全面解读 SQL 优化 - 统计信息
一、简介
数据库中的优化器(optimizer)是一个重要的组件,用于分析 SQL 查询语句,并生成执行计划。在生成执行计划时,优化器需要依赖数据库中的统计信息来估算查询的成本,从而选择最优的执行计划。以下是关于数据库中优化器统计信息的简介:
(1)统计信息概述
统计信息是描述表或索引中数据分布情况的元数据。这些信息包括行数、数据分布、重复值等,都是优化器选择执行计划的关键因素。
(2)统计信息来源
统计信息被收集并存储在数据字典中,可以通过特定的 SQL 命令(如 ANALYZE TABLE)来手动收集;也可以被自动收集,以保持数据字典的最新状态。
(3)统计信息类型
统计信息包括两种不同类型的信息,系统级别和对象级别。系统级别的统计信息是全局性的,如整个数据库中所有表的平均行长度;而对象级别的统计信息是特定对象的信息,如表或索引的平均行长度、列值的分布和直方图等。
(4)统计信息用途
优化器使用统计信息作为计算成本的基础,从而选择最优执行计划。优化器所使用的统计信息包括表的行数、每个列的唯一值数目、平均列长度等。
(5)统计信息更新
数据的分布会随着时间和数据量的增长而发生变化,因此统计信息也需要定期更新。更新统计信息的频率取决于表中数据的变化速度和查询的要求。
总之,优化器统计信息是一个关键的组件,用于执行计划的生成和执行。数据库管理员需要定期维护和更新统计信息,以支持数据库的正常运行和高效执行 SQL 查询。
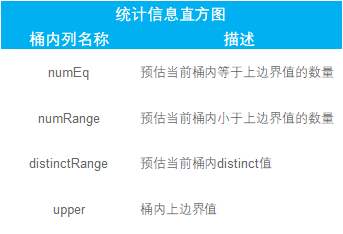
目前 KaiwuDB 维护的统计信息包括表和列的统计信息,这是本期技术贴重点介绍的内容。
➢ 表的统计信息:总行数;
➢ 列的统计信息:不同值的数目,NULL 值的数目和直方图。
二、统计信息流程
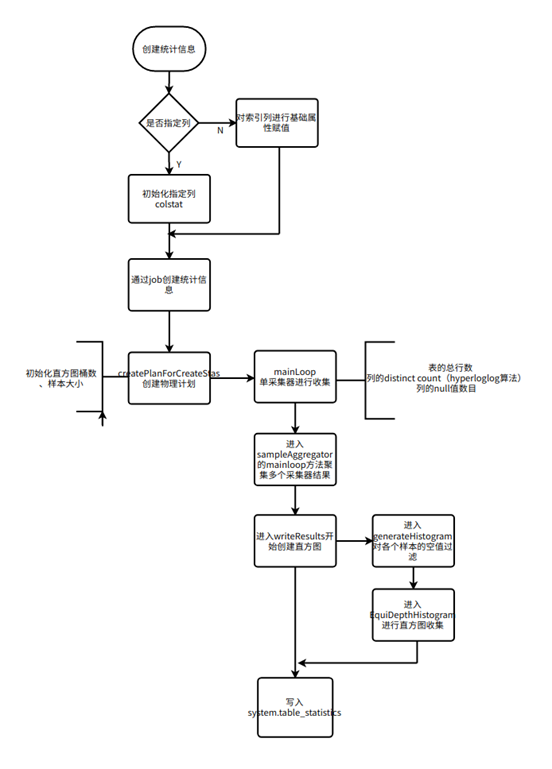
生成统计信息的简单流程如图所示,详细采样过程由后文部分介绍。
-
Sampler("采样器"处理器的规范)
该处理器返回输入列的样本(随机子集)并计算列集上的基数估计草图 。
-
SampleAggregator(处理器的规范)
该处理器聚合来自多个采样器处理器的结果,并将统计信息写到 system.table_statistics 中。
三、基数统计算法
HyperLogLog 是一种基数(cardinality)估计算法,用于在海量数据中估计不同元素的数量。该算法使用了概率技巧和哈希函数,可以在极大数据量下高效地统计基数。以下是关于 HyperLogLog 的简介:
-
基数(cardinality)
基数是指集合中不同元素的数量。例如,在某个网站上的用户访问记录中,基数表示的是不同的用户数量;
-
精确计数局限
对于大规模数据,精确计算基数的代价会非常昂贵,因为需要遍历整个数据集,消耗大量计算资源和时间;
-
算法原理
HyperLogLog 利用了哈希函数和概率的原理,将输入的元素通过哈希函数映射到一个固定大小的二进制空间,并计算这些哈希值的最大前缀 0 的位数。然后,将这些最大前缀 0 的位数的平均值作为基数的估计值;
-
精度控制
HyperLogLog 的精度受哈希函数的影响,可以通过调整哈希函数的参数来控制精度。一般来说,HyperLogLog 算法可以在仅占原始数据 1-2% 的空间下,对基数进行非常准确的估计,误差通常在 1% 以内;
-
应用场景
HyperLogLog 广泛应用于大规模数据的基数统计,如页面访问、IP 地址统计、社交网络中用户数量估算等。
总之,HyperLogLog 算法是一种高效的基数统计算法,可以在大规模数据下进行快速而准确的基数估计,具有广泛的应用前景,以下将为大家介绍 KaiwuDB 是如何进行实现的。
