【深度学习实验】卷积神经网络(六):自定义卷积神经网络模型(VGG)实现图片多分类任务
目录
一、实验介绍
二、实验环境
1. 配置虚拟环境
2. 库版本介绍
三、实验内容
0. 导入必要的工具包
1. 构建数据集(CIFAR10Dataset)
a. read_csv_labels()
b. CIFAR10Dataset
2. 构建模型(FeedForward)
3.整合训练、评估、预测过程(Runner)
4. __main__
预测结果
5. 代码整合
一、实验介绍
本实验实现了一个简化版VGG网络,并基于此完成图像分类任务。
VGG网络是深度卷积神经网络中的经典模型之一,由牛津大学计算机视觉组(Visual Geometry Group)提出。它在2014年的ImageNet图像分类挑战中取得了优异的成绩(分类任务第二,定位任务第一),被广泛应用于图像分类、目标检测和图像生成等任务。
VGG网络的主要特点是使用了非常小的卷积核尺寸(通常为3x3)和更深的网络结构。该网络通过多个卷积层和池化层堆叠在一起,逐渐增加网络的深度,从而提取图像的多层次特征表示。VGG网络的基本构建块是由连续的卷积层组成,每个卷积层后面跟着一个ReLU激活函数。在每个卷积块的末尾,都会添加一个最大池化层来减小特征图的尺寸。VGG网络的这种简单而有效的结构使得它易于理解和实现,并且在不同的任务上具有很好的泛化性能。
VGG网络有几个不同的变体,如VGG11、VGG13、VGG16和VGG19,它们的数字代表网络的层数。这些变体在网络深度和参数数量上有所区别,较深的网络通常具有更强大的表示能力,但也更加复杂。

