C++位图—布隆过滤器

目录
- 位图概念
- 位图应用
- 布隆过滤器
- 简介
- 布隆过滤器的优缺点
- 布隆过滤器应用场景
- 布隆过滤器实现
- 布隆过滤器误判率分析
- 总结
位图概念

位图是一种数据结构,用于表示一组元素的存在或不存在,通常用于大规模数据集的快速查询。它基于一个位数组(或位向量),其中每个位代表一个元素,位的值表示该元素的存在或不存在。通常来说,位图中的每个元素都与一个唯一的整数索引相关联,通过这个索引来设置或检查相应的位。
位图的主要优点包括通过映射快速判断一个元素的两种状态,例如在一堆数据里面查询某一个数存不存在,这样就只需要查看这个数的映射位置判断0和1(用0和1来表示存不存在)。通常可以在常量时间内完成,因此具有非常高的查询性能。用位图来映射大量数据可以节省大量空间,因为在位图中不要用将原始数据进行存储,只需要将该数映射到某一个比特位,用这个比特位的0和1来表示这个数据的存在与否。因此对于包含大量元素的数据集,位图通常比使用其他数据结构(如哈希表)更节省内存。
但是,位图也有自己的一些限制,例如需要固定范围的整数索引,位图适用于需要表示整数范围内的元素集合,如果索引不是整数或者需要处理非常大的范围,可能不太适合。并且不支持元素的重复,每个元素在位图中只能表示存在或不存在,不能计数重复的元素。尽管如此,位图在生活的应用还是非常的广泛,位图通常用于各种应用,包括数据库管理、网络路由表、数据压缩和位集合运算等领域,它们在需要高效的集合操作时非常有用。
位图应用
当我们遇到这样一个问题,有40亿个不重复的无符号整数,并且没有排过序。现在给一个无符号整数,如何快速判断一个数是否在这40亿个数中?如果使用整形将数据进行存储然后遍历的话,那这个内存的消耗无疑是巨大的,可以粗略的计算下需要的空间,在32位系统下40亿个无符号整数大概占据160亿个字节,约等于16G。因此使用整型进行存储不是一个好的方案,这时候使用位图就会是一个很好的解决方案。
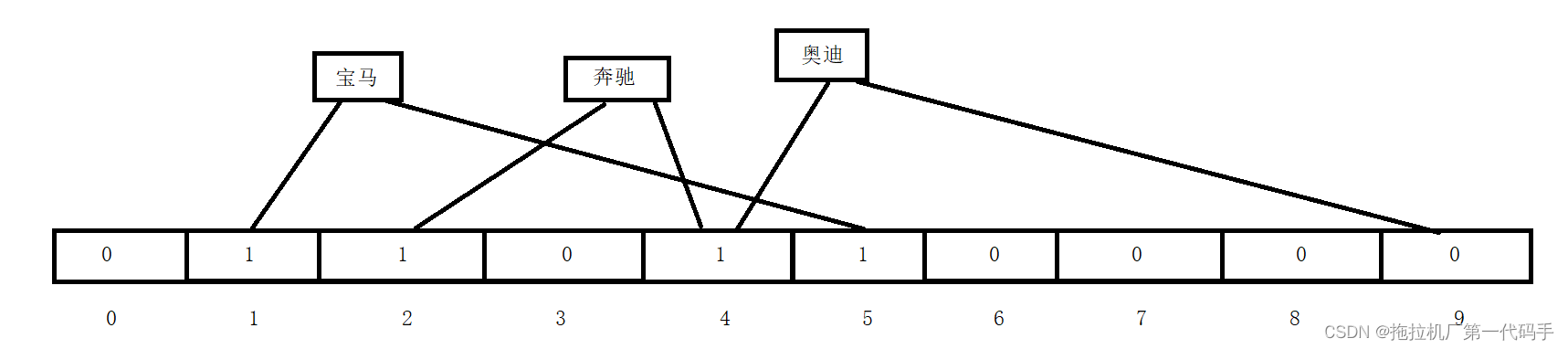
使用一个比特位的0和1来表示这个数的存在与不存在,用这个比特位的位置来映射这个数。因为一个字节有8个比特位,在32位系统下一个整型4个字节,即32个比特位,也就是一个整型可以映射32个整数,所以用位图的话只需要用大概512M的空间即可将所有数据进行映射。根据上述思路可以定义出如下的类:
template <size_t N>
class bits_set
{
public:bits_set():_bits(N / 8 + 1){}~bits_set(){}void set(size_t n){size_t i = n / 8;size_t j = n % 8;_bits[i] |= (1 << j);}void reset(size_t n){size_t i = n / 8;size_t j = n % 8;_bits[i] &= ~(1 << j);}bool test_bits(size_t n){size_t i = n / 8;size_t j = n % 8;return (_bits[i] >> j) & 1;}
private:vector<char> _bits;
};
在定义时可以给出数据范围,然后对象自己开辟出相应的空间。类中提供了3个方法,set方法是将数字映射的位置置1,表示该数字读取到了,reset方法是将数字映射位置置0,表示该数字删除掉了,test_bits方法表示检查该数字是否存在。如下测试:
bits_set<10> bits;bits.set(5);bits.set(1);bits.set(10);if (bits.test_bits(10)){cout << "存在" << endl;}else{cout << "不存在" << endl;}bits.reset(10);if (bits.test_bits(10)){cout << "存在" << endl;}else{cout << "不存在" << endl;}
如果是40亿个整数,可以直接用0xFFFFFFFF或者-1来表示,如下:
bits_set<0xFFFFFFFF> bits;
//bits_set<-1> bits;
布隆过滤器