主要计算:2 的第一个 0 出现位置次方的调和平均值
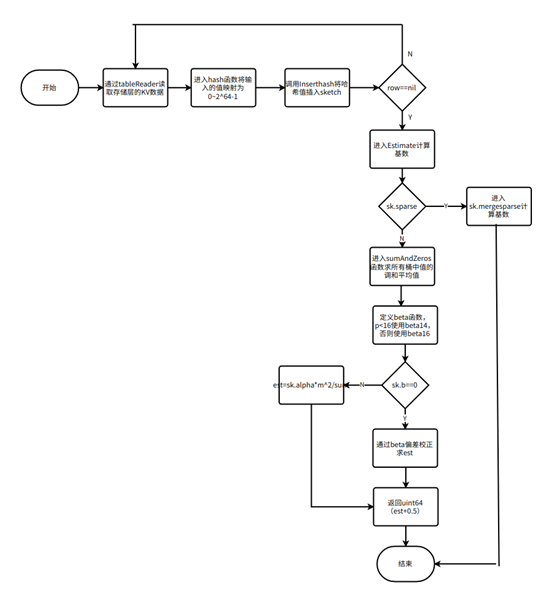
1. 算法步骤
(1)转化为比特串
通过哈希函数,将输入的数据转化为 64 位比特串,哈希函数将 2^64 个不同值映射到 0~2^64-1 地址上。比特串中的 0 和 1 可以类比为硬币的正与反,这是实现估值统计的第一步;
(2)分桶平均
首先初始化数据结构 sketch,包括分桶数、修正系数等。然后将每个元素的 hash 值取最后的 p 位决定桶的编号,在剩余的(64-p)位中找到最大的第一个"0"出现的位置;
(3)计算调和平均数
所有元素处理完毕后,求所有桶中值的调和平均数即可得到 distinct 值。
2. 估算流程
HyperLogLog 是 KaiwuDB 统计信息中计算 Distinct 值的主要估计算法。下图为详细流程:
3. 算法优势
利用尽可能少的内存空间实现大数据集的基数统计。
-
2^14桶
Go
root@:26257/defaultdb> select count(*) from t1;count
---------10000
(1 row)Time: 3.300613msroot@:26257/defaultdb> Show statistics for table t1;statistics_name | column_names | created | row_count | distinct_count | null_count | histogram_id
------------------+--------------+----------------------------------+-----------+----------------+------------+---------------------t1s | {c1} | 2023-05-28 00:53:09.573502+00:00 | 10000 | 9920 | 0 | 868891982501675009
(1 row)Time: 2.021244ms-
2^16桶
Go
root@:26257/defaultdb> select count(*) from t1;count
---------10000
(1 row)Time: 4.210306msroot@:26257/defaultdb> Show statistics for table t1;statistics_name | column_names | created | row_count | distinct_count | null_count | histogram_id
------------------+--------------+----------------------------------+-----------+----------------+------------+---------------------t1s | {c1} | 2023-05-28 01:02:29.997638+00:00 | 10000 | 9999 | 0 | 868893818901430273
(1 row)Time: 3.056793ms桶的个数越多,HyperLogLog 的精度就越高,同时所占用的内存也越大。
四、 蓄水池算法
蓄水池算法(Reservoir Sampling)是一种在数据流中随机采样的算法,常用于生成一个固定大小的随机样本。以下是关于蓄水池算法的介绍:
(1)数据流
在大规模数据处理中,数据通常以数据流的形式出现,即数据无法事先被全部存储下来,而必须通过流式处理方式来逐个处理;
(2)算法原理
