【计算机网络笔记九】I/O 多路复用
阻塞 IO 和 非阻塞 IO
阻塞 I/O 和 非阻塞 I/O 的主要区别:
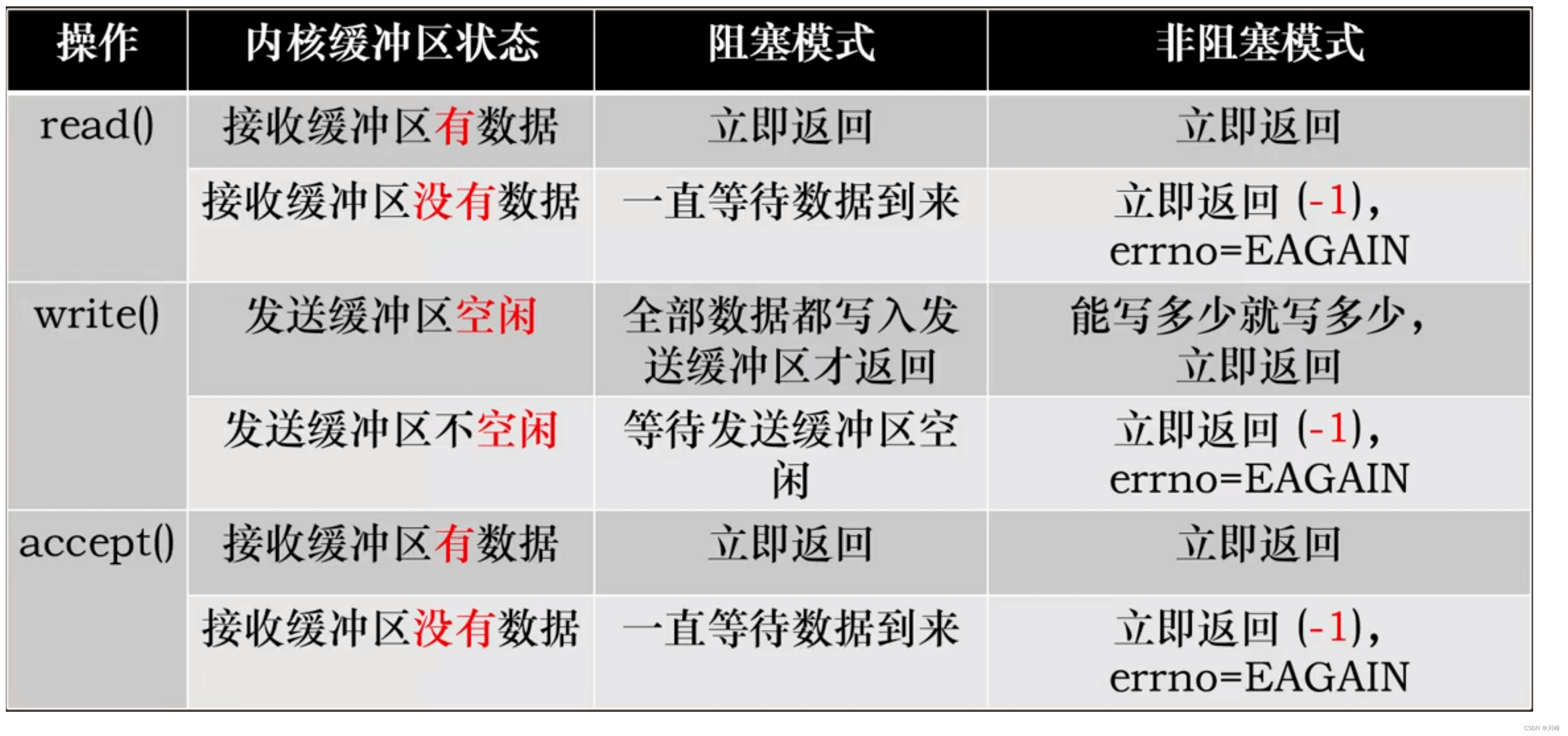
- 阻塞 I/O 执行用户程序操作是同步的,调用线程会被阻塞挂起,会一直等待内核的 I/O 操作完成才返回用户进程,唤醒挂起线程
- 非阻塞 I/O 执行用户程序操作是异步的,读写操作调用后内核会立即返回给用户一个状态值,用户可以立即执行其他操作。
阻塞 IO 模型
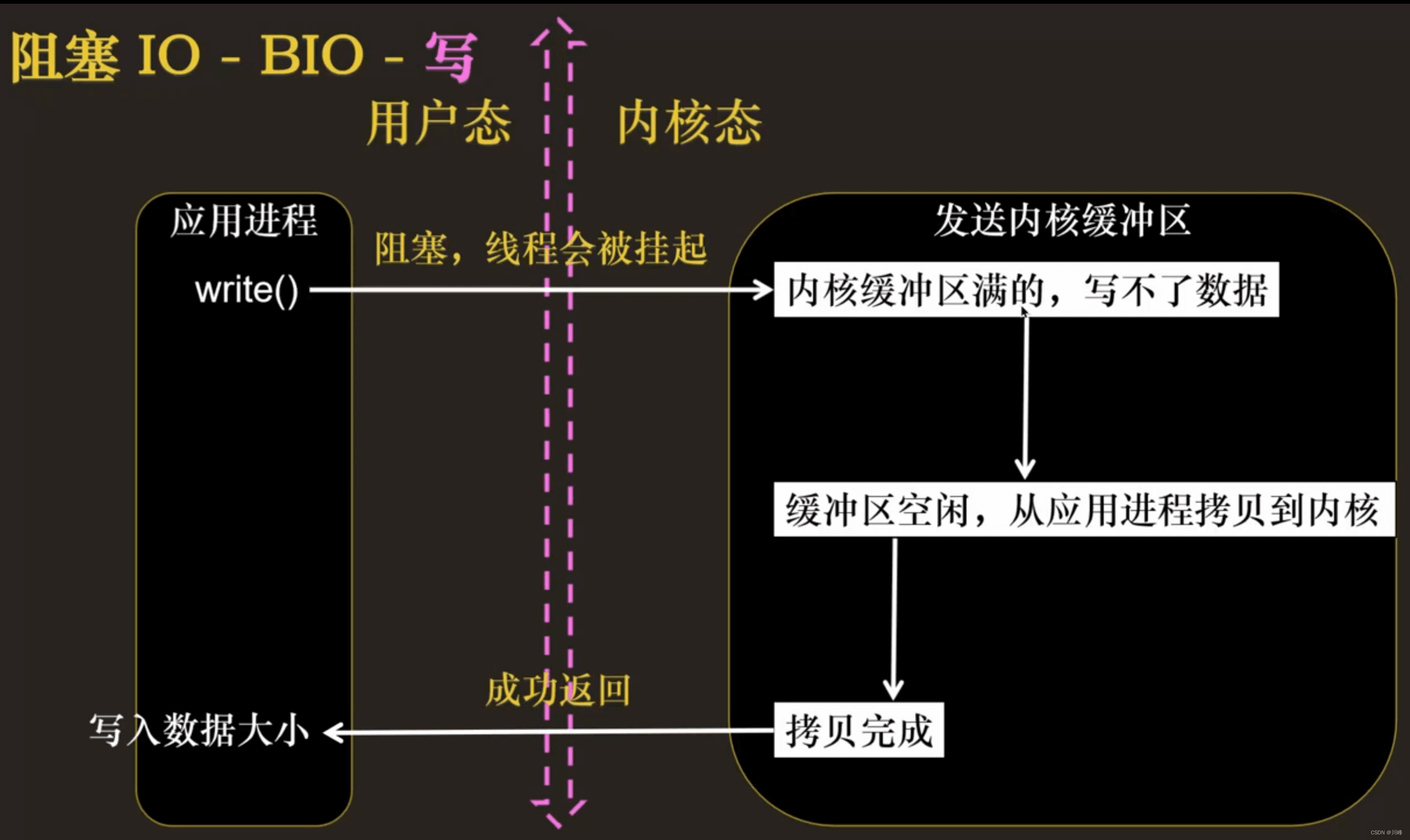
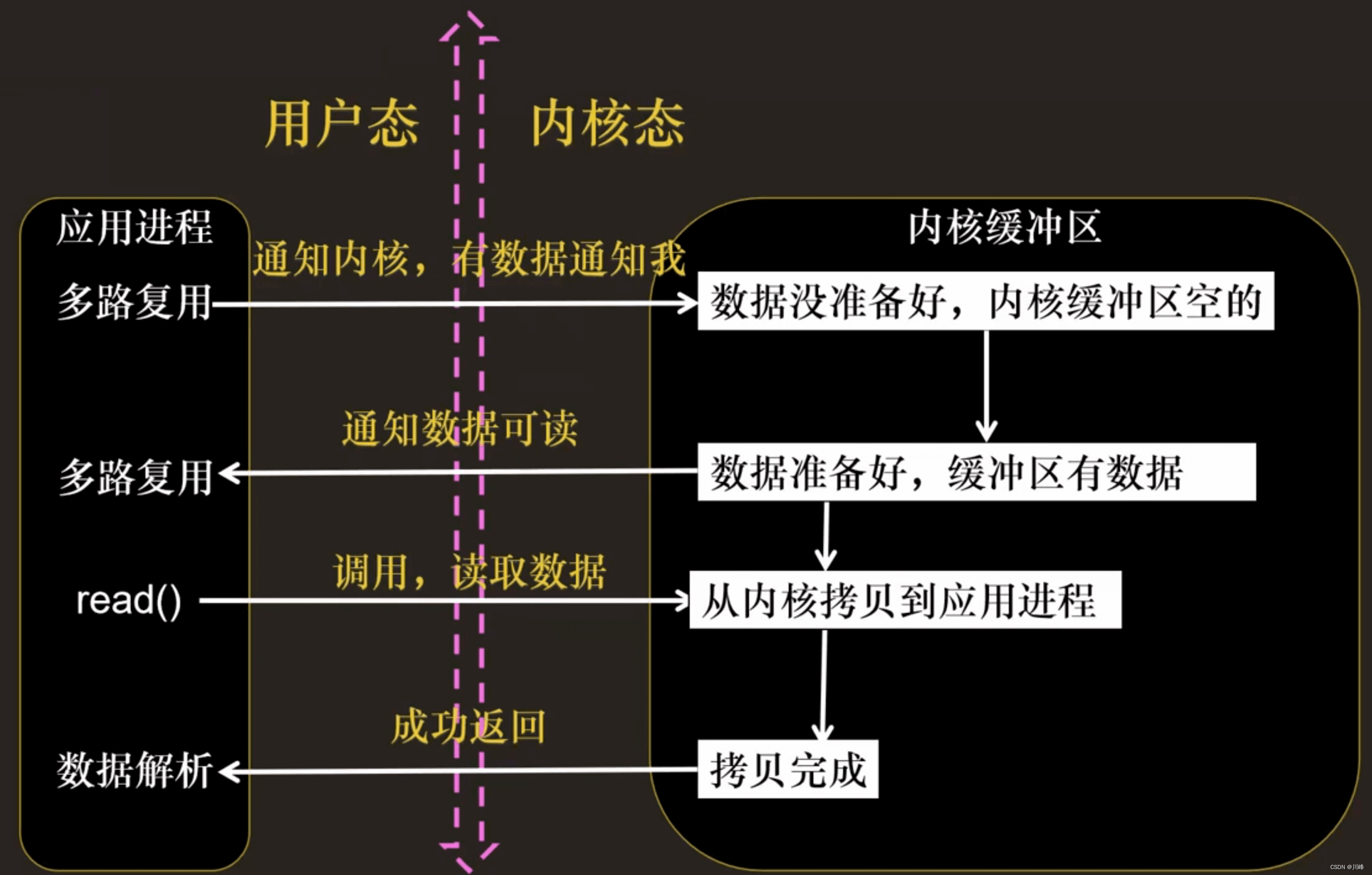
应用程序调用一个 IO 函数,导致应用程序阻塞,等待数据准备好。 如果数据没有准备好,一直等待….数据准备好了,从内核拷贝到用户空间,IO 函数返回成功指示。
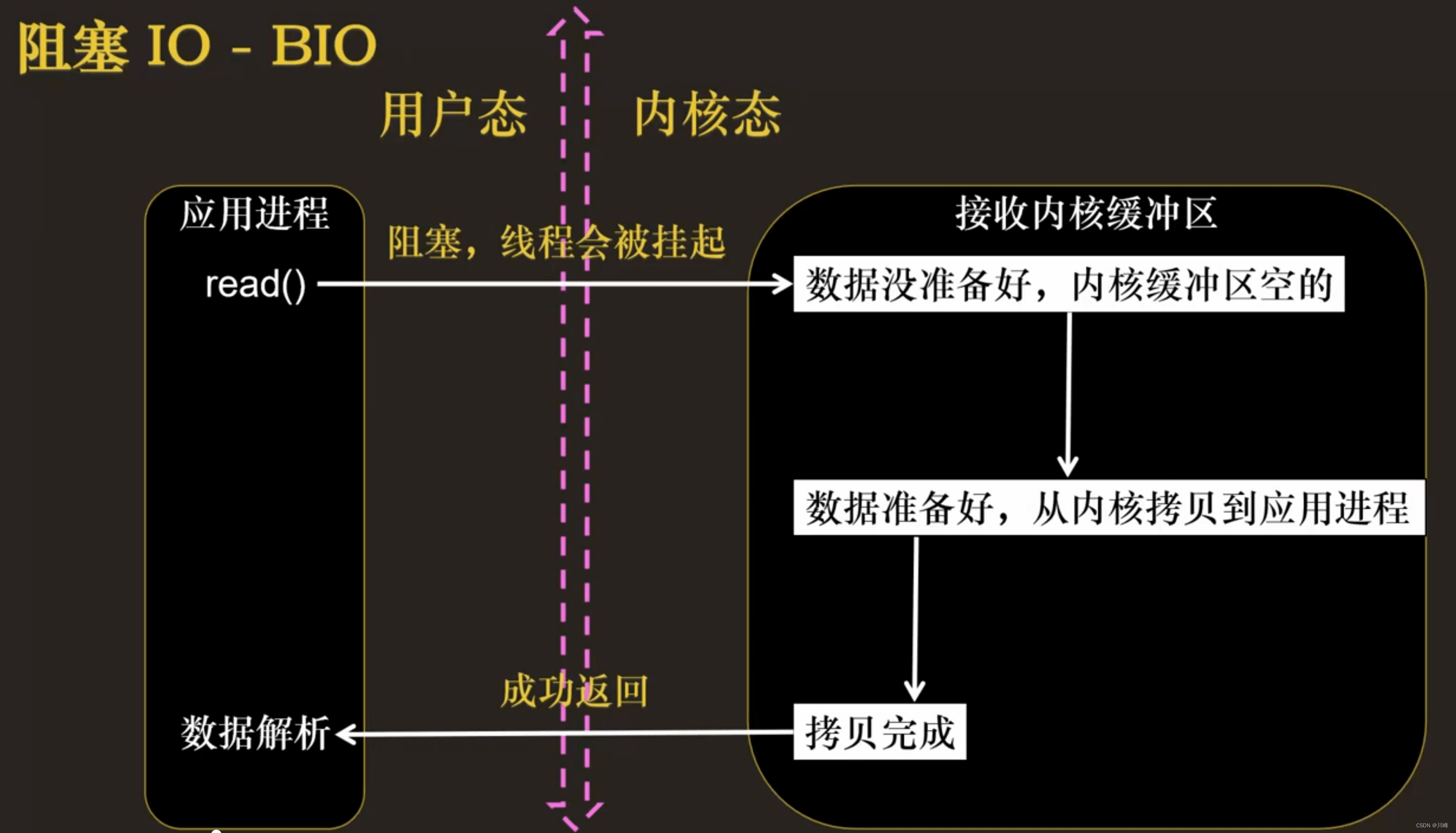
- 当调用 read() 函数时,系统首先查是否有准备好的数据。如果数据没有准备好,那么系统就处于等待状态。当数据准备好后,将数据从系统缓冲区复制到用户空间,然后该函数返回。在套接应用程序中,当调用 read() 函数时,未必用户空间就已经存在数据,那么此时 read() 函数就会处于等待状态。
非阻塞 IO 模型
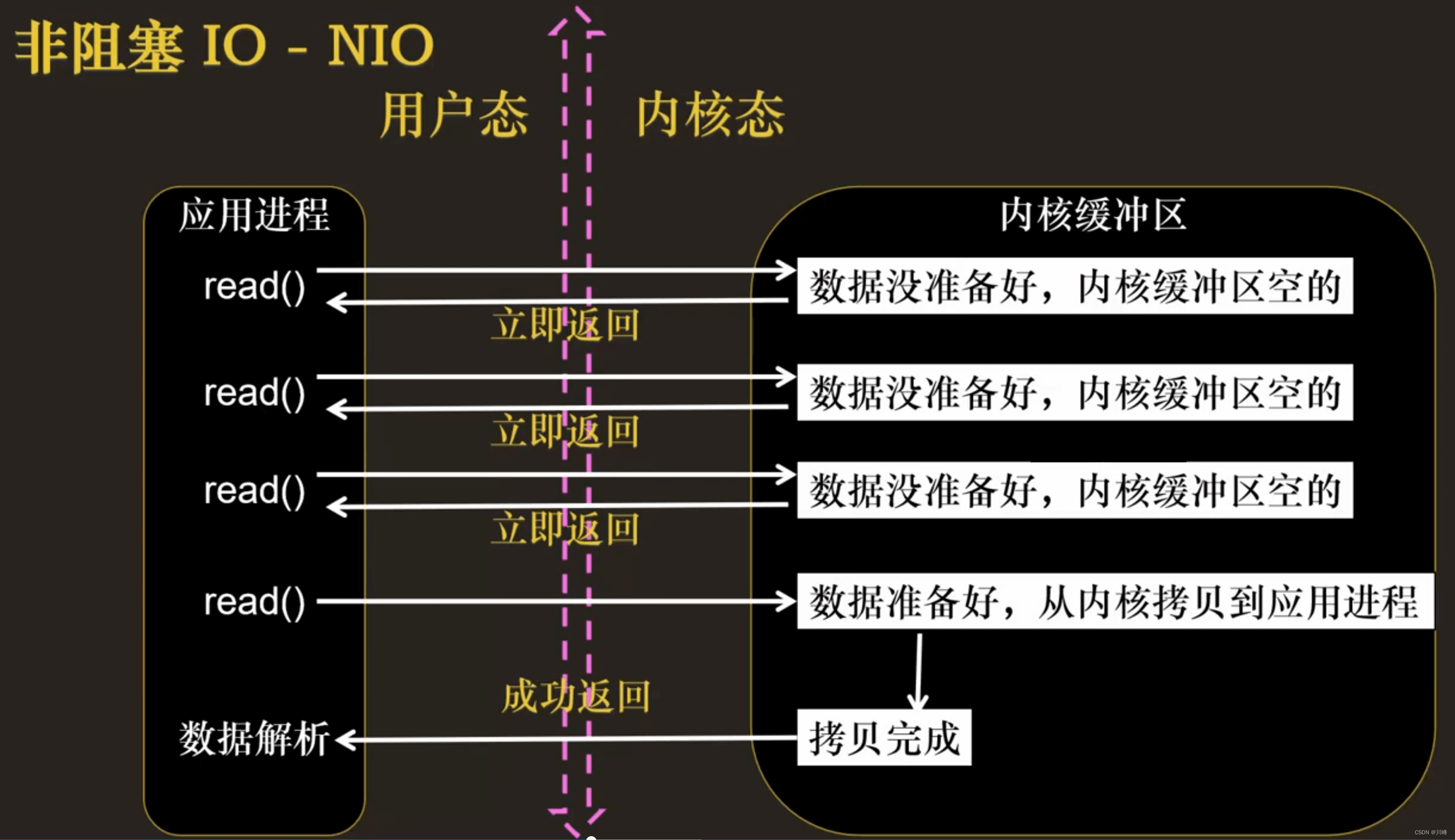
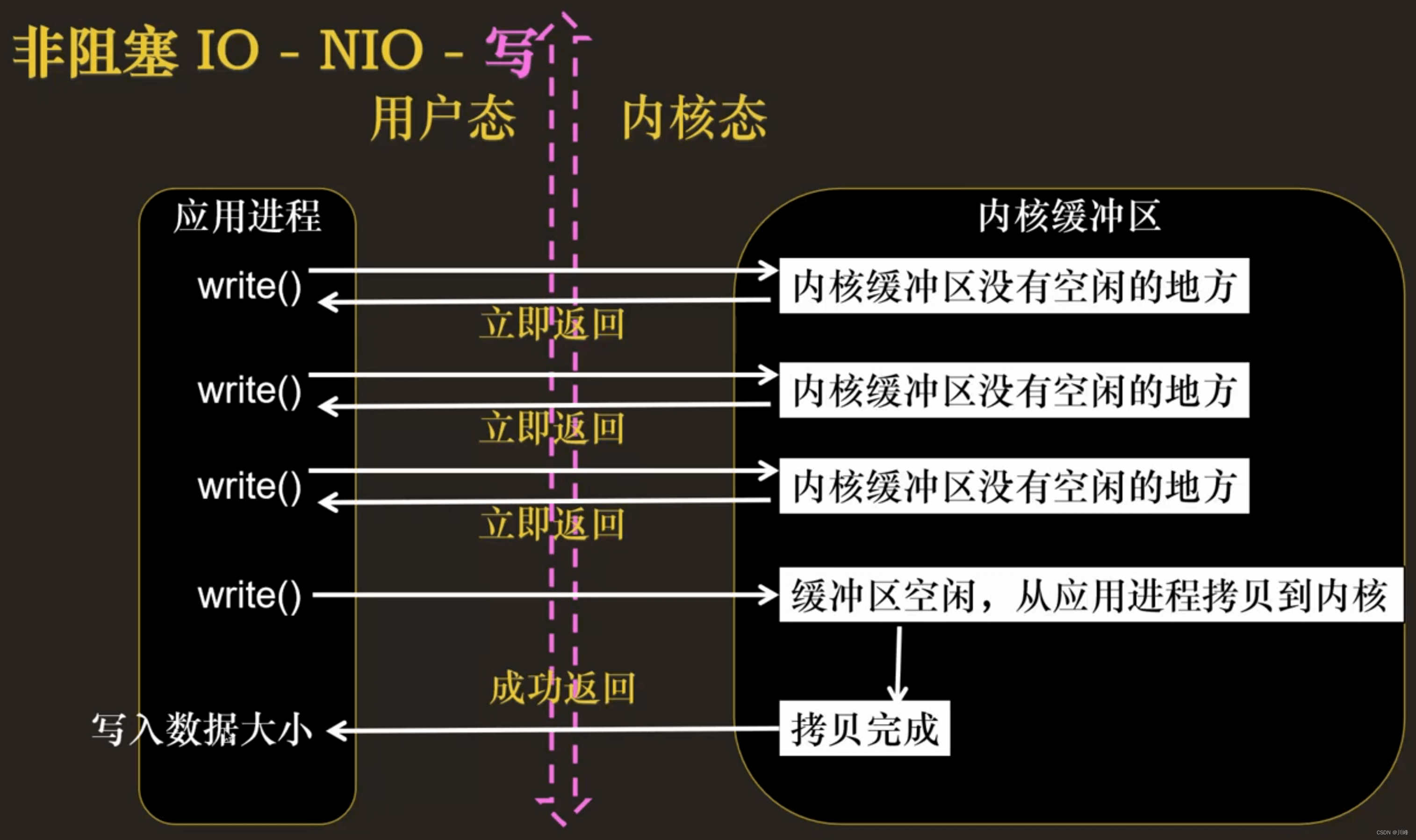
我们把一个 SOCKET 接口设置为非阻塞就是告诉内核,当所请求的 I/O 操作无法完成时,不要将进程睡眠,而是返回一个错误。这样我们的 I/O 操作函数将不断的测试数据是否已经准备好,如果没有准备好,继续测试,直到数据准备好为止。在这个不断测试的过程中,会大量的占用 CPU 的时间。该模型不被
推荐。
IO 复用模型
