初级篇—第四章聚合函数
文章目录
- 聚合函数介绍
- 聚合函数介绍
- COUNT函数
- AVG和SUM函数
- MIN和MAX函数
- GROUP BY
- 语法
- 基本使用
- 使用多个列分组
- WITH ROLLUP
- HAVING
- 基本使用
- WHERE和HAVING的对比
- 开发中的选择
- SELECT的执行过程
- 查询的结构
- SQL 的执行原理
- 练习
- 流程函数
聚合函数介绍
聚合函数作用于一组数据,并对一组数据返回一个值

聚合函数类型
- AVG()
- SUM()
- MAX()
- MIN()
- COUNT()
聚合函数介绍

COUNT函数
- count(*)
- count(字段)
- count(常数)
COUNT(*)返回表中记录总数,适用于任意数据类型。
SELECT COUNT(*) FROM employees;
- 返回107行
COUNT(expr) 返回expr不为空的记录总数
SELECT COUNT(commission_pct) FROM employees
- 返回35行
问题:用count(*),count(1),count(列名)谁好呢?
- 其实,对于MyISAM引擎的表是没有区别的。这种引擎内部有一计数器在维护着行数。Innodb引擎的表用count(*),count(1)直接读行数,复杂度是O(n),因为Innodb真的要去数一遍。但好于具体的count(列名)。
问题:能不能使用count(列名)替换count(*)?
- 不要使用 count(列名)来替代 count(
*) , count(*) 是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。 - 说明:count(
*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
AVG和SUM函数
可以对数值型数据使用AVG 和 SUM 函数
SELECT AVG(salary), MAX(salary),MIN(salary), SUM(salary) FROM employees
- AVG就是求平均值
- SUM就是求和
SELECT AVG(commission_pct),SUM(commission_pct),SUM(commission_pct)/COUNT(1),SUM(commission_pct)/COUNT(commission_pct) FROM employees;AVG(commission_pct) SUM(commission_pct) sum(commission_pct)/count(1) SUM(commission_pct)/count(commission_pct)
------------------- ------------------- ---------------------------- -------------------------------------------0.222857 7.80 0.072897 0.222857
- 从这能看出,AVG和SUM统计的都是非空的值
MIN和MAX函数
可以对任意数据类型的数据使用 MIN 和 MAX 函数
SELECT MIN(hire_date), MAX(hire_date) FROM employees;
GROUP BY

