Flink-CDC——MySQL、SqlSqlServer、Oracle、达梦等数据库开启日志方法
目录
1. 前言
2. 数据源安装与配置
2.1 MySQL
2.1.1 安装
2.1.2 CDC 配置
2.2 Postgresql
2.2.1 安装
2.2.2 CDC 配置
2.3 Oracle
2.3.1 安装
2.3.2 CDC 配置
2.4 SQLServer
2.4.1 安装
2.4.2 CDC 配置
2.5达梦
2.4.1安装
2.4.2CDC配置
3. 验证
3.1 Flink版本与CDC版本的对应关系
3.2 下载相关包
3.3 添加cdc jar 至lib目录
3.4 验证
1. 前言
关于如何使用和配置flink cdc功能,其实在官方文档(https://ververica.github.io/flink-cdc-connectors/master/)有相关的教程了
本文主要就是记录在docker下安装和配置各种数据源,以实现flink cdc的功能,包含如下常见的数据源:
数据源 版本
MySQL 8.0.25
Postgresql 10.6
Oracle 11g
SqlServer 2019
2. 数据源安装与配置
2.1 MySQL
版本:8.0.25
2.1.1 安装
Step1: 拉取mysql镜像:
docker pull mysql:8.0.25
Step2: 创建并运行 MySQL 容器
docker run -d -p 30025:3306 --name mysql8.0.25 -e MYSQL_ROOT_PASSWORD=root mysql:8.0.25
2.1.2 CDC 配置
Step1:进入正在运行的mysql容器:
docker exec -it mysql8.0.25 mysql -uroot -proot
Step2:配置 CDC
-- 启用二进制日志
mysql> SET GLOBAL log_bin = ON;
-- 设置二进制日志格式为行级别
mysql> SET GLOBAL binlog_format = 'ROW';
Step3(非必要):如果配置没生效,重启容器
docker restart mysql8.0.25
2.2 Postgresql
版本:PostgreSQL 10.6 (Debian 10.6-1.pgdg90+1)
2.2.1 安装
Step1: 拉取 PostgreSQL 10.6 版本的镜像:
docker pull postgres:10.6
Step2:创建并启动 PostgreSQL 容器,在这里,我们将把容器的端口 5432 映射到主机的端口 30028,账号密码设置为postgres,并将 pgoutput 插件加载到 PostgreSQL 实例中:
docker run -d -p 30028:5432 --name postgres-10.6 -e POSTGRES_PASSWORD=postgres postgres:10.6 -c 'shared_preload_libraries=pgoutput'
Step3: 查看容器是否创建成功:
docker ps | grep postgres-10.6
2.2.2 CDC 配置
Step1:docker进去Postgresql数据的容器:
docker exec -it postgres-10.6 bash
Step2:编辑postgresql.conf配置文件:
vi /var/lib/postgresql/data/postgresql.conf
配置内容如下:
# 更改wal日志方式为logical(方式有:minimal、replica 、logical )
wal_level = logical
# 更改solts最大数量(默认值为10),flink-cdc默认一张表占用一个slots
max_replication_slots = 20
# 更改wal发送最大进程数(默认值为10),这个值和上面的solts设置一样
max_wal_senders = 20
# 中断那些停止活动超过指定毫秒数的复制连接,可以适当设置大一点(默认60s,0表示禁用)
wal_sender_timeout = 180s
Step3:重启容器:
docker restart postgres-10.6
连接数据库,如果查询一下语句,返回logical表示修改成功:
SHOW wal_level;
Step4:新建用户并赋权。使用创建容器时的账号密码(postgres/postgres)登录Postgresql数据库。
-- 创建数据库 test_db
CREATE DATABASE test_db;
-- 连接到新创建的数据库 test_db
\c test_db
-- 创建 t_user 表
CREATE TABLE "public"."t_user" (
"id" int8 NOT NULL,
"name" varchar(255),
"age" int2,
PRIMARY KEY ("id")
);
-- pg新建用户
CREATE USER test1 WITH PASSWORD 'test123';
-- 给用户复制流权限
ALTER ROLE test1 replication;
-- 给用户登录数据库权限
GRANT CONNECT ON DATABASE test_db to test1;
-- 把当前库public下所有表查询权限赋给用户
GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA public TO test1;
Step4:发布表:
-- 设置发布为true
update pg_publication set puballtables=true where pubname is not null;
-- 把所有表进行发布
CREATE PUBLICATION dbz_publication FOR ALL TABLES;
-- 查询哪些表已经发布
select * from pg_publication_tables;
-- 更改复制标识包含更新和删除之前值(目的是为了确保表 t_user 在实时同步过程中能够正确地捕获并同步更新和删除的数据变化。如果不执行这两条语句,那么 t_user 表的复制标识可能默认为 NOTHING,这可能导致实时同步时丢失更新和删除的数据行信息,从而影响同步的准确性)
ALTER TABLE t_user REPLICA IDENTITY FULL;
-- 查看复制标识(为f标识说明设置成功,f(表示 full),否则为 n(表示 nothing),即复制标识未设置)