I/O 复用模型会用到 select、poll、epoll 函数,这几个函数也会使进程阻塞,但是和阻塞 I/O 所不同的的,这两个函数可以同时阻塞多个 I/O 操作。而且可以同时对多个读操作,多个写操作的 I/O 函数进行检测,直到有数据可读或可写时,才真正调用 I/O 操作函数。
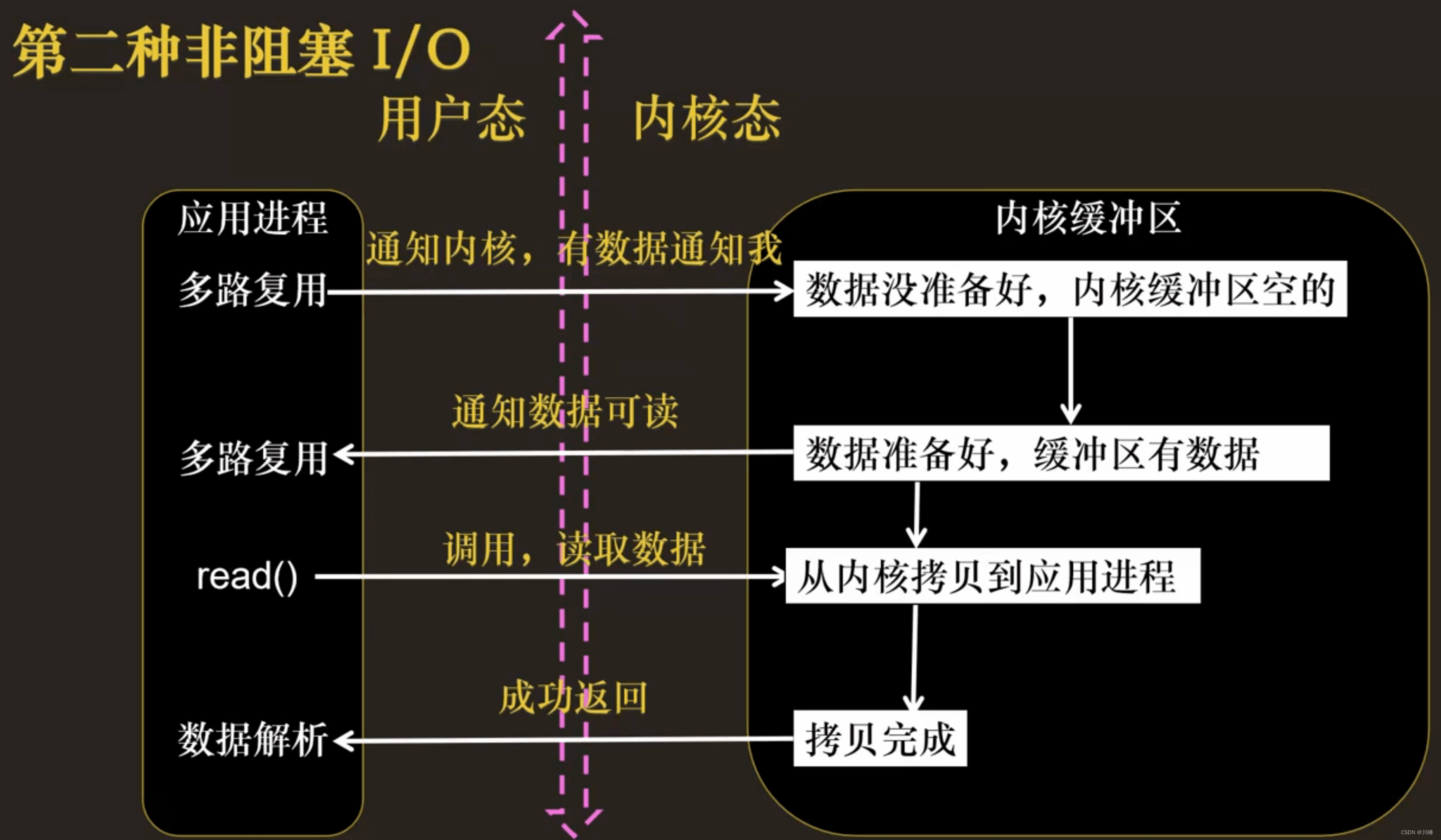
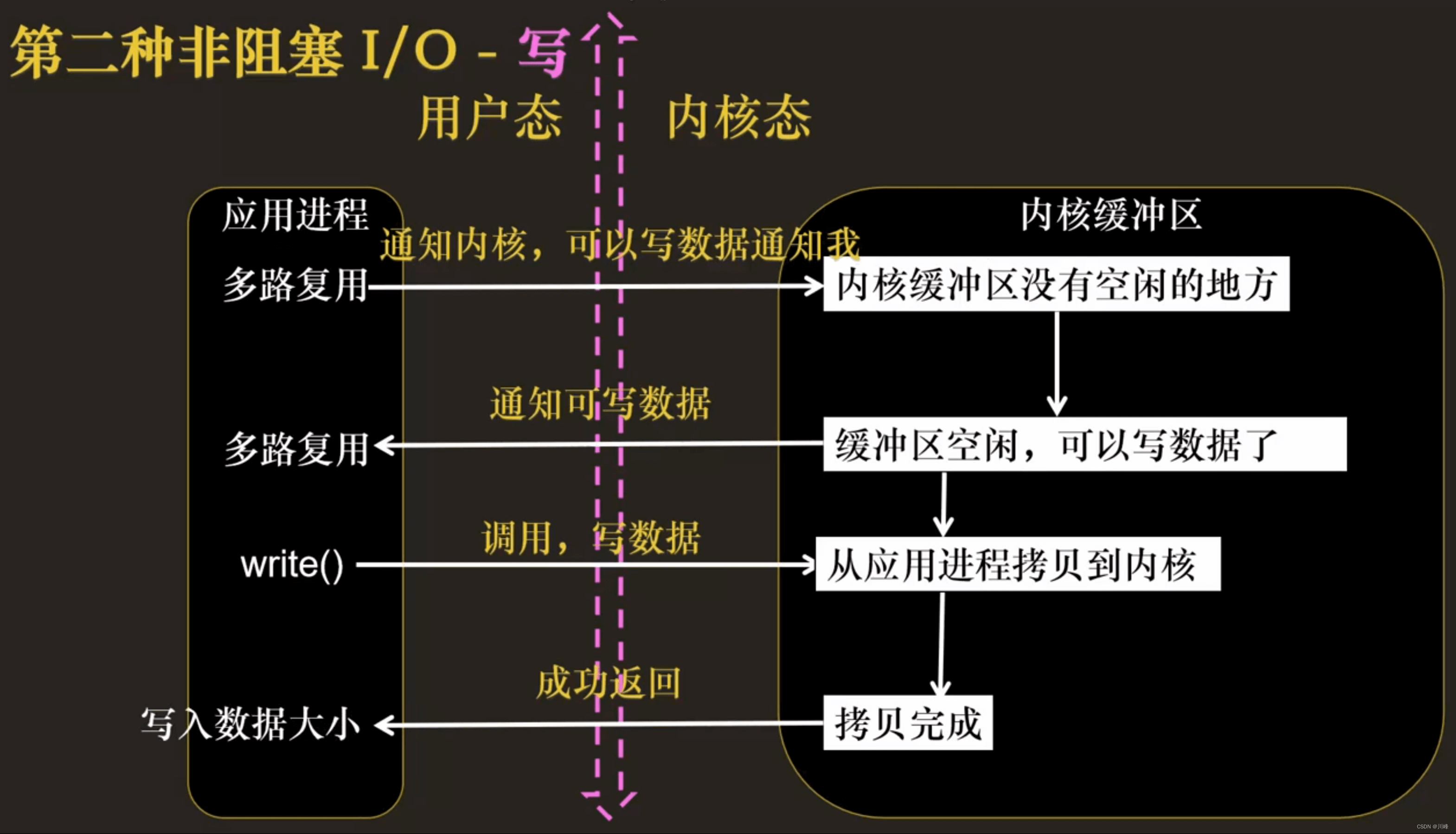
当用户进程调用了 select,那么整个进程会被 block;而同时,kernel 会“监视”所有 select 负责的 socket;当任何一个 socket 中的数据准备好了,select 就会返回。这个时候,用户进程再调用 read 操作,将数据从 kernel 拷贝到用户进程。
这个图和 blocking IO 的图其实并没有太大的不同,事实上还更差一些。因为这里需要使用两个系统调用,而 blocking IO 只调用了一个系统调用。但是,用 select 的优势在于它可以同时处理多个 connection。
(所以,如果处理的连接数不是很高的话,使用 select/epoll 的 web server 不一定比使用 multi-threading + blocking IO 的 web server 性能更好,可能延迟还更大。select/epoll 的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。)
信号驱动 IO 模型
简介:两次调用,两次返回
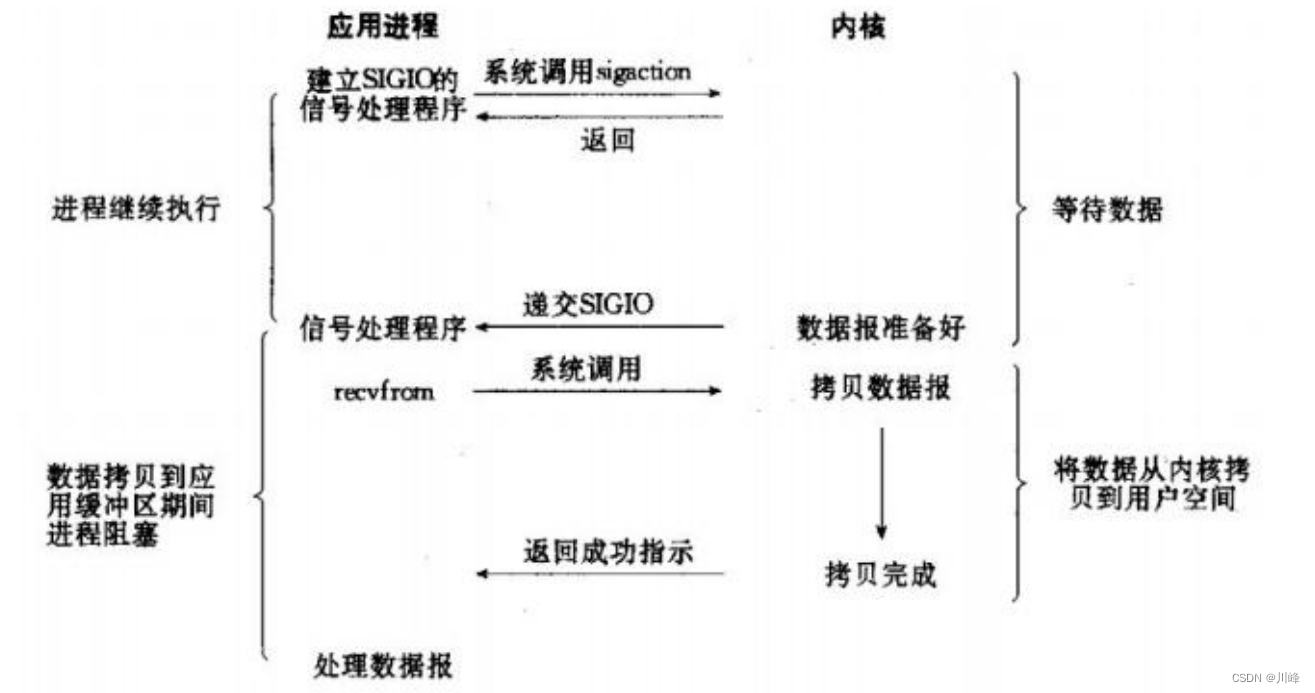
首先我们允许套接口进行信号驱动 I/O,并安装一个信号处理函数,进程继续运行并不阻塞。当数据准备好时,进程会收到一个 SIGIO 信号,可以在信号处理函数中调用 I/O 操作函数处理数据。
异步 IO 模型