语法
可以使用GROUP BY子句将表中的数据分成若干组
SELECT column, group_function(column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[ORDER BY column];
明确:WHERE一定放在FROM后面
基本使用
在SELECT列表中所有未包含在组函数中的列都应该包含在 GROUP BY子句中
#求出各部门的平均工资
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id ;
- 包含在 GROUP BY 子句中的列不必包含在SELECT 列表中
使用多个列分组
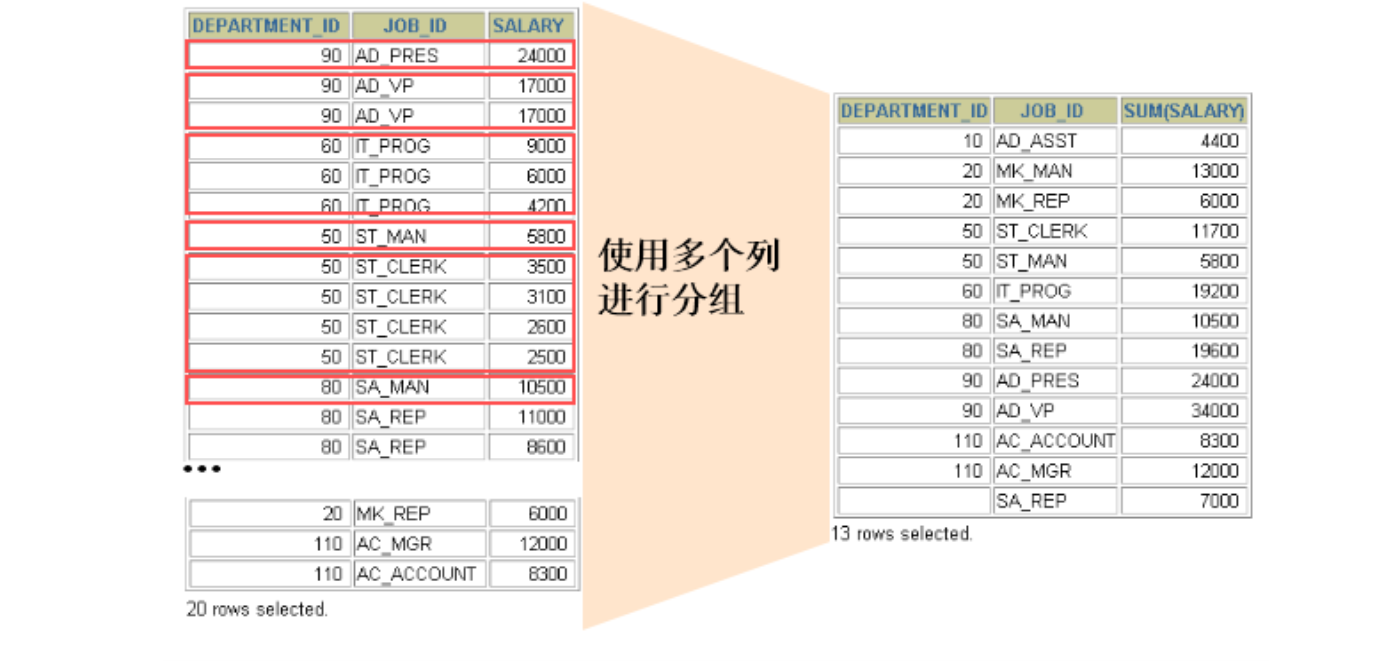
#求个各个部门,各个工种的平均工资
SELECT department_id dept_id, job_id, SUM(salary)
FROM employees
GROUP BY department_id, job_id ;
WITH ROLLUP
使用 WITH ROLLUP 关键字之后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量。
SELECT department_id,AVG(salary)
FROM employees
WHERE department_id > 80
GROUP BY department_id WITH ROLLUP;
注意:当使用ROLLUP时,不能同时使用ORDER BY子句进行结果排序,即ROLLUP和ORDER BY是互相排斥的。
HAVING
基本使用
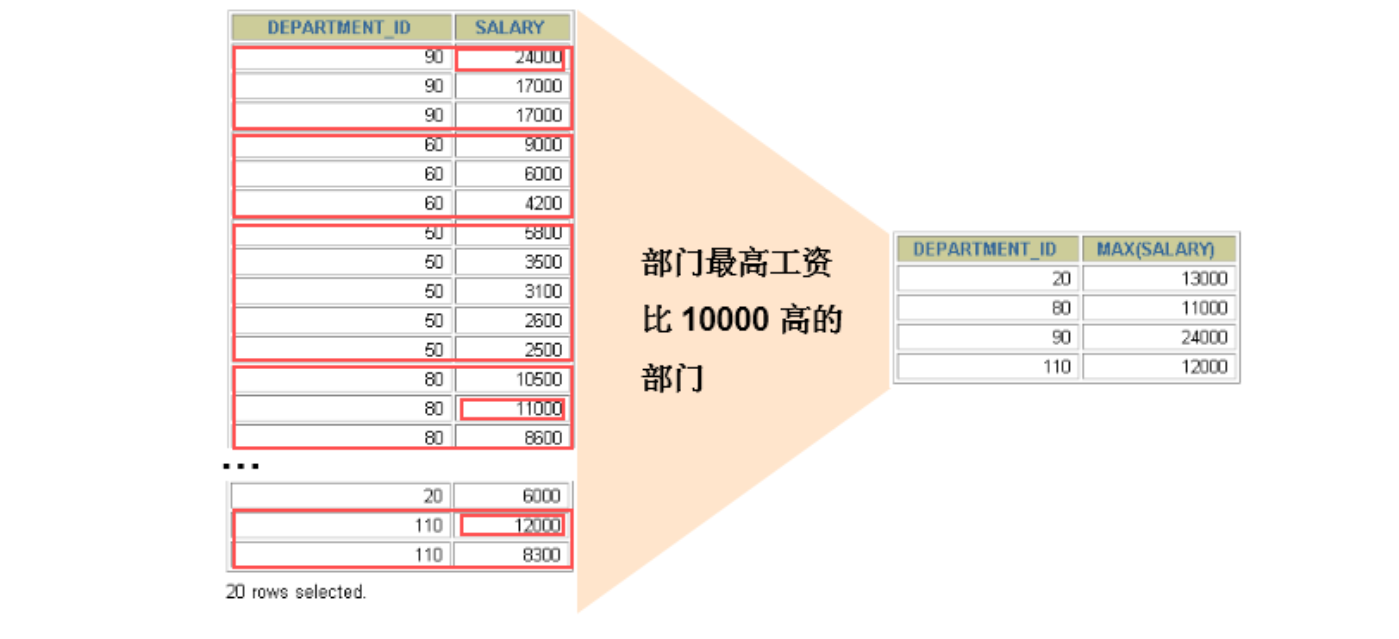
过滤分组:HAVING子句
- 行已经被分组。
- 使用了聚合函数。
- 满足HAVING 子句中条件的分组将被显示。
- HAVING 不能单独使用,必须要跟 GROUP BY 一起使用。
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary)>10000 ;
非法使用聚合函数 : 不能在 WHERE 子句中使用聚合函数
SELECT department_id, AVG(salary)
FROM employees
WHERE AVG(salary) > 8000
GROUP BY department_id;
查询:SELECT department_id, AVG(salary) FROM employees WHERE AVG(salary) > 8000 GROUP BY department_id LIMIT 0, 1000错误代码: 1111 Invalid use of group function
WHERE和HAVING的对比
区别1:WHERE 可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;
HAVING 必须要与 GROUP BY 配合使用,可以把分组计算的函数和分组字段作为筛选条件。
- 这决定了,在需要对数据进行分组统计的时候,HAVING 可以完成 WHERE 不能完成的任务。这是因为,在查询语法结构中,WHERE 在 GROUP BY 之前,所以无法对分组结果进行筛选。HAVING 在 GROUP BY 之后,可以使用分组字段和分组中的计算函数,对分组的结果集进行筛选,这个功能是 WHERE 无法完成的。另外,WHERE排除的记录不再包括在分组中。
区别2:如果需要通过连接从关联表中获取需要的数据,WHERE 是先筛选后连接,而 HAVING 是先连接后筛选。
这一点,就决定了在关联查询中,WHERE 比 HAVING 更高效。
- 因为 WHERE 可以先筛选,用一个筛选后的较小数据集和关联表进行连接,这样占用的资源比较少,执行效率也比较高。HAVING 则需要先把结果集准备好,也就是用未被筛选的数据集进行关联,然后对这个大的数据集进行筛选,这样占用的资源就比较多,执行效率也较低。
开发中的选择
WHERE 和 HAVING 也不是互相排斥的,我们可以在一个查询里面同时使用 WHERE 和 HAVING。包含分组统计函数的条件用 HAVING,普通条件用 WHERE。这样,我们就既利用了 WHERE 条件的高效快速,又发挥了 HAVING 可以使用包含分组统计函数的查询条件的优点。当数据量特别大的时候,运行效率会有很大的差别。
SELECT的执行过程
查询的结构
#方式1:
SELECT ...,....,...
FROM ...,...,....
WHERE 多表的连接条件
AND 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...#方式2:
SELECT ...,....,...
FROM ... JOIN ...
ON 多表的连接条件
JOIN ...
ON ...
WHERE 不包含组函数的过滤条件
AND/OR 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...#其中:
#(1)from:从哪些表中筛选
#(2)on:关联多表查询时,去除笛卡尔积
#(3)where:从表中筛选的条件
#(4)group by:分组依据
#(5)having:在统计结果中再次筛选
#(6)order by:排序
#(7)limit:分页
关键字的顺序是不能颠倒
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT...
SELECT 语句的执行顺序(在 MySQL 和 Oracle 中,SELECT 执行顺序基本相同
