深入探讨 Presto 中的缓存
【squids.cn】 全网zui低价RDS,免费的迁移工具DBMotion、数据库备份工具DBTwin、SQL开发工具等
Presto是一种流行的开源分布式SQL引擎,使组织能够在多个数据源上大规模运行交互式分析查询。缓存是一种典型的提高 Presto 查询性能的优化技术。它为 Presto 平台提供了显着的性能和效率改进。
缓存通过将频繁访问的数据存储在内存或快速本地存储中,避免了昂贵的磁盘或网络行程来重新获取数据,从而加快了整体查询的执行速度。在本文中,我们将深入探讨 Presto 的缓存机制以及如何使用它们来提高查询速度并降低成本。
缓存的好处
缓存提供了三个关键优势。通过在 Presto 中实施缓存,您可以:
-
提高查询性能。缓存频繁访问的数据使 Presto 能够从更快、更近的缓存中检索结果,而不是扫描速度较慢的存储。对于重复的分析查询,这可以将查询速度提高几个数量级,从而减少总体延迟。通过加速查询执行,缓存可实现交互式查询和更快的洞察时间。
-
降低基础设施成本。缓存减少了从 S3 等远程存储系统读取的数据量,从而降低了出口费用和存储 API 请求的费用。对于存储在云中的数据,缓存可以最大限度地减少通过网络重复检索数据。这可以节省大量成本,尤其是对于大型数据集。
-
最大限度地减少网络开销。通过减少 Presto 组件和远程存储之间不必要的数据传输,缓存可以缓解网络拥塞。本地缓存可防止分布式 Presto 工作线程之间的网络链接出现瓶颈。它还减少了与外部数据源连接的负载和带宽使用。
总体而言,缓存可以提高 Presto 查询的性能和效率,为基于 Presto 的分析平台提供巨大的价值和投资回报率。
Presto 中不同类型的缓存
Presto中有两种类型的缓存,内置缓存和第三方缓存。内置缓存包括Metastore缓存、文件列表缓存和Alluxio SDK缓存。它使用 Presto 集群的内存和 SSD 资源,与 Presto 在同一进程中运行,以获得最佳性能。
内置缓存的主要优点是延迟非常低并且没有网络开销,因为数据在 Presto 集群中本地缓存。然而,内置缓存容量受到工作节点资源的限制。
第三方缓存,例如Alluxio分布式缓存,可以独立部署,并提供更好的可扩展性和更大的缓存容量。它们对于大规模分析工作负载、跨区域/云部署以及降低云存储的 API 和出口成本特别有利。
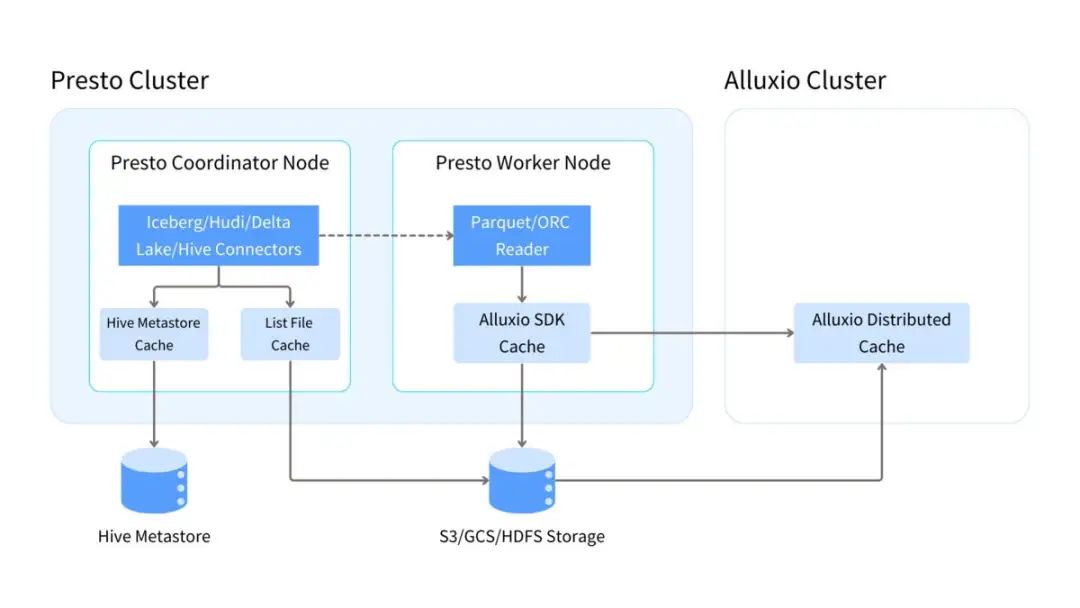
上图和下表总结了不同的缓存类型及其相应的资源类型和位置。
| 缓存类型 | 缓存位置 | 资源类型 |
| 元存储缓存 | Presto协调器 | 内存 |
| 列出文件缓存 | Presto协调器 | 内存 |
| Alluxio SDK缓存 | Presto工作节点 | 内存/SSD |
| Alluxio分布式缓存 | Alluxio工作节点 | 内存/SSD/HDD |
Presto的缓存默认都是禁用的。您需要修改Presto的配置来激活它们。我们将在接下来的部分更详细地解释不同的缓存类型以及如何通过配置属性启用它们。
元存储缓存
Presto 的元存储缓存将 Hive 元存储查询结果存储在内存中,以便更快地访问。这减少了规划时间和元存储请求。
当 Hive 元存储过载时,元存储缓存非常有用。对于大型分区表,缓存将分区元数据存储在本地,从而实现更快的访问和更少的重复查询。这减少了 Hive 元存储上的总体负载。
要启用元存储缓存,请使用以下设置:
hive.partition-versioning-enabled=truehive.metastore-cache-scope=ALLhive.metastore-cache-ttl=1dhive.metastore-refresh-interval=1dhive.metastore-cache-maximum-size=10000000
