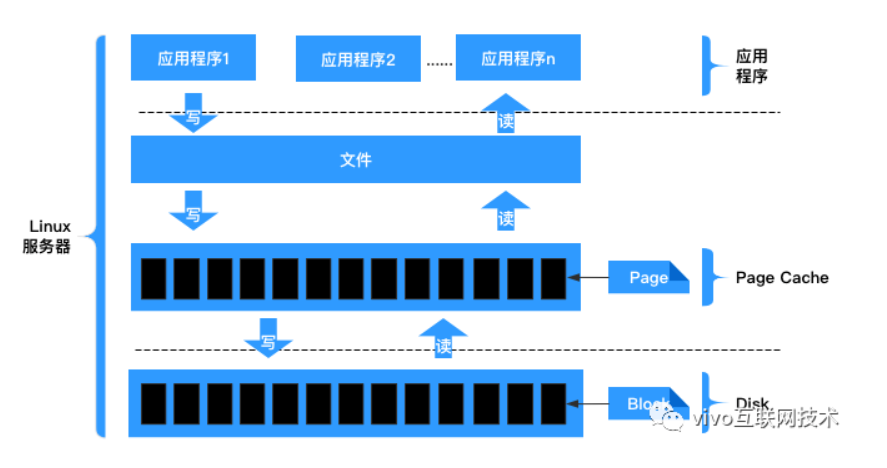
读Cache
当内核发起一个读请求时(例如进程发起read()请求),首先会检查请求的数据是否缓存到了Page Cache中。
如果有,那么直接从内存中读取,不需要访问磁盘,这被称为cache命中(cache hit);
如果cache中没有请求的数据,即cache未命中(cache miss),就必须从磁盘中读取数据。然后内核将读取的数据缓存到cache中,这样后续的读请求就可以命中cache了。
page可以只缓存一个文件部分的内容,不需要把整个文件都缓存进来。
写Cache
当内核发起一个写请求时(例如进程发起write()请求),同样是直接往cache中写入,后备存储中的内容不会直接更新(当服务器出现断电关机时,存在数据丢失风险)。
内核会将被写入的page标记为dirty,并将其加入dirty list中。内核会周期性地将dirty list中的page写回到磁盘上,从而使磁盘上的数据和内存中缓存的数据一致。
当满足以下两个条件之一将触发脏数据刷新到磁盘操作:
- 数据存在的时间超过了dirty_expire_centisecs(默认300厘秒,即30秒)时间;
- 脏数据所占内存 > dirty_background_ratio,也就是说当脏数据所占用的内存占总内存的比例超过dirty_background_ratio(默认10,即系统内存的10%)的时候会触发pdflush刷新脏数据。
如何查看Page Cache参数
执行命令 sysctl -a|grep dirty
如何提高 Kafka 性能
调整内核参数来优化IO性能
1.vm.dirty_background_ratio参数优化
这个参数指定了当文件系统缓存脏页数量达到系统内存百分之多少时(如5%)就会触发后台回写进程运行,将一定缓存的脏页异步地刷入磁盘;
当cached中缓存当数据占总内存的比例达到这个参数设定的值时将触发刷磁盘操作。
把这个参数适当调小,这样可以把原来一个大的IO刷盘操作变为多个小的IO刷盘操作,从而把IO写峰值削平。对于内存很大和磁盘性能比较差的服务器,应该把这个值设置的小一点。
2.vm.dirty_ratio参数优化
这个参数则指定了当文件系统缓存脏页数量达到系统内存百分之多少时(如10%),系统不得不开始处理缓存脏页(因为此时脏页数量已经比较多,为了避免数据丢失需要将一定脏页刷入外存);在此过程中很多应用进程可能会因为系统转而处理文件IO而阻塞。
对于写压力特别大的,建议把这个参数适当调大;对于写压力小的可以适当调小;如果cached的数据所占比例(这里是占总内存的比例)超过这个设置,
系统会停止所有的应用层的IO写操作,等待刷完数据后恢复IO。所以万一触发了系统的这个操作,对于用户来说影响非常大的。
3.vm.dirty_expire_centisecs参数优化
这个参数会和参数vm.dirty_background_ratio一起来作用,一个表示大小比例,一个表示时间;即满足其中任何一个的条件都达到刷盘的条件。
