Hive【Hive(三)查询语句】
前言
今天是中秋节,早上七点就醒了,干啥呢,大一开学后空教室紧缺,还不趁着假期来学校等啥呢。顺便偷偷许个愿吧,希望在明年的这个时候,秋招不知道赶不赶得上,我希望拿几个国奖,蓝桥杯、中国大学生计算机设计大赛、挑战杯、软件杯... 。最大的愿望还是能够早点找到一份心仪的工作!!!不说了,开卷!
Hive 查询语句
查询语句必然是 Hive 的重中之重,之前的 SQL 基础也不是那么牢固,尤其是高级的 SQL 语句,这里需要恶补一下。
1、基本语法
每个关键字的顺序不能颠倒。
SELECT [ALL | DISTINCT] 字段1, 字段2, ...FROM 表名[WHERE 条件][GROUP BY 字段] --分组查询[HAVING 字段] --分组后过滤(group by 后只能用 having 不能再用 where)[ORDER BY 字段] --排序[CLUSTER BY col_list| [DISTRIBUTE BY col_list] [SORT BY col_list]][LIMIT 页数] --分页显示
2、基本查询
2.1、数据准备(Select…From)
创建文件 dept.txt、emp.txt、loc.txt。
dept.txt:
10 行政部 1700
20 财务部 1800
30 教学部 1900
40 销售部 1700emp.txt:
7369 张三 研发 800.00 30
7499 李四 财务 1600.00 20
7521 王五 行政 1250.00 10
7566 赵六 销售 2975.00 40
7654 侯七 研发 1250.00 30
7698 马八 研发 2850.00 30
7782 金九 \N 2450.0 30
7788 银十 行政 3000.00 10
7839 小芳 销售 5000.00 40
7844 小明 销售 1500.00 40
7876 小李 行政 1100.00 10
7900 小元 讲师 950.00 30
7902 小海 行政 3000.00 10
7934 小红明 讲师 1300.00 30loc.txt:
1700 北京
1800 上海
1900 深圳创建表
dept:
use default;
-- 创建部门表 在hdfs生成目录: /user/hive/warehouse/dept
create table if not exists dept(deptno int, --部门编号dname string, --部门名称loc int --部门位置
)
row format delimited fields terminated by '\t';
emp:
-- 创建员工表 在hdfs生成目录: /user/hive/warehouse/emp
create table if not exists emp(empno int, --员工编号ename string, --员工姓名job string, --员工岗位sal double, --员工工资deptno int --部门编号
)
row format delimited fields terminated by '\t';location:
create table location(loc int,loc_name string
)
row format delimited fields terminated by '\t';导入数据
load data local inpath '/opt/module/hive-3.1.2/datas/dept.txt' into table dept;load data local inpath '/opt/module/hive-3.1.2/datas/emp.txt' into table emp;load data local inpath '/opt/module/hive-3.1.2/datas/loc.txt' into table location;2.2、全表和特定列查询
-- 查询全表
select * from emp;
-- 查询指定字段
select empno,ename from emp;
2.3、列别名
可以省去 as 。
-- 列别名 as 或者 直接字段后跟 别名
select empno as id,ename name from emp;2.3、limit 分页显示
-- 分页显示 limit(begin,len) begin从0开始算起 向下读取len行
select * from emp limit 5;
select * from emp limit 0,3;2.4、关系运算符(between、in、is Null)
这里只
-- 关系运算符
-- 查询部门id为30或20的员工信息
select * from emp
where deptno in (30,20);
-- 比较运算符
select * from emp where sal =3000;
select * from emp where sal between 500 and 1000;
select * from emp where job is null;2.5、逻辑运算符(and、or、not)
-- 查询除了20部门和30部门以外的员工信息select * from emp where deptno not IN(30, 20);2.6、like 和 Rlike
like 可以用来进行 模糊匹配:
- % 代表零个或多个字符(任意个字符)。
- _ 代表一个字符。