二、实验环境
本系列实验使用了PyTorch深度学习框架,相关操作如下:
1. 配置虚拟环境
conda create -n DL python=3.7 conda activate DLpip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib conda install scikit-learn2. 库版本介绍
| 软件包 | 本实验版本 | 目前最新版 |
| matplotlib | 3.5.3 | 3.8.0 |
| numpy | 1.21.6 | 1.26.0 |
| python | 3.7.16 | |
| scikit-learn | 0.22.1 | 1.3.0 |
| torch | 1.8.1+cu102 | 2.0.1 |
| torchaudio | 0.8.1 | 2.0.2 |
| torchvision | 0.9.1+cu102 | 0.15.2 |
三、实验内容
ChatGPT:
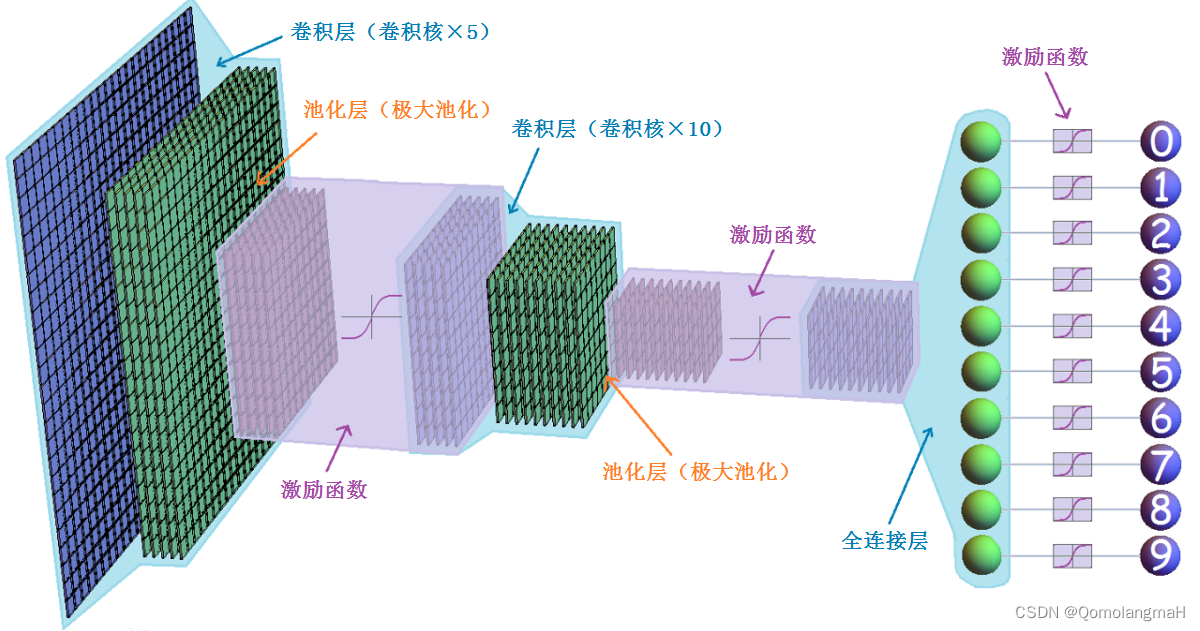
卷积神经网络(Convolutional Neural Network,简称CNN)是一种深度学习模型,广泛应用于图像识别、计算机视觉和模式识别等领域。它的设计灵感来自于生物学中视觉皮层的工作原理。
卷积神经网络通过多个卷积层、池化层和全连接层组成。
- 卷积层主要用于提取图像的局部特征,通过卷积操作和激活函数的处理,可以学习到图像的特征表示。
- 池化层则用于降低特征图的维度,减少参数数量,同时保留主要的特征信息。
- 全连接层则用于将提取到的特征映射到不同类别的概率上,进行分类或回归任务。
卷积神经网络在图像处理方面具有很强的优势,它能够自动学习到具有层次结构的特征表示,并且对平移、缩放和旋转等图像变换具有一定的不变性。这些特点使得卷积神经网络成为图像分类、目标检测、语义分割等任务的首选模型。除了图像处理,卷积神经网络也可以应用于其他领域,如自然语言处理和时间序列分析。通过将文本或时间序列数据转换成二维形式,可以利用卷积神经网络进行相关任务的处理。
0. 导入必要的工具包
import torch
from torch import nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision.io import read_image
import matplotlib.pyplot as plt
import os1. 构建数据集(CIFAR10Dataset)
a. read_csv_labels()
从CSV文件中读取标签信息并返回一个标签字典。
def read_csv_labels(fname):"""读取fname来给标签字典返回一个文件名"""with open(fname, 'r') as f:# 跳过文件头行(列名)lines = f.readlines()[1:]tokens = [l.rstrip().split(',') for l in lines]return dict(((name, label) for name, label in tokens))-
使用
open函数打开指定文件名的CSV文件,并将文件对象赋值给变量f。这里使用'r'参数以只读模式打开文件。 -
使用文件对象的
readlines()方法读取文件的所有行,并将结果存储在名为lines的列表中。通过切片操作[1:],跳过了文件的第一行(列名),将剩余的行存储在lines列表中。 -
列表推导式(list comprehension):对
lines列表中的每一行进行处理。对于每一行,使用rstrip()方法去除行末尾的换行符,并使用split(',')方法将行按逗号分割为多个标记。最终,将所有行的标记组成的子列表存储在tokens列表中。 -
使用字典推导式(dictionary comprehension)将
tokens列表中的子列表转换为字典。对于tokens中的每个子列表,将子列表的第一个元素作为键(name),第二个元素作为值(label),最终返回一个包含这些键值对的字典。
b. CIFAR10Dataset
class CIFAR10Dataset(Dataset):def __init__(self, folder_path, fname):self.labels = read_csv_labels(os.path.join(folder_path, fname))self.folder_path = os.path.join(folder_path, 'train')def __len__(self):return len(self.labels)def __getitem__(self, idx):img = read_image(self.folder_path + '/' + str(idx + 1) + '.png')label = self.labels[str(idx + 1)]return img, torch.tensor(int(label))-
构造函数:
-
接受两个参数
-
folder_path表示数据集所在的文件夹路径 -
fname表示包含标签信息的文件名。
-
-
调用
read_csv_labels函数,传递folder_path和fname作为参数,以读取CSV文件中的标签信息,并将返回的标签字典存储在self.labels变量中。 -
通过拼接
folder_path和字符串'train'来构建数据集的文件夹路径,将结果存储在self.folder_path变量中。
-
-
def __len__(self)-
这是
CIFAR10Dataset类的方法,用于返回数据集的长度,即样本的数量。
-
-
def __getitem__(self, idx): 这是CIFAR10Dataset类的方法,用于根据给定的索引idx获取数据集中的一个样本。它首先根据索引idx构建图像文件的路径,并调用read_image函数来读取图像数据,将结果存储在img变量中。然后,它通过将索引转换为字符串,并使用该字符串作为键来从self.labels字典中获取相应的标签,将结果存储在label变量中。最后,它返回一个元组,包含图像数据和经过torch.tensor转换的标签。
2. 构建模型(FeedForward)
参考前文:
【深度学习实验】卷积神经网络(五):深度卷积神经网络经典模型——VGG网络(卷积层、池化层、全连接层)_QomolangmaH的博客-CSDN博客![]() https://blog.csdn.net/m0_63834988/article/details/133350927?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_63834988/article/details/133350927?spm=1001.2014.3001.5501
# 每个卷积块由Conv2d卷积 + BatchNorm2d(批量标准化处理) + ReLU激活层组成
def conv_layer(chann_in, chann_out, k_size, p_size):layer = nn.Sequential(nn.Conv2d(chann_in, chann_out, kernel_size=k_size, padding=p_size),nn.BatchNorm2d(chann_out),nn.ReLU())return layer# vgg卷积模块是由几个相同的卷积块以及最大池化组成
def vgg_conv_block(in_list, out_list, k_list, p_list, pooling_k, pooling_s):layers = [conv_layer(in_list[i], out_list[i], k_list[i], p_list[i]) for i in range(len(in_list)) ]layers += [nn.MaxPool2d(kernel_size = pooling_k, stride = pooling_s)]return nn.Sequential(*layers)# vgg全连接层由Linear + BatchNorm1d + ReLU组成
def vgg_fc_layer(size_in, size_out):layer = nn.Sequential(nn.Linear(size_in, size_out),nn.BatchNorm1d(size_out),nn.ReLU())return layer# 为了简化,我们少使用了几层卷积层,方便大家使用
class VGG_S(nn.Module):def __init__ (self, num_classes):super().__init__()self.layer1 = vgg_conv_block([3,64], [64,64], [3,3], [1,1], 2, 2) self.layer2 = vgg_conv_block([64,128], [128,128], [3,3], [1,1], 2, 2)self.layer3 = vgg_conv_block([128,256,256], [256,256,256], [3,3,3], [1,1,1], 2, 2)# 全连接层self.layer4 = vgg_fc_layer(4096, 1024)# Final layerself.layer5 = nn.Linear(1024, num_classes)def forward(self, x):out = self.layer1(x)out = self.layer2(out)vgg16_features = self.layer3(out)out = vgg16_features.view(out.size(0), -1)out = self.layer4(out)out = self.layer5(out)return out
3.整合训练、评估、预测过程(Runner)
参考前文:
【深度学习实验】前馈神经网络(九):整合训练、评估、预测过程(Runner)_QomolangmaH的博客-CSDN博客![]() https://blog.csdn.net/m0_63834988/article/details/133219448?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_63834988/article/details/133219448?spm=1001.2014.3001.5501