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT 的字段 -> DISTINCT -> ORDER BY -> LIMIT
比如你写了一个 SQL 语句,那么它的关键字顺序和执行顺序是下面这样的:
SELECT DISTINCT player_id, player_name, count(*) as num # 顺序 5
FROM player JOIN team ON player.team_id = team.team_id # 顺序 1
WHERE height > 1.80 # 顺序 2
GROUP BY player.team_id # 顺序 3
HAVING num > 2 # 顺序 4
ORDER BY num DESC # 顺序 6
LIMIT 2 # 顺序 7
在 SELECT 语句执行这些步骤的时候,每个步骤都会产生一个虚拟表 ,然后将这个虚拟表传入下一个步骤中作为输入。需要注意的是,这些步骤隐含在 SQL 的执行过程中,对于我们来说是不可见的。
SQL 的执行原理
- SELECT 是先执行 FROM 这一步的。在这个阶段,如果是多张表联查,还会经历下面的几个步骤:
- 首先先通过 CROSS JOIN 求笛卡尔积,相当于得到虚拟表 vt(virtual table)1-1;
- 通过 ON 进行筛选,在虚拟表 vt1-1 的基础上进行筛选,得到虚拟表 vt1-2;
- 添加外部行。如果我们使用的是左连接、右链接或者全连接,就会涉及到外部行,也就是在虚拟表 vt1-2 的基础上增加外部行,得到虚拟表 vt1-3。当然如果我们操作的是两张以上的表,还会重复上面的步骤,直到所有表都被处理完为止。这个过程得到是我们的原始数据
- 第二步就是通过WHERE进行条件的过滤掉不满足条件的行,得到虚拟表vt2
- 然后进入第三步和第四步,也就是 GROUP 和 HAVING 阶段 。在这个阶段中,实际上是在虚拟表 vt2 的基础上进行分组和分组过滤,得到中间的虚拟表 vt3 和 vt4
- 当我们完成了条件筛选部分之后,就可以筛选表中提取的字段,也就是进入到 SELECT 和 DISTINCT阶段 。首先在 SELECT 阶段会提取想要的字段,然后在 DISTINCT 阶段过滤掉重复的行,分别得到中间的虚拟表vt5-1 和 vt5-2 。
- 当我们提取了想要的字段数据之后,就可以按照指定的字段进行排序,也就是 ORDER BY 阶段 ,得到虚拟表 vt6 。
- 最后在 vt6 的基础上,取出指定行的记录,也就是 LIMIT 阶段 ,得到最终的结果,对应的是虚拟表vt7 。当然我们在写 SELECT 语句的时候,不一定存在所有的关键字,相应的阶段就会省略。
同时因为 SQL 是一门类似英语的结构化查询语言,所以我们在写 SELECT 语句的时候,还要注意相应的关键字顺序,所谓底层运行的原理,就是我们刚才讲到的执行顺序。
练习
#1.where子句可否使用组函数进行过滤?
#不可以,因为先进行where进行数据过滤,再进行分组,计算分组函数
#2.查询公司员工工资的最大值,最小值,平均值,总和
SELECT MAX(salary), MIN(salary), AVG(salary), sum(salary)
from employees;
#3.查询各job_id的员工工资的最大值,最小值,平均值,总和
SELECT MAX(salary), MIN(salary), AVG(salary), SUM(salary)
FROM employees
group by job_id;
#4.选择具有各个job_id的员工人数
select job_id, count(*)
fROM employees
group by job_id;
# 5.查询员工最高工资和最低工资的差距(DIFFERENCE)
SELECT MAX(salary) - MIN(salary) as DIFFERENCE
FROM employees;
# 6.查询各个管理者手下员工的最低工资,其中最低工资不能低于6000,没有管理者的员工不计算在内
select manager_id,MIN(salary)
FROM employees
where manager_id is not null
group by manager_id
having MIN(salary) >=6000;
# 7.查询所有部门的名字,location_id,员工数量和平均工资,并按平均工资降序`departments`
select t2.`department_name`,t2.`location_id`,count(t1.department_id), avg(t1.salary)
from employees t1
right join departments t2 on t1.department_id = t2.department_id
group by t2.`department_name`,t2.`location_id`
order by AVG(t1.salary) desc;
# 8.查询每个工种、每个部门的部门名、工种名和最低工资
select t1.job_id, t2.`department_name` ,Min(t1.salary)
from employees t1
right join departments t2 on t1.department_id = t2.department_id
group by t1.job_id, t2.department_id
流程函数
流程处理函数可以根据不同的条件,执行不同的处理流程,可以在SQL语句中实现不同的条件选择。MySQL中的流程处理函数主要包括IF()、IFNULL()和CASE()函数
| 函数 | 用法 |
|---|---|