为什么要这么设计呢?如果只有参数 vm.dirty_background_ratio ,也就是说cache中的数据需要超过这个阀值才会满足刷磁盘的条件;如果数据一直没有达到这个阀值,那相当于cache中的数据就永远无法持久化到磁盘,这种情况下,一旦服务器重启,那么cache中的数据必然丢失。
结合以上情况,所以添加了一个数据过期时间参数。当数据量没有达到阀值,但是达到了我们设定的过期时间,同样可以实现数据刷盘。
4.vm.dirty_writeback_centisecs参数优化
理论上调小这个参数,可以提高刷磁盘的频率,从而尽快把脏数据刷新到磁盘上。但一定要保证间隔时间内一定可以让数据刷盘完成。
5.vm.swappiness参数优化
禁用swap空间,设置vm.swappiness=0
减少网络开销批处理
批处理是一种常用的用于提高I/O性能的方式。对Kafka而言,批处理既减少了网络传输的Overhead,又提高了写磁盘的效率。
Kafka 的send方法并非立即将消息发送出去,而是通过batch.size和linger.ms控制实际发送频率,从而实现批量发送。
由于每次网络传输,除了传输消息本身以外,还要传输非常多的网络协议本身的一些内容(称为Overhead),所以将多条消息合并到一起传输,可有效减少网络传输的Overhead,进而提高了传输效率。
数据压缩降低网络负载
Kafka支持将数据压缩后再传输给Broker。除了可以将每条消息单独压缩然后传输外,Kafka还支持在批量发送时,将整个Batch的消息一起压缩后传输。数据压缩的一个基本原理是,重复数据越多压缩效果越好。因此将整个Batch的数据一起压缩能更大幅度减小数据量,从而更大程度提高网络传输效率。
Broker接收消息后,并不直接解压缩,而是直接将消息以压缩后的形式持久化到磁盘。Consumer Fetch到数据后再解压缩。因此Kafka的压缩不仅减少了Producer到Broker的网络传输负载,同时也降低了Broker磁盘操作的负载,也降低了Consumer与Broker间的网络传输量,从而极大得提高了传输效率,提高了吞吐量。
高效的序列化方式
Kafka消息的Key和Value的类型可自定义,只需同时提供相应的序列化器和反序列化器即可。
因此用户可以通过使用快速且紧凑的序列化-反序列化方式(如Avro,Protocal Buffer)来减少实际网络传输和磁盘存储的数据规模,从而提高吞吐率。这里要注意,如果使用的序列化方法太慢,即使压缩比非常高,最终的效率也不一定高。
相关文章:
Kafka 常见问题
文章目录 kafka 如何确保消息的可靠性传输Kafka 高性能的体现利用Partition实现并行处理利用PageCache 如何提高 Kafka 性能调整内核参数来优化IO性能减少网络开销批处理数据压缩降低网络负载高效的序列化方式 kafka 如何确保消息的可靠性传输 消费端弄丢了数据 唯一可能导致…...