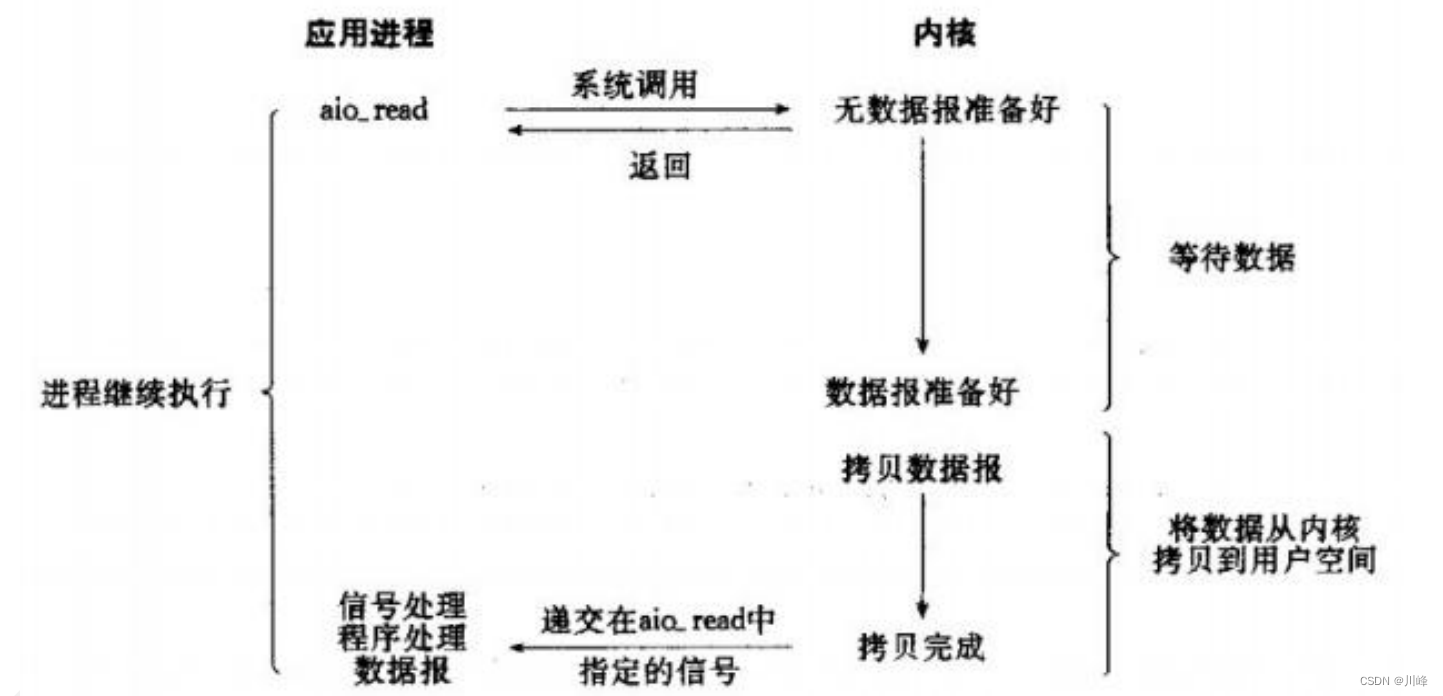
当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者的输入输出操作。
多路复用的概念
先看一个例子
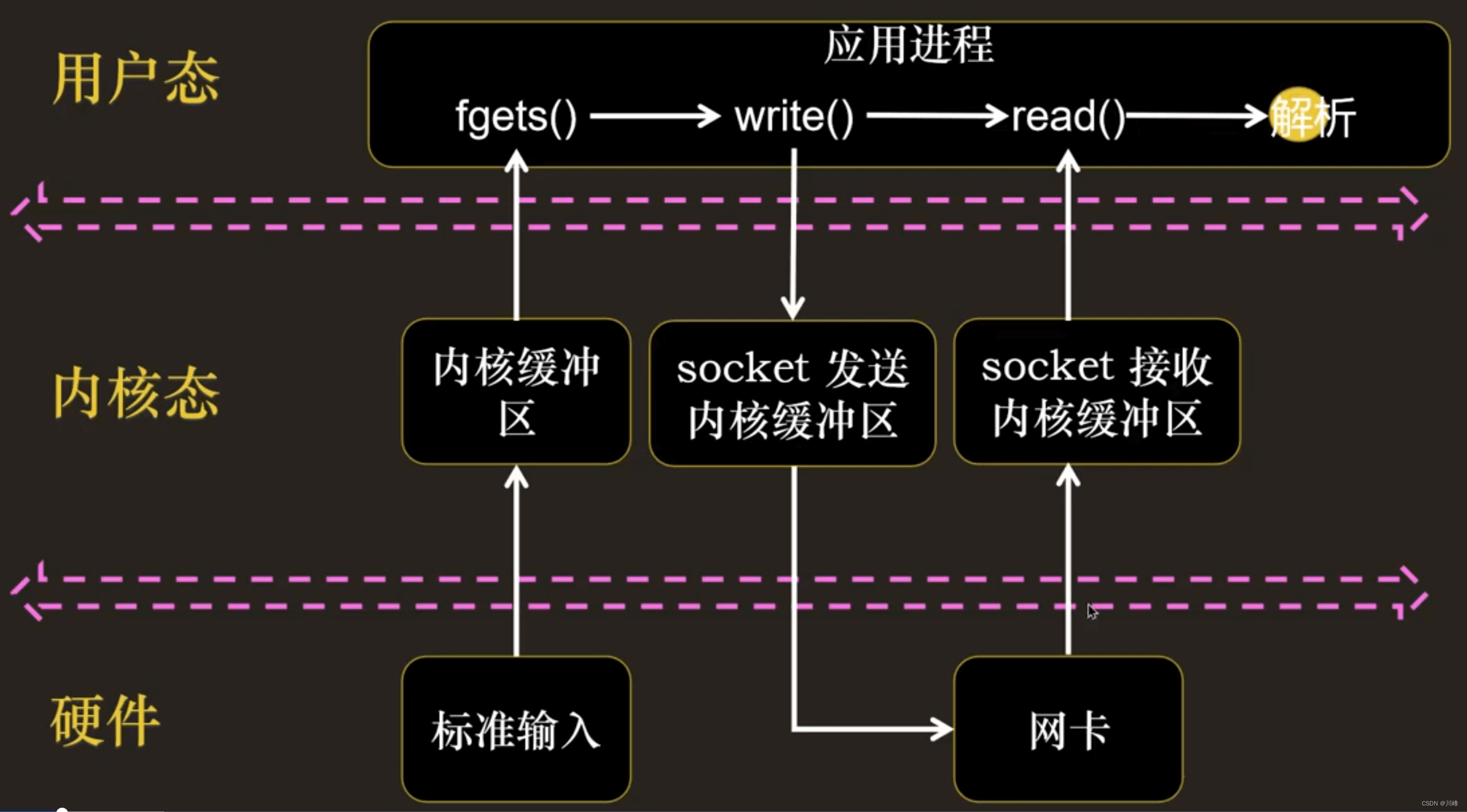
这里一旦使用 fgets() 方法等待标准输入,就没有办法在 Socket 有数据的时候读出数据:
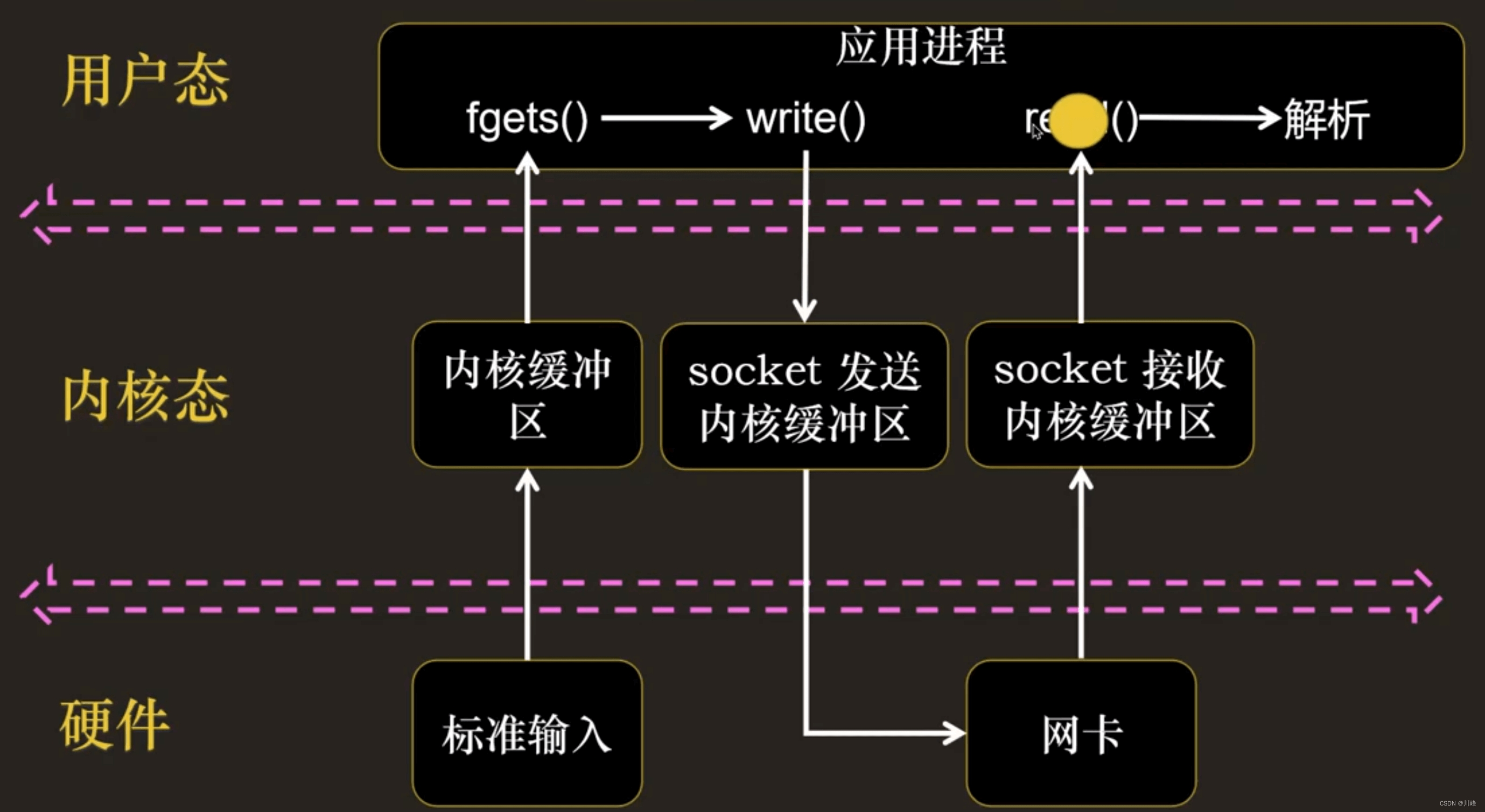
I/O 多路复用:把标准输入、Socket等都看做 I/O 的一路,多路复用的意思,就是在任何一路 I/O 有事件发生的情况下,通知应用程序去处理相应的 I/O 事件
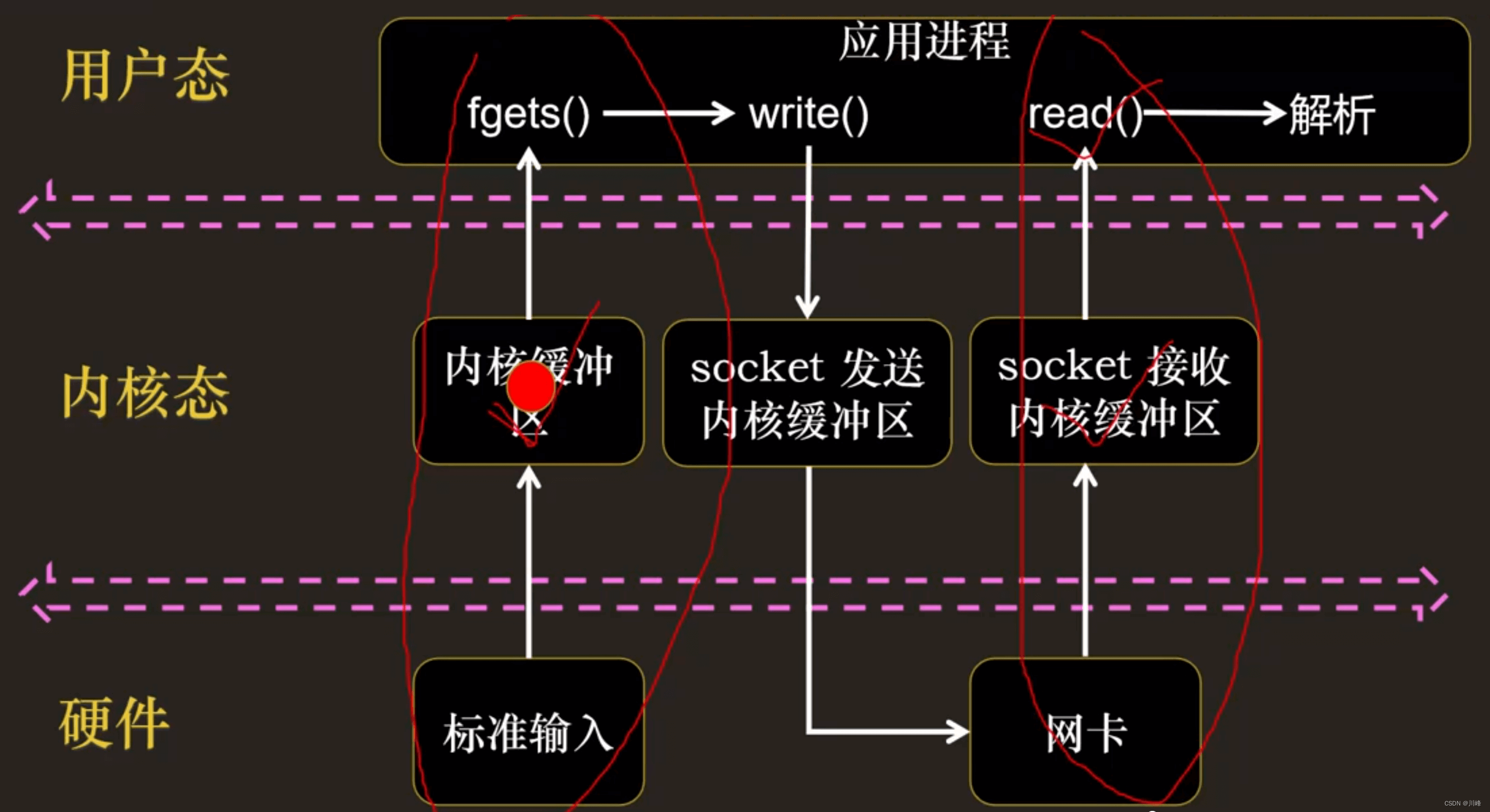
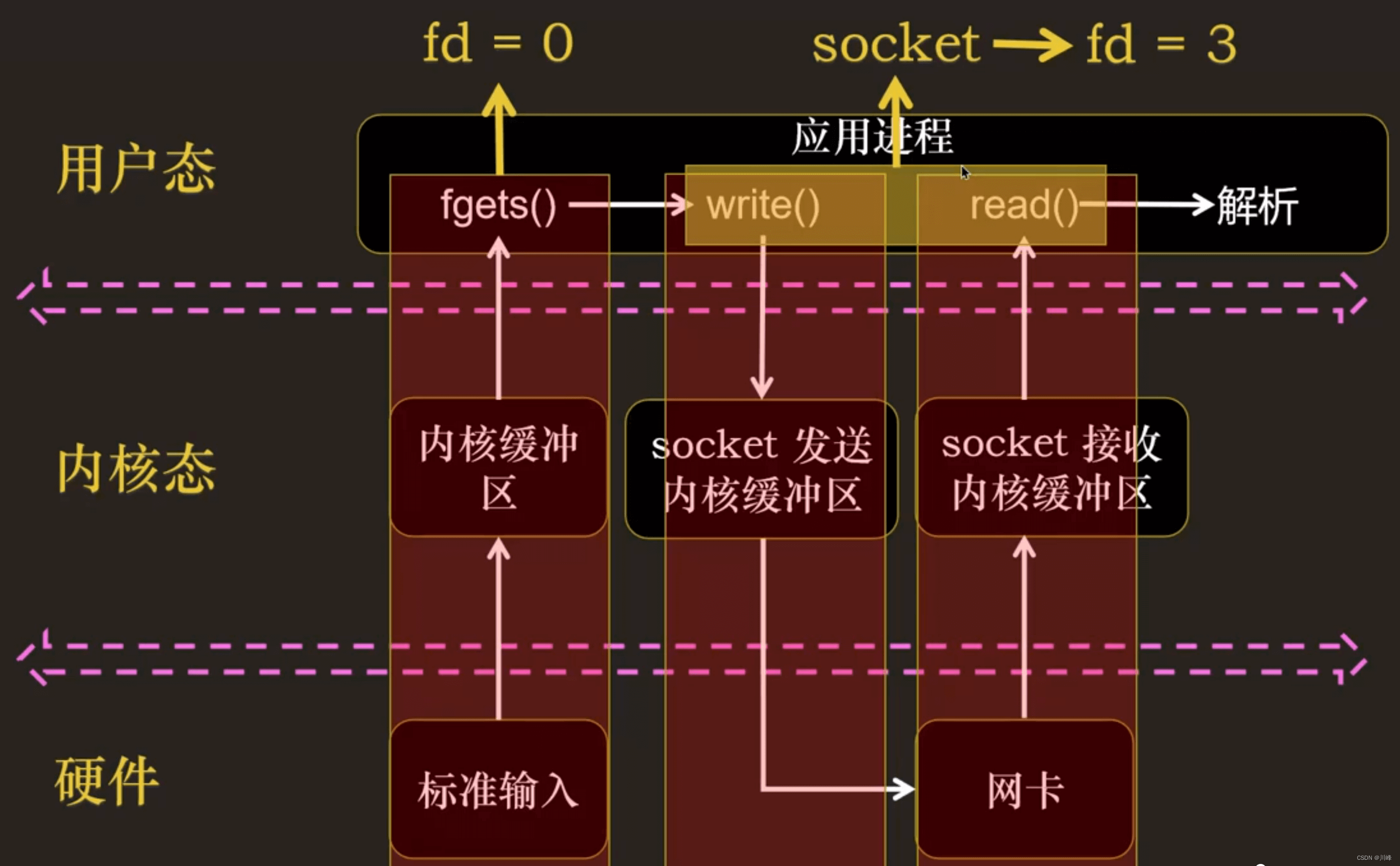
多路中的每一路本质上就是一个 fd:
什么是 I/O 事件,例如:
- I/O 事件一:fd 对应的内核缓冲区来了数据,可读;
- I/O 事件二:fd 对应的内核缓冲区空闲,可写;
- I/O 事件三:fd 出现异常
多路复用技术的实现主要有:
- ① select
- ② poll
- ③ epoll
I/O 多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但 select,poll,epoll 本质上都是同步 I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步 I/O 则无需自己负责进行读写,异步 I/O 的实现会负责把数据从内核拷贝到用户空间。
select 多路复用
首先,应用进程需要告诉内核它感兴趣的 I/O 事件,然后,内核感知设备发生的 I/O 事件,然后通知应用进程:你感兴趣的 fd 发生了你感兴趣的 I/O 事件类型。

