数据结构-哈希表
系列文章目录
1.集合-Collection-CSDN博客
2.集合-List集合-CSDN博客
3.集合-ArrayList源码分析(面试)_喜欢吃animal milk的博客-CSDN博客
4.数据结构-哈希表_喜欢吃animal milk的博客-CSDN博客
文章目录
目录
系列文章目录
文章目录
前言
一 . 什么是哈希表?
哈希碰撞
冲突避免
冲突解决
1.闭散列
1.1线性探测
编辑
1.2 二元探测
2.开散列
二 . 代码实现
前言
大家好,今天给大家介绍一下哈希表相关内容以及模拟实现
一 . 什么是哈希表?
哈希表(Hash Table),也称为散列表,是一种根据关键码值(Key)而直接进行访问的数据结构。它通过将关键码值映射到表中的一个位置来访问记录,以加快查找的速度。
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即,搜索的效率取决于搜索过程中元素的比较次数。
哈希表的基本思想是利用哈希函数将关键码值映射到表中的一个位置,然后在该位置上进行查找或插入操作。哈希函数将关键码值映射到表中的位置时,应该尽量避免冲突,即不同的关键码值映射到同一个位置。当两个不同的关键码值映射到同一个位置时,称为哈希冲突。
解决哈希冲突的常用方法有两种:
-
开放定址法:当发生冲突时,通过一定的规则找到下一个空的位置,将冲突的元素放到该位置。常见的开放定址法有线性探测法、二次探测法和双重哈希法。
-
链地址法:将哈希表的每个位置都设置为一个链表,当发生冲突时,将冲突的元素插入到链表中。链地址法可以处理任意数量的冲突,但是需要额外的空间来存储链表。
哈希表的优点是可以快速地进行插入、删除和查找操作,平均时间复杂度为 O(1)。但是它也有一些缺点,如哈希冲突的处理和空间的浪费等。
例如:数据集合{1,7,6,4,5,9}; 哈希函数设置为:hash(key) = key % capacity; capacity为存储元素底层空间总的大小。
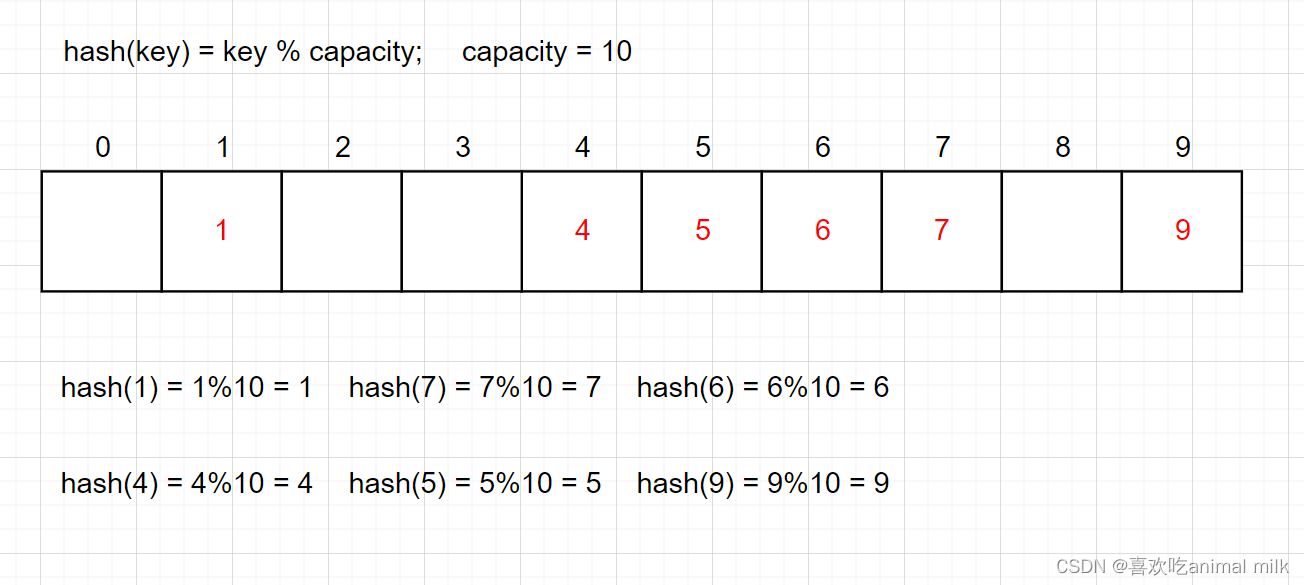
哈希碰撞
对于两个数据元素的关键字 Ki 和 Kj (i != j),有 Ki != Kj,但有:Hash(Ki ) == Hash(Kj ),即:不同关键字通过相同哈 希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
想象一下,如果在上面的哈希表中插入44 hash(44) = 44%10 = 4 这个时候该怎么解决?
还记得上面提到的解决方法吗?
冲突避免
负载因子(Load Factor)是指哈希表中已存储元素个数与哈希表大小之比。它可以用来衡量哈希表的空间利用率。
负载因子的计算公式为:负载因子 = 已存储元素个数 / 哈希表大小。
负载因子的大小会影响哈希表的性能和空间利用率。当负载因子较小时,表示哈希表中的元素较少,空间利用率较低,但是哈希表的性能可能较好,因为冲突的概率较低。当负载因子较大时,表示哈希表中的元素较多,空间利用率较高,但是哈希表的性能可能较差,因为冲突的概率较高。
通常情况下,负载因子的取值范围是 0 到 1,可以根据实际情况进行调整。一般来说,当负载因子超过某个阈值(如 0.75),就需要进行扩容操作,以保证哈希表的性能。扩容操作会重新计算哈希函数和重新分配存储空间,因此会引起一定的开销。