select relreplident from pg_class where relname='t_user';
2.3 Oracle
版本:Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production
2.3.1 安装
Step1:拉取 oracle 11g 镜像(有6g,要等较长的时间)
docker pull registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g
Step2:执行以下命令以创建并运行 Oracle 11g 容器
docker run -d -p 30026:1521 -p 8081:8080 \
--name oracle_11g \
-e ORACLE_HOME=/home/oracle/app/oracle/product/11.2.0/dbhome_2 \
-e ORACLE_SID=helowin \
registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g
Step3:查看容器是否启动
docker ps -a|grep oracle_11g
Step4:进入容器
docker exec -it oracle_11g bash
**Step5:**设置账号密码
# 1. 切换至root用户(默认是oracle用户),密码为helowin
su root
# 2. 创建软链接
ln -s $ORACLE_HOME/bin/sqlplus /usr/bin
# 3.切换回oracle用户
su oracle
# 4. 登录sql plus
sqlplus /nolog
conn /as sysdba
## 4.1 修改system用户密码为system
alter user system identified by system;
## 4.2 修改sys用户密码为system
alter user sys identified by system;
## 4.3 新增一个测试用户(用户名:test,密码:test123);
create user test identified by test123;
## 4.4 将dba权限给内部管理员账号和密码
grant connect,resource,dba to test;
## 4.5 修改密码策略规则为:密码永不过期
ALTER PROFILE DEFAULT LIMIT PASSWORD_LIFE_TIME UNLIMITED;
## 4.6 修改数据库最大连接数;
alter system set processes=1000 scope=spfile;
## 4.7 最后重启数据库;
shutdown immediate;
startup;
# 5.退出
exit
2.3.2 CDC 配置
Step1:进入容器
docker exec -it oracle_11g bash
Step2:以DBA的权限登录数据库
sqlplus /nolog
CONNECT sys/system AS SYSDBA
Step3:启用日志归档
-- 设置数据库恢复文件目标大小为10G
alter system set db_recovery_file_dest_size = 10G;
-- 设置数据库恢复文件目标路径
alter system set db_recovery_file_dest = '/home/oracle/app/oracle/product/11.2.0' scope=spfile;
-- 立即关闭数据库
shutdown immediate;
-- 以mount模式启动数据库
startup mount;
-- 启用数据库归档日志模式
alter database archivelog;
-- 打开数据库,允许用户访问
alter database open;
Step4:查看日志归档是否启用(如果显示“Archive Mode”表示已经启用)
archive log list;
Step5:创建表空间
-- 以DBA的权限登录数据库
sqlplus /nolog
CONNECT sys/system AS SYSDBA
-- 创建一个名为"logminer_tbs"的表空间
-- 指定表空间的数据文件路径为"/home/oracle/app/oracle/product/11.2.0/logminer_tbs.dbf",其中"/home/oracle/app/oracle/product/11.2.0"是数据文件存储的目录,"logminer_tbs.dbf"是数据文件的文件名
-- 设置表空间的初始大小为25MB
-- 如果数据文件已经存在且可重用,将其重用,否则创建一个新的数据文件
-- 启用表空间的自动扩展功能,即当表空间空间不足时,自动增加数据文件的大小
-- 设置表空间的最大允许大小为无限,即表空间可以无限制地自动扩展
CREATE TABLESPACE logminer_tbs DATAFILE '/home/oracle/app/oracle/product/11.2.0/logminer_tbs.dbf' SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
Step6:创建用户并赋权
-- 创建一个名为"flinkuser"的用户,密码为"flinkpw",将其默认表空间设置为"LOGMINER_TBS",并在该表空间上设置无限配额。
CREATE USER flinkuser IDENTIFIED BY flinkpw DEFAULT TABLESPACE LOGMINER_TBS QUOTA UNLIMITED ON LOGMINER_TBS;
-- 允许"flinkuser"用户创建会话,即允许该用户连接到数据库。
GRANT CREATE SESSION TO flinkuser;
-- (不支持Oracle 11g)允许"flinkuser"用户在多租户数据库(CDB)中设置容器。
-- GRANT SET CONTAINER TO flinkuser;
-- 允许"flinkuser"用户查询V_$DATABASE视图,该视图包含有关数据库实例的信息。
GRANT SELECT ON V_$DATABASE TO flinkuser;
-- 允许"flinkuser"用户执行任何表的闪回操作。
GRANT FLASHBACK ANY TABLE TO flinkuser;
-- 允许"flinkuser"用户查询任何表的数据。