(略有改动:)
class Runner(object):def __init__(self, model, optimizer, loss_fn, metric=None):self.model = modelself.optimizer = optimizerself.loss_fn = loss_fn# 用于计算评价指标self.metric = metric# 记录训练过程中的评价指标变化self.dev_scores = []# 记录训练过程中的损失变化self.train_epoch_losses = []self.dev_losses = []# 记录全局最优评价指标self.best_score = 0# 模型训练阶段def train(self, train_loader, dev_loader=None, **kwargs):# 将模型设置为训练模式,此时模型的参数会被更新self.model.train()num_epochs = kwargs.get('num_epochs', 0)log_steps = kwargs.get('log_steps', 100)save_path = kwargs.get('save_path','best_model.pth')eval_steps = kwargs.get('eval_steps', 0)# 运行的step数,不等于epoch数global_step = 0if eval_steps:if dev_loader is None:raise RuntimeError('Error: dev_loader can not be None!')if self.metric is None:raise RuntimeError('Error: Metric can not be None')# 遍历训练的轮数for epoch in range(num_epochs):total_loss = 0# 遍历数据集for step, data in enumerate(train_loader):x, y = datalogits = self.model(x.float())loss = self.loss_fn(logits, y.long())total_loss += lossif step%log_steps == 0:print(f'loss:{loss.item():.5f}')loss.backward()self.optimizer.step()self.optimizer.zero_grad()# 每隔一定轮次进行一次验证,由eval_steps参数控制,可以采用不同的验证判断条件if eval_steps != 0 :if (epoch+1) % eval_steps == 0:dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)print(f'[Evalute] dev score:{dev_score:.5f}, dev loss:{dev_loss:.5f}')if dev_score > self.best_score:self.save_model(f'model_{epoch+1}.pth')print(f'[Evaluate]best accuracy performance has been updated: {self.best_score:.5f}-->{dev_score:.5f}')self.best_score = dev_score# 验证过程结束后,请记住将模型调回训练模式 self.model.train()global_step += 1# 保存当前轮次训练损失的累计值train_loss = (total_loss/len(train_loader)).item()self.train_epoch_losses.append((global_step,train_loss))self.save_model(f'{save_path}.pth') print('[Train] Train done')# 模型评价阶段def evaluate(self, dev_loader, **kwargs):assert self.metric is not None# 将模型设置为验证模式,此模式下,模型的参数不会更新self.model.eval()global_step = kwargs.get('global_step',-1)total_loss = 0self.metric.reset()for batch_id, data in enumerate(dev_loader):x, y = datalogits = self.model(x.float())loss = self.loss_fn(logits, y.long()).item()total_loss += loss self.metric.update(logits, y)dev_loss = (total_loss/len(dev_loader))self.dev_losses.append((global_step, dev_loss))dev_score = self.metric.accumulate()self.dev_scores.append(dev_score)return dev_score, dev_loss# 模型预测阶段,def predict(self, x, **kwargs):self.model.eval()logits = self.model(x)return logits# 保存模型的参数def save_model(self, save_path):torch.save(self.model.state_dict(), save_path)# 读取模型的参数def load_model(self, model_path):self.model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))4. __main__
if __name__ == '__main__':batch_size = 20# 构建训练集train_data = CIFAR10Dataset('cifar10_tiny', 'trainLabels.csv')train_iter = DataLoader(train_data, batch_size=batch_size)# 构建测试集test_data = CIFAR10Dataset('cifar10_tiny', 'trainLabels.csv')test_iter = DataLoader(test_data, batch_size=batch_size)# 模型训练num_classes = 10# 定义模型model = VGG_S(num_classes)# 定义损失函数loss_fn = F.cross_entropy# 定义优化器optimizer = torch.optim.SGD(model.parameters(), lr=0.1)runner = Runner(model, optimizer, loss_fn, metric=None)runner.train(train_iter, num_epochs=10, save_path='chapter_5')# 模型预测runner.load_model('chapter_5.pth')x, label = next(iter(test_iter))predict = torch.argmax(runner.predict(x.float()), dim=1)print('predict:', predict)print(' label:', label)预测结果
predict: tensor([6, 1, 9, 6, 1, 1, 6, 7, 0, 3, 4, 7, 7, 1, 9, 0, 9, 5, 3, 6])label: tensor([6, 9, 9, 4, 1, 1, 2, 7, 8, 3, 4, 7, 7, 2, 9, 9, 9, 3, 2, 6])5. 代码整合
# 导入必要的工具包
import torch
from torch import nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision.io import read_image
import matplotlib.pyplot as plt
import osdef read_csv_labels(fname):"""读取fname来给标签字典返回一个文件名"""with open(fname, 'r') as f:# 跳过文件头行(列名)lines = f.readlines()[1:]tokens = [l.rstrip().split(',') for l in lines]return dict(((name, label) for name, label in tokens))class CIFAR10Dataset(Dataset):def __init__(self, folder_path, fname):self.labels = read_csv_labels(os.path.join(folder_path, fname))self.folder_path = os.path.join(folder_path, 'train')def __len__(self):return len(self.labels)def __getitem__(self, idx):img = read_image(self.folder_path + '/' + str(idx + 1) + '.png')label = self.labels[str(idx + 1)]return img, torch.tensor(int(label))# 每个卷积块由Conv2d卷积 + BatchNorm2d(批量标准化处理) + ReLU激活层组成
def conv_layer(chann_in, chann_out, k_size, p_size):layer = nn.Sequential(nn.Conv2d(chann_in, chann_out, kernel_size=k_size, padding=p_size),nn.BatchNorm2d(chann_out),nn.ReLU())return layer# vgg卷积模块是由几个相同的卷积块以及最大池化组成