请注意,如果表频繁更新,您应该为元存储版本化缓存配置较短的 TTL 或刷新间隔。较短的缓存刷新间隔可确保仅存储当前元数据,从而降低查询执行中元数据过时的风险。这可以防止 Presto 使用过时的数据。
列出文件状态缓存
列表文件缓存存储文件路径和属性,以避免从名称节点或对象存储中重复检索。
当 HDFS namenode 过载或对象存储的文件列表性能较差时,列表文件缓存可显着改善查询延迟。列表文件调用可能会成为 HDFS 的瓶颈,使名称节点不堪重负,并增加 S3 存储的成本。启用列表文件状态缓存后,Presto 协调器会在内存中缓存文件列表,以便更快地访问常用数据,从而减少冗长的远程 listFile 调用。
要配置列表文件状态缓存,请使用以下设置:
hive.file-status-cache-expire-time=1hhive.file-status-cache-size=10000000hive.file-status-cache-tables=*
请注意,列表文件状态缓存只能应用于密封目录,因为 Presto 会跳过缓存开放分区以确保数据新鲜度。
Alluxio SDK缓存(原生)
Alluxio SDK缓存是Presto内置的缓存,用于减少表扫描的延迟。由于Presto是一个与存储无关的引擎,因此其性能经常受到存储的限制。在Presto工作节点的SSD上本地缓存数据可以实现快速的查询访问和执行。通过最小化重复的网络请求,Alluxio缓存还降低了对远程数据的云出口费用和存储API成本。
Alluxio SDK缓存对于查询远程数据特别有益,如跨区域或混合云对象存储。这大大减少了查询延迟以及相关的云存储出口费用和API成本。
使用以下设置启用Alluxio SDK缓存:
cache.enabled=truecache.type=ALLUXIOcache.base-directory=file:///tmp/alluxiocache.alluxio.max-cache-size=100MB
为了达到最好的缓存命中率,将节点选择策略改为软亲和性:
hive.node-selection-strategy=SOFT_AFFINITY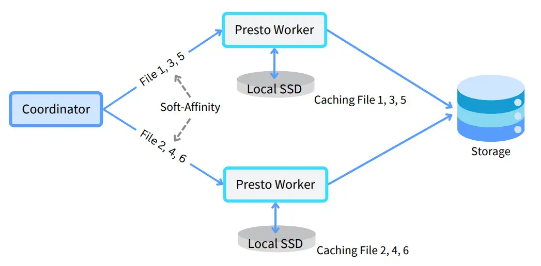
上图展示了软亲和力节点选择架构。软关联调度尝试根据文件路径向工作程序发送请求,通过在工作程序缓存中定位数据来最大化缓存命中率。软亲和力之所以是“软”,是因为它不是一个严格的规则——如果首选工作人员繁忙,则将分片发送到另一个可用工作人员而不是等待。
如果遇到诸如“Unsupported Under FileSystem”之类的错误,请从 Maven 存储库下载最新的Alluxio 客户端 JAR并将其放置在 {$presto_root_path}/plugin/hive-hadoop2/ 目录中。
Alluxio分布式缓存(第三方)
如果 Presto 内存或存储不足以容纳大型数据集,则使用第三方缓存解决方案可以为频繁的数据访问提供扩展缓存。第三方缓存可以为 Presto 提供多种优化:
-
通过减少 I/O 延迟来提高性能
-
加速远程跨数据中心或云数据存储的查询
-
在 Presto 工作线程、集群和其他引擎(例如Apache Spark)之间提供共享缓存
-
启用弹性缓存以节省现货实例的成本
Alluxio 分布式缓存是第三方缓存的一个示例。如下图所示,Alluxio分布式缓存部署在Presto和S3等存储之间。Alluxio使用主从架构,其中主节点管理元数据,工作节点管理本地存储(内存、SSD、HDD)上的缓存数据。当缓存命中时,Alluxio工作线程将数据返回给Presto工作线程。否则,Alluxio工作线程从持久存储中检索数据并缓存数据以供将来使用。Presto 工作线程处理缓存的数据,协调器将结果返回给用户。
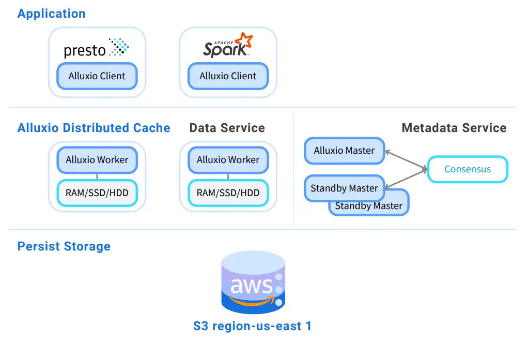
以下是使用 Presto 部署 Alluxio 分布式缓存的步骤。