GRANT SELECT ANY TABLE TO flinkuser;
-- 允许"flinkuser"用户拥有SELECT_CATALOG_ROLE角色,该角色允许查询数据字典和元数据。
GRANT SELECT_CATALOG_ROLE TO flinkuser;
-- 允许"flinkuser"用户拥有EXECUTE_CATALOG_ROLE角色,该角色允许执行一些数据字典中的过程和函数。
GRANT EXECUTE_CATALOG_ROLE TO flinkuser;
-- 允许"flinkuser"用户查询任何事务。
GRANT SELECT ANY TRANSACTION TO flinkuser;
-- (不支持Oracle 11g)允许"flinkuser"用户进行数据变更追踪(LogMiner)。
-- GRANT LOGMINING TO flinkuser;
-- 允许"flinkuser"用户创建表。
GRANT CREATE TABLE TO flinkuser;
-- 允许"flinkuser"用户锁定任何表。
GRANT LOCK ANY TABLE TO flinkuser;
-- 允许"flinkuser"用户修改任何表。
GRANT ALTER ANY TABLE TO flinkuser;
-- 允许"flinkuser"用户创建序列。
GRANT CREATE SEQUENCE TO flinkuser;
-- 允许"flinkuser"用户执行DBMS_LOGMNR包中的过程。
GRANT EXECUTE ON DBMS_LOGMNR TO flinkuser;
-- 允许"flinkuser"用户执行DBMS_LOGMNR_D包中的过程。
GRANT EXECUTE ON DBMS_LOGMNR_D TO flinkuser;
-- 允许"flinkuser"用户查询V_$LOG视图,该视图包含有关数据库日志文件的信息。
GRANT SELECT ON V_$LOG TO flinkuser;
-- 允许"flinkuser"用户查询V_$LOG_HISTORY视图,该视图包含有关数据库历史日志文件的信息。
GRANT SELECT ON V_$LOG_HISTORY TO flinkuser;
-- 允许"flinkuser"用户查询V_$LOGMNR_LOGS视图,该视图包含有关LogMiner日志文件的信息。
GRANT SELECT ON V_$LOGMNR_LOGS TO flinkuser;
-- 允许"flinkuser"用户查询V_$LOGMNR_CONTENTS视图,该视图包含LogMiner日志文件的内容。
GRANT SELECT ON V_$LOGMNR_CONTENTS TO flinkuser;
-- 允许"flinkuser"用户查询V_$LOGMNR_PARAMETERS视图,该视图包含有关LogMiner的参数信息。
GRANT SELECT ON V_$LOGMNR_PARAMETERS TO flinkuser;
-- 允许"flinkuser"用户查询V_$LOGFILE视图,该视图包含有关数据库日志文件的信息。
GRANT SELECT ON V_$LOGFILE TO flinkuser;
-- 允许"flinkuser"用户查询V_$ARCHIVED_LOG视图,该视图包含已归档的数据库日志文件的信息。
GRANT SELECT ON V_$ARCHIVED_LOG TO flinkuser;
-- 允许"flinkuser"用户查询V_$ARCHIVE_DEST_STATUS视图,该视图包含有关归档目标状态的信息。
GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO flinkuser;
Step7:数据库和表启用增量日志
-- 切换至flinkuser用户
sqlplus /nolog
CONNECT flinkuser/flinkpw
-- 创建customers表
CREATE TABLE customers (
customer_id NUMBER PRIMARY KEY,
customer_name VARCHAR2(50),
email VARCHAR2(100),
phone VARCHAR2(20)
) TABLESPACE LOGMINER_TBS;
-- 查看LOGMINER_TBS表空间下的所有表
select tablespace_name, table_name from user_tables
where tablespace_name = 'LOGMINER_TBS';
-- 以DBA的权限登录数据库
sqlplus /nolog
CONNECT sys/system AS SYSDBA
-- 为LOGMINER_TBS表空间下的customers表启用增强日志记录
ALTER TABLE FLINKUSER.CUSTOMERS ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS
-- 为数据库启用增强日志记录:
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
2.4 SQLServer
版本:Microsoft SQL Server 2019 (RTM-CU21) (KB5025808) - 15.0.4316.3 (X64)
2.4.1 安装
Step1:拉取SQL Server 2019 镜像
docker pull mcr.microsoft.com/mssql/server:2019-latest
Step2:运行 SQL Server 容器(密码必须是8个字符,并包含字母、数字和特殊字符,如:abc@123456 ,下面映射主机端口为30027)
docker run -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=abc@123456' -p 30027:1433 --name sql_server_2019 -d mcr.microsoft.com/mssql/server:2019-latest
Step3:验证 SQL Server 容器是否正在运行
docker ps -a|grep sql_server_2019
2.4.2 CDC 配置
Step1:开启SQLServer代理
## 使用root用户登录容器
docker exec -it --user root sql_server_2019 bash
## 进入容器后,执行命令启用Agent
/opt/mssql/bin/mssql-conf set sqlagent.enabled true
