Llama2-Chinese项目:3.1-全量参数微调
提供LoRA微调和全量参数微调代码,训练数据为data/train_sft.csv,验证数据为data/dev_sft.csv,数据格式如下所示:
"<s>Human: "+问题+"\n</s><s>Assistant: "+答案
举个例子,如下所示:
<s>Human: 用一句话描述地球为什么是独一无二的。</s><s>Assistant: 因为地球是目前为止唯一已知存在生命的行星。</s>
1.全量参数微调脚本
全量参数微调脚本train/sft/finetune.sh,如下所示:
output_model=save_folder
# 需要修改到自己的输入目录
if [ ! -d ${output_model} ];then mkdir ${output_model}
fi
cp ./finetune.sh ${output_model} # 复制脚本到输出目录
CUDA_VISIBLE_DEVICES=0,1 deepspeed --num_gpus 2 finetune_clm.py \ # deepspeed:分布式训练,num_gpus:使用的gpu数量,finetune_clm.py:训练脚本--model_name_or_path meta-llama/Llama-2-7b-chat-hf \ # model_name_or_path:模型名称或路径--train_files ../../data/train_sft.csv \ # train_files:训练数据集路径../../data/train_sft_sharegpt.csv \ # train_files:训练数据集路径--validation_files ../../data/dev_sft.csv \ # validation_files:验证数据集路径../../data/dev_sft_sharegpt.csv \ # validation_files:验证数据集路径--per_device_train_batch_size 1 \ # per_device_train_batch_size:每个设备的训练批次大小--per_device_eval_batch_size 1 \ # per_device_eval_batch_size:每个设备的验证批次大小--do_train \ # do_train:是否训练--do_eval \ # do_eval:是否验证--use_fast_tokenizer false \ # use_fast_tokenizer:是否使用快速分词器--output_dir ${output_model} \ # output_dir:输出目录--evaluation_strategy steps \ # evaluation_strategy:评估策略--max_eval_samples 800 \ # max_eval_samples:最大评估样本数--learning_rate 1e-4 \ # learning_rate:学习率--gradient_accumulation_steps 8 \ # gradient_accumulation_steps:梯度累积步数--num_train_epochs 10 \ # num_train_epochs:训练轮数--warmup_steps 400 \ # warmup_steps:预热步数--logging_dir ${output_model}/logs \ # logging_dir:日志目录--logging_strategy steps \ # logging_strategy:日志策略--logging_steps 10 \ # logging_steps:日志步数--save_strategy steps \ # save_strategy:保存策略--preprocessing_num_workers 10 \ # preprocessing_num_workers:预处理工作数--save_steps 20 \ # save_steps:保存步数--eval_steps 20 \ # eval_steps:评估步数--save_total_limit 2000 \ # save_total_limit:保存总数限制--seed 42 \ # seed:随机种子--disable_tqdm false \ # disable_tqdm:禁用tqdm--ddp_find_unused_parameters false \ # 注释:ddp查找未使用的参数--block_size 2048 \ # block_size:块大小--report_to tensorboard \ # report_to:报告给tensorboard--overwrite_output_dir \ # overwrite_output_dir:覆盖输出目录--deepspeed ds_config_zero2.json \ # deepspeed:分布式训练配置文件--ignore_data_skip true \ # ignore_data_skip:忽略数据跳过--bf16 \ # bf16:使用bf16--gradient_checkpointing \ # gradient_checkpointing:梯度检查点--bf16_full_eval \ # bf16_full_eval:bf16全评估--ddp_timeout 18000000 \ # ddp_timeout:ddp超时| tee -a ${output_model}/train.log # tee:将标准输出重定向到文件,同时显示在屏幕上# --resume_from_checkpoint ${output_model}/checkpoint-20400 \ # resume_from_checkpoint:从检查点恢复
2.全量参数微调代码
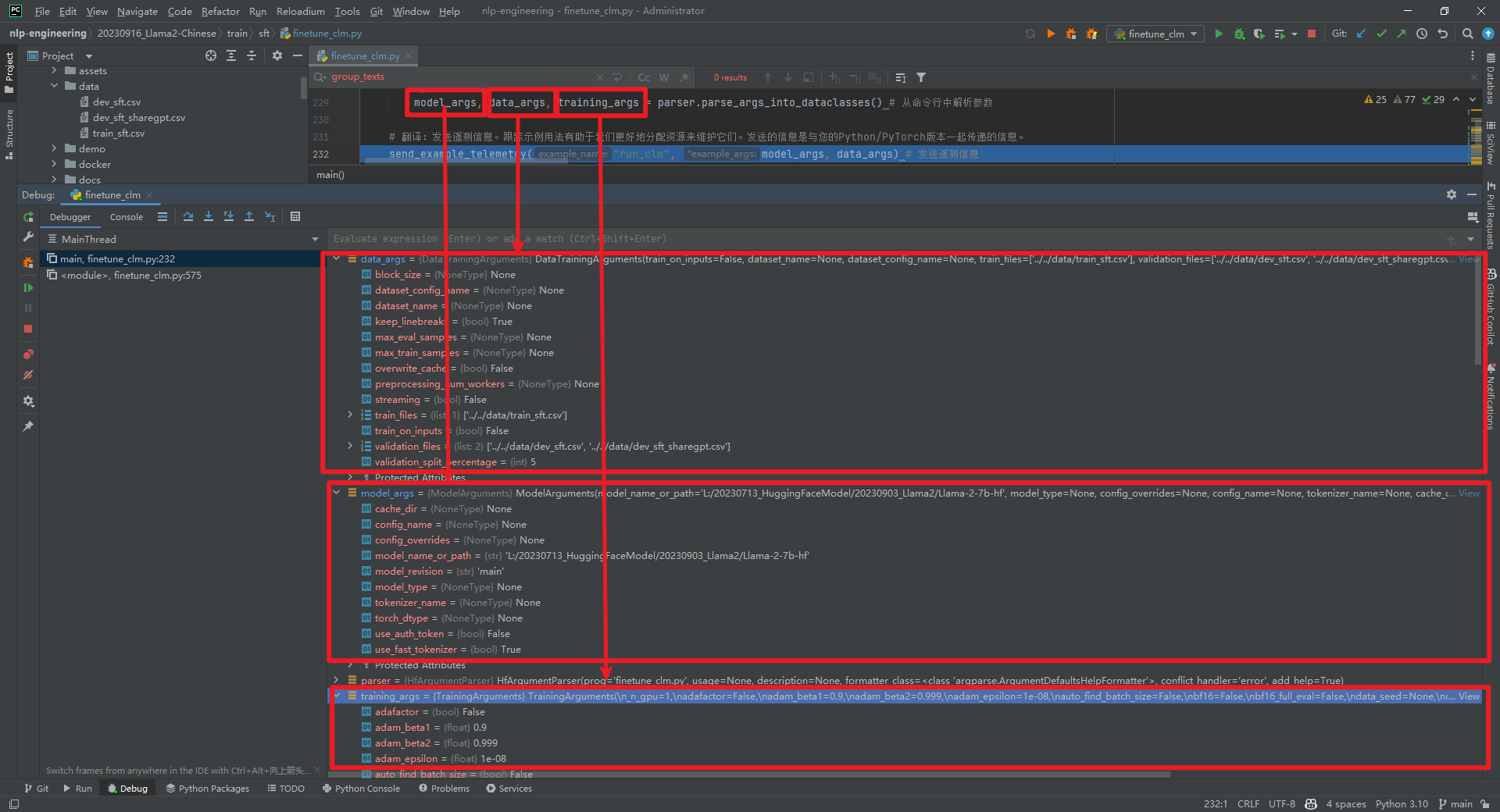
全量参数微调具体实现代码train/sft/finetune_clm.py,全部代码参考文献[5]。从命令行中解析参数model_args, data_args, training_args = parser.parse_args_into_dataclasses()。model_args、data_args和training_args如下所示:
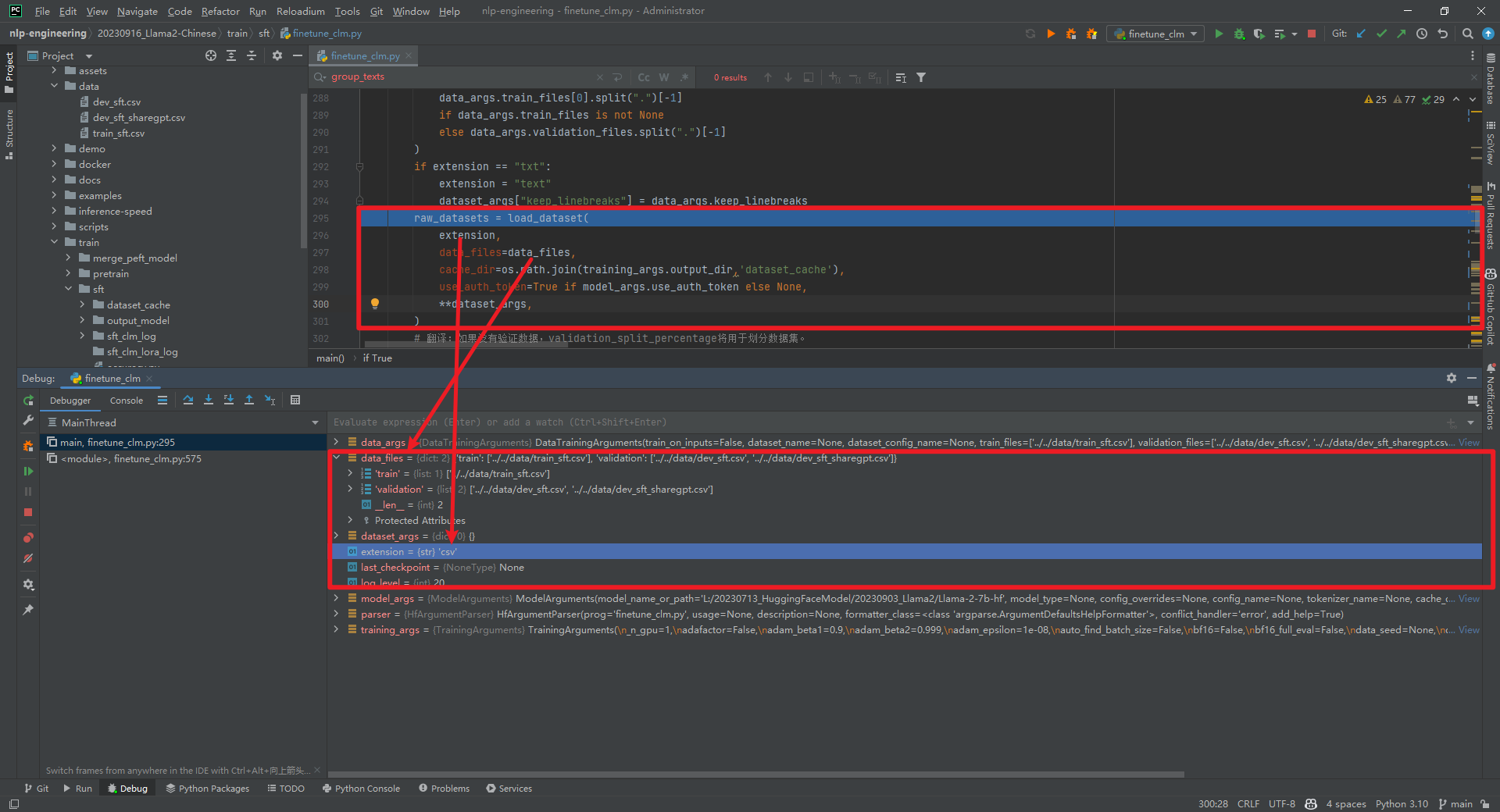
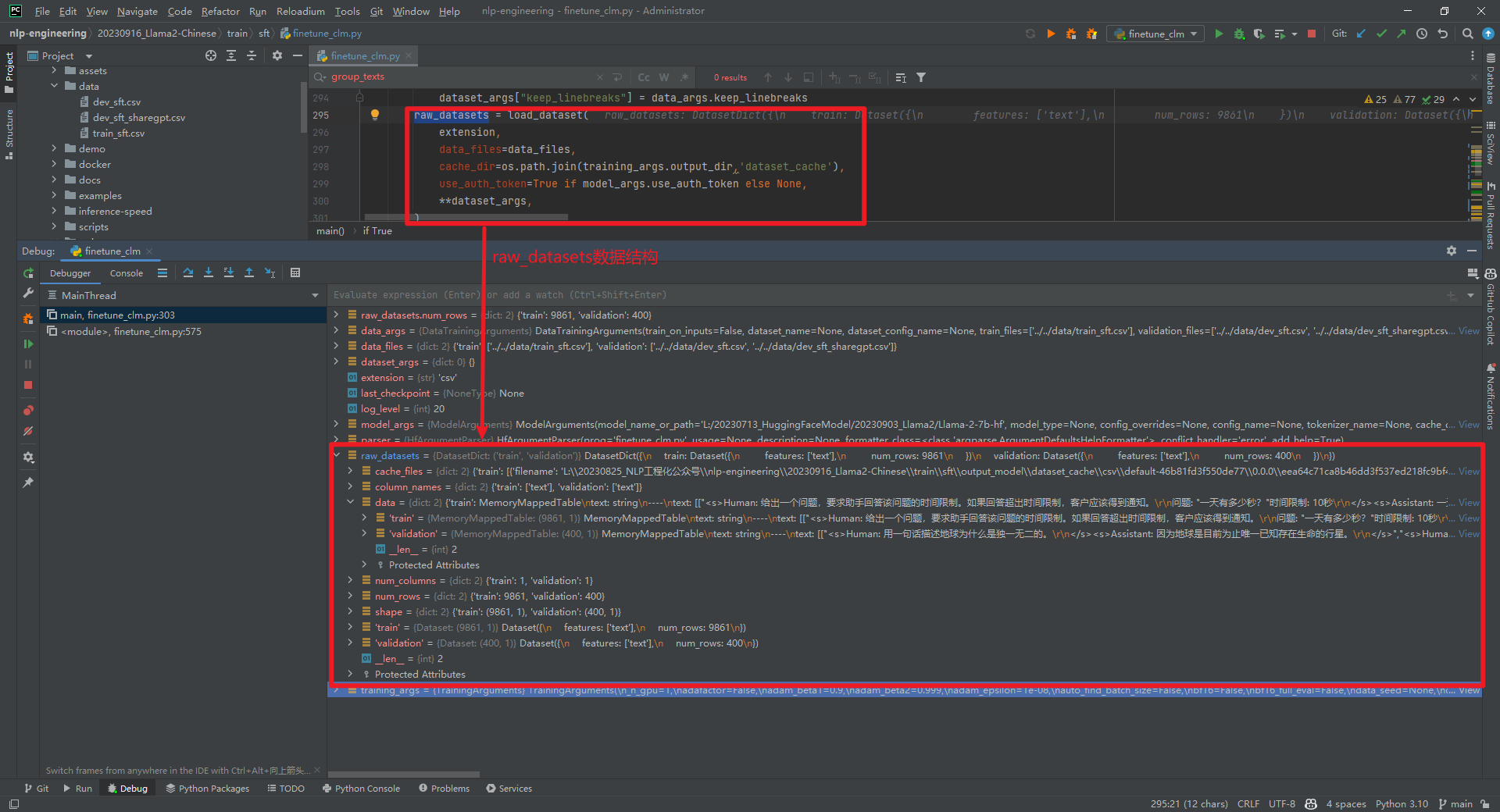
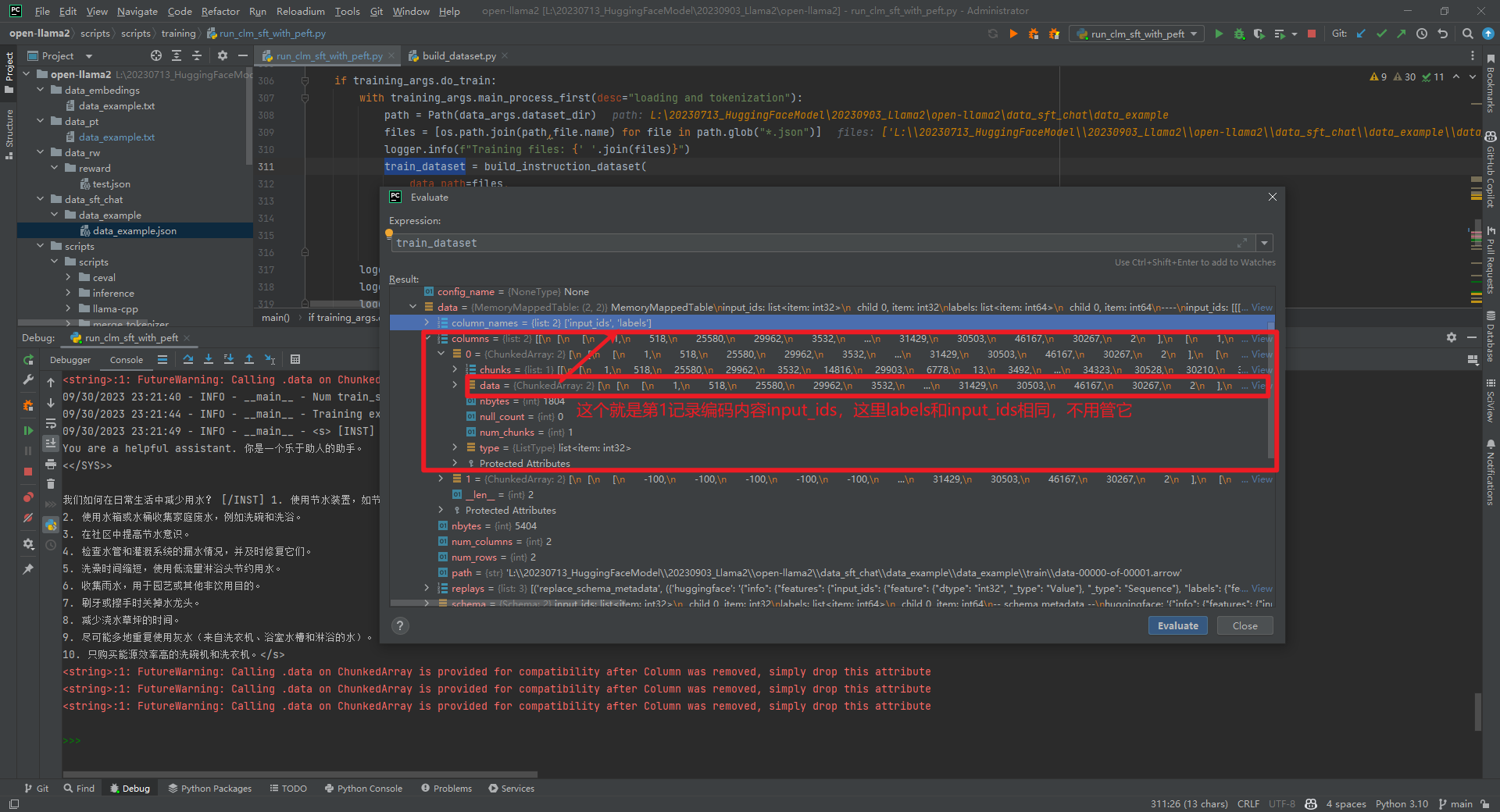
raw_datasets = load_dataset(...)数据结构如下所示:
tokenized_datasets = raw_datasets.map(...)数据结构如下所示:
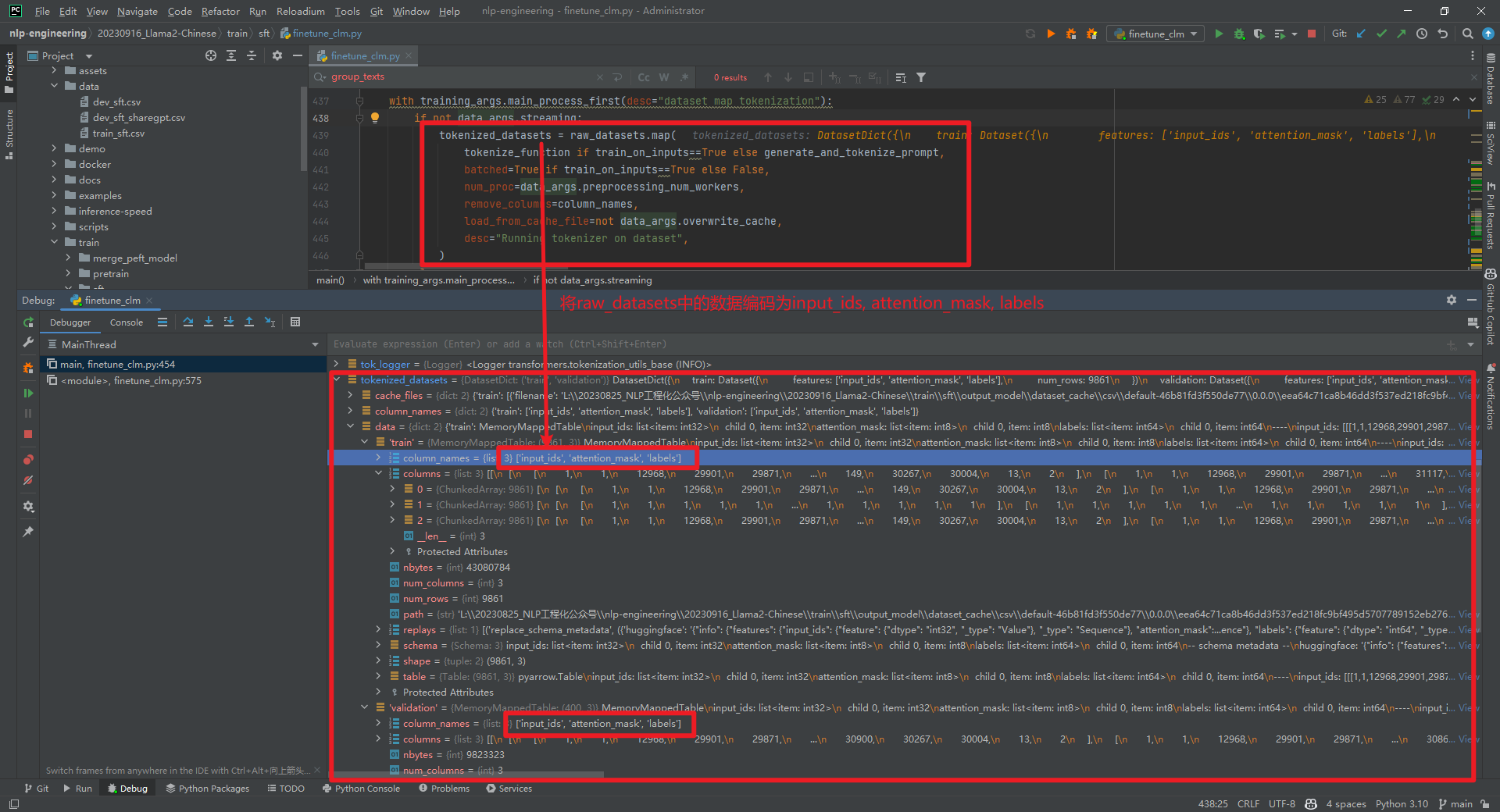
从上面可以看到是对一行记录进行了编码,即input_ids数值。比如,<s>Human: 给出一个问题,要求助手回答该问题的时间限制。如果回答超出时间限制,客户应该得到通知。问题: "一天有多少秒?"时间限制: 10秒</s><s>Assistant: 一天有86400秒。</s>。
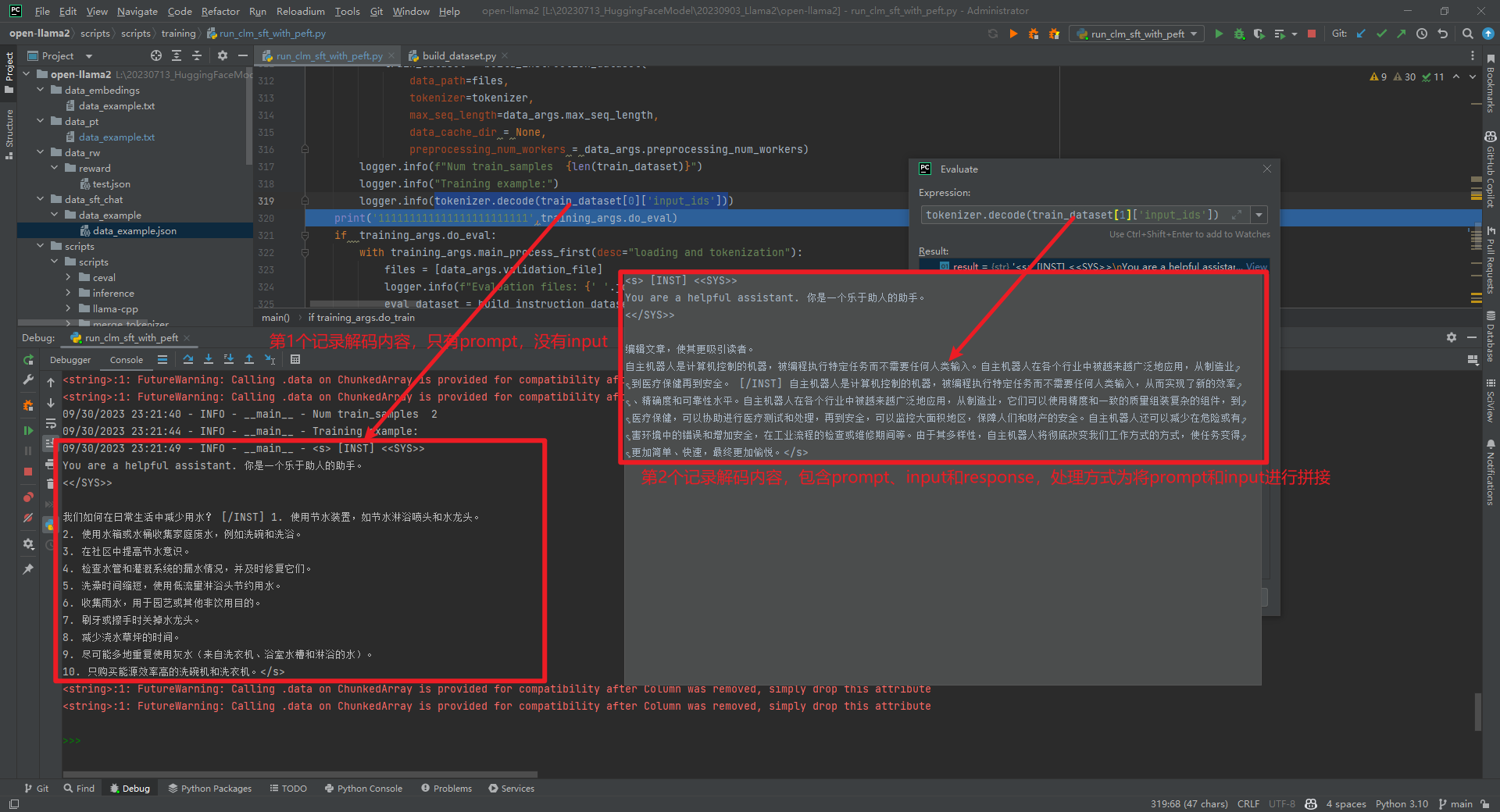
这个时候可能有个疑问,如果是指令数据格式,那么在微调的时候如何进行编码呢?找到了开源项目open-llama2[4],它的微调数据data_example.json文件如下所示:
[{"instruction": "我们如何在日常生活中减少用水?","input": "","output": "1. 使用节水装置,如节水淋浴喷头和水龙头。 \n2. 使用水箱或水桶收集家庭废水,例如洗碗和洗浴。 \n3. 在社区中提高节水意识。 \n4. 检查水管和灌溉系统的漏水情况,并及时修复它们。 \n5. 洗澡时间缩短,使用低流量淋浴头节约用水。 \n6. 收集雨水,用于园艺或其他非饮用目的。 \n7. 刷牙或擦手时关掉水龙头。 \n8. 减少浇水草坪的时间。 \n9. 尽可能多地重复使用灰水(来自洗衣机、浴室水槽和淋浴的水)。 \n10. 只购买能源效率高的洗碗机和洗衣机。"},{"instruction": "编辑文章,使其更吸引读者。","input": "自主机器人是计算机控制的机器,被编程执行特定任务而不需要任何人类输入。自主机器人在各个行业中被越来越广泛地应用,从制造业到医疗保健再到安全。","output": "自主机器人是计算机控制的机器,被编程执行特定任务而不需要任何人类输入,从而实现了新的效率、精确度和可靠性水平。自主机器人在各个行业中被越来越广泛地应用,从制造业,它们可以使用精度和一致的质量组装复杂的组件,到医疗保健,可以协助进行医疗测试和处理,再到安全,可以监控大面积地区,保障人们和财产的安全。自主机器人还可以减少在危险或有害环境中的错误和增加安全,在工业流程的检查或维修期间等。由于其多样性,自主机器人将彻底改变我们工作方式的方式,使任务变得更加简单、快速,最终更加愉悦。"}
]
通过调试发现,如果input不为空,那么将prompt+input拼接在一起作为问题,如下所示:
三.加载全量参数微调
调用方式同模型调用代码示例,如下所示:
from transformers import AutoTokenizer, AutoModelForCausalLM
from pathlib import Path
import torchpretrained_model_name_or_path = r'...'
model = AutoModelForCausalLM.from_pretrained(Path(f'{pretrained_model_name_or_path}'), device_map='auto', torch_dtype=torch.float16, load_in_8bit=True) #加载模型
model = model.eval() #切换到eval模式
tokenizer = AutoTokenizer.from_pretrained(Path(f'{pretrained_model_name_or_path}'), use_fast=False) #加载tokenizer
tokenizer.pad_token = tokenizer.eos_token #为了防止生成的文本出现[PAD],这里将[PAD]重置为[EOS]