蓄水池算法需要维护一个大小为 k 的蓄水池,初始时将前 k 个元素放入蓄水池中,然后对于第 i 个元素,有 1/i 的概率将其替换蓄水池中的任意一个元素;
(3)采样理论
根据采样理论,该算法可以保证每个元素被采样的概率都相等,即 1/n,其中 n 为数据流中元素的数量;
(4)应用场景
蓄水池算法广泛应用于随机采样问题,如从海量数据中随机选取 k 个元素进行分析、从实时日志数据中随机选取一部分数据进行监控等;
(5)算法优点
蓄水池算法具有高效、可扩展、精度高等优点,并且能够在空间与时间复杂度上做到线性级别。
总之,蓄水池算法是一种高效的随机采样算法,可以在数据流中进行随机采样,并保证每个元素被选中的概率都相等,具有广泛的应用前景,以下内容为蓄水池算法在 KaiwuDB 中的实现流程。
在 mainloop 函数中通过蓄水池抽样算法,来生成均匀抽样集合。
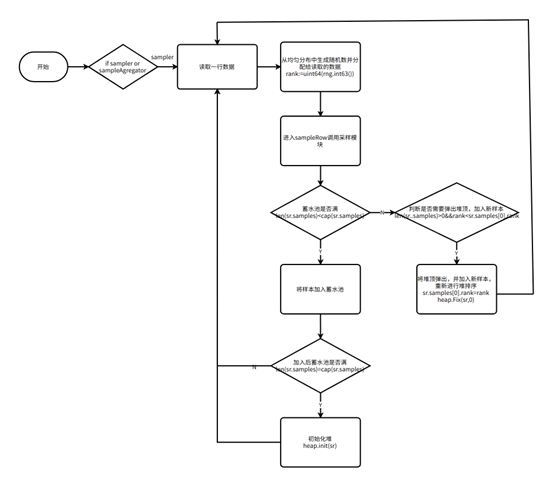
采样过程的 processor 有 sampler 和 sampleaggregator 都采用了采样模块。
其中 sampler processor 的输入为 tablereader 下读取到的数据,是未经任何采样的数据;sampleaggregator processor 输入为各个 sampler processor 的取样结果,是经过采样的数据。
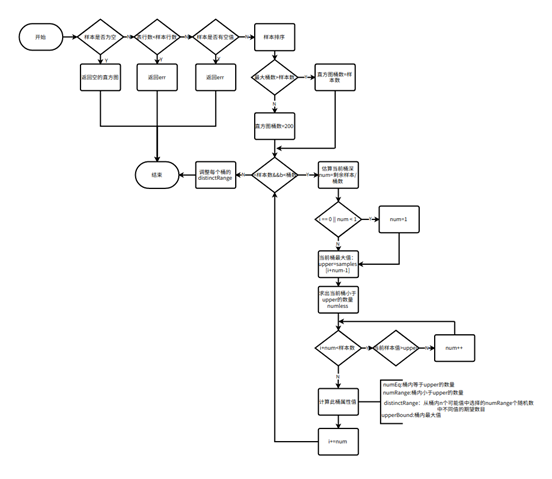
五、直方图计算流程
直方图是一个描述数据分布情况的工具,KaiwuDB 采用等深直方图。
根据采样得到的样本进行直方图的创建,创建方法大致如下(详情参考EquiDepthHistogram函数):
将样本排序,顺序遍历每一个值 V:
-
如果 V 等于上一个值,那么把 V 放在与上一个值相同的一个桶里,无论桶是不是已经满,这样可以保证每个值只存在于一个桶中;
-
如果 V 不等于上一个值,那么需要判断当前桶是否已经满,如果不是的话,就直接放入当前桶;否则,就放入下一个桶。
创建完毕,在函数 writeResults 中将结果存储在 system.table_statistics 中。
六、应用统计信息计算选择率
选择率表示一个查询根据谓词选择出元组的占比,主要用于优化器预估选择的元组的大小,从而进一步选择出最优的执行计划。
主要流程:当一个过滤条件输入进来时,根据其谓词表达式判断对应的列适用于哪些过滤率的计算方式,然后根据收集到的统计信息与计算方式相结合,得到最终的过滤率。
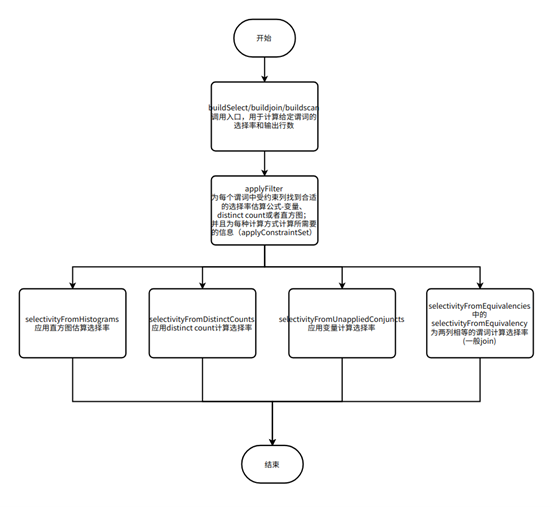
应用直方图和 distinct count 为每个列应用过滤的公式:
SQL
selectivity = (output row count) / (input row count)
其中:
output row count = nonNullSelectivity*输入的非空值数量 + nullSelectivity*输入空值数量
input row count:该列总行数
nonNullSelectivity:桶过滤后的非空值行数/桶过滤前的非空值的行数
nullSelectivity:过滤前后空值的占比相关文章:
全面解读 SQL 优化 - 统计信息
一、简介 数据库中的优化器(optimizer)是一个重要的组件,用于分析 SQL 查询语句,并生成执行计划。在生成执行计划时,优化器需要依赖数据库中的统计信息来估算查询的成本,从而选择最优的执行计划。以下是关…...
Spring整合RabbitMQ——生产者
1.生产者整合步骤 添加依赖坐标,在producer和consumer模块的pom文件中各复制一份。 配置producer的配置文件 配置producer的xml配置文件 编写测试类发送消息...

