Mysql分库分表
1.原理




2.Sharding JDBC
官网https://shardingsphere.apache.org/

2.1 水平拆分
创建一个新的springboot项目

导入依赖,直接将原本的dependencies给覆盖掉
<dependencies><!-- ShardingJDBC依赖 --><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId><version>5.1.0</version></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.2.2</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.31</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>
</dependencies>


在本地和远端创建数据库
create database yyds;
use yyds;
create table test (`id` int primary key,`name` varchar(255) NULL,`passwd` varchar(255) NULL
);


配置两个数据源
spring:shardingsphere:datasource:# 有几个数据就配几个,这里是名称,按照下面的格式,名称+数字的形式names: db0,db1# 为每个数据源单独进行配置db0:# 数据源实现类,这里使用默认的HikariDataSourcetype: com.zaxxer.hikari.HikariDataSource# 数据库驱动driver-class-name: com.mysql.cj.jdbc.Driver# 不用我多说了吧jdbc-url: jdbc:mysql://192.168.0.8:3306/yydsusername: rootpassword: 123456db1:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://192.168.0.13:3306/yydsusername: rootpassword: 123456


添加实体类和mapper


@Data
@AllArgsConstructor
public class User {int id;String name;String passwd;
}
@Mapper
public interface UserMapper {@Select("select * from test where id = #{id}")User getUserById(int id);@Insert("insert into test(id, name, passwd) values(#{id}, #{name}, #{passwd})")上述代码都是正常业务。现在需要编写配置文件,告诉ShardingJDBC要如何进行分片。首先明确:现在是两个数据库都有test表存放用户数据,目标是将用户信息分别存放到这两个数据库的表中。
进行配置
spring:shardingsphere:rules:sharding:tables:#这里填写表名称,程序中对这张表的所有操作,都会采用下面的路由方案#比如我们上面Mybatis就是对test表进行操作,所以会走下面的路由方案test:#这里填写实际的路由节点,比如现在我们要分两个库,那么就可以把两个库都写上,以及对应的表#也可以使用表达式,比如下面的可以简写为 db$->{0..1}.testactual-data-nodes: db0.test,db1.test#这里是分库策略配置database-strategy:#这里选择标准策略,也可以配置复杂策略,基于多个键进行分片standard:#参与分片运算的字段,下面的算法会根据这里提供的字段进行运算sharding-column: id#这里填写我们下面自定义的算法名称sharding-algorithm-name: my-algsharding-algorithms:#自定义一个新的算法,名称随意my-alg:#算法类型,官方内置了很多种,这里演示最简单的一种# 取模分片算法-根据sharding-column(id)的值对2取模,结果为0存第一个库,结果为1存第二个库type: MODprops:sharding-count: 2props:#开启日志,一会方便我们观察sql-show: true



编写测试类测试

@ResourceUserMapper mapper;@Testvoid contextLoads() {for (int i = 0; i < 10; i++) {//这里ID自动生成0-9,然后插入数据库mapper.addUser(new User(i, "xxx", "ccc")); }}
这里出现注入错误,需要在启动类上加上@MapperScan(“com.example.mapper”)注解。分析日志往往在最后一句,不需要将所有报错信息都进行查找。
运行测试类后结果



这样就实现了分库策略。
实现分表策略

以本地数据库为例,创建两张表
create table test_0 (`id` int primary key,`name` varchar(255) NULL,`passwd` varchar(255) NULL
);create table test_1 (`id` int primary key,`name` varchar(255) NULL,`passwd` varchar(255) NULL
);

在分库策略基础上只修改配置文件内容
rules:sharding:tables:test:#db0.test_$->{0..1}actual-data-nodes: db0.test_0,db0.test_1#现在我们来配置一下分表策略,注意这里是table-strategy上面是database-strategytable-strategy:#基本都跟之前是一样的standard:sharding-column: idsharding-algorithm-name: my-algsharding-algorithms:my-alg:#这里我们演示一下INLINE方式,我们可以自行编写表达式来决定type: INLINEprops:#比如我们还是希望进行模2计算得到数据该去的表#只需要给一个最终的表名称就行了test_,后面的数字是表达式取模算出的#实际上这样写和MOD模式一模一样algorithm-expression: test_$->{id % 2}#没错,查询也会根据分片策略来进行,但是如果我们使用的是范围查询,那么依然会进行全量查询#这个我们后面紧接着会讲,这里先写上吧,false代表不允许全量查询allow-range-query-with-inline-sharding: falseprops:#开启日志,一会方便我们观察sql-show: true