## 退出,重启容器
exit
docker restart sql_server_2019
Step2:创建’cdc_test’测试数据库,并使用连接工具登录该数据库,使用以下 SQL 命令启用 CDC 功能
-- 创建数据库
CREATE DATABASE cdc_test;
-- 启用CDC功能
EXEC sys.sp_cdc_enable_db;
-- 判断当前数据库是否启用了CDC(如果返回1,表示已启用)
SELECT is_cdc_enabled FROM sys.databases WHERE name = 'cdc_test';
Step3:选择要进行 CDC 跟踪的表(这里使用orders表作为演示)
-- 创建示例表(orders)
CREATE TABLE orders (
id int,
order_date date,
purchaser int,
quantity int,
product_id int,
PRIMARY KEY ([id])
);
--将下面四行sql代码执行,使数据表开启CDC
-- schema_name 是表所属的模式(schema)的名称。
-- source_name 是要启用 CDC 跟踪的表的名称。
-- role_name 是 CDC 使用的角色的名称。
EXEC sys.sp_cdc_enable_table
@source_schema = 'dbo',
@source_name = 'tablename',
@role_name = 'cdc_role';
-- 判断当前数据表是否启用了CDC(如果返回1,表示已启用)
select is_tracked_by_cdc from sys.tables where name = 'tablename';
--关闭表CDC
EXEC sys.sp_cdc_disable_table
@source_schema = 'dbo',
@source_name = 'tablename',
@capture_instance = 'dbo_tablename';
2.5达梦
2.4.1安装
省略了安装过程
2.4.2CDC配置
SYSDBA用户登录达梦数据库,进行如下操作:
1)修改数据库为 MOUNT 状态。
SQL> ALTER DATABASE MOUNT;
操作已执行
已用时间: 00:00:01.769. 执行号:0.
2)配置本地归档
SQL>ALTER DATABASE ADD ARCHIVELOG 'DEST = /home/dmdba/data/DAMENG/arch, TYPE = local, FILE_SIZE = 1024, SPACE_LIMIT = 2048';
操作已执行
已用时间: 00:00:02.139. 执行号:0.
3)开启归档模式
SQL>ALTER DATABASE ARCHIVELOG;
操作已执行
已用时间: 00:00:01.018. 执行号:0.
4)修改数据库为 OPEN 状态
SQL>ALTER DATABASE OPEN;
操作已执行
已用时间: 00:00:03.954. 执行号:0.
操作完成后,使用如下语句确认数据库是否为归档模式。
SQL> select arch_mode from v$database;
行号 ARCH_MODE
---------- ---------
1 Y
已用时间: 12.308(毫秒). 执行号:4.
3. 验证
如果要验证flink cdc的功能,需要先下载flink的安装包,然后下载相应的cdc jar包并依赖,最后使用安装包里面的sql-client写相关的flink sql即可验证。
3.1 Flink版本与CDC版本的对应关系
下载Flink安装包以及jar包前,必须确定Flink CDC与Flink版本关系:
Flink CDC 版本 Flink 版本
1.0.0 1.11.*
1.1.0 1.11.*
1.2.0 1.12.*
1.3.0 1.12.*
1.4.0 1.13.*
2.0.* 1.13.*
2.1.* 1.13.*
2.2.* 1.13.*, 1.14.*
2.3.* 1.13.*, 1.14.*, 1.15.*, 1.16.0
2.4.* 1.13.*, 1.14.*, 1.15.*, 1.16.*, 1.17.0
本文以 Flink1.13.6 + Flink CDC 2.2.0 版本为例子演示。
3.2 下载相关包
flink 安装包下载,下载地址:https://flink.apache.org/downloads/
下载cdc相关的jar,根据自己的需求,下载相关的cdc jar:https://repo1.maven.org/maven2/com/ververica/
3.3 添加cdc jar 至lib目录
把需要验证的cdc jar放到flink安装包解压之后的lib目录(<FLINK_HOME>/lib/):
3.4 验证
使用下面的命令启动 Flink 集群:
./bin/start-cluster.sh
启动成功,可以访问 http://localhost:8081 访问到 Flink Web UI:
使用下面的命令启动 Flink SQL CLI :
./bin/sql-client.sh
展示如下页面,表示启动flink客户端成功:
执行如下FlinkSQL:
CREATE TABLE t_source_sqlserver (
id INT,
order_date DATE,
purchaser INT,
quantity INT,
product_id INT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'sqlserver-cdc',
'hostname' = '10.194.183.120',
'port' = '30027',
'username' = 'sa',
'password' = 'abc@123456',
'database-name' = 'cdc_test',
'schema-name' = 'dbo',
'table-name' = 'orders'
);
可以看到执行成功了:
执行select 语句,以便实时查看该表的数据变动:
select * from t_source_sqlserver;
从下图,可以看出,只要修改左边的数据,会在控制台实时显示新增删除的数据。
同时,也能在Flink web页面看到任务正在运行:
最后,可以通过如下命令关闭掉Flink启动的集群:
./stop-cluster.sh
相关文章:

Flink-CDC——MySQL、SqlSqlServer、Oracle、达梦等数据库开启日志方法
目录 1. 前言 2. 数据源安装与配置 2.1 MySQL 2.1.1 安装 2.1.2 CDC 配置 2.2 Postgresql 2.2.1 安装 2.2.2 CDC 配置 2.3 Oracle 2.3.1 安装 2.3.2 CDC 配置 2.4 SQLServer 2.4.1 安装 2.4.2 CDC 配置 2.5达梦 2.4.1安装 2.4.2CDC配置 3. 验证 3.1 Flink版…...

linux设置tomcat redis开机自启动
设置Tomcat自启动 1.修改 /etc/rc.d/rc.local 文件 [rootiowZ]# vim /etc/rc.d/rc.local在/etc/rc.d/rc.local文件最后加上: export JAVA_HOME/usr/local/jdk /usr/local/apache-tomcat-8.5.73/bin/startup.sh start退出vim并保存修改的文件。 说明:/u…...

跨域问题讨论
问题 跨域定义 当一个请求url的协议、域名、端口三者之间任意一个与当前页面地址不同即为跨域。 跨域的安全隐患(CSRF攻击) 也就是说,一旦允许跨域,意味着允许恶意网站随意攻击可信网站,带来安全风险。 这里面有一…...

