Kafka收发消息核心参数详解
文章目录
- 1、从基础的客户端说起
- 1.1、消息发送者主流程
- 1.2、消息消费者主流程
- 2、从客户端属性来梳理客户端工作机制
- 2.1、消费者分组消费机制
1、从基础的客户端说起
Kafka提供了非常简单的客户端API。只需要引入一个Maven依赖即可:
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka_2.13</artifactId><version>3.4.0</version></dependency>
1.1、消息发送者主流程
然后可以使用Kafka提供的Producer类,快速发送消息。
public class MyProducer {private static final String BOOTSTRAP_SERVERS = "worker1:9092,worker2:9092,worker3:9092";private static final String TOPIC = "disTopic";public static void main(String[] args) throws ExecutionException, InterruptedException {//PART1:设置发送者相关属性Properties props = new Properties();// 此处配置的是kafka的端口props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);// 配置key的序列化类props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");// 配置value的序列化类props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");Producer<String,String> producer = new KafkaProducer<>(props);CountDownLatch latch = new CountDownLatch(5);for(int i = 0; i < 5; i++) {//Part2:构建消息ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC, Integer.toString(i), "MyProducer" + i);//Part3:发送消息//单向发送:不关心服务端的应答。producer.send(record);System.out.println("message "+i+" sended");//同步发送:获取服务端应答消息前,会阻塞当前线程。RecordMetadata recordMetadata = producer.send(record).get();String topic = recordMetadata.topic();int partition = recordMetadata.partition();long offset = recordMetadata.offset();String message = recordMetadata.toString();System.out.println("message:["+ message+"] sended with topic:"+topic+"; partition:"+partition+ ";offset:"+offset);//异步发送:消息发送后不阻塞,服务端有应答后会触发回调函数producer.send(record, new Callback() {@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {if(null != e){System.out.println("消息发送失败,"+e.getMessage());e.printStackTrace();}else{String topic = recordMetadata.topic();long offset = recordMetadata.offset();String message = recordMetadata.toString();System.out.println("message:["+ message+"] sended with topic:"+topic+";offset:"+offset);}latch.countDown();}});}//消息处理完才停止发送者。latch.await();producer.close();}
}
整体来说,构建Producer分为三个步骤:
- 设置Producer核心属性 :Producer可选的属性都可以由ProducerConfig类管理。比如ProducerConfig.BOOTSTRAP_SERVERS_CONFIG属性,显然就是指发送者要将消息发到哪个Kafka集群上。这是每个Producer必选的属性。在ProducerConfig中,对于大部分比较重要的属性,都配置了对应的DOC属性进行描述。
- 构建消息:Kafka的消息是一个Key-Value结构的消息。其中,key和value都可以是任意对象类型。其中,key主要是用来进行Partition分区的,业务上更关心的是value。
- 使用Producer发送消息:通常用到的就是单向发送、同步发送和异步发送者三种发送方式。
1.2、消息消费者主流程
接下来可以使用Kafka提供的Consumer类,快速消费消息。