| IF(value,value1,value2) | 如果value的值为TRUE,返回value1, 否则返回value2 |
| IFNULL(value1, value2) | 如果value1不为NULL,返回value1,否 则返回value2 |
| CASE WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2 … [ELSE resultn] END | 相当于Java的if…else if…else… |
| CASE expr WHEN 常量值1 THEN 值1 WHEN 常量值1 THEN 值1 … [ELSE 值n] END | 相当于Java的switch…case… |
SELECT IF(1 > 0,'正确','错误')
->正确
SELECT IFNULL(null,'Hello Word')
->Hello WordSELECT employee_id,12 * salary * (1 + IFNULL(commission_pct,0))
FROM employees;
SELECT CASE
WHEN 1 > 0
THEN '1 > 0'
WHEN 2 > 0
THEN '2 > 0'
ELSE '3 > 0'
END
->1 > 0SELECT employee_id,salary, CASE WHEN salary>=15000 THEN '高薪'
WHEN salary>=10000 THEN '潜力股'
WHEN salary>=8000 THEN '屌丝'
ELSE '草根' END "描述"
FROM employees;
employee_id salary 描述
----------- -------- -----------100 24000.00 高薪 101 17000.00 高薪 102 17000.00 高薪 103 9000.00 屌丝 104 6000.00 草根 105 4800.00 草根 106 4800.00 草根 107 4200.00 草根 108 12000.00 潜力股
SELECT CASE 1
WHEN 1 THEN '我是1'
WHEN 2 THEN '我是2'
ELSE '你是谁SELECT oid,`status`, CASE `status` WHEN 1 THEN '未付款'
WHEN 2 THEN '已付款'
WHEN 3 THEN '已发货'
WHEN 4 THEN '确认收货'
ELSE '无效订单' END
FROM t_order;
mysql> SELECT CASE 1 WHEN 0 THEN 0 WHEN 1 THEN 1 ELSE -1 END;
+------------------------------------------------+
| CASE 1 WHEN 0 THEN 0 WHEN 1 THEN 1 ELSE -1 END |
+------------------------------------------------+
| 1 |
+------------------------------------------------+
1 row in set (0.00 sec)
mysql> SELECT CASE -1 WHEN 0 THEN 0 WHEN 1 THEN 1 ELSE -1 END;
+-------------------------------------------------+
| CASE -1 WHEN 0 THEN 0 WHEN 1 THEN 1 ELSE -1 END |
+-------------------------------------------------+
| -1 |
+-------------------------------------------------+
1 row in set (0.00 sec)
SELECT last_name, job_id, salary,
CASE job_id WHEN 'IT_PROG' THEN 1.10*salary
WHEN 'ST_CLERK' THEN 1.15*salary
WHEN 'SA_REP' THEN 1.20*salary
ELSE salary END "REVISED_SALARY"
FROM employees;
last_name job_id salary REVISED_SALARY
----------- ---------- -------- ----------------
King AD_PRES 24000.00 24000.00
Kochhar AD_VP 17000.00 17000.00
De Haan AD_VP 17000.00 17000.00
Hunold IT_PROG 9000.00 9900.00
Ernst IT_PROG 6000.00 6600.00
相关文章:
初级篇—第四章聚合函数
文章目录 聚合函数介绍聚合函数介绍COUNT函数AVG和SUM函数MIN和MAX函数 GROUP BY语法基本使用使用多个列分组WITH ROLLUP HAVING基本使用WHERE和HAVING的对比开发中的选择 SELECT的执行过程查询的结构SQL 的执行原理 练习流程函数 聚合函数介绍 聚合函数作用于一组数据&#x…...
计算机图像处理-中值滤波
非线性滤波 非线性滤波是利用原始图像跟模版之间的一种逻辑关系得到结果,常用的非线性滤波方法有中值滤波和高斯双边滤波,分别对应cv2.medianBlur(src, ksize)方法和cv2.bilateralFilter(src, d, sigmaColor, sigmaSpace[, dst[, borderType]])方法。 …...