def vgg_conv_block(in_list, out_list, k_list, p_list, pooling_k, pooling_s):layers = [conv_layer(in_list[i], out_list[i], k_list[i], p_list[i]) for i in range(len(in_list))]layers += [nn.MaxPool2d(kernel_size=pooling_k, stride=pooling_s)]return nn.Sequential(*layers)# vgg全连接层由Linear + BatchNorm1d + ReLU组成
def vgg_fc_layer(size_in, size_out):layer = nn.Sequential(nn.Linear(size_in, size_out),nn.BatchNorm1d(size_out),nn.ReLU())return layer# 为了简化,我们少使用了几层卷积层,方便大家使用
class VGG_S(nn.Module):def __init__(self, num_classes):super().__init__()self.layer1 = vgg_conv_block([3, 64], [64, 64], [3, 3], [1, 1], 2, 2)self.layer2 = vgg_conv_block([64, 128], [128, 128], [3, 3], [1, 1], 2, 2)self.layer3 = vgg_conv_block([128, 256, 256], [256, 256, 256], [3, 3, 3], [1, 1, 1], 2, 2)# 全连接层self.layer4 = vgg_fc_layer(4096, 1024)# Final layerself.layer5 = nn.Linear(1024, num_classes)def forward(self, x):out = self.layer1(x)out = self.layer2(out)vgg16_features = self.layer3(out)out = vgg16_features.view(out.size(0), -1)out = self.layer4(out)out = self.layer5(out)return outclass Runner(object):def __init__(self, model, optimizer, loss_fn, metric=None):self.model = modelself.optimizer = optimizerself.loss_fn = loss_fn# 用于计算评价指标self.metric = metric# 记录训练过程中的评价指标变化self.dev_scores = []# 记录训练过程中的损失变化self.train_epoch_losses = []self.dev_losses = []# 记录全局最优评价指标self.best_score = 0# 模型训练阶段def train(self, train_loader, dev_loader=None, **kwargs):# 将模型设置为训练模式,此时模型的参数会被更新self.model.train()num_epochs = kwargs.get('num_epochs', 0)log_steps = kwargs.get('log_steps', 100)save_path = kwargs.get('save_path', 'best_model.pth')eval_steps = kwargs.get('eval_steps', 0)# 运行的step数,不等于epoch数global_step = 0if eval_steps:if dev_loader is None:raise RuntimeError('Error: dev_loader can not be None!')if self.metric is None:raise RuntimeError('Error: Metric can not be None')# 遍历训练的轮数for epoch in range(num_epochs):total_loss = 0# 遍历数据集for step, data in enumerate(train_loader):x, y = datalogits = self.model(x.float())loss = self.loss_fn(logits, y.long())total_loss += lossif step % log_steps == 0:print(f'loss:{loss.item():.5f}')loss.backward()self.optimizer.step()self.optimizer.zero_grad()# 每隔一定轮次进行一次验证,由eval_steps参数控制,可以采用不同的验证判断条件if eval_steps != 0:if (epoch + 1) % eval_steps == 0:dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)print(f'[Evalute] dev score:{dev_score:.5f}, dev loss:{dev_loss:.5f}')if dev_score > self.best_score:self.save_model(f'model_{epoch + 1}.pth')print(f'[Evaluate]best accuracy performance has been updated: {self.best_score:.5f}-->{dev_score:.5f}')self.best_score = dev_score# 验证过程结束后,请记住将模型调回训练模式self.model.train()global_step += 1# 保存当前轮次训练损失的累计值train_loss = (total_loss / len(train_loader)).item()self.train_epoch_losses.append((global_step, train_loss))self.save_model(f'{save_path}.pth')print('[Train] Train done')# 模型评价阶段def evaluate(self, dev_loader, **kwargs):assert self.metric is not None# 将模型设置为验证模式,此模式下,模型的参数不会更新self.model.eval()global_step = kwargs.get('global_step', -1)total_loss = 0self.metric.reset()for batch_id, data in enumerate(dev_loader):x, y = datalogits = self.model(x.float())loss = self.loss_fn(logits, y.long()).item()total_loss += lossself.metric.update(logits, y)dev_loss = (total_loss / len(dev_loader))self.dev_losses.append((global_step, dev_loss))dev_score = self.metric.accumulate()self.dev_scores.append(dev_score)return dev_score, dev_loss# 模型预测阶段,def predict(self, x, **kwargs):self.model.eval()logits = self.model(x)return logits# 保存模型的参数def save_model(self, save_path):torch.save(self.model.state_dict(), save_path)# 读取模型的参数def load_model(self, model_path):self.model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))if __name__ == '__main__':batch_size = 20# 构建训练集train_data = CIFAR10Dataset('cifar10_tiny', 'trainLabels.csv')train_iter = DataLoader(train_data, batch_size=batch_size)# 构建测试集test_data = CIFAR10Dataset('cifar10_tiny', 'trainLabels.csv')test_iter = DataLoader(test_data, batch_size=batch_size)# 模型训练num_classes = 10# 定义模型model = VGG_S(num_classes)# 定义损失函数loss_fn = F.cross_entropy# 定义优化器optimizer = torch.optim.SGD(model.parameters(), lr=0.1)runner = Runner(model, optimizer, loss_fn, metric=None)runner.train(train_iter, num_epochs=10, save_path='chapter_5')# 模型预测runner.load_model('chapter_5.pth')x, label = next(iter(test_iter))predict = torch.argmax(runner.predict(x.float()), dim=1)print('predict:', predict)print(' label:', label)相关文章:
【深度学习实验】卷积神经网络(六):自定义卷积神经网络模型(VGG)实现图片多分类任务
目录 一、实验介绍 二、实验环境 1. 配置虚拟环境 2. 库版本介绍 三、实验内容 0. 导入必要的工具包 1. 构建数据集(CIFAR10Dataset) a. read_csv_labels() b. CIFAR10Dataset 2. 构建模型(FeedForward&…...

