【Java-LangChain:面向开发者的提示工程-5】推断
第五章 推断
推断任务可以看作是模型接收文本作为输入,并执行某种分析的过程。其中涉及提取标签、提取实体、理解文本情感等等。如果你想要从一段文本中提取正面或负面情感,在传统的机器学习工作流程中,需要收集标签数据集、训练模型、确定如何在云端部署模型并进行推断。这样做可能效果还不错,但是执行全流程需要很多工作。
而且对于每个任务,如情感分析、提取实体等等,都需要训练和部署单独的模型。
LLM 的一个非常好的特点是,对于许多这样的任务,你只需要编写一个 Prompt 即可开始产出结果,而不需要进行大量的工作。这极大地加快了应用程序开发的速度。你还可以只使用一个模型和一个 API 来执行许多不同的任务,而不需要弄清楚如何训练和部署许多不同的模型。
环境配置
参考第二章的 环境配置小节内容即可。
情感推断与信息提取
情感分类
以电商平台关于一盏台灯的评论为例,可以对其传达的情感进行二分类(正向/负向)。
//评论示例private String review = "我需要一盏漂亮的卧室灯,这款灯具有额外的储物功能,价格也不算太高。\n" +"我很快就收到了它。在运输过程中,我们的灯绳断了,但是公司很乐意寄送了一个新的。\n" +"几天后就收到了。这款灯很容易组装。我发现少了一个零件,于是联系了他们的客服,他们很快就给我寄来了缺失的零件!\n" +"在我看来,Lumina 是一家非常关心顾客和产品的优秀公司!";现在让我们来编写一个 Prompt 来分类这个评论的情感。如果我想让系统告诉我这个评论的情感是什么,只需要编写 “以下产品评论的情感是什么” 这个 Prompt ,加上通常的分隔符和评论文本等等。
然后让我们运行一下。结果显示这个产品评论的情感是积极的,这似乎是非常正确的。虽然这盏台灯不完美,但这个客户似乎非常满意。这似乎是一家关心客户和产品的伟大公司,可以认为积极的情感似乎是正确的答案。
String prompt = "以下用三个反引号分隔的产品评论的情感是什么?\n" +"评论文本: ```{" + review + "}```";String message = this.getCompletion(prompt);log.info("iterative1:\n{}", message);情感是积极的。
如果你想要给出更简洁的答案,以便更容易进行后处理,可以在上述 Prompt 基础上添加另一个指令:用一个单词回答:「正面」或「负面」。这样就只会打印出 “正面” 这个单词,这使得输出更加统一,方便后续处理。
String prompt = "以下用三个反引号分隔的产品评论的情感是什么?\n" +" 用一个单词回答:「正面」或「负面」。\n" +" 评论文本: ```{" + review + "}```";String message = this.getCompletion(prompt);log.info("iterative2:\n{}", message);正面
识别情感类型
仍然使用台灯评论,我们尝试另一个 Prompt 。这次我需要模型识别出评论作者所表达的情感,并归纳为列表,不超过五项。
String prompt = "识别以下评论的作者表达的情感。包含不超过五个项目。将答案格式化为以逗号分隔的单词列表。\n" +" 评论文本: ```{" + review + "}```";String message = this.getCompletion(prompt);log.info("iterative3:\n{}", message);满意,感激,积极,赞赏,信任
大型语言模型非常擅长从一段文本中提取特定的东西。在上面的例子中,评论所表达的情感有助于了解客户如何看待特定的产品.
识别愤怒
对于很多企业来说,了解某个顾客是否非常生气很重要。所以产生了下述分类问题:以下评论的作者是否表达了愤怒情绪?因为如果有人真的很生气,那么可能值得额外关注,让客户支持或客户成功团队联系客户以了解情况,并为客户解决问题。
String prompt = "以下评论的作者是否表达了愤怒?评论用三个反引号分隔。给出是或否的答案。\n" +" 评论文本: ```{" + review + "}```";String message = this.getCompletion(prompt);log.info("iterative4:\n{}", message);否
上面这个例子中,客户并没有生气。注意,如果使用常规的监督学习,如果想要建立所有这些分类器,不可能在几分钟内就做到这一点。我们鼓励大家尝试更改一些这样的 Prompt ,也许询问客户是否表达了喜悦,
或者询问是否有任何遗漏的部分,并看看是否可以让 Prompt 对这个灯具评论做出不同的推论。
商品信息提取
接下来,让我们从客户评论中提取更丰富的信息。信息提取是自然语言处理(NLP)的一部分,与从文本中提取你想要知道的某些事物相关。因此,在这个 Prompt 中,我要求它识别以下内容:购买物品和制造物品的公司名称。