再次测试



测试查询
@Testvoid contextLoads() {System.out.println(mapper.getUserById(0));System.out.println(mapper.getUserById(1));}

测试范围查询
@Select("select * from test where id between #{start} and #{end}")
List<User> getUsersByIdRange(int start, int end);

将配置文件的允许范围查询改为allow-range-query-with-inline-sharding改为true

测试范围查询
@Testvoid contextLoads() {System.out.println(mapper.getUsersByIdRange(3, 5));}


最终得出来的sql语句是直接对两个表都进行查询,然后求出一个并集算出来作为最后的结果。
相关文章:
Mysql分库分表
1.原理 2.Sharding JDBC 官网https://shardingsphere.apache.org/ 2.1 水平拆分 创建一个新的springboot项目 导入依赖,直接将原本的dependencies给覆盖掉 <dependencies><!-- ShardingJDBC依赖 --><dependency><groupId>org.apache.shardings…...

【算法学习】-【双指针】-【复写零】
LeetCode原题链接:1089. 复写零 下面是题目描述: 给你一个长度固定的整数数组 arr ,请你将该数组中出现的每个零都复写一遍,并将其余的元素向右平移。 注意:请不要在超过该数组长度的位置写入元素。请对输入的数组 …...

【算法优选】双指针专题——叁
文章目录 😎前言🌳[两数之和](https://leetcode.cn/problems/he-wei-sde-liang-ge-shu-zi-lcof/)🚩题目描述:🚩算法思路:🚩算法流程:🚩代码实现 🎄[三数之和]…...

Java栈的压入、弹出序列(详解)
目录 1.题目描述 2.题解 方法1 方法2 1.题目描述 输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否可能为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈序…...

RabbitMQ学习笔记(消息发布确认,死信队列,集群,交换机,持久化,生产者、消费者)
MQ(message queue):本质上是个队列,遵循FIFO原则,队列中存放的是message,是一种跨进程的通信机制,用于上下游传递消息。MQ提供“逻辑解耦物理解耦”的消息通信服务。使用了MQ之后消息发送上游只…...
PyTorch - 模型训练损失 (Loss) NaN 问题的解决方案
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/133378367 在模型训练中,如果出现 NaN 的问题,严重影响 Loss 的反传过程,因此,需要加入一些微小值…...
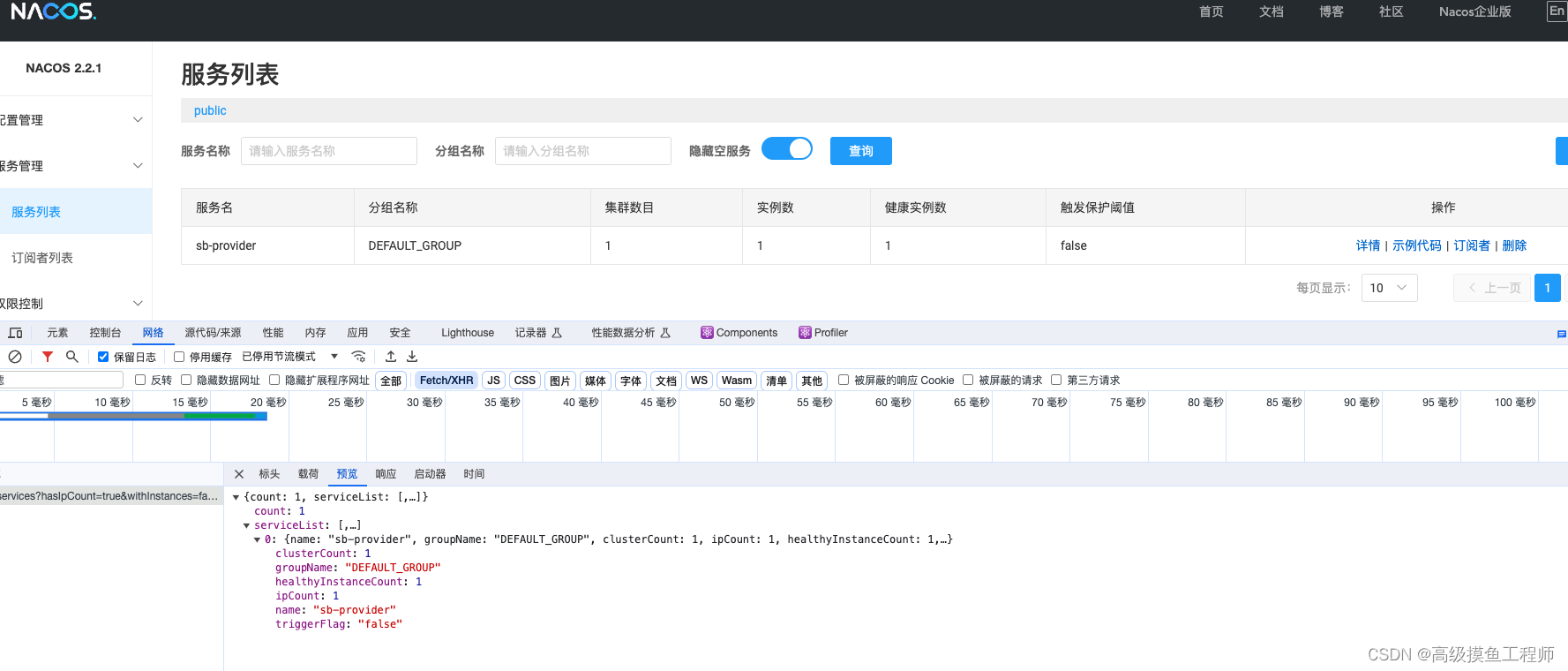
8、Nacos服务注册服务端源码分析(七)
本文收录于专栏 Nacos 中 。 文章目录 前言确定前端路由CatalogController.listDetail()ServiceManager总结 前言 前文我们分析了Nacos中客户端注册时数据分发的设计链路,本文根据Nacos前端页面请求,看下前端页面中的服务列表的数据源于哪里。 确定前端…...