Golang中的包和模块设计
Go,也被称为Golang,是一种静态类型、编译型语言,因其简洁性和对并发编程的强大支持而受到开发者们的喜爱。Go编程的一个关键方面是其包和模块系统,它允许创建可重用、可维护和高效的代码。本博客文章将深入探讨在Go中设计包和模块…...
web:[极客大挑战 2019]Upload
题目 页面显示为一个上传,猜测上传一句话木马文件 先查看源代码看一下有没有有用的信息,说明要先上传图片,先尝试上传含有一句话木马的图片 构造payload <?php eval($_POST[123]);?> 上传后页面显示为,不能包含<&…...
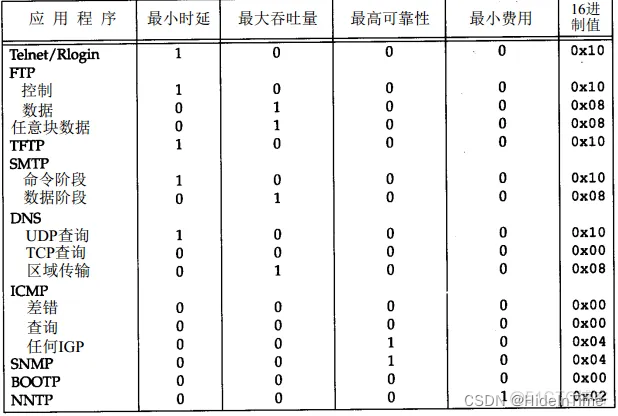
ICMP差错包
ICMP报文分类 Type Code 描述 查询/差错 0-Echo响应 0 Echo响应报文 查询 3-目的不可达 0 目标网络不可达报文 差错 1 目标主机不可达报文 差错 2 目标协议不可达报文 差错 3 目标端口不可达报文 差错 4 要求分段并设置DF flag标志报文 差错 5 源路由…...
算法基础课第二部分
算法基础课 第四讲 数学知识AcWing1381. 阶乘(同余,因式分解) 质数AcWing 866. 质数的判定---试除法AcWing 868. 质数的判定---埃氏筛AcWing867. 分解质因数---试除法AcWing 197. 阶乘---分解质因数---埃式筛 约数AcWing 869. 求约数---试除法AcWing 870. 约数个数-…...