简介
布隆过滤器(Bloom Filter)是由布隆于1970年提出的,是一种用于快速检查一个元素是否属于一个集合的概率型数据结构。它的设计初衷是为了解决数据库中的快速查找问题,特别是在大规模数据集合中判断一个元素是否存在。布隆过滤器的关键思想是使用多个哈希函数将元素映射到一个位数组中,通过多个哈希函数的多次映射,使得位数组中的多个位可能被设置为1。当查询一个元素时,同样的哈希函数会将该元素映射到相同的位上,如果所有对应的位都被设置为1,就认为元素可能存在。简单来说,布隆过滤器就是哈希和位图的有机结合。
布隆过滤器的优缺点
优点:
-
快速查询:布隆过滤器能够以常数时间复杂度进行元素的查询操作,无需遍历整个数据集合。
-
节省内存:相比于存储原始数据集合,布隆过滤器通常占用更少的内存空间,特别在处理大规模数据集合时,内存占用有显著优势。
-
高效的元素排除:它可以迅速排除大部分不可能存在的元素,减轻后续查询或操作的负担,提高系统性能。
-
保密性:布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
限制:
-
误判率:布隆过滤器具有一定的误判率,即有可能判断一个元素存在于集合中,但实际上并不存在。误判率随着哈希函数数量和位数组大小的选择有关。
-
不支持删除操作:一般情况下一旦元素被添加到布隆过滤器中,就无法从中删除。这对于需要支持删除操作的应用不适用。
-
精确性限制:它不能提供精确的元素存在性检查,只能提供概率性的结果。
-
哈希函数依赖:布隆过滤器的性能高度依赖于哈希函数的选择和质量。
总的来说,布隆过滤器在某些特定场景下是非常有用的,特别是在需要快速查询和内存效率的应用中。然而,在应用时需要谨慎考虑误判率以及不支持删除操作等限制。
布隆过滤器应用场景
因为误判率的存在,布隆过滤器适合能够容忍一些误判的场景下来使用,例如注册界面下对一些用户感知不到的并且影响不大的信息处理就可以使用布隆过滤器,例如用户昵称。
布隆过滤器可以对用户的昵称进行快速筛选,因为布隆过滤器判断不存在是不会出现误判的,判断存在才会出现误判,所以布隆过滤器在这些场景下进行快速筛选的应用是非常广泛的。例如:
-
网络爬虫,用于快速排除已经爬取的网页或URL,避免重复爬取相同内容。
-
缓存系统,用于判断某个数据是否已经在缓存中,以减少数据库或文件系统的访问次数,提高性能。
-
防止重复提交:在Web应用中,用于防止用户重复提交表单或请求。
-
垃圾邮件过滤:用于过滤垃圾邮件,快速排除已知的垃圾邮件。
-
数据库查询优化:用于快速判断一个数据库中是否存在某个记录,减少昂贵的数据库查询操作。
-
资源管理:用于管理资源池中的资源,快速判断资源是否可用。
布隆过滤器实现
因为布隆过滤器是哈希和位图的有机结合,因此可以用上述的位图代码做布隆过滤器的底层容器。除此之外还需要提供哈希函数用来计算数据的映射,如下代码:
template<size_t N, size_t X = 5, class K = string, class HashFunc1 = BKDRHash, class HashFunc2 = APHash,class HashFunc3 = DJBHash>
class BloomFilter
{