input_ids = tokenizer(['<s>Human: 介绍一下中国\n</s><s>Assistant: '], return_tensors="pt", add_special_tokens=False).input_ids.to('cuda') #将输入的文本转换为token
generate_input = {"input_ids": input_ids, #输入的token"max_new_tokens": 512, #最大生成的token数量"do_sample": True, #是否采样"top_k": 50, #采样的top_k"top_p": 0.95, #采样的top_p"temperature": 0.3, #采样的temperature"repetition_penalty": 1.3, #重复惩罚"eos_token_id": tokenizer.eos_token_id, #结束token"bos_token_id": tokenizer.bos_token_id, #开始token"pad_token_id": tokenizer.pad_token_id #pad token
}
generate_ids = model.generate(**generate_input) #生成token
text = tokenizer.decode(generate_ids[0]) #将token转换为文本
print(text) #输出生成的文本
参考文献:
[1]https://huggingface.co/blog/llama2
[2]全参数微调时,报没有target_modules变量:https://github.com/FlagAlpha/Llama2-Chinese/issues/169
[3]https://huggingface.co/FlagAlpha
[4]https://github.com/huxiaosheng123/open-llama2/tree/main#微调脚本
[5]https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/train/sft/finetune_clm.py
相关文章:
Llama2-Chinese项目:3.1-全量参数微调
提供LoRA微调和全量参数微调代码,训练数据为data/train_sft.csv,验证数据为data/dev_sft.csv,数据格式如下所示: "<s>Human: "问题"\n</s><s>Assistant: "答案举个例子,如下所…...