在实际应用中,选择合适的负载因子可以平衡哈希表的性能和空间利用率。较小的负载因子可以提高性能,但会浪费空间;较大的负载因子可以提高空间利用率,但会降低性能。因此,需要根据具体的应用场景和需求来选择合适的负载因子。
冲突解决
1.闭散列
也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以 把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置呢?
比如上面的场景,现在需要插入元素44,先通过哈希函数计算哈希地址,下标为4,因此44理论上应该插在该 位置,但是该位置已经放了值为4的元素,即发生哈希冲突。
1.1线性探测
从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
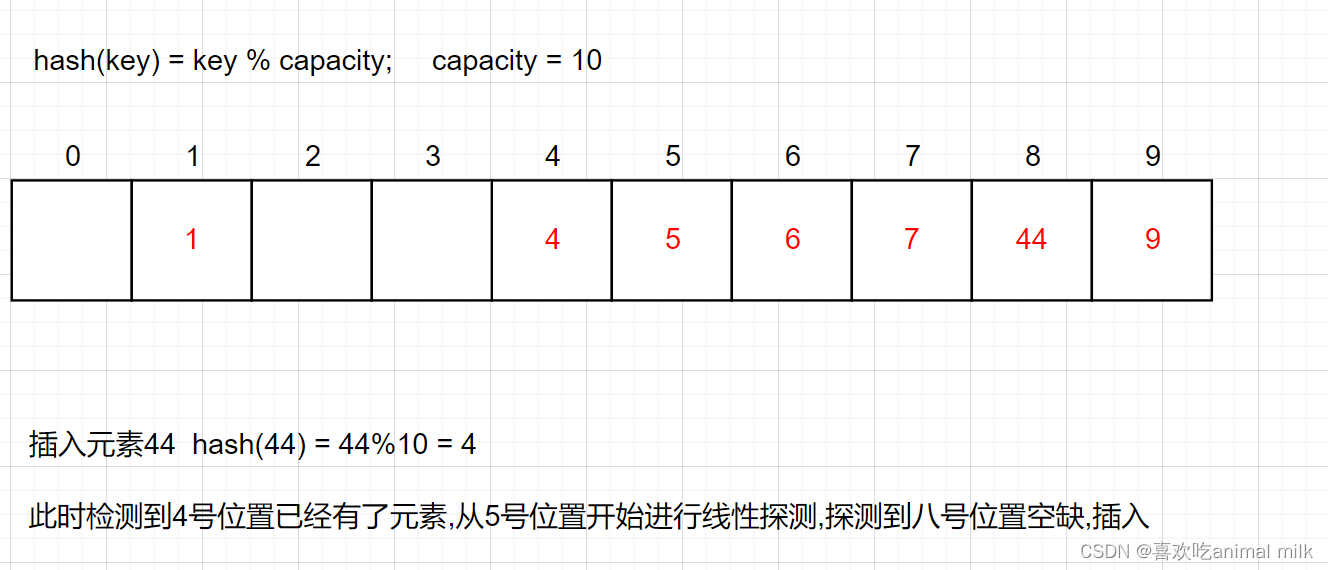
采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他 元素的搜索。比如删除元素4,如果直接删除掉,44查找起来可能会受影响。因此线性探测采用标 记的伪删除法来删除一个元素。
1.2 二元探测
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨 着往后逐个去找。
二元探测步骤:
- 假设哈希表的大小为 capacity,哈希函数将关键码值映射到位置 pos = hash(key) % capacity。
- 如果位置 pos 已经被占用,即发生了哈希冲突,那么继续探测下一个位置。
- 下一个位置的计算公式为 pos = (pos + i^2) % capacity,其中 i 是探测的次数。
- 如果下一个位置仍然被占用,继续增加 i 的值,继续探测下一个位置,直到找到一个空的位置
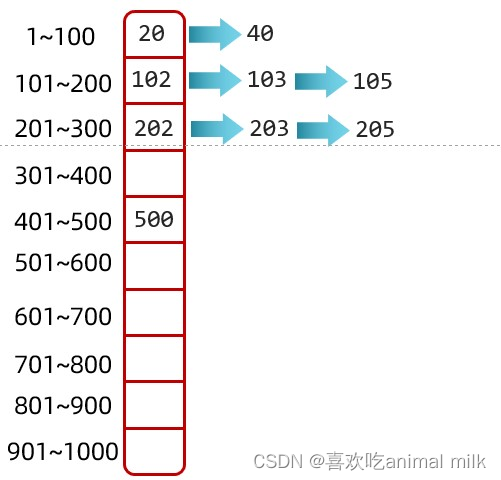
2.开散列
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子 集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
二 . 代码实现
案例: 使用哈希表管理员工
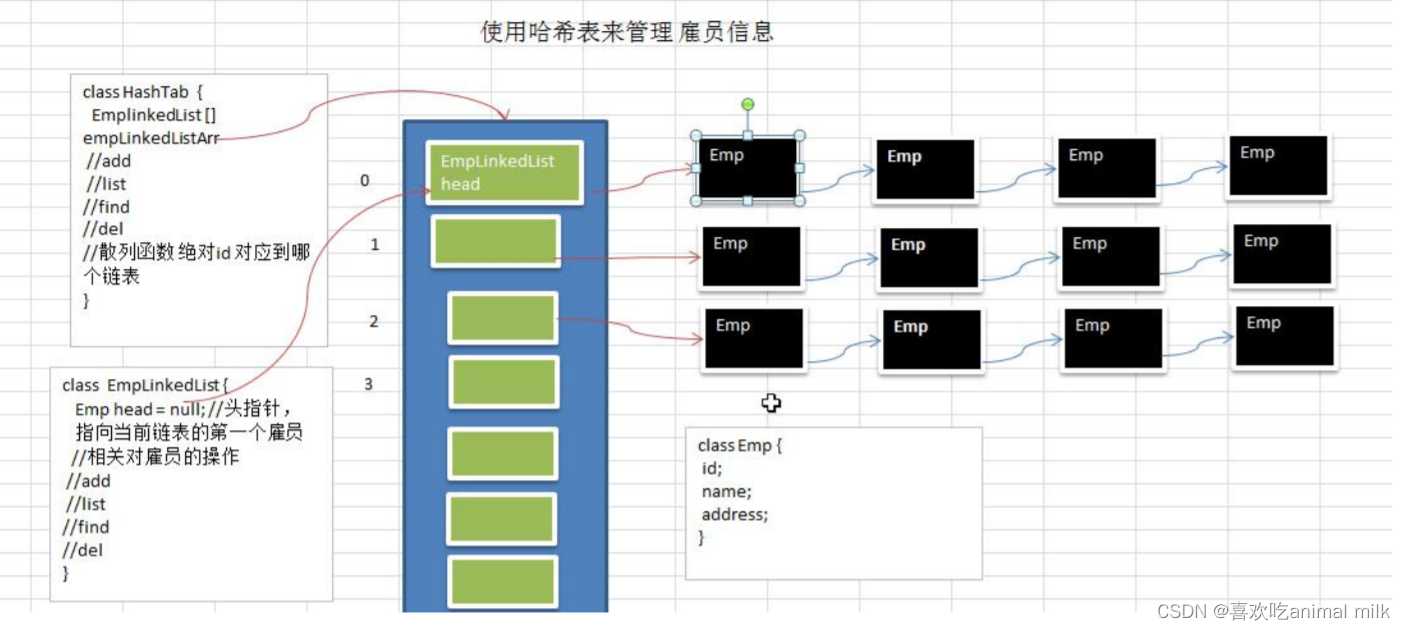
Emp
public class Emp {public int id;public String name;public Emp next;// 默认为空public Emp(int id,String name){super();this.id = id;this.name = name;}
}
EmpLikedList
// 表示链表,存放数据
public class EmpLikedList {private Emp head;// 头指针,指向当前链表的第一个雇员// 添加雇员// 假定id自增长,直接尾增public void add(Emp emp){if(head == null){head = emp;return;}Emp cur = head;while(cur.next != null){cur = cur.next;}cur.next = emp;}// 遍历链表的雇员信息public void list(int count){if(head == null){System.out.println("第"+count+"条链表为空");return;}System.out.println("第"+count+"条链表的信息为");Emp cur = head;while(cur != null){if(cur.next == null){System.out.printf("(id = %d name = %s)\n",cur.id,cur.name);return;}System.out.printf("(id = %d name = %s)=>",cur.id,cur.name);cur = cur.next;}}// 通过id查找对应的雇员public Emp findEmp(int id){Emp cur = head;while(true){if(cur == null){System.out.println("雇员不存在");return null;}if(cur.id == id){return cur;}cur = cur.next;}}
}HashTable
// 创建 HashTable 管理多条链表
public class HashTable {// 盛放链表的数组,即哈希表EmpLikedList[] EmpLikedListArr;public int capacity;// 构造器,制定链表数量public HashTable(int capacity){this.capacity = capacity;EmpLikedListArr = new EmpLikedList[capacity];// 初始化一把,不然直接报空指针异常for (int i = 0; i < capacity; i++) {EmpLikedListArr[i] = new EmpLikedList();}}// 添加public void add(Emp emp){// 根据员工id确定员工应该在哪个链表EmpLikedListArr[HashFunction(emp.id)].add(emp);}// 遍历所有的链表public void list(){int count = 0;while (count < capacity) {EmpLikedListArr[count].list(count);count++;}}// 根据Id查找对应的雇员public void findEmp(int id){int count = HashFunction(id);Emp emp = EmpLikedListArr[count].findEmp(id);if(emp == null){System.out.println("没有找到该雇员");}else{System.out.println("找到了该雇员,在第"+count+"条链表中"+"id = "+id);}}// 散列函数 取模法public int HashFunction(int no){return no%capacity;}}相关文章:
数据结构-哈希表
系列文章目录 1.集合-Collection-CSDN博客 2.集合-List集合-CSDN博客 3.集合-ArrayList源码分析(面试)_喜欢吃animal milk的博客-CSDN博客 4.数据结构-哈希表_喜欢吃animal milk的博客-CSDN博客 文章目录 目录 系列文章目录 文章目录 前言 一 . 什么是哈希表&a…...