ESP32设备通信-两个ESP32设备之间HTTP通信
两个ESP32设备之间HTTP通信 文章目录 两个ESP32设备之间HTTP通信1、应用介绍2、软件准备3、硬件准备4、代码实现4.1 ESP32服务器节点代码4.2 ESP32客户端节点代码在本文中,我们将介绍如何在没有任何物理路由器或互联网连接的情况下使用 Wi-Fi 在两个 ESP32 开发板之间执行无线…...
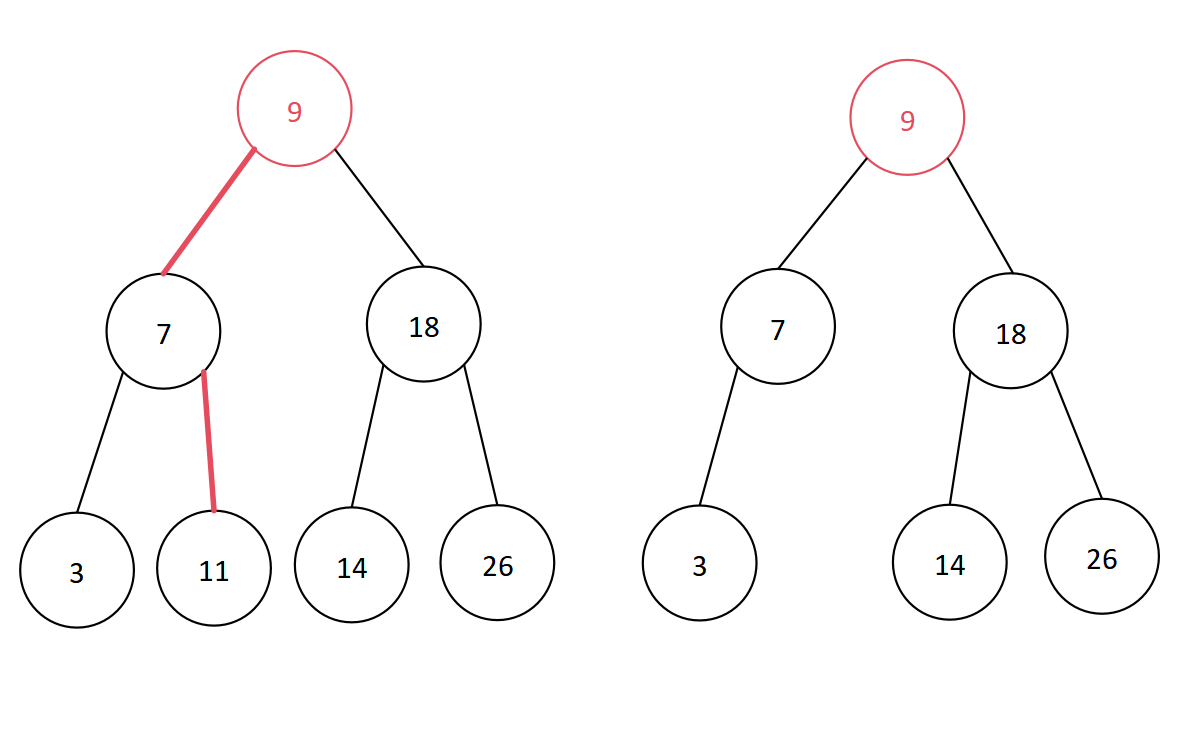
数据结构学习笔记——查找算法中的树形查找(平衡二叉树)
目录 一、平衡二叉树的定义二、平衡因子三、平衡二叉树的插入和构造(一)LL型旋转(二)LR型旋转(三)RR型旋转(四)RL型旋转 四、平衡二叉树的删除(一)叶子结点&a…...