Git/GitHub/Idea的搭配使用
目录 1. Git 下载安装1.1. 下载安装1.2. 配置 GitHub 秘钥 2. Idea 配置 Git3. Idea 配置 GitHub3.1. 获取 GitHub Token3.2. Idea 根据 Token 登录 GitHub3.3. Idea 提交代码到远程仓库3.3.1. 配置本地仓库3.3.2. GitHub 创建远程仓库1. 创建单层目录2. 创建多层目录3. 删除目…...
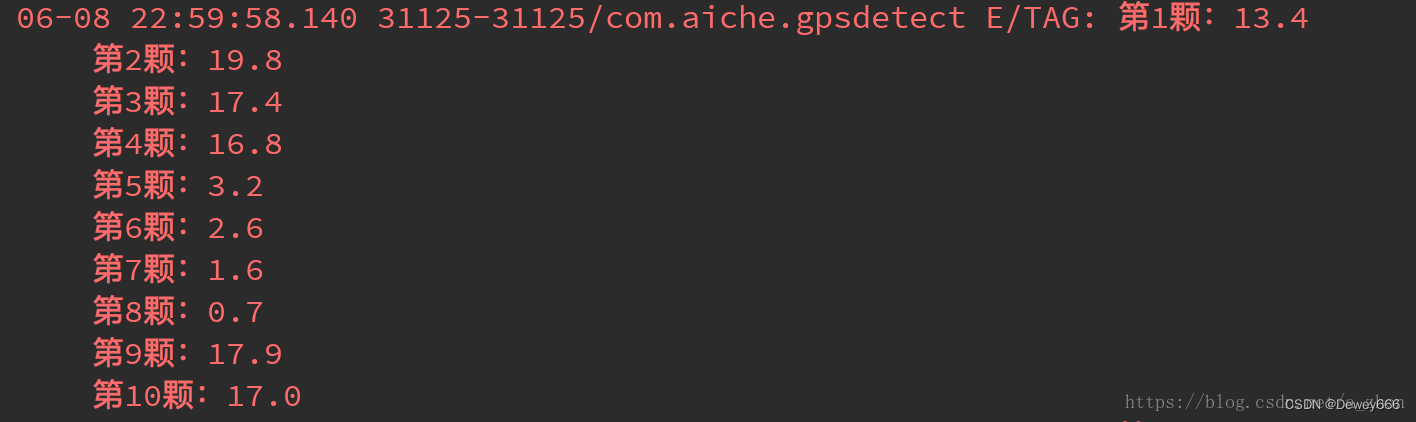
Android的GNSS功能,搜索卫星数量、并获取每颗卫星的信噪比
一、信噪比概念 信噪比,英文名称叫做SNR或S/N(SIGNAL-NOISE RATIO),又称为讯噪比。是指一个电子设备或者电子系统中信号与噪声的比例。 信噪比越大,此颗卫星越有效(也就是说可以定位)。也就是说࿰…...
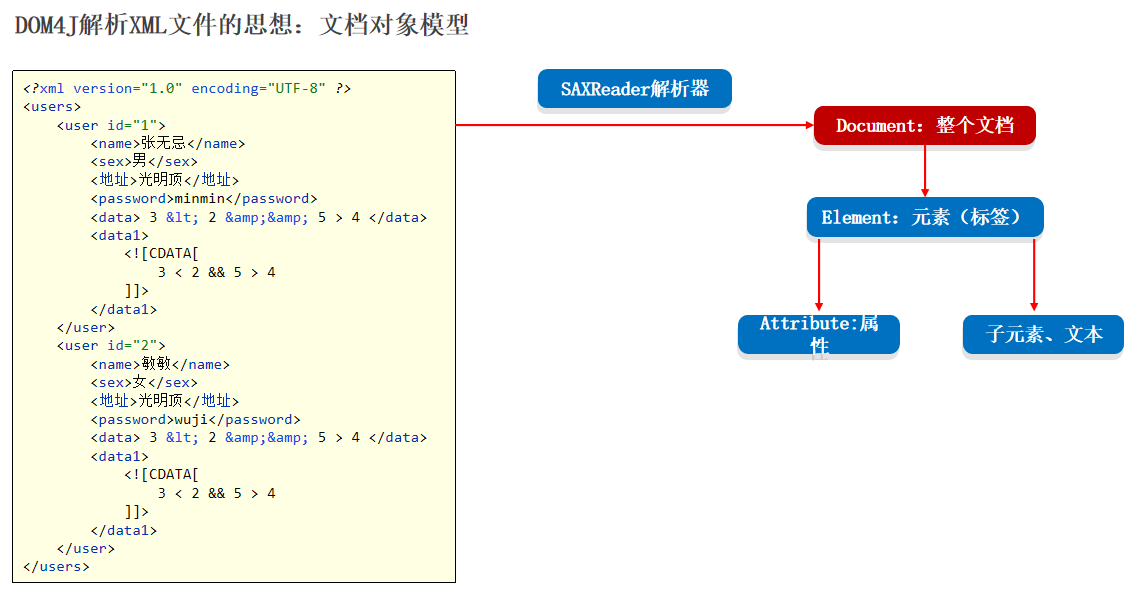
23-properties文件和xml文件以及dom4j的基本使用操作
特殊文件 我们利用这些特殊文件来存放我们 java 中的数据信息,当数据量比较大的时候,我们可以利用这个文件对数据进行快速的赋值 对于多个用户数据的存储的时候我们要用这个XML来进行存储 关于这些特殊文件,我们主要学什么 了解他们的特点&…...