1.将Alluxio客户端JAR分发到所有Presto服务器
为了让 Presto 能够与 Alluxio 服务器通信,Alluxio 客户端 jar 必须位于 Presto 服务器的类路径中。将 Alluxio 客户端 JAR /<PATH_TO_ALLUXIO>/client/alluxio-2.9.3-client.jar 放入所有 Presto 服务器上的目录 ${PRESTO_HOME}/plugin/hive-hadoop2/ 中。使用以下命令重新启动 Presto 工作线程和协调器:
$ ${PRESTO_HOME}/bin/launcher restart2.将Alluxio配置添加到Presto的HDFS配置文件中
您可以将Alluxio的属性添加到HDFS配置文件中,例如core-site.xml和hdfs-site.xml,然后在文件${PRESTO_HOME}/etc/catalog/hive.properties中使用Presto属性hive.config.resources指向每个 Presto Worker 上的 HDFS 配置文件的位置。
hive.config.resources=/<PATH_TO_CONF>/core-site.xml,/<PATH_TO_CONF>/hdfs-site.xml然后,将该属性添加到 HDFS core-site.xml 配置中,该配置由 Presto 属性中的 hive.config.resources 链接。
<configuration><property><name>alluxio.master.rpc.addresses</name>
<value>master_hostname_1:19998,master_hostname_2:19998,master_hostname_3:19998</value></property>
</configuration>基于上面的配置,Presto能够定位Alluxio集群并将数据访问转发给它。
为您的用例选择合适的缓存
Presto 和 Alluxio 开源社区不断致力于改进现有的缓存功能并开发新的功能来增强查询速度、优化效率并提高系统的可扩展性和可靠性。
缓存是提高Presto查询性能的强大方式。在本文中,我们介绍了Presto中的不同缓存机制,包括元存储缓存、列出文件状态缓存、Alluxio SDK缓存和Alluxio分布式缓存。如下表所示,您可以根据您的用例使用这些缓存来加速数据访问。
| 缓存类型 | 何时使用 |
| 元存储缓存 | 规划时间慢 Hive metastore慢 具有数百个分区的大表 |
| 列出文件状态缓存 | 超载的HDFS namenode 如S3这样的超载对象存储 |
| Alluxio SDK缓存 | 外部存储速度慢或不稳定 |
| Alluxio分布式缓存 | 跨区域、多云、混合云 与其他计算引擎共享数据 |
作者:Beinan Wang and Hope Wang
更多内容请关注公号【云原生数据库】
squids.cn,云数据库RDS,迁移工具DBMotion,云备份DBTwin等数据库生态工具。
相关文章:
深入探讨 Presto 中的缓存
【squids.cn】 全网zui低价RDS,免费的迁移工具DBMotion、数据库备份工具DBTwin、SQL开发工具等 Presto是一种流行的开源分布式SQL引擎,使组织能够在多个数据源上大规模运行交互式分析查询。缓存是一种典型的提高 Presto 查询性能的优化技术。它为 Prest…...
3.物联网射频识别,(高频)RFID应用ISO14443-2协议,(校园卡)Mifare S50卡
一。ISO14443-2协议简介 1.ISO14443协议组成及部分缩略语 (1)14443协议组成(下面的协议简介会详细介绍) 14443-1 物理特性 14443-2 射频功率和信号接口 14443-3 初始化和防冲突 (分为Type A、Type B两种接口&…...

