JDBC【DBUtils】
一、 DBUtils工具类🍓
(一)、DBUtils简介🥝
使用JDBC我们发现冗余的代码太多了,为了简化开发 我们选择使用 DbUtils
Commons DbUtils是Apache组织提供的一个对JDBC进行简单封装的开源工具类库,使用它能够简化JDBC应用程序的开发,同时也不会影响程序的性能。
使用方式:
DBUtils就是JDBC的简化开发工具包。需要项目导入commons-dbutils-1.6.jar。
(二)、Dbutils核心功能介绍🥝
- QueryRunner 中提供对sql语句操作的API.
- ResultSetHandler接口,用于定义select操作后,怎样封装结果集.
- DbUtils类,他就是一个工具类,定义了关闭资源与事务处理相关方法.
(三)、案例相关知识🥝
表和类之间的关系
- 整个表可以看做是一个类
- 表中的一行记录,对应一个类的实例(对象)
- 表中的一列,对应类中的一个成员属性
JavaBean组件
JavaBean 就是一个类, 开发中通常用于封装数据,有一下特点
- 需要实现 序列化接口, Serializable (暂时可以省略)
- 提供私有字段: private 类型 变量名;
- 提供 getter 和 setter
- 提供 空参构造
创建Employee类和数据库的employee表对应,我们可以创建一个 entity包,专门用来存放 JavaBean类
public class Employee implements Serializable { private int eid; private String ename; private int age; private String sex; private double salary; private Date empdate; //空参 getter setter省略 }
(四)、1.4 DBUtils完成 CRUD🥝
1)QueryRunner核心类🍎
构造方法
- QueryRunner()
- QueryRunner(DataSource ds) ,提供数据源(连接池),DBUtils底层自动维护连接connection
常用方法
- update(Connection conn, String sql, Object… params) ,用来完成表数据的增加、删除、更新操作
- query(Connection conn, String sql, ResultSetHandler rsh, Object… params) ,用来完成表数据的查询操作
2) QueryRunner的创建🍎
手动模式
//手动方式 创建QueryRunner对象 具体使用到的时候在给信息
QueryRunner qr = new QueryRunner();自动模式
//自动创建 传入数据库连接池对象 直接给DataSource
QueryRunner qr2 = new QueryRunner(DruidUtils.getDataSource());工具类需要返回dataSource
//获取连接池对象
public static DataSource getDataSource(){ return dataSource;
}3) QueryRunner实现增、删、改操作🍎
核心方法
- update(Connection conn, String sql, Object… params)
- Object… param Object类型的 可变参,用来设置占位符上的参数
步骤:
1.创建QueryRunner(手动或自动)
2.占位符方式 编写SQL
3.设置占位符参数
4.执行
添加
@Test
public void testInsert() throws SQLException { //1.创建 QueryRunner 手动模式创建 QueryRunner qr = new QueryRunner(); //2.编写 占位符方式 String sql = "insert into employee values(?,?,?,?,?,?)"; //3.设置占位符的参数 Object[] param = {null,"张百万",20,"女",10000,"1990-12-26"}; //4.执行 update方法 Connection con = DruidUtils.getConnection(); int i = qr.update(con, sql, param); //5.释放资源 DbUtils.closeQuietly(con);
}
修改
//修改操作 修改姓名为张百万的员工工资
@Test
public void testUpdate() throws SQLException { //1.创建QueryRunner对象 自动模式,传入数据库连接池 QueryRunner qr = new QueryRunner(DruidUtils.getDataSource());//2.编写SQL String sql = "update employee set salary = ? where ename = ?"; //3.设置占位符参数 Object[] param = {0,"张百万"}; //4.执行update, 不需要传入连接对象 qr.update(sql,param);
}删除
//删除操作 删除id为1 的数据
@Test
public void testDelete() throws SQLException { QueryRunner qr = new QueryRunner(DruidUtils.getDataSource()); String sql = "delete from employee where eid = ?"; //只有一个参数,不需要创建数组 qr.update(sql,1);
}(五)、 QueryRunner实现查询操作🥝
ResultSetHandler接口简介
ResultSetHandler可以对查询出来的ResultSet结果集进行处理,达到一些业务上的需求。
ResultSetHandler 结果集处理类
本例展示的是使用ResultSetHandler接口的几个常见实现类实现数据库的增删改查,可以大大减少代码量,优化程序。
每一种实现类都代表了对查询结果集的一种处理方式
ResultSetHandler 实现类
- ArrayHandler 将结果集中的第一条记录封装到一个Object[]数组中,数组中的每一个元素就是这条记录中的每一个字段的值 id,ename,eage Array
- ArrayListHandler 将结果集中的每一条记录都封装到一个Object[]数组中,将这些数组在封装到List集合中。List
- BeanHandler 将结果集中第一条记录封装到一个指定的javaBean中. 返回一个对象
- BeanListHandler 将结果集中每一条记录封装到指定的javaBean中,再将这些javaBean在封装到List集合中 List
- ColumnListHandler 将结果集中指定的列的字段值,封装到一个List集合中
- KeyedHandler 将结果集中每一条记录封装到Map<String,Object>,在将这个map集合做为另一个Map的value,另一个Map集合的key是指定的字段的值。
- MapHandler 将结果集中第一条记录封装到了Map<String,Object>集合中,key就是字段名称,value就是字段值
- MapListHandler 将结果集中每一条记录封装到了Map<String,Object>集合中,key就是字段名称,value就是字段值,在将这些Map封装到List集合中。
- ScalarHandler 它是用于封装单个数据。例如 select count(*) from 表操作。
ResultSetHandler 常用实现类测试
- QueryRunner的查询方法
- query方法的返回值都是泛型,具体的返回值类型,会根据结果集的处理方式,发生变化
方法