多路中的每一路本质上就是一个 fd。
select函数定义如下:
/* According to POSIX.1-2001 */
#include <sys/select.h>
/* According to earlier standards */
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
fd_set
其中 fd_set 结构体定义如下:
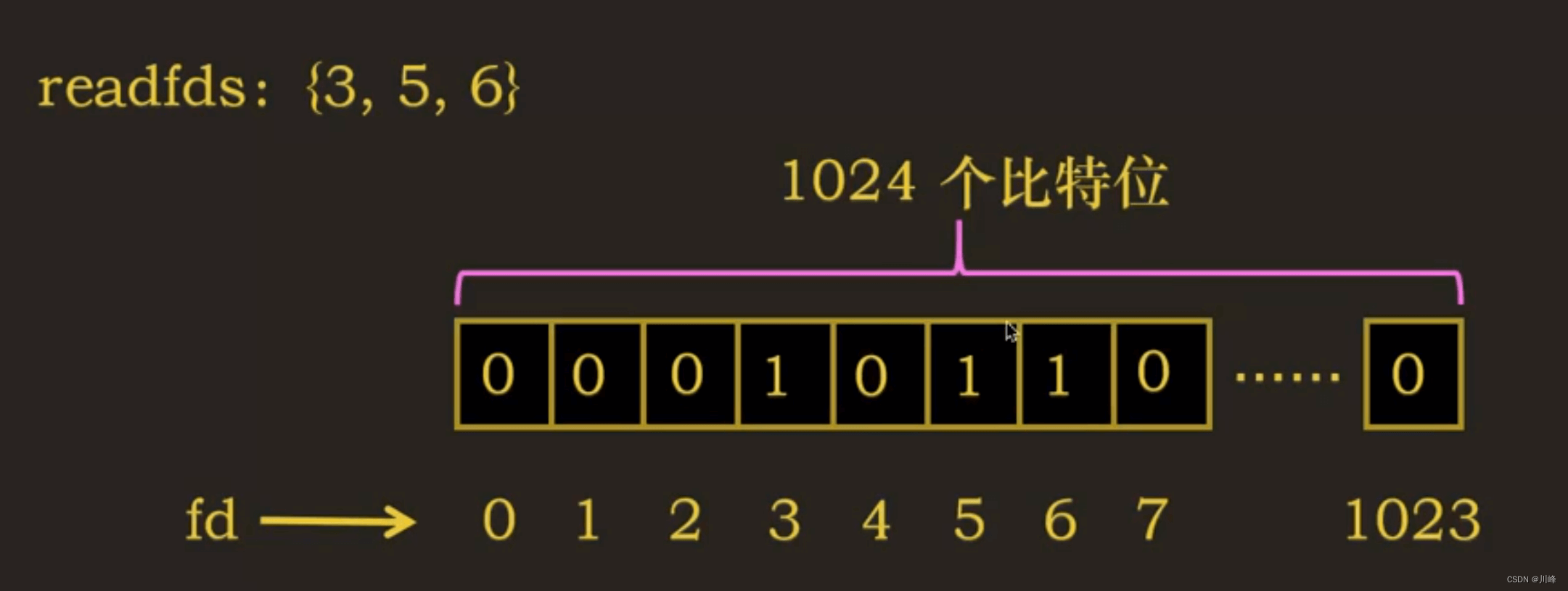
#define __FD_SETSIZE 1024 typedef struct {unsigned long fds_bits[__FD_SETSIZE / (8 * sizeof(long))];
} __kernel_fd_set;
这里一个 long 占 8 个字节(64位系统),一个字节占 8 位,8 * sizeof(long) 总共占 64 位。
因此 __FD_SETSIZE / (8 * sizeof(long)) 的值是 1024/64 = 16,即数组大小16个(0-15),16个 long 数组总共有 64*16 = 1024 位 。
所以,fd_set 是长度为 1024 的比特位数组,数组索引表示文件描述符。
如何设置这些描述符集合
void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);
void FD_SET(int fd, fd_set *set);
void FD_ZERO(fd_set *set);
FD_ZERO:用来将这个set的所有元素都设置成0;FD_SET:set[fd] = 1;FD_CLR:set[fd] = 0;FD_ISSET:set[fd] == 1 ? true : false
timeval
struct timeval {long tv_sec; /* seconds */ long tv_usec; /* microseconds */
};
最后一个参数是 timeval 时间结构体
- ① 设置成空(
NULL),表示如果没有 I/O 事件发生,则select一直等待下去。 - ② 设置一个非零的值,这个表示等待固定的一段时间后从
select阻塞调用中返回 - ③ 将
tv_sec和tv_usec都设置成0,表示根本不等待,检测完毕立即返回。这种情况使用得比较少。
select 执行流程
select 底层调用流程图:https://www.processon.com/view/link/62d3fdfce401fd259605006d
下面是简要描述:
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
select函数监视的文件描述符分 3 类,分别是writefds、readfds和exceptfds。- 调用后
select函数会阻塞,直到有描述符就绪(可读/可写/有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。 - 当
select函数返回后,可以通过遍历fdset,来找到就绪的描述符。 fd_set是一个只包含长度为1024的比特位数组的结构体,数组的索引表示文件描述符,数组的值用1和0表示是否对当前索引的fd的 I/O 事件感兴趣。- 将这三个
fd_set文件描述符拷贝到内核态的三个数组,并创建三个对应的结果数组 - 内核中
for循环不断遍历 3 个fd_set数组中所有的fd,看其是否有可读/可写 I/O 事件发生,如果有,将结果数组的对应比特位设置为1,如果没有 I/O 事件发生,将该fd对应进程放入等待队列中(每个fd都有一个进程等待队列,当fd发生 I/O 事件时会唤醒这个进程) for循环结束后,如果一个fd都没有 I/O 事件发生,则当前调用select的进程进入休眠,让出 CPU 使用权,如果有某个fd发生 I/O 事件,就将结果数组返回,拷贝到用户态空间的三个fd_set的数组中
select 缺点
-
① 支持的文件描述符的个数是有限的。在 Linux 系统中,
select的默认最大值为1024。 -
② 内核会修改用户态传递的
readfds、writefds参数的值
最佳实践:多路复用 + 非阻塞 IO
poll 多路复用
#include <poll.h>int poll(struct pollfd *fds, nfds_t nfds, int timeout);
fds:pollfd数组,存放应用进程所有感兴趣的fd及其相应的 IO 事件nfds:pollfd数组的大小,可以大于1024,突破文件描述符个数限制timeout:超时时间
如果是一个< 0的数,表示在有事件发生之前永远等待;
如果是0,表示不阻塞进程,立即返回;
如果是一个> 0的数,表示poll调用方等待指定的毫秒数后返回。
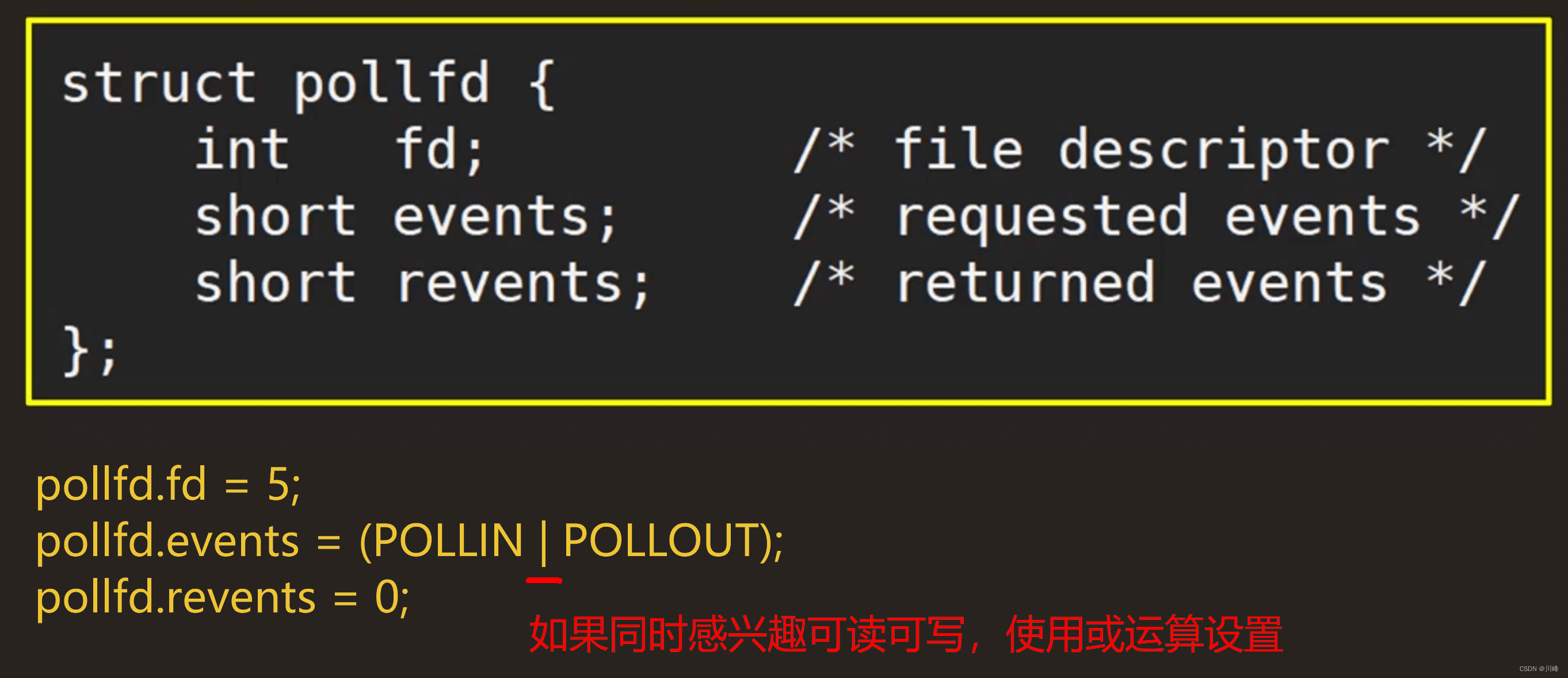
其中 pollfd 结构体定义如下:
struct pollfd { int fd; /* file descriptor */ short events; /* requested events */ short revents; /* returned events */
};
fd:感兴趣的文件描述符events:注册这个fd下感兴趣的 I/O 事件(可读事件、可写事件等)revents:内核通知的这个fd下发生的 I/O 事件,称为returned events
poll 中感兴趣的 IO 事件有哪些:
#define POLLIN Θx0001 /* any readable data available */
#define POLLPRI 0x0002 /* 00B/Urgent readable data */
#define POLLOUT 0x0004 /* file descriptor is writeable */#define POLLERR 0x0008 /* 一些错误发送 */
#define POLLHUP Θx0010 /* 描述符挂起 */
#define POLLNVAL Θx0020 /* 请求的事件无效 */