如何去开展软件测试工作
1. 软件测试 在一般的项目中,一开始均为手动测试,由于自动化测试前期投入较大,一般要软件项目达到一定的规模,更新频次和质量均有一定要求时才会上自动化测试或软件测试。 1.1. 项目中每个成员的测试职责 软件测试从来不是某一…...
详解如何在python中实现简单的app自动化框架
一、app自动化环境搭建 1、安装jdk及配置jdk的环境变量 app底层是c语言,应用层是java,所以需要jdk 2、安装SDK,配置android SDK环境 3、安装模拟器 4、下载安装Appium工具 01、appium客户端 appium destop 服务器 02、命令行安装&#…...
【TCP】三次握手 与 四次挥手 详解
三次握手 与 四次挥手 1. 三次握手2. 四次挥手三次握手和四次挥手的区别 在正常情况下,TCP 要经过三次握手建立连接,四次挥手断开连接 1. 三次握手 服务端状态转化: [CLOSED -> LISTEN] 服务器端调用 listen 后进入 LISTEN 状态ÿ…...

正则表达式新解
文章目录 是什么?正则用法匹配单个字符匹配一组字符其他元字符核心函数 贪婪匹配和非贪婪匹配正则练习 是什么? 正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊…...
MissionPlanner编译过程
环境 windows 10 mission planner 1.3.80 visual studio 2022 git 2.22.0 下载源码 (已配置git和ssh) 从github上克隆源码 git clone gitgithub.com:ArduPilot/MissionPlanner.git进入根目录 cd MissionPlanner在根目录下的ExtLibs文件下是链接的其它github源码࿰…...

SpringBoot 员工管理---通用模板 ---苍穹外卖day2
感谢点击 希望你有所收获! 目录 1.新增员工 需求分析:根据页面原型进行业务分析 接口设计 数据库设计 代码开发 功能测试 如何在接口文档中统一添加JWT令牌 获取当前登录员工的ID 2.员工分页查询 需求分析 代码开发 如何将日期格式化 3.启用禁用员工 1.新…...
可信执行环境(Tee)入门综述
SoK: Hardware-supported Trusted Execution Environments [ArXiv22] 摘要引言贡献 范围系统和威胁模型系统模型威胁模型共存飞地对手无特权软件对手系统软件对手启动对手外围对手结构对手侵入性对手 关于侧信道攻击的一点注记 VERIFIABLE LAUNCH信任根(RTM…...

Java浮点运算为什么不精确
有的时候博客内容会有变动,首发博客是最新的,其他博客地址可能会未同步,认准https://blog.zysicyj.top 首发博客地址[1] 面试题手册[2] 系列文章地址[3] 1. 什么是 Java 浮点运算? 在 Java 中,浮点运算指的是对浮点数进行加减乘除等基本运算…...
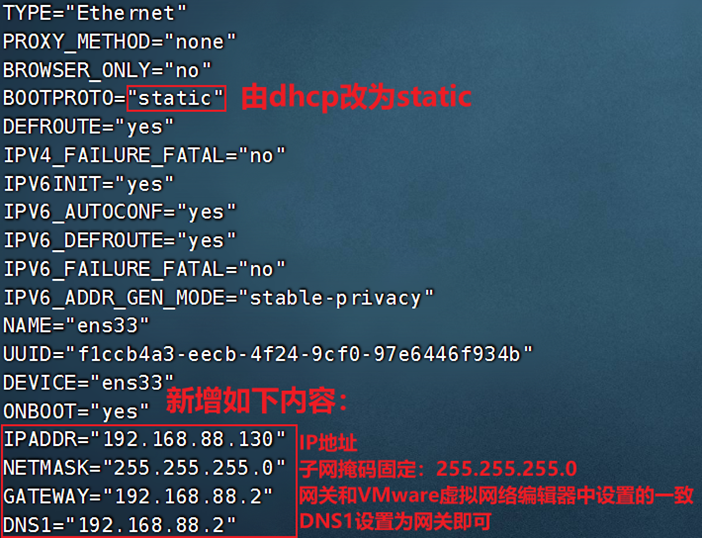
linux使用操作[1]
文章目录 版权声明快捷键ctrl c 强制停止ctrl d 退出、登出history命令光标移动快捷键清屏快捷键 软件安装命令常见linux系统包管理器yum命令apt命令 systemctl命令软连接日期&时区修改linux时区ntp程序 IP地址&主机名ip&主机名域名解析win配置主机名映射虚拟机…...