Spring的注解开发-Bean基本注解开发
Bean基本注解开发 Spring除了xml配置文件进行配置之外,还可以使用注解方式进行配置,注解方式慢慢成为xml配置的替代方案。我们有了xml开发的经验,学习注解开发就会方便很多,注解开发更加快捷方便。Spring提供的注解有三个版本 2.…...
【Ubuntu18.04】Autoware.ai安装
Autoware.ai安装 引言1 ROS安装2 Ubuntu18.04安装Qt5.14.23 安装GCC、G4 Autoware.ai-1.14.0安装与编译4.1 源码的编译4.1.1 python2.7环境4.1,2 针对Ubuntu 18.04 / Melodic的依赖包安装4.1.3 先安装一些缺的ros依赖4.1.4 安装eigen3.3.74.1.5 安装opencv 3.4.164.1.6 编译4.1…...

SpringMVC 学习(一)Servlet
本系列文章为【狂神说 Java 】视频的课堂笔记,若有需要可配套视频学习。 1. Hello Servlet (1) 创建父工程 删除src文件夹 引入一些基本的依赖 <!--依赖--> <dependencies><dependency><groupId>junit</groupId><artifactId>…...

26943-2011 升降式高杆照明装置 课堂随笔
声明 本文是学习GB-T 26943-2011 升降式高杆照明装置. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 1 范围 本标准规定了升降式高杆照明装置的技术要求、试验方法、检验规则以及标志、包装、运输及贮 存等。 本标准适用于公路、广场、机场、港口、…...

