【操作系统】调度算法的评价指标和三种调度算法

🐌个人主页: 🐌 叶落闲庭
💨我的专栏:💨
c语言
数据结构
javaEE
操作系统
Redis
石可破也,而不可夺坚;丹可磨也,而不可夺赤。
操作系统
- 一、调度算法的评价指标
- 1.1 CPU利用率
- 1.2 系统吞吐量
- 1.3 周转时间
- 1.4 等待时间
- 1.5 响应时间
- 二、 调度算法
- 2.1 先来先服务(FCFS)
- 2.2 短作业优先(SJF)
- 2.3 高响应比优先(HRRN)
一、调度算法的评价指标
1.1 CPU利用率
- 由于早期的CPU造价极其昂贵,因此人们会希望让CPU尽可能多地工作
- CPU利用率:指CPU“忙碌”的时间占总时间的比例。
利用率 = 忙碌的时间 / 总时间- Eg:某计算机只支持单道程序,某个作业刚开始需要在CPU上运行5秒再用打印机打印输出5秒,之后再执行5秒,才能结束。在此过程中,CPU利用率、打印机利用率分别是多少?
-
- CPU利用率 = (5 + 5) / (5 + 5 + 5) = 66.66%
-
- 打印机利用率 = 5 / (5 + 5 + 5 ) = 33.33%
1.2 系统吞吐量
- 对于计算机来说,希望能用尽可能少的时间处理完尽可能多的作业
- 系统吞吐量:单位时间内完成作业的数量
- 系统吞吐量 = 总共完成了多少道作业 / 总共花了多少时间
-
- Eg:某计算机系统处理完10道作业,共花费100秒,则系统吞吐量为?
-
-
- 10/100=0.1道/秒
-
1.3 周转时间
- 对于计算机的用户来说,他很关心自己的作业从提交到完成花了多少时间。
- 周转时间,是指从作业被提交给系统开始,到作业完成为止的这段时间间隔。
- 它包括四个部分:作业在外存后备队列上等待作业调度(高级调度)的时间、进程在就绪队列上等待进程调度(低级调度)的时间、进程在CPU上执行的时间、进程等待/O操作完成的时间。后三项在一个作业的整个处理过程中,可能发生多次。
- (作业)周转时间 = 作业完成时间 - 作业提交时间
- 对于用户来说,更关心自己的单个作业的周转时间
- 平均周转时间= 各作业周转时间之和 / 作业数
- 对于操作系统来说,更关心系统的整体表现,因此更关心所有作业周转时间的平均值
- 带权周转时间 = 作业周转时间 / 作业实际运行的时间 = (作业完成时间 - 作业提交时间)/ 作业实际运行的时间
- 对于周转时间相同的两个作业,实际运行时间长的作业在相同时间内被服务的时间更多带权周转时间更小,用户满意度更高
- 对于实际运行时间相同的两个作业,周转时间短的带权周转时间更小,用户满意度更高
- 平均带权周转时间 = 各作业带权周转时间之和 / 作业数
1.4 等待时间
- 计算机的用户希望自己的作业尽可能少的等待处理机
- 等待时间,指进程/作业处于等待处理机状态时间之和,等待时间越长,用户满意度越低。
- 对于进程来说,等待时间就是指进程建立后等待被服务的时间之和,在等待/O完成的期间其实进程也是在被服务的,所以不计入等待时间。
- 一个作业总共需要被CU服务多久,被I/O设备服务多久一般是确定不变的,因此调度算法其实只会影响作业/进程的等待时间。当然,与前面指标类似,也有“平均等待时间”来评价整体性能。
1.5 响应时间
- 对于计算机用户来说,会希望自己的提交的请求(比如通过键盘输入了一个调试命令)尽早地开始被系
统服务、回应。 - 响应时间,指从用户提交请求到首次产生响应所用的时间。
二、 调度算法
2.1 先来先服务(FCFS)
例题:各进程到达就绪队列的时间、需要的运行时间如下表示。使用先来先服务调度算法,计算各进程的等待时间、平均等待时间、周转时间、平均周转时间、带权周转时间、平均带权周转时间。
| 进程 | 到达时间 | 运行时间 |
|---|---|---|
| P1 | 0 | 7 |
| P2 | 2 | 4 |
| P3 | 4 | 1 |
| P4 | 5 | 4 |
- 先来先服务调度算法:按照到达的先后顺序调度,事实上就是等待时间越久的越优先得到服务。
- 因此,调度顺序为:P1→P2→P3→P4