深度学习在图像识别领域还有哪些应用?
深度学习在图像识别领域的应用非常广泛,除了之前提到的图像分类、目标检测、语义分割和图像生成,还有其他一些应用。 图像超分辨率重建:深度学习技术可以用于提高图像的分辨率,例如通过使用生成对抗网络(GANÿ…...
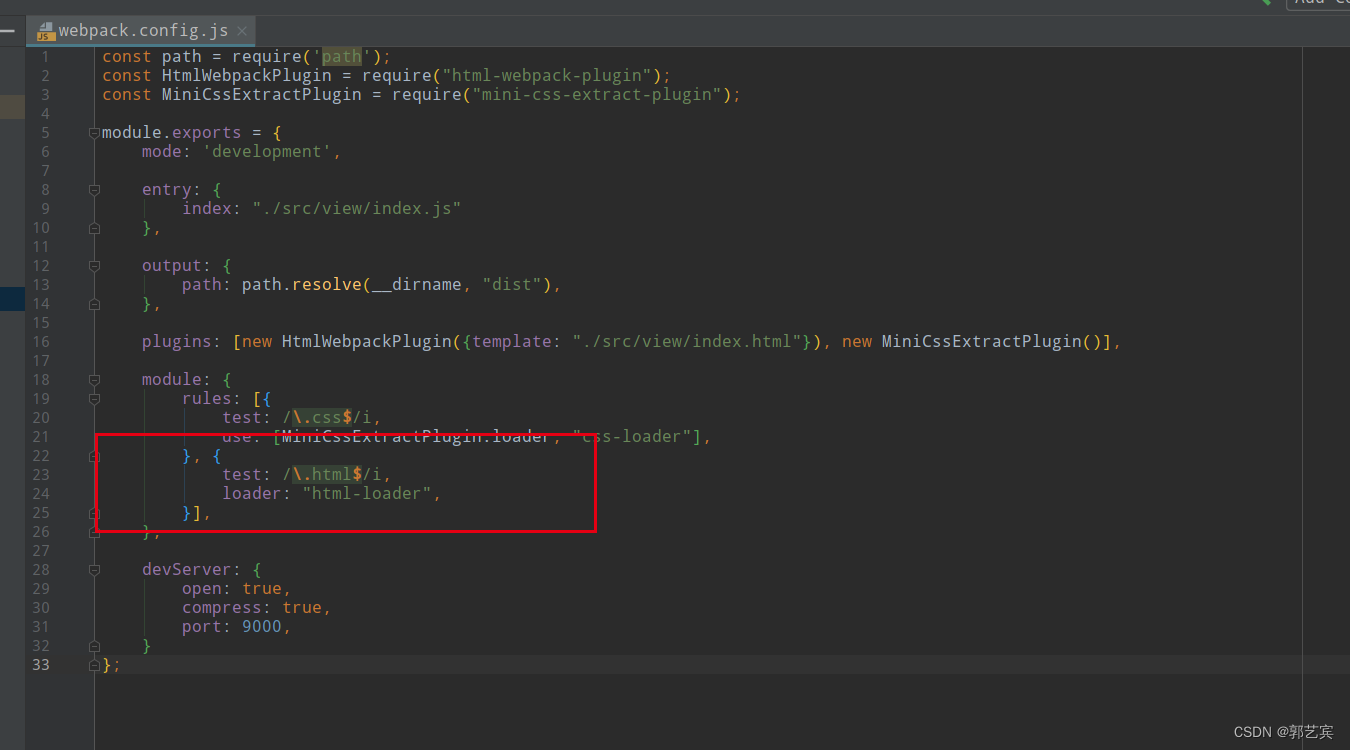
前端项目练习(练习-005-webpack-03)
学习前,首先,创建一个web-005项目,内容和web-004一样。(注意将package.json中的name改为web-005) 前面的代码中,打包工作已经基本完成了,下面开始在本地启动项目。这里需要用到webpack-dev-serv…...