【IDEA】IDEA 单行注释开头添加空格
操作 打开 IDEA 的 Settings 对话框(快捷键为CtrlAltS);在左侧面板中选择Editor -> Code Style -> Java;在右侧面板中选择Code Generation选项卡;将Line comment at first column选项设置为false使注释加在行开…...
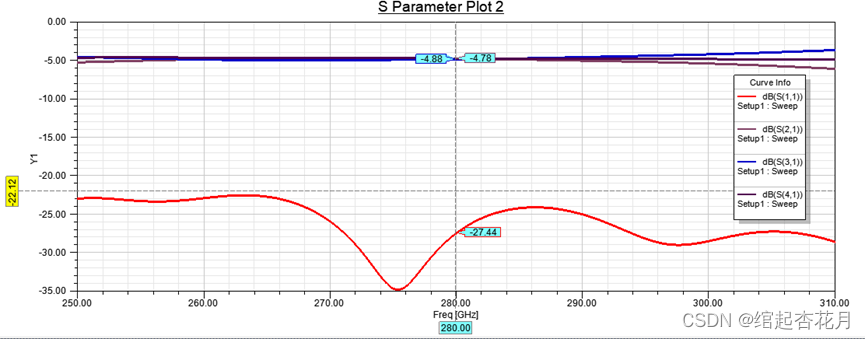
三等分功分器[波导]设计详细教程
想必大家通过阅读相关文献可以发现三等分实现可以有很多不同的方法,这里采用的是先不等分再等分的方式,仅供参考。 主要指标 中心频率为280GHz,采用WR-3频段的标准波导,将2:1不等功率分配耦合器与3dB等功率分配耦合器级联&#…...