蓝桥等考Python组别十级001
第一部分:选择题 1、Python L10 (15分) 已知s = Hello!,下列说法正确的是( )。 s[1]对应的字符是Hs[2]对应的字符是ls[-1]对应的字符是os[3]对应的字符是o正确答案:B 2、Python L10 (15分) 运行下面程序,输入字符串“Banana”,输出的结果是&#x...

记录 Git 操作时遇到的问题及解决方案
目录 问题:git pull 时报错报错内容: ! [rejected] v1.0.3 -> v1.0.3 (would clobber existing tag)原因:本地 Git 仓库中已经存在名为 v1.0.3 和 v1.0.6 的标签了,而尝试从远程仓库(GitHub)拉取这些标签…...
第一届“龙信杯”电子数据取证竞赛Writeup
目录 移动终端取证 请分析涉案手机的设备标识是_______。(标准格式:12345678) 请确认嫌疑人首次安装目标APP的安装时间是______。(标准格式:2023-09-13.11:32:23) 此检材共连接过______个WiFi。&#x…...

Vue与React//双绑问题
Vue和React是两个目前最流行的前端框架,它们有一些区别主要区别如下: 响应式原理:Vue使用基于模板的方式进行双向绑定,其中使用了Vue自己实现的响应式系统。Vue能够通过追踪数据的依赖关系,自动更新DOM元素。而React采…...