同样,如果你试图总结在线购物电子商务网站的许多评论,对于这些评论来说,弄清楚是什么物品、谁制造了该物品,弄清楚积极和消极的情感,有助于追踪特定物品或制造商收获的用户情感趋势。
在下面这个示例中,我们要求它将响应格式化为一个 JSON 对象,其中物品和品牌作为键。
String prompt = "从评论文本中识别以下项目:\n" +" - 评论者购买的物品\n" +" - 制造该物品的公司\n" +" 评论文本用三个反引号分隔。将你的响应格式化为以 “物品” 和 “品牌” 为键的 JSON 对象。\n" +" 如果信息不存在,请使用 “未知” 作为值。\n" +" 让你的回应尽可能简短。\n" +" 评论文本: ```{" + review + "}```";String message = this.getCompletion(prompt);log.info("iterative5:\n{}", message);
{"物品": "卧室灯","品牌": "Lumina"
}
如上所示,它会说这个物品是一个卧室灯,品牌是 Luminar.
综合完成任务
提取上述所有信息使用了 3 或 4 个 Prompt ,但实际上可以编写单个 Prompt 来同时提取所有这些信息。
String prompt = "从评论文本中识别以下项目:\n" +"- 情绪(正面或负面)\n" +"- 审稿人是否表达了愤怒?(是或否)\n" +"- 评论者购买的物品\n" +"- 制造该物品的公司\n" +"评论用三个反引号分隔。将您的响应格式化为 JSON 对象,以 “Sentiment”、“Anger”、“Item” 和 “Brand” 作为键。\n" +"如果信息不存在,请使用 “未知” 作为值。\n" +"让你的回应尽可能简短。\n" +"将 Anger 值格式化为布尔值。\n" +"评论文本: ```{" + review + "}```";String message = this.getCompletion(prompt);log.info("iterative6:\n{}", message);
{"Sentiment": "正面","Anger": false,"Item": "卧室灯","Brand": "Lumina"
}
这个例子中,我们告诉它将愤怒值格式化为布尔值,然后输出一个 JSON。您可以自己尝试不同的变化,或者甚至尝试完全不同的评论,看看是否仍然可以准确地提取这些内容。
主题推断
大型语言模型的另一个很酷的应用是推断主题。给定一段长文本,这段文本是关于什么的?有什么话题?以以下一段虚构的报纸报道为例。
推断讨论主题
上面是一篇虚构的关于政府工作人员对他们工作机构感受的报纸文章。我们可以让它确定五个正在讨论的主题,用一两个字描述每个主题,并将输出格式化为逗号分隔的列表。
String prompt = "确定以下给定文本中讨论的五个主题。\n" +"每个主题用1-2个单词概括。\n" +"输出时用逗号分割每个主题。\n" +"给定文本: ```{" + story + "}```";String message = this.getCompletion(prompt);log.info("iterative7:\n{}", message);主题1: NASA满意度高
主题2: 社会保障管理局满意度低
主题3: NASA员工对工作感到自豪
主题4: 政府承诺解决员工问题
主题5: 政府努力提高工作满意度
为特定主题制作新闻提醒
假设我们有一个新闻网站或类似的东西,这是我们感兴趣的主题:NASA、地方政府、工程、员工满意度、联邦政府等。假设我们想弄清楚,针对一篇新闻文章,其中涵盖了哪些主题。
可以使用这样的prompt:确定以下主题列表中的每个项目是否是以下文本中的主题。以 0 或 1 的形式给出答案列表。
String prompt = "判断主题列表中的每一项是否是给定文本中的一个话题,\n" +" 以列表的形式给出答案,每个主题用 0 或 1。\n" +" 主题列表:美国航空航天局、当地政府、工程、员工满意度、联邦政府\n" +" 给定文本: ```{" + story + "}```";String message = this.getCompletion(prompt);log.info("iterative9:\n{}", message);
[1, 0, 0, 1, 0]
有结果可见,这个故事是与关于 NASA 、员工满意度、联邦政府有关,而与当地政府的、工程学无关。这在机器学习中有时被称为 Zero-Shot (零样本)学习算法,因为我们没有给它任何标记的训练数据。仅凭 Prompt ,它就能确定哪些主题在新闻文章中有所涵盖。
这就是关于推断的全部内容了,仅用几分钟时间,我们就可以构建多个用于对文本进行推理的系统,而以前则需要熟练的机器学习开发人员数天甚至数周的时间。这非常令人兴奋,无论是对于熟练的机器学习开发人员,还是对于新手来说,都可以使用 Prompt 来非常快速地构建和开始相当复杂的自然语言处理任务。
相关文章:

【Java-LangChain:面向开发者的提示工程-5】推断
第五章 推断 推断任务可以看作是模型接收文本作为输入,并执行某种分析的过程。其中涉及提取标签、提取实体、理解文本情感等等。如果你想要从一段文本中提取正面或负面情感,在传统的机器学习工作流程中,需要收集标签数据集、训练模型、确定如…...
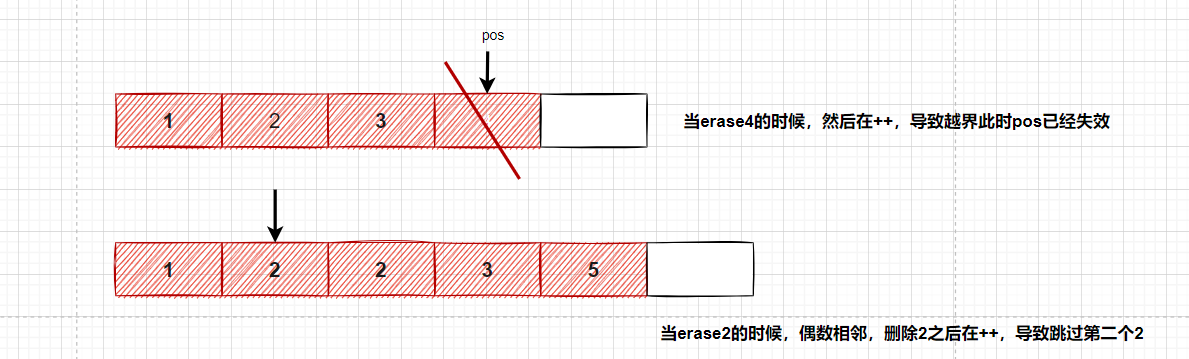
【C++】手撕vector(vector的模拟实现)
手撕vector目录: 一、基本实现思路方针 二、vector的构造函数剖析(构造歧义拷贝构造) 2.1构造函数使用的歧义问题 2.2 vector的拷贝构造和赋值重载(赋值重载不是构造哦,为了方便写在一起) 三、vector的…...