poll 执行流程
poll 底层调用流程图:https://www.processon.com/view/link/62d3fe350e3e74607274c241
其大致流程跟 select 相似
select vs poll
int poll (struct pollfd *fds, unsigned int nfds, int timeout);
- 不同于
select使用三个位图来表示三个fdset的方式,poll使用一个pollfd数组实现。 pollfd结构体包含了要监视的文件描述符fd, 对该fd感兴趣的 IO 事件events和内核通知fd下发生的 IO 事件revents。- 使用
nfds设置数组pollfd的大小,没有最大数量限制。 - 和
select函数一样,poll返回后,需要轮询pollfd来获取就绪的描述符。
最主要的区别是以下两点:
select支持最大的fds是1024,poll则没有这个限制select还需要遍历不感兴趣的fd, 但是poll只关心感兴趣的fd(不感兴趣的fd不存在pollfd数组中)
select/poll 的缺点
- 每次调用 select/poll 时,都需要在用户态和内核态之间拷贝数据
- 在内核中,select/poll 在检测 IO 事件时,只要有一个
fd有事件发生,就会线性扫描所有的fds,时间复杂度 O(n)
epoll 多路复用
epoll 是在 Linux 2.6 内核中提出的,是之前的 select 和 poll 的增强版本。相对于 select 和 poll 来说,epoll 更加灵活,没有描述符限制。
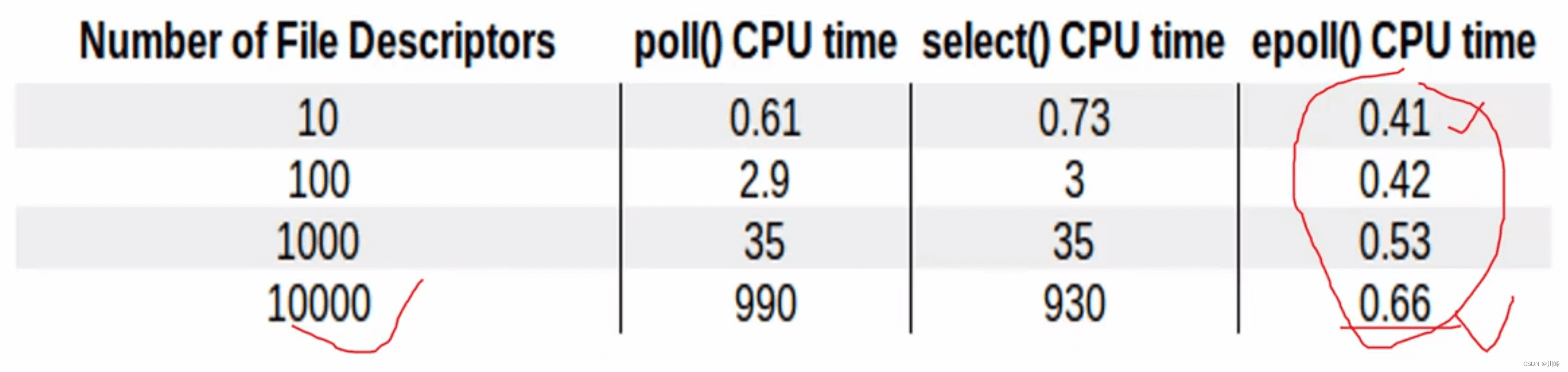
从图中可以明显地看到,epoll 的性能是最好的,即使在多达 10000 个文件描述的情况下,其性能的下降和有10个文件描述符的情况相比,差别也不是很大。而随着文件描述符的增大,常规的 select 和 poll 方法性能逐渐变得很差。
epoll 的使用
epoll_create:创建 epoll 实例
#include <sys/epoll.h> int epoll_create(int size);
创建一个 epoll 实例,从 Linux 2.6.8 开始,参数 size 被忽略,但是必须大于0
关于这个参数size,在一开始的 epoll_create 实现中,是用来告知内核期望监控fd的数量,然后内核使用这部分的信息来初始化内核数据结构,在新的实现中,这个参数不再被需要,因为内核可以动态分配需要的内核数据结构。
我们只需要注意,每次将 size 设置成一个大于0的整数就可以了。
epoll_create() 返回一个文件描述符,这个文件描述符对应着这个epoll实例。Linux 中一切皆文件,epoll 也被看成是一个文件,在内核中也有 file 实例与之对应。
epoll_ctl:操作 epoll 实例中的 IO 事件
#include <sys/epoll.h>int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
- ①
epfd:epoll_create创建的epoll实例对应的文件描述符 - ②
op:对 IO 事件的操作类型
EPOLL_CTL_ADD: 向epoll实例添加fd对应的事件;
EPOLL_CTL_DEL: 向epoll实例删除fd对应的事件;
EPOLL_CTL_MOD:修改fd对应的事件。 - ③
fd:注册的事件的文件描述符,比如一个监听套接字(socket) - ④
event:表示注册的事件类型
其中 epoll_event 结构体定义如下:
struct epoll_event { uint32_t events; /* Epoll events */epoll_data_t data; /* User data variable*/
};
events 就表示事件类型,Epoll 中的 IO 事件类型主要有以下几种:
EPOLLIN:表示对应的文件描述字可以读;EPOLLOUT:表示对应的文件描述字可以写;EPOLLRDHUP:表示套接字的一端已经关闭,或者半关闭;EPOLLHUP:表示对应的文件描述字被挂起;EPOLLET:设置为edge-triggered,默认为level-triggered
epoll_wait:等待内核 I/O 事件的分发
#include <sys/epoll.h>int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
-
①
epfd:epoll_create创建的epoll实例对应的文件描述符 -
②
events: 接口的返回参数,内核返回给用户态应用进程所有需要处理的 I/O 事件,这是一个数组,数组中的每个元素都是一个需要待处理的 I/O 事件。epoll 会把发生的事件的集合从内核复制到events数组中。events数组是一个用户分配好大小的数组,数组长度大于等于maxevents。(events不可以是空指针,内核只负责把数据复制到这个events数组中,不会去帮助我们在用户态中分配内存)其中
events表示具体的事件类型,事件类型取值和epoll_ctl可设置的值一样 -
③
maxevents:一个大于0的整数,表示本次epoll_wait可以返回的最大事件值。通常maxevents参数与预分配的events数组的大小是相等的。 -
④
timeout:超时事件,如果这个值设置为-1,表示不超时;如果设置为0则立即返回,即使没有任何 I/O 事件发生。设置> 0的数值,则表示等待一段时间内没有事件发生,则超时。
范例程序
参见目录 linux-C-net\nio 下的 C 代码,这份代码未经调试,不保证能正常运行,意在表述 Linux 下 IO 复用网络通信代码的基本模式。
epoll 执行流程
epoll 原理图:https://www.processon.com/view/link/62d3fe5a7d9c08119ce3bbbc
-
epoll_cteate() : 内核会创建一个
eventpoll结构体实例,返回一个文件描述符与eventpoll实例相对应 -
epoll_ctl():注册感兴趣的
fd,以及对该fd感兴趣的事件类型 -
epoll_wait():等待内核 IO 事件分发,返回值表示要处理 IO 事件的数量,最大不超过
maxevents,需要返回给用户态的所有需要处理的 IO 事件存放在events数组中,events数组的大小由epoll_wait()返回值决定。 -
用户注册的
fd有 IO 事件发生时,就会将其对应的epitem挂到一个双向链表rdllist中(位于eventpoll结构体中) -
epoll_wait就是在一个循环中不断查看这个rdllist链表中是否有就绪事件,如果有,就将就绪事件返回,拷贝到用户空间中,如果没有,当前进程就进入休眠,CPU 被调度给其他进程使用 -
进程被唤醒的条件:
1)进程超时
2)进程收到一个signal信号
3)某个fd上有事件发生
4)当前进程被CPU重新调度
epoll vs select/poll
select/poll 的缺点:
-
① 每次调用 select/poll 时都需要在用户态/内核态之间进行拷贝数据
-
② 在内核中,select/poll 在检测 IO 事件时,只要有一个
fd有事件发生,就会线性扫描所有的 fds,时间复杂度 O(n)
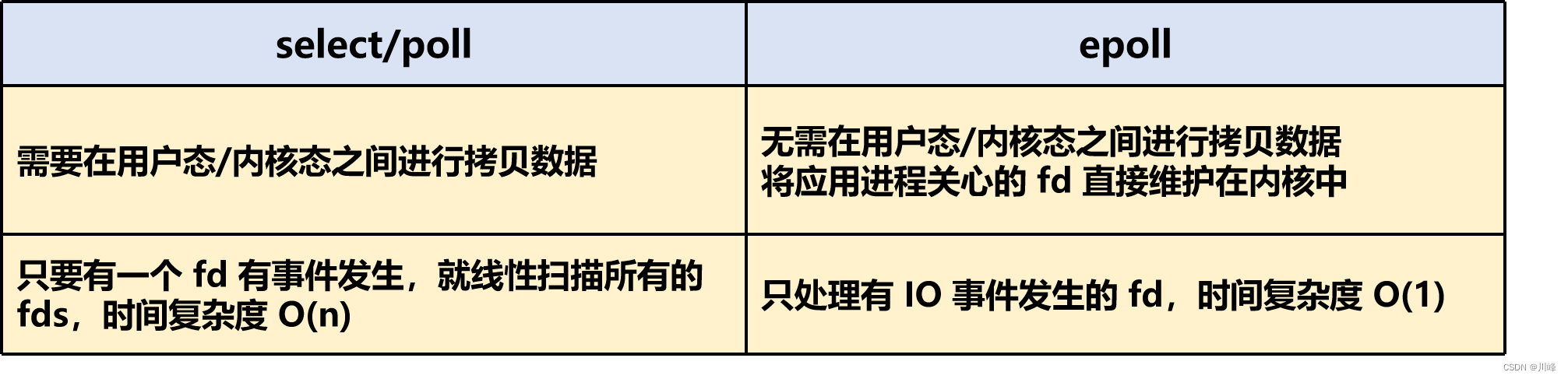
与 select/poll 的缺点相比,epoll 的高效之处是:
- ① 将应用进程关心的 fd 直接维护在内核中,不再进行用户态和内核态间的拷贝(使用红黑树维护,高效增删改)
- ② epoll 只处理有 IO 事件发生的 fd,不会扫描所有的 fds,时间复杂度 O(1)
条件触发 和 边缘触发
条件触发(Level_triggered):又叫水平触发,当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据一次性全部读写完(如读写缓冲区太小),那么下次调用 epoll_wait() 时,它还会通知你在上没读写完的文件描述符上继续读写,当然如果你一直不去读写,它会一直通知你!!!如果系统中有大量你不需要读写的就绪文件描述符,而它们每次都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率!!!
边缘触发(Edge_triggered):当被监控的文件描述符上有可读写事件发生时,epoll_wait() 会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用 epoll_wait() 时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符!!
总结:
- 条件触发:只要满足事件的条件,比如有数据需要读,就一直不断的把这个事件传递给用户
- 边缘触发:只有第一次满足条件的时候才触发,之后就不会再传递同样的事件了
- 边缘触发的效率比条件触发的效率高,epoll 支持边缘触发和条件触发,默认是条件触发,select 和 poll 都是条件触发
epoll 高效原理和底层机制详细分析
总述:
-
当某一进程调用
epoll_create()方法时,Linux 内核会创建一个eventpoll结构体,在内核cache里建了个红黑树用于存储以后epoll_ctl()传来的 socket 外,还会再建立一个rdllist双向链表,用于存储准备就绪的事件,当epoll_wait()调用时,仅仅观察这个rdllist双向链表里有没有数据即可。有数据就返回,没有数据就 sleep,等到 timeout 时间到后即使链表没数据也返回。 -
同时,所有添加到 epoll 中的事件都会与设备(如网卡)驱动程序建立回调关系,也就是说相应事件的发生时会调用这里的回调方法。这个回调方法在内核中叫做
ep_poll_callback,它会把这样的事件放到上面的rdllist双向链表中。 -
当调用
epoll_wait()检查是否有发生事件的连接时,只是检查eventpoll对象中的rdllist双向链表是否有epitem元素而已,如果rdllist链表不为空,则这里的事件复制到用户态内存(使用共享内存提高效率)中,同时将事件数量返回给用户。因此epoll_wait()效率非常高,可以轻易地处理百万级别的并发连接。
从网卡接收数据说起
一个典型的计算机结构图,计算机由 CPU、存储器(内存)、网络接口等部件组成。了解 epoll 本质的第一步,要从硬件的角度看计算机怎样接收网络数据。
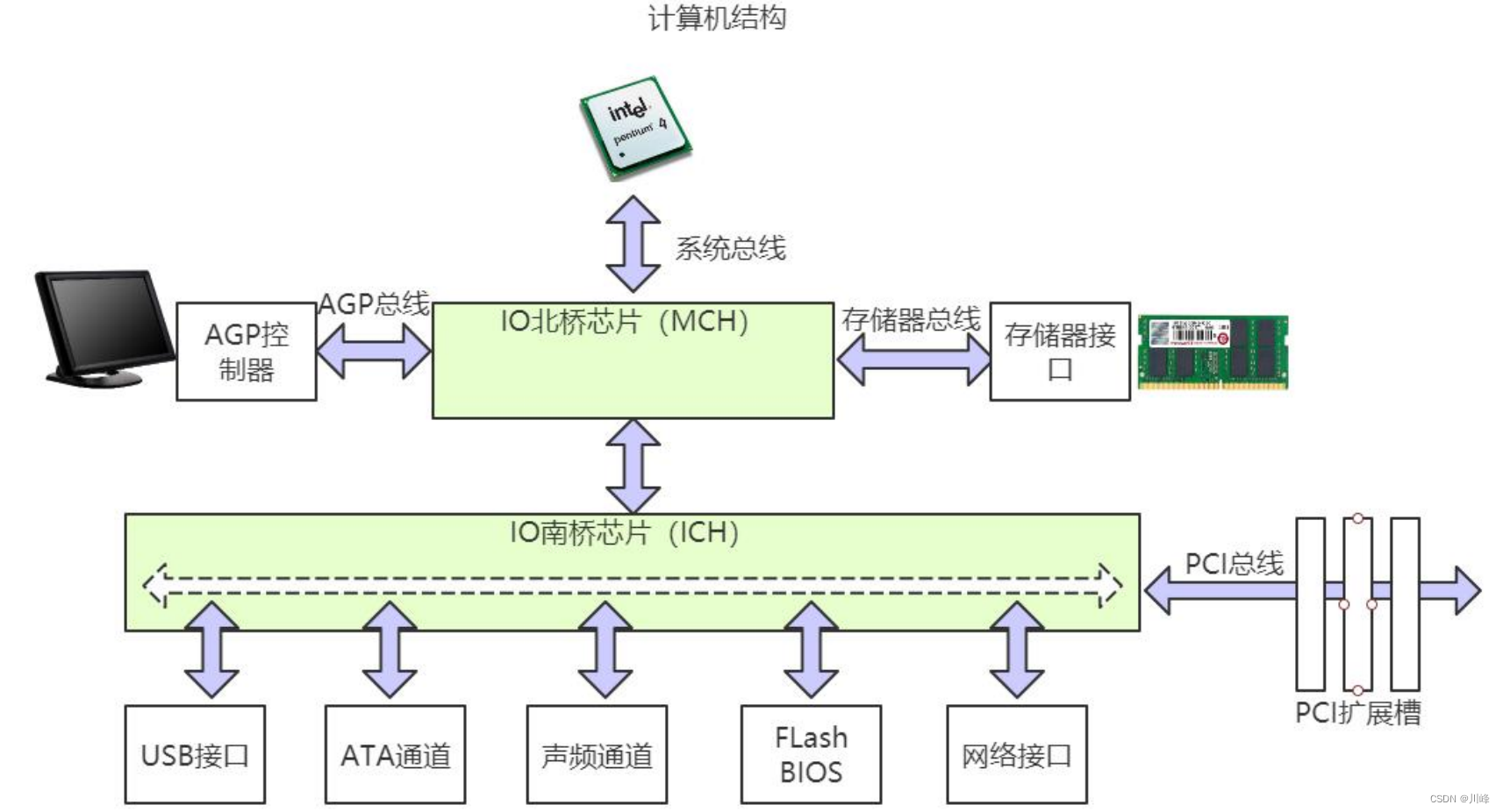
网卡接收数据的过程:网卡收到网线传来的数据;经过硬件电路的传输;最终将数据写入到内存中的某个地址上。这个过程涉及到 DMA 传输、IO 通路选择等硬件有关的知识,但我们只需知道:网卡会把接收到的数据写入内存。操作系统就可以去读取它们。
如何知道接收了数据?
CPU 的如何知道网络上有数据要接收?很简单,使用中断机制。
进程阻塞
了解 epoll 本质,要从操作系统进程调度的角度来看数据接收。阻塞是进程调度的关键一环,指的是进程在等待某事件(如接收到网络数据)发生之前的等待状态,recv、select 和 epoll 都是阻塞方法。了解“进程阻塞为什么不占用 cpu资源?”,也就能够了解这一步。
为简单起见,我们从普通的 recv 接收开始分析,先看看下面代码:
int s = socket(AF_INET, SOCK_STREAM, 0); // 创建 socket
bind(s, ...) // 绑定
listen(s, ...) // 监听
int c = accept(s, ...) // 接受客户端连接
recv(c, ...); // 接收客户端数据
printf(...) // 将数据打印出来
这是一段最基础的网络编程代码,先新建 socket 对象,依次调用 bind、listen、accept,最后调用 recv 接收数据。recv 是个阻塞方法,当程序运行到 recv 时,它会一直等待,直到接收到数据才往下执行。
那么阻塞的原理是什么?
操作系统为了支持多任务,实现了进程调度的功能,会把进程分为“运行”和“等待”等几种状态。运行状态是进程获得 cpu 使用权,正在执行代码的状态;等待状态是阻塞状态,比如上述程序运行到 recv 时,程序会从运行状态变为等待状态,接收到数据后又变回运行状态。操作系统会分时执行各个运行状态的进程,由于速度很快,看上去就像是同时执行多个任务。
下图中的计算机中运行着 A、B、C 三个进程,其中进程 A 执行着上述基础网络程序,一开始,这 3 个进程都被操作系统的工作队列所引用,处于运行状态,会分时执行。
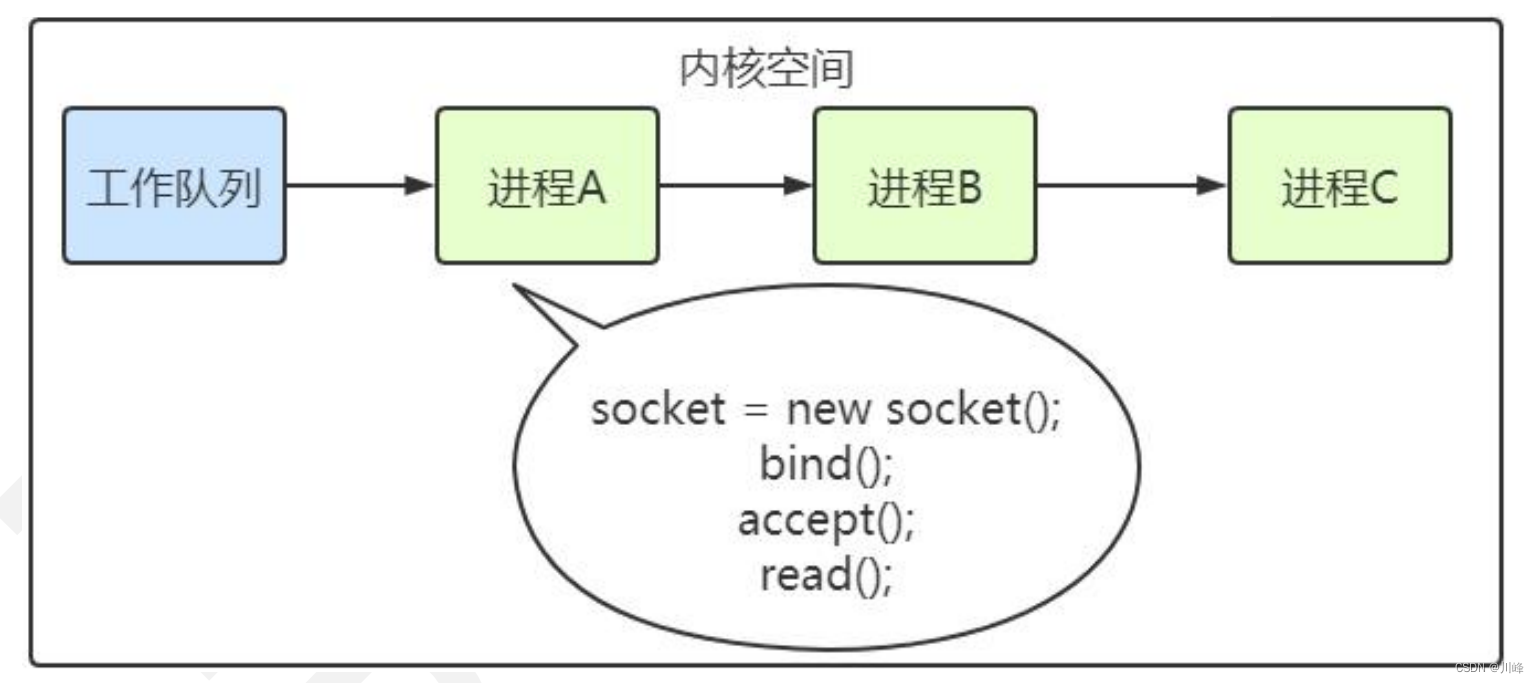
当进程 A 执行到创建 socket 的语句时,操作系统会创建一个由文件系统管理的 socket 对象。这个 socket 对象包含了发送缓冲区、接收缓冲区、等待队列等成员。等待队列是个非常重要的结构,它指向所有需要等待该 socket 事件的进程。
当程序执行到 recv 时,操作系统会将进程 A 从工作队列移动到该 socket 的等待队列中(如下图)。由于工作队列只剩下了进程 B 和 C,依据进程调度,cpu 会轮流执行这两个进程的程序,不会执行进程 A 的程序。所以进程 A 被阻塞,不会往下执行代码,也不会占用 cpu 资源。
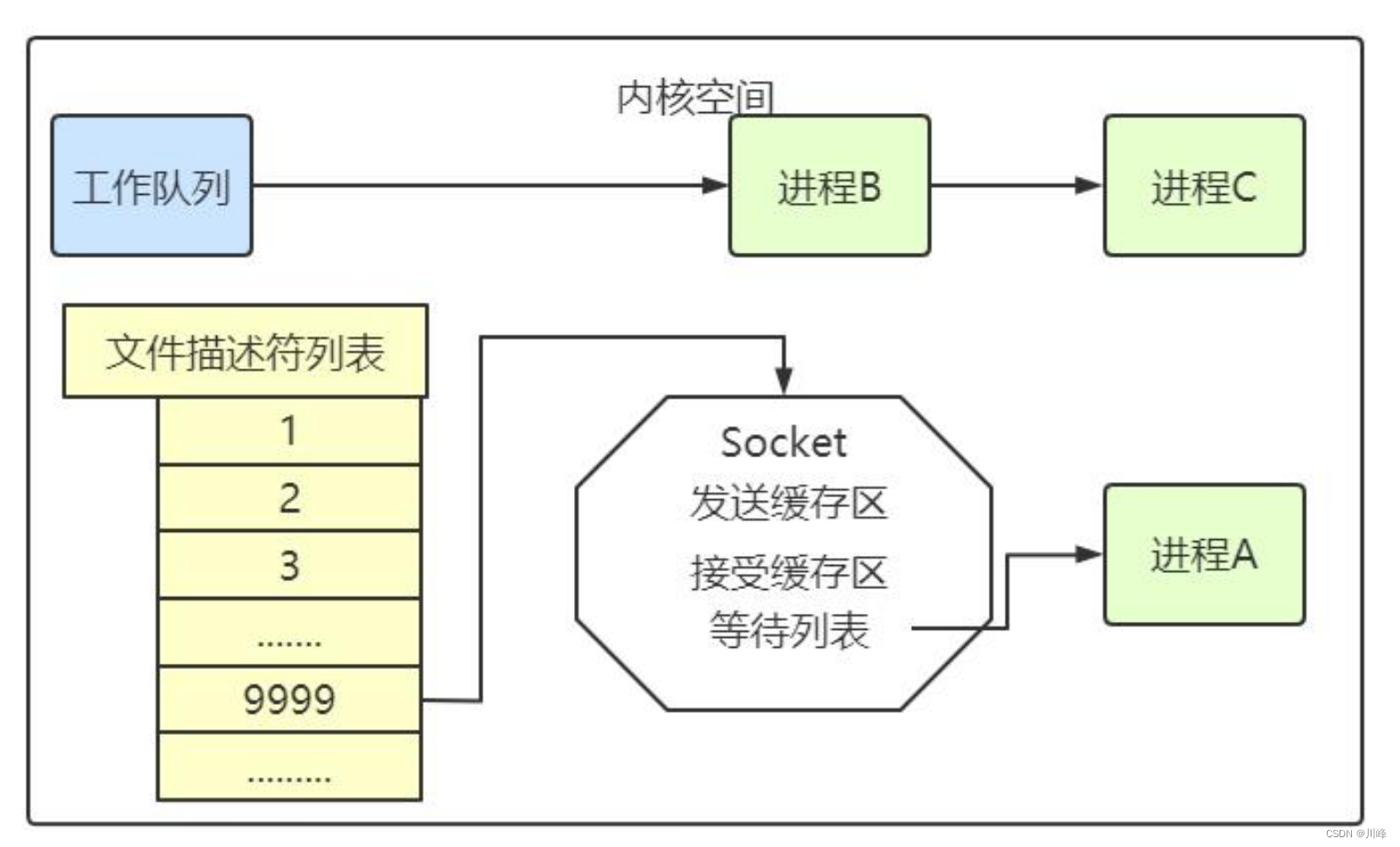
操作系统添加等待队列只是添加了对这个“等待中”进程的引用,以便在接收到数据时获取进程对象、将其唤醒,而非直接将进程管理纳入自己之下。上图为了方便说明,直接将进程挂到等待队列之下。
当 socket 接收到数据后,操作系统将该 socket 等待队列上的进程重新放回到工作队列,该进程变成运行状态,继续执行代码。也由于 socket 的接收缓冲区已经有了数据,recv 可以返回接收到的数据。
内核接收网络数据全过程