『力扣每日一题10』:字符串中的单词数
因为身体原因,再加上学校的 DeadLine 比较多,太忙太累,拖更了半个月。现在开始重拾日更,期待我们一起遇见更好的自己! 一、题目 统计字符串中的单词个数,这里的单词指的是连续的不是空格的字符。 请注意&a…...

初级篇—第三章多表查询
文章目录 为什么需要多表查询一个案例引发的多表连接初代查询笛卡尔积(或交叉连接)的理解 多表查询分类等值连接 vs 非等值连接自连接 vs 非自连接内连接VS外连接 SQL99语法实现多表查询内连接的实现外连接的实现左外连接右外连接满外连接 UNION的使用7种…...
<Xcode> Xcode IOS无开发者账号打包和分发
关于flutter我们前边聊到的初入门、数据解析、适配、安卓打包、ios端的开发和黑苹果环境部署,但是对于苹果的打包和分发,我只是给大家了一个链接,作为一个顶级好男人,我认为这样是对大家的不负责任,那么这篇就主要是针…...

vertx的学习总结2
一、什么是verticle verticle是vertx的基本单元,其作用就是封装用于处理事件的技术功能单元 (如果不能理解,到后面的实战就可以理解了) 二、写一个verticle 1. 引入依赖(这里用的是gradle,不会吧&#…...
网络安全内网渗透之DNS隧道实验--dnscat2直连模式
目录 一、DNS隧道攻击原理 二、DNS隧道工具 (一)安装dnscat2服务端 (二)启动服务器端 (三)在目标机器上安装客户端 (四)反弹shell 一、DNS隧道攻击原理 在进行DNS查询时&#x…...