洛谷题解 | AT_abc321_c Primes on Interval
目录 题目翻译题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 样例 #2样例输入 #2样例输出 #2 样例 #3样例输入 #3样例输出 #3 题目简化题目思路AC代码 题目翻译 【题目描述】 你决定用素数定理来做一个调查. 众所周知, 素数又被称为质数,其含义就是除了数…...
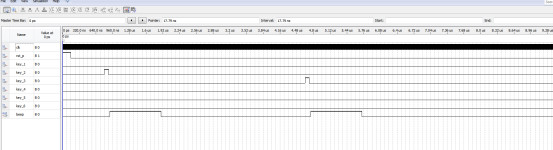
Quartus医院病房呼叫系统病床呼叫Verilog,源代码下载
名称:医院病房呼叫系统病床呼叫 软件:Quartus 语言:Verilog 要求: 1、用1~6个开关模拟6个病房的呼叫输入信号,1号优先级最高;1~6优先级依次降低; 2、 用一个数码管显示呼叫信号的号码;没信号呼叫时显示0;有多个信号呼叫时,显…...
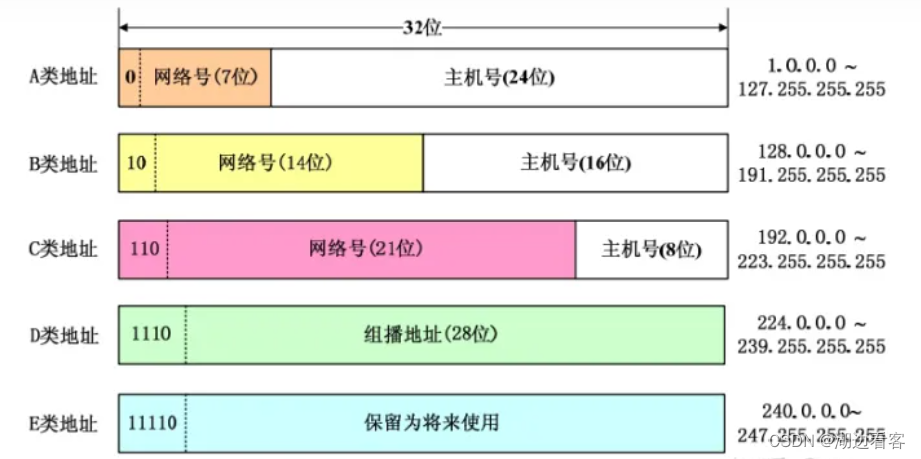
ip的标准分类---分类的Ip
分类的 IP 即将 IP 地址划分为若干个固定类,每一类地址都由两个固定长度的字段组成。 其中第一个字段是网络号(net-id),它标志主机或路由器所连接的网络。一个网络号在整个因特网内必须是唯一的。 第二个字段是主机号…...
)
理解并掌握C#的Channel:从使用案例到源码解读(一)
引言 在C#的并发编程中,Channel是一种非常强大的数据结构,用于在生产者和消费者之间进行通信。本文将首先通过一个实际的使用案例,介绍如何在C#中使用Channel,然后深入到Channel的源码中,解析其内部的实现机制。 使用案…...

如何让git命令仅针对当前目录
背景 我们有时候建的git仓库是这样的,a目录下有b、c、d三个模块(文件夹)。有时候只想查看b下面的变化,而使用 git status、git diff 的时候会把c和d的变化都列出来,要怎么只查b目录的变化? 操作 要查b目…...

【0223】源码剖析smgr底层设计机制(3)
1. smgr设计机制 PG内核中smgr完整磁盘存储介质的管理是通过下面三部分实现的。 1.1 函数指针结构体 f_smgr 函数指针结构体 f_smgr。 通过该函数指针类型,可完成类似于UNIX系统中的VFD功能,上层只需要调用open()、read()、write()等系统函数,用户不必去关系底层的文件系统…...

Visual Studio 2019 C# winform CefSharp 中播放视频及全屏播放
VS C# winform CefSharp 浏览器控件,默认不支持视频播放,好在有大佬魔改了dll,支持流媒体视频播放。虽然找了很久,好歹还是找到了一个版本100.0.230的dll(资源放在文末) 首先创建一个项目 第二、引入CefSha…...