进程在 recv 阻塞期间,计算机收到了对端传送的数据(步骤①)。数据经由网卡传送到内存(步骤②),然后网卡通过中断信号通知 cpu 有数据到达,cpu 执行中断程序(步骤③)。此处的中断程序主要有两项功能,先将网络数据写入到对应 socket 的接收缓冲区里面(步骤④),再唤醒进程 A(步骤⑤),重新将
进程 A 放入工作队列中。
思考下,操作系统如何知道网络数据对应于哪个 socket?
- 因为一个 socket 对应着一个端口号,而网络数据包中包含了 ip 和端口的信息,内核可以通过端口号找到对应的 socket。当然,为了提高处理速度,操作系统会维护端口号到 socket 的索引结构,以快速读取。
思考下,如何同时监视多个 socket 的数据?
同时监视多个 socket 的简单方法
服务端需要管理多个客户端连接,而 recv 只能监视单个 socket,这种矛盾下,人们开始寻找监视多个 socket 的方法。epoll 的要义是高效的监视多个 socket。从历史发展角度看,必然先出现一种不太高效的方法,人们再加以改进。只有先理解了不太高效的方法,才能够理解 epoll 的本质。
假如能够预先传入一个 socket 列表,如果列表中的 socket 都没有数据,挂起进程,直到有一个 socket 收到数据,唤醒进程。这种方法很直接,也是 select 的设计思想。
为方便理解,我们先复习 select 的用法。在如下的代码中,先准备一个数组(下面代码中的 fds),让 fds 存放着所有需要监视的 socket。然后调用 select,如果 fds 中的所有 socket 都没有数据,select 会阻塞,直到有一个 socket 接收到数据,select 返回,唤醒进程。用户可以遍历 fds,通过 FD_ISSET 判断具体哪个socket 收到数据,然后做出处理。
int fds[] = 存放需要监听的 socket
while(1) {int n = select(..., fds, ...)for(int i=0; i < fds.count; i++) {if (FD_ISSET(fds[i], ...)) {// fds[i]的数据处理}}
}
select 的实现思路很直接。假如程序同时监视 sock1、sock2 和 sock3 三个socket,那么在调用 select 之后,操作系统把进程 A 分别加入这三个 socket 的等待队列中。
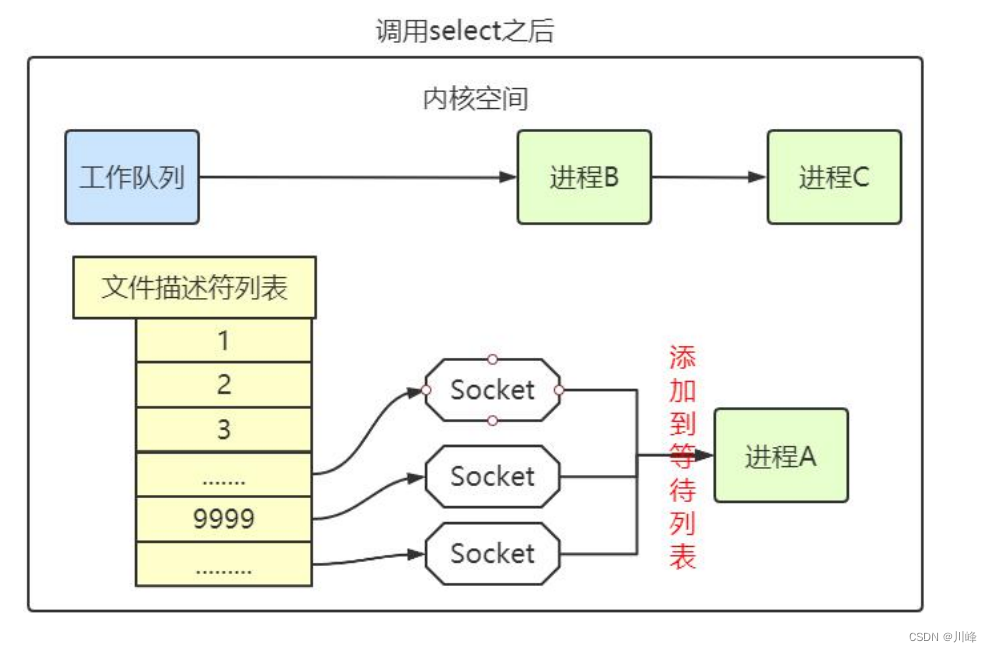
当任何一个 socket 收到数据后,中断程序将唤起进程。所谓唤起进程,就是将进程从所有的等待队列中移除,加入到工作队列里面。
经由这些步骤,当进程 A 被唤醒后,它知道至少有一个 socket 接收了数据。程序只需遍历一遍 socket 列表,就可以得到就绪的 socket。
这种简单方式行之有效,在几乎所有操作系统都有对应的实现。
但是简单的方法往往有缺点,主要是:
-
其一,每次调用 select 都需要将进程加入到所有被监视 socket 的等待队列,每次唤醒都需要从每个队列中移除,都必须要进行遍历。而且每次都要将整个 fds 列表传递给内核,有一定的开销。正是因为遍历操作开销大,出于效率的考量,才会规定 select 的最大监视数量,默认只能监视
1024个 socket。 -
其二,进程被唤醒后,程序并不知道哪些 socket 收到数据,还需要遍历一次。
那么,有没有减少遍历的方法?有没有保存就绪 socket 的方法?这两个问题便是 epoll 技术要解决的。
当然,当程序调用 select 时,内核会先遍历一遍 socket,如果有一个以上的 socket 接收缓冲区有数据,那么 select 直接返回,不会阻塞。这也是为什么 select 的返回值有可能大于 1 的原因之一。如果没有 socket 有数据,进程才会阻塞。
epoll 的设计思路
epoll 是在 select 出现 N 多年后才被发明的,是 select 和 poll 的增强版本。
epoll 通过以下一些措施来改进效率:
-
措施一:功能分离
select 低效的原因之一是将“维护等待队列”和“阻塞进程”两个步骤合二为一。每次调用 select 都需要这两步操作,然而大多数应用场景中,需要监视的 socket 相对固定,并不需要每次都修改。epoll 将这两个操作分开,先用 epoll_ctl 维护等待队列,再调用 epoll_wait 阻塞进程。显而易见的,效率就能得到提升。
相比 select,epoll 拆分了功能。
为方便理解后续的内容,我们先复习下 epoll 的用法。如下的代码中,先用 epoll_create 创建一个 epoll 对象 epfd,再通过 epoll_ctl 将需要监视的 socket 添加到 epfd 中,最后调用 epoll_wait 等待数据。
int epfd = epoll_create(...);
epoll_ctl(epfd, ...); // 将所有需要监听的 socket 添加到 epfd 中
while(1) {int n = epoll_wait(...)for (接收到数据的 socket) {// 处理}
}
功能分离,使得 epoll 有了优化的可能。
-
措施二:就绪列表
select 低效的另一个原因在于程序不知道哪些 socket 收到数据,只能一个个遍历。如果内核维护一个“就绪列表”,引用收到数据的 socket,就能避免遍历。
epoll 的原理和流程
当某个进程调用 epoll_create 方法时,内核会创建一个 eventpoll 对象(也就是程序中 epfd 所代表的对象)。eventpoll 对象也是文件系统中的一员,和 socket 一样,它也会有等待队列。
创建 epoll 对象后,可以用 epoll_ctl 添加或删除所要监听的 socket。以添加 socket 为例,如下图,如果通过 epoll_ctl 添加 sock1、sock2 和 sock3 的监视,内核会将 eventpoll 添加到这三个 socket 的等待队列中。
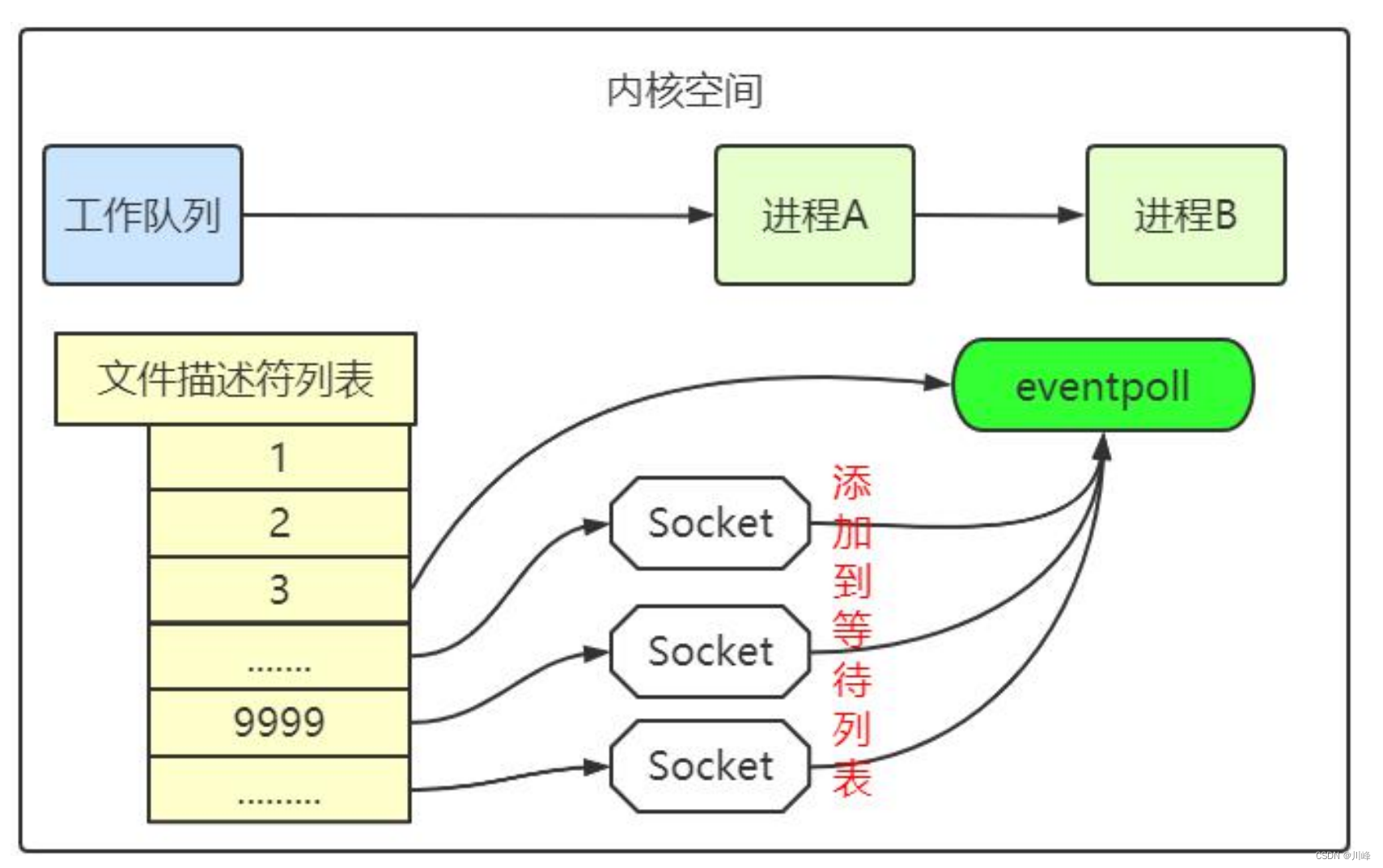
当 socket 收到数据后,中断程序会操作 eventpoll 对象,而不是直接操作进程。中断程序会给 eventpoll 的“就绪列表”添加 socket 引用。如下图展示的是 sock2 和 sock3 收到数据后,中断程序让 rdlist 引用这两个 socket。
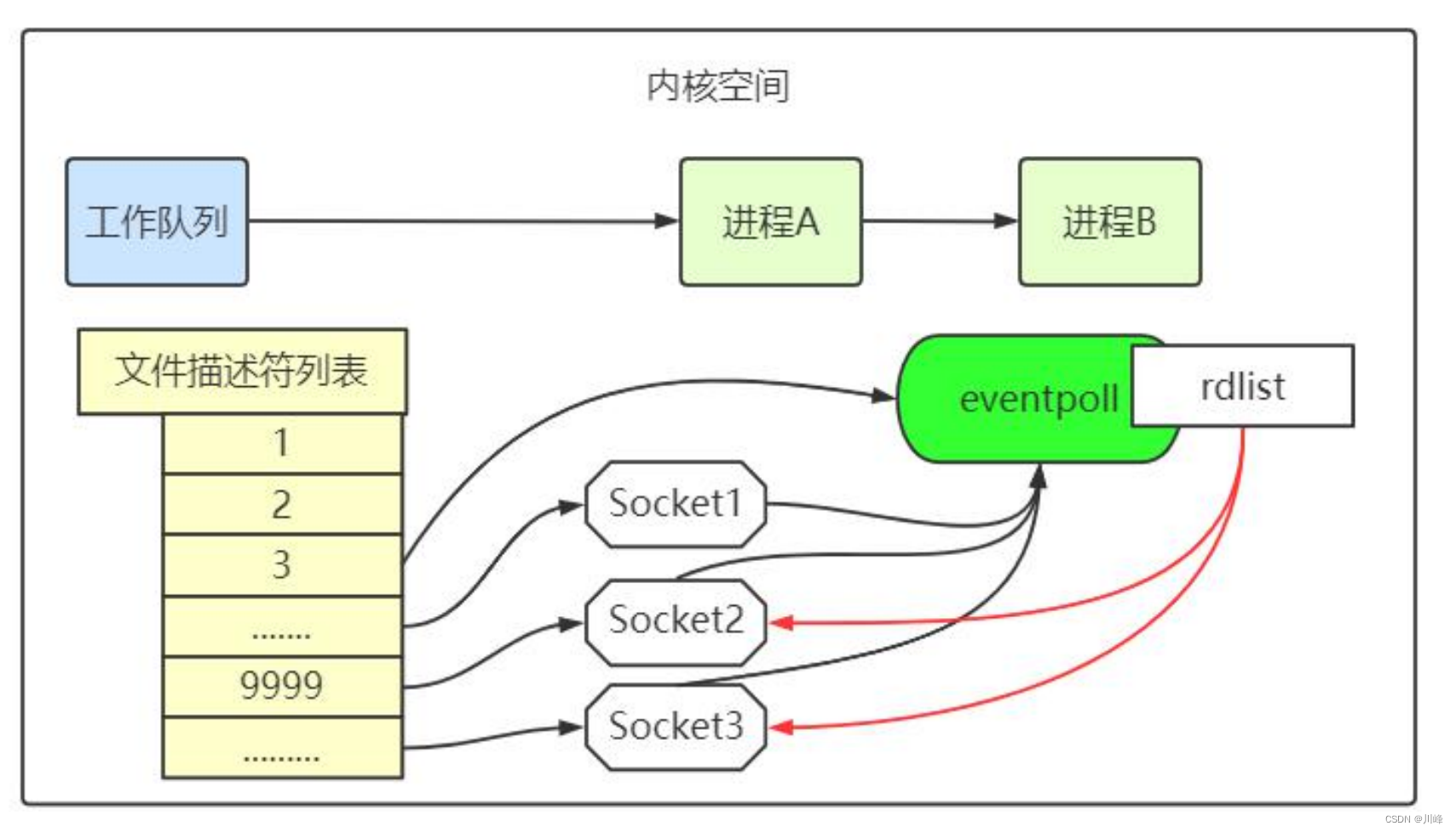