public class MyConsumer {private static final String BOOTSTRAP_SERVERS = "worker1:9092,worker2:9092,worker3:9092";private static final String TOPIC = "disTopic";public static void main(String[] args) {//PART1:设置发送者相关属性Properties props = new Properties();//kafka地址props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);//每个消费者要指定一个groupprops.put(ConsumerConfig.GROUP_ID_CONFIG, "test");//key序列化类props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");//value序列化类props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");Consumer<String, String> consumer = new KafkaConsumer<>(props);consumer.subscribe(Arrays.asList(TOPIC));while (true) {//PART2:拉取消息// 100毫秒超时时间ConsumerRecords<String, String> records = consumer.poll(Duration.ofNanos(100));//PART3:处理消息for (ConsumerRecord<String, String> record : records) {System.out.println("offset = " + record.offset() + ";key = " + record.key() + "; value= " + record.value());}//提交offset,消息就不会重复推送。consumer.commitSync(); //同步提交,表示必须等到offset提交完毕,再去消费下一批数据。
// consumer.commitAsync(); //异步提交,表示发送完提交offset请求后,就开始消费下一批数据了。不用等到Broker的确认。}}
}
整体来说,Consumer同样是分为三个步骤:
- 设置Consumer核心属性 :可选的属性都可以由ConsumerConfig类管理。在这个类中,同样对于大部分比较重要的属性,都配置了对应的DOC属性进行描述。同样BOOTSTRAP_SERVERS_CONFIG是必须设置的属性。
- 拉取消息:Kafka采用Consumer主动拉取消息的Pull模式。consumer主动从Broker上拉取一批感兴趣的消息。
- 处理消息,提交位点:消费者将消息拉取完成后,就可以交由业务自行处理对应的这一批消息了。只是消费者需要向Broker提交偏移量offset。如果不提交Offset,Broker会认为消费者端消息处理失败了,还会重复进行推送。
Kafka的客户端基本就是固定的按照这三个大的步骤运行。在具体使用过程中,最大的变数基本上就是给生产者和消费者的设定合适的属性。这些属性极大的影响了客户端程序的执行方式。
2、从客户端属性来梳理客户端工作机制
渔与鱼:Kafka的客户端API的重要目的就是想要简化客户端的使用方式,所以对于API的使用,尽量熟练就可以了。对于其他重要的属性,都可以通过源码中的描述去学习,并且可以设计一些场景去进行验证。其重点,是要逐步在脑海之中建立一个Message在Kafka集群中进行流转的基础模型。
其实Kafka的设计精髓,是在网络不稳定,服务也随时会崩溃的这些作死的复杂场景下,如何保证消息的高并发、高吞吐,那才是Kafka最为精妙的地方。但是要理解那些复杂的问题,都是需要建立在这个基础模型基础上的。
2.1、消费者分组消费机制
这是我们在使用kafka时,最为重要的一个机制,因此最先进行梳理。
在Consumer中,都需要指定一个GROUP_ID_CONFIG属性,这表示当前Consumer所属的消费者组。他的描述是这样的:
public static final String GROUP_ID_CONFIG = "group.id";public static final String GROUP_ID_DOC = "A unique string that identifies the consumer group this consumer belongs to. This property is required if the consumer uses either the group management functionality by using <code>subscribe(topic)</code> or the Kafka-based offset management strategy.";
既然这里提到了kafka-based offset management strategy,那是不是也有非Kafka管理Offset的策略呢?
另外,还有一个相关的参数GROUP_INSTANCE_ID_CONFIG,可以给组成员设置一个固定的instanceId,这个参数通常可以用来减少Kafka不必要的rebalance。
从这段描述中看到,对于Consumer,如果需要在subcribe时使用组管理功能以及Kafka提供的offset管理策略,那就必须要配置GROUP_ID_CONFIG属性。这个分组消费机制简单描述就是这样的:
image.png
生产者往Topic下发消息时,会尽量均匀的将消息发送到Topic下的各个Partition当中。而这个消息,会向所有订阅了该Topic的消费者推送。推送时,每个ConsumerGroup中只会推送一份。也就是同一个消费者组中的多个消费者实例,只会共同消费一个消息副本。而不同消费者组之间,会重复消费消息副本。这就是消费者组的作用。
与之相关的还有Offset偏移量。这个偏移量表示每个消费者组在每个Partiton中已经消费处理的进度。在Kafka中,可以看到消费者组的Offset记录情况。
[oper@worker1 bin]$ ./kafka-consumer-groups.sh --bootstrap-server worker1:9092 --describe --group test
相关文章:

Kafka收发消息核心参数详解
文章目录 1、从基础的客户端说起1.1、消息发送者主流程1.2、消息消费者主流程 2、从客户端属性来梳理客户端工作机制2.1、消费者分组消费机制 1、从基础的客户端说起 Kafka提供了非常简单的客户端API。只需要引入一个Maven依赖即可: <dependency><groupId…...

Springboot中Aop的使用
Springboot中使用拦截器、过滤器、监听器-CSDN博客 相比较于拦截器,Spring 的aop则功能更强大,封装的更细致,需要单独引用 jar包。 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-b…...

创建vue3项目、链式调用、setup函数、ref函数、reactive函数、计算和监听属性、vue3的生命周期、torefs的使用、vue3的setup写法
1 创建vue3项目 # 两种方式- vue-cli:vue脚手架---》创建vue项目---》构建vue项目--》工具链跟之前一样- vite :https://cn.vitejs.dev/-npm create vuelatest // 或者-npm create vitelatest一路选择即可# 运行vue3项目-vue-cli跟之前一样-vite 创建的…...

搭建好自己的PyPi服务器后怎么使用
当您成功搭建好自己的 PyPI 服务器后,您可以使用以下步骤来发布和使用您的包: 打包您的代码: 首先,将您的 Python 项目打包成一个发布包。确保您已经在项目根目录下创建了 setup.py 文件,并按照正确的格式填写了项目信…...

Vue3 中使用provide和reject
1、provide 和reject 可以实现一条事件线上的 父传子,父传孙等;相比较 props emits 仅限与父子传参更方便,相较于pinia书写更简单,但是需要注意使用响应式,如果是非响应式的会导致页面更新不及时 父组件 <templat…...
大数据flink篇之一-基础知识
一、起源 2010至2014年间,由柏林工业大学、柏林洪堡大学和哈索普拉特纳研究所联合发起名Stratosphere的研究项目。2014年4月,项目贡献给Apache基金会,成为孵化项目。更名为Flink2014年12月,成为基金会顶级项目2015年9月ÿ…...

No140.精选前端面试题,享受每天的挑战和学习
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云课上架的前后端实战课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入…...
Oracle 11g_FusionOS_安装文档
同事让安装数据库,查询服务器信息发现操作系统是超聚变根据华为openEuler操作系统更改的自研操作系统,安装过程中踩坑不少,最后在超聚变厂商的技术支持下安装成功,步骤可参数该文。 一、 安装环境准备 1.1 软件下载 下载地址:…...
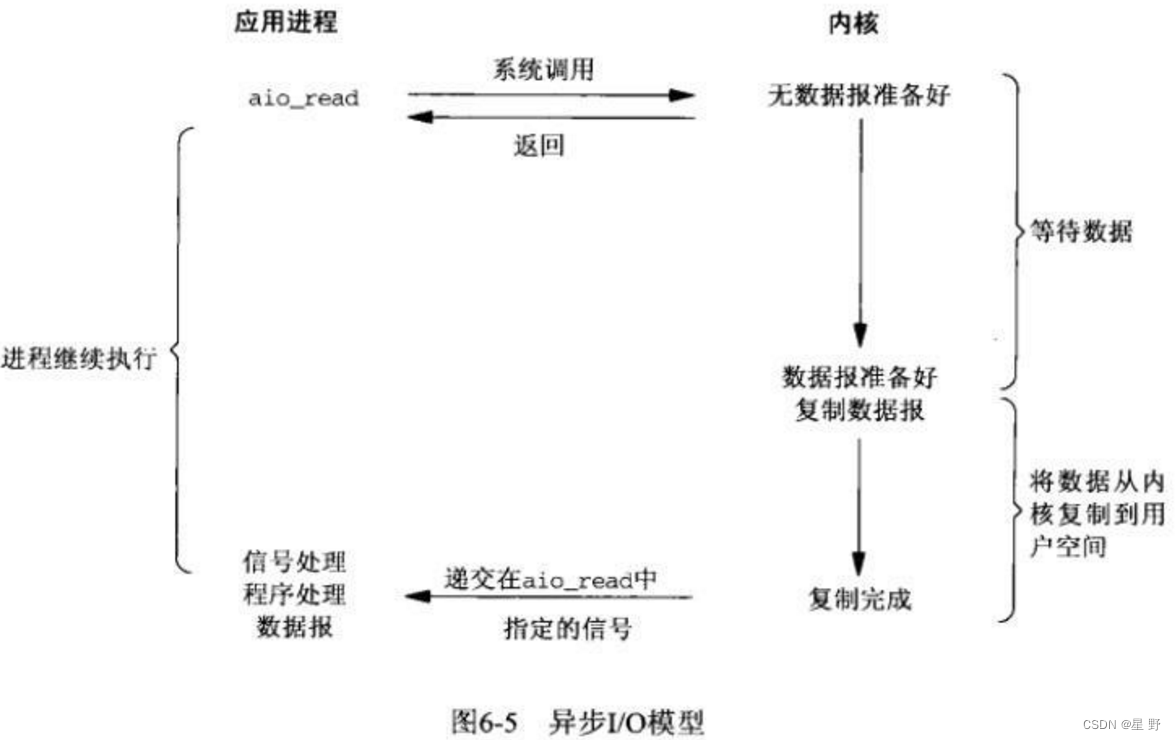
Linux驱动实现IO模型
在Linux系统分为内核态和用户态,CPU会在这两个状态之间进行切换。当进行IO操作时,应用程序会使用系统调用进入内核态,内核操作系统会准备好数据,把IO设备的数据加载到内核缓冲区。 然后内核操作系统会把内核缓冲区的数据从内核空…...