Rlike 是 Hive 对like的扩展,使它可以通过Java的正则表达式这个更强大的语言来指定匹配条件。
-- 查找名字以A开头的员工信息
select * from emp where ename LIKE ‘A%’; hiveselect * from emp where ename RLIKE ‘^A’;3、分组
3.1、group by
GROUP BY语句通常会和聚合函数一起使用,按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作。
注意:使用聚合函数必须使用 group by!
在 Hive 中,当你在查询语句中使用聚合函数(如sum())时,你需要使用group by子句来对数据进行分组。这是因为聚合函数会对每个组的数据进行操作,而不是对整个数据集进行操作。
-- 计算没个部门的平均工资
select t.deptno, avg(t.sal) from emp t group by t.deptno; --用时27s--计算每个部门中每个岗位的最高薪水
select t.deptno,t.job,max(t.sal) from emp t group by t.deptno,t.job; --用时22s3.2、having
如果我们要对分组后的结果进行条件过滤,这时候不能使用 where ,需要使用 having。
-- 使用 where 对grou by的结果进行再次过滤
select job,cnt from
(select job,count(*) cnt from emp group by job)t1
where cnt>=2;-- 上面的写法太复杂了 所以有了 having
select job,count(*) cnt from emp having cnt>=2;-- 查询平均工资>1000的部门id
select deptno,avg(sal) avg_sal from emp group by deptno having avg_sal > 1000;4、Join 语句
4.1、内连接
返回两张表中满足关联条件的行,拼接成一张宽表(因为两张表横向合并,字段增加)
-- 内连接 (返回两张表的所有能关联上(满足e.deptno = d.deptno)的行)
-- 根据部门编号查询出员工的部门名称
select e.empno,e.ename,d.dname from emp e join dept d on e.deptno = d.deptno;4.2、左外连接
把左表的全部行和右表进行拼接,右表如果不满足拼接条件,则拼接的部分补 NULL。
当执行左外连接时,Hive 会将左表的每一行与右表中满足关联条件的行进行匹配。如果右表中存在匹配的行,则返回左表和右表中匹配行的组合。如果右表中不存在匹配的行,则返回左表的行,右表的部分将用 NULL 值填充。
-- 左外连接 (返回左表的全部行)
select e.empno,e.ename,d.deptno from emp e left join dept d on e.deptno = d.deptno;4.3、右外连接
把右表的全部行和左表进行拼接,左表如果不满足拼接条件,则拼接的部分补 NULL。
-- 右外连接 (返回右表的全部行)
select e.empno,e.ename,d.deptno from emp e right join dept d on e.deptno = d.deptno;4.4、满外连接
返回左表和右表中所有的行,以及两者之间满足连接条件的匹配行。如果某一侧的表中没有匹配的行,则返回NULL值。
-- 满外连接
select e.empno,e.ename,d.deptno from emp e full join dept d on e.deptno = d.deptno;4.5、多表连接
大多数情况下,Hive会对每对join连接对象启动一个MapReduce任务。本例中会首先启动一个MapReduce job对表e和表d进行连接操作,然后会再启动一个MapReduce job将第一个MapReduce job的输出和表l进行连接操作。
-- 用emp表的deptno 关联dept表的deptno字段,再用dept表的loc字段关联location表的loc字段
select * from emp e
join dept don e.deptno = d.deptno
join location l
on d.loc = l.loc;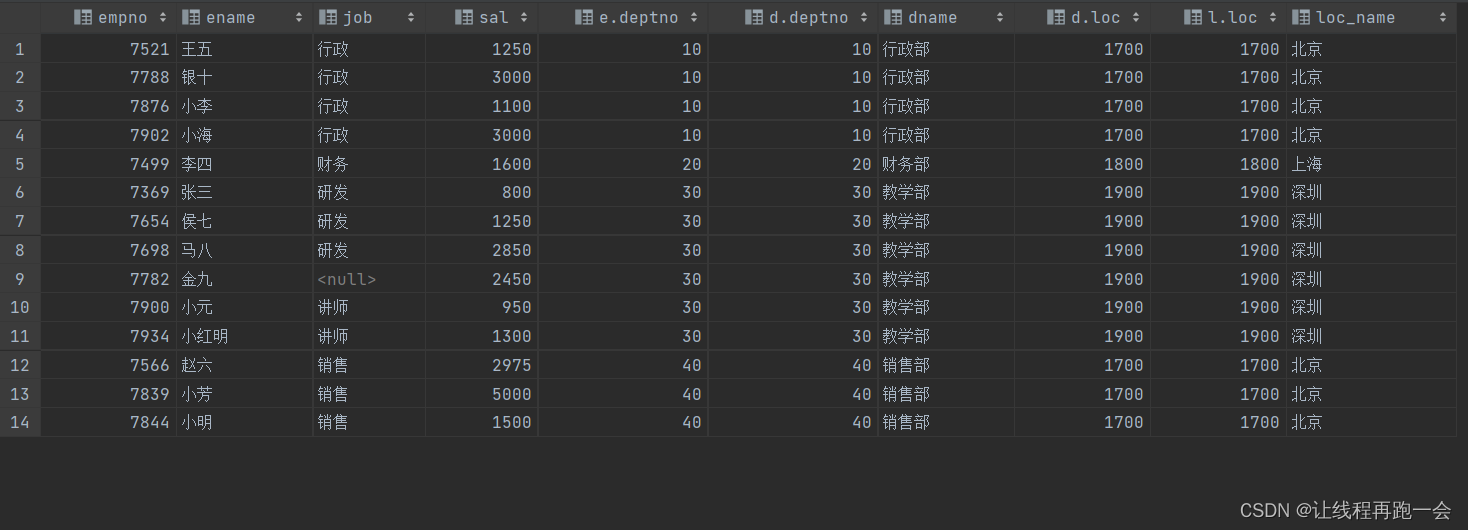 4.6、笛卡尔集
4.6、笛卡尔集
笛卡尔集会在下面条件下产生
- 省略连接条件
- 连接条件无效
- 所有表中的所有行互相连接
--笛卡尔集 (把a表每一行数据和b表每一行数据关联到一起) 不要轻易使用
-- a | 1 => (a,1)(b,1)(c,1)
-- b | 2 => (a,2)(b,2)(c,2)
-- c | 3 => (a,3)(b,3)(c,3)
-- 结果总行数: a行数*b行数, 3*3=9行
select empno,dname from emp,dept;4.7、联合(union、union all)
纵向拼接,要求必须字段数相同,字段类型相同。
-- 联合union
-- join 是横向拼接(形成宽表,增加了字段) 而 union是纵向拼接(增加表的数据,也就是两张表的大部分字段的个数和类型必须一致)
-- union去重,union all不去重
select * from emp
where deptno = 30
union
select * from emp