public:void set(const K& key){size_t len = X * N;size_t hash1 = HashFunc1()(key) % len;_bs.set(hash1);size_t hash2 = HashFunc2()(key) % len;_bs.set(hash2); size_t hash3 = HashFunc3()(key) % len;_bs.set(hash3);}bool test(const K& key){size_t len = X * N;size_t hash1 = HashFunc1()(key) % len;if (!_bs.test_bits(hash1)){return false;}size_t hash2 = HashFunc2()(key) % len;if (!_bs.test_bits(hash2)){return false;}size_t hash3 = HashFunc3()(key) % len;if (!_bs.test_bits(hash3)){return false;}//可能误判return true;}
private:bits_set<N * X> _bs;
};
这段代码定义了一个布隆过滤器类 BloomFilter,其中N是布隆过滤器的位数组大小。X是一个倍数,用于计算位数组的实际大小,即 X * N。K 是要插入和测试的元素的类型,默认为 string。HashFunc1、HashFunc2 和 HashFunc3 是哈希函数的类型,默认分别为 BKDRHash、APHash 和 DJBHash。
BKDRHash是一种简单的哈希函数,最初由Brian Kernighan和Dennis Ritchie提出。它的设计目标是快速计算字符串的哈希值,通常用于散列和哈希表中。BKDRHash的基本思想是将字符串中的每个字符都映射到一个32位整数,并通过一系列位运算来组合这些整数,最终得到字符串的哈希值。
struct BKDRHash
{size_t operator()(const string& s){size_t value = 0;for (auto ch : s){value *= 31;value += ch;}return value;}
};
APHash也称作Adler-32哈希,是一种非常快速的哈希函数,通常用于计算字符串的哈希值。它最初是Adler-32校验和算法的一部分,但后来被广泛用于哈希表和布隆过滤器等数据结构。APHash的核心思想是通过一系列位运算和异或操作来组合字符串的字符以生成哈希值。
struct APHash
{size_t operator()(const string& s){size_t hash = 0;for (long i = 0; i < s.size(); i++){if ((i & 1) == 0){hash ^= ((hash << 7) ^ s[i] ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ s[i] ^ (hash >> 5)));}}return hash;}
};
DJBHash是一种哈希函数,它由Daniel J. Bernstein于1991年设计。DJBHash使用了一个常数5381作为初始哈希值,然后对字符串中的每个字符进行迭代处理。对于每个字符c,哈希值通过以下公式进行更新:hash = ((hash << 5) + hash) + c。最后,返回最终的哈希值。
struct DJBHash