wsl2 更新报错问题解决记录
1、问题 win10 中安装的 wsl2,启动 docker desktop 时提示 wsl2 有问题: 于是点击推荐的地址连接到微软,下载 wsl2 的更新文件。之后运行,又报错: 更新被卡住。 2、解决方法 WinR 输入 cmd 打开命令行窗口&#x…...

突破算法迷宫:精选50道-算法刷题指南
前言 在计算机科学和编程领域,算法和数据结构是基础的概念,无论你是一名初学者还是有经验的开发者,都需要掌握它们。本文将带你深入了解一系列常见的算法和数据结构问题,包括二分查找、滑动窗口、链表、二叉树、TopK、设计题、动…...

玩转Mysql系列 - 第26篇:聊聊mysql如何实现分布式锁?
这是Mysql系列第26篇。 本篇我们使用mysql实现一个分布式锁。 分布式锁的功能 分布式锁使用者位于不同的机器中,锁获取成功之后,才可以对共享资源进行操作 锁具有重入的功能:即一个使用者可以多次获取某个锁 获取锁有超时的功能ÿ…...

linux 解压缩命令tar
Tar tar 命令的选项有很多(用 man tar 可以查看到),但常用的就那么几个选项,下面来举例说明一下: tar -cf all.tar *.jpg 这条命令是将所有.jpg 的文件打成一个名为 all.tar 的包。-c 是表示产生新的包,-f 指 定包的文件名。 …...

OpenAI ChatGPT API 文档之 Embedding
译者注: Embedding 直接翻译为嵌入似乎不太恰当,于是问了一下 ChatGPT,它的回复如下: 在自然语言处理和机器学习领域,"embeddings" 是指将单词、短语或文本转换成连续向量空间的过程。这个向量空间通常被称…...

Java常用类(二)
好久不见,因工作原因,好久没发文了,OldWang 回来了,持续更新Java内容!⭐ 不可变和可变字符序列使用陷阱⭐ 时间处理相关类⭐ Date 时间类(java.util.Date)⭐ DateFormat 类和 SimpleDateFormat 类⭐ Calendar 日历类 ⭐…...
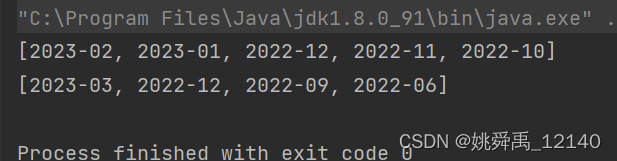
Java获取给定月份的前N个月份和前N个季度
描述: 在项目开发过程中,遇到这样一个需求,即:给定某一月份,得到该月份前面的几个月份以及前面的几个季度。例如:给定2023-09,获取该月份前面的前3个月,即2023-08、2023-07、2023-0…...