where deptno = 20;5、排序
5.1、全局排序(Order By)
语法:
select * from 表名 order by 字段 [asc | desc];asc:升序(默认)
desc:降序
-- 1.全局排序 order by
-- asc: 升序 desc:降序
select * from emp order by sal;我们在实际开发中,order by 其实是一个比较危险的操作,因为我们一个 order by 操作的底层中,Map 可能是多个 Map 任务,但是 Reduce 任务默认只有一个。这样的话,如果我们这张表对应的数据源非常大,那么 Reduce 任务的压力可想而知。
实际开发中,我们更多的时候并不需要整个结果排好序的数据,而往往要的是前几个或者后几个数据,所以我们的 order by 经常是配合 limit 来使用的。这样的性能往往是最好的,因为假如有100w条数据,我们只需要前100个升序的结果,那么我们就可以让 Reduce 任务只拉取每个 Map 任务的前 100 条数据即可。
select * form 表名 order by 字段 limit 100;5.2、每个Reducer内部排序(Sort By)
作用:指定排序字段。
对于很大规模的数据,order by 可以保证所有的数据结果保存在一个文件并全局有序,但是很多时候,我们并不需要全局排序,此时可以使用 sort by。
sort by 为每个 Reduce 任务产生一个排序文件,只能保证每个 Reduce 任务的结果有序,而不是全局有序。
设置 reduce 个数
-- 设置reduce 任务数量为 3
set mapreduce.job.reduces = 3;查看 reduce 个数
set mapreduce.job.reduces;测试
-- 根据员工薪资进行降序排序
select * from emp sort by sal desc ;运行结果:
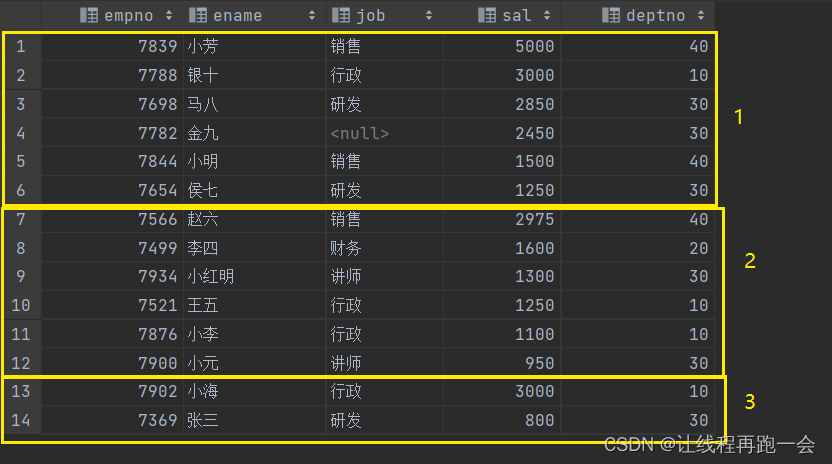
我们的数据并不是全局有序,而是分为了3块(reduce 任务个数),各自局部有序。
这里,我在 reduce 任务数为 3 的情况下又测试了一遍 order by,发现结果是全局有序了,说明有两个 reduce 任务没有开启。
将查询结果导出到文件中
-- 格式化导出
insert overwrite local directory '/opt/module/hive-3.1.2/datas/sortby-result'
row format delimited fields terminated by '\t'
select * from emp sort by sal; 运行结果: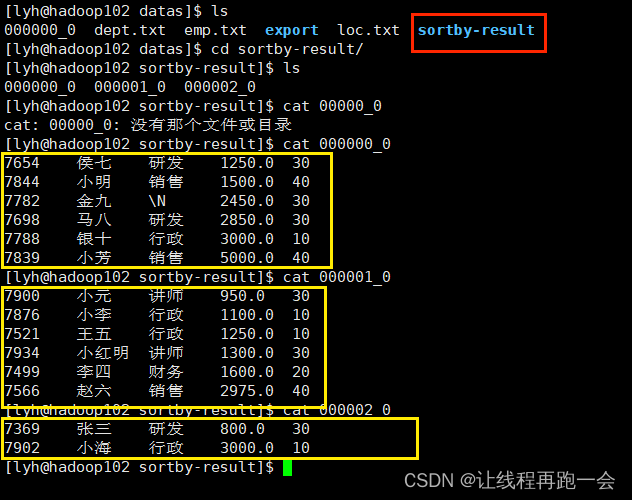
可以看到,一共导出了3个文件,分别内部有序。
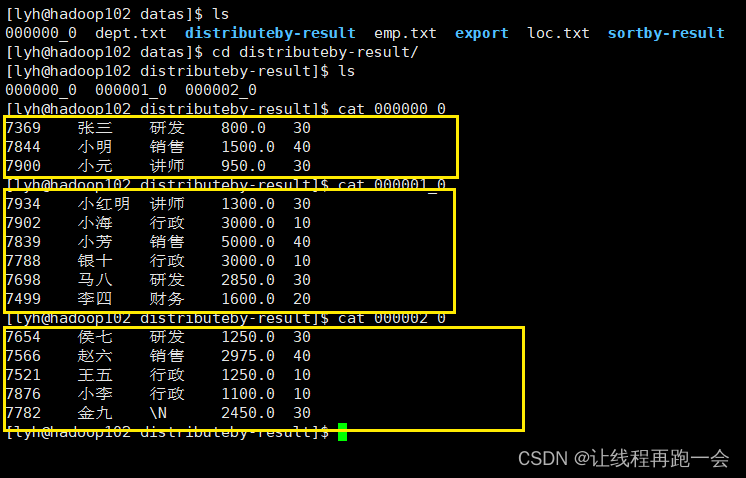
5.3、分区(Distribute By)
作用:指定分区字段
我们 hadoop 默认的分区规则如下:
public int getPartition(K key, V value, int numReduceTasks) {return (key.hashCode() & 2147483647) % numReduceTasks;}这里,我们指定我们的 Reduce 任务数为 3,这样理论应该产生 3 个分区:
insert overwrite local directory '/opt/module/hive-3.1.2/datas/distributeby-result'
row format delimited fields terminated by '\t'
select * from emp distribute by sal;运行结果:
5.4、分区排序(Cluster By)
如果我们的分区字段(distribute by)和排序字段(sort by)是同一个字段的时候,我们可以简写为 cluster by 。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
select * from emp cluster by deptno;相当于
select * from emp
sort by deptno
distribute by deptno;相关文章:
Hive【Hive(三)查询语句】
前言 今天是中秋节,早上七点就醒了,干啥呢,大一开学后空教室紧缺,还不趁着假期来学校等啥呢。顺便偷偷许个愿吧,希望在明年的这个时候,秋招不知道赶不赶得上,我希望拿几个国奖,蓝桥杯…...
商场做小程序商城的作用是什么?
商场是众多商家聚集在一起的购物公共场所,大商场也往往入驻着众多行业商家,是每个城市重要的组成部分。 随着互联网电商深入及客户消费行为改变,不少商场如今的客流量非常有限,甚至可以说是员工比客人多,这就导致撤店…...
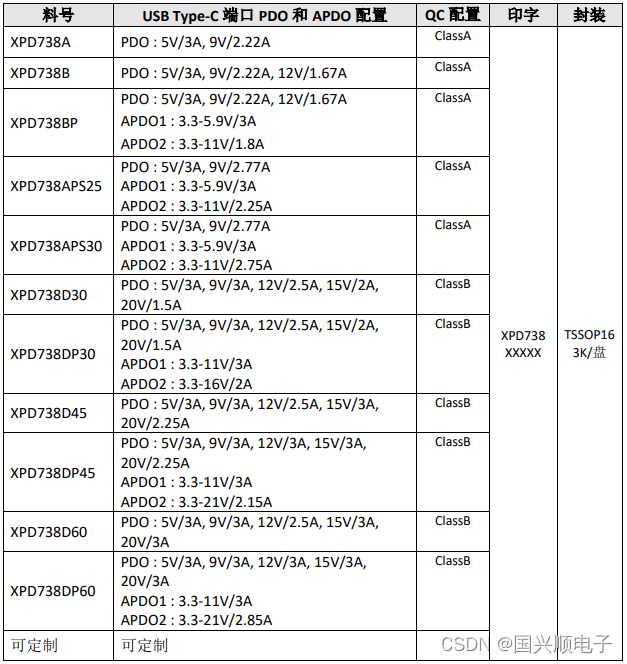
XPD738协议系列-USB Type-C PD 和 Type-A 双口控制器
产品描述: XPD738 是一款集成 USB Type-C、USB Power Delivery(PD)2.0/3.0 以及 PPS、QC3.0/QC3.0/QC2.0 快充协议、华为 FCP/SCP/HVSCP 快充协议、三星 AFC 快充协议、BC1.2 DCP 以及苹果设备 2.4A 充电规范的多功能 USB Type-C 和 Type-A …...