MySQL使用Xtrabackup在线做主从
1、主库上操作 1.1前提 172.16.11.2(主库) 172.16.11.4(从库) 在执行备份之前,确保数据库没有锁定,以避免备份期间的任何写操作。 确保主库上的 MySQL 服务器正在运行,以便备份数据的一致性。…...
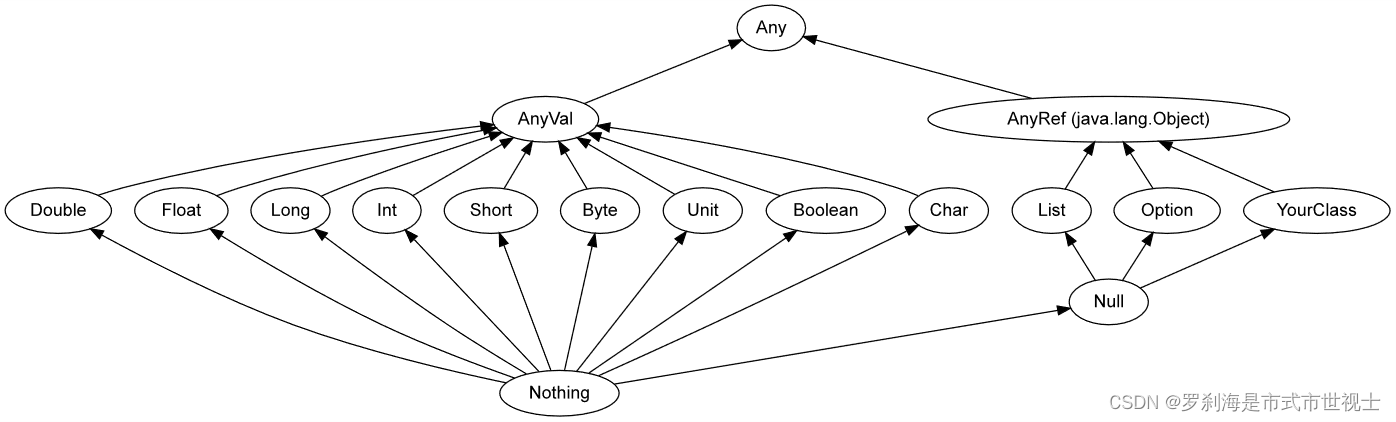
scala基础入门
一、Scala安装 下载网址:Install | The Scala Programming Language ideal安装 (1)下载安装Scala plugins (2)统一JDK环境,统一为8 (3)加载Scala (4)创建工…...