【数据结构】外部排序、多路平衡归并与败者树、置换-选择排序(生成初始归并段)、最佳归并树算法
目录 1、外部排序 1.1 基本概念 1.2 方法 2、多路平衡归并与败者树 2.1 K路平衡归并 2.2 败者树 3、置换-选择排序(生成初始归并段)编辑 4、最佳归并树 4.1 理论基础编辑 4.2 构造方法 编辑 5、各种排序算法的性质 1、外部排序 1.1 基本概…...

抽象工厂模式 创建性模式之五
在看这篇文章之前,请先看看“简单工厂模式”和“工厂方法模式”这两篇博文,会更有助于理解。我们现在已经知道,简单工厂模式就是用一个简单工厂去创建多个产品,工厂方法模式是每一个具体的工厂只生产一个具体的产品,然…...

servlet如何获取PUT和DELETE请求的参数
1. servlet为何不能获取PUT和DELETE请求的参数 Servlet的规范是POST的数据需要转给request.getParameter*()方法,没有规定PUT和DELETE请求也这么做 The Servlet spec requires form data to be available for HTTP POST but not for HTTP PUT or PATCH requests. T…...
【Vue.js】使用Element中的Mock.js搭建首页导航左侧菜单---【超高级教学】
一,Mock.js 1.1 认识Mock.js Mock.js是一个用于前端开发中生成随机数据、模拟接口响应的 JavaScript 库。模拟数据的生成器,用来帮助前端调试开发、进行前后端的原型分离以及用来提高自动化测试效率 总结来说,Element中的Mock.js是一个用于…...

从技术创新到应用实践,百度智能云发起大模型平台应用开发挑战赛!
大模型已经成为未来技术发展方向的重大变革,热度之下更需去虚向实,让技术走进产业场景。在这样的背景下,百度智能云于近期发起了“百度智能云千帆大模型平台应用开发挑战赛”。 挖掘大模型落地应用 千帆大模型平台应用开发挑战赛启动 在不久前…...
简单三步 用GPT-4和Gamma自动生成PPT PDF
1. 用GPT-4 生产PPT内容 我想把下面的文章做成PPT,请你给出详细的大纲和内容 用于谋生的知识,学生主要工作是学习,成年人的工作是养家糊口,这是基本的要求,在这之上,才能有更高的追求。 不要短期期望过高…...