【面试八股】IP协议八股
IP协议八股 子网掩码的作用为什么IP协议需要分片IP协议什么时候需要分片IP协议是怎么进行分片的那么IP协议是如果进行标识属于同一个分片呢?TCP协议和UDP协议将数据交给IP协议之后,是否需要分片传输? 子网掩码的作用 用来标识网络号和主机号…...
【冰糖R语言】创建R包(打包R程序)
目标:将现有R程序打包 可能涉及知识点:devtools包、usethis包、Rstudio软件 一、R包的类型 通常一个R包中包含以下元素: 1)R文件夹:函数代码 2)man文件夹:存放每个函数的注释文件 3&#x…...
照片后期处理软件DxO FilmPack 6 mac中文说明
DxO FilmPack 6 for Mac是一款照片后期处理软件。它可以模拟超过60种著名胶片品牌和类型的色彩和颗粒感,使照片具有复古、艺术和时尚风格。 DxO FilmPack 6 mac支持RAW和JPG格式的照片,并提供丰富的调整选项,如亮度、对比度、曝光、阴影和高…...
51单片机音乐闹钟秒表倒计时整点报时多功能电子钟万年历数码管显示( proteus仿真+程序+原理图+报告+讲解视频)
51单片机音乐闹钟秒表倒计时整点报时多功能电子钟万年历数码管显示( proteus仿真程序原理图报告讲解视频) 讲解视频1.主要功能:2.仿真3. 程序代码4.原理图5. 设计报告6. 设计资料内容清单 51单片机音乐闹钟秒表倒计时整点报时多功能电子钟万年历数码管显…...