Mysql分库分表
1.原理 2.Sharding JDBC 官网https://shardingsphere.apache.org/ 2.1 水平拆分 创建一个新的springboot项目 导入依赖,直接将原本的dependencies给覆盖掉 <dependencies><!-- ShardingJDBC依赖 --><dependency><groupId>org.apache.shardings…...

【算法学习】-【双指针】-【复写零】
LeetCode原题链接:1089. 复写零 下面是题目描述: 给你一个长度固定的整数数组 arr ,请你将该数组中出现的每个零都复写一遍,并将其余的元素向右平移。 注意:请不要在超过该数组长度的位置写入元素。请对输入的数组 …...

【算法优选】双指针专题——叁
文章目录 😎前言🌳[两数之和](https://leetcode.cn/problems/he-wei-sde-liang-ge-shu-zi-lcof/)🚩题目描述:🚩算法思路:🚩算法流程:🚩代码实现 🎄[三数之和]…...

Java栈的压入、弹出序列(详解)
目录 1.题目描述 2.题解 方法1 方法2 1.题目描述 输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否可能为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈序…...

RabbitMQ学习笔记(消息发布确认,死信队列,集群,交换机,持久化,生产者、消费者)
MQ(message queue):本质上是个队列,遵循FIFO原则,队列中存放的是message,是一种跨进程的通信机制,用于上下游传递消息。MQ提供“逻辑解耦物理解耦”的消息通信服务。使用了MQ之后消息发送上游只…...
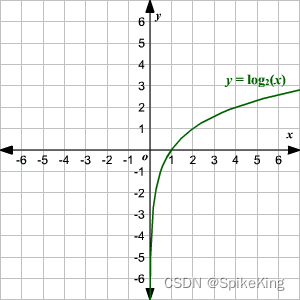
PyTorch - 模型训练损失 (Loss) NaN 问题的解决方案
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/133378367 在模型训练中,如果出现 NaN 的问题,严重影响 Loss 的反传过程,因此,需要加入一些微小值…...
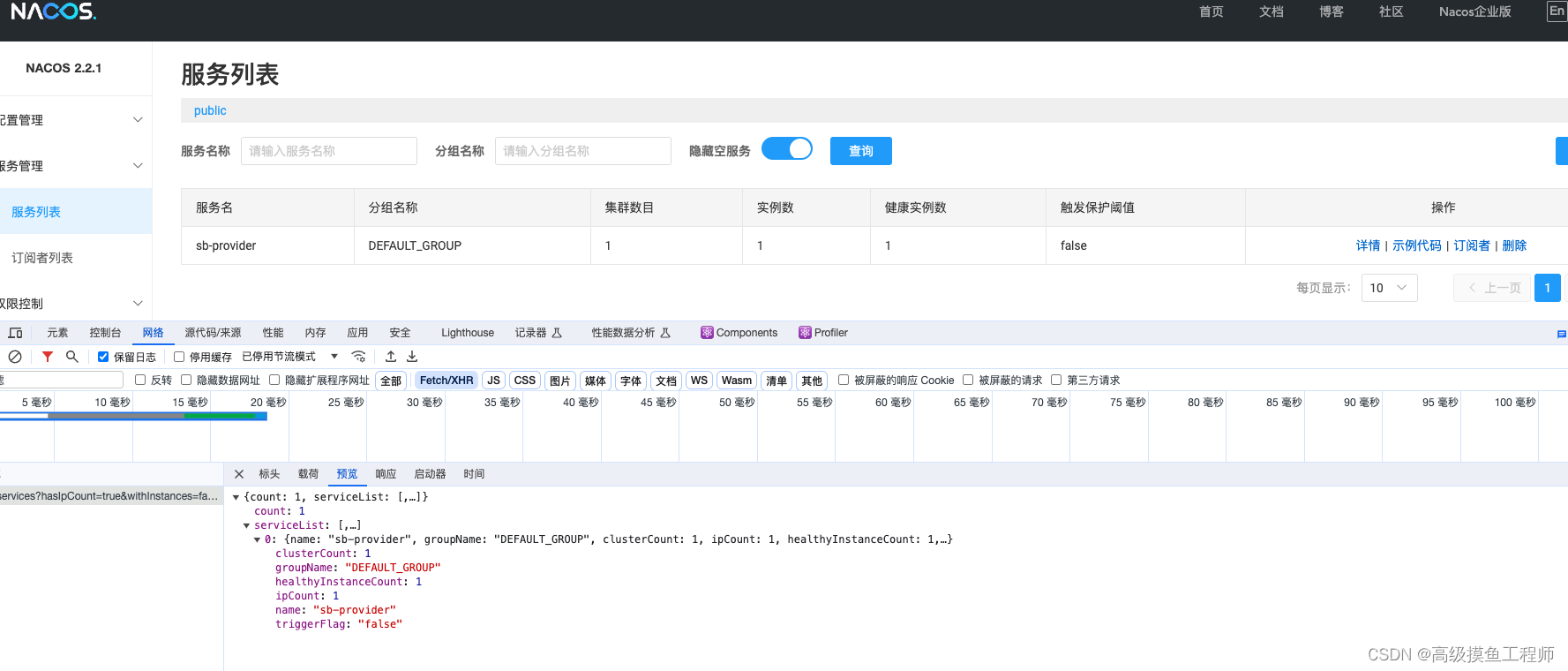
8、Nacos服务注册服务端源码分析(七)
本文收录于专栏 Nacos 中 。 文章目录 前言确定前端路由CatalogController.listDetail()ServiceManager总结 前言 前文我们分析了Nacos中客户端注册时数据分发的设计链路,本文根据Nacos前端页面请求,看下前端页面中的服务列表的数据源于哪里。 确定前端…...