天选之子Linux是如何发展起来的?为何对全球IT行业的影响如此之大?
天选之子Linux是如何发展起来的?为何对全球IT行业的影响如此之大? 前言一、UNIX发展史二、Linux发展历史三、开源四、官网五、 企业应用现状六、发行版本 前言 上面这副图是博主历时半小时完成的,给出了Linxu的一些发展背景。球球给位看官老…...
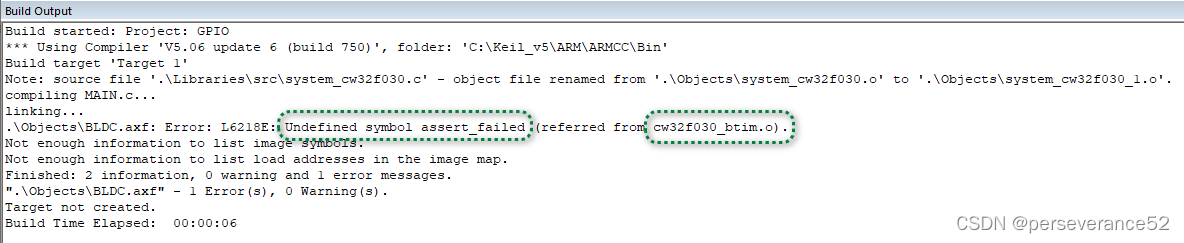
MDK报错:Undefined symbol assert_failed报错解决策略
MDK报错:Undefined symbol assert_failed报错解决策略 🎯🪕在全网搜索相关MDK编译报错:Error: L6218E: Undefined symbol assert_param (referred from xxx.o). ✨有些问题看似很简单,可能产生的问题是由于不经意的细节原因导致。…...
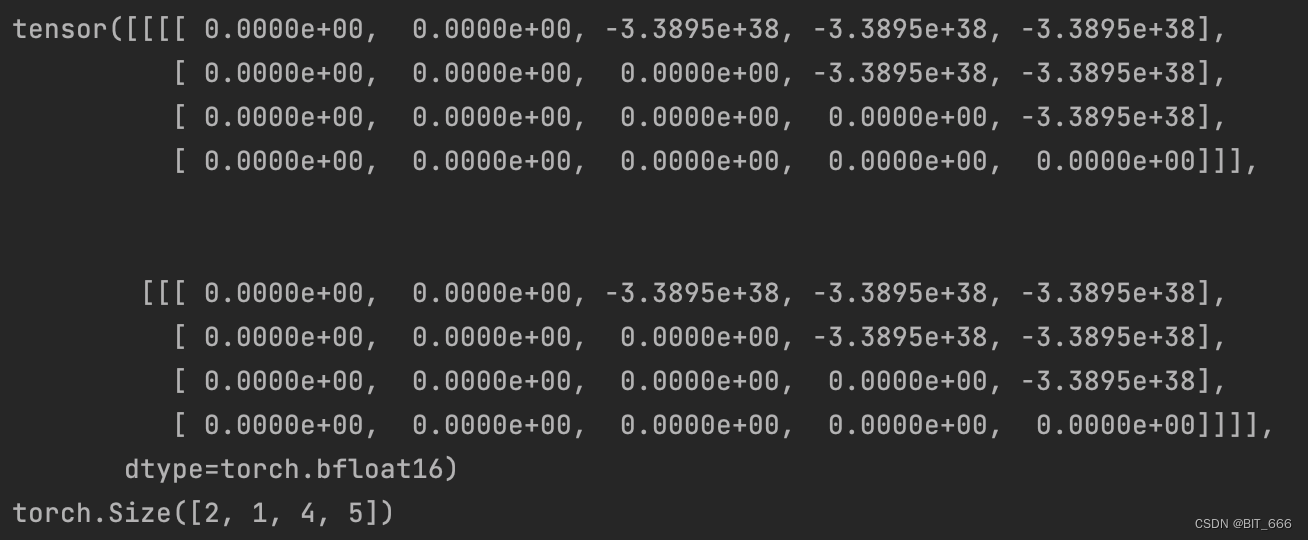
LLM - Make Causal Mask 构造因果关系掩码