{size_t operator()(const string& s){size_t hash = 5381;for (auto ch : s){hash += (hash << 5) + ch;}return hash;}
};
类中的 set 函数用于将元素插入布隆过滤器,它使用三个不同的哈希函数对元素进行哈希,并将对应的位数组位置设置为 1。test 函数用于测试元素是否存在于布隆过滤器中,它同样使用三个不同的哈希函数对元素进行哈希,并检查对应的位数组位置是否为 1。如果有任何一个位置为 0,则返回 false,表示元素不在布隆过滤器中;否则,返回 true,表示元素可能存在于布隆过滤器中。(可能存在误判)bits_set<N * X> 是一个位数组,用于存储布隆过滤器的位信息。
布隆过滤器误判率分析
因为布隆过滤器的误判是不可避免的,但是可以尽量去降低误判率,为了方便查看误判率,可以写一个程序来查看,如下代码:
const size_t N = 10000;
BloomFilter<N> bf;vector<string> v1;
string url = "https://blog.csdn.net/wzh18907434168?spm=1010.2135.3001.5343";for (size_t i = 0; i < N; ++i) {v1.push_back(url + to_string(i));
}for (const auto& str : v1) {bf.set(str);
}vector<string> v2;
for (size_t i = 0; i < N; ++i) {std::string url = "https://blog.csdn.net/wzh18907434168?spm=1010.2135.3001.5343";url += to_string(999999 + i);v2.push_back(url);
}size_t n2 = 0;
for (const auto& str : v2) {if (bf.test(str)) {++n2;}
}
cout << "相似字符串误判率: " << (double)n2 / (double)N << endl;vector<string> v3;
for (size_t i = 0; i < N; ++i) {std::string url = "www.com";url += to_string(i + rand());v3.push_back(url);
}size_t n3 = 0;
for (const auto& str : v3) {if (bf.test(str)) {++n3;}
}
cout << "不相似字符串误判率: " << (double)n3 / (double)N << endl;
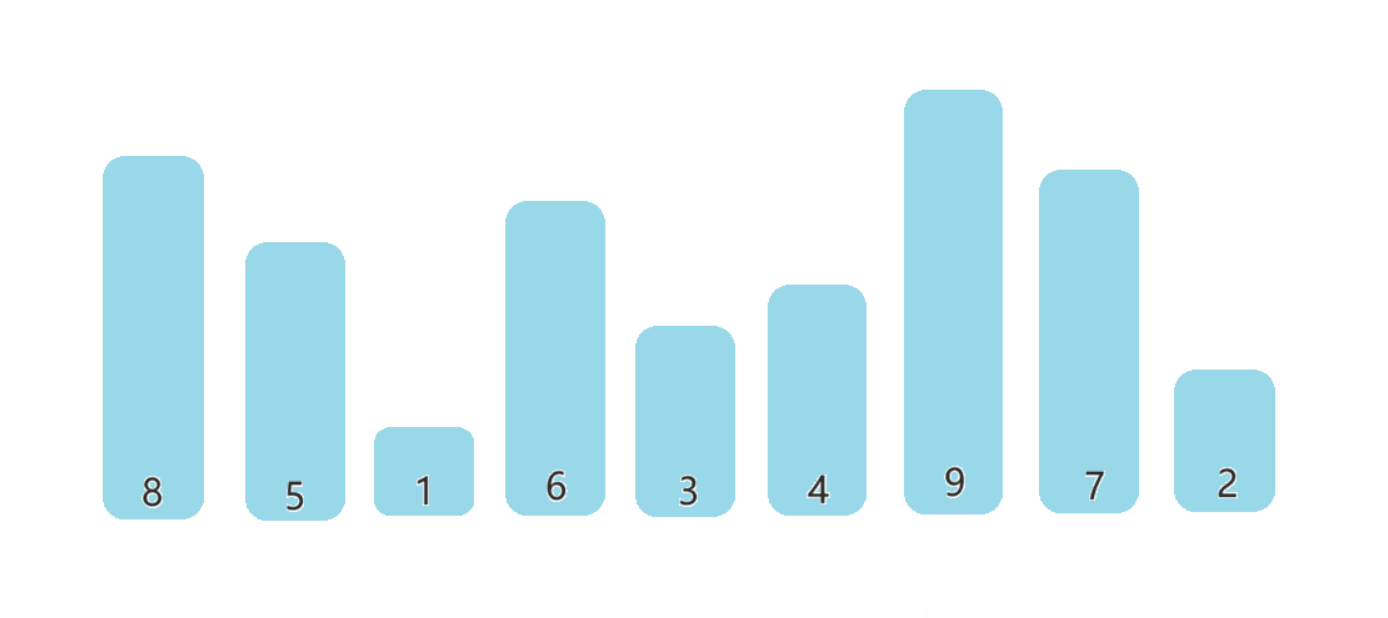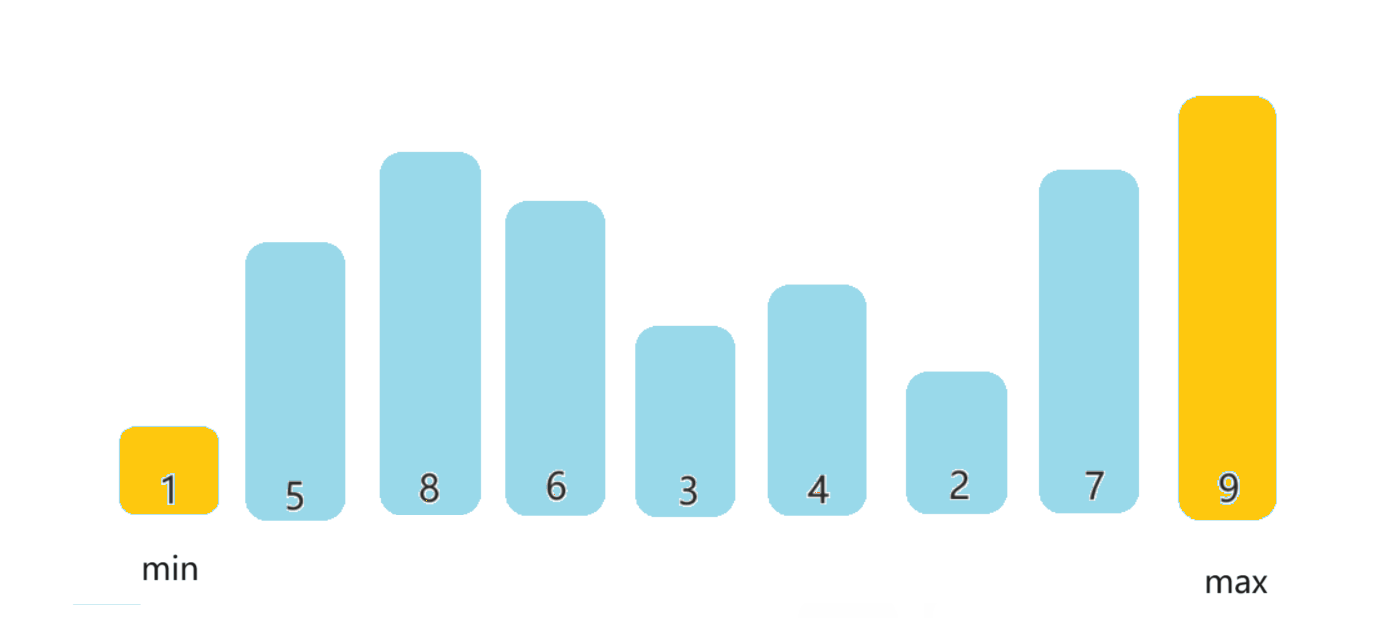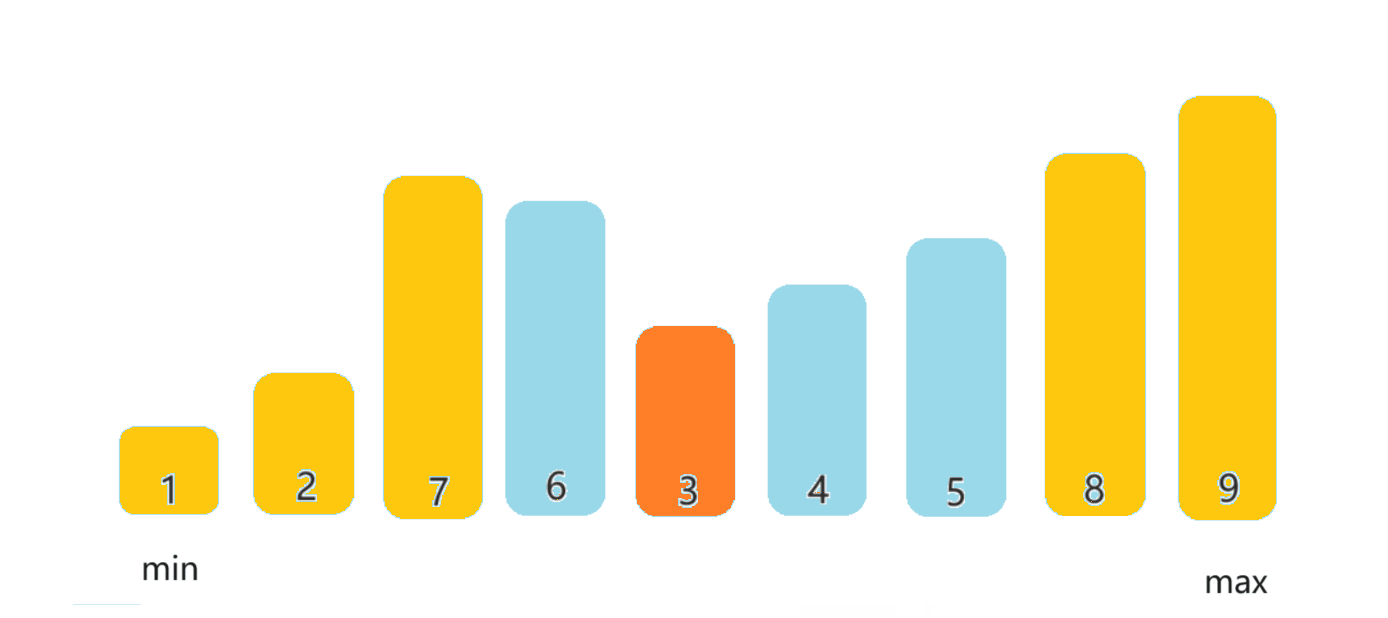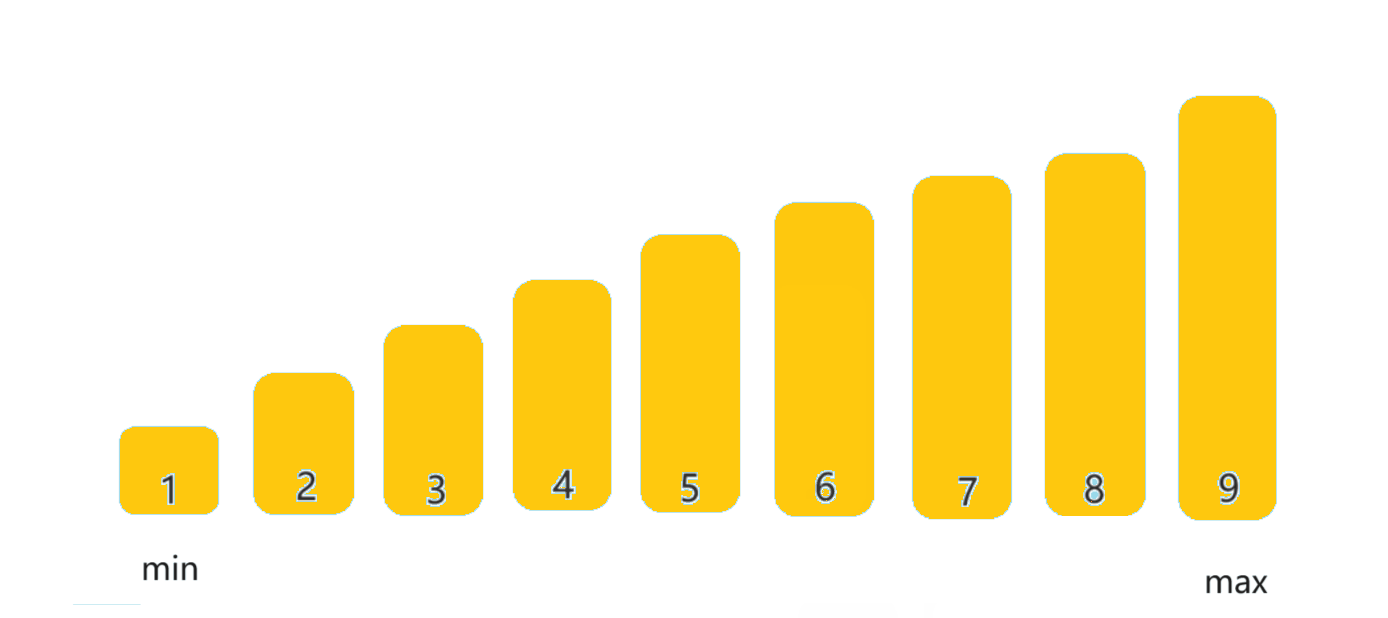
这段代码创建了一个布隆过滤器对象 bf,并进行了相似字符串集和不相似字符串集的测试。当X设置为4的时候,误判率如下:
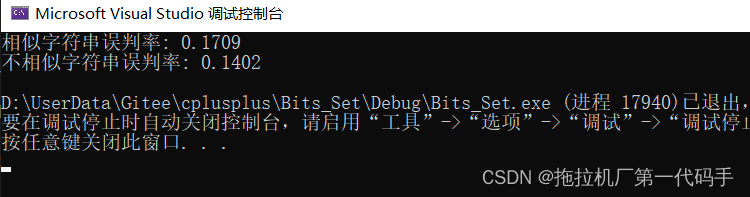
当X设置为5的时候,误判率如下:

当X设置为6的时候,误判率如下:

可以看到,当X设置的值越大误判率就越低,但也并不是X设置的越大越好,X设置的越大空间开的就越大,误判率还跟提供的哈希函数有关,具体详情可以跳转详解布隆过滤器的原理,使用场景和注意事项。
总结
文章中介绍了位图和布隆过滤器的特点,应用场景,以及实现。总的来说,位图是一种存储和处理二进制数据的高效数据结构,特别适用于需要快速集合操作和大规模数据的应用。但需要谨慎选择使用场景,因为它不适用于所有类型的数据处理需求。布隆过滤器是一种用于快速估计元素存在性的数据结构,适用于某些特定的应用场景,但需要注意其误判率和容量的控制。没有那种数据结构可以适应所有的应用场景,只有它自己适用的场景,因此,选择合适的数据结构也是非常重要的。

相关文章:
C++位图—布隆过滤器
目录 位图概念位图应用 布隆过滤器简介布隆过滤器的优缺点布隆过滤器应用场景布隆过滤器实现布隆过滤器误判率分析 总结 位图概念 位图是一种数据结构,用于表示一组元素的存在或不存在,通常用于大规模数据集的快速查询。它基于一个位数组(或位…...

SQL SELECT 语句进阶
之前探讨了SQL SELECT 语句的基础内容,包括语法、字段选择、记录限制和数据源指定。今天将进一步深入,探讨多表连接、过滤结果集和逻辑运算等高级主题,还有LIKE 模糊查询、ORDER BY 对结果集排序、运用聚合函数汇总结果以及 GROUP BY 子句与相关应用。 本文将继续使用《三国…...
Mac程序坞美化工具 uBar
uBar是一款为Mac用户设计的任务栏增强软件,它可以为您提供更高效和更个性化的任务管理体验。 以下是uBar的一些主要特点和功能: 更直观的任务管理:uBar改变了Mac上传统的任务栏设计,将所有打开的应用程序以类似于Windows任务栏的方…...
【数据结构】排序之插入排序和选择排序
🔥博客主页:小王又困了 📚系列专栏:数据结构 🌟人之为学,不日近则日退 ❤️感谢大家点赞👍收藏⭐评论✍️ 目录 一、排序的概念及其分类 📒1.1排序的概念 📒1.2排序…...

6.html表单
HTML表单(HTML form)是网页中用于收集用户输入数据的一种方式。表单由多个表单元素组成,通常包括输入框,复选框,单选按钮,下拉列表和提交按钮等。 HTML表单元素的基本结构如下: <form acti…...

【python学习第11节:numpy】
文章目录 一,numpy(上)1.1基础概念1.2数组的属性1.3数组创建1.4 类型转换1.5ndarry基础运算(上)矢量化运算1.6拷贝和视图1.6.1完全不复制1.6.2视图或浅拷贝1.6.3深拷贝 1.7索引,切片和迭代1.7.1一维数组1.7…...