- 周转时间 = 完成时间 - 到达时间
- 周转时间: P1=7-0=7;P2=11-2=9:P3=12-4=8;P4=16-5=11
- 带权周转时间 = 周转时间 / 运行时间
- 带权周转时间:P1=7/7=1;2=9/4=2.25;P3=8/1=8;P4=11/4=2.75
- 等待时间 = 周转时间 - 运行时间
- 等待时间:P1=7-7=0;P2=9-4=5;P3=8-1=7;P4=11-4=7
- 平均周转时间=(7+9+8+11)/4=8.75
- 平均带权周转时间=(1+2.25+8+2.75)/4=3.5
- 平均等待时间=(0+5+7+7)/4=4.75
- 优点:公平、算法实现简单
- 缺点:排在长作业(进程)后面的短作业需要等待很长时间,带权周转时间很大,对短作业来说用户体验不好。即,FCFS算法对长作业有利,对短作业不利
2.2 短作业优先(SJF)
- 算法思想:
-
- 追求最少的平均等待时间,最少的平均周转时间、最少的平均平均带权周转时间
- 算法规则:
-
- 最短的作业/进程优先得到服务(所谓“最短”,是指要求服务时间最短)
- 用于作业/进程调度:
-
- 即可用于作业调度,也可用于进程调度。用于进程调度时称为“短进程优先(SPE,Shortest Process First)算法”
- SJF和SPF是非抢占式的算法。但是也有抢占式的版本一一最短剩余时间优先算法(SRTN,Shortest Remaining Time Next)
例题:各进程到达就绪队列的时间、需要的运行时间如下表示。使用非抢占式的短作业优先调度算法,计算各进程的等待时间、平均等待时间、周转时间、平均周转时间、带权周转时间、平均带权周转时间。
| 进程 | 到达时间 | 运行时间 |
|---|---|---|
| P1 | 0 | 7 |
| P2 | 2 | 4 |
| P3 | 4 | 1 |
| P4 | 5 | 4 |
- 短作业/进程优先调度算法:每次调度时选择当前己到达且运行时间最短的作业/进程。
- 因此,调度顺序为:P1→P3→P2→P4
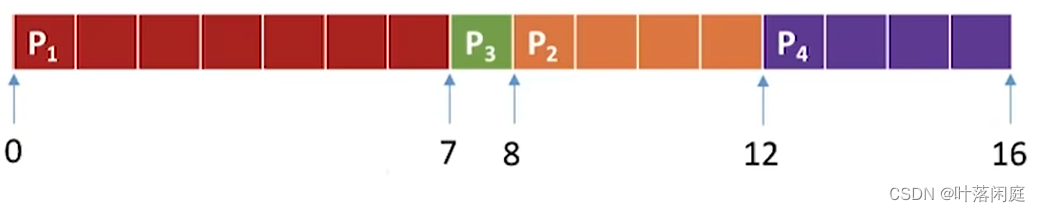
-
周转时间 = 完成时间 - 到达时间
-
周转时间:P1=7-0=7;P3=8-4=4:P2=12-2=10:P4=16-5=11
Access token invalid or no longer valid -
带权周转时间 = 周转时间 / 运行时间
-
带权周转时间:P1=7/7=1;P3=4/1=4;P2=10/4=2.5;P4=11/4=2.75
-
等待时间 = 周转时间 - 运行时间
-
等待时间:P1=7-7=0:P3=4-1=3;P2=10-4=6;P4=11-4=7
-
平均周转时间=(7+4+10+11)/4=8
-
平均带权周转时间=(1+4+2.5+2.75)/4=2.56
-
平均等待时间=(0+3+6+7)/4=4
例题:各进程到达就绪队列的时间、需要的运行时间如下表示。使用抢占式的短作业优先调度算法,计算各进程的等待时间、平均等待时间、周转时间、平均周转时间、带权周转时间、平均带权周转时间。
| 进程 | 到达时间 | 运行时间 |
|---|---|---|
| P1 | 0 | 7 |
| P2 | 2 | 4 |
| P3 | 4 | 1 |
| P4 | 5 | 4 |
- 最短剩余时间优先算法:每当有进程加入就绪队列改变时就需要调度,如果新到达的进程剩余时间比当前运行的进程剩余时间更短,则由新进程抢占处理机,当前运行进程重新回到就绪队列。另外,当一个进程完成时也需要调度