权限提升Linux篇
提权工具 https://github.com/liamg/traitor https://github.com/AlessandroZ/BeRoot https://github.com/rebootuser/LinEnum https://github.com/mzet-/linux-exploit-suggester https://github.com/sleventyeleven/linuxprivchecker https://github.com/jondonas/linux…...

影刀自动化采集底层逻辑
hello,大家好,这里是【玩数据的诡途】 接上回 <我的影刀故事> 今天给大家介绍一下整个采集的底层逻辑,包括业务流程自动化也是基于这一套基础逻辑进行展开的,顺便带大家熟悉一下影刀,既然叫影刀系列了,那后续一些…...

swiper使用
介绍 Swiper(swiper master)是一个第三方的库,可以用来实现移动端、pc端的滑动操作。,swiper应用广泛,使用频率仅次于jquery, 轮播图类排名第一,是网页设计师必备技能,众多耳熟能详的品牌在使用…...
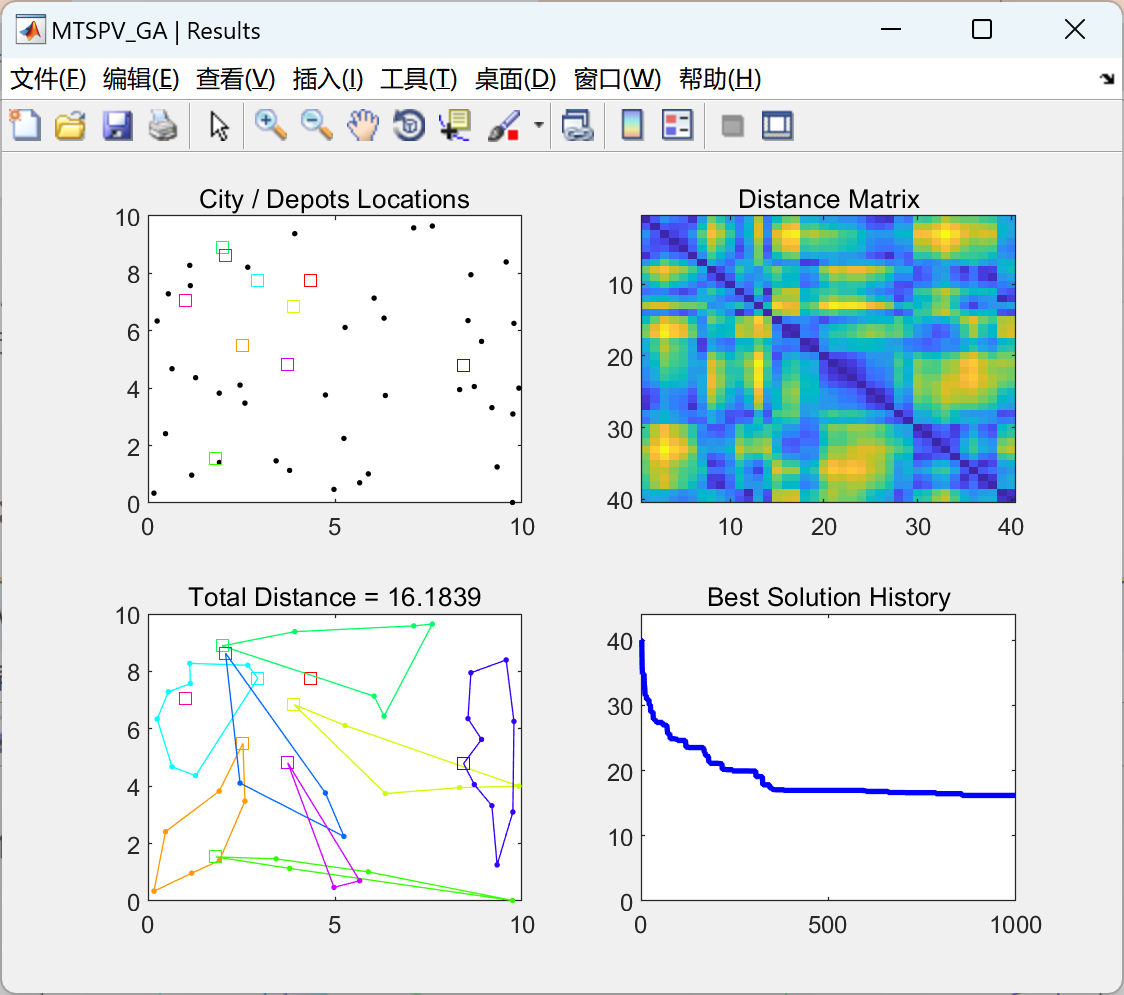
基于遗传算法解决的多仓库多旅行推销员问题(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
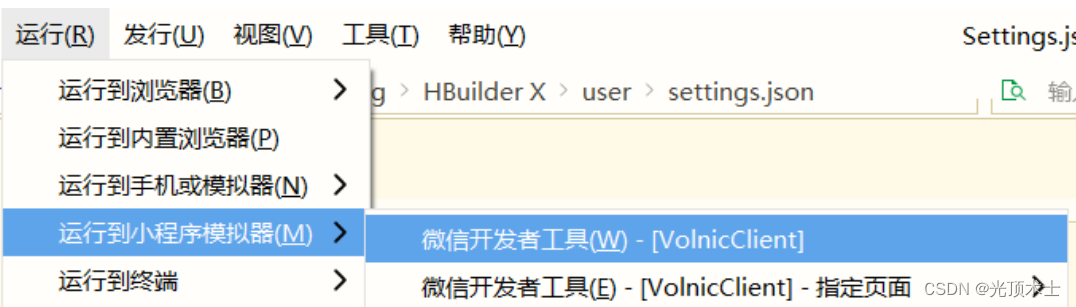
微信小程序 工具使用(HBuilderX)
微信小程序 工具使用:HBuilderX 一 HBuilderX 的下载二 工具的配置2.1 工具 --> 设置 --> 运行配置2.1.1 微信开发者工具路径2.1.2 node 运行配置 2.2 插件 工具 --> 插件安装2.2.1 下载插件 三 微信小程序端四 同步运行五 BUG5.1 nodemon在终端无法识别 一 HBuilderX…...
)
设计模式:观察者模式(C++实现)
观察者模式(Observer Pattern)是一种设计模式,用于定义对象之间的一对多依赖关系,当一个对象(称为主题或可观察者)的状态发生变化时,它的所有依赖对象(称为观察者)都会收…...