eventpoll 对象相当于是 socket 和进程之间的中介,socket 的数据接收并不直接影响进程,而是通过改变 eventpoll 的就绪列表来改变进程状态。
当程序执行到 epoll_wait 时,如果 rdlist 已经引用了 socket,那么 epoll_wait 直接返回,如果 rdlist 为空,阻塞进程。
假设计算机中正在运行进程 A 和进程 B,在某时刻进程 A 运行到了 epoll_wait 语句。如下图所示,内核会将进程 A 放入 eventpoll 的等待队列中,阻塞进程。
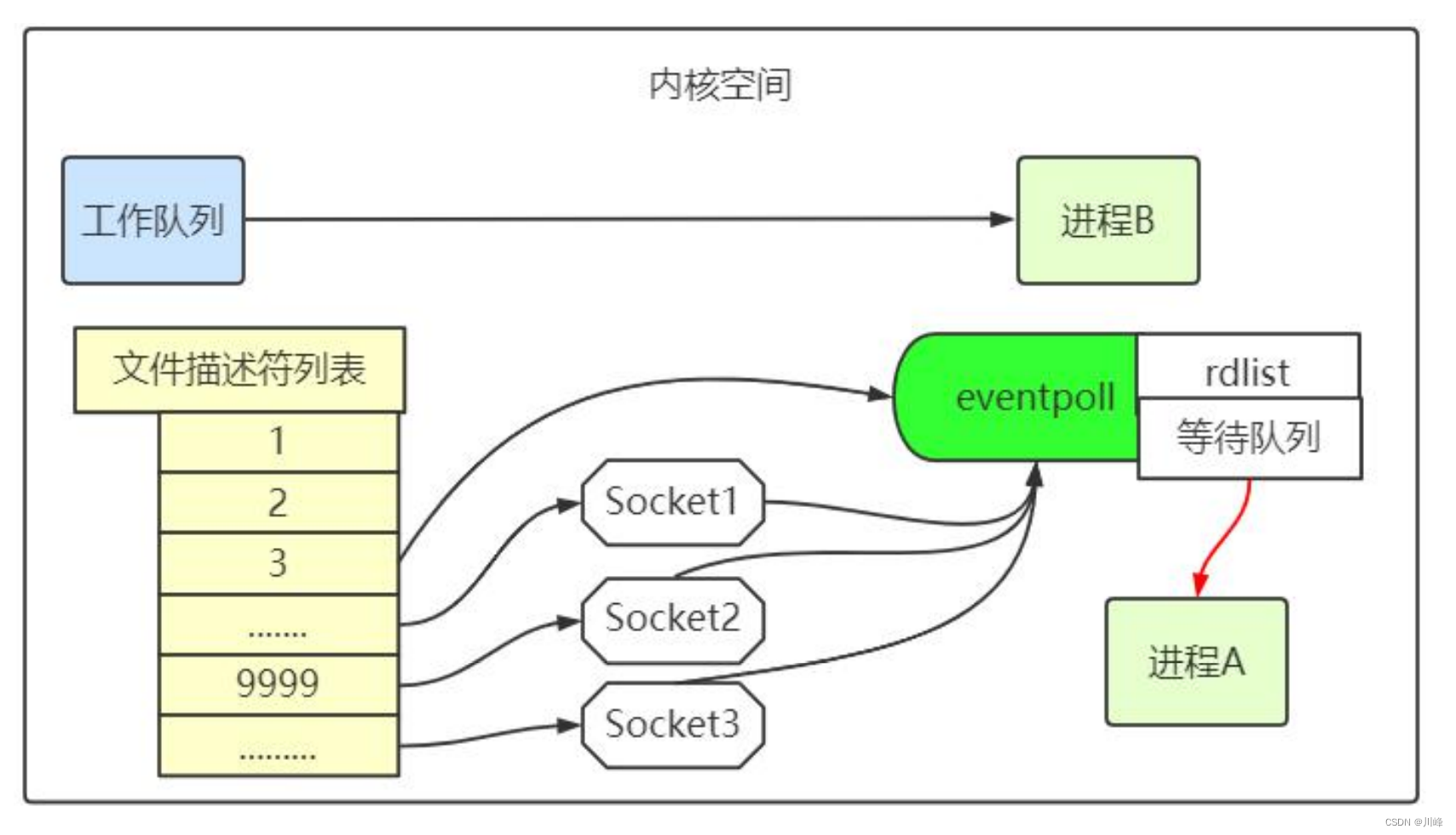
当 socket 接收到数据,中断程序一方面修改 rdlist,另一方面唤醒 eventpoll 等待队列中的进程,进程 A 再次进入运行状态。也因为 rdlist 的存在,进程 A 可以知道哪些 socket 发生了变化。
epoll 的实现细节
现在对 epoll 的本质已经有一定的了解。但我们还留有一个问题,eventpoll 的数据结构是什么样子?
思考两个问题,就绪队列应该应使用什么数据结构?eventpoll 应使用什么数据结构来管理通过 epoll_ctl 添加或删除的 socket?
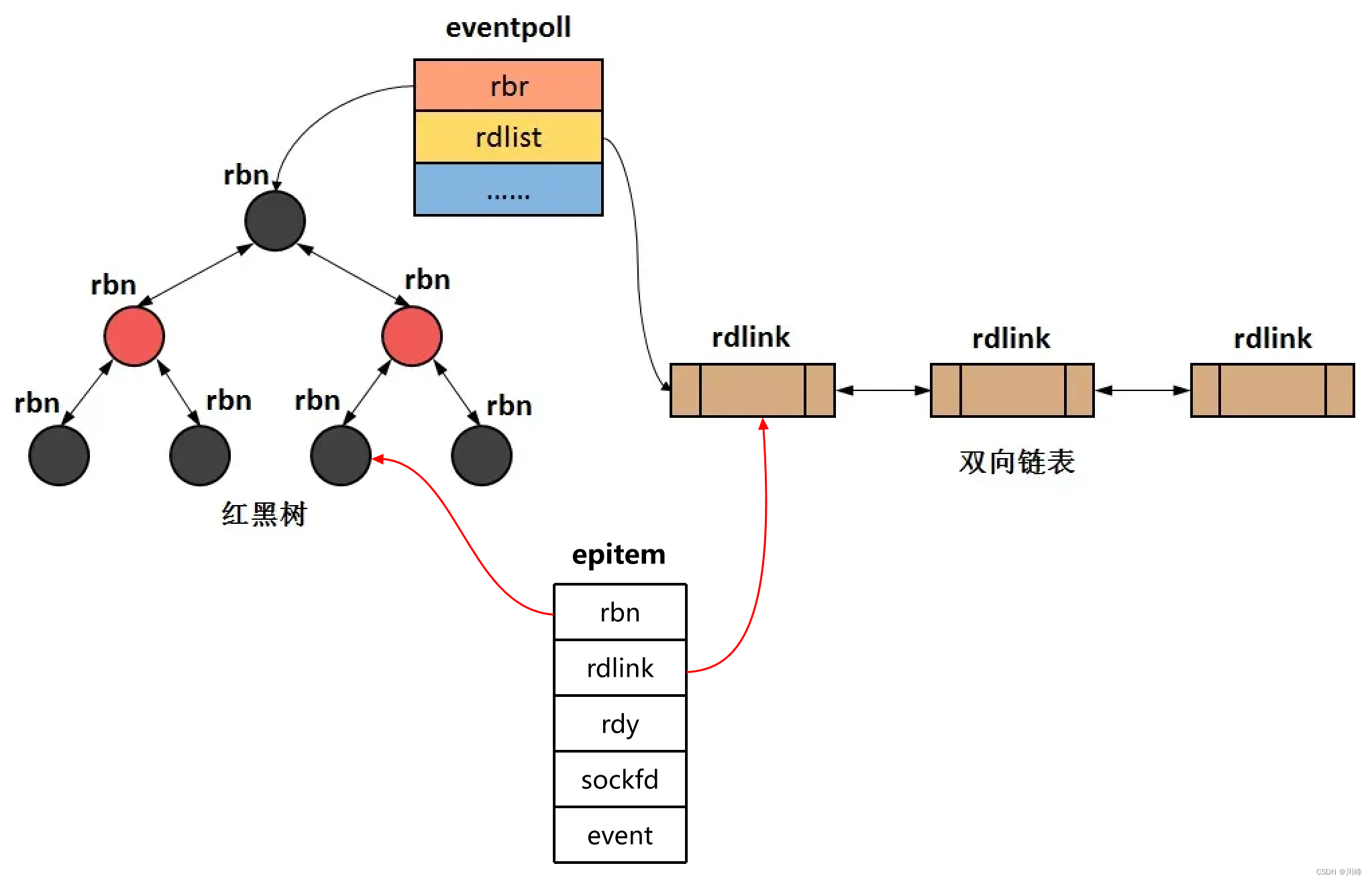
struct eventpoll {/** This mutex is used to ensure that files are not removed* while epoll is using them. This is held during the event * collection loop, the file cleanup path, the epoll file exit* code and the ctl operations. */struct mutex mtx;/* Wait queue used by sys_epoll_wait()*/ wait_queue_head_t wq;/* Wait queue used by file->pol1()*/ wait_queue_head_t poll_wait;/* List of ready file descriptors */ struct list_head rdllist;/* Lock which protects rdllist and ovflist */ rwlock_t lock;/* RB tree root used to store monitored fd structs */ struct rb_root_cached rbr;/** This is a single linked list that chains all the "struct epitem" that* happened while transferring ready events to userspace w/out* holding ->lock.*/struct epitem *ovflist;/* wakeup_source used when ep_scan_ready_list is running */ struct wakeup_source *wsj/* The user that created the eventpoll descriptor */ struct user_struct *user;struct file *file;/* used to optimize loop detection check */ u64 gen;
}
就绪列表引用着就绪的 socket,所以它应能够快速的插入数据。
程序可能随时调用 epoll_ctl 添加监视 socket,也可能随时删除。当删除时,若该 socket 已经存放在就绪列表中,它也应该被移除。
所以就绪列表应是一种能够快速插入和删除的数据结构。双向链表就是这样一种数据结构,epoll 使用双向链表来实现就绪队列,也就是 Linux 源码中的rdllist:
/* List of ready file descriptors */
struct list_head rdllist;
既然 epoll 将“维护监视队列”和“进程阻塞”分离,也意味着需要有个数据结构来保存监视的 socket。至少要方便的添加和移除,还要便于搜索,以避免重复添加。红黑树是一种自平衡二叉查找树,搜索、插入和删除时间复杂度都是 O(log(N)),效率较好。epoll 使用了红黑树作为索引结构,也就是 Linux 源码中的rbr:
/* RB tree root used to store monitored fd structs */
struct rb_root_cached rbr;
eventpoll中的rbr成员变量指向红黑树的根节点,而rdlist成员变量指向双链表的头结点。
因为操作系统要兼顾多种功能,以及由更多需要保存的数据,rdlist 并非直接引用 socket,而是通过 epitem 间接引用,红黑树的节点也是 epitem 对象。
struct epitem {RB_ENTRY(epitem) rbn;/* RB_ENTRY(epitem) rbn等价于struct { struct type *rbe_left; //指向左子树struct type *rbe_right; //指向右子树struct type *rbe_parent; //指向父节点int rbe_color; //该节点的颜色} rbn*/LIST_ENTRY(epitem) rdlink;/* LIST_ENTRY(epitem) rdlink等价于struct { struct type *le_next; //指向下个元素struct type **le_prev; //前一个元素的地址}*/int rdy; //判断该节点是否同时存在与红黑树和双向链表中int sockfd; //socket句柄struct epoll_event event; //存放用户填充的事件
};
结论
epoll 在 select 和 poll(poll 和 select 基本一样,有少量改进)的基础引入了 eventpoll 作为中间层,使用了红黑树和双向链表等先进的数据结构,是一种高效的多路复用技术。
相关文章:
【计算机网络笔记九】I/O 多路复用
阻塞 IO 和 非阻塞 IO 阻塞 I/O 和 非阻塞 I/O 的主要区别: 阻塞 I/O 执行用户程序操作是同步的,调用线程会被阻塞挂起,会一直等待内核的 I/O 操作完成才返回用户进程,唤醒挂起线程非阻塞 I/O 执行用户程序操作是异步的…...