- query(String sql, handler ,Object[] param) 自动模式创建QueryRunner, 执行查询
- query(Connection con,String sql,handler,Object[] param) 手动模式创建QueryRunner, 执行查询
案例
创建一个测试类, 对ResultSetHandler接口的几个常见实现类进行测试
1.查询id为5的记录,封装到数组中
2.查询所有数据,封装到List集合中
3.查询id为5的记录,封装到指定JavaBean中
4.查询薪资大于 3000 的所员工信息,封装到JavaBean中再封装到List集合中
5.查询姓名是 张百万的员工信息,将结果封装到Map集合中
6.查询所有员工的薪资总额
1.查询id为5的记录,封装到数组中
/** 查询id为5的记录,封装到数组中
* ArrayHandler 将结果集的第一条数据封装到数组中
*/
@Test
public void testFindById() throws SQLException { //1.创建QueryRunner QueryRunner qr = new QueryRunner(DruidUtils.getDataSource()); //2.编写SQL String sql = "select * from employee where eid = ?"; //3.执行查询 Object[] query = qr.query(sql, new ArrayHandler(), 5); //4.获取数据 System.out.println(Arrays.toString(query));
}
2.查询所有数据,封装到List集合中
/*** 查询所有数据,封装到List集合中 * ArrayListHandler可以将每条数据先封装到数组中, 再将数组封装到集合中 */ @Test public void testFindAll() throws SQLException { //1.创建QueryRunner QueryRunner qr = new QueryRunner(DruidUtils.getDataSource()); //2.编写SQL String sql = "select * from employee"; //3.执行查询 List<Object[]> query = qr.query(sql, new ArrayListHandler()); //4.遍历集合获取数据 for (Object[] objects : query) { System.out.println(Arrays.toString(objects)); } }
3.根据ID查询,封装到指定JavaBean中
/*** 查询id为3的记录,封装到指定JavaBean中 * BeanHandler 将结果集的第一条数据封装到 javaBean中 */@Test public void testFindByIdJavaBean() throws SQLException { QueryRunner qr = new QueryRunner(DruidUtils.getDataSource()); String sql = "select * from employee where eid = ?"; Employee employee = qr.query(sql, new BeanHandler<Employee>(Employee.class), 3); System.out.println(employee); }
4.查询薪资大于 3000 的所员工信息,封装到JavaBean中再封装到List集合中
/** * 查询薪资大于 3000 的所员工信息,封装到JavaBean中再封装到List集合中 * BeanListHandler 将结果集的每一条和数据封装到 JavaBean中 * 再将JavaBean 放到list集合中 **/ @Test public void testFindBySalary() throws SQLException { QueryRunner qr = new QueryRunner(DruidUtils.getDataSource()); String sql = "select * from employee where salary > ?"; List<Employee> list = qr.query(sql, new BeanListHandler<Employee>(Employee.class), 3000); for (Employee employee : list) { System.out.println(employee); }
}
5.查询姓名是 张百万的员工信息,将结果封装到Map集合中
/** * 查询姓名是 张百万的员工信息,将结果封装到Map集合中 * MapHandler 将结果集的第一条记录封装到 Map<String,Object>中 * key对应的是 列名 value对应的是 列的值 **/ @Test public void testFindByName() throws SQLException { QueryRunner qr = new QueryRunner(DruidUtils.getDataSource()); String sql = "select * from employee where ename = ?"; Map<String, Object> map = qr.query(sql, new MapHandler(), "张百万"); Set<Map.Entry<String, Object>> entries = map.entrySet();for (Map.Entry<String, Object> entry : entries) { //打印结果 System.out.println(entry.getKey() +" = " +entry.getValue()); }
}
6.查询所有员工的薪资总额
/** * 查询所有员工的薪资总额 * ScalarHandler 用于封装单个的数据 **/ @Test public void testGetSum() throws SQLException { QueryRunner qr = new QueryRunner(DruidUtils.getDataSource()); String sql = "select sum(salary) from employee"; Double sum = (Double)qr.query(sql, new ScalarHandler<>()); System.out.println("员工薪资总额: " + sum); }二、MySql元数据🍓
描述 数据库 中数据的数据
展示数据库信息的数据
(一)、什么是元数据🥝
- 除了表之外的数据都是元数据,可以分为三类
- 查询结果信息: UPDATE 或 DELETE语句 受影响的记录数。
- 数据库和数据表的信息: 包含了数据库及数据表的结构信息。
- MySQL服务器信息: 包含了数据库服务器的当前状态,版本号等。
(二)、常用命令🥝
-- 元数据相关的命令介绍
-- 1.查看服务器当前状态
show status;-- 2.查看MySQl的版本信息
select version();-- 3.查询表中的详细信息 和desc table_name一样
show columns from table_name;-- 4.显示数据表的详细索引信息
show index from table_name;-- 5.列出所有数据库
show databases:-- 6.显示当前数据库的所有表
show tables :-- 7.获取当前的数据库名
select database():
(三)、使用JDBC 获取元数据🥝
通过JDBC 也可以获取到元数据,比如数据库的相关信息,或者当我们使用程序查询一个不熟悉的表时, 我们可以通过获取元素据信息,了解表中有多少个字段,字段的名称 和 字段的类型.
(四)、常用类介绍🥝
JDBC中描述元数据的类