【Java-LangChain:面向开发者的提示工程-5】推断
第五章 推断 推断任务可以看作是模型接收文本作为输入,并执行某种分析的过程。其中涉及提取标签、提取实体、理解文本情感等等。如果你想要从一段文本中提取正面或负面情感,在传统的机器学习工作流程中,需要收集标签数据集、训练模型、确定如…...
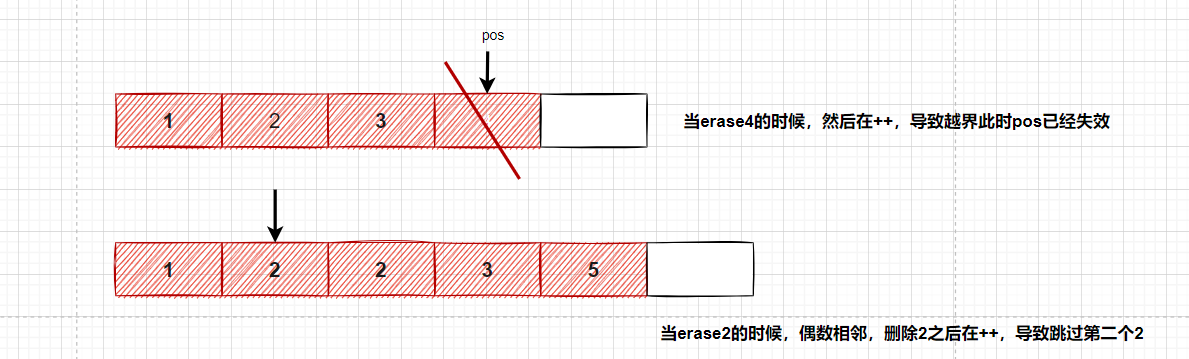
【C++】手撕vector(vector的模拟实现)
手撕vector目录: 一、基本实现思路方针 二、vector的构造函数剖析(构造歧义拷贝构造) 2.1构造函数使用的歧义问题 2.2 vector的拷贝构造和赋值重载(赋值重载不是构造哦,为了方便写在一起) 三、vector的…...

智能指针那些事
《Effective Modern C》学习笔记之条款二十一:优先选用std::make_unique和std::make_shared,而非直接new - 知乎...
Fiddler抓取手机https包的步骤
做接口测试时,有时我们需要使用fiddler进行抓包分析,那么如何抓取https包。主要分为以下七步: 1.设置fiddler选项:Tools->Options,按如下图勾选 2.下载并安装Fiddler证书生成器 下载地址:http://www.telerik.com/…...
idea没有maven工具栏解决方法
背景:接手的一些旧项目,有pom文件,但是用idea打开的时候,没有认为是maven文件,所以没有maven工具栏,不能进行重新加载pom文件中的依赖。 解决方法:选中pom.xml文件,右键 选择添加为…...
levelDB引擎
一、背景 1.1、影响磁盘性能的因素: 主要受限于磁盘的寻道时间,优化磁盘数据访问的方法是尽量减少磁盘的IO次数。磁盘数据访问效率取决于磁盘IO次数,而磁盘IO次数又取决于数据在磁盘上的组织方式。磁盘数据存储大多采用B树类型数据结构&…...

IM同步服务
设计概述 后台同步方案的设计就是数据存储结构的设计,如何快速体现“信息变化”,如何快速计算出“变化信息”。后台数据存储结构是由同步协议中同步契约决定的。 设计方案 该方案的同步是按照业务粒度来划分,只需要同步sdk要求同步的数据。…...