目录 一.引言 二.make_causal_mask 1.完整代码 2.Torch.full 3.torch.view 4.torch.masked_fill_ 5.past_key_values_length 6.Test Main 三.总结 一.引言 Causal Mask 主要用于限定模型的可视范围,防止模型看到未来的数据。在具体应用中,Caus…...
概念和itertools)
Python函数式编程(一)概念和itertools
Python函数式编程是一种编程范式,它强调使用纯函数来处理数据。函数是程序的基本构建块,并且尽可能避免或最小化可变状态和副作用。在函数式编程中,函数被视为一等公民,可以像值一样传递和存储。 函数式编程概念 编程语言支持通…...
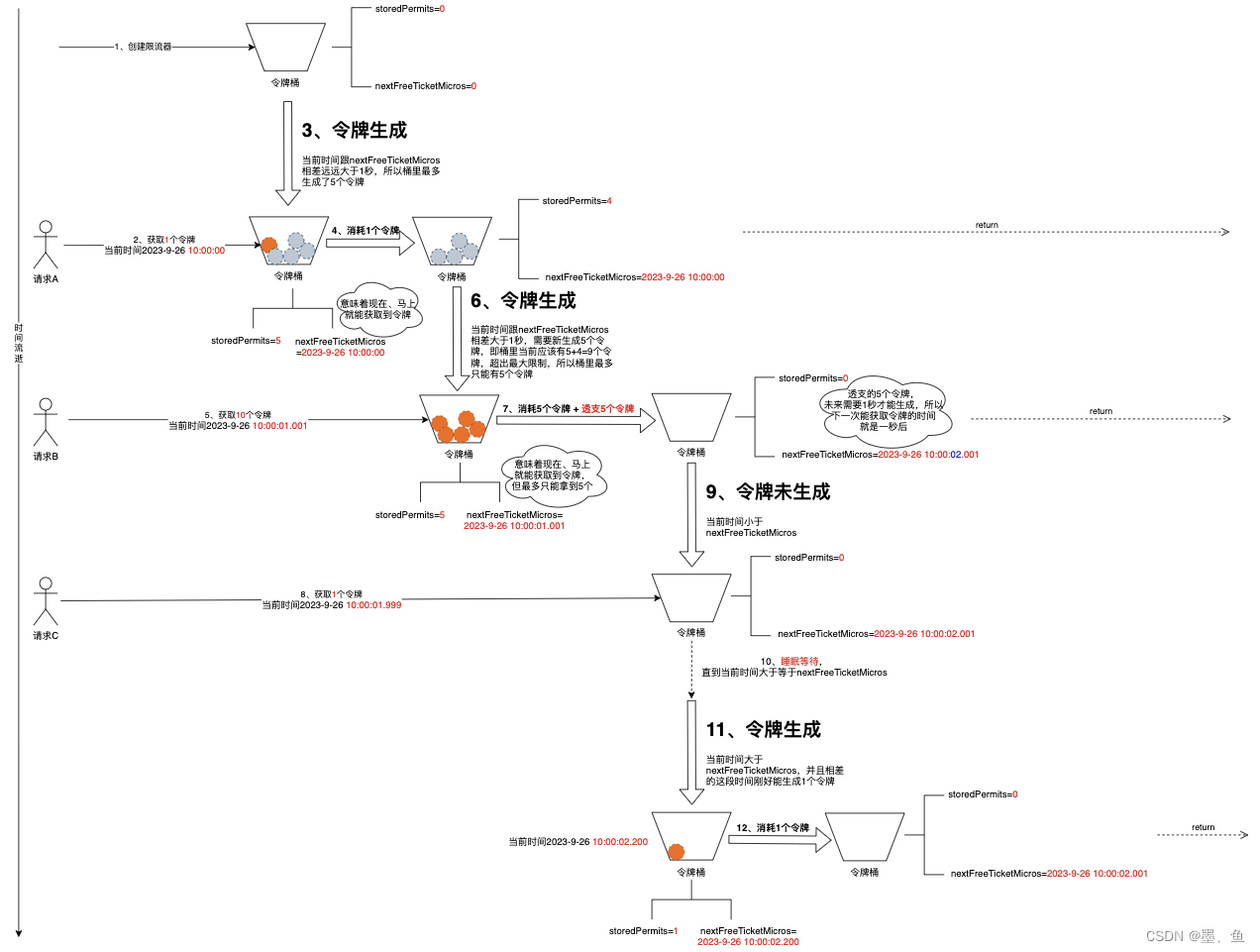
Guava限流器原理浅析
文章目录 基本知识限流器的类图使用示例 原理解析限流整体流程问题驱动1、限流器创建的时候会初始化令牌吗?2、令牌是如何放到桶里的?3、如果要获取的令牌数大于桶里的令牌数会怎么样4、令牌数量的更新会有并发问题吗 总结 实际工作中难免有限流的场景。…...