踩坑日记 《正确的使用Vuex》基于 uniapp Vue3 setup 语法糖 vuex4 项目 太多坑了要吐了
踩坑日记 《正确的使用Vuex》基于 uniapp Vue3 setup 语法糖 vuex4 项目 太多坑了要吐了 完美解决页面数据不刷新 或者数据慢一步刷新 页面使用html <template><view><template v-if"cartData.data.length>0"><!-- 自定义导航栏 --><…...

Python无废话-办公自动化Excel修改数据
如何修改Excel 符合条件的数据?用Python 几行代码搞定。 需求:将销售明细表的产品名称为PG手机、HW手机、HW电脑的零售价格分别修改为4500、5500、7500,并保存Excel文件。如下图 Python 修改Excel 数据,常见步骤: 1&…...

MySQL系统架构设计
MySQL 一、MySQL整体架构1.1 SQL接口1.2 解析器 Parser1.3 查询优化器 Optimizer1.3.1 逻辑优化1.3.2 物理优化1.3.3 explain1.4 缓存 Cache1.5 存储引擎 Stroage Management1.6 一条查询SQL的执行流程二、缓存池(Buffer Pool)2.1 Buffer Pool 预读机制2.2 Buffer Pool free链…...

Google vs IBM vs Microsoft: 哪个在线数据分析师证书最好
Google vs IBM vs Microsoft: 哪个在线数据分析师证书最好? 对目前市场上前三个数据分析师证书进行审查和比较|Madison Hunter 似乎每个重要的公司都推出了自己版本的同一事物:专业数据分析师认证,旨在使您成为雇主的下一个热门商品。 随着…...
数据链路层 MTU 对 IP 协议的影响
在介绍主要内容之前,我们先来了解一下数据链路层中的"以太网" 。 “以太网”不是一种具体的网络,而是一种技术标准;既包含了数据链路层的内容,也包含了一些物理层的内容。 下面我们再来了解一下以太网数据帧ÿ…...
一文拿捏基于redis的分布式锁、lua、分布式性能提升
1.分布式锁 jdk的锁: 1、显示锁:Lock 2、隐式锁:synchronized 使用jdk锁保证线程的安全性要求:要求多个线程必须运行在同一个jvm中 但现在的系统基本都是分布式部署的,一个应用会被部署到多台服务器上,s…...

机器学习必修课 - 如何处理缺失数据
运行环境:Google Colab 处理缺失数据可简单分为两种方法:1. 删除具有缺失值的列 2. 填充 !git clone https://github.com/JeffereyWu/Housing-prices-data.git下载数据集 import pandas as pd from sklearn.model_selection import train_test_split导…...

阿里云服务器方升架构、自研硬件、AliFlash技术创新
阿里云服务器技术创新:服务器方升架构及自研硬件、自研存储硬件AliFlash和阿里云异构计算加速平台,阿里云百科分享阿里云服务器有哪些技术创新: 目录 服务器技术创新 服务器方升架构及自研硬件 自研存储硬件AliFlash 阿里云异构计算加速…...
知识工程---neo4j 5.12.0+GDS2.4.6安装
(已安装好neo4j community 5.12.0) 一. GDS下载 jar包下载地址:https://neo4j.com/graph-data-science-software/ 下载得到一个zip压缩包,解压后得到jar包。 二. GDS安装及配置 将解压得到的jar包放入neo4j安装目录下的plugi…...

BUUCTF reverse wp 81 - 85
[SCTF2019]babyre 反编译失败, 有花指令 有一个无用字节, 阻止反编译, patch成0x90 所有标红的地方nop掉之后按p重申函数main和loc_C22, F5成功 int __cdecl main(int argc, const char **argv, const char **envp) {char v4; // [rspFh] [rbp-151h]int v5; // [rsp10h] [rb…...
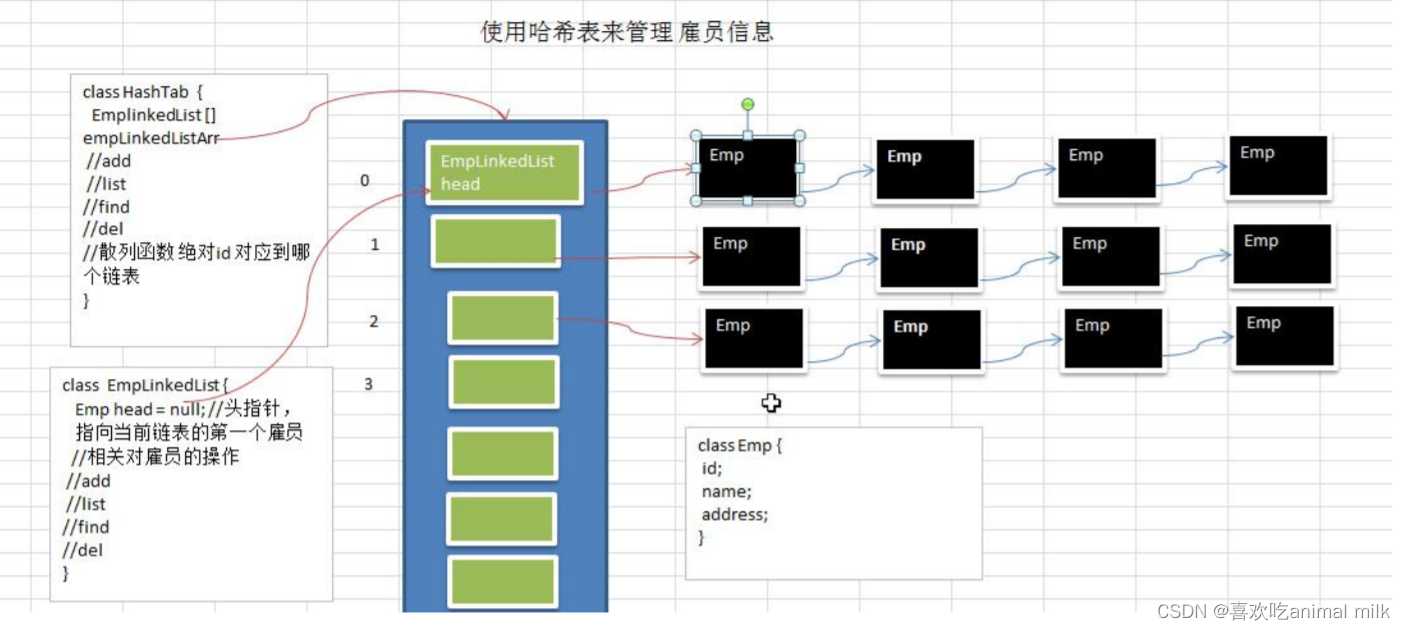
数据结构-哈希表
系列文章目录 1.集合-Collection-CSDN博客 2.集合-List集合-CSDN博客 3.集合-ArrayList源码分析(面试)_喜欢吃animal milk的博客-CSDN博客 4.数据结构-哈希表_喜欢吃animal milk的博客-CSDN博客 文章目录 目录 系列文章目录 文章目录 前言 一 . 什么是哈希表&a…...

深度学习在图像识别领域还有哪些应用?
深度学习在图像识别领域的应用非常广泛,除了之前提到的图像分类、目标检测、语义分割和图像生成,还有其他一些应用。 图像超分辨率重建:深度学习技术可以用于提高图像的分辨率,例如通过使用生成对抗网络(GANÿ…...
前端项目练习(练习-005-webpack-03)
学习前,首先,创建一个web-005项目,内容和web-004一样。(注意将package.json中的name改为web-005) 前面的代码中,打包工作已经基本完成了,下面开始在本地启动项目。这里需要用到webpack-dev-serv…...

『力扣每日一题10』:字符串中的单词数
因为身体原因,再加上学校的 DeadLine 比较多,太忙太累,拖更了半个月。现在开始重拾日更,期待我们一起遇见更好的自己! 一、题目 统计字符串中的单词个数,这里的单词指的是连续的不是空格的字符。 请注意&a…...

初级篇—第三章多表查询
文章目录 为什么需要多表查询一个案例引发的多表连接初代查询笛卡尔积(或交叉连接)的理解 多表查询分类等值连接 vs 非等值连接自连接 vs 非自连接内连接VS外连接 SQL99语法实现多表查询内连接的实现外连接的实现左外连接右外连接满外连接 UNION的使用7种…...
<Xcode> Xcode IOS无开发者账号打包和分发
关于flutter我们前边聊到的初入门、数据解析、适配、安卓打包、ios端的开发和黑苹果环境部署,但是对于苹果的打包和分发,我只是给大家了一个链接,作为一个顶级好男人,我认为这样是对大家的不负责任,那么这篇就主要是针…...

vertx的学习总结2
一、什么是verticle verticle是vertx的基本单元,其作用就是封装用于处理事件的技术功能单元 (如果不能理解,到后面的实战就可以理解了) 二、写一个verticle 1. 引入依赖(这里用的是gradle,不会吧&#…...
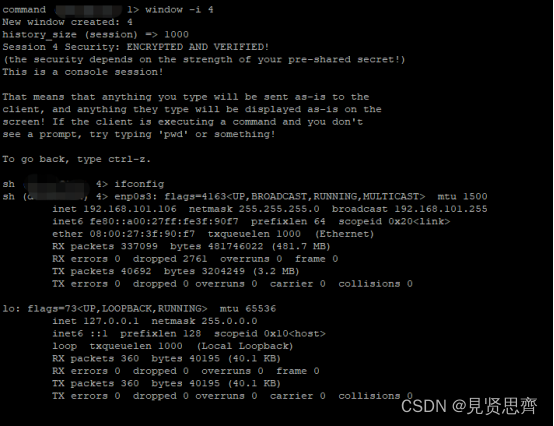
网络安全内网渗透之DNS隧道实验--dnscat2直连模式
目录 一、DNS隧道攻击原理 二、DNS隧道工具 (一)安装dnscat2服务端 (二)启动服务器端 (三)在目标机器上安装客户端 (四)反弹shell 一、DNS隧道攻击原理 在进行DNS查询时&#x…...

探索ClickHouse——连接Kafka和Clickhouse
安装Kafka 新增用户 sudo adduser kafka sudo adduser kafka sudo su -l kafka安装JDK sudo apt-get install openjdk-8-jre下载解压kafka 可以从https://downloads.apache.org/kafka/下找到希望安装的版本。需要注意的是,不要下载路径包含src的包,否…...
)
RustFS实战:5分钟在Linux服务器上搭个私有S3兼容存储(保姆级配置+避坑指南)
RustFS实战:5分钟在Linux服务器上搭个私有S3兼容存储(保姆级配置避坑指南) 最近在折腾一个需要私有文件存储的Side Project,既不想用公有云S3(太贵),又嫌MinIO配置繁琐。偶然发现RustFS这个基于…...

OpenClaw+百川2-13B:个人知识库自动整理与问答系统搭建
OpenClaw百川2-13B:个人知识库自动整理与问答系统搭建 1. 为什么需要本地化知识管理系统 去年整理博士论文资料时,我遇到了一个典型的研究者困境:电脑里堆积了237个PDF、643篇网页存档和无数零散的笔记片段,但需要引用某个概念时…...

stm32开发新手福音:告别复杂安装,用快马ai生成带详解的hal库基础代码
作为一名刚接触STM32开发的新手,我最近在尝试用HAL库控制GPIO时遇到了不少麻烦。从下载安装STM32CubeMX到配置工程,每一步都让我这个小白手忙脚乱。直到发现了InsCode(快马)平台,整个过程变得简单多了——不需要自己搭建环境,AI就…...

别再混淆了!FFmpeg提取AAC/H264流时常见的3个容器格式误区
别再混淆了!FFmpeg提取AAC/H264流时常见的3个容器格式误区 第一次用FFmpeg提取音频时,我把.m4a文件直接重命名为.aac,结果播放器报错——这个看似简单的操作背后,隐藏着容器格式与编码格式的深层差异。本文将用真实踩坑案例&#…...

基于Matlab的11种图像清晰度评价指标:直接可运行,联系我
基于matlab图像清晰度评价指标。 一共11种。 程序已调通,可直接运行。 需要直接联系。 基于matlab图像清晰度评价指标。 一共11种。 程序已调通,可直接运行。 需要直接联系。 图像剃度的清晰度评价(EOG, Roberts, Tenengrad, Brenner,Variance, Laplace,…...

RPA-Python与pytest-cinderclient集成:打造高效OpenStack Cinder测试自动化方案
RPA-Python与pytest-cinderclient集成:打造高效OpenStack Cinder测试自动化方案 【免费下载链接】RPA-Python Python package for doing RPA 项目地址: https://gitcode.com/gh_mirrors/rp/RPA-Python RPA-Python作为强大的Python机器人流程自动化工具包&…...

Newtonsoft.Json-for-Unity:Unity开发者的终极JSON解决方案指南
Newtonsoft.Json-for-Unity:Unity开发者的终极JSON解决方案指南 【免费下载链接】Newtonsoft.Json-for-Unity Newtonsoft.Json (Json.NET) 10.0.3, 11.0.2, 12.0.3, & 13.0.1 for Unity IL2CPP builds, available via Unity Package Manager 项目地址: https:…...
)
基于LangChain的RAG与Agent智能体开发 - 持久化会话记忆功能实现(RunnableWithMessageHistory+RedisChatMessageHistory)
大家好,我是小锋老师,最近更新《2027版 基于LangChain的RAG与Agent智能体 开发视频教程》专辑,感谢大家支持。本课程主要介绍和讲解RAG,LangChain简介,接入通义千万大模型 ,Ollama简介以及安装和使…...

OpenClaw安全指南:百川2-13B模型权限管控与敏感操作防护
OpenClaw安全指南:百川2-13B模型权限管控与敏感操作防护 1. 为什么需要安全防护机制 去年冬天的一个深夜,我的OpenClaw经历了一次"惊魂时刻"。当时我让AI助手整理财务表格,结果它误将包含个人银行账号的临时文件上传到了云存储。…...

3步精通n8n浏览器自动化:从安装到流程编排
3步精通n8n浏览器自动化:从安装到流程编排 【免费下载链接】n8n-nodes-puppeteer n8n node for requesting webpages using Puppeteer 项目地址: https://gitcode.com/gh_mirrors/n8/n8n-nodes-puppeteer n8n-nodes-puppeteer是一款专为n8n平台开发的浏览器控…...