- 获取元数据对象的方法 : getMetaData ()
- connection 连接对象, 调用 getMetaData () 方法,获取的是
DatabaseMetaData 数据库元数据对象 - PrepareStatement 预处理对象调用 getMetaData () , 获取的是ResultSetMetaData , 结果集元数据对象
- connection 连接对象, 调用 getMetaData () 方法,获取的是
- DatabaseMetaData的常用方法
方法说明
getURL() : 获取数据库的URL
getUserName(): 获取当前数据库的用户名
getDatabaseProductName(): 获取数据库的产品名称
getDatabaseProductVersion(): 获取数据的版本号
getDriverName(): 返回驱动程序的名称
isReadOnly(): 判断数据库是否只允许只读 true 代表只读
- ResultSetMetaData的常用方法
方法说明
getColumnCount() : 当前结果集共有多少列
getColumnName(int i) : 获取指定列号的列名, 参数是整数 从1开始
getColumnTypeName(int i): 获取指定列号列的类型, 参数是整数 从1开始代码示例
public class TestMetaData {
//1.获取数据库相关的元数据信息 使用DatabaseMetaData
@Test
public void testDataBaseMetaData() throws SQLException {
//1.获取数据库连接对象
Connection connection = DruidUtils.getConnection();
//2.获取代表数据库的 元数据对象
DatabaseMetaData DatabaseMetaData metaData = connection.getMetaData();
//3.获取数据库相关的元数据信息
String url = metaData.getURL();
System.out.println("数据库URL: " + url);
String userName = metaData.getUserName();
System.out.println("当前用户: " + userName );
String productName = metaData.getDatabaseProductName();
System.out.println("数据库产品名: " + productName);
String version = metaData.getDatabaseProductVersion();
System.out.println("数据库版本: " + version);String driverName = metaData.getDriverName();
System.out.println("驱动名称: " + driverName);
//判断当前数据库是否只允许只读
boolean b = metaData.isReadOnly();
//如果是 true 就表示 只读
if(b){System.out.println("当前数据库只允许读操作!");
}else{System.out.println("不是只读数据库");
}
connection.close();
}
//获取结果集中的元数据信息
@Test
public void testResultSetMetaData() throws SQLException {
//1.获取连接
Connection con = DruidUtils.getConnection();
//2.获取预处理对象
PreparedStatement ps = con.prepareStatement("select * from employee");
ResultSet resultSet = ps.executeQuery();
//3.获取结果集元素据对象
ResultSetMetaData metaData = ps.getMetaData();
//1.获取当前结果集 共有多少列
int count = metaData.getColumnCount();
System.out.println("当前结果集中共有: " + count + " 列");
//2.获结果集中 列的名称 和 类型
for (int i = 1; i <= count; i++) { String columnName = metaData.getColumnName(i); System.out.println("列名: "+ columnName); String columnTypeName = metaData.getColumnTypeName(i); System.out.println("类型: " +columnTypeName);
}
//释放资源
DruidUtils.close(con,ps,resultSet);
}
}相关文章:
JDBC【DBUtils】
一、 DBUtils工具类🍓 (一)、DBUtils简介🥝 使用JDBC我们发现冗余的代码太多了,为了简化开发 我们选择使用 DbUtils Commons DbUtils是Apache组织提供的一个对JDBC进行简单封装的开源工具类库,使用它能够简化JDBC应用程序的开发,…...