- 周转时间=完成时间-到达时间
- 周转时间:P1=16-0=16:P2=7-2=5:P3=5-4=1:P4=11-5=6
- 带权周转时间=周转时间/运行时间
- 带权周转时间:P1=16/7=2.28;P2=5/4=1.25;P3=1/1=1;P4=6/4=1.5
- 等待时间=周转时间-运行时间
- 等待时间:P1=16-7=9:P2=5-4=1;P3=1-1=0;P4=6-4=2
- 平均周转时间=(16+5+1+6)/4=7
- 平均带权周转时间=(2.28+1.25+1+1.5)/4=1.5
- 平均等待时间=(9+1+0+2)/4=3
- 优点:“最短的”平均等待时间、平均周转时间
- 缺点:不公平。对短作业有利,对长作业不利。可能产生饥饿现象。另外,作业/进程的运行时间是由用户提供的,并不一定真实,不一定能做到真正的短作业优先
- 会导致饥饿,如果源源不断地有短作业/进程到来,可能使长作业/进程长时间得不到服务,产生“饥饿”现象。如果一直得不到服务,则称为“饿死”
2.3 高响应比优先(HRRN)
- 算法思想:
- 要综合考虑作业/进程的等待时间和要求服务的时间
- 算法规则:
- 在每次调度时先计算各个作业/进程的响应比,选择响应比最高的作业/进程为其服务
- 既可用于作业调度,也可用于进程调度
- 非抢占式的算法。因此只有当前运行的作业/进程主动放弃处理机时,才需要调度,才需要计算响应比
- 响应比 = (等待时间+要求服务时间)/ 要求服务时间
例题:各进程到达就绪队列的时间、需要的运行时间如下表示。使用高响应比优先调度算法,计算各进程的等待时间、平均等待时间、周转时间、平均周转时间、带权周转时间、平均带权周转时间。
| 进程 | 到达时间 | 运行时间 |
|---|---|---|
| P1 | 0 | 7 |
| P2 | 2 | 4 |
| P3 | 4 | 1 |
| P4 | 5 | 4 |
- 高响应比优先算法:非抢占式的调度算法,只有当前运行的进程主动放弃CPU时(正常/异常完成,或主动阻塞),才需要进行调度,调度时计算所有就绪进程的响应比,选响应比最高的进程上处理机。
- 0时刻:只有P1到达就绪队列,P1上处理机
- 7时刻(P1主动放弃CPU):就绪队列中有P2(响应比=(5+4)/4=2.25)、P3(3+1)/1=4)、P4(2+4)/4=1.5),
- 8时刻(P3完成):P2(2.5)、P4(1.75)
- 12时刻(P2完成):就绪队列中只剩下P4