P1830 轰炸III
题目背景 一个大小为 ��nm 的城市遭到了 �x 次轰炸,每次都炸了一个每条边都与边界平行的矩形。 题目描述 在轰炸后,有 �y 个关键点,指挥官想知道,它们有没有受到过轰炸,如…...

大语言模型LLM知多少?
你知道哪些流行的大语言模型?你都体验过哪写? GPT-4,Llamma2, T5, BERT 还是 BART? 1.GPT-4 1.1.GPT-4 模型介绍 GPT-4(Generative Pre-trained Transformer 4)是由OpenAI开发的一种大型语言模型。GPT-4是前作GPT系列模型的进一步改进,旨在提高语言理解和生成的能力,…...

Redis命令行使用Lua脚本
Redis命令行使用Lua脚本 Lua脚本在Redis中的使用非常有用,它允许你在Redis服务器上执行自定义脚本,可以用于复杂的数据处理、原子性操作和执行多个Redis命令。以下是Lua脚本在Redis中的基本使用详细讲解: 运行Lua脚本: 在Redis中…...

HTML详细基础(三)表单控件
本帖介绍web开发中非常核心的标签——表格标签。 在日常我们使用到的各种需要输入用户信息的场景——如下图,均是通过表格标签table创造出来的: 目录 一.表格标签 二.表格属性 三.合并单元格 四.无序列表 五.有序列表 六.自定义标签 七.表单域 …...
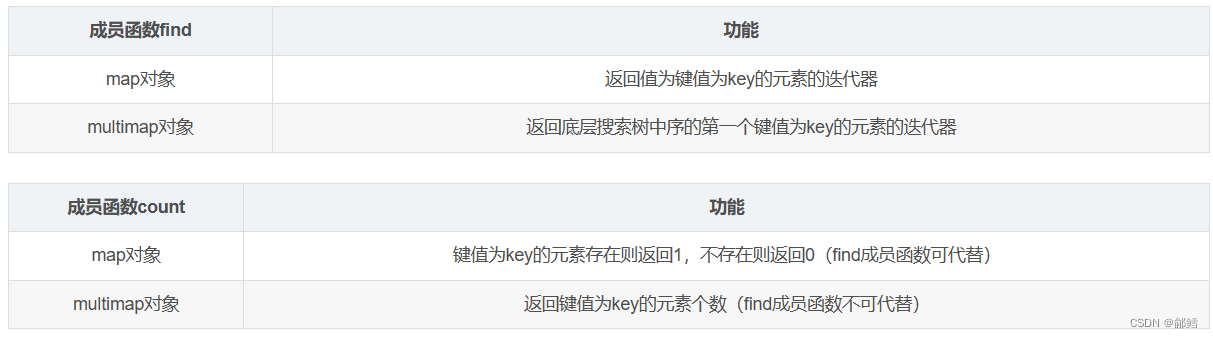
map和set的具体用法 【C++】
文章目录 关联式容器键值对setset的定义方式set的使用 multisetmapmap的定义方式insertfinderase[]运算符重载map的迭代器遍历 multimap 关联式容器 关联式容器里面存储的是<key, value>结构的键值对,在数据检索时比序列式容器效率更高。比如:set…...
聚合统一,SpringBoot实现全局响应和全局异常处理
目录 前言 全局响应 数据规范 状态码(错误码) 全局响应类 使用 优化 全局异常处理 为什么需要全局异常处理 业务异常类 全局捕获 使用 优化 总结 前言 在悦享校园1.0版本中的数据返回采用了以Map对象返回的方式,虽然较为便捷但也带来一些问题。一是在…...
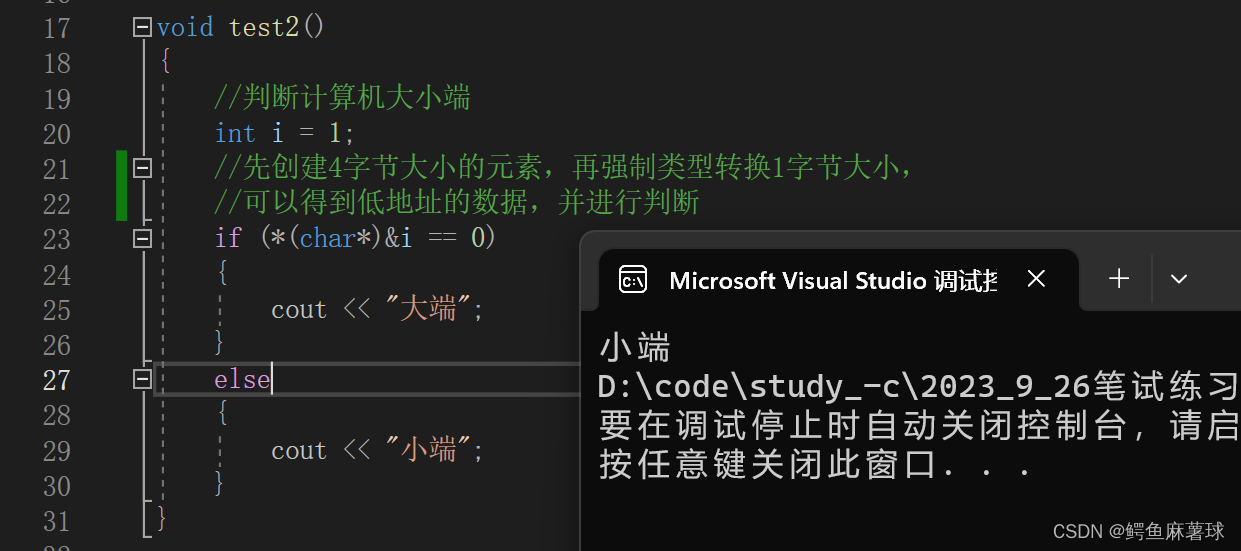
【C/C++笔试练习】——数组名和数组名、switch循环语句、数据在计算机中的存储顺序、字符串中找出连续最长的数字串、数组中出现次数超过一半的数字
文章目录 C/C笔试练习1.数组名和&数组名(1)数组名和&数组名的差异(2)理解数组名和指针偏移(3)理解数组名代表的含义(4)理解数组名代表的含义 2.switch循环语句(6…...
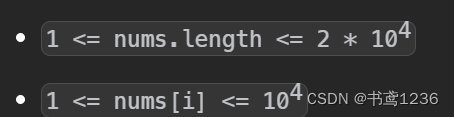
力扣每日一题(+日常水题|树型dp)
740. 删除并获得点数 - 力扣(LeetCode) 简单分析一下: 每一个数字其实只有2个状态选 or 不 可得预处理每一个数初始状态(不选为0,选为所有x的个数 * x)累加即可 for(auto &x : nums)dp[x][1] x;每选一个树 i 删去 i 1 和 i - 1 故我们可以将 i…...

使用perming加速训练可预测的模型
监督学习模型的训练流程 perming是一个主要在支持CUDA加速的Windows操作系统上架构的机器学习算法,基于感知机模型来解决分布在欧式空间中线性不可分数据集的解决方案,是基于PyTorch中预定义的可调用函数,设计的一个面向大规模结构化数据集的…...

【数据库】存储引擎InnoDB、MyISAM、关系型数据库和非关系型数据库、如何执行一条SQL等重点知识汇总
目录 存储引擎InnoDB、MyISAM的适用场景 关系型和非关系型数据库的区别 MySQL如何执行一条SQL的 存储引擎InnoDB、MyISAM的适用场景 InnoDB 是 MySQL 默认的事务型存储引擎,只有在需要它不支持的特性时,才考虑使用其它存储引擎。实现了四个标准的隔…...

车道线分割检测
利用opencv,使用边缘检测、全局变化梯度阈值过滤、算子角度过滤、HLS阈值过滤的方法进行车道线分割检测,综合多种阈值过滤进行检测提高检测精度。 1.利用cv2.Sobel()计算图像梯度(边缘检测) import cv2 import numpy as np import matplotlib.pyplot a…...