探索ClickHouse——连接Kafka和Clickhouse
安装Kafka 新增用户 sudo adduser kafka sudo adduser kafka sudo su -l kafka安装JDK sudo apt-get install openjdk-8-jre下载解压kafka 可以从https://downloads.apache.org/kafka/下找到希望安装的版本。需要注意的是,不要下载路径包含src的包,否…...

基于监督学习的多模态MRI脑肿瘤分割,使用来自超体素的纹理特征(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
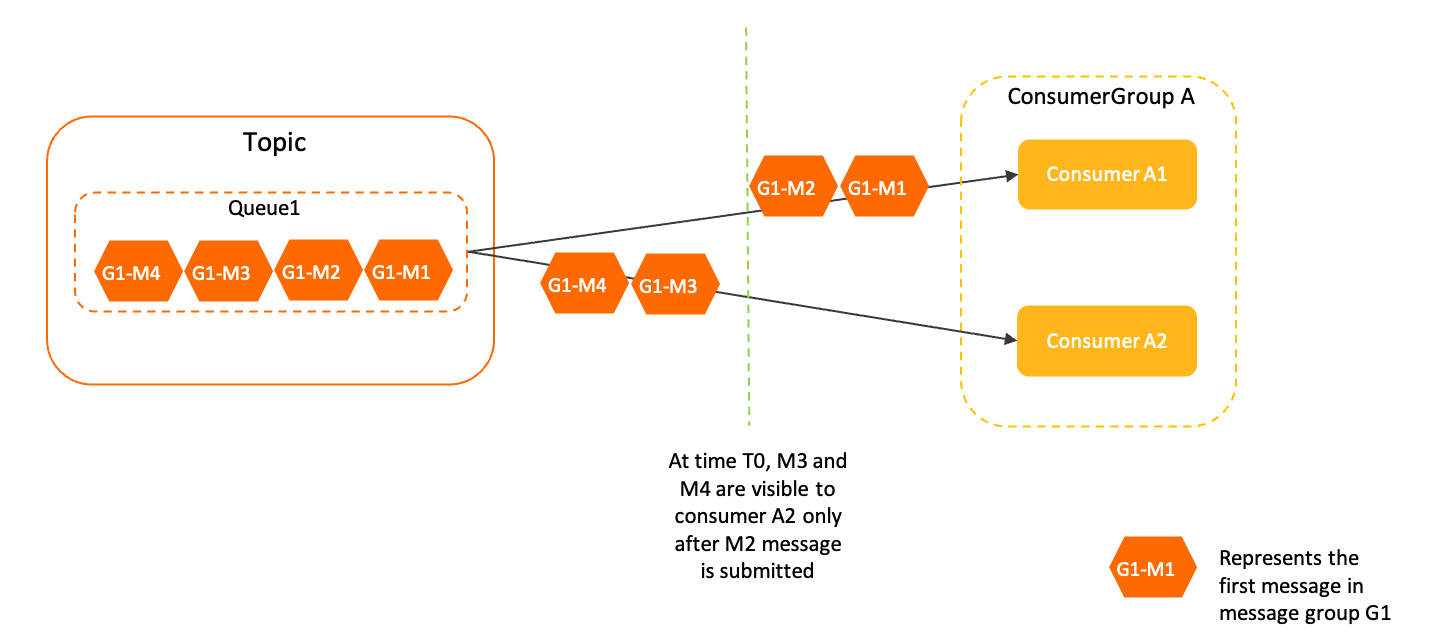
【RocketMQ】(八)Rebalance负载均衡
消费者负载均衡,是指为消费组下的每个消费者分配订阅主题下的消费队列,分配了消费队列消费者就可以知道去消费哪个消费队列上面的消息,这里针对集群模式,因为广播模式,所有的消息队列可以被消费组下的每个消费者消费不…...