大数据Doris(一):Doris概述篇
文章目录 Doris概述篇 一、前言 二、Doris简介...

vue 基于vue-seamless-scroll无缝滚动的用法和遇到的问题解决
vue 基于vue-seamless-scroll无缝滚动的用法和遇到的问题解决 背景 最近再做一个大屏项目,需要用到表格滚动效果,之前自己写过js实现,最近发现一个组件vue-seamless-scroll可以实现滚动,感觉挺方便的,准备用一下,但是用完之后才发现这个组件有很多坑需要解决.我把用法和一些问…...

SmartX 边缘计算解决方案:简单稳定,支持各类应用负载
在《一文了解近端边缘 IT 基础架构技术需求》文章中,我们为大家分析了边缘应用对 IT 基础架构的技术要求,以及为什么超融合架构是支持边缘场景的最佳选择。值得一提的是,IDC 近日发布的《中国软件定义存储(SDS)及超融合…...
FPGA 多路视频处理:图像缩放+视频拼接显示,HDMI采集,提供2套工程源码和技术支持
目录 1、前言版本更新说明免责声明 2、相关方案推荐FPGA图像缩放方案推荐FPGA视频拼接方案推荐 3、设计思路框架视频源选择IT6802解码芯片配置及采集动态彩条缓冲FIFO图像缩放模块详解设计框图代码框图2种插值算法的整合与选择 视频拼接算法图像缓存视频输出 4、vivado工程1&am…...
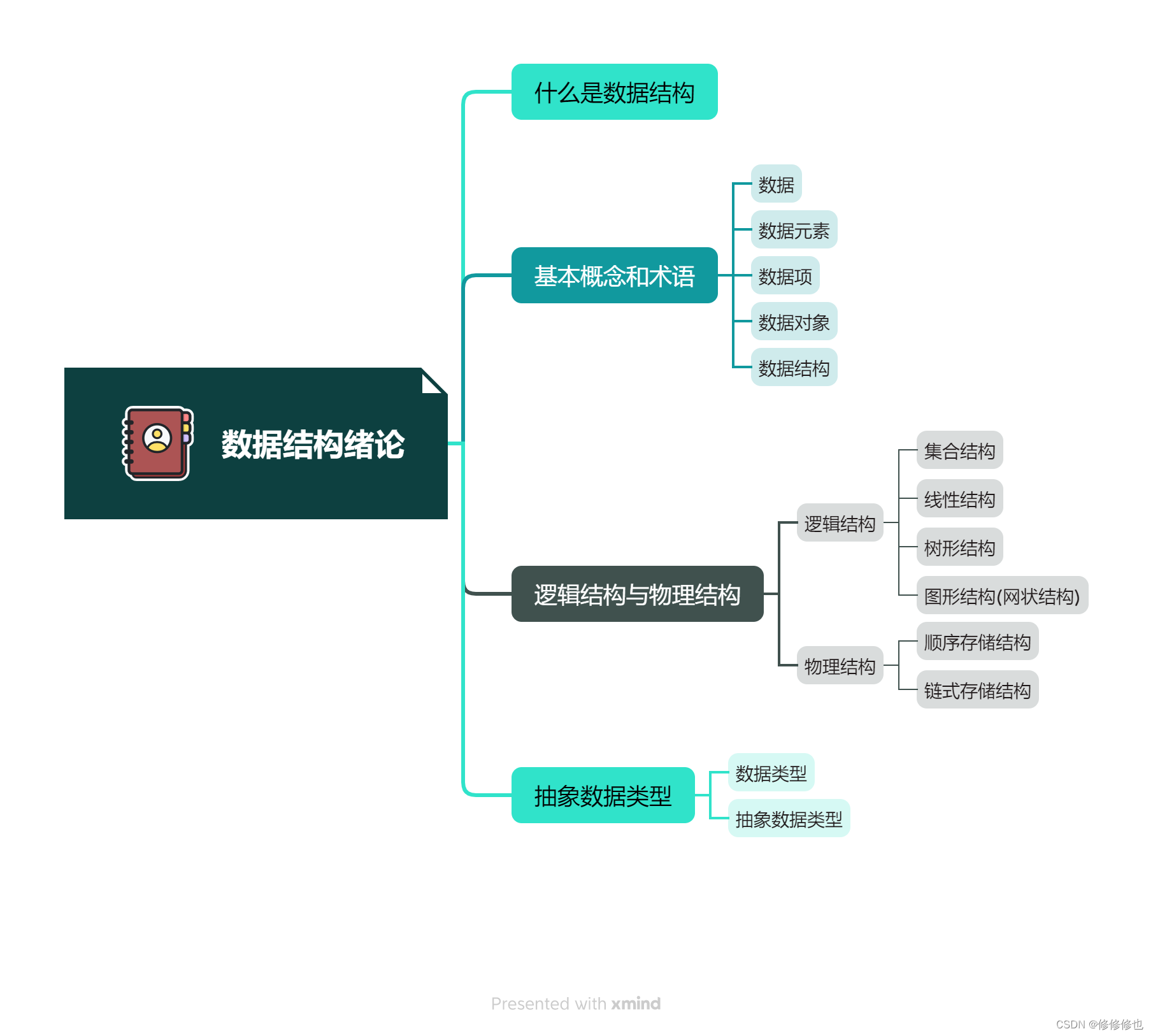
【数据结构】抽象数据类型
🦄个人主页:修修修也 🎏所属专栏:数据结构 ⚙️操作环境:Visual Studio 2022 目录 🎏数据类型 🎏抽象数据类型 结语 🎏数据类型 数据类型:是指一组性质相同的值的集合及定义在此集合上的一些操作的总称. 数据类型(d…...