信息安全第四周
社会工程学 社会工程学主要研究如何操纵人的心理和情感来获取机密信息或其他目标。它主要不是通过技术手段攻击计算机系统,而是通过心理学和人际交往技巧来欺骗人,使他们泄露密码、安全代码或其他敏感信息。社会工程学主要是一种安全风险,主要…...

机器学习基础概念与常见算法入门【机器学习、常见模型】
机器学习基础概念与算法 机器学习是计算机科学领域的一个分支,它致力于让计算机系统具备从数据中学习和改进的能力,而不需要显式地进行编程。与传统编程相比,机器学习有着根本性的不同之处。 机器学习与传统编程的不同 传统编程࿱…...

移动端 [Android iOS] 压缩 ECDSA PublicKey
移动端 [Android & iOS] 压缩 ECDSA PublicKey AndroidiOS 使用 Android KeyStore 和 iOS 的 Secure Enclave 提供的安全能力使用 P-256 来对 API 请求进行签名,服务器端再进行验证。 但是发现不论是 iOS 还是安卓都没有提供一个便捷的方式从 iOS 的SecKeyCopyE…...

Spring的配置Bean的方式
在Spring框架中,配置Bean有三种主要方式:自动装配、基于Java的显式配置和基于XML的显式配置。 1、自动装配: 自动装配是Spring容器根据Bean之间的依赖关系,自动将需要的Bean注入到目标Bean中。这是一种非常简便和快捷的配置方式&…...

安防监控/视频汇聚平台EasyCVR云端录像不展示是什么原因?该如何解决?
视频云存储/安防监控EasyCVR视频汇聚平台基于云边端智能协同,支持海量视频的轻量化接入与汇聚、转码与处理、全网智能分发、视频集中存储等。音视频流媒体视频平台EasyCVR拓展性强,视频能力丰富,具体可实现视频监控直播、视频轮播、视频录像、…...

毛玻璃态登录表单
效果展示 页面结构组成 通过上述的效果展示可以看出如下几个效果 底部背景有三个色块并且效果是毛玻璃效果登录表单是毛玻璃效果登录表单的周围的小方块也是有毛玻璃效果并且与登录表单有层次效果 CSS3 知识点 filter 属性backdrop-filter 属性绝对定位属性动画属性 底部背…...

Java:使用 Graphics2D 类来绘制图像
目录 过程介绍创建一个 BufferedImage 对象创建一个 Graphics2D 对象绘制字符和干扰线将生成的图像保存到文件 示例代码 过程介绍 创建一个 BufferedImage 对象 首先创建一个 BufferedImage 对象来表示图像 创建一个 Graphics2D 对象 然后使用 createGraphics() 方法创建一…...
VUE2项目:尚品汇VUE-CLI脚手架初始化项目以及路由组件分析(一)
标题 环境VUE2目录publicassetscomponentsmain.jsbabel.config.jspackage.jsonvue.config.js 项目路由分析Header与Footer非路由组件完成Header示例 路由组件的搭建声明式导航编程式导航 Footer组件的显示与隐藏路由传递参数重写push和replace三级联动组件拆分附件 环境 前提要…...

输入网址input,提取标题和正文
https://m.51cmm.com/wz/WZnKubw1.html?share_token715beaff-33ef-466b-8b6c-092880b9a716&tt_fromcopy_link&utm_sourcecopy_link&utm_mediumtoutiao_android&utm_campaignclient_share - 【科学决策七步骤 - 希律心理】 - 今日头条 提取标题和正文input输…...

docker--redis容器部署及与SpringBoot整合
1. 容器化部署docker 拉取镜像创建数据目录data 及 配置目录conf创建配置文件redis.conf启动redis容器进入容器,进行Redis操作设置为自启动:docker update redis --restart=alwaysdocker pull redis:5.0.12docker run -d --rm --name my_redis -p 6379:6379 -v D:/docker/red…...
)
数据库:Hive转Presto(二)
继续上节代码,补充了replace_func函数, import re import os from tkinter import *class Hive2Presto:def __int__(self):self.t_funcs [substr, nvl, substring, unix_timestamp] \[to_date, concat, sum, avg, abs, year, month, ceiling, floor]s…...
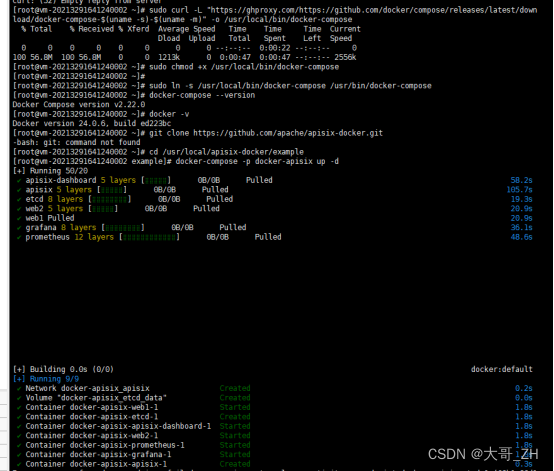
docker安装apisix全教程包含windows和linux
docker安装apisix 一、Windows安装1、首先需要安装docker和docker compose,如果直接安装docker desktop,会自动安装docker compose。2、重新启动电脑3、访问 Docker 的下载([https://www.docker.com/products/docker-desktop](https://www.do…...