树莓集团又一力作,打造天府蜂巢成都直播产业园样板工程
树莓集团再次推出惊艳之作,以打造成都天府蜂巢直播产业园为目标。该基地将充分展现成都直播产业园的巨大潜力与无限魅力,成为一个真正的产业园样板工程。 强强联手 打造未来 成都天府蜂巢直播产业园位于成都科学城兴隆湖高新技术服务产业园内࿰…...

ubuntu 软件包管理之二制作升级包
Deb 包(Debian 软件包)是一种用于在 Debian 及其衍生发行版(例如 Ubuntu)中分发和安装软件的标准包装格式。它们构成了 Debian Linux 发行版中的软件包管理系统的核心组成部分,旨在简化软件的分发、安装、更新和卸载流程。在本篇文章中,我们将深入探讨以下内容: Deb 包基…...
)
TCP/IP网络江湖——数据链路层的防御招式(数据链路层下篇:数据链路层的安全问题)
目录 引言 一、 数据链路层的隐私与保密 二、数据链路层的安全协议与加密...

ios项目安装hermes-engine太慢问题
问题说明 ios工程,在使用"pod install"安装依赖的时候,由于超时总是报错 $ pod install ... Installing hermes-engine (0.71.11)[!] Error installing hermes-engine [!] /usr/bin/curl -f -L -o /var/folders/4c/slcchpy55s53ysmz_1_q_gzw…...

PaDiM实战:从理论到代码的异常检测全流程拆解
1. PaDiM异常检测模型入门指南 第一次接触PaDiM时,我也被那些数学公式吓到了。但真正用起来才发现,这个基于预训练CNN的异常检测框架其实很友好。简单来说,它就像个"找不同"的高手 - 先记住正常样本长什么样(训练阶段&a…...

Kibana 7.3.0 导出CSV报告保姆级教程:从保存搜索到解决内存溢出
Kibana 7.3.0 高效数据导出实战:从基础配置到性能调优全攻略 当你面对TB级别的日志数据需要离线分析时,Kibana的CSV导出功能就像一把双刃剑——用得好能大幅提升工作效率,用不好则可能陷入内存溢出和性能瓶颈的泥潭。本文将带你深入Kibana 7…...

ARM AXD CLI调试器:嵌入式开发高效调试指南
1. ARM AXD CLI调试器核心功能解析ARM AXD CLI(Command-line Interface)是ARM开发工具链中的调试器命令行接口,专为嵌入式系统开发者设计。这个强大的工具允许开发者通过命令行直接与目标处理器交互,实现比图形界面更高效的调试操…...

工业视觉检测算法和系统 实时检测芯片引脚的缺陷 使用计算机视觉YOLOV8模型训练芯片缺陷检测数据集 识别检测芯片中的污染引脚 损坏引脚 划痕 自动识别引脚缺陷
工业视觉检测算法和系统 实时检测芯片引脚的缺陷 使用计算机视觉YOLOV8模型训练芯片缺陷检测数据集 识别检测芯片中的污染引脚 损坏引脚 划痕 自动识别引脚缺陷 文章目录芯片引脚缺陷数据集信息表数据集概述类别标签及样本分布统计表数据集特点总结✅ 一、环境搭建(…...

Bun 六天完成从 Zig 到 Rust 重写,AI 重写软件大趋势下速度与质量难题待解
Zig 版 Bun 被判“死刑”2026 年 5 月 11 日,Bun 创始人 Jarred Sumner 在 X 上发推文称,“Bun v1.3.14 将于明日发布。如果我们合并 Rust 重写版本,这将是 Zig 的最后一个版本”,宣告了 Zig 版 Bun 的终结。四年前,Bu…...

终极解放!淘宝自动任务神器让你每天多出30分钟自由时间
终极解放!淘宝自动任务神器让你每天多出30分钟自由时间 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi 你知…...

MiGPT小爱音箱AI升级终极指南:5步快速接入ChatGPT和豆包大模型
MiGPT小爱音箱AI升级终极指南:5步快速接入ChatGPT和豆包大模型 【免费下载链接】mi-gpt 🏠 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。 项目地址: https://gitcode.com/GitHub_Trending/mi/mi-gpt 你是否曾希望家中的小…...

KeyboardChatterBlocker:彻底解决机械键盘连击问题的免费开源方案
KeyboardChatterBlocker:彻底解决机械键盘连击问题的免费开源方案 【免费下载链接】KeyboardChatterBlocker A handy quick tool for blocking mechanical keyboard chatter. 项目地址: https://gitcode.com/gh_mirrors/ke/KeyboardChatterBlocker 机械键盘在…...

终极解决方案:3分钟搞定百度网盘提取码的免费自动化工具
终极解决方案:3分钟搞定百度网盘提取码的免费自动化工具 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为百度网盘资源下载卡在提取码这一步而烦恼吗?每次遇到需要密码的分享链接,都要…...

Syzygy-of-Thoughts:用代数几何思想提升大语言模型推理能力
1. 项目概述:当大语言模型遇上代数几何如果你最近在折腾大语言模型(LLM)的推理能力提升,大概率听说过“思维链”(Chain of Thought, CoT)和“自洽性”(Self-Consistency, CoT-SC)这些…...