新型信息基础设施IP追溯:保护隐私与网络安全的平衡
随着信息技术的飞速发展,新型信息基础设施在全球范围内日益普及,互联网已经成为我们社会和经济生活中不可或缺的一部分。然而,随着网络使用的增加,隐私和网络安全问题也引发了广泛关注。在这个背景下,IP(In…...

django 实现:闭包表—树状结构
闭包表—树状结构数据的数据库表设计 闭包表模型 闭包表(Closure Table)是一种通过空间换时间的模型,它是用一个专门的关系表(其实这也是我们推荐的归一化方式)来记录树上节点之间的层级关系以及距离。 场景 我们 …...

Redis与分布式-集群搭建
接上文 Redis与分布式-哨兵模式 1. 集群搭建 搭建简单的redis集群,创建6个配置,开启集群模式,将之前配置过的redis删除,重新复制6份 针对主节点redis 1,redis 2,redis 3都是以上修改内容,只是…...
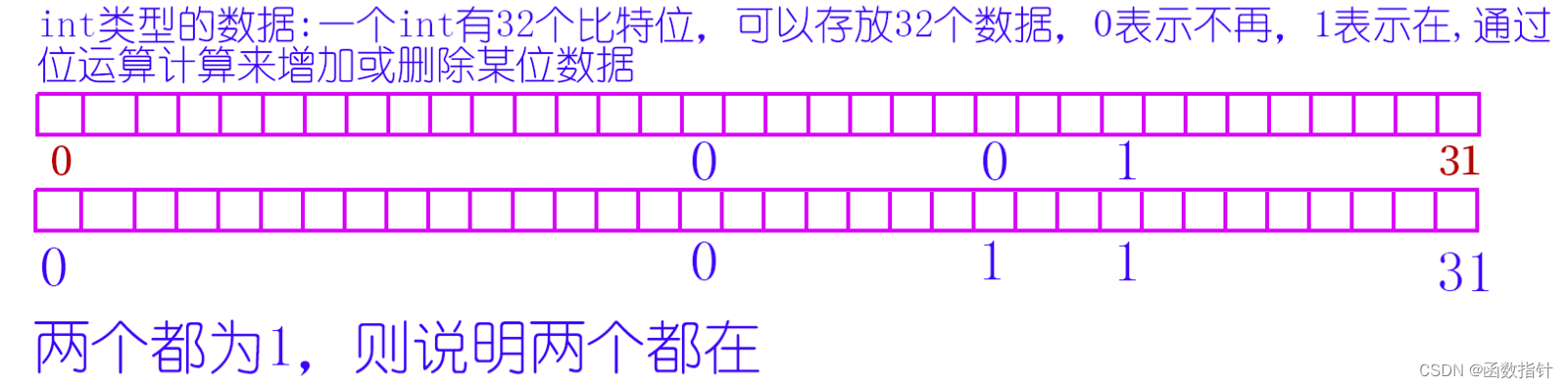
C++--位图和布隆过滤器
1.什么是位图 所谓位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用来判断某个数据存不存在的。比如int 有32位,就可以存放0到31这32个数字在不在某个文件中。当然,其他类型也可以。 2.位…...

linux常识
目录 i.mx6ull开发板配置ip 静态IP配置 命令行配置 配置文件配置 动态IP配置 命令行配置 配置文件配置 为什么编译驱动程序之前要先编译内核? init系统服务 systemv守护进程 systemd守护进程 i.mx6ull开发板配置ip i.mx6ull有两个网卡(eth0和…...