【C++进阶】:C++11
C11 一.统一列表的初始化1.{}初始化2.initializer_list 二.声明1.decltype2.nullptr 三.右值引用和移动语义1.左值和右值1.转义语句2.完美转发 四.可变参数模板1.基本概念2.STL里emplace类接口 五.lambda表达式六.新的类功能 一.统一列表的初始化 1.{}初始化 在C98中…...
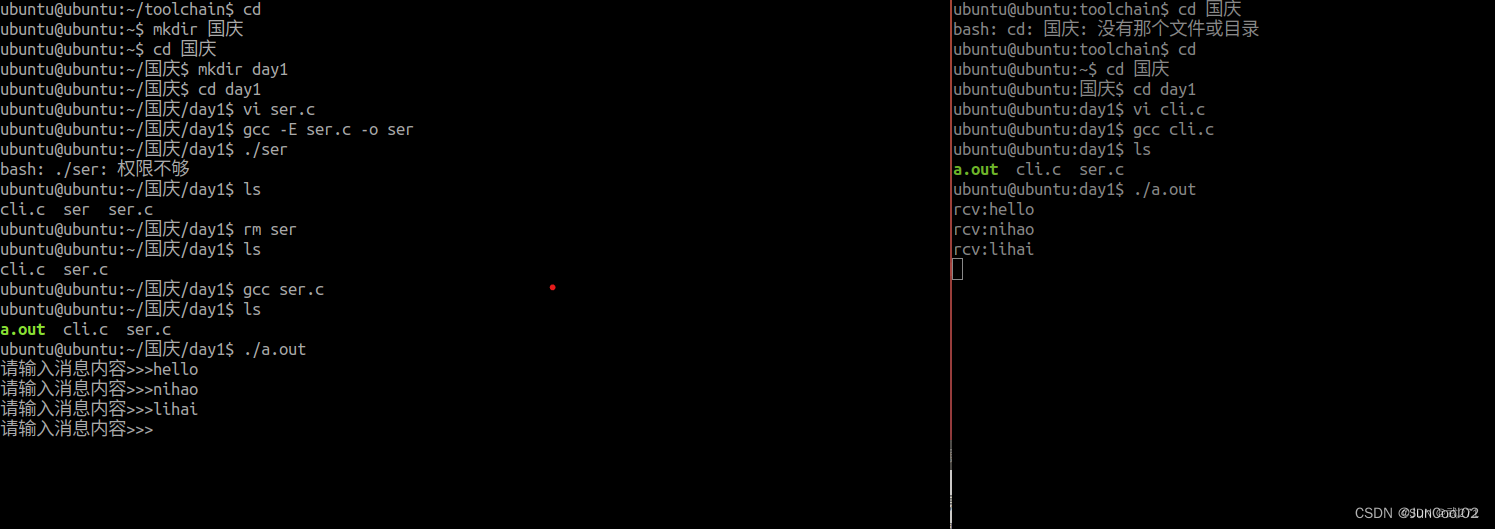
9.30消息队列实现进程之间通信方式代码,现象
服务端 #include <myhead.h>#define ERR_MSG(msg) do{\fprintf(stderr,"__%d__:",__LINE__);\perror(msg);\ }while(0)typedef struct{ long msgtype; //消息类型char data[1024]; //消息正文 }Msg;#define SIZE sizeof(Msg)-sizeof(long)int main(int argc…...

【Oracle】Oracle系列之十三--游标
文章目录 往期回顾前言1. 游标的定义2. 游标的类型(1)显式游标(2)隐式游标 3. 游标的应用(1)基本用法(2)数据处理(3)更新数据(4)注意事…...

边缘计算中的机器学习能效优化与混合架构实践
1. 边缘计算中的机器学习能效革命在智能手表、健康监测设备等穿戴式设备中,实时运行机器学习模型一直是个棘手的问题。传统方案要么耗电太快导致续航崩溃,要么精度太低失去实用价值。我们团队最近实验的一组数据很能说明问题:在常见的运动识别…...

算法将驱动一切:边缘AI智能体如何重塑智能系统
仓库装卸区的安全摄像头每天采集86400秒的视频数据。长途卡车上的车队远程信息记录仪在两次加油之间积累了数GB的行车影像。外科手术机器人的立体摄像头以每秒60帧的速度生成密集点云。所有这些数据都产生于数字世界与现实世界的交界处,但几乎没有任何一条被用于智能…...

淘宝要接入AI购物助手:以后买东西,可能不是搜索,而是“让AI帮你挑”
最近AI圈有一个很值得关注的新热点。据路透社5月10日报道,阿里巴巴正准备把通义千问Qwen接入淘宝,让用户可以通过和AI聊天的方式浏览、比较和购买商品,而不是像以前那样自己一个个翻商品列表。报道还提到,Qwen应用将接入淘宝和天猫…...

阿里云效前端流水线自动化部署
一、权限准备 如果你想实现这个功能,那么你的云效必须要有权限!!这非常重要!!如何确定自己是否有相关权限呢? 流水线权限 制品仓库权限 就是云服务器的权限,这个权限是要你可以读写文件的…...

网站国产化改造怎么做?深度解读国产化替代路径与CMS推荐
在近年来科技领域的舆论场中,“国产化”无疑是出现频率最高的关键词之一。从芯片到操作系统,从数据库到办公软件,再到企业对外展示的门户——网站,国产化替代已从“可选项”变成了很多行业的“必答题”。但国产化仅仅是“换个牌子…...

从电机控制到呼吸灯:用STM32CubeMX玩转TIM高级定时器的互补PWM与死区时间配置
从电机控制到呼吸灯:用STM32CubeMX玩转TIM高级定时器的互补PWM与死区时间配置 在嵌入式开发中,定时器是最基础也最强大的外设之一。对于STM32开发者来说,掌握高级定时器的互补PWM输出和死区时间配置,意味着可以解锁从电机控制到LE…...

602 游戏平台 — 做玩家喜爱、信任的游戏平台!
602 游戏是2013 年上线的老牌正规页游平台,十年稳定运营,始终以 “玩家喜爱、信任”为核心,主打传奇类精品页游 ,三端互通✅ 平台核心优势(为什么玩家信任)正规合规,账号安全:文网文…...

JPlag代码抄袭检测:17种编程语言的智能原创守护者
JPlag代码抄袭检测:17种编程语言的智能原创守护者 【免费下载链接】JPlag State-of-the-Art Source Code Plagiarism & Collusion Detection. Check for plagiarism in a set of programs. 项目地址: https://gitcode.com/gh_mirrors/jp/JPlag 在数字化教…...

SkillSync MCP:为AI技能市场构建自动化安全门禁系统
1. 项目概述:为AI技能市场装上“安全门” 如果你和我一样,是Claude Code、Cursor这类AI编程助手的深度用户,那你一定对“技能”(Skills)这个概念不陌生。简单来说,技能就是一些预定义的提示词模板或工具脚…...

飞书文档批量导出工具:25分钟搞定700+文档的迁移难题
飞书文档批量导出工具:25分钟搞定700文档的迁移难题 【免费下载链接】feishu-doc-export 飞书文档导出服务 项目地址: https://gitcode.com/gh_mirrors/fe/feishu-doc-export 当企业需要切换办公平台或进行数据备份时,飞书文档的批量迁移常常成为…...