Eclipse 主网即将上线迎空投预期,Zepoch 节点或成受益者?
目前,Zepoch 节点空投页面中,模块化 Layer2 Rollup 项目 Eclipse 出现在其空投列表中。 配合近期 Eclipse 宣布了其将由 SVM 提供支持的 Layer2 主网架构,并将在今年年底上线主网的消息后,不免引发两点猜测:一个是 Ecl…...
 | 输入输出)
JavaSE | 初识Java(四) | 输入输出
基本语法 System.out.println(msg); // 输出一个字符串, 带换行 System.out.print(msg); // 输出一个字符串, 不带换行 System.out.printf(format, msg); // 格式化输出 println 输出的内容自带 \n, print 不带 \n printf 的格式化输出方式和 C 语言的 printf 是基本一致的 代码…...

车牌超分辨率:License Plate Super-Resolution Using Diffusion Models
论文作者:Sawsan AlHalawani,Bilel Benjdira,Adel Ammar,Anis Koubaa,Anas M. Ali 作者单位:Prince Sultan University 论文链接:http://arxiv.org/abs/2309.12506v1 内容简介: 1)方向:图像超分辨率技术…...
如何制作在线流程图?6款在线工具帮你轻松搞定
流程图,顾名思义 —— 用视觉化的方式来描述一种过程或流程。它可以应用于各种领域,从业务流程,算法,到计算机程序等。然而,在创建流程图时,可能会遇到许多问题或者困惑,如缺乏专业的设计技能&a…...

反SSDTHOOK的另一种思路-0环实现自己的系统调用
反SSDTHOOK的另一种思路-0环实现自己的系统调用 大家都知道我们在应用层使用系统api除了gdi相关的都会走中断门或者systementer进0环然后在走ssdt表去执行0环的函数 这也就导致了ssdthook可以挡下大部分的api调用,那如果我们进0环走另外一条路线的话不通过ssdt就可…...
)
Certbot签发和续费泛域名SSL证书(通过DNS TXT记录来验证域名有效性)
我们在使用let’s encrypt获取免费的HTTPS证书的时候,let’s encrypt需要对域名进行验证,以确保域名是你自己的 之前用默认的文件验证方式总有奇怪的问题导致失败,我也是很无奈,于是改用验证DNS-TXT记录的方式来验证,而…...

PY32F003F18之RTC
一、RTC振荡器 PY32F003F18实时时钟的振荡器是内部RC振荡器,频率为32.768KHz。它也可以使用HSE时钟,不建议使用。HAL库提到LSE振荡器,但PY32F003F18实际上没有这个振荡器。 缺点:CPU掉电后,需要重新配置RTCÿ…...

redis主从从,redis-7.0.13
redis主从从,redis-7.0.13 下载redis安装redis安装redis-7.0.13过程报错1、没有gcc,报错2、没有python3,报错3、[adlist.o] 错误 127 解决安装报错安装完成 部署redis 主从从结构redis主服务器配置redis启动redis登录redisredis默认是主 redi…...