网页资源加载过程
网页资源加载是指在浏览器中访问一个网页时,浏览器如何获取和显示网页内容的过程。这个过程通常分为以下几个步骤: DNS 解析: 当用户在浏览器中输入一个网址(例如,https://www.example.com),浏览…...
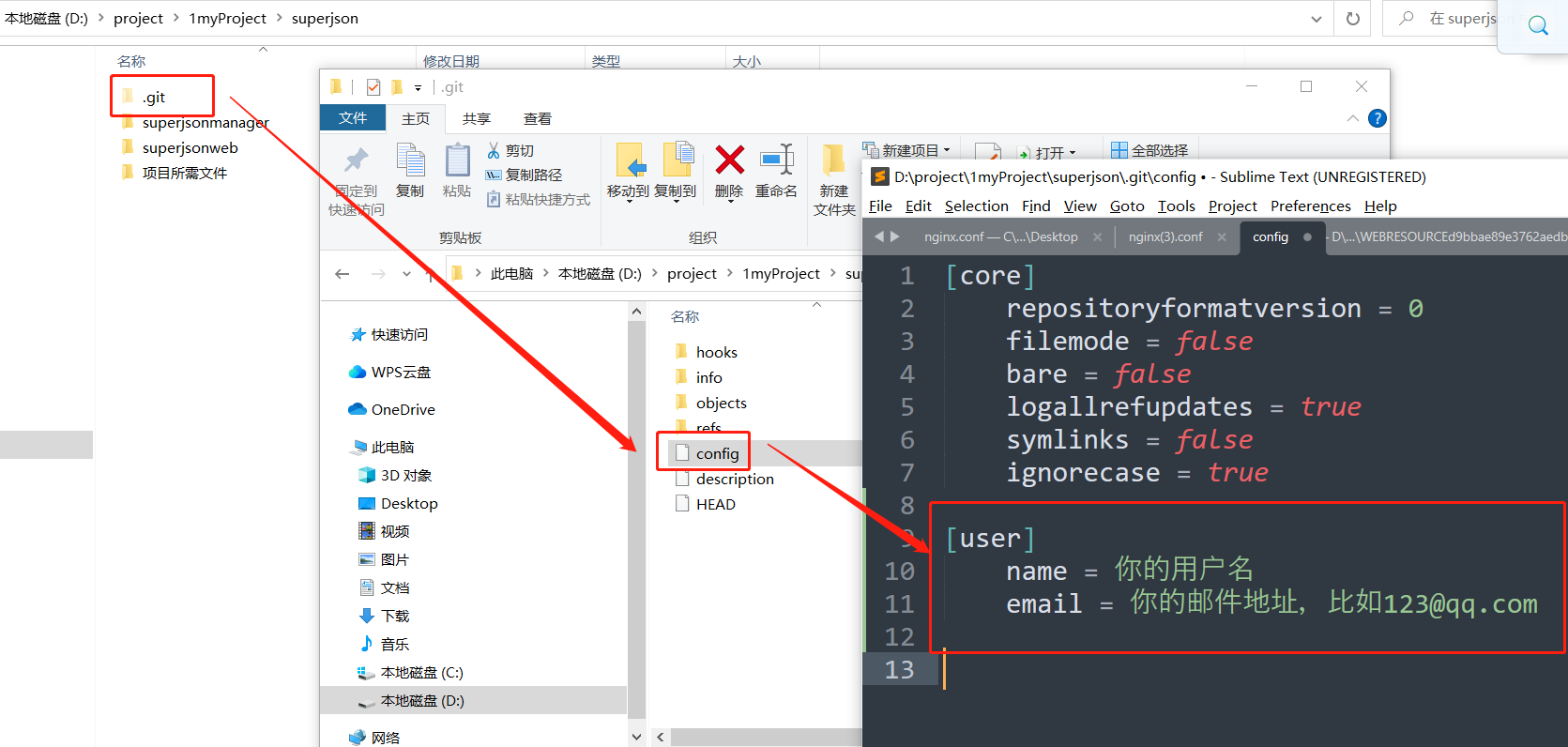
使用git config --global设置用户名和邮件,以及git config的全局和局部配置
文章目录 1. 文章引言2. 全局配置2.1 命令方式2.2 配置文件方式 3. 局部配置3.1 命令方式3.2 配置文件方式 4. 总结 1. 文章引言 我们为什么要设置设置用户名和邮件? 我们在注册github,gitlab等时,一般使用用户名或邮箱: 这个用户…...