Scala第九章节
Scala第九章节 scala总目录 章节目标 理解包的相关内容掌握样例类, 样例对象的使用掌握计算器案例 1. 包 实际开发中, 我们肯定会遇到同名的类, 例如: 两个Person类. 那在不改变类名的情况下, 如何区分它们呢? 这就要使用到包(package)了. 1.1 简介 包就是文件夹, 用关…...
arduino - UNO-R3,mega2560-R3,NUCLEO-H723ZG的arduino引脚定义区别
文章目录 arduino - UNO-R3,mega2560-R3,NUCLEO-H723ZG的引脚定义区别概述笔记NUCLEO-H723ZGmega2560-R3UNO-R3经过比对, 这2个板子(NUCLEO-H723ZG, mega2560-R3)都是和UNO-R3的arduino引脚定义一样的.mega2560-r3和NUCLEO-H723ZG的区别补充arduino uno r3的纯数字IO和模拟IO作…...

提取多个txt数据并合成excel——例子:与中国建交的国家
提取多个txt数据并合成excel——例子:与中国建交的国家 一、概要二、整体架构流程三、完整代码 一、概要 这段代码主要执行以下任务: 1. 定义辅助函数:首先,定义了两个辅助函数。has_chinese_chars函数用于检查给定的字符串中是否…...