智能指针那些事
《Effective Modern C》学习笔记之条款二十一:优先选用std::make_unique和std::make_shared,而非直接new - 知乎...
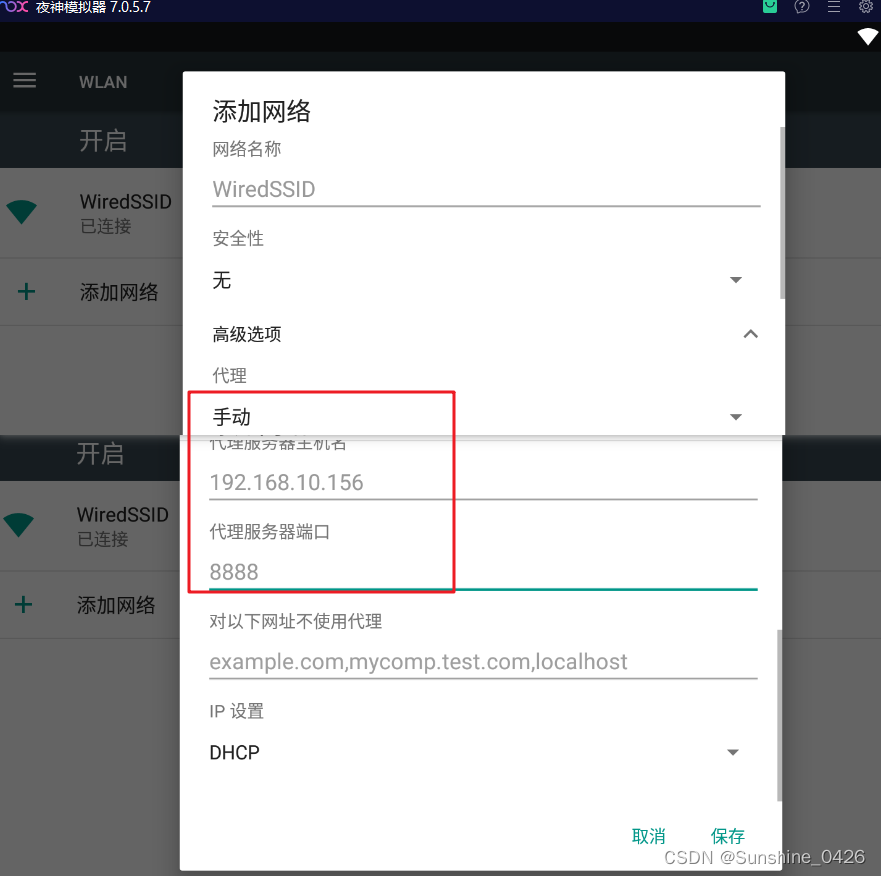
Fiddler抓取手机https包的步骤
做接口测试时,有时我们需要使用fiddler进行抓包分析,那么如何抓取https包。主要分为以下七步: 1.设置fiddler选项:Tools->Options,按如下图勾选 2.下载并安装Fiddler证书生成器 下载地址:http://www.telerik.com/…...
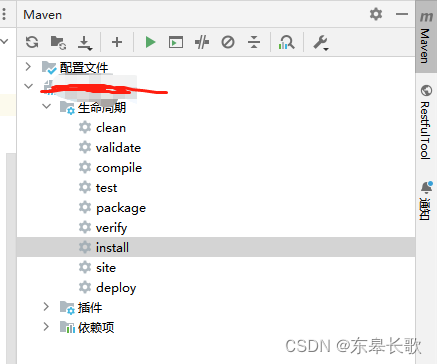
idea没有maven工具栏解决方法
背景:接手的一些旧项目,有pom文件,但是用idea打开的时候,没有认为是maven文件,所以没有maven工具栏,不能进行重新加载pom文件中的依赖。 解决方法:选中pom.xml文件,右键 选择添加为…...
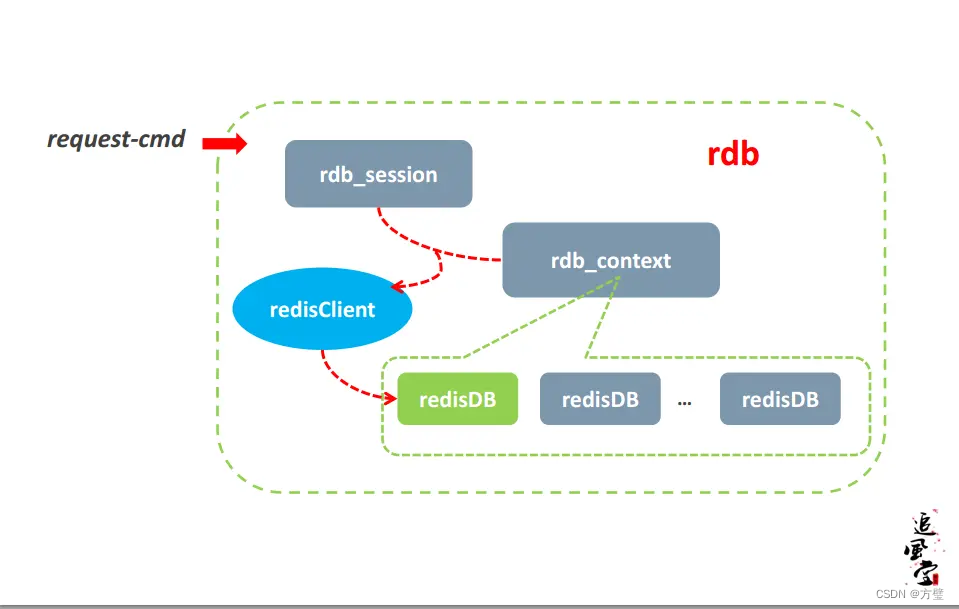
levelDB引擎
一、背景 1.1、影响磁盘性能的因素: 主要受限于磁盘的寻道时间,优化磁盘数据访问的方法是尽量减少磁盘的IO次数。磁盘数据访问效率取决于磁盘IO次数,而磁盘IO次数又取决于数据在磁盘上的组织方式。磁盘数据存储大多采用B树类型数据结构&…...