【C语言】21-指针-3
目录 1. 指针数组1.1 什么是指针数组1.2 如何定义指针数组1.3 如何使用指针数组2. 多重指针2.1 二重指针的定义2.2 二重指针的初始化与赋值2.3 二重指针的使用3. 指针常量、常量指针、指向常量的常指针3.1 概念3.2 const pointer3.3 pointer to a constant3.3.1 (pointer to a …...
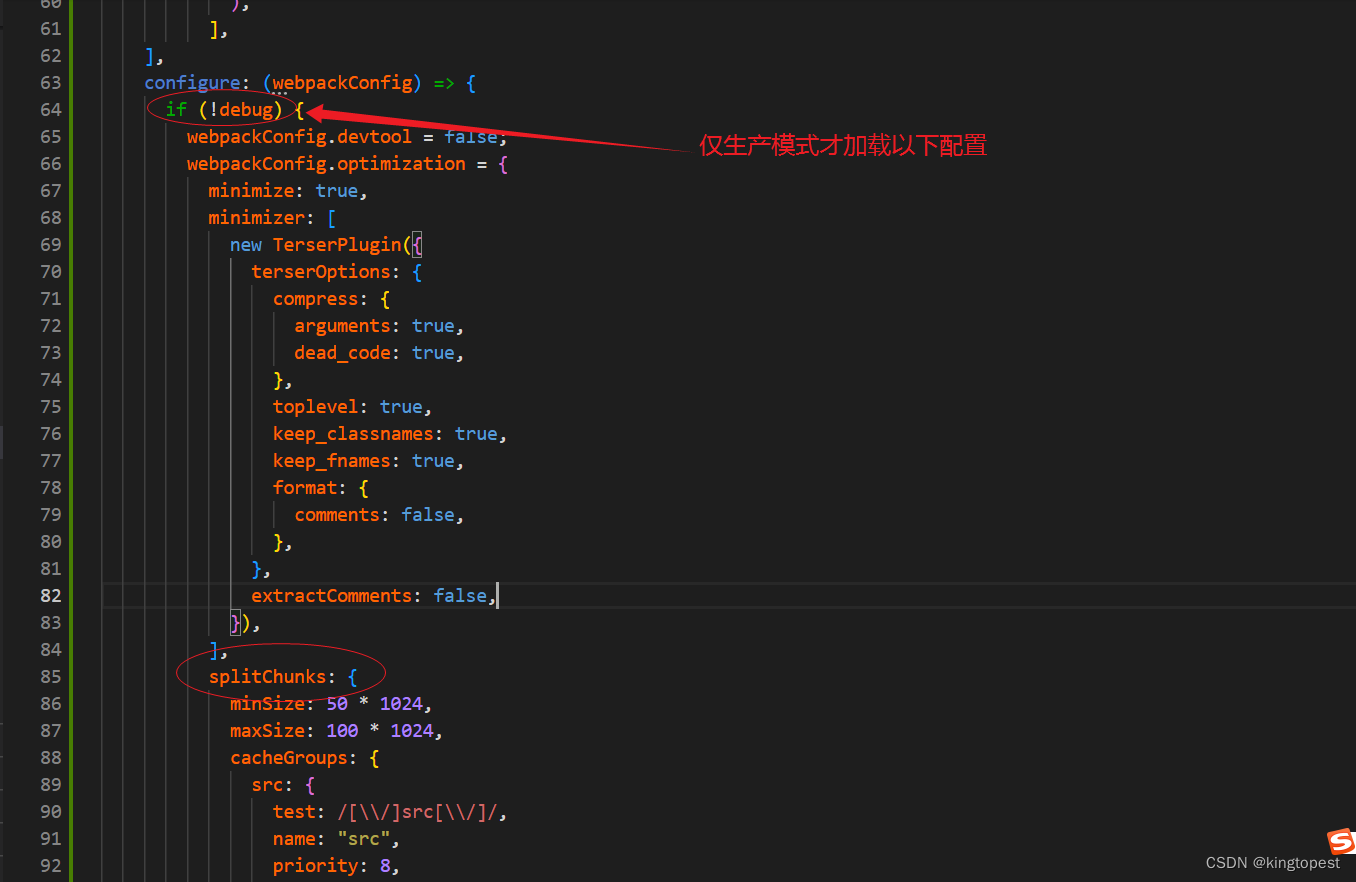
解决craco启动react项目卡死在Starting the development server的问题
现象: 原因:craco.config.ts配置文件有问题 经过排查发现Dev开发模式下不能有splitChunk的配置, 解决办法: 加一个生产模式的判断,开发模式不加载splitChunk的配置,仅在生产模式才加载 判断条件代码&#…...