第四十二章 持久对象和SQL - 用于创建持久类和表的选项
文章目录 第四十二章 持久对象和SQL - 用于创建持久类和表的选项用于创建持久类和表的选项访问数据 第四十二章 持久对象和SQL - 用于创建持久类和表的选项 用于创建持久类和表的选项 要创建持久类及其对应的 SQL 表,可以执行以下任一操作: 使用 IDE …...

集合-ArrayList源码分析(面试)
系列文章目录 1.集合-Collection-CSDN博客 2.集合-List集合-CSDN博客 3.集合-ArrayList源码分析(面试)_喜欢吃animal milk的博客-CSDN博客 目录 系列文章目录 前言 一 . 什么是ArrayList? 二 . ArrayList集合底层原理 总结 前言 大家好,今天给大家讲一下Arra…...

终极指南:如何用免费3D模型库打造你的Cherry MX个性化键帽
终极指南:如何用免费3D模型库打造你的Cherry MX个性化键帽 【免费下载链接】cherry-mx-keycaps 3D models of Chery MX keycaps 项目地址: https://gitcode.com/gh_mirrors/ch/cherry-mx-keycaps 想为你的机械键盘打造一套独一无二的键帽吗?Cherr…...

PowerBI主题模板终极指南:35款可视化模板快速美化报表
PowerBI主题模板终极指南:35款可视化模板快速美化报表 【免费下载链接】PowerBI-ThemeTemplates Snippets for assembling Power BI Themes 项目地址: https://gitcode.com/gh_mirrors/po/PowerBI-ThemeTemplates 还在为PowerBI报表的单调外观而烦恼吗&#…...
)
从‘古董’到统一:聊聊Linux内核中buffer与cache合并背后的那些事儿(附free命令实战)
从‘古董’到统一:Linux内核中buffer与cache合并背后的设计哲学 在Linux系统的性能优化领域,free命令的输出一直是开发者关注的焦点。当你键入free -h时,那行看似简单的"buff/cache"统计背后,隐藏着一段跨越二十年的内…...

为个人AI助手项目集成多模型API实现成本与性能平衡
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为个人AI助手项目集成多模型API实现成本与性能平衡 构建个人AI助手是许多独立开发者热衷的项目。在开发过程中,一个常见…...

【权威验证版】Perplexity检索JAMA文章的7个致命误区:哈佛医学院信息学团队实测复现报告
更多请点击: https://intelliparadigm.com 第一章:Perplexity检索JAMA文章的权威验证背景与复现意义 临床证据检索的可信度挑战 在循证医学实践中,JAMA(Journal of the American Medical Association)作为顶级同行评…...

从零搭建自动化任务中心:mgks/automation-hub部署与实战指南
1. 项目概述:自动化工作流的“中央厨房”如果你和我一样,在开发、运维或者日常工作中,经常需要重复执行一系列命令、脚本或者任务,那么你肯定对“自动化”这个词有着深刻的渴望。从简单的文件备份、日志清理,到复杂的C…...

VMware Workstation Pro 17免费许可证密钥终极指南:快速激活专业虚拟化工具
VMware Workstation Pro 17免费许可证密钥终极指南:快速激活专业虚拟化工具 【免费下载链接】VMware-Workstation-Pro-17-Licence-Keys Free VMware Workstation Pro 17 full license keys. Weve meticulously organized thousands of keys, catering to all major …...

AI Agent配置安全实践:用Config-Guard为自动化变更加锁
1. 项目概述:为AI Agent系统配置变更加上“安全锁”如果你正在运行一个基于OpenClaw或其他类似框架的AI Agent系统,那么你一定对那个核心的配置文件——通常是openclaw.json或类似的config.json——又爱又恨。它掌控着网关、模型、渠道和工具的命脉&…...
:从网络搭建到渐进式训练全流程)
手把手教你用PyTorch复现EfficientNetV2(附完整代码):从网络搭建到渐进式训练全流程
从零实现EfficientNetV2:代码级解析与渐进式训练实战 当你第一次翻开EfficientNetV2论文时,那些复杂的复合缩放系数和渐进式训练策略可能让人望而生畏。但别担心——本文将带你用PyTorch从最基础的卷积模块开始,逐层构建这个高效的视觉模型。…...

5分钟快速上手:res-downloader 全网资源下载神器终极指南
5分钟快速上手:res-downloader 全网资源下载神器终极指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否经…...