【前端打怪升级日志之微前端框架篇】微前端qiankun框架子应用间跳转方法
参考链接qiankun官网:微应用之间如何跳转? 1.主应用、子应用路由都是hash模式 主应用根据 hash 来判断微应用,无需考虑该问题 2.主应用根据path判断子应用 方法实现适用条件参数传递存在问题a标签跳转<a href"/toA"></…...

C语言中的typedef struct用法
在学习数据结构的时候,我经常遇到typedef struct,刚开始感觉很别扭,查阅资料之后才真真理解了。 先从结构体说起。 1、结构体用法 struct Student{int age;char s;}如果要定义一个该结构体变量,就需要:struct Student st1; 有没…...

司徒理财:9.27黄金原油日内多空走势行情操作建议
黄金走势分析: 黄金昨日抵达了此前一直强调的日线布林下轨的1903位置,甚至更低!昨天的空单也是直接获利收割了!现在如果是要继续做空,下方是有日线支撑的,甚至周线的支撑也不远,在1890…...
)
C++设计模式(Design Patterns)
设计模式主要原则 单一职责原则(Single Responsibility Principle) 实现类要职责单一 里氏替换原则(Liskov Substitution Principle) 不要破坏继承关系 依赖倒置原则(Dependence Inversion Principle) …...