uni-app:js修改元素样式(宽度、外边距)
效果 代码 1、在<view>元素上添加一个ref属性,用于在JavaScript代码中获取对该元素的引用:<view ref"myView" id"mybox"></view> 2、获取元素引用 :const viewElement this.$refs.myView.$el; 3、修改…...

day36-单元测试
1. 单元测试Junit 1.1 什么是单元测试?(掌握) 对部分代码进行测试。 1.2 Junit的特点?(掌握) 是一个第三方的工具。(把别人写的代码导入项目中)(专业叫法:…...

7、脏话检测
6、片花关联长视频 脏话检测功能本身远不如上一篇介绍的片花关联长视频有技术挑战性,不过还是值得说说,因为这是我们采用技术方式提高工作效率的第一次尝试。 游戏解说是审核难度比较大的一类短视频内容,一方面是时间比较长,很多…...
Godot信号教程(使用C#语言)| 创建自定义信号 | 发出自定义信号 | 使用代码监听信号
文章目录 信号是什么连接信号使用编辑器连接信号使用代码连接信号Lambda 自定义信号声明信号发射信号带参数的信号 其他文章 信号是什么 在Godot游戏引擎中,信号是一种用于对象之间通信的重要机制。它允许一个对象发出信号,而其他对象可以连接到这个信号…...
分布式文件存储系统minio、大文件分片传输
上传大文件 1、Promise对象 Promise 对象代表一个异步操作,有三种状态: pending: 初始状态,不是成功或失败状态。fulfilled: 意味着操作成功完成。rejected: 意味着操作失败。 只有异步操作的结果,可以决定当前是哪一种状态&a…...

在 msys2/mingw 下安装及编译 opencv
最简单就是直接安装 pacman -S mingw-w64-x86_64-opencv 以下记录一下编译的过程 1. 安装编译工具及第三方库 pacman -S --needed base-devel mingw-w64-x86_64-toolchain unzip gccpacman -S python mingw-w64-x86_64-python2 mingw-w64-x86_64-gtk3 mingw-w64-x86_64-…...

java 根据身份证号码判断性别
在Java中,您可以根据身份证号码的规则来判断性别。中国的身份证号码通常采用的是以下规则: 第17位数字代表性别,奇数表示男性,偶数表示女性。 通常,男性的出生日期的第15、16位数字是01,女性是02。 请注意&…...
)
信息服务上线渗透检测网络安全检查报告和解决方案4(XSS漏洞修复)
系列文章目录 信息服务上线渗透检测网络安全检查报告和解决方案2(安装文件信息泄漏、管理路径泄漏、XSS漏洞、弱口令、逻辑漏洞、终极上传漏洞升级)信息服务上线渗透检测网络安全检查报告和解决方案信息服务上线渗透检测网络安全检查报告和解决方案3(系统漏洞扫描、相对路径覆…...
【SQL】mysql创建定时任务执行存储过程--20230928
1.先设定时区 https://blog.csdn.net/m0_46629123/article/details/133382375 输入命令show variables like “%time_zone%”;(注意分号结尾)设置时区,输入 set global time_zone “8:00”; 回车,然后退出重启(一定记得重启&am…...
安全基础 --- MySQL数据库解析
MySQL的ACID (1)ACID是衡量事务的四个特性 原子性(Atomicity,或称不可分割性)一致性(Consistency)隔离性(Isolation)持久性(Durability) &…...