Codeforces Round 901 (Div. 1) B. Jellyfish and Math(思维题/bfs)
题目 t(t<1e5)组样例,每次给出a,b,c,d,m(0<a,b,c,d,m<2的30次方) 初始时,(x,y)(a,b),每次操作,你可以执行以下四种操作之一 ①xx&y,&为与 ②xx|y,|为或 ③yx^y,^为异或 …...
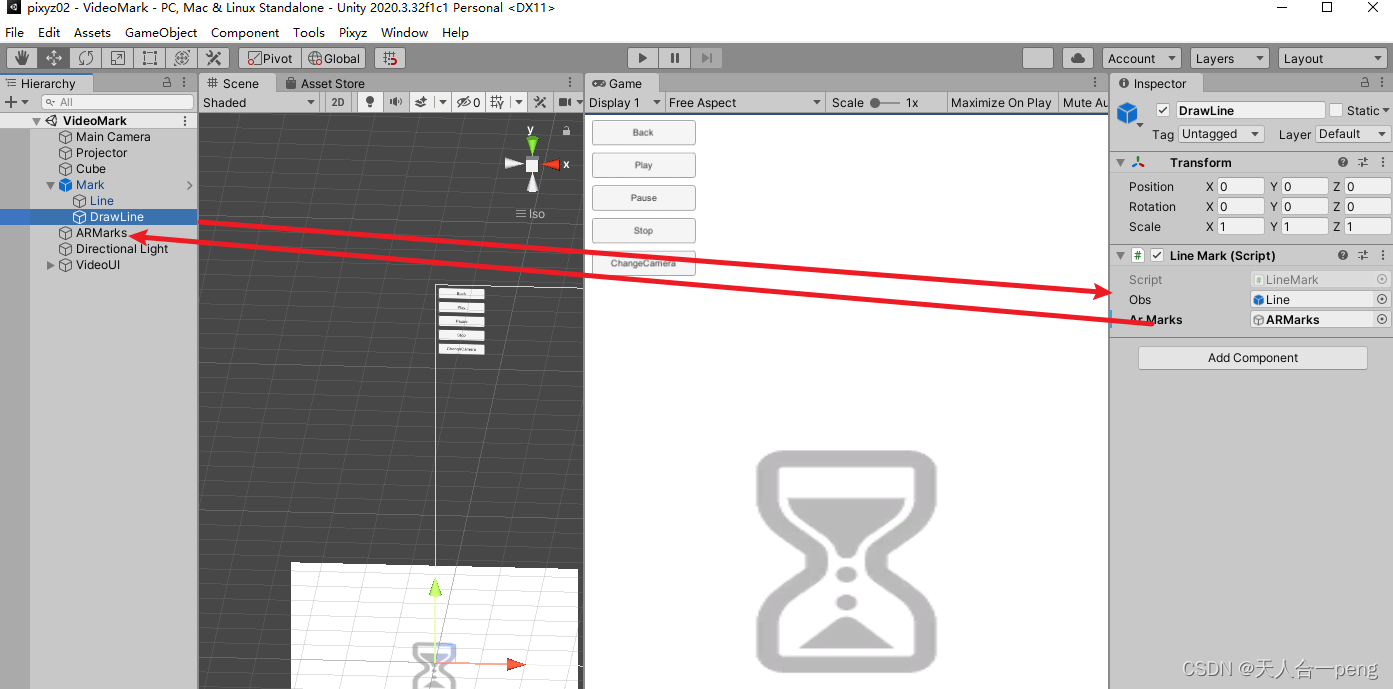
unity 鼠标标记 左键长按生成标记右键长按清除标记,对象转化为子物体
linerender的标记参考 unity linerenderer在Game窗口中任意画线_游戏内编辑linerender-CSDN博客 让生成的标记转化为ARMarks游戏对象的子物体 LineMark.cs using System.Collections; using System.Collections.Generic; using UnityEngine;public class LineMark : MonoBeh…...
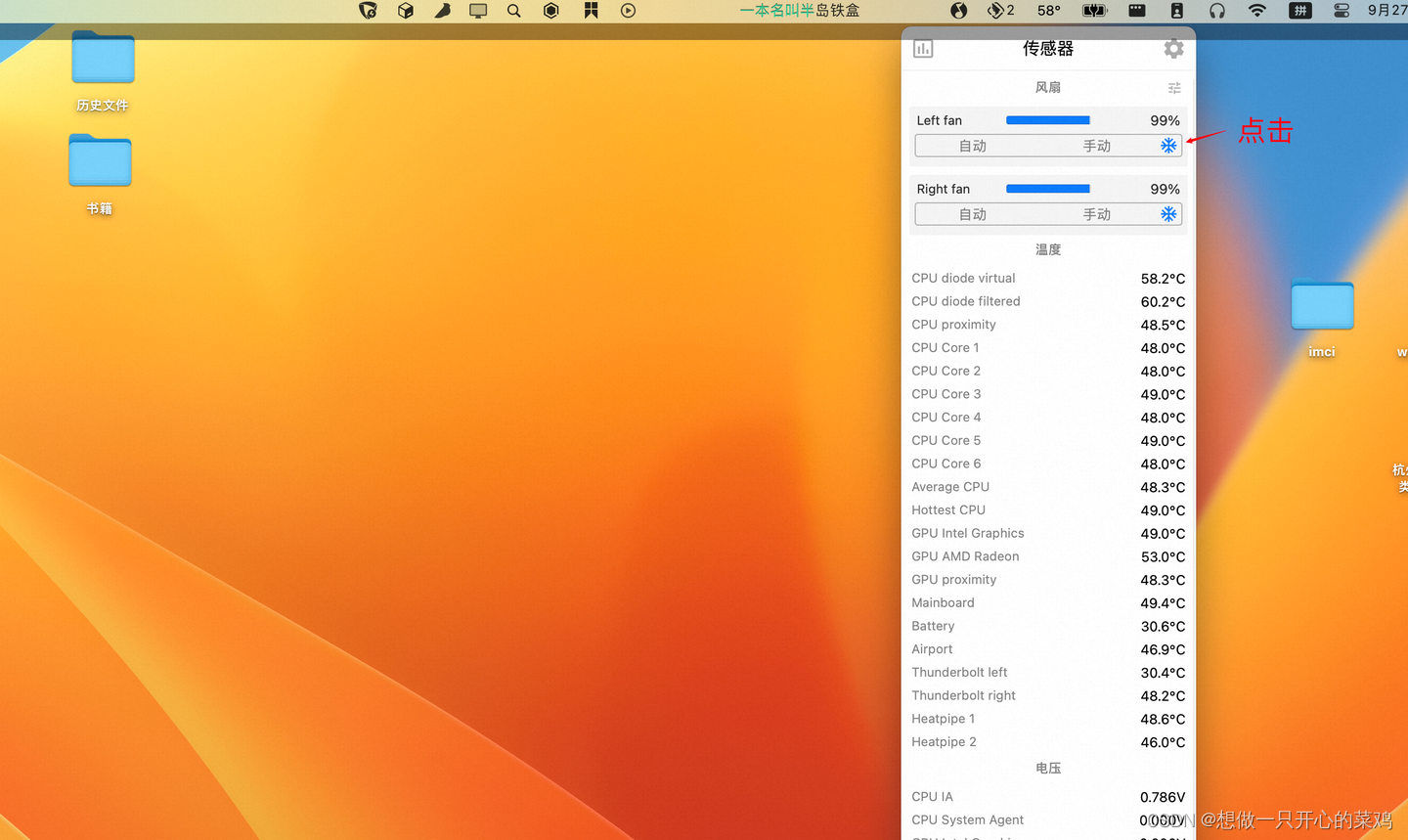
解决mac pro 连接4k显示器严重发烫、卡顿问题
介绍个不用花钱的方法。其实mac自带的风扇散热能力还可以的,但是默认比较懒散,可以用一个软件来控制下,激发下它的潜能。 可以下个stats软件 打开传感器开关,以及同步控制风扇开关 以及cpu显示温度 点击控制台上的温度图标&…...
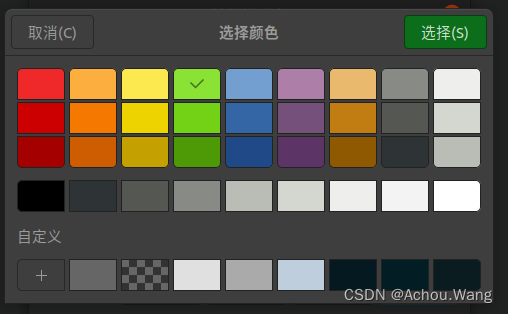
QT的ui设计中改变样式表的用法
在QT的ui设计中,我们右键会弹出一个改变样式表的选项,很多人不知道这个是干什么的。 首先我们来看下具体的界面 首先我们说一下这个功能具体是干嘛的, 我们在设置很多控件在界面上之后,常常都是使用系统默认的样式,但是当有些时候为了美化界面我们需要对一些控件进行美化…...
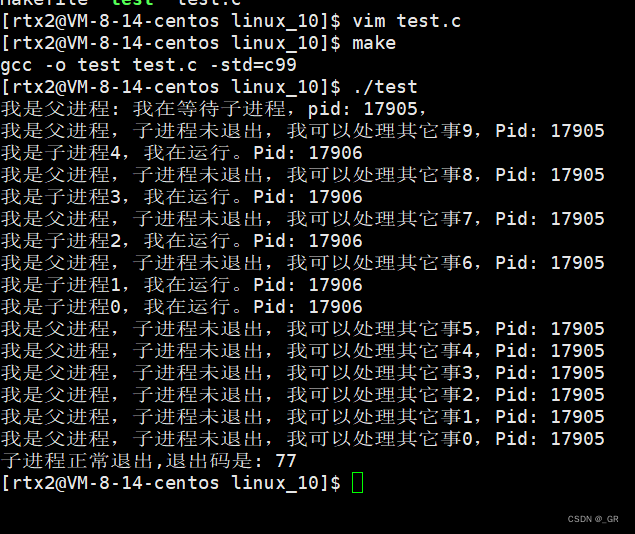
零基础Linux_10(进程)进程终止(main函数的返回值)+进程等待
目录 1. 进程终止 1.1 main函数的返回值 1.2 进程退出码和错误码 1.3 进程终止的常见方法 2. 进程等待 2.1 进程等待的原因 2.2 wait 函数 2.3 waitpid 函数 2.4 int* status参数 2.5 int options非阻塞等待 本篇完。 1. 进程终止 进程终止指的就是程序执行结束了&…...