MySQL 运维常用脚本
常用功能脚本 1.导出整个数据库 mysqldump -u 用户名 -p –default-character-setlatin1 数据库名 > 导出的文件名(数据库默认编码是latin1) mysqldump -u wcnc -p smgp_apps_wcnc > wcnc.sql 2.导出一个表 mysqldump -u 用户名 -p 数据库名 表名> 导出的文件…...

ABC322刷题记
ABC322刷题记 T1.A A - First ABC 2。 妥妥的简单题…… 用find函数做就行。(如果不存在那个子串就返回-1,否则返回第一次出现位置) 注意题目中编号是从1开始的。 时间复杂度:O(log(n))。find函数有一定代价,我记…...
visual studio的安装及scanf报错的解决
visual studio是一款很不错的c语言编译器 下载地址:官网 点击后跳转到以下界面 下滑后点击下载Vasual Sutdio,选择社区版即可 选择位置存放下载文件后,即可开始安装 安装时会稍微等一小会儿。然后会弹出这个窗口,我们选择安装位…...

React生命周期
React的生命周期主要是指React组件从创建到销毁的过程,包括三个阶段:挂载期(实例化期)、更新期(存在期)、卸载期(销毁期) 挂载期: constructor(props&#…...

AI计算前沿:从存内计算到神经形态芯片的硬件革命
1. 从CES的喧嚣到AI研究的深水区:一次认知的转向每年一月的拉斯维加斯,消费电子展(CES)总是充斥着最炫目的灯光、最酷炫的 gadgets 和最大声的营销口号。作为一名长期跟踪半导体与系统设计的行业观察者,我和我的搭档—…...

在旧版iOS设备上部署ChatGPT客户端:逆向工程与兼容性实战
1. 项目概述:为旧版iOS设备注入AI灵魂 如果你手头还保留着一台运行iOS 6或7的iPhone 4s、iPad 2,或者任何被时代“遗忘”的旧设备,看着它们除了怀念似乎别无他用,那么今天分享的这个项目,或许能让它们重获新生。我最近…...
:无监督拓扑保持的高维数据可视化与聚类)
自组织映射(SOM):无监督拓扑保持的高维数据可视化与聚类
1. 什么是自组织映射(SOM)?它到底能帮你解决什么实际问题?我第一次在客户现场看到SOM落地,是在一家做工业设备预测性维护的公司。他们有上百台传感器,每台每秒产生十几维的振动、温度、电流数据,…...

抖音下载器终极指南:从零开始掌握无水印批量下载技巧
抖音下载器终极指南:从零开始掌握无水印批量下载技巧 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...

TongWeb实战:GBase数据库连接池的配置与性能调优指南
1. 连接池基础与TongWeb集成 第一次在TongWeb里配置GBase数据库连接池时,我犯了个低级错误——直接把最大连接数设成了1000,结果系统刚上线就崩溃了。后来才明白,连接池不是越大越好,它本质上是个数据库连接的共享停车场。想象一…...

抖音无水印视频下载终极指南:免费批量保存高清内容
抖音无水印视频下载终极指南:免费批量保存高清内容 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...

告别手动配网!用IEEE 1905.1协议实现Wi-Fi AP自动配置的保姆级流程拆解
告别手动配网!用IEEE 1905.1协议实现Wi-Fi AP自动配置的保姆级流程拆解 想象一下,当你需要为三层别墅部署全屋Wi-Fi覆盖,或是为小型办公室搭建多AP无线网络时,传统方式需要逐个登录每个AP的后台,重复输入SSID、密码、…...

一站式解决Windows程序运行问题的Visual C++运行库修复指南
一站式解决Windows程序运行问题的Visual C运行库修复指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过打开软件时突然弹窗提示"缺少msv…...

超长上下文处理能力翻倍,响应速度提升47%,API成本下降22%:Claude 3.5 Sonnet新功能落地实战手册,仅限本周内有效
更多请点击: https://intelliparadigm.com 第一章:Claude 3.5 Sonnet新功能概览与核心突破 Anthropic 正式发布的 Claude 3.5 Sonnet 在推理效率、多模态理解边界与开发者集成体验上实现了显著跃迁。相比前代,其上下文窗口稳定支持 200K tok…...

告别模拟器!3种方法在Windows上直接安装Android应用
告别模拟器!3种方法在Windows上直接安装Android应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上流畅运行Android应用,却厌…...