MySQL使用Xtrabackup在线做主从
1、主库上操作 1.1前提 172.16.11.2(主库) 172.16.11.4(从库) 在执行备份之前,确保数据库没有锁定,以避免备份期间的任何写操作。 确保主库上的 MySQL 服务器正在运行,以便备份数据的一致性。…...
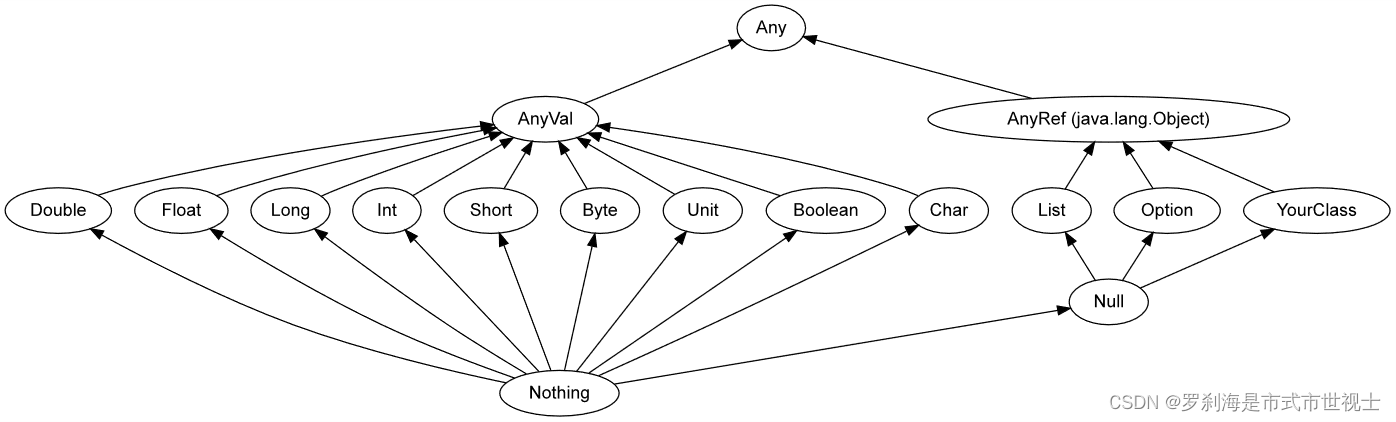
scala基础入门
一、Scala安装 下载网址:Install | The Scala Programming Language ideal安装 (1)下载安装Scala plugins (2)统一JDK环境,统一为8 (3)加载Scala (4)创建工…...

【Java-LangChain:面向开发者的提示工程-5】推断
第五章 推断 推断任务可以看作是模型接收文本作为输入,并执行某种分析的过程。其中涉及提取标签、提取实体、理解文本情感等等。如果你想要从一段文本中提取正面或负面情感,在传统的机器学习工作流程中,需要收集标签数据集、训练模型、确定如…...
【C++】手撕vector(vector的模拟实现)
手撕vector目录: 一、基本实现思路方针 二、vector的构造函数剖析(构造歧义拷贝构造) 2.1构造函数使用的歧义问题 2.2 vector的拷贝构造和赋值重载(赋值重载不是构造哦,为了方便写在一起) 三、vector的…...

智能指针那些事
《Effective Modern C》学习笔记之条款二十一:优先选用std::make_unique和std::make_shared,而非直接new - 知乎...
Fiddler抓取手机https包的步骤
做接口测试时,有时我们需要使用fiddler进行抓包分析,那么如何抓取https包。主要分为以下七步: 1.设置fiddler选项:Tools->Options,按如下图勾选 2.下载并安装Fiddler证书生成器 下载地址:http://www.telerik.com/…...
idea没有maven工具栏解决方法
背景:接手的一些旧项目,有pom文件,但是用idea打开的时候,没有认为是maven文件,所以没有maven工具栏,不能进行重新加载pom文件中的依赖。 解决方法:选中pom.xml文件,右键 选择添加为…...
levelDB引擎
一、背景 1.1、影响磁盘性能的因素: 主要受限于磁盘的寻道时间,优化磁盘数据访问的方法是尽量减少磁盘的IO次数。磁盘数据访问效率取决于磁盘IO次数,而磁盘IO次数又取决于数据在磁盘上的组织方式。磁盘数据存储大多采用B树类型数据结构&…...