Android 查看路由表
Android 查看路由表_android 路由表_念雅的博客-CSDN博客...
vulnhub靶机-DC系列-DC-3
文章目录 信息收集漏洞查找漏洞利用SQL注入John工具密码爆破反弹shell 提权 信息收集 主机扫描 arp-scan -l可以用netdiscover 它是一个主动/被动的ARP 侦查工具。使用Netdiscover工具可以在网络上扫描IP地址,检查在线主机或搜索为它们发送的ARP请求。 netdiscover -r 192.1…...
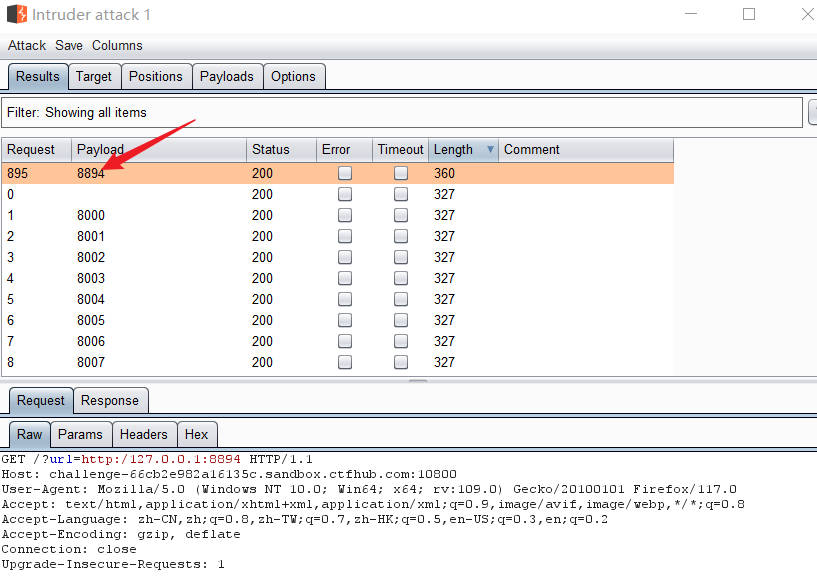
【CTFHUB】SSRF原理之简单运用(一)
一、漏洞原理 SSRF 服务端请求伪造 原理:在某些网站中提供了从其他服务器获取数据的功能,攻击者能通过构造恶意的URL参数,恶意利用后可作为代理攻击远程或本地的服务器。 二、SSRF的利用 1.对目标外网、内网进行端口扫描。 2.攻击内网或本…...
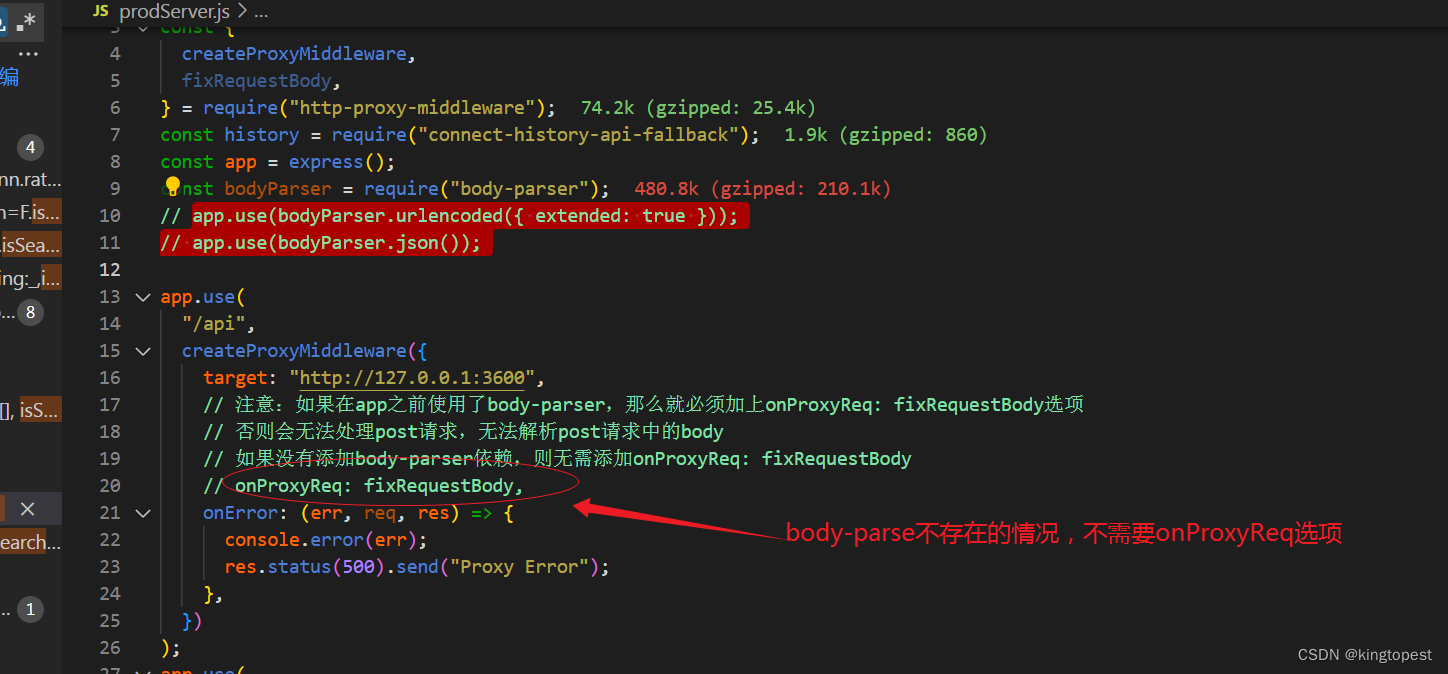
wepack打包生产环境使用http-proxy-middleware做api代理转发的方法
首先安装http-proxy-middleware依赖,这个用npm和yarn安装都可以。 然后在express服务器的代码增加如下内容: const express require("express"); const app express(); const { createProxyMiddleware, fixRequestBody, } require("h…...

一百八十六、大数据离线数仓完整流程——步骤五、在Hive的DWS层建动态分区表并动态加载数据
一、目的 经过6个月的奋斗,项目的离线数仓部分终于可以上线了,因此整理一下离线数仓的整个流程,既是大家提供一个案例经验,也是对自己近半年的工作进行一个总结。 二、数仓实施步骤 (五)步骤五、在Hive的…...
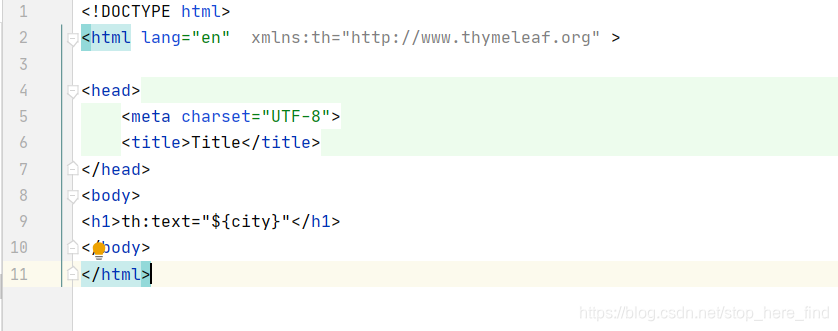
Idea引入thymeleaf失败解决方法
报错 Whitelabel Error Page This application has no explicit mapping for /error, so you are seeing this as a fallback.Fri Sep 29 09:42:00 CST 2023 There was an unexpected error (typeNot Found, status404). 原因:html没有使用thymeleaf 首先要引入…...