- 综合考虑了等待时间和运行时间(要求服务时间)
- 等待时间相同时,要求服务时间短的优先(SF的优点)
- 要求服务时间相同时,等待时间长的优先(FCFS的优点)
- 对于长作业来说,随着等待时间越来越久,其响应比也会越来越大,从而避免了长作业饥饿的问题
相关文章:
【操作系统】调度算法的评价指标和三种调度算法
🐌个人主页: 🐌 叶落闲庭 💨我的专栏:💨 c语言 数据结构 javaEE 操作系统 Redis 石可破也,而不可夺坚;丹可磨也,而不可夺赤。 操作系统 一、调度算法的评价指标1.1 CPU利…...
CSS详细基础(三)复合选择器
前两章介绍了CSS中的基础属性,以及一些基础的选择器,本贴开始介绍复合选择器的内容~ 在 CSS 中,可以根据选择器的类型把选择器分为基础选择器和复合选择器,复合选择器是建立在基础选择器之上,对基本选择器进行组合形…...
LeetCode【2251. 花期内花的数目】
给你一个下标从 0 开始的二维整数数组 flowers ,其中 flowers[i] [starti, endi] 表示第 i 朵花的 花期 从 starti 到 endi (都 包含)。同时给你一个下标从 0 开始大小为 n 的整数数组 people ,people[i] 是第 i 个人来看花的时间…...
:数据可视化(一))
大数据(九):数据可视化(一)
专栏介绍 结合自身经验和内部资料总结的Python教程,每天3-5章,最短1个月就能全方位的完成Python的学习并进行实战开发,学完了定能成为大佬!加油吧!卷起来! 全部文章请访问专栏:《Python全栈教程(0基础)》 再推荐一下最近热更的:《大厂测试高频面试题详解》 该专栏对…...
讲讲项目里的仪表盘编辑器(二)
应用场景 正常来说,编辑器应用场景应该包括: 编辑器-预览 编辑器 最终运行时 怎么去设计 上一篇推文,我们已经大概了解了编辑器场景。接下来,我们来看预览时的设计 编辑器-预览 点击预览按钮,执行以…...
文心一言 VS 讯飞星火 VS chatgpt (102)-- 算法导论9.3 8题
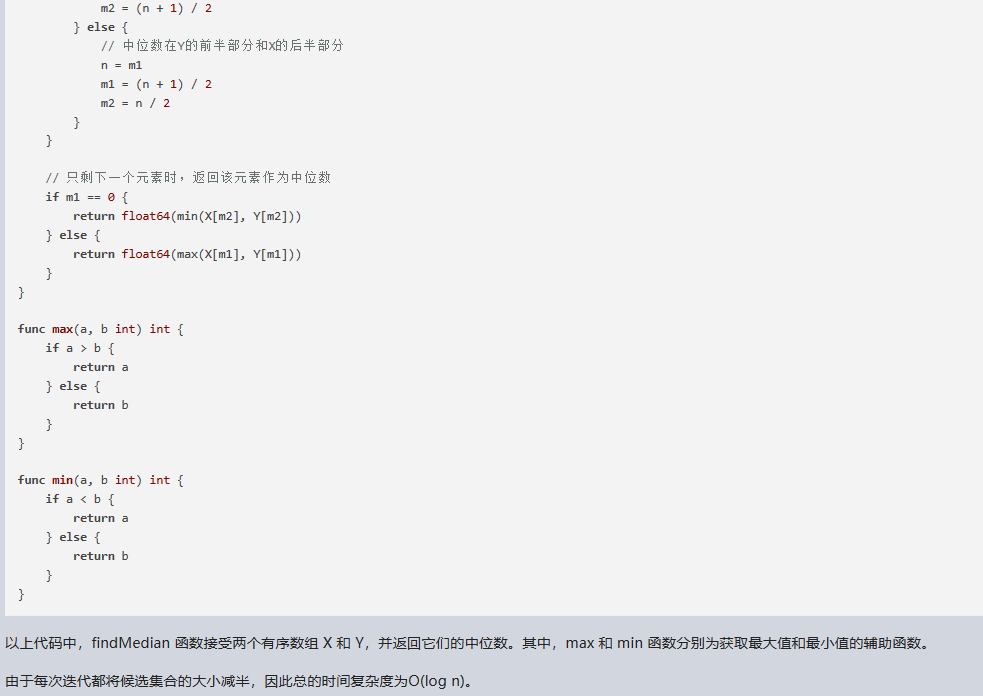
八、用go语言,设 X[1…n]和 Y[1…n]为两个数组,每个都包含n个有序的元素。请设计一个 O(lgn)时间的算法来找出数组 X和Y中所有 2n 个元素的中位数。 文心一言: 要在 O(lgn) 时间内找出两个有序数组 X 和 Y 中所有元素的中位数,可…...

axios添加缓存请求,防止多次请求,单页面多个同一组件造成多次请求解决方案
在axios中,添加 const cacheMap {};响应拦截添加 try {// 删除缓存const api res.config.url.replace(process.env.VUE_APP_BASE_API, "");if (cacheMap.hasOwnProperty(api)) {delete cacheMap[api];}} catch (err) {}创建两个请求方法 /*** Get缓存…...