IM同步服务
设计概述 后台同步方案的设计就是数据存储结构的设计,如何快速体现“信息变化”,如何快速计算出“变化信息”。后台数据存储结构是由同步协议中同步契约决定的。 设计方案 该方案的同步是按照业务粒度来划分,只需要同步sdk要求同步的数据。…...

MySQL 运维常用脚本
常用功能脚本 1.导出整个数据库 mysqldump -u 用户名 -p –default-character-setlatin1 数据库名 > 导出的文件名(数据库默认编码是latin1) mysqldump -u wcnc -p smgp_apps_wcnc > wcnc.sql 2.导出一个表 mysqldump -u 用户名 -p 数据库名 表名> 导出的文件…...

ABC322刷题记
ABC322刷题记 T1.A A - First ABC 2。 妥妥的简单题…… 用find函数做就行。(如果不存在那个子串就返回-1,否则返回第一次出现位置) 注意题目中编号是从1开始的。 时间复杂度:O(log(n))。find函数有一定代价,我记…...
visual studio的安装及scanf报错的解决
visual studio是一款很不错的c语言编译器 下载地址:官网 点击后跳转到以下界面 下滑后点击下载Vasual Sutdio,选择社区版即可 选择位置存放下载文件后,即可开始安装 安装时会稍微等一小会儿。然后会弹出这个窗口,我们选择安装位…...