Dev C++安装与运行
参考: https://blog.csdn.net/Keven_11/article/details/126388791 https://www.cnblogs.com/-Wallace-/p/cpp-stl.html 2021年真题要求 2022年真题要求 河南省的考试环境 IDE环境 Dev C 安装 下载 安装 点击OK,选择我接受 修改安装路径为D盘d:\Program Fi…...
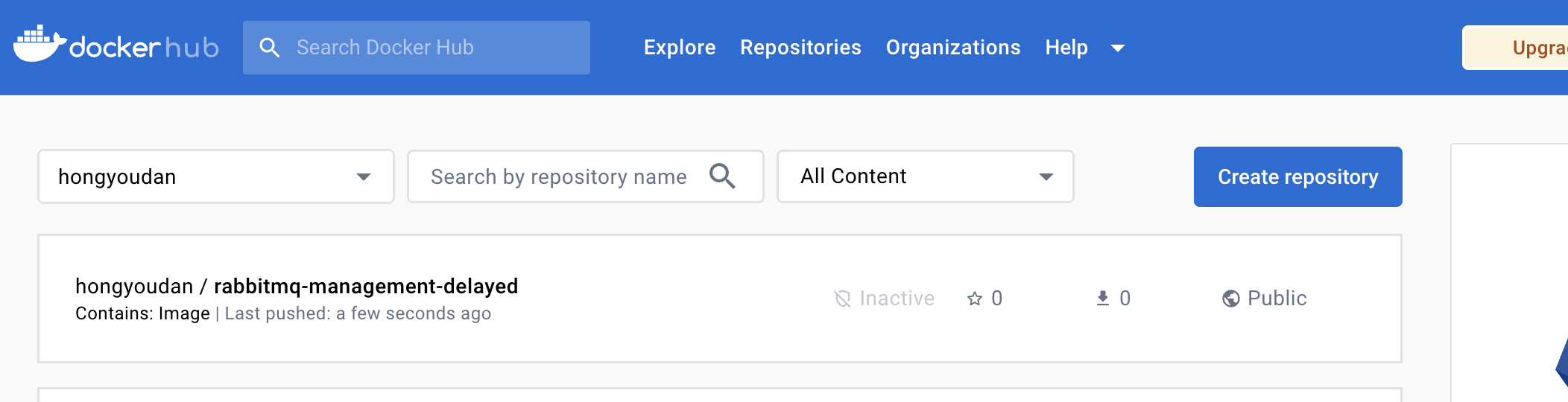
Docker下如何构建包含延迟插件的RabbitMQ镜像
👨🏻💻 热爱摄影的程序员 👨🏻🎨 喜欢编码的设计师 🧕🏻 擅长设计的剪辑师 🧑🏻🏫 一位高冷无情的编码爱好者 大家好,我是 DevO…...
)
Vue3理解(6)
列表渲染 1.v-for指令基于一个数组来渲染列表,v-for指令的值需要使用 item in items形式的特殊语法,items是源数据的数组,而item是迭代项的别名。 2.在v-for块中可以完整访问父作用域内的属性和变量,v-for的第二个参数表示当前项的位置索引。…...

react+IntersectionObserver实现页面丝滑帧动画
实现效果: 加入帧动画前: 普通的静态页面 加入帧动画后: 可以看到,加入帧动画后,页面效果还是比较丝滑的。 技术实现 加入animation动画类 先用 **scss **定义三种动画类: .withAnimation {.fade1 {ani…...