【已解决】opencv 交叉编译 ffmpeg选项始终为NO
一、opencv 交叉编译没有 ffmpeg ,会导致视频打不开 在交叉编译时候,发现在 pc 端能用 opencv 打开的视频,但是在 rv1126 上打不开。在网上查了很久,原因可能是 交叉编译过程 ffmpeg 造成的。之前 ffmpeg 是直接用 apt 安装的&am…...

rust生命期
一、生命期是什么 生命期,又叫生存期,就是变量的有效期。 实例1 {let r;{let x 5;r &x;}println!("r: {}", r); }编译错误,原因是r所引用的值已经被释放。 上图中的绿色范围’a表示r的生命期,蓝色范围’b表示…...

实现将一张图片中的目标图片抠出来
要在python中实现将一张图片中的目标图片裁剪出来,需要用到图像处理及机器学习库,以下是一个常用的基本框架 加载图片并使用OpenCV库将其转换为灰度图像 import cv2img cv2.imread(screenshot.jpg) gray cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)准备模…...

Rust 使用Cargo
Rust 使用技巧 Rust 使用crates 假设你正在编写一个 Rust 程序,要使用一个名为 rand 的第三方库来生成随机数。首先,你需要在 Cargo.toml 文件中添加以下依赖项: toml [dependencies] rand "0.7.3" 然后运行 cargo build&…...

【k8s】集群搭建篇
文章目录 搭建kubernetes集群kubeadm初始化操作安装软件(master、所有node节点)Kubernetes Master初始化Kubernetes Node加入集群部署 CNI 网络插件测试 kubernetes 集群停止服务并删除原来的配置 二进制搭建(单master集群)初始化操作部署etcd集群安装Docker部署master节点解压…...

10.1select并发服务器以及客户端
服务器: #include<myhead.h>//do-while只是为了不让花括号单独存在,并不循环 #define ERR_MSG(msg) do{\fprintf(stderr,"%d:",__LINE__);\perror(msg);\ }while(0);#define PORT 8888//端口号1024-49151 #define IP "192.168.2.5…...

基于Python的流浪动物救助平台毕业设计
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Python的流浪动物救助平台,以实现流浪动物的有效救助与管理工作。具体研究目的如下: 首先,通过构建流…...

YOLOv7剪枝实战:5种高效剪枝方法对比与代码实现
YOLOv7剪枝实战:5种高效剪枝方法对比与代码实现 在目标检测领域,YOLOv7以其卓越的速度-精度平衡成为工业界宠儿。但当我们将模型部署到边缘设备或需要高吞吐量的生产环境时,原始模型的计算量和参数量往往成为瓶颈。这时,模型剪枝技…...

H3C无线调优案例
用户报无线经常掉线,用户现场无线用的H3C 首先登录无线控制器搜集对应接入体验差的AP的诊断日志,从日志中可以看到AP有线上行口的组播广播包数量远远超过了单播报文;没有CRC错误报文,说明网线质量没有问题。接着看:我们…...

AI辅助开发深度探索:在快马平台上对比评测类qoderwork官网的AI代码生成能力
最近在研究AI辅助开发时,发现一个很有意思的现象:同样是生成一个网页项目,不同AI模型给出的代码风格和实现思路差异很大。这让我萌生了一个想法——能不能搭建一个平台,专门用来对比评测不同AI模型的代码生成能力?就像…...
)
在Ubuntu 20.04上搞定OpenFace:一份保姆级安装与避坑指南(含CEN模型和虚拟显示配置)
在Ubuntu 20.04服务器上部署OpenFace的终极实践指南 当你第一次尝试在无图形界面的Ubuntu服务器上部署OpenFace时,是否遇到过那些令人抓狂的报错信息?从缺失的CEN模型到GTK显示问题,每一步都可能成为阻碍你前进的绊脚石。本文将带你穿越这些技…...

从预处理指令看跨语言兼容:手把手封装C++库供C调用的5个关键步骤
从预处理指令看跨语言兼容:手把手封装C库供C调用的5个关键步骤 在嵌入式开发和SDK设计中,经常需要将C库封装成C语言接口。这种跨语言调用看似简单,实则暗藏玄机。本文将深入剖析extern "C"和__cplusplus预处理指令的底层原理&#…...

EmbeddingGemma-300m在Mathtype公式的语义理解中的应用
EmbeddingGemma-300m在Mathtype公式的语义理解中的应用 1. 引言 数学公式的语义理解一直是自然语言处理领域的挑战性任务。传统的文本嵌入模型在处理复杂的数学表达式时往往力不从心,无法准确捕捉公式背后的数学含义和逻辑关系。EmbeddingGemma-300m作为Google最新…...

GME-Qwen2-VL-2B效果实测:抽象文字如何匹配具体图片?
GME-Qwen2-VL-2B效果实测:抽象文字如何匹配具体图片? 1. 多模态搜索的突破性体验 想象一下,你脑海中浮现出一句富有哲理的句子:"人生不是裁决书",却想找一张能表达这种意境的图片。传统搜索引擎会怎么做&a…...

Windows下OpenClaw安装指南:对接ollama GLM-4.7-Flash模型
Windows下OpenClaw安装指南:对接ollama GLM-4.7-Flash模型 1. 为什么选择OpenClaw GLM-4.7-Flash组合 作为一个长期在Windows环境下折腾AI工具的开发者,我一直在寻找一个既能保持本地数据隐私,又能灵活对接各类开源模型的自动化框架。Open…...
translategemma-27b-it部署指南:Ollama模型缓存管理与多版本切换实践
translategemma-27b-it部署指南:Ollama模型缓存管理与多版本切换实践 你是不是也遇到过这样的烦恼:好不容易在Ollama上部署了一个大模型,用了一段时间想试试新版本,结果发现硬盘空间告急,或者不知道旧版本模型文件藏在…...