IM同步服务
设计概述 后台同步方案的设计就是数据存储结构的设计,如何快速体现“信息变化”,如何快速计算出“变化信息”。后台数据存储结构是由同步协议中同步契约决定的。 设计方案 该方案的同步是按照业务粒度来划分,只需要同步sdk要求同步的数据。…...

NodeMCU PyFlasher:ESP8266图形化固件烧录终极解决方案
NodeMCU PyFlasher:ESP8266图形化固件烧录终极解决方案 【免费下载链接】nodemcu-pyflasher Self-contained NodeMCU flasher with GUI based on esptool.py and wxPython. 项目地址: https://gitcode.com/gh_mirrors/no/nodemcu-pyflasher 对于ESP8266开发者…...

AI专著生成神器登场!快速输出20万字专著,写作不用愁!
学术专著写作困境与AI工具的崛起 对于许多学术研究者来说,撰写学术专著时面临的最大挑战,无疑是“有限的精力”和“无穷的需求”之间的矛盾。撰写专著通常需要三到五年,甚至更长时间,而研究者还需平衡教学、科研项目和学术交流等…...
详解与最佳实践)
HoRain云--PHP日期格式化函数date()详解与最佳实践
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

收藏必备!小白程序员轻松入门大模型:ReAct与Reflexion核心技术与实战应用
大语言模型(LLM)在复杂任务中存在事实幻觉、缺乏实时信息等局限。本文介绍ReAct和Reflexion两大提示技术框架,ReAct通过推理与行动协同,有效解决幻觉问题;Reflexion在ReAct基础上增加自我反思机制,形成闭环…...

基于Tauri与Bun的本地多智能体AI助手YouClaw:架构、配置与实战
1. 项目概述:一个桌面端的多智能体AI助手运行时 最近在折腾AI智能体(Agent)的本地化部署和集成,发现了一个挺有意思的开源项目——YouClaw。简单来说,它是一个基于Tauri 2构建的桌面应用,核心是一个支持多…...

可穿戴设备十年演进:从技术突破到健康与生产力工具
1. 从预言到现实:可穿戴计算浪潮的十年回望与深度拆解十年前,当EE Times那篇关于Apple iWatch和Google Glasses将引领可穿戴计算浪潮的文章发表时,业界还弥漫着一种将信将疑的氛围。彼时,智能手机正处巅峰,人们很难想象…...

如何快速掌握91160-cli:面向新手的医院全自动挂号完整指南
如何快速掌握91160-cli:面向新手的医院全自动挂号完整指南 【免费下载链接】91160-cli 健康160全自动挂号脚本,捡漏神器 项目地址: https://gitcode.com/gh_mirrors/91/91160-cli 还在为医院挂号难而烦恼吗?91160-cli是一款专为医疗预…...

PCB高级工艺如何降本:盲孔、微孔与HDI设计的成本优化实战
1. 项目概述:当高级PCB技术成为降本利器在硬件研发圈子里待久了,总有一个根深蒂固的印象:但凡沾上“高级”、“高密度”这些词的技术,比如盲孔、埋孔和微孔,那成本肯定是蹭蹭往上涨。我刚开始接触HDI板设计时也是这么想…...

2025 - 2026年国资跑步入场脑机接口,重新定义游戏规则!
突发!国资入场脑机接口赛道2025 - 2026年,脑机接口赛道的资本格局悄然生变。从IT桔子融资数据来看,国资/政府基金密集出现在近一年的轮次中:上海国投先导、国投创合跟投阶梯医疗5亿战略融资;浦东创投、张江科投联手投资…...

模拟电路缩放迷思破解:从挑战到协同优化的设计范式转变
1. 模拟电路缩放:一个被误解的“物理定律”在半导体行业里,尤其是数字电路设计工程师和项目经理之间,流传着一个近乎“常识”的观点:模拟电路不能像数字电路那样随着工艺节点进步而有效缩放。这个说法听起来很有道理,毕…...