力扣-338.比特位计数
Idea 直接暴力做法:计算从0到n,每一位数的二进制中1的个数,遍历其二进制的每一位即可得到1的个数 AC Code class Solution { public:vector<int> countBits(int n) {vector<int> ans;ans.emplace_back(0);for(int i 1; i < …...
【Leetcode】 17. 电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。 给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。 示例 1: 输入:digits "23" 输出&…...
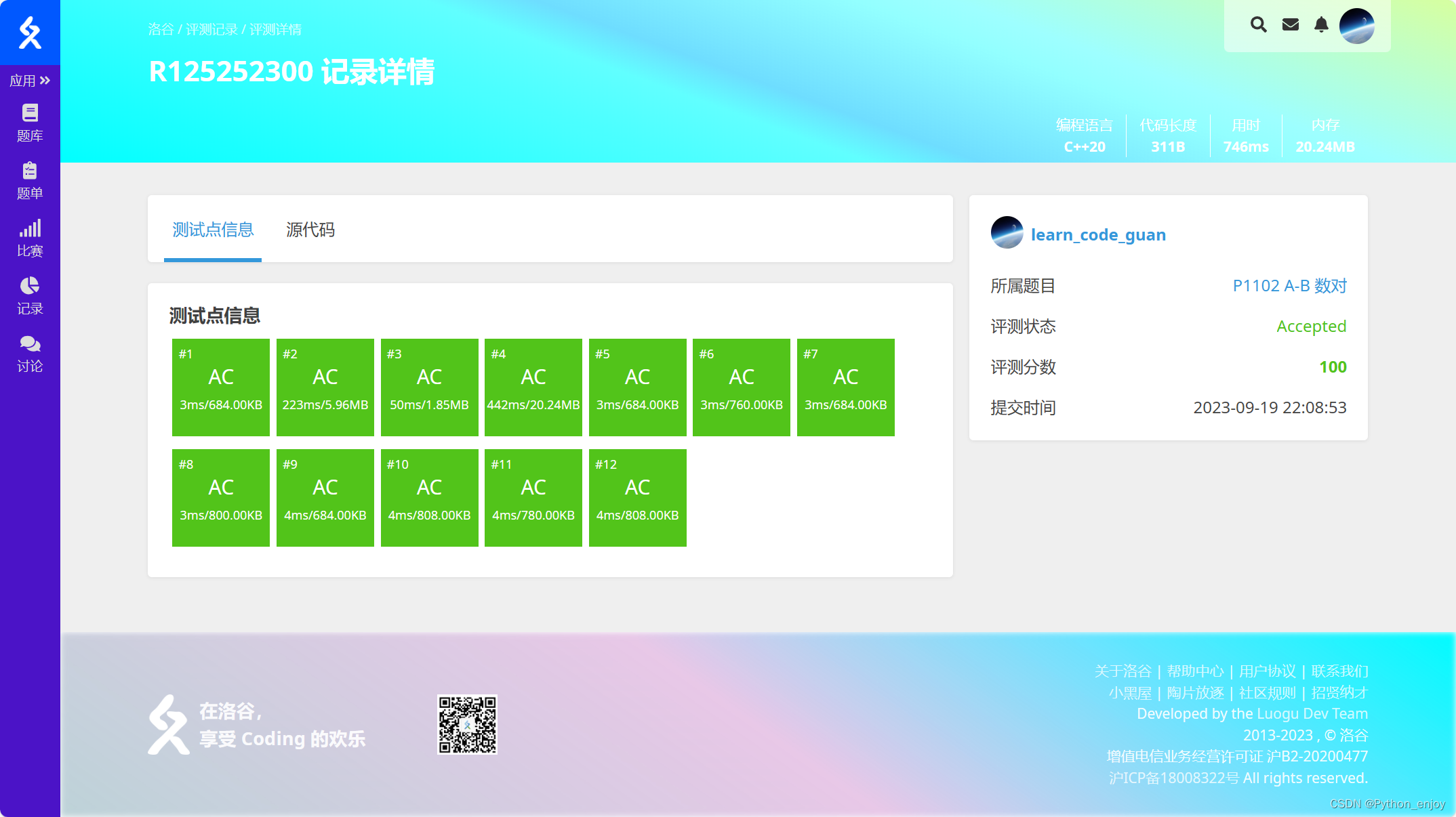
洛谷P1102 A-B 数对题解
目录 题目A-B 数对题目背景题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1提示传送门 代码解释亲测 题目 A-B 数对 题目背景 出题是一件痛苦的事情! 相同的题目看多了也会有审美疲劳,于是我舍弃了大家所熟悉的 AB Problem,改用 …...
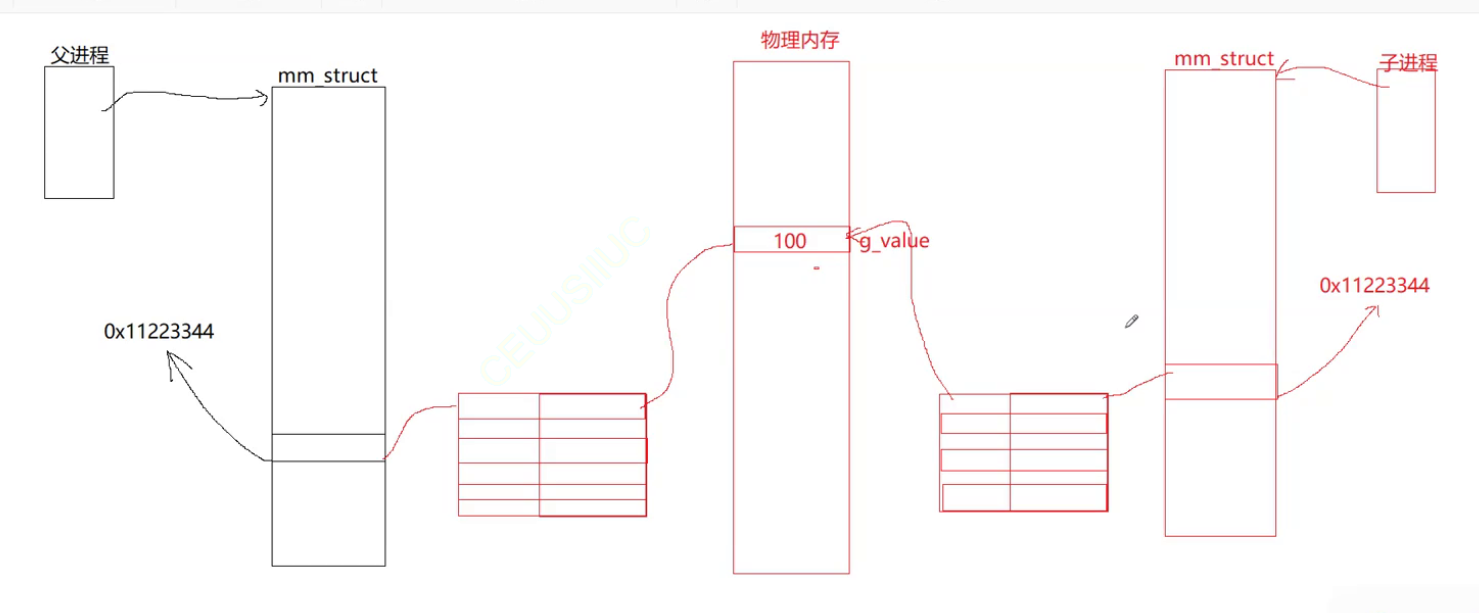
【Linux进行时】进程地址空间
进程地址空间 例子引入: 我们在讲C语言的时候,老师给大家画过这样的空间布局图,但是我们对它不了解 我们写一个代码来验证Linux进程地址空间 #include<stdio.h> #include<assert.h> #include<unistd.h> int g_value100; …...
批量将文件名称符合要求的文件自动复制到新文件夹:Python实现
本文介绍基于Python语言,读取一个文件夹,并将其中每一个子文件夹内符合名称要求的文件加以筛选,并将筛选得到的文件复制到另一个目标文件夹中的方法。 本文的需求是:现在有一个大的文件夹,其中含有多个子文件夹&#x…...
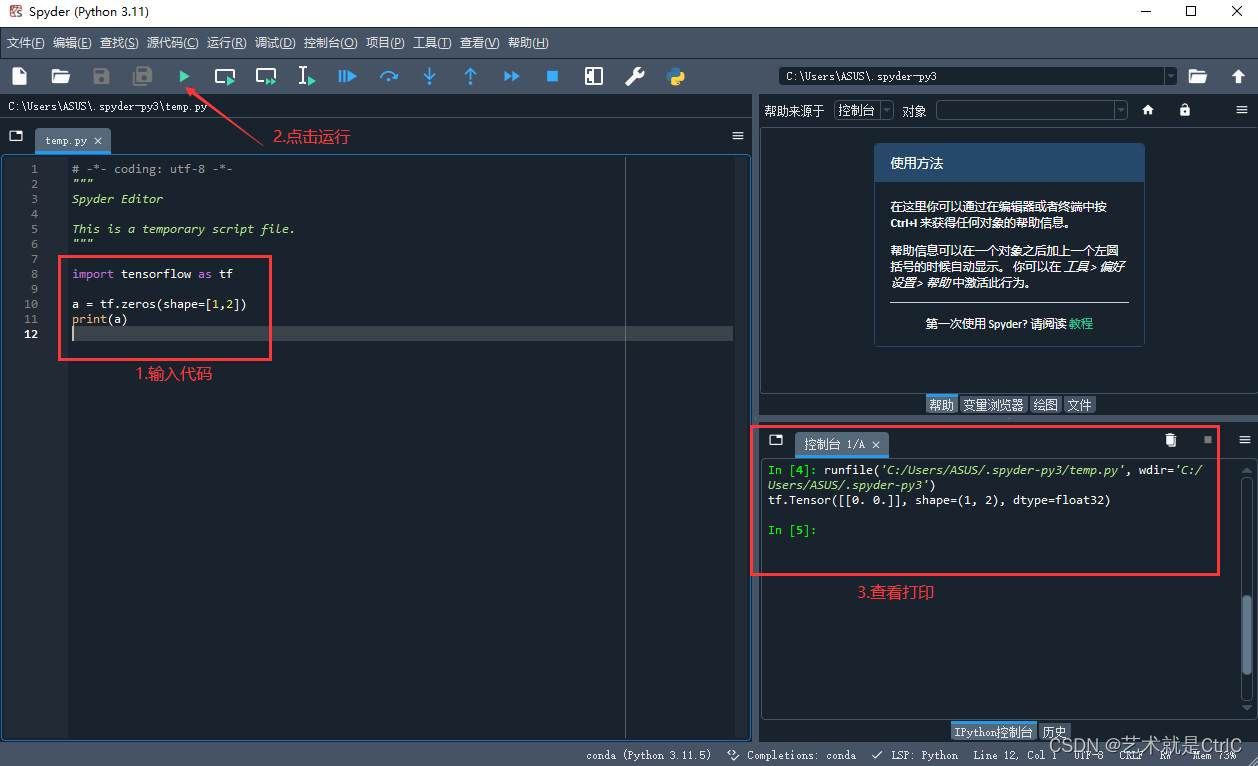
TensorFlow入门(一、环境搭建)
一、下载安装Anaconda 下载地址:http://www.anaconda.comhttp://www.anaconda.com 下载完成后运行exe进行安装 二、下载cuda 下载地址:http://developer.nvidia.com/cuda-downloadshttp://developer.nvidia.com/cuda-downloads 下载完成后运行exe进行安装 安装后winR cmd进…...