QT设置弹窗显示屏幕中央
Qt设置每次运行弹窗显示屏幕中央 要确保Qt应用程序中的弹出窗口每次都显示在屏幕的中央,您可以使用以下方法: 使用QMessageBox的move方法手动设置窗口位置: #include <QApplication> #include <QMessageBox> #include <QDesk…...
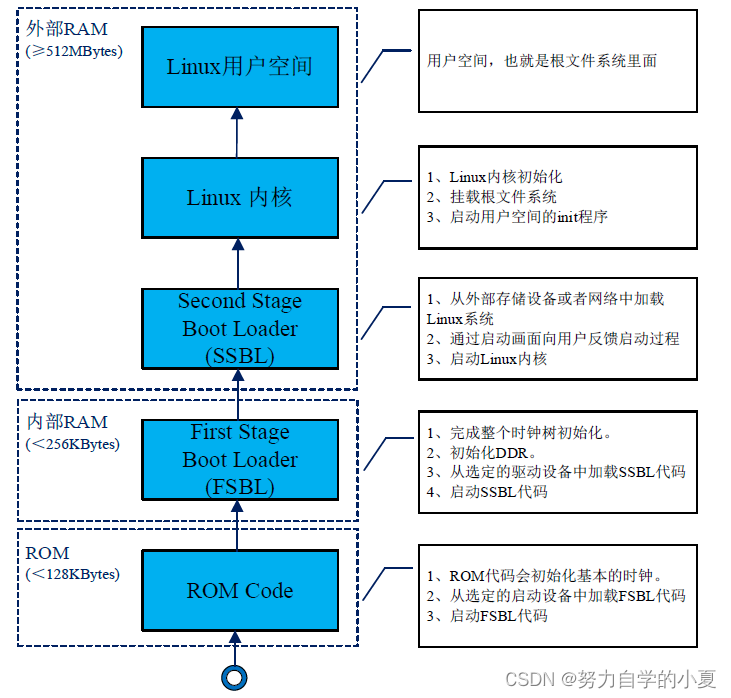
正点原子嵌入式linux驱动开发——STM32MP1启动详解
STM32单片机是直接将程序下载到内部 Flash中,上电以后直接运行内部 Flash中的程序。 STM32MP157内部没有供用户使用的 Flash,系统都是存放在外部 Flash里面的,比如 EMMC、NAND等,因此 STM32MP157上电以后需要从外部 Flash加载程序…...
FPGA的数字钟带校时闹钟报时功能VHDL
名称:基于FPGA的数字钟具有校时闹钟报时功能 软件:Quartus 语言:VHDL 要求: 1、计时功能:这是数字钟设计的基本功能,每秒钟更新一次,并且能在显示屏上显示当前的时间。 2、闹钟功能:如果当前的时间与闹钟设置的时…...
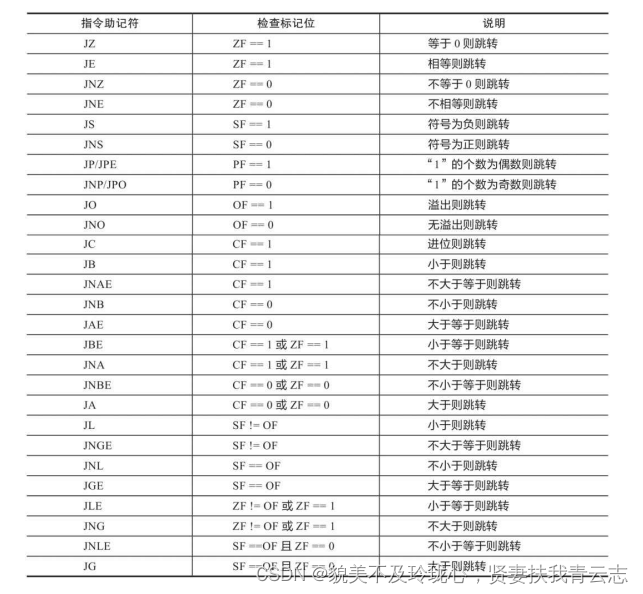
分析各种表达式求值过程
目录 算术运算与赋值 编译器常用的两种优化方案 常量传播 常量折叠 加法 Debug编译选项组下编译后的汇编代码分析 Release开启02执行效率优先 减法 Release版下优化和加法一致,不再赘述 乘法 除法 算术结果溢出 自增和自减 关系运算与逻辑运算 JCC指…...
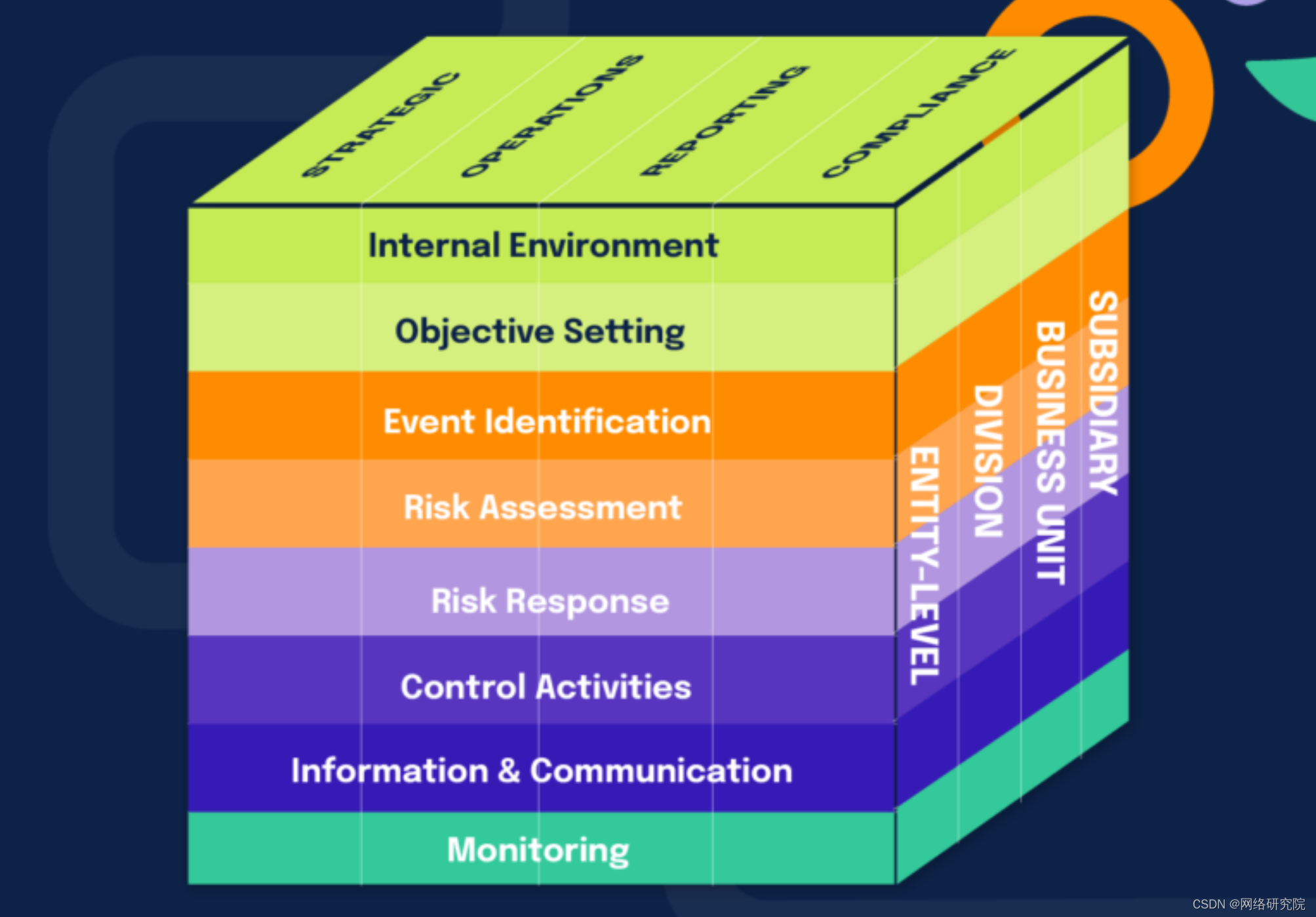
企业风险管理策略终极指南
企业风险管理不一定是可怕的。企业风险管理是一个模糊且难以定义的主题领域。它涵盖了企业的多种风险和程序,与传统的风险管理有很大不同。 那么,企业风险管理到底是什么?在本文中,我们将确定它是什么,提出两种常见的…...