React生命周期
React的生命周期主要是指React组件从创建到销毁的过程,包括三个阶段:挂载期(实例化期)、更新期(存在期)、卸载期(销毁期) 挂载期: constructor(props&#…...
SpringBoot整合RocketMQ笔记
SpringBoot版本为2.3.12.Release RocketMQ对比kafka 学习链接 https://zhuanlan.zhihu.com/p/335216381 代码实战 https://www.cnblogs.com/RedOrange/p/17401238.html Centos安装rocketmq https://blog.csdn.net/chuige2013/article/details/123783612 RocketMQ详细配置与…...
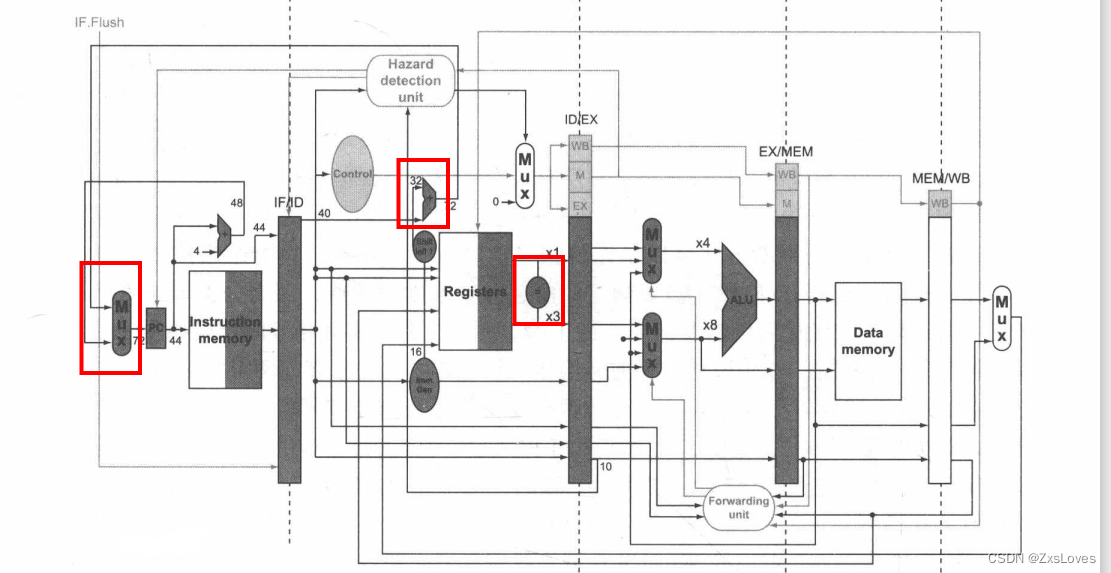
【【萌新的RiscV学习之在写代码之前对于关键路径的分析-11】】
萌新的RiscV学习之在写代码之前对于关键路径的分析-11 首先我们最简单的control 模块 全分段 因为只有分段 , 分开使用之后 , 各个阶段的具体功能才会合理使用 就像是为了后续 “气泡” 赋值 为 0 还有单独比较前递这种 EX : ALUOP ALUSrc …...

A. Sequence with Digits
题目:样例: 输入 8 1 4 487 1 487 2 487 3 487 4 487 5 487 6 487 7输出 42 487 519 528 544 564 588 628 思路: 暴力模拟题,看这数据范围,有些人可能会被唬住,以为是高精度或者容易超时,实际上…...

gitlab配置webhook限制提交注释
一、打开gitlab相关配置项 vim /etc/gitlab/gitlab.rb gitlab_shell[custom_hooks_dir] "/etc/gitlab/custom_hooks" 二、创建相关文件夹 mkdir -p /etc/gitlab/custom_hooks mkdir -p /etc/gitlab/custom_hooks/post-receive.d mkdir -p /etc/gitlab/custom_h…...

蓝桥杯Python scratch C++选拔赛stema个人如何报名?
如果不会操作,可以微信makytony协助。...

Cesium实现动态旋转四棱锥(2023.9.11)
Cesium实现动态悬浮旋转四棱锥效果 2023.9.11 1、引言2、两种实现思路介绍2.1 思路一:添加已有的四棱锥(金字塔)模型实现(简单但受限)2.2 思路二:自定义四棱锥几何模型实现(复杂且灵活ÿ…...
2023最新PS(photoshop)Win+Mac免费下载安装包及教程内置AI绘画-网盘下载
2023最新PS(photoshop)WinMac免费下载安装包及教程内置AI绘画-网盘下载 2023最新PS(photoshop)免费下载安装教程来咯~ 「PhotoShop」全套,winmac: https://pan.quark.cn/s/9d8d8ef5c400#/list/share 所有版本都有 1,复制链接…...

【JAVA】为什么要使用封装以及如何封装
个人主页:【😊个人主页】 系列专栏:【❤️初识JAVA】 前言 Java的封装指的是在一个类中将数据和方法进行封装,使其可以保护起来,只能在该类内部访问,而不允许外部直接访问和修改。这是Java面向对象编程的三…...
18.示例程序(编码器接口测速)
STM32标准库开发-各章节笔记-查阅传送门_Archie_IT的博客-CSDN博客https://blog.csdn.net/m0_61712829/article/details/132434192?spm1001.2014.3001.5501 main.c #include "stm32f10x.h" // Device header #include "Delay.h" #incl…...