Java包装类与自动拆箱装箱
有的时候博客内容会有变动,首发博客是最新的,其他博客地址可能会未同步,认准https://blog.zysicyj.top 首发博客地址[1] 面试题手册[2] 系列文章地址[3] 1. 什么是 Java 包装类和自动拆箱装箱? Java 中的基本数据类型(如 int、cha…...
基于SpringBoot网上超市的设计与实现【附万字文档(LW)和搭建文档】
主要功能 前台登录: 注册用户:用户名、密码、姓名、联系电话 用户: ①首页、商品信息推荐、商品资讯、查看更多 ②商品信息、商品详情、评论、点我收藏、添加购物车、立即购买 ③个人中心、余额、点我充值、更新信息、我的订单、我的地址、我…...
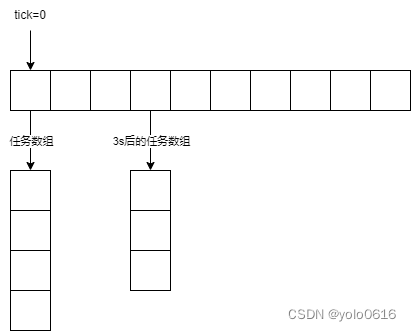
二、C++项目:仿muduo库实现并发服务器之时间轮的设计
文章目录 一、为什么要设计时间轮?(一)简单的秒级定时任务实现:(二)Linux提供给我们的定时器:1.原型2.例子 二、时间轮(一)思想(一)代码 一、为什…...

计算机竞赛 深度学习OCR中文识别 - opencv python
文章目录 0 前言1 课题背景2 实现效果3 文本区域检测网络-CTPN4 文本识别网络-CRNN5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **基于深度学习OCR中文识别系统 ** 该项目较为新颖,适合作为竞赛课题方向,…...

蓝桥等考Python组别五级003
第一部分:选择题 1、Python L5 (15分) 表达式“a >= b”等价于下面哪个表达式?( ) a > b and a == ba > b or a == ba < b and a == ba < b or a > b正确答案:B 2、Python L5 (15分) 当x是偶数时,下面哪个表达式的值一定是True?( …...
学之思项目第一天-完成项目搭建
一、前端 拉下前端代码执行 npm i 然后执行npm run serve就行了 二、后端 搭建父子模块 因为这个涉及到前台以及后台管理所以使用父子模块 并且放置一个公共模块,放置公共的依赖以及公共的代码 2.1 搭建父子工程 这个可以使用直接一个个的maven模块ÿ…...

pandas--->CSV / JSON
csv CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。 CSV 是一种通用的、相对简单的文…...
LeetCode算法二叉树—116. 填充每个节点的下一个右侧节点指针
目录 116. 填充每个节点的下一个右侧节点指针 题解: 代码: 运行结果: 给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下: struct Node {int val;Node *left;N…...
二、2023.9.28.C++基础endC++内存end.2
文章目录 17、说说new和malloc的区别,各自底层实现原理。18、 说说const和define的区别。19、 说说C中函数指针和指针函数的区别?20、 说说const int *a, int const *a, const int a, int *const a, const int *const a分别是什么,有什么特点…...
DevSecOps 将会嵌入 DevOps
通常人们在一个项目行将结束时才会考虑到安全,这么做会导致很多问题;将安全融入到DevOps的工作流中已产生了积极结果。 DevSecOps:安全正当时 一直以来,开发人员在构建软件时认为功能需求优先于安全。虽然安全编码实践起着重要作…...

不同管径地下管线的地质雷达响应特征分析
不同管径地下管线的地质雷达响应特征分析 前言 以混凝土管线为例,建立了不同管径的城市地下管线模型,进行二维地质雷达正演模拟,分析不同管径管线的地质雷达响应特征。 文章目录 不同管径地下管线的地质雷达响应特征分析前言1、管径50cm2、…...