从测试开发到智能体工程师,我的转型全流程,全是避坑指南
文章目录 前言一、为什么我要从测试开发转智能体工程师1.1 测试开发的职业天花板,比我想象的还要低1.2 AI正在以惊人的速度,吞噬传统测试的工作1.3 智能体赛道,是程序员最后的红利期 二、转型前我踩过的那些致命大坑2.1 坑1:上来就…...

如何高效拆分CATIA多实体零件:pycatia自动化解决方案的完整指南
如何高效拆分CATIA多实体零件:pycatia自动化解决方案的完整指南 【免费下载链接】pycatia python module for CATIA V5 automation 项目地址: https://gitcode.com/gh_mirrors/py/pycatia 在CATIA三维设计领域,工程师们经常面临一个常见挑战&…...

桌面3D扫描技术解析:从结构光原理到实战避坑指南
1. 从工业殿堂到桌面工坊:3D扫描的平民化浪潮 几年前,如果你跟人提起3D扫描,脑海里浮现的画面多半是电影特效工作室里,演员身上贴满标记点,被一圈昂贵的专业相机环绕;或者是汽车制造车间里,巨大…...

终极指南:使用boardgame.io在React Native中开发跨平台棋盘游戏的完整教程
终极指南:使用boardgame.io在React Native中开发跨平台棋盘游戏的完整教程 【免费下载链接】boardgame.io State Management and Multiplayer Networking for Turn-Based Games 项目地址: https://gitcode.com/gh_mirrors/bo/boardgame.io 想要在移动设备上创…...

发现开源神器:三步解锁卡车模拟器的智能驾驶新纪元
发现开源神器:三步解锁卡车模拟器的智能驾驶新纪元 【免费下载链接】Euro-Truck-Simulator-2-Lane-Assist Plugin based interface program for ETS2/ATS. 项目地址: https://gitcode.com/gh_mirrors/eur/Euro-Truck-Simulator-2-Lane-Assist 你是否曾梦想在…...

C语言中的strchr函数
strchr是string.h库中的函数,它的形式为: char * strchr (char * str, int character );功能: 返回一个指针,指向字符在 C 字符串 str 中第一次出现的位置。C 字符串末尾的空字符 \0 被视为字符串的一部分。因此,你也可…...

PyInstaller打包PyTorch项目,为什么我最终放弃了单文件exe?
PyInstaller打包PyTorch项目:为什么单文件exe不是最佳选择? 当我们需要将基于PyTorch的AI应用分发给终端用户时,打包工具的选择往往决定了最终用户体验的好坏。许多开发者最初会被PyInstaller的单文件exe方案吸引——毕竟,谁不想给…...

基于RAG架构的本地知识库构建:从原理到Shannon实战
1. 项目概述:一个面向开发者的高效本地知识库构建工具最近在折腾个人知识管理和团队文档沉淀时,发现了一个挺有意思的开源项目,叫Shannon。这项目名挺有深意,取自信息论之父克劳德香农,一听就知道是跟信息处理和知识组…...

工业控制中自定义串行总线协议的设计与实现:DataView系统实战
1. 项目背景与核心需求:为什么需要自定一个串行总线?在工业控制领域,尤其是信号调理模块和开关电源这类产品里,我们常常会遇到一个看似简单、实则棘手的问题:如何在有限的成本、空间和算力下,为多个分散的模…...

四川全行业 APP 开发服务商参考
随着四川各行业数字化进程加快,APP 开发覆盖政务、电商、教育、生活服务、企业管理等多元场景,市场服务商在行业适配、技术能力、服务保障上各有侧重。本文结合多行业落地案例、技术全面性、交付稳定性、运维支持能力,整理全行业适配的 APP 开…...