为什么我们的浏览器操作效率低下?如何用Shortkeys扩展实现3倍效率提升
为什么我们的浏览器操作效率低下?如何用Shortkeys扩展实现3倍效率提升 【免费下载链接】shortkeys A browser extension for custom keyboard shortcuts 项目地址: https://gitcode.com/gh_mirrors/sh/shortkeys 每天在浏览器上,我们花费大量时间…...
)
ComfyUI全面掌握-知识点详解——自定义节点安装与首次 AI 绘图(实操+排错)
本文为系列第 6 篇(第一章第 5 个知识点),讲解自定义节点的作用与安装方式,手把手教读者加载默认工作流、完成首次 AI 绘图,解读核心参数并排查常见问题。 目录 一、引言:自定义节点是什么?为什…...

OpenClaw Memory启动器:快速构建AI记忆系统的开源脚手架
1. 项目概述:一个为AI记忆系统设计的开源启动器最近在折腾AI应用开发,特别是那些需要长期记忆和上下文管理的项目时,发现了一个挺有意思的GitHub仓库:christiancaviedes/openclaw-memory-starter。这本质上是一个为“OpenClaw Mem…...

macOS Unlocker V3.0:在Windows/Linux电脑上运行macOS虚拟机的终极指南
macOS Unlocker V3.0:在Windows/Linux电脑上运行macOS虚拟机的终极指南 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unlo/unlocker macOS Unlocker V3.0是一款革命性的开源工具,专为VMware W…...
 的6个高阶用法,数据分析师必看)
别再只会用0填充了!Pandas DataFrame.fillna() 的6个高阶用法,数据分析师必看
别再只会用0填充了!Pandas DataFrame.fillna() 的6个高阶用法,数据分析师必看 在数据分析的日常工作中,缺失值处理就像是一道无法回避的数学题。许多刚入行的分析师会条件反射般地输入.fillna(0),这就像用创可贴处理所有伤口——有…...

模型运行记录
1753...

Claude Code 多项目 API 配置管理实践
背景 Claude Code 的项目级配置文件 .claude/settings.json 中包含 API 提供商相关的环境变量。当同时维护多个项目,每个项目使用不同的 API 提供商(Anthropic 直连、OpenRouter 代理、自建转发等)时,每次切换项目都需要手动修改…...

抖音无水印下载神器:douyin-downloader完整指南,轻松保存高清视频
抖音无水印下载神器:douyin-downloader完整指南,轻松保存高清视频 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and …...

如何将Claude Code的配置无缝迁移至Taotoken平台以解决封号困扰
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何将Claude Code的配置无缝迁移至Taotoken平台以解决封号困扰 Claude Code 作为一款高效的编程助手,其核心能力依赖于…...

BioClaw:基于自然语言对话的生物信息学智能分析平台
1. 项目概述:BioClaw,一个能聊天的生物信息学工具箱 如果你是一名生物医学领域的研究者,我猜你对下面这个场景一定不陌生:你刚拿到一批测序数据,需要先跑个FastQC看看质量;同时,实验室的师弟在…...