杰理之似于“PO”声,如果切换的时机刚好在音量较高的时候,比较容易出现【篇】
似于“PO”声,如果切换的时机刚好在音量较高的时候,比较容易出现...

超级记忆与智能体框架:构建LLM长期记忆系统的开源实践
1. 项目概述与核心价值最近在折腾个人知识库和AI工具链的朋友,估计都绕不开一个核心痛点:如何让AI真正“理解”并记住我们给它的私有信息。无论是想打造一个能回答公司内部文档问题的智能助手,还是想构建一个能基于个人笔记进行深度对话的聊天…...

Arduino驱动多LED矩阵:I2C总线与位图编程实现动态表情动画
1. 项目概述:用Arduino驱动多个LED矩阵,打造动态表情动画如果你玩过Arduino和LED点阵,大概都体验过点亮单个8x8矩阵的乐趣——显示个字符、画个简单图案。但当你想要做一个更酷的项目,比如一个能眨眼、能变换嘴型的机器人脸&#…...

达梦数据库主备集群手工搭建及主备切换演练
环境:DM8、Linux(CentOS 7 ),三台服务器。 本文记录从零搭一套"一主一备一监视" 式的主备集群,纯手工操作,不依赖图形化工具。 一、环境规划 1.1 IP规划 角色主机名业务IP心跳IP实例名主库&…...

034、LVGL默认主题与自定义主题
LVGL默认主题与自定义主题 一次UI“变脸”引发的血案 上周调试一块基于STM32F429的智能家居面板,LVGL版本8.3.5。客户要求界面风格从“科技蓝”改成“暖木色”,我心想不就是改个颜色主题嘛,简单。结果改完lv_conf.h里的LV_THEME_DEFAULT_COLOR_PRIMARY,编译下载,屏幕一亮…...

ARM Cortex-M0+极限性能优化:从超频到外设压榨的嵌入式实战
1. 项目概述:一次基于经典平台的极限性能探索“飞思卡尔Freedom打造新记录!”这个标题,对于很多嵌入式领域的老兵而言,瞬间就能勾起一段充满挑战与激情的回忆。飞思卡尔(Freescale,现为NXP的一部分…...

我靠技术博客,从无人问津到拿到硅谷offer
在软件测试这个领域,我们常常自嘲是“质量守门员”,却很少把自己当作技术的创造者与传播者。三年前,我和大多数测试同行一样,每天重复着用例设计、手工执行、提交缺陷的循环,偶尔写点自动化脚本,也仅止于“…...

Win11内存完整性报错?手把手教你定位并安全移除不兼容驱动程序
1. 遇到Win11内存完整性警告怎么办? 最近很多升级到Windows 11的用户都遇到了一个让人头疼的问题——系统右下角突然弹出"内存完整性已关闭"的安全警告。这个黄色的小三角图标确实挺烦人的,特别是对于像我这样有点强迫症的用户来说。第一次看到…...
3. 开源纳米级计量检测设备卡点)
0403开源:第四卷光刻机整机控制与量检测系统(A级 中期集中攻坚)3. 开源纳米级计量检测设备卡点
开源光刻机整机控制与量检测系统(A级 中期集中攻坚) 3. 开源纳米级计量检测设备卡点(全参数开源硬核壁垒拆解喂饭级溯源破局) 前置开源声明 本节全程无保留开源光刻量检测底层原理、设备架构、纳米级计量阈值、国内外参数对标、核…...

d2s-editor:暗黑破坏神2存档修改终极实战宝典
d2s-editor:暗黑破坏神2存档修改终极实战宝典 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 还在为暗黑破坏神2的刷装备、练级、属性点分配而烦恼吗?d2s-editor为你带来全新的单机游戏体验——这是一款基…...