线性筛和埃氏筛
线性筛: #define _CRT_SECURE_NO_WARNINGS #include<iostream> #include<cstdio> #include<cstdlib> #include<string> #include<cstring> #include<cmath> #include<ctime> #include<algorithm> #include<ut…...

【Java 进阶篇】JDBC ResultSet 类详解
在Java应用程序中,与数据库交互通常涉及执行SQL查询以检索数据。一旦执行查询,您将获得一个ResultSet对象,该对象包含查询结果的数据。本文将深入介绍ResultSet类,它是Java JDBC编程中的一个核心类,用于处理查询结果。…...
)
Centos7常用服务脚本(.service)
Centos7常用服务脚本(.service) 注意:[Service]中配置路径必须使用绝对路径。 启停: systemctl { start | stop | restart | reload } xxx.service 自启动: systemctl { enable | disable } xxx.service nginx.se…...
)
MySQL 视图View的SQL语法和更新(视图篇 二)
视图语法基本操作 创建 -- [ ]表示可选 create [or replace] view 视图名称[(列名列表)] as select语句 [ with [cascaded | local ] check option ]; 添加(虽然视图是虚拟表,但是向视图操作的数据实际上会影响到实际关联的表数据) -- 视图添…...
38 翻转二叉树
翻转二叉树 理解题意,翻转即每个结点的左右子树翻转/对调题解1 递归——自下而上题解2 迭代——自上而下 给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。 提示: 树中节点数目范围在 [0, 100] 内-100 < Node.…...
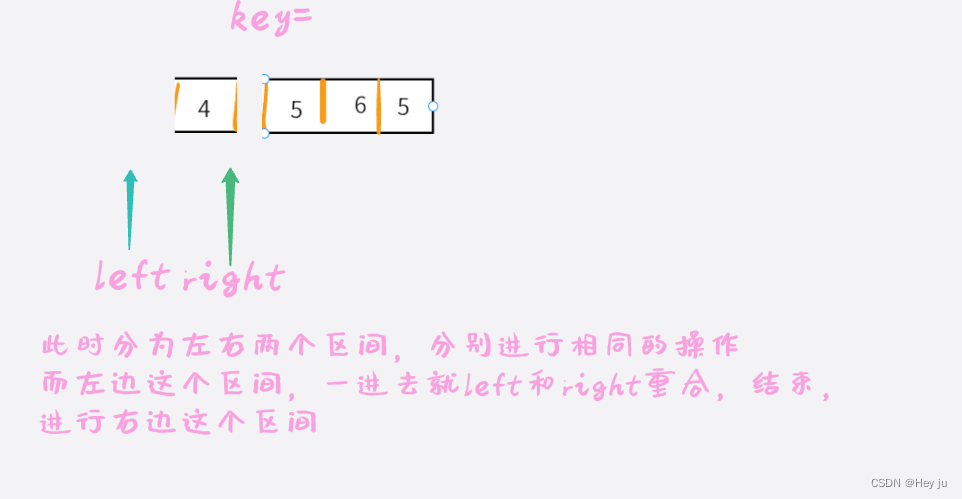
数据结构-快速排序-C语言实现
引言:快速排序作为一种非常经典且高效的排序算法,无论是工作还是面试中广泛用到,作为一种分治思想,需要熟悉递归思想。下面来讲讲快速排序的实现和改进。 老规矩,先用图解来理解一下:(这里使用快…...

玩客云Armbian_23.08.0-trunk_Onecloud_bookworm_edge_6.4.14.burn配置
固定IP # interface file auto-generated by buildrootauto lo iface lo inet loopback// 上面是默认的内容,下面是新增的内容,上下之间需要一个空行隔开 // 接口顶格写,属性的前面有一个tab的缩进 # The primary network interfaceauto eth0 iface eth0 inet staticaddress 1…...

Nginx查找耗时的接口
Nginx查找耗时的接口 # grep 是筛选的域名 awk中的$5是判断的状态码 sort中的15是指的upstream_response_time 当然也可以统计request_time的时间cat access.log | grep zhhll.icu | awk $5 200{print $0} | sort -k 15 -n -r | head -10 https://zhhll.icu/2021/linux/实…...