OpenCV之分水岭算法(watershed)
Opencv 中 watershed函数原型: void watershed( InputArray image, InputOutputArray markers ); 第一个参数 image,必须是一个8bit 3通道彩色图像矩阵序列,第一个参数没什么要说的。关键是第二个参数 markers,Opencv官方文档的说…...

npm 命令
目录 初始化 搜索 安装 删除 更新 换源 查看 其他 补充 1.初始化 npm init #初始化一个package.json文件 npm init -y | npm init --yes 2.搜索 npm s jquery | npm search jquery 3.安装 npm install npm -g #更新到最新版本 npm i uniq | npm ins…...

【bug 记录】yolov5_C_demo 部署在 rv1126
问题1:opencv find 不到 在 CMakeLists 中将正确的 OpenCV库 路径添加到 CMAKE_PREFIX_PATH 变量中 set(CMAKE_PREFIX_PATH “/mnt/usr/local” ${CMAKE_PREFIX_PATH}) 问题2: rknn_api.h 找不到 将该文件从别处复制到项目 include 文件夹 问题3&…...

AI Agent在智能风控中的实战:多智能体欺诈检测与预警
AI Agent在智能风控中的实战:多智能体欺诈检测与预警 你有没有过明明是正常交易却被银行冻结账户的糟糕体验?或是听说过某电商平台上线新活动首日就被黑产团伙薅走数千万补贴的新闻?随着黑产欺诈向团伙化、专业化、动态化演进,传统依赖规则引擎、单模型机器学习的风控体系已…...

Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 [特殊字符]
Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 🚀 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一个基于HTML5的雪碧图生成器,它采…...

T型翼/尾板导向的穿浪双体船姿态控制【附代码】
✨ 长期致力于穿浪双体船、T型翼、尾板、多自由度姿态控制、舒适性评估研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)动态水翼升力模型与耦合运动方…...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...
)
别再用SonarQube凑数了!DeepSeek原生圈复杂度引擎的6大颠覆性能力(含GitHub私有部署密钥)
更多请点击: https://kaifayun.com 第一章:DeepSeek圈复杂度分析的底层原理与范式革命 DeepSeek圈复杂度分析并非传统McCabe度量的简单复刻,而是基于控制流图(CFG)动态重构与语义感知路径裁剪的双重机制构建的新范式。…...

Burp Suite深度解析:从流量抓包到业务逻辑漏洞挖掘
1. 这不是“学个插件”——Burp Suite 是渗透测试的呼吸系统 很多人第一次听说 Burp Suite,是在某篇“三步拿下登录框”的速成教程里:装好Java、拖进浏览器代理、点几下Repeater就弹出密码明文。结果真去测一个中型SaaS后台,不到十分钟就卡在…...

轻量化部署,异地机房快速接入,多机房管理不用再大动干戈
随着业务拓展,不少企业、单位陆续建起异地分部机房、多区域节点机房。传统资产管理系统部署复杂、对接困难,异地机房接入成本高、周期长,改造繁琐,让很多运维团队望而却步,只能继续沿用分散人工管理,资产混…...

【紧急预警】Lindy衰减临界点已提前至第8.3个月!2024最新《营销自动化寿命健康度白皮书》限时开放前500份
更多请点击: https://kaifayun.com 第一章:Lindy衰减临界点的理论重构与实证突破 Lindy效应传统上描述“越老越长寿”的非线性生存规律,但其在现代软件系统、开源生态与协议层技术栈中的适用边界正遭遇结构性挑战。本文首次将Lindy模型从静…...
)
保姆级避坑指南:在Ubuntu 22.04上搞定ROS2 Humble、PX4与Gazebo的联合仿真(附Empy版本降级)
保姆级避坑指南:Ubuntu 22.04下ROS2 Humble与PX4联合仿真的21个关键陷阱当你在Ubuntu 22.04上第一次尝试搭建ROS2 Humble、PX4与Gazebo的联合仿真环境时,可能会遇到比预期更多的挑战。这不是一个简单的"复制粘贴命令就能完成"的任务——版本冲…...
)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例) 算法研究者们常常需要借助标准测试函数来验证优化算法的性能,而CEC2017测试函数集因其复杂性和多维度的挑战性,成为评估算法鲁棒性的…...