告别虚拟机臃肿:用QEMU+OVMF在Ubuntu上快速搭建一个32MB的极简Linux内核调试环境
极简Linux内核调试环境:QEMUOVMF实战指南 每次打开臃肿的虚拟机都要等待漫长的启动时间,看着进度条缓慢爬行,作为开发者的你是否感到效率被无情吞噬?在调试内核模块或研究启动流程时,我们真正需要的只是一个轻量级、即…...

储能出海架构重构:摒弃传统x86工控机,基于ARM边缘节点的EMS策略下沉实战
摘要: 随着储能系统在全球范围的大规模部署,出海项目的硬件BOM成本压力与恶劣环境下的维护成本日益凸显。传统的“x86工控机下发控制 透传网关上传数据”的双体架构显得极度臃肿且易引发单点故障。本文从底层研发架构师视角出发,深度拆解符合…...
)
【仅限奇点大会注册开发者获取】:Istio for AI策略模板库(含RAG路由、推理超时分级、Token流控等12个YAML黄金配置)
更多请点击: https://intelliparadigm.com 第一章:AI原生服务网格应用:2026奇点智能技术大会Istio for AI 在2026奇点智能技术大会上,Istio社区正式发布 Istio for AI —— 一个专为大模型推理、微调与多租户AI工作负载设计的服务…...

终极Dell G15温度控制解决方案:开源软件TCC-G15完整指南
终极Dell G15温度控制解决方案:开源软件TCC-G15完整指南 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 还在为你的Dell G15笔记本高温发烫而烦恼吗…...

iOS激活锁终极绕过指南:开源工具applera1n的完整解决方案
iOS激活锁终极绕过指南:开源工具applera1n的完整解决方案 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 面对iOS设备激活锁的困扰,你是否曾为无法使用二手iPhone而烦恼&#x…...

免费LLM API集成实战:从选型到构建高可用AI服务
1. 项目概述:一个汇聚免费LLM API的宝藏仓库如果你正在开发一个需要AI对话、文本生成或代码补全功能的应用,但又被高昂的API调用费用或复杂的申请流程劝退,那么你很可能需要这个项目。Clovenhoofed-loadingarea139/awesome-free-llm-apis是一…...

Cursor AI 编辑器一键配置指南:从零搭建高效编程工作站
1. 项目概述:一个为 Cursor 编辑器量身定制的“开箱即用”向导如果你是一名开发者,最近肯定没少听人提起 Cursor 这款编辑器。它基于 VS Code,但深度集成了 AI 能力,号称能理解你的代码上下文,帮你写代码、改 Bug、甚至…...

LNG船BOG再液化系统流程优化与动态蒸发率控制【附模型】
✨ 本团队擅长数据搜集与处理、建模仿真、程序设计、仿真代码、EI、SCI写作与指导,毕业论文、期刊论文经验交流。 ✅ 专业定制毕设、代码 ✅如需沟通交流,点击《获取方式》 (1)液氮预冷BOG缓冲再液化系统流程设计与Aspen HYSYS建模…...
技术解析:提升网络速度与容量的关键手段)
5G载波聚合(CA)技术解析:提升网络速度与容量的关键手段
5G载波聚合(CA)技术解析:提升网络速度与容量的关键手段 在5G通信技术不断演进的进程中,载波聚合(Carrier Aggregation,简称CA)作为一项重要技术,正逐渐成为提升网络性能、满足用户多…...

XUnity.AutoTranslator完整指南:让Unity游戏告别语言障碍的终极解决方案
XUnity.AutoTranslator完整指南:让Unity游戏告别语言障碍的终极解决方案 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾因为语言不通而错过精彩的日本RPG游戏?是否面对欧…...