C++ Primer 一 变量和基本类型
本章讲解C内置的数据类型(如:字符、整型、浮点数等)和自定义数据类型的机制。下一章讲解C标准库里面定义的更加复杂的数据类型,比如可变长字符串和向量等。 1.基本内置类型 C内置的基本类型包括:算术类型和空类型。算…...

Kubernetes多租户架构设计与实践
Kubernetes多租户架构设计与实践 一、引言 多租户是指在同一个Kubernetes集群中为多个用户或团队提供隔离的资源和环境。本文将深入探讨Kubernetes多租户架构的核心概念、实现方法和最佳实践。 二、多租户架构设计 2.1 多租户参考架构 ┌────────────────…...

Gemini实时字幕在Google Meet中延迟超800ms?揭秘谷歌内部SRE监控数据与3步毫秒级调优法
更多请点击: https://intelliparadigm.com 第一章:Gemini实时字幕在Google Meet中延迟超800ms?揭秘谷歌内部SRE监控数据与3步毫秒级调优法 谷歌内部SRE团队近期公开的一组匿名化监控数据显示:在高并发(>500人&…...

Vivado时序约束实战:输入/输出延时设置背后的时序模型与设计考量
1. 时序约束的本质:从理论到实践的桥梁 刚接触FPGA设计时,我最头疼的就是时序约束。那些建立时间、保持时间的概念看得人云里雾里,更别说要在Vivado里实际设置了。直到有一次项目因为时序问题导致整板无法工作,我才真正明白时序约…...

后端开发必看:设计高并发系统时,如何估算你的RTT和时延带宽积?
高并发系统设计实战:从RTT到时延带宽积的性能优化指南 在分布式系统的世界里,网络性能指标往往成为制约整体吞吐量的隐形瓶颈。我曾亲眼见证过一个日活百万的社交平台,因为微服务间调用的RTT估算偏差,导致高峰期请求堆积如山的惨状…...

深度相机三剑客:TOF、双目与结构光的场景化选型指南
1. 深度相机技术入门:从原理到应用 第一次接触深度相机时,我被各种技术名词搞得晕头转向。TOF、双目、结构光听起来都很高大上,但到底有什么区别?经过多年项目实战,我发现这三种技术就像不同的"眼睛"&#…...
)
用微信小程序点灯!STC89C51+ESP8266物联网入门实战(附完整源码)
用微信小程序点灯!STC89C51ESP8266物联网入门实战(附完整源码) 当你第一次看到手机上的按钮能控制真实世界的灯泡时,那种"魔法成真"的震撼感,正是物联网的魅力所在。本文将带你用不到百元的硬件成本…...

让机房管理告别粗放,每一寸资源都物尽其用
对于机房运维人员而言,U 位管理看似是基础小事,却是决定机房运维效率、资产安全与合规水平的关键。当前,不少企业机房、单位机房仍沿用传统人工管理模式,机柜 U 位全靠记忆、台账全靠 Excel、盘点全靠熬夜,看似节省了成…...

S32K144开发板调试实战:除了点灯,如何用S32DS的调试窗口快速排查变量异常问题?
S32K144开发板调试实战:变量异常排查与高效调试技巧 调试嵌入式系统时,最令人头疼的莫过于程序看似正常运行,但某些变量值却莫名其妙地偏离预期。作为一名长期使用S32 Design Studio(S32DS)进行S32K144开发的工程师&a…...
)
告别手敲!手把手教你给STM32CubeIDE 1.3.0装上Keil同款代码补全插件(附成品包)
5分钟极速配置:为STM32CubeIDE注入Keil级代码补全能力 从Keil切换到STM32CubeIDE的开发者,最不适应的莫过于代码补全功能的缺失。每次输入变量名时手动敲击完整字符的体验,让开发效率大打折扣。本文将分享一种无需Java基础、无需手动编译的插…...

2026 年 Redis 面试题全解析:原理 + 实战 + 高频考点
Redis 高频面试题全解析(2026 最新版) Redis 作为后端开发高并发、高可用架构的核心组件,是面试中必问的核心考点。本文从基础入门、核心原理、高并发实战、高可用架构、进阶运维五大模块,整理大厂高频面试题与标准答案ÿ…...