【接口测试学习】白盒测试 接口测试 自动化测试
一、什么是白盒测试 白盒测试是一种测试策略,这种策略允许我们检查程序的内部结构,对程序的逻辑结构进行检查,从中获取测试数据。白盒测试的对象基本是源程序,所以它又称为结构测试或逻辑驱动测试,白盒测试方法一般分为…...
7.网络原理之TCP_IP(下)
文章目录 4.传输层重点协议4.1TCP协议4.1.1TCP协议段格式4.1.2TCP原理4.1.2.1确认应答机制 ACK(安全机制)4.1.2.2超时重传机制(安全机制)4.1.2.3连接管理机制(安全机制)4.1.2.4滑动窗口(效率机制…...

AI创业从模型竞赛到场景落地:2026年生态爆发与实战指南
1. 从HumanX 2026归来:我眼中的AI创业生态爆发图景刚从HumanX 2026的会场回来,整个人还沉浸在那种高速迭代、热气腾腾的氛围里。如果你问我最大的感受是什么,我会毫不犹豫地说:AI创业的“场景化落地”竞赛,已经进入了白…...
)
别再搞混了!Web地图开发必懂的EPSG:4326和EPSG:3857(附JavaScript转换代码)
Web地图开发中的坐标系解密:从原理到实战 第一次在Leaflet地图上叠加GPS轨迹数据时,我盯着那个偏离了三条街的路径百思不得其解——经纬度坐标明明正确,为什么显示位置完全不对?这个困扰无数Web开发者的经典问题,根源在…...

AI营销技能库:模块化设计提升Claude Code与智能体工作流效率
1. 项目概述:一个为AI营销工作流设计的技能库如果你正在用Claude Code、Cursor这类AI编程工具做营销、内容创作或增长相关的工作,并且感觉每次都要花大量时间写重复的提示词,或者希望团队能有一套标准化的AI工作流程,那么这个名为…...

AI Agent技能生成器:从零创建精准高效的SKILL.md文件
1. 项目概述:一个为AI Agent生成“技能说明书”的元技能如果你和我一样,经常在Claude Code、Cursor或者Codex这类AI编程助手工具里折腾,想让它帮你处理一些特定的、重复性的开发任务,那你肯定对“技能”(Skill…...

基于Kubernetes Operator的企业级区块链网络自动化部署实践
1. 项目概述:企业级区块链的云原生部署方案如果你正在寻找一个能够将企业级区块链网络快速、稳定地部署到Kubernetes集群上的成熟方案,那么ConsenSys开源的quorum-kubernetes项目绝对值得你花时间深入研究。这个项目不是一个简单的概念验证,而…...
)
手把手教你用C语言实现三相锁相环(附完整源码与仿真波形分析)
手把手教你用C语言实现三相锁相环(附完整源码与仿真波形分析) 在电力电子和电机控制领域,锁相环(PLL)技术是实现电网同步、逆变器控制的核心组件。传统教材往往停留在理论推导,而实际工程中,如何…...

004、TinyML技术栈全景图:从模型到部署
004 TinyML技术栈全景图:从模型到部署 去年冬天调试一个智能门磁项目,板子是STM32L4,Flash只有256KB。模型在PC上跑F1值0.97,烧进去直接死机——不是推理结果不对,是内存分配直接溢出。我盯着map文件看了三个小时,最后发现是TensorFlow Lite Micro的arena大小设错了,多…...

VRM-VRChat双向转换引擎:打破虚拟角色平台壁垒的技术解决方案
VRM-VRChat双向转换引擎:打破虚拟角色平台壁垒的技术解决方案 【免费下载链接】VRMConverterForVRChat 项目地址: https://gitcode.com/gh_mirrors/vr/VRMConverterForVRChat VRM格式转换、VRChat SDK3兼容、Unity编辑器扩展、虚拟角色迁移、跨平台角色转换…...
下载分享)
上古卷轴5天际整合包下载最新全热门MOD整合(画质+人物+功能+场景全美化)下载分享
一、整合包基础概况 新手向懒人专属整合资源,适配电脑Windows系统。整合包集成多款热门优质MOD,无需玩家单独下载模组,整合包整体兼容性强,适配主流家用电脑,官方提前做好模组适配优化,规避多数模组冲突问…...

Blender 3MF插件终极指南:3D打印工作流的完整解决方案
Blender 3MF插件终极指南:3D打印工作流的完整解决方案 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 你是否正在寻找一个简单高效的3D打印文件处理方案&…...