弯曲波触觉反馈技术:为触摸屏注入真实按键手感的工程实践
1. 项目概述:当触摸屏需要“手感”在2012年,如果你告诉一个家电设计师,未来的微波炉、冰箱或烤箱面板将是一块完全平整、没有任何物理凸起的玻璃或塑料板,他可能会皱起眉头。因为这意味着用户将失去最直接的交互反馈——那个“咔哒…...
—— 提前终止 + 参数共享 + 稀疏表示(三十))
深度学习正则化(三)—— 提前终止 + 参数共享 + 稀疏表示(三十)
1. 定位导航 正则化 5 篇中,本篇承前启后: 第 28:参数范数惩罚(L1/L2)— 加在损失函数上 第 29:数据增强、噪声、半监督 — 操作数据 第 30(本篇):提前终止、参数共享、稀疏表示 — 隐式正则化 第 31:Bagging + Dropout 第 32:对抗训练 + 切面分类 本篇的三个方法表…...

从单场到多场并发:知识竞赛平台的弹性扩展能力
🚀 从单场到多场并发:知识竞赛平台的弹性扩展能力动态调度 平滑扩容 稳定支撑📌 演进中的需求:从单一活动到复杂场景传统的知识竞赛活动往往以单场、线下或小规模在线形式进行,对技术平台的压力相对有限。然而&#…...

渗透PHP伪协议
一、debug调试 1、定义 Debug,又叫断点调试,就是对写好的程序进行逐步运行、分解、调试的过程,通过这个过程,我们可以跟踪程序的详细运行过程, 是程序员的开发神器,也是开发必会的一个重要技能。 2、意义…...

AI信息摘要系统:从RSS抓取到LLM摘要的自动化实现
1. 项目概述:AI驱动的每日信息摘要最近在GitHub上看到一个挺有意思的项目,叫“ai-daily-digest”。光看名字,你大概能猜到它想做什么:用人工智能来帮你整理每日信息。但具体怎么实现,能解决什么问题,背后又…...

Azure OpenAI代理:无缝迁移OpenAI应用到Azure云服务
1. 项目概述如果你正在使用或开发基于OpenAI官方API的应用,比如各种ChatGPT Web UI、LangChain应用,但同时又想利用微软Azure OpenAI Service在合规性、稳定性、网络延迟或成本控制上的优势,那么你大概率会遇到一个头疼的问题:这两…...

从灰度图到粉彩叙事,全程可复现:5个精准Prompt模板+3类LUT预设,零基础速产美术馆级Pastel印相
更多请点击: https://intelliparadigm.com 第一章:从灰度图到粉彩叙事:Pastel印相的美学本质与技术边界 Pastel印相并非简单的色彩叠加,而是一种基于人眼感知非线性响应与胶片化学特性的数字模拟范式。其核心在于将灰度图像的亮度…...

游戏开发资源宝库:从计算机图形学到Unity生态的全栈知识索引
1. 项目概述:一份游戏开发者的“藏宝图”如果你是一名游戏开发者,无论是刚入行的新人,还是摸爬滚打多年的老兵,大概都经历过这样的时刻:为了实现一个特定的效果,或是解决一个棘手的技术难题,在搜…...

AI助手碳核算技能:基于MCP协议与CCDB数据库的实战指南
1. 项目概述:当AI助手学会“碳核算” 如果你是一名开发者、数据分析师,或者任何需要处理碳排放相关工作的从业者,最近可能被一个词频繁刷屏:AI Agent。我们总希望手边的AI编程助手(比如Cursor、Claude Code࿰…...

从零构建Telegram天气机器人:Python异步编程与API集成实战
1. 项目概述:一个能聊天的天气机器人 如果你用过Telegram,大概率会见过或者用过一些机器人。它们能帮你查新闻、翻译、管理任务,甚至陪你聊天。今天要聊的这个项目, imkarimkarim/Telegram-Weather-Bot ,就是一个典型…...