项目实战第四十六讲:财务经营看板
项目实战第四十六讲:财务经营看板 本文是项目实战第四十六讲,财务经营看板。财务模块划分为两类:① 财务工具(执行和业务财务闭环)② 财务报表,本期需求为新增财务看板,共增加4个看板 文章目录 项目实战第四十六讲:财务经营看板1、需求背景2、流程图3、技术方案4、相关…...
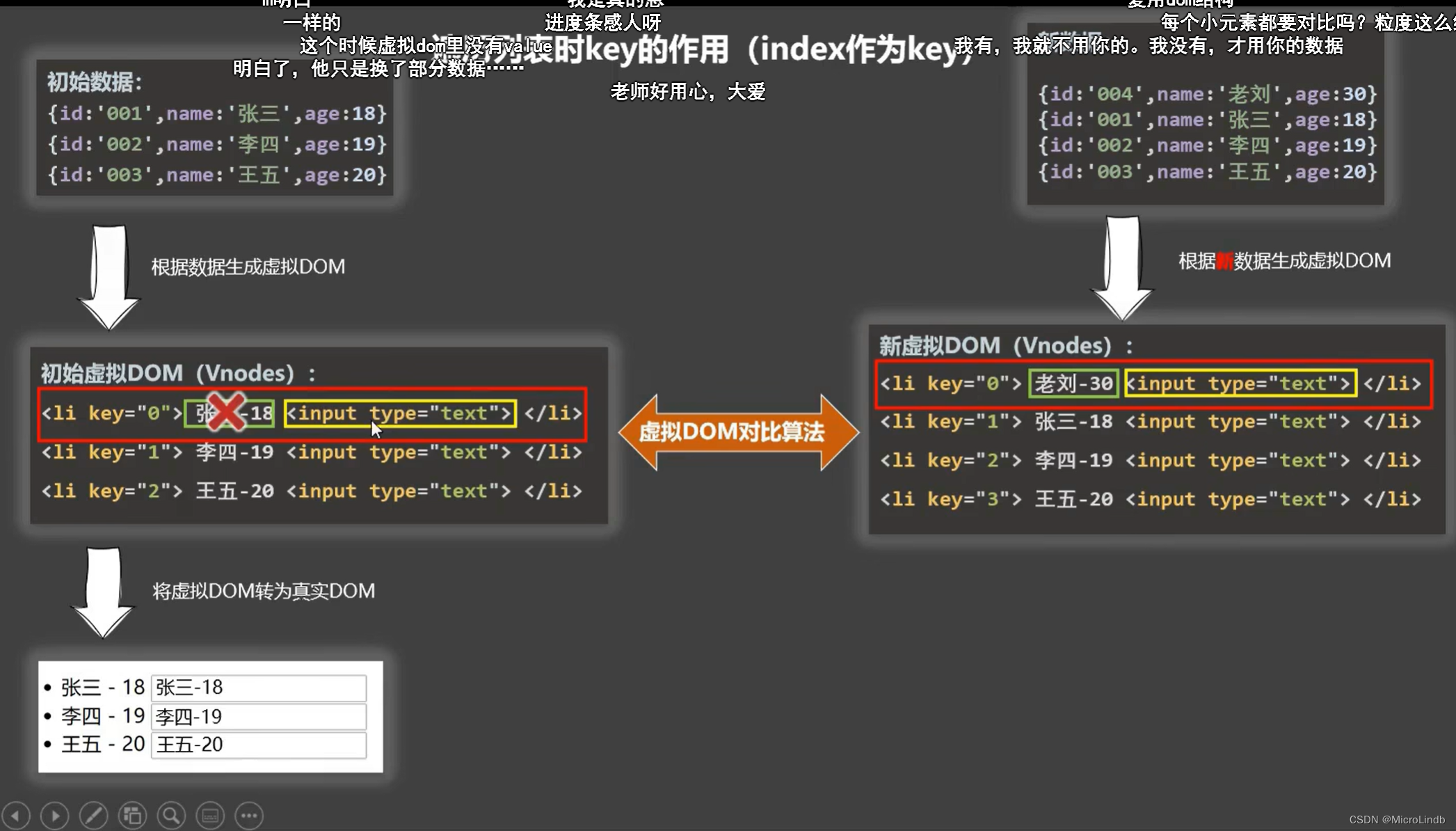
【VUE复习·10】v-for 高级::key 作用和原理;尽量不要使用 index 来遍历
总览 1.:key 作用和原理 2.尽量不要使用 index 来遍历 一、:key 作用和原理 1.数据产生串位的原因 在我们使用 index 进行遍历的时候,会出现虚拟 DOM 和 真实 DOM 的渲染问题。 二、尽量不要使用 index 来遍历 详情见视频 1/3 处: https://www.bili…...
阿里云七代云服务器实例、倚天云服务器及通用算力型和经济型实例规格介绍
在目前阿里云的云服务器产品中,既有五代六代实例规格,也有七代和八代倚天云服务器,同时还有通用算力型及经济型这些刚推出不久的新品云服务器实例,其中第五代实例规格目前不在是主推的实例规格了,现在主售的实例规格是…...
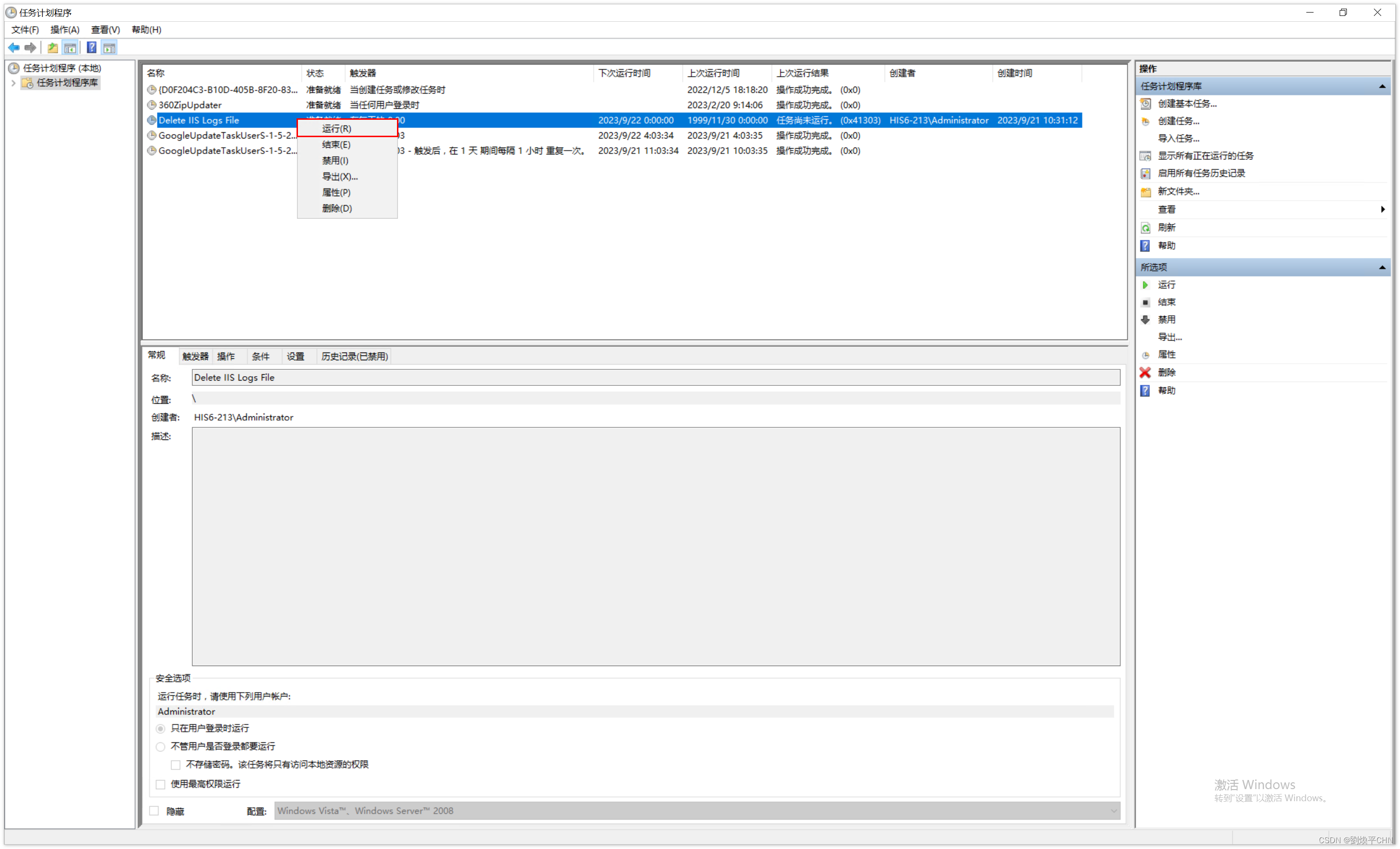
《IIS系列》IIS日志文件管理
我们在使用IIS部署网站的时候,随着时间推移,IIS 生成的日志文件可能会消耗大量磁盘空间。 日志可能会填满整个硬盘驱动器,为了缓解此问题,许多用户完全关闭日志记录,但关了记录又会导致出现问题无从排查,故…...
)
STM32F4上给GUI换“活字”:FreeType2.13.2移植实战(含字形缓存优化)
STM32F4嵌入式GUI矢量字体革命:FreeType2.13.2深度移植与性能突围 在嵌入式系统领域,GUI界面的美观度与多语言支持能力正成为产品差异化的关键要素。传统点阵字体方案如同活字印刷时代的铅字,每个字号、每种语言都需要独立制作字库ÿ…...

MLC LLM:大语言模型通用编译部署实战指南
1. 项目概述:当大语言模型遇见“通用编译” 最近几个月,我身边不少做AI应用和部署的朋友都在讨论一个词: MLC LLM 。这可不是一个新的大模型,而是一个旨在解决大语言模型(LLM)部署“最后一公里”问题的开…...

一键解锁B站缓存视频:从平台依赖到个人数字资产管理的智能方案
一键解锁B站缓存视频:从平台依赖到个人数字资产管理的智能方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 在数字内容瞬息万变的…...

BetterRTX终极教程:5分钟免费提升Minecraft画质的完整方案
BetterRTX终极教程:5分钟免费提升Minecraft画质的完整方案 【免费下载链接】BetterRTX-Installer The Powershell Installer for BetterRTX! BetterRTX is a Ray-Tracing mod for Minecraft Bedrock. 项目地址: https://gitcode.com/gh_mirrors/be/BetterRTX-Inst…...

APP加固后审核被拒怎么办?iOS上架失败紧急解决流程与性能排查
花了大量心血开发的应用,提交到App Store后,等来的不是上架成功的邮件,而是一封来自苹果的审核拒绝信,理由还是“元数据被拒”或“二进制文件被拒”。更让人崩溃的是,排查下来,问题很可能指向刚做的iOS应用…...

利用OpenClaw与gws CLI构建AI Agent的Google Workspace自动化技能
1. 项目概述与核心价值最近在折腾AI智能体(AI Agent)的自动化工作流,发现一个痛点:想让Agent帮我处理Gmail邮件、整理Google Drive文件或者安排Calendar日程,往往需要自己写一堆API集成代码,不仅麻烦&#…...

ClawX:OpenClaw AI智能体桌面门户,图形化编排与自动化实战
1. 项目概述:ClawX,为OpenClaw AI智能体打造的桌面门户如果你和我一样,对AI智能体(AI Agent)的潜力感到兴奋,却又对在终端里敲打复杂的命令行、配置繁琐的YAML文件感到头疼,那么ClawX的出现&…...
)
用Python+OpenCV给《梦幻西游》写个自动挖图脚本(附完整代码与避坑指南)
用PythonOpenCV实现《梦幻西游》自动挖宝图的全流程实战 最近在技术社区看到不少关于游戏自动化的讨论,尤其是像《梦幻西游》这类经典MMORPG,很多开发者尝试用计算机视觉技术实现自动化操作。作为一个长期关注OpenCV应用的开发者,我花了三周…...

ViGEmBus虚拟游戏控制器驱动终极指南:Windows内核级游戏手柄模拟深度解析
ViGEmBus虚拟游戏控制器驱动终极指南:Windows内核级游戏手柄模拟深度解析 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 在Windows游戏开发与输…...

SpringBoot的服装商城系统毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Vue框架的服装商城系统以解决传统电商平台在用户体验优化与业务逻辑实现方面的局限性。当前电子